
一种无人机集群对抗多耦合任务智能决策方法
2021-05-24 07:31:58文永明石晓荣黄雪梅
宇航学报 2021年4期
文永明,石晓荣,黄雪梅,余 跃
(北京控制与电子技术研究所,北京100038)
0 引 言
随着集群技术和人工智能的发展,基于群体智能的集群协同技术逐渐发展为未来智能化战争的发展方向[1-3]。无人机集群利用低成本、大规模和分布式的优势,协同侦查作战可以体现出显著的灵活性和智能性。无人机集群协同侦查在线决策主要包括协同目标分配和突防轨迹规划等多个相互耦合的任务,无人机集群需要根据战场态势和作战任务决策出每架无人机的侦查目标和突防轨迹,以最大化集群对抗效能。随着对抗环境愈加复杂动态,对抗手段愈加多样智能,无人机集群对抗在线决策存在耦合任务多、决策空间大和场景不确定难题,导致传统基于专家知识和现代优化算法的决策方法难以同时满足在线决策的实时性、最优性和泛化性。
随着人工智能技术的发展与突破[4],尤其是深度强化学习在智能决策等方面得到了广泛关注与研究[5-7]。深度强化学习是深度学习和强化学习的有机结合,深度学习善于拟合,可通过深层神经网络表征复杂空间的非线性和泛化性,强化学习善于决策,可通过迭代学习使累计奖励最大化来获得高性能策略。深度强化学习基于大量离线训练得到智能策略网络,进行快速在线决策,可弥补无人机集群对抗程序化策略带来的局限性,提升应对复杂飞行环境和突发事件的适应能力[8]。
在深度强化学习架构方面,当决策问题由单个任务或少数简单任务构成时,通常采用集中式深度强化学习架构来解决。如图1所示,集中式架构的多耦合任务使用同一套策略网络、奖励函数和经验池,进行集中式耦合训练,在决策时一次同时输出各个任务的动作。集中式架构建模简单,并且在理论上可保证存在全局最优解。

图1 集中式架构Fig.1 Centralized architecture
文献[9]基于DDPG集中式架构优化一类变体飞行器外形,因其决策空间较小,故可以快速收敛到最优变外形策略。文献[10]采用DQN(Deep Q-Network)算法对多个Atari小游戏(比如“乒乓球”、“打砖块”等)进行建模和训练,最终在多款游戏上的表现超越了人类玩家。然而,在“蒙特祖玛的复仇”这款游戏中,DQN算法的胜率为0%[11],其原因是这款游戏的任务较多且相互耦合(比如爬楼梯、躲避敌人、拿钥匙等),策略空间巨大,集中式架构在有限计算资源下难以收敛。为了解决多个耦合复杂任务所带来的决策空间爆炸等问题,分层式深度强化学习架构被提出[12]。如图2所示,分层式架构的多耦合任务使用多套对应的策略网络、奖励函数和经验池,按照任务间的逻辑关系进行分层单独训练,在决策时输出各自的动作进行组合来完成整个决策问题。分层式架构将多耦合任务进行解耦建模与分层单独训练,可以缩小整个决策问题的策略空间,使得各个任务的策略网络收敛速度加快。
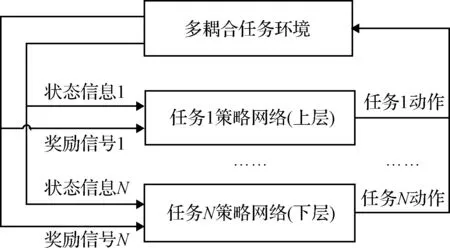
