
藏文词向量技术研究综述
2021-05-23 09:30索朗拉姆群诺
电脑知识与技术 2021年11期
索朗拉姆 群诺

摘要:当前伴随社会的发展,此时在NLP中也普遍使用到了深度学习。截至目前,很多学者都将对深度学习模型以及词向量相融合进行了相关的研究和分析。由于藏文涵盖了丰富的信息,在藏文词向量的研究工作中有很大的作用,且藏文词向量问题将能更深层次地解决藏文句法和语义等问题,因此藏文词向量方面恶的研究工作是非常有意义的。文章首先对藏文字(词)的构建做了详细叙述,然后较全面地阐述了藏文词向量技术研究。本文的最后环节就是最后对于未来藏文词向量技术方面的进步提供一些本人的建议和看法。
关键词:自然语言处理;词向量;藏文
中图分类号:TP183 文献标识码:A
文章编号:1009-3044(2021)11-0226-03
Survey of the Research on Tibetan Word Vector Technology
SUO Lang La Mu,QUN Nuo
(Tibet University, School of Information Science and Technology, Lhasa 850000, China)
Abstract: With the development of society, deep learning is also widely used in NLP. Up to now, many scholars have conducted relevant research and analysis on deep learning model and word vector fusion. Since Tibetan contains a wealth of information, it plays an important role in the study of vector of Tibetan words, and the vector of Tibetan words can solve the syntactic and semantic problems in a deeper level, so the research on vector of Tibetan words is of great significance. This paper first gives a detailed description of the construction of Tibetan words and then describes the research on vector technology of Tibetan words in a comprehensive way. The last part of this paper is to provide some Suggestions and views on the future progress of Vector technology of Tibetan words.
Key words:natural language processing;word vector;tibetan
在處理自然语言过程中,最为基础的处理单元指的就是词,以词向量为观察对象其被称作是词嵌入,这本身也作为机内表示形式的一种,为了能够让计算机更好且便捷的理解,这种表示方法主要进行自然语言任务处理的关键工具。由于研究进程的持续迈进,此时词向量不单单只是使用到了自然语言处理方面,其本身也会在其他不同的领域所应用。
如果想要对藏文自然语言进行很好的研究和处理,那么就一定要涉及到藏文词向量。假如想要使得自然语言直接被计算机所理解,语言以数字的形式表达出来,方便计算机理解,而最直接的方法是词语映射到一个向量空间中,用向量来表示词语的信息,而词向量是在NLP领域中重要的基础,它有利于我们研究情感、句法、语义等方向进行分析,所以在研究工作中分析词向量是非常关键和重要的。
