
用于表格事实检测的图神经网络模型∗
2021-05-23 13:17邓哲也
软件学报 2021年3期
邓哲也,张 铭
(北京大学 信息科学技术学院 计算机科学技术系,北京 100871)
随着如今文本数据越来越多,并且可以轻松地通过互联网传播,当人们面对错综复杂的信息时,为了辨别信息的真假,需要对这些信息进行验证,这就体现出了事实检测任务的重要性.
在自然语言理解和语义表征的研究中,验证一句文本陈述是否基于给定的事实证据非常重要,这是自然语言理解中的一个基础任务.现有的研究主要局限于处理非结构化证据的事实验证,如自然语言的句子、文档、新闻等,在这一类研究中,细分下来有很多不同的任务,如检查文本关联性[1]、自然语言推理[2]、基于维基百科的事实验证[3].它们用到的证据都是纯文本信息.而结构化证据下的验证还有待探索,比如基于表格、图表、数据库等形式的事实验证.在这一类研究中,有基于图片证据的数据集NLVR[4]/NLVR2[5],还有基于表格证据的数据集TabFact[6].
TabFact 数据集是一个包含1.6 万个维基百科中的表格作为事实证据和11.8 万条人工标注的自然语言陈述的事实验证数据集.不仅形式上与纯文本数据不同,采用的是表格形式的数据,而且它与一般的事实验证数据集不同的点在于,它要求模型同时具有语义推理和符号推理的能力.图1 就是该数据集的一个实例.