图2 分层式架构Fig.2 Hierarchical architecture
文献[13]采用分层深度强化学习架构将“蒙特祖玛的复仇”抽象成多个不同层次的子任务进行建模,AI可以完成游戏任务。文献[14]采用分层深度强化学习架构对一款篮球游戏建模,基于下层已熟练掌握的篮球技巧,智能体学到了上层的有效策略。文献[15]基于高斯过程回归与深度强化学习的分层人机协作控制方法,并以人机协作控制球杆系统为例检验该方法的高效性。然而,分层式架构的各个子任务的策略网络分离,即使各个子任务都收敛到各自的全局最优解,但是将它们组合后,得到的结果很可能不是整个任务的全局最优解。例如在无人机集群对抗中,目标分配结果是轨迹规划的输入,而轨迹规划性能是目标分配的依据,分层式架构将这两个子任务分开训练,没有充分考虑它们之间固有的耦合关系,因此多耦合任务间的协同性无法充分体现,集群对抗效能无法充分发挥。本文针对无人机集群对抗中耦合任务多和决策空间大难题,结合集中式和分层式架构的优点,设计了面向多耦合任务的混合式深度强化学习架构,通过构建多套相关联的多耦合任务分层策略网络进行集中耦合训练,可提升多耦合任务间的协同性和集群对抗效能。
在深度强化学习奖励函数设计方面,序贯动作导致的稀疏奖励问题是指在多步强化学习中,往往只在最后一步存在明确奖励,而中间过程的即时奖励函数难以人为设计且存在主观性和经验性。例如无人机集群对抗的多步轨迹规划只在结束时才能得到是否被拦截或者侦查目标的结果,而中间过程很难根据当前的位置和速度等信息设计合适的即时奖励函数来引导突防和侦查目标。强化学习是求累计奖励期望最大时的最优策略,奖励函数不同将直接影响策略的性能,如果没有合适的即时奖励,稀疏奖励问题会导致策略网络难以快速且稳定收敛[16]。为了解决稀疏奖励问题,文献[17]提出逆向强化学习方法,即专家在完成某项任务时,其决策往往是最优或接近最优,可以假设,当所有的策略所产生的累积奖励期望都不比专家策略所产生的累积奖励期望大时,所对应的奖励函数就是根据示例学到的奖励函数。为了使逆向强化学习可以很好地扩展到具有大量状态的系统,将其与深度学习相结合,在神经网络中学习状态动作对的奖励,如基于最大边际法的深度逆向强化学习[18]和基于深度Q网络的深度学徒学习[19]等。然而,逆向强化学习和深度逆向强化学习都是从专家示例中学习奖励函数,在复杂场景下无人机集群对抗问题中难以获取足够的专家示例来支撑上述方法。本文针对轨迹规划序贯决策的稀疏奖励难题,设计了基于轨迹构造的一步式动作空间设计方法,回避了多步决策的中间过程,从而避免了稀疏奖励问题,可使策略网络稳定快速收敛。