通过对传统词表示方法进行分析和理解能够看出,其方法包含了独热表示,而使用到的原理就是借助某个仅包含0 以及 1 的向量来对某个词进行表示,这个向量的维数是词典中词的数目[1]。one-hot表达不能判断语义相似度,单词关系是垂直关系,在两个向量中看不到两个词之间的关系,并且两个词始终是独立的; 100维度的one-hot表示法做多可以表达100个不同的单词,因此,存在高维度容易数据稀疏性之类的问题。随着深度学习技术发展,学者们开始用神经网络方法表示词向量,该方法解决了传统独热表示带来的问题,由此获得的词向量本身具备词以及词之间所呈现出的语义关联性,针对相似词其自身的向量也同样具有某种程度上的相似性,其可以将反义词以及一次多义方面的问题进行有效的解决。自然语言处理目前存在很多歧义,要消除这些歧义要依靠词与词之间的语义关系,捕获更多词与词之间的关系,以此来辅助解决歧义问题。
1 研究现状
在国内,很早就研究了汉文、英文的词向量,其也在处理自然语言词向量方面取得了不错的成果,本文将近几年的研究成果做了综述。在2014年的时候,著名学者杨阳等在研究的过程中创新型的借助统计方法来对新词进行辨别,随后也借助了词向量来对所有词之间的关联性进行挖掘。最后将以词向量为基础的情感词发现方法提出[2]。2016年冯艳红等人[3]在借鉴他人形成的特征的基础上,加入词向量与领域术语之间的相似度特征,利用词向量技术得到文本特征向量。2018年王乔乐等人将神经网络语言模型 NNLM引入到中文分词和词向量训练中,提出了一种基于神经网络的词向量训练模型[1]。在2018年的时候,学者苟瀚文等人在研究的过程中借助词向量对句子完成了相关相似度分析工作。这对之后的工作起到了借鉴作用[4]。他们将单词向量和WCos公式联系了传统词语与词之间语义优点。在2019年的时候,学者阴爱英等人将以fast test模型为基础的词向量表示算法进行改良,这样一来不但能够对具有相似语义词进行预测,同时还能够将相似词所出现的预测问题很好的解决。如此使得精准率得以提升[5]。2019年马力等人研究了基于单词向量的文本分类[6]。文章利用深度学习工具Word2vec训练的单词之间的语义关系,将其应用于传统的特征选择过程,利用大规模语料库来训练高质量的单词向量,并提出了一种基于单词向量的改进的特征选择算法。在2019年的时候,学者王恒升[7]基于大量分析和研究的基础上将skip-gram模型进行改进。
藏文词向量表示方法的研究比起汉文、英文,还处于起步阶段。早在2004年,我国就开始涉足藏语词向量的研究工作。在2017年的时候,学者珠杰等人[8]借助深度学习方法来对藏文进行细致的研究。同年学者郑亚楠等人[9]借助词向量将词性标注问题进行了处理,最终获得了很好的效果。词向量模型可以用于情感分类任务当中,2017年巴桑卓玛等人以词向量法为基础,对藏语情感词典的构建进行了研究[10]。2018年才智杰从藏文字构建分解、藏文文本分词、藏文词向量评测和藏文词向量表示等四个方面研究了藏文词向量表示的关键技术,该文章基于英汉词向量评估集的构建方法,建立了藏语词向量评估集的构建方法,选择使用现在最佳效果的词向量表示模型Glove、CBOW和Skip-gram模型,对于藏文词的向量进行了创建,同时对于并词向量表示方面所取得的成绩还是非常不错的[11]。根据藏文字构建为理论依据,以构件为单位用向量表示藏文音节向量,这个方法避免了分词操作的错误,同时把组成词的每个藏文字的一维向量作为列可以直接得到藏文词的向量模型[12]。2019年龙从军本文研究了基于词向量的藏语语义相似词知识库的构建[13]。他们基于藏语音节和单词计算了词向量,构建了藏语语义相似词知识库,取得了良好的效果。2019年李琳[14]等人研究了基于词向量特征的藏语谓语动词短语识别模型,对于此文的训练词向量一共用了两个模型,一个是用了CBOW模型,还有一个是Skip-gram模型,最终的结果证明,词向量特征基于CBOW模型训练的,再识别模型想过方面提升的非常明显。
2 藏文字(词)构件研究
对于藏语来说其就是拼音型的字符,是30个辅音、4个元音还有标点符号等所直接组成。
在藏文中有18785个藏文字,藏文的30个基字可以单独成字,也可以通过前后添加其他成分构成藏文字,因此这30个辅音字母的生成极为重要。另外三个上加字(?、?、?)添加在基字上符合藏文文法书写的一共有33个,四个下加字(?、?、?、?)中除去(?)加在基字下面的一共有24个,在藏文中三重叠加的字符有14个,五个前加字(?、?、?、?、?)只能加在受限制的基字前面,藏字由前加字加基字所直接生成的有48个,前加字+基字+下加字以及前加字+上加字+基字的藏字有57个,再添加下加字中除去的?的组合字14个,以上221个字符作为藏文的基础字且受到严格的文法限制,藏文中的四个元音可以加在任何的藏文基础字上面,生成了884个藏字,基础字添加后加字时,添加的除?以外的9个后进行了加字,如此基础字+元音+后加字的字有9945个字,根据以上的数据总共生成11050个字。藏文中还有两个是需要进行的再后加字(?、?),其中的?只能放在后加字?、?、?的后面,再后加字?只能加在后加字?、?、?、?的后面,这样就产生了18785个所有藏文字符。