Fig.1 An instance of the TabFact dataset图1 TabFact 数据集的一个实例
TabFact[6]中提出了两个基线模型,分别是基于自然语言推理的Table-BERT 和基于搜索和数据库查询的LatentProgram 算法.这两个做法都没有取得非常好的效果,因为Table-BERT 简单地把表格中的内容拼接在一起组成了文本,转化为了基于文本的事实验证问题,忽略了表格中行与行、列与列之间的关系;而LatentProgram 算法是基于人工规则的搜索,泛化效果并不好.
本文将围绕TabFact 数据集,针对表格数据的特殊的结构特征,设计基于表格数据的事实验证模型和算法,完成代码实现,并在基于表格的事实检测数据集上验证了效果.
本文的贡献可以概括为以下两点:
(1)提出了以表格的行为单位的Row-GVM 模型,利用表格的行特征和图注意力网络对该任务建模,准确率相比基线模型提升了2.62%;
(2)提出了以表格的单元格为单位的Cell-GVM 模型,利用表格的单元格特征和图卷积网络对该任务建模,准确率相比基线模型提升了2.77%.
1 相关工作
1.1 事实检测任务数据集
FEVER(fact extraction and verification,事实抽取和检测)[3]数据集是一个公开的事实检测数据集,它包含185 445 条陈述,陈述是通过改编维基百科中的句子生成的.FEVER 数据集关注的是验证文本陈述的真伪,依据是维基百科中词条里出现的文本信息.这与本文关注的基于表格的事实验证任务非常相似.在本文的任务中,陈述也是文本的形式,但是依据的形式是维基百科中词条里出现的表格.
TabFact[6]数据集是一种全新的基于表格的事实验证数据集,难点在于需要模型能够完成语义推理和符号推理.还有一些其他的基于表格的数据集,如基于表格的问答数据集WikiTableQuestion[7],但本质上和TabFact数据集有很大的区别,因为WikiTableQuestion 数据集中的问题对答案的类型有强烈的指向性,对于模型的推理能力要求不高,因此,在这个数据集上的做法很难迁移到TabFact 数据集上.
1.2 图神经网络
图神经网络[8]可以比一般的神经网络更好地挖掘出用图表示的数据.在图神经网络中,节点可以通过与它相连的边共享邻居节点的信息,学到更好的表示.最近的一些研究在利用不同的神经网络结构来优化整张图中节点信息的交互.
图神经网络在基于文本的事实检测任务数据集FEVER 上有不错的表现.GEAR[9]使用了图注意力网络(GAT)[10]来对陈述-依据对进行推理和整合,它把陈述和依据的文本拼在一起当作节点,构建了一张完全图,利用GAT 在图上传递节点信息.KGAT[11]也采用了GAT,它把依据的文本当作节点,引入了称为边核和点核的高斯核池化层,其中,边核用来在依据图上传递信息,点核用来把所有节点的信息进行合并得到整个图的表示.这种方法得到的依据和陈述的注意力相对而言更为集中,使得在FEVER 数据集上的表现要好过GEAR.不同于直接把依据文本传进预训练语言模型的其他模型,DREAM[12]关注到了文本中的语义层面的信息,比如人物、地点、时间等不同实体之间的关系,认为这类语义信息对理解依据中的结构关系非常重要,于是对陈述和依据建出了语义图,在语义图上,利用图卷积网络(GCN)[13]进行推理,在FEVER 数据集上取得了目前最好的结果.
图神经网络在阅读理解任务上也有很好的表现,比如,Entity-GCN[14]在建图过程中,把文本中出现的所有实体都当作了图中的节点.根据节点之间的关系连接了不同种类的边,如:不同文档中描述的同一实体之间连边,同一文档中的所有点互相连边等.之后,运用GCN 对文本内容进行多轮推理,取得了目前最好的效果.
1.3 自然语言推理
对语言的推理建模,是自然语言理解的重要的第1 步.自然语言推理的目标是,判断一个自然语言假设可否由一个自然语言前提推理得到.具体地说,是判断假设和前提的关系,可以是支持、反驳或中立中的任何一种.
随着深度学习的兴起,涌现出了很多解决这类问题的模型,如 SNLI[2],Decomposed Model[15],Enhanced-LSTM[16],Multi-NLI[17],BERT[18].本文的任务虽然也是自然语言推理,但是本文的前提不是完全以文本形式呈现的,而是由文本组成的半结构化的表格形式呈现的,所以该任务可以看作是半结构化领域的自然语言推理问题.
1.4 预训练语言模型
如今在很多自然语言处理的任务上,预训练的语言表示模型,如ELMo[19],OpenAI GPT[20],都被证明是非常高效的.BERT[18]是一种预训练语言表示的新方法,通过联合调节所有层中的双向Transformer 来预训练深度双向表示.在本文的工作中,使用BERT 来对文本信息进行编码.
2 方 法
2.1 任务定义
在介绍本文的方法之前,首先给这个基于表格的事实检测任务进行一个正式的定义.
本文把数据集中的每个实例表示成(T,C,L),其中:表格T={Ti,j|0≤i≤RT,1≤j≤CT},RT和CT分别为表格的行列数,Ti,j表示第i行第j列的单元格的内容;陈述C={c1,c2,…,cn}是一个n个单词组成的基于表格内容的陈述;标签L∈{0,1},L=1 表示陈述C被表格T支持,L=0 表示陈述C被表格T反驳.本文的目标是给定(T,C),预测正确的标签L.
2.2 方 法
本文结合表格的结构特征,提出了两种用来对基于表格信息的陈述进行事实检测的模型,分别是:
(1)Row-GVM:以表格中的每一行为单位的(Row-level)基于图神经网络的事实检测模型(GNN-based verification model);
(2)Cell-GVM:以表格中的每一个单元格为单位的(Cell-level)基于图神经网络的事实检测模型.
2.2.1 Row-GVM
如图2 所示,Row-GVM 模型分为3 个部分.
(1)信息编码:对行信息进行编码,把每一行当作图中的一个节点;
(2)信息传递:建立一个全连接图,在图上利用GAT 的原理进行信息传递;
(3)整合预测:整合每个节点的表示得到一个最终表示,进行二分类预测.

Fig.2 A flowchart of Row-GVM图2 Row-GVM 的流程图
(1)编码
为了得到第i行的表示,本文把第i行的信息拼接起来,得到Ti,*.为了在后续的信息传递中更好地捕捉和陈述相关的信息,本文将第i行的信息Ti,*和陈述C拼接在一起后,通过BERT 获得第i个节点的表示Ni=BERT(Ti,*,C).Ni∈ℝF,其中,F是每个节点的特征维数.
(2)信息传递
在信息传递模块,本文引入了GAT,它是由若干个图注意力层堆叠而成的.
在第t层图注意力层中,输入是ht−1,输出是ht.为了更好地捕捉节点之间的信息,本文先用一个矩阵Wt∈ℝF′×ℝF把ht−1映射到高维空间,再对每个节点计算自注意力,用映射β∈ℝF′×ℝF′→ℝ来计算注意力系数这表示第j个点对第i个点的重要程度.本文希望每个节点的信息都可以传达到图中其他的每一个点,所以对每一对节点都要计算注意力系数.对于点i,本文要把其他点对它的重要程度做一个正则化,这里使用softmax函数:

在本文的实验中,自注意力模块β中,和第i个节点有关的重要程度是用一个权值向量βi∈ℝ2×F′来实现的,并且引入了LeakyReLU(负数输入的斜率为0.1)[21],αij可以重写为

其中,⋅T表示转置,||表示向量的连接操作.
最后,根据计算出的注意力系数把其他点的表示整合起来,得到每个节点的新的表示,作为第t层的输出:

(3)预测
为了进行最后的预测,本文需要得到一个整张图的表示.这里,本文采用求每一维特征的平均值的方法得到最终表示hG,hG∈ℝF.得到了图的表示hG后,用一个一层的全连接网络来获得最终的预测结果:
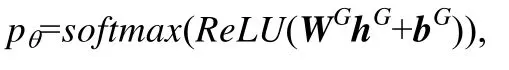
其中,WG∈ℝ2×F,bG∈ℝ2×1.本文通过优化参数θ来最小化交叉熵损失L(pθ,L),其中,L是真实的标签.
2.2.2 Cell-GVM
如图3 所示,Cell-GVM 模型分为3 个部分.
(1)信息编码:对单元格的信息进行编码,把每个单元格当作图中的一个节点;
(2)信息传递:同一行之间的点两两之间互相连边(图3 中的实线边),记作ROW 边;同一列之间的点两两之间互相连边(图3 中的点线边),记作COL 边.在图上利用GCN 的原理进行信息传递;
(3)整合预测:整合每个节点的表示得到一个最终表示,进行二分类预测.

Fig.3 A flowchart of Cell-GVM图3 Cell-GVM 的流程图
(1)编码
为了在后续的信息传递中更好地捕捉和陈述相关的信息,将第i行第j列的单元格的信息Ti,j和陈述C拼接在一起后,通过BERT 获得第i行第j列的节点的表示Ni,j=BERT(Ti,j,C).这里把陈述C也通过BERT,得到它的表示NC=BERT(C).Ni,j,NC∈ℝF,其中,F是每个节点的特征维数.
(2)信息传递
在信息传递模块,与Row-GVM 不同的是,本文引入了GCN.
本文把RC个节点和RC(C−1)/2 条ROW 边组成的子图记作GCOW,RC个节点和RC(R−1)/2 条COL 边组成的子图记作GCOL.
记图Gr(r∈{ROW,COL})给每个点加上自环后的邻接矩阵为Ar,度数矩阵为,归一化后
第t层图卷积层会通过两类边整合每个点的邻居的信息,得到第t层的输出:的对称邻接矩阵为

其中,r表示的是边的种类,是权值矩阵,σ是激活函数.
(3)预测
为了得到图的表示,先用矩阵WH和WC分别把ht−1和NC映射到高维空间,WH,WC∈ℝF′×F,然后用映射γ:ℝF′×ℝF′→ℝ来计算节点和陈述之间的注意力,然后进行归一化,得到:

在本文的实验中,映射γ采用的是点积运算,所以βi,j可以重写为

得到了图的表示hG后,把它和陈述的表示NC拼接在一起,通过一个一层的全连接网络来获得最终的预测结果:

其中,WG∈ℝ2×F,bG∈ℝ2×1,||表示向量的连接操作.
本文通过优化参数θ来最小化交叉熵损失L(pθ,L),其中,L是真实的标签.
3 实 验
3.1 实验设置
3.1.1 数据集
本文的实验全部在TabFact 数据集[6]的子集TabFact-small 上进行,其中每一条陈述都是针对某一个表格的,并且被人工打上了“支持”或者“反驳”的标签.
由于计算资源的限制,本文从原数据集中移除了最大的一些表格,这部分表格占到原数据集的8.12%左右.本文对所有模型做的实验都是在TabFact-small 数据集上进行.TabFact-small 数据集的信息见表1.
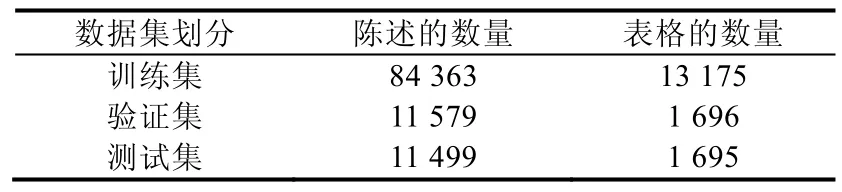
Table 1 Statistics for the TabFact-small dataset表1 TabFact-small 数据集的统计数据
3.1.2 基线模型
本次实验中的基线模型一共有3 个.其中,第1 个模型Bert-Concat 是TabFact 数据集[6]中提出的表现最好的模型;后面两个模型Row-Mean 和Cell-Atten 是受第1 个模型的启发,并结合本文提出的模型,实现的两个基线模型.
• Bert-Concat[6]
如图4 右上角图所示,把每一个单元格的信息拼起来,然后和陈述C拼接在一起,通过Bert 和一个多层感知器fMLP对结果进行分类,得到一个预测pθ(T,C)=σ(fMLP(BERT(T,C))),其中,σ是sigmoid函数.