在深度强化学习的泛化性研究方面,泛化性是指训练好的智能策略网络在未见过的场景中也具有一定的适应能力,其体现在深度神经网络对独立同分布数据强大的拟合和预测能力。因此,在深度强化学习训练过程中,使策略网络探索到尽可能大的决策空间,增加数据的多样性,是提升其泛化性的有效途径。2017年,DeepMind团队在《Nature》上推出了围棋人工智能AlphaZero[20],AlphaZero不需要人类专家知识,只使用纯粹的深度强化学习和蒙特卡洛树搜索,经过3天的自我博弈就以100比0的成绩完败了AlphaGo,AlphaZero强大的搜索能力和泛化性得益于海量且多样的自我博弈数据。文献[21]指出,AlphaZero智能化方法框架可以启发人工智能在智能指挥决策等领域的应用。本文针对强对抗条件下的场景不确定难题,基于无人机集群红蓝对抗仿真平台,设计了基于多随机场景的红蓝博弈训练方法,通过随机变化对抗双方的初始位置和速度等,来设置每局的对抗态势,从而得到多样化的对抗训练数据;通过设计蓝方AI,采用红蓝博弈的方式获得更加智能的蓝方策略作为红方AI的陪练,从而可以进一步提升红方AI的泛化性。
本文的主要创新点和贡献:1)针对无人机集群对抗中耦合任务多和决策空间大难题,设计了面向多耦合任务的混合式深度强化学习架构,可提升多耦合任务间的协同性和集群对抗效能;2)针对轨迹规划序贯决策的稀疏奖励难题,设计了基于轨迹构造的一步式动作空间设计方法,可加快策略网络收敛速度;3)针对强对抗条件下的场景不确定难题,设计了基于多随机场景的红蓝博弈训练方法,可增强策略网络的泛化性。
1 混合式深度强化学习架构
混合式架构将集中式架构和分层式架构进行结合。多耦合任务使用多套与子任务对应的执行者-评估者(Actor-Critic, AC)神经网络与奖励函数分层构建网络,且多个经验池中的经验相互关联。在策略网络训练控制器的调度下,多个策略网络按照多任务间的分层关系进行集中耦合训练。在训练过程中,每个评估者(Critic)网络收集所有任务的状态和动作信息作为评价的输入,从而为策略更新提供准确且稳定的信号,更充分的状态和动作信息有助于提高耦合任务间的协同性;在策略执行过程中,各任务只需根据自己的状态和执行者(Actor)网络,进行决策控制,如图3所示。
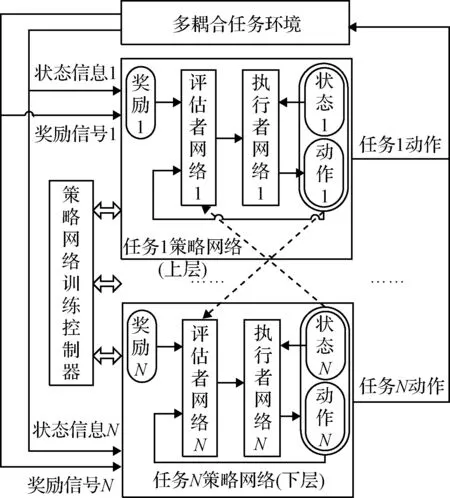
图3 混合式架构Fig.3 Hybrid architecture
混合式架构保留了集中式和分层式架构的主要优点,又克服了它们的突出缺点,既保证了各个耦合任务之间相对稳定的训练环境,有利于得到多任务协同下的全局最优解,又使得策略空间规模可接受,有利于策略网络快速收敛。三种深度强化学习架构特点对比如表1所示。
混合式深度强化学习架构主要由多任务策略网络和策略网络训练控制器组成,多任务策略网络利用多套相关联的AC网络对子任务进行建模并分层,策略网络训练控制器按照多任务间的分层关系进行集中耦合训练。混合式架构的建模和训练流程如图4所示。
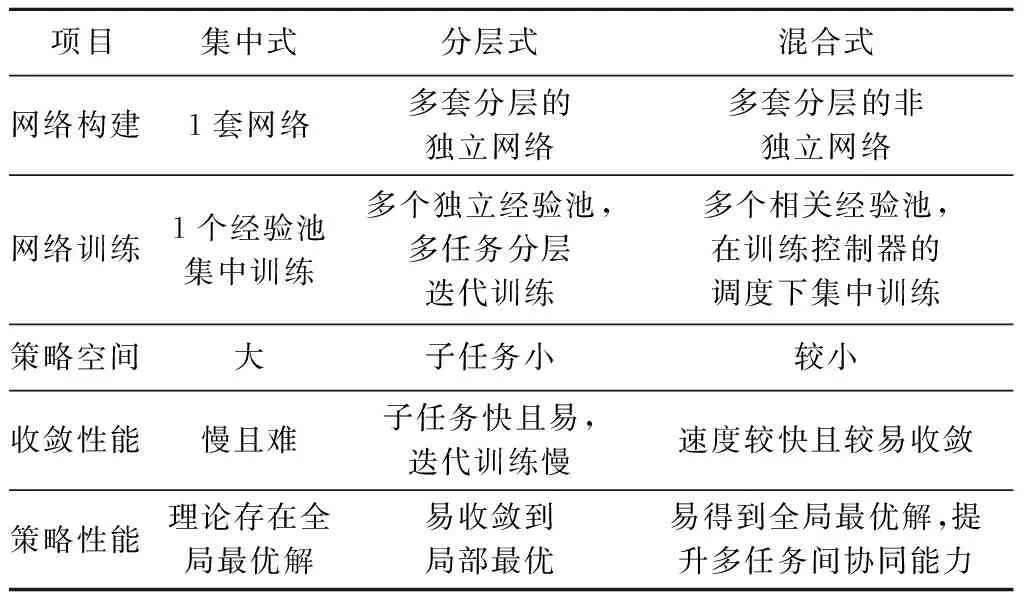
表1 三种架构特点对比Table 1 Comparison of three architectures
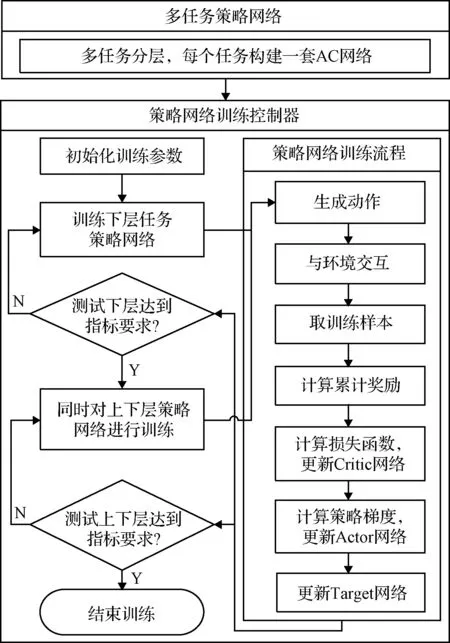