对于每一个藏字来说,其构成主要如下:基字和前加字,还有上下加字以及后和再后加字,最后还有元音搭配,并且藏字搭配遵循嚴格的文法规则,这就使得藏字的组成具有一定的限制条件,通过这些限制条件,可以将每个藏字进行拆解并识别构件。藏文字符最多由7个组成部分,例如:???????? = ? + ? + ? +? +?+ ?+ ? + ?。它是根据相应的代码存储在计算机中的,而?????在藏文中可以单独成字也有严格的语法限制,后面的???没有受语法限制,因此符合藏文文法书写的数量是一定的。受限制的221个藏文基础字,然后符合藏文字符结构的基础上生成了全藏字,对于受限制藏文字符最为关键的后面,直接加上元音,然后再后加字,接着再后加字,最终生成18785个藏字。对于藏字构件的长度来说,是不等长的,1-7个构件可以组成一个藏字,除了两个特殊字(????和????)以外,这两个特殊字含有再下加字的构件,它可以横向拼写,也可以纵向拼写,其中基字(30个辅音)是每个藏字的必不可少的构件,同样30个辅音单独构成藏字,其中有4个是无法构成藏字的。按照不一样长度构件的藏字,其中有一个字符可以直接构成的辅音字母达到30个;两个字符的有4种不同的结构;三个字符的有12种结构;四个字符的14种结构;五个字符的有11种结构;1六个字符的有5个结构;七个字符的有一种结构,一共有这么多种藏字结构。藏文词是由字组成,具有语义信息的词才是一个正确的藏文词。
藏文词向量表示可以将组成藏文词的每个藏文字的向量作为列,得到藏文词向量,所有藏字用7行18785列的矩阵表示,词与向量是一种映射关系,例如:?????????????????。
?????????????????用7行4列的矩阵[30300000127112620000133010010002]表示:
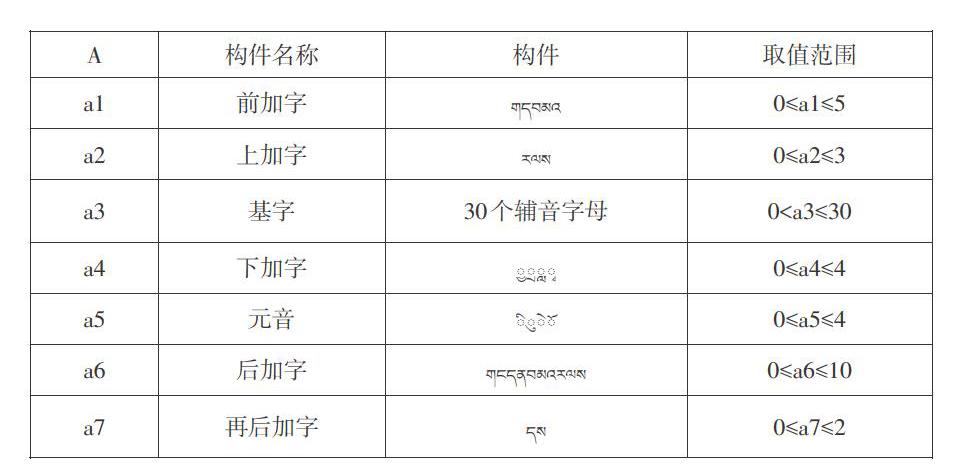
藏文字是有最多7个构件构成的,比如:???????? = ? + ? + ? +? +?+ ?+ ? + ?除去特殊藏字外,7个构件用一维向量表示{a1,a2,a3,a4,a5,a6,a7},以构件形式映射到向量集A中,具体每个构件映射的向量以及向量的取值范围如下表:
在构件藏文字向量的基础上表示需要研究藏文字(词)构件。
3 藏文词向量技术研究
藏文词向量技术的研究相对于其他技术还处于起步阶段,要想研究藏文词向量,首先,要了解藏文字(词)的构建;第二,需要分词处理藏文的文本,毕竟对于藏文词向量来说,其处理是以词作为单位的,不论是语法的分析还是及其的翻译等等都被会分词的准确率所直接影响。最后,分词完了之后,可以通过向量来表示词语。
基于自然语言方面的处理领域,词向量方法用于文本分类、情感分析和句子(文本)相似度计算。到现在为止,所谓的词向量方法分布表示技术就是对于一个词就采取一个向量来进行表示,进而将语义距离基于词和词之间的就可以核算出来,进而将一些稀疏和高维以及离散等相关问题就可以进行解决,然而在速度上分布式表示训练词向量还是比较慢的,增加新的语料库存在困难,不容易扩展短语、句子的表示,因此,很多研究者采用神经网络方法进行词向量技术的研究,且已经取得了一定成效。2013年Google公司推出一款对词向量进行训练的工具开源式的并且是面向大众的,其名字叫作Word2vec,其核心特征就是全部词语均已经采用的是向量化,如此词和词二者的语义关系就可以理解,同时对于词语上下文的相关信息还可以进行捕捉。那么其所涵盖的训练模式有两种[14],分别是CBOW和Skip-gram模型,CBOW模型是将周边的词向量进行相加,进而会得到中心词的向量,直接去掉了隐藏层,加速了训练速度且用低维的实数向量来藏文词语。然而,Skip-Gram模型与CBOW模型正好是反着来的,这个是要求预测中间词,如此就可以将量变的向量进行获取。而CBOW和Skip-gram模型对于全文的信息以及词的顺序进行考虑,因而就将新的词向量的表示方法进行了提出即Glove,在此不做具体的描述。