Fig.4 Flowcharts of baseline models图4 基线模型的流程图
• Row-Mean
如图4 左下角图所示,把每行的所有单元格的信息拼起来,一共得到R个句子.每一行的句子都和陈述C拼接在一起,通过Bert 后先对所有表示取平均值,然后用一个多层感知器fMLP对结果进行分类,得到一个预测:

其中,σ是sigmoid函数.
• Cell-Atten
如图4 右下角图所示,对每一个单元格都得到一个句子,一共有RC个句子.每一个单元格的句子都和陈述C拼接在一起,通过Bert 后对所有表示计算和它和陈述C之间的注意力,然后用一个多层感知器fMLP对结果进行分类,得到一个预测:

其中,σ是sigmoid函数.
3.1.3 评价标准本文通过比较模型的预测输出和数据集中人工标注的真实标签计算准确率来评价模型,即:
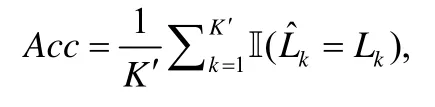
其中,K′是测试集的大小,是模型预测的标签,Lk是真实的标签.
3.2 实现细节
在所有的模型中,本文使用的都是用104 种语言预训练的12 层、隐藏层维数768、12 头的BERT 模型[18].所有的参数都是默认参数.优化器是BERTAdam[18],学习率是1e−5.对于Row-GVM,最大序列长度设为128,批大小设为8;对于Cell-GVM,最大序列长度设为64,批大小设为2.热身比例是0.4.
4 结果与分析
4.1 实验结果
在表2 中列出了每个模型在TabFact-small 数据集的验证集和测试集上的表现.在这个表中有如下发现.
(1)Row-Mean 的表现比Bert-Concat 稍好,但是Cell-Atten 的表现没有超过Bert-Concat.这可能是因为独立地检查单个单元格很难得出正确的判断,需要一行或所有单元格联合起来才能提供更有效的信息;
(2)Row-GVM 和Cell-GVM 都显著地超过了原文献的基线模型Bert-Concat,它们在验证集上的提升分别是2.47%和3.08%,在测试集上的提升分别是2.62%和2.77%.这说明利用表格的行与列的相关性特征可以显著提高模型的表现;
(3)Cell-GVM 在该数据集上取得了最好的效果.
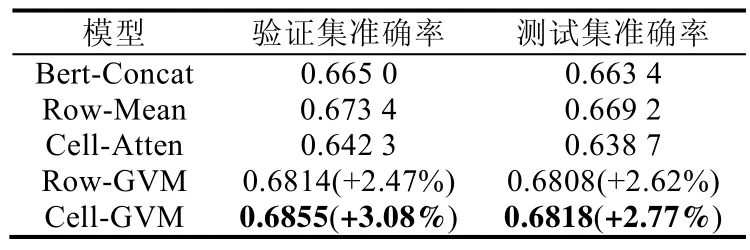
Table 2 Main results表2 主要实验结果
4.2 消融实验与分析
4.2.1 Row-GVM 中GAT 模块的有效性
为了验证Row-GVM 中GAT 的有效性,本文调整了GAT 的层数,分别设置成了0 层~3 层,每种情况的实验结果都列在表3 中.其中,0 层的GAT 等价于从Row-GVM 中删除了GAT 模块,退化为Row-Mean 模型.