图4 混合式架构建模与训练流程图Fig.4 Hybrid architecture modeling and training flow chart
1.1 多任务策略网络
多耦合任务M由N个子任务mi组成,即M={mi}(i表示子任务编号且i=1,2,…,N),根据多耦合任务之间的逻辑关系,将N个子任务进行分层。任务mi基于AC架构构建执行者(Actor)神经网络Ai和评估者(Critic)神经网络Ci。任务mi的状态空间为si,动作空间为ai,奖励值为ri。任务mi的经验池设计为:
ei={s1,s2,…,sN,a1,a2,…,aN,
s′1,s′2,…,s′N,ri,d1,d2,…,dN}
(1)
式中:s′i为任务mi下一步的状态,di为任务mi结束标志,且当任务mi结束时,di=1,反之,di=0。
任务mi的评估者神经网络Ci的输入层为所有任务的状态S={s1,s2,…,sN}和所有任务的动作A={a1,a2,…,aN},Ci的输出层为1维的全局评估值。任务mi的执行者神经网络Ai的输入层为任务mi的状态si,Ai的输出层为任务mi的动作ai。
1.2 策略网络训练控制器
为了多耦合任务M的整个策略网络能够快速稳定收敛,下层任务需要给上层任务创造良好的学习环境基础,故策略网络训练控制器设计为先训练下层任务,达到设计指标后,再耦合训练上一层任务,即上下层集中训练。
策略网络训练控制器设计训练流程如下:
1)初始化:设置多任务策略网络和策略网络训练控制器参数;
2)生成下层动作:根据下层执行者神经网络Ai的策略生成动作:
ai=Ai(si)+δi
(2)
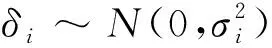
3)生成上层动作:上层任务随机生成动作:
ai=ξi
(3)
式中:ξi为服从均匀分布的随机数;
4)与仿真环境交互:将得到动作集合A={a1,a2,…,aN}在仿真环境中执行,得到奖励值集合R={r1,r2,…,rN},下一个状态集合S′={s′1,s′2,…,s′N}和任务是否结束标志集合D={d1,d2,…,dN};
5)保存经验:将经验
ei={S,A,S′,ri,D}={s1,s2,…,sN,a1,a2,…,
aN,s′1,s′2,…,s′N,ri,d1,d2,…,dN}
(4)
存入任务mi的经验池Ei;
6)策略网络训练:当任务mi的经验池Ei总经验数达到开始训练的条件时,开始对任务mi的策略网络进行训练:
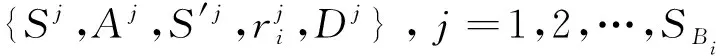
(2)定义累计奖励函数:令任务mi的累计奖励为:
(5)
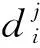
(3)定义损失函数:令任务mi的损失函数为:
(6)
式中:Ci(·)为任务mi在神经网络参数为θCi下的评估者神经网络价值函数。通过求L(θCi)的极小值来更新θCi;
(4)定义采样策略梯度函数:令任务mi的采样策略梯度为:
(7)