但是对于藏文词的向量研究成果方面目前还是比较欠缺的,2018年的时候,才智杰作为一名知名的教授,将藏文词向量表示是在藏文构件的字信息以及藏文字向量进行融合的基础上进行了提出,每个藏文字对应7个分量的一维向量,同时将已经组成词的每个藏文字的一维向量作为列可以得到藏文词的向量模型。在本文中已经把这个模型和Skip-gram、CBOW和Glove开始了对比,同时还和字符信息以及藏文字符向量都进行了结合,模型由藏文词向量进行表示的可能性进行了改进。还利用藏文拼写原则,基于规则约束得到藏文字符的向量,是一种很好的藏文拼写纠错方法。研究者们对于藏文词向量进行研究的时候主要就是对藏文自身的特征进行了结合,而藏文最基本的组成单元是构件,对于藏文词向量进行表示的方法目前已经提出,其中的一个叫做多基元的联合训练模型,多基元是指藏文的构件、字以及词的联合。在汉文、英文方面有很多词向量评测集,而藏文也是才智杰教授首次建立了词向量评测集,且效果良好。相对于汉文、英文的词向量研究,我们认为藏文词向量方面下一步可以开展以下文体的研究:1)可以把语言学方面的知识,如藏文句法的语法规则以及动词、名词等的信息融入到词向量的学习过程中,提高藏文词向量的研究成果;2)神经网络的表示研究仅限于词向量方面,还需要结合藏文自身特点用已经有的藏文词向量表示技术运用到藏文句子或段落的向量表示,采取递归神经网络,深入递归组合了词向量,进而就获取到了句子的向量表示;3)对于句子向量来说,其就是一个最核心的技术在对于一义多词以及一词多义问题的解决方面,如果一个唯一的词向量代表了一个词,那么针对一词多义的问题就是无法解决的,因此,继续研究解决一词多义的问题是非常必要的;4)存在新出现的词没有向量表示。
4 结语
本文较详细地阐述了藏文字(词)的构建和藏文词向量技术。针对目前藏文词向量研究技术现状及词向量技术的发展,我们给出了四點可做研究的问题,并将在今后的研究工作中结合藏文本身的特点,采用神经网络方法进行改进和扩充藏文词向量工作。
参考文献:
[1] 王乔乐.中文分词和词向量[J].中国新通信,2018,20(23):192-193.
[2]杨阳,刘龙飞,魏现辉,等.基于词向量的情感新词发现方法[J].山东大学学报(理学版),2014,49(11):51-58.
[3] 冯艳红,于红,孙庚,等.基于词向量和条件随机场的领域术语识别方法[J].计算机应用,2016,36(11):3146-3151.
[4] 苟瀚文,苟先太.基于词向量的词语间离和句子相似度分析[J].科学技术创新,2018(33):55-56.
[5] 阴爱英,吴运兵,郑一江,等.基于fastText模型的词向量表示改进算法[J].福州大学学报(自然科学版),2019,47(3):314-319.
[6] 马力,李沙沙.基于词向量的文本分类研究[J].计算机与数字工程,2019,47(2):281-284,303.
[7] 王恒升,刘通,任晋.基于领域知识的增强约束词向量[J].中文信息学报,2019,33(4):37-47.
[8] 珠杰,李天瑞.深度学习模型的藏文人名识别方法[J].高原科学研究,2017,1(1):112-124.
[9] 郑亚楠,珠杰.基于词向量的藏文词性标注方法研究[J].中文信息学报,2017,31(1):112-117.
[10] 巴桑卓玛,李苗苗,高定国.基于词向量的藏文情感词典的构建方法研究[J].电子技术与软件工程,2017(20):132-134.
[11] 才智杰.藏文词向量表示关键技术研究[D].西宁:青海师范大学,2018.
[12] 才智杰,孙茂松,才让卓玛.藏文词向量相似度和相关性评测集构建[J].中文信息学报,2019,33(7):81-87,100.
[13] 龙从军,周毛克,刘汇丹.基于词向量的藏文语义相似词知识库构建[J].中文信息学报,2020,34(10):33-38,50.
[14] 李琳,赵维纳,泽旺宽卓.基于词向量特征的藏语谓语动词短语识别模型[J].电子技术与软件工程,2019(4):242-243.
【通联编辑:唐一东】
猜你喜欢
西藏研究(2021年1期)2021-06-09
布达拉(2020年3期)2020-04-13
中央民族大学学报(自然科学版)(2018年1期)2018-06-27
西藏艺术研究(2017年2期)2018-01-22
计算机应用(2016年12期)2017-01-13
西藏大学学报(自然科学版)(2016年1期)2016-11-15
新闻传播(2016年17期)2016-07-19
求知导刊(2016年10期)2016-05-01