Table 3 Comparison of different layers of GAT with respect to their effectiveness表3 不同的GAT 层数对模型效果的影响
本文发现:有GAT 模块的Row-GVM 的表现始终比删去GAT 模块的Row-Mean 要好,表现最好的由3 层GAT 组成的Row-GVM 在结果上提升了0.80%,证实了GAT 模块的有效性,同时也说明了Row-GVM 有能力处理需要多轮推理的事实检测问题.
4.2.2 Cell-GVM 中GCN 模块的有效性
为了验证Cell-GVM 中的有效性,本文调整了GCN 的层数,分别设置成了0 层~3 层,每种情况的实验结果都列在表4 中.其中,0 层的GCN 等价于从Cell-GCN 中删除了GCN 模块,退化为Cell-Atten 模型.

Table 4 Comparison of different layers of GCN with respect to their effectiveness表4 不同的GCN 层数对模型效果的影响
值得注意的是,Cell-Atten 的表现要低于基线模型Bert-Concat.本文分析:这是因为本文对所有单元格的内容都求出了经过Bert 的向量表示,然后直接对所有表示进行了简单融合,因此不能捕捉单元格与单元格之间的联系.相比之下,把所有单元格拼成一起经过Bert 得到的表示还是可以捕捉到一部分单元格之间的联系,所以Cell-Atten 的表现会低于Bert-Concat.
本文发现:有GCN 模块的Cell-GVM 的表现始终比删去GCN 模块的Cell-Atten 要好,表现最好的由3 层GCN 组成的Cell-GVM 在结果上提升了4.32%,证实了GCN 模块的有效性,同时也说明了Cell-GVM 有能力处理需要多轮推理的事实检测问题.
4.2.3 Cell-GVM 中区分边的种类的有效性
为了验证Cell-GVM 中区分ROW 边和COL 边的有效性,本文设置了一组对比实验.在这组实验中,不区分ROW 边和COL 边,建图时把这两类边标记为同一种边,信息传递时,节点的信息不再通过两种边传递,而是只通过这一种边传递.在该模型的GCN 的第t层中,直接整合第i行第j列的单元格节点的邻居的信息:
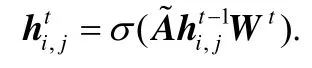
记该模型为Cell-GVM-SameEdge.
Cell-GVM-SameEdge 和Cell-GVM 的实验结果列在表5 中.可以看到:在不区分边的情况下,Cell-GVM 的表现下降了0.42%,证实了区分边的种类对提升实验效果是有效的.

Table 5 Comparison of different types of edges with respect to their effectiveness表5 边的种类对模型效果的影响
本文分析认为:3 层GCN 是最有效的,因为3 层的GCN 可以把一个单元格(如hi,j)的信息通过ROW 边传到同一行的另一个单元格(hi,k),再通过COL 边传到同一列的另一个单元格(hl,k),最后通过ROW 边传到同一行,且和起点单元格的列数一样的单元格(hi,j).这样就可以在3 步之内整合另一列的信息传递到这一列中其他的节点上.
5 结 论
本文针对基于表格的事实验证数据集TabFact,利用了表格的结构特征,结合图注意力网络和图卷积神经网络,分别设计了以表格的行为单位的Row-GVM 和以表格的单元格为单位的Cell-GVM,并且都在TabFact-small数据集上取得了最好的结果,比基线模型分别提高了2.62%和2.77%.这两个模型通过实验被证明都是高效的,这说明利用表格的行与列的相关性特征确实可以提高模型的表现.
从目前的结果可以看到,预测的准确率还有很大的提升空间.分析了错误的案例后,发现本文的模型在捕捉和陈述相关的行与单元格方面的表现有较好的提升,但是符号推理方面表现稍有不足.在未来的研究中,将设计更加侧重于符号推理的模块,融入到本文的模型中,相信会有更好的表现.
猜你喜欢
考试与评价·七年级版(2021年5期)2021-08-14
电脑爱好者(2021年8期)2021-04-21
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学大王·趣味逻辑(2020年6期)2020-06-22
数学大王·趣味逻辑(2020年5期)2020-06-19
数学物理学报(2019年6期)2020-01-13
唐山师范学院学报(2018年6期)2018-12-25
心声歌刊(2018年4期)2018-09-26
西部皮革(2018年6期)2018-05-07
中华诗词(2017年9期)2017-04-18