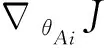
(5)更新策略网络参数:根据式(7)估计的策略梯度通过深度学习优化器来更新任务mi的执行者神经网络参数θAi;
(6)更新目标网络参数:满足一定条件时,按照式(8)来更新任务mi的目标执行者神经网络参数θ′Ai和目标评估者神经网络参数θ′Ci:
(8)
式中:τi为神经网络参数更新频率,“←”表示赋值。
(7)测试与训练层级递进:训练一定次数后,测试当前层对应的所有任务是否都达到设计指标,如果是,则开始上一层任务的训练;否则,继续本层任务的训练;
(8)循环:重复流程(1)至流程(8),直至多耦合任务M训练结束,且测试达到预定指标。
1.3 无人机集群对抗混合式架构建模
1) 多任务策略网络。上层:协同目标分配,决策红方无人机集群中每架无人机的侦查目标,以最大化集群对抗效能(侦查总得分);下层:突防轨迹规划,决策红方无人机的突防和侦查轨迹,既要进行躲避机动又要保留足够的机动能力对目标进行侦查,以最大化突防概率(突防成功的红方无人机数量除以红方无人机总数量)和侦查成功率(侦查成功的红方无人机数量除以红方无人机总数量)。
2)状态空间。目标分配策略网络的状态主要包括:红方无人机数量、位置、速度和蓝方待侦查目标数量、位置、价值等;轨迹规划策略网络的状态主要包括:红方无人机位置、速度和蓝方待侦查目标位置等。
3)动作空间。目标分配策略网络的动作为:红方无人机侦查目标的编号;轨迹规划策略网络的动作为:红方无人机轨迹构造函数的参数。
4)奖励函数。确定3个元奖励分别为突防元奖励ro_tf、侦查元奖励ro_zc和效能元奖励ro_xn。红方无人机突防成功,则ro_tf=1,否则ro_tf=-1;红方无人机成功侦查目标,则ro_zc=1,否则ro_zc=-1;集群对抗效能归一化作为效能元奖励ro_xn。为了进一步体现各个耦合任务之间的协同性,采用元奖励加权的方式使目标分配和轨迹规划的奖励函数相互关联。根据目标分配对各个元奖励的影响确定目标分配的突防权重wo_tf_mb、侦查权重wo_zc_mb和效能权重wo_xn_mb,且满足wo_tf_mb+wo_zc_mb+wo_xn_mb=1。同理,根据轨迹规划对各个元奖励的影响确定轨迹规划的突防权重wo_tf_gj、侦查权重wo_zc_gj和效能权重wo_xn_gj,且满足wo_tf_gj+wo_zc_gj+wo_xn_gj=1。则目标分配奖励函数为:
rmb=wo_tf_mbro_tf+wo_zc_mbro_zc+wo_xn_mbro_xn
(9)
轨迹规划的奖励函数为:
rgj=wo_tf_gjro_tf+wo_zc_gjro_zc+wo_xn_gjro_xn
(10)
5)策略网络训练控制器。先训练下层轨迹规划策略网络。当突防概率和侦查成功率达到指标要求后,再训练上层目标分配策略网络,两个任务进行集中耦合训练,直至突防概率、侦查成功率和集群对抗效能达到指标要求后,训练完毕。
2 基于轨迹构造的一步式动作空间设计方法
在突防轨迹规划中,红方无人机通过在线生成机动指令来达到躲避拦截和侦查目标的目的。通常采用多步序贯决策方式会带来稀疏奖励问题,它是指在每个决策周期都生成无人机的机动指令,但只在最后一步存在明确的奖励,而过程奖励难以设计,会导致策略网络难以快速稳定收敛。针对上述问题,设计了基于轨迹构造的一步式动作空间设计方法。
根据红方无人机机动特性和蓝方拦截无人机的拦截特点确定突防轨迹构造函数表示为:
nc(t)=F(P,t)+a0(t)
(11)
式中:nc(t)表示t时刻无人机的机动指令。a0(t)表示t时刻无人机的比例导引指令,引导无人机飞向目标。F(P,t)表示t时刻无人机的附加机动指令函数,控制机动突防,P为函数参数集合。F(P,t)的具体表达形式可以根据无人机的机动特性和拦截无人机的拦截特点确定,比如无人机的动态性能良好且蓝方拦截策略简单,F(P,t)可确定为方波函数;无人机的动态性能一般且蓝方拦截策略简单,F(P,t)可确定为正弦函数;蓝方拦截策略复杂,F(P,t)可确定为多项式函数。
从函数参数集合P中确定待优化的参数,表示为:
P=C∪X
(12)
式中:C={c1,c2,…,cm}表示m个常值参数集合,X={x1,x2,…,xn}表示n个待优化参数集合。
确定深度强化学习的动作空间表示为:
A=[x1,x2,…,xn]T(ximin≤xi≤ximax,i=1,2,…,n)
(13)
式中:ximin表示待优化参数xi的最小值,ximax表示待优化参数xi的最大值。
基于轨迹构造的一步式动作空间设计方法只需决策一次突防轨迹构造函数的参数就可以规划出完整的轨迹,对抗仿真后即可得到一次明确的奖励,即一个动作对应一个奖励,因此避免了序贯动作的稀疏奖励问题,使收敛速度和稳定性有效提升。
3 基于多随机场景的红蓝博弈训练方法
针对强对抗条件下的场景不确定难题,基于无人机集群红蓝对抗仿真平台,设计基于多随机场景的红蓝博弈训练方法。
红方无人机集群的作战任务为最大化侦查覆盖蓝方目标编队,红方无人机在飞行过程中会受到蓝方拦截无人机的拦截,在红方无人机突防后,需要飞到待侦查目标附近且保留一定的机动能力进行侦查。如图5所示,无人机集群红蓝对抗的主要场景及设计要素如下:1)红方侦查无人机集群:由NH架侦查无人机组成;2)蓝方待侦查目标编队:由NL个待侦查目标组成,五角星表示主要待侦查目标(需要3架红方无人机侦查保证覆盖目标),三角形表示次要目标(需要2架红方无人机侦查保证覆盖目标);3)蓝方拦截无人机:针对1架红方无人机最多可用2架蓝方无人机进行拦截;4)集群对抗效能:1架红方无人机成功侦查目标得1分,成功侦查主要目标最多得3分,成功侦查次要目标最多得2分,所得总分即为集群对抗效能;5)集群对抗效能比:为了对比不同想定之间的效能,定义集群对抗效能比为集群对抗效能除以理论最大效能。想定的名称用“NHV NL”表示。

图5 典型对抗场景示意图Fig.5 Typical confrontation scenarios
设置多个典型无人机集群对抗想定(如8V5、8V7、12V10、18V12、18V14等)训练策略网络,设定红蓝对抗双方的初始位置和速度等参数的合理变化范围,每一局对抗训练随机选取一个想定和一组参数来设置对抗态势,则通过大量对抗仿真可得到多样化的对抗训练数据。
蓝方的对抗模型和策略通常采用基于专家知识的方式进行建模,然后进行红蓝对抗仿真对红方策略网络进行单方面训练,而基于蓝方单一策略对红方策略网络进行训练容易过拟合,导致红方策略单一且对蓝方策略的变化缺乏泛化性,难以适应高动态的实际战场环境。
设计蓝方策略网络,智能决策蓝方拦截无人机的拦截目标和起飞时机,红蓝策略网络在无人机集群红蓝对抗仿真平台上采用红蓝博弈方式进行训练。红蓝博弈训练方法流程如图6所示,在每个并行的博弈环境中,红蓝策略网络视对方为环境进行学习。为增强博弈训练中策略学习的稳定性,在每个博弈周期的训练中,固定红蓝双方中一方的策略,训练另一方。在每一个博弈周期结束后,根据红蓝方策略的表现进行优胜劣汰,将实力相当的红蓝策略网络配对,进行下一周期的博弈,如此往复,不断提升红方策略网络对不同蓝方策略的泛化性。
多平台分布式红蓝博弈训练场景如图7所示。

图6 红蓝博弈训练流程Fig.6 Red blue game training process

图7 多平台分布式红蓝博弈训练场景Fig.7 Multi platform distributed red blue game training scenario
4 仿真校验
4.1 有效性校验
采用基于多随机场景的红蓝博弈训练方法对红方和蓝方策略网络进行训练,得到最优的红方策略网络(红AI),以18架无人机集群侦查14个蓝方目标编队(18V14)为例来阐述仿真与测试结果。红方按照遗传算法决策,得到的典型红蓝对抗平面轨迹如图8(a)所示;红方按照策略网络决策,得到的典型红蓝对抗平面轨迹如图8(b)所示。
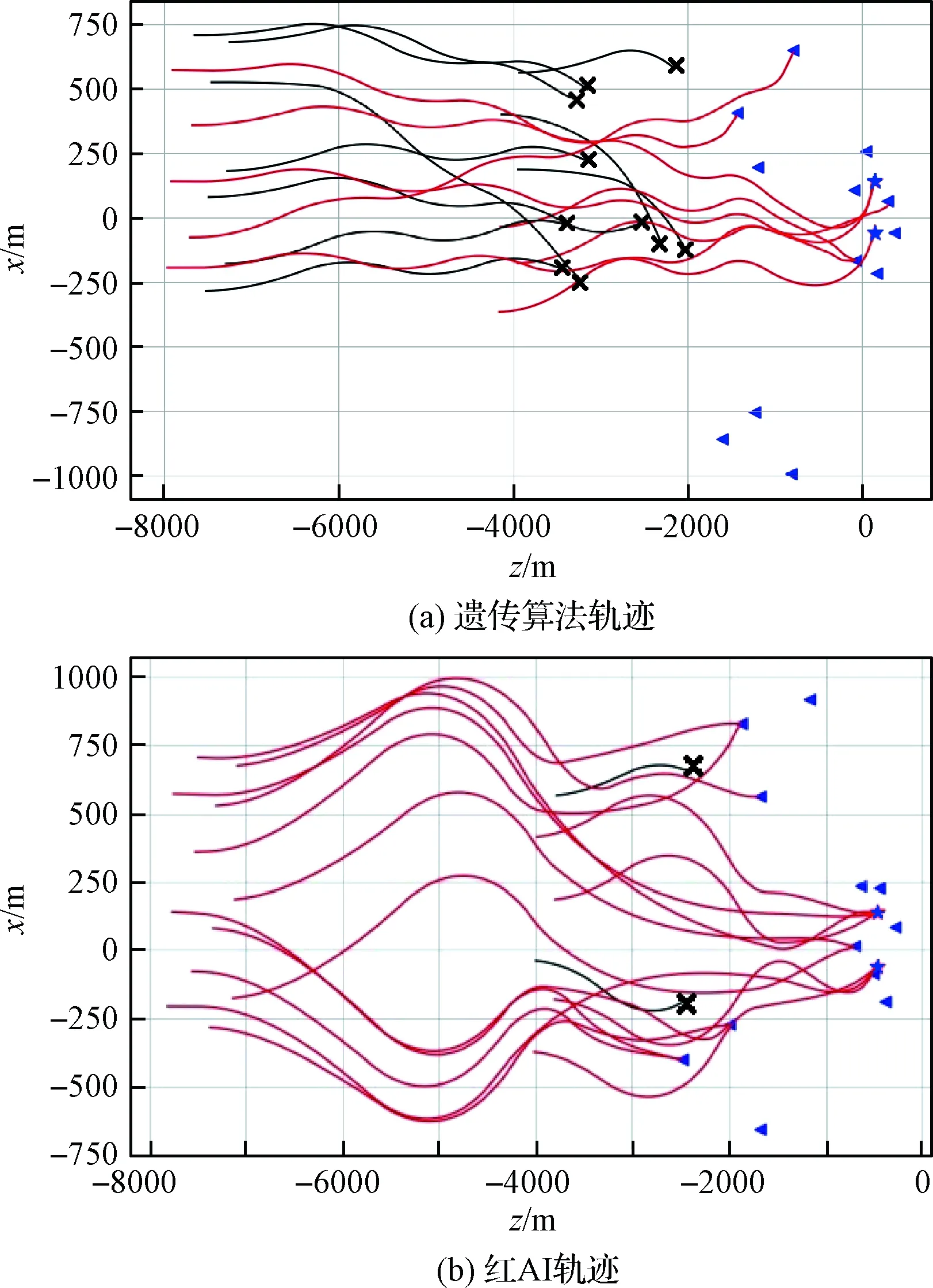
图8 典型平面轨迹Fig.8 Typical plane trajectory
图8中,轨迹末端“×”表示红方无人机被蓝方无人机拦截或机动能力不足导致侦查失败。由图8可得遗传算法的突防概率为8÷18=44%,集群对抗效能比为7÷18=39%;红AI的突防概率为16÷18=89%,集群对抗效能比为15÷18=83%。通过对比可知:红AI可以为红方无人机集群分配合理的侦查目标和规划有效的突防和成功侦查目标轨迹,有效提高了集群对抗效能。
红AI训练过程曲线如图9所示。
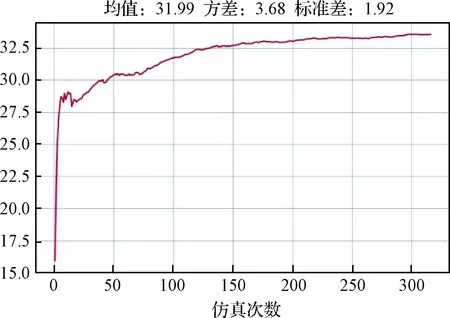
图9 集群对抗效能训练曲线Fig.9 Efficiency training curve of group confrontation
图9中的训练曲线为单平台训练过程,仿真次数为200时,红AI收敛。采用60个无人机集群红蓝对抗仿真平台进行多平台分布式红蓝博弈训练,因此红AI的训练收敛次数约为200×60=12000次。
遗传算法和红AI测试得到的性能对比如表2所示。由表2可得,红AI相比基于遗传算法在集群对抗效能上提升了约95%,说明了本文方法的有效性。

表2 遗传算法与红AI性能对比Table 2 Performance comparison between genetic algorithm and red AI
4.2 泛化性校验
通过对12V10、18V14等场景进行随机训练,得到的策略网络在未训练过的场景上(13V10、17V15)进行泛化性测试,得到的结果如表3所示。由表3可得,策略网络在未训练过场景上的适应性平均大于90%,说明红AI具有一定的泛化性。
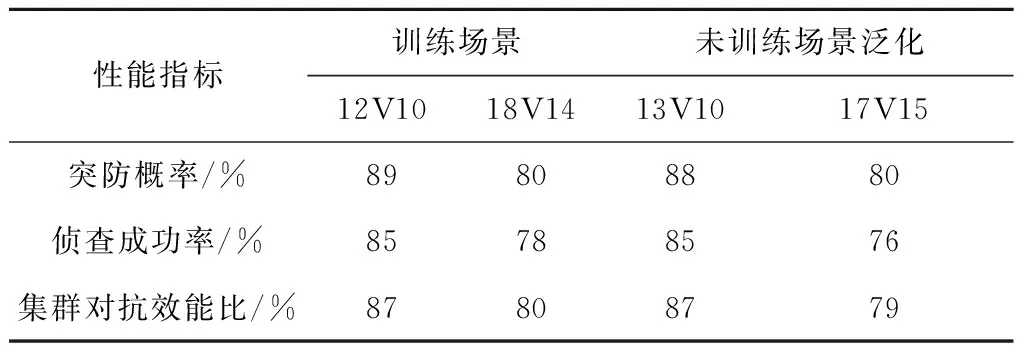
表3 泛化性测试Table 3 Generalization testing
4.3 先进性校验
将集中式架构训练得到的集中式AI、分层式架构训练得到的分层式AI分别在无人机集群红蓝对抗仿真平台测试,得到的性能对比结果如表4所示。
从表4中可以得到以下结论:1)集中式AI在有限计算资源条件下难以收敛;2)分层式AI多任务迭代训练耗时大,且未得到全任务最优策略;3)混合式AI学到了多耦合任务间的协同能力,得到了全任务最优策略,相比分层式AI在集群对抗效能上提升了约31%;混合式AI策略网络收敛速度较快,相比分层式AI收敛速度提升567%。上述结果表明:在多耦合任务决策问题上,混合式深度强化学习架构相比集中式和分层式架构,具有较强的先进性。

表4 三种架构性能对比Table 4 Performance comparison of three architectures
5 结 论
本文针对复杂场景下无人机集群对抗中协同目标分配和突防轨迹规划等多耦合任务的决策问题,提出了一种集群对抗多耦合任务智能决策方法。设计了面向多耦合任务的混合式深度强化学习架构、基于轨迹构造的一步式动作空间设计方法和基于多随机场景的红蓝博弈训练方法,解决了无人机集群对抗在线决策耦合任务多、决策空间大和场景不确定等难题,增强了策略网络的收敛性能和泛化性,提升了无人机集群对抗多耦合任务间的协同性、集群对抗效能。通过与传统方法、集中式架构方法和分层式架构方法进行对比,验证了本文提出方法的有效性和先进性。
猜你喜欢
小学生学习指导·高年级(2023年8期)2023-11-19 05:33:56
散文选刊·下半月(2021年8期)2021-09-03 12:23:42
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
西江月(2014年3期)2014-11-17 05:49:49
棋艺(2014年3期)2014-05-29 14:27:14
棋艺(2009年8期)2009-04-29 08:53:52
中国青年(1983年2期)1983-08-21 03:00:18
