
基于遗传算法优化反向传播神经网络的锅炉NOx 排放研究及应用
2021-05-20 02:22:18唐永基李前宇陈虎亮
山西电力 2021年2期
唐永基,李前宇,陈虎亮
(1.宁夏京能宁东发电有限责任公司,宁夏 银川 750409;2.北京京能电力股份有限公司,北京 100124;3.北京源深节能技术有限责任公司,北京 100036)
0 引言
目前我国火电厂普遍采用高效率选择性催化还原法SCR(selective catalytic reduction) 脱硝装置、低NOx燃烧等技术对锅炉进行改造[1-3],使NOx的排放浓度显著下降[4]。大量试验表明,煤质差异不大时,不同的运行方式会造成锅炉省煤器出口NOx质量浓度差异明显,同时也会影响锅炉热效率。因此,对锅炉进行低氮燃烧优化意义重大。本文以某330 MW 超临界机组为研究对象,利用反向传播BP(back propagation)神经网络对锅炉特性建模,并利用遗传算法实现操作参数的实时寻优[5-7]。结果表明:该模型通过对运行参数进行实时优化控制,有效降低了NOx排放浓度。
1 BP 神经网络建模
BP 神经网络学习规则是使用梯度下降法计算得到预测输出值和样本值进行误差分析,不断反向传播来调整网络中权值和阈值,使网络的输出值接近所期望的输出值,最终误差满足要求[8-9]。
1.1 模型参数选择
本文依据燃烧原理与现场燃烧优化试验,分析影响锅炉效率与NOx质量浓度的可控必要因素,确定采用入炉煤量、入炉总风量来代表锅炉负荷的影响,其中现场投用5 台磨煤机和5 台给煤机,取5台给煤机煤量代表磨煤机的组合方式及入炉总煤量,取入炉一次风量、二次风量各一个值代表入炉总风量;燃烬风共投用5 层,同层联动,采用1 号角5 个燃烬风风门开度值;燃料风共投运5 层,同层开度联动,采用1 号角5 个燃料风风门开度值;二次风共投用6 层,同层开度联动,采用6 个二次风风门开度值表示二次风的配风模式;二次风箱与炉膛之间的差压也影响二次风和燃烬风喷口出口速度,取其中参数值作为1 个输入参数;取省煤器氧量以代表燃烧氧量影响;所有燃烧器均以相同摆角在炉内高度方向摆动以调节再热汽温,取1 个燃烧器摆角值;所有燃烬风摆角同时联动控制燃烬风进入炉膛的角度,取1 个燃烬风摆角值;共28 个输入变量。选取NOx排放值为网络输出参数。
为了确保网络不会因为数据分散且数量级差异悬殊而导致不收敛,且能使网络完全准确地识别学习样本,使模型运行时收敛加快,需要对输入、输出数据进行标准化归一处理,将输入、输出变量均归一化到[-1,1]区间,方法如下。
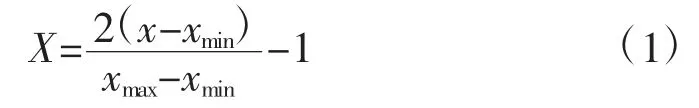
其中,X 为归一化后的数据;x 为原始数据;xmax、xmin分别为变量在所有工况中的最大值和最小值。
1.2 建立模型
基于Python 开发工具创建网络模型,其中BP神经网络采用双隐层网络结构,输入层为28 个节点,第一隐藏层节点数为25 个,第二隐藏层节点数为5 个,输出层为1 个节点(NOx排放浓度),网络激活函数采用sigmoid 函数,利用梯度下降算法,误差反向传播,选用平方差函数更新权重,其中学习速率设为0.000 1,训练均方误差小于0.001,根据训练目标或训练次数作为程序结束运行条件。
2 遗传算法优化
本文利用遗传算法并行的随机启发式搜索优化方法[10-11],将完成训练的BP 神经网络作为求解目标函数值的数学表达式,利用遗传算法通过选择、交叉、变异等操作(其中设定种群规模为50 个,交换概率为0.8,突变概率为0.7),模拟自然界进化过程来找出不同负荷下、不同燃烧状况下的锅炉燃烧最佳参数设定值,指导锅炉燃烧优化调整,降低NOx排放浓度,实现锅炉燃烧系统的经济运行。
利用遗传算法优化锅炉各项参数时,将输入参数分为可调参数及不可调参数,设定不可调参数锅炉实时负荷、磨煤机煤量、一次风量、二次风量、大风箱与炉膛差压、炉膛氧量为定值,在寻优过程中保持数值不变,设定可调参数燃烬风风门开度值、燃料风风门开度值、辅助风风门开度值、燃烧器摆角、燃烬风摆角为寻优参数,同时对每个参数规定了参数的上下变化范围。在寻优过程中还需要输入当前负荷下的理想NOx值,用于染色体适应度的计算,该数值表示当前负荷下NOx能达到的理想最小值,但手动输入值并不是越小越好,要同时考虑函数的适应度值,寻优过程如图1 所示。
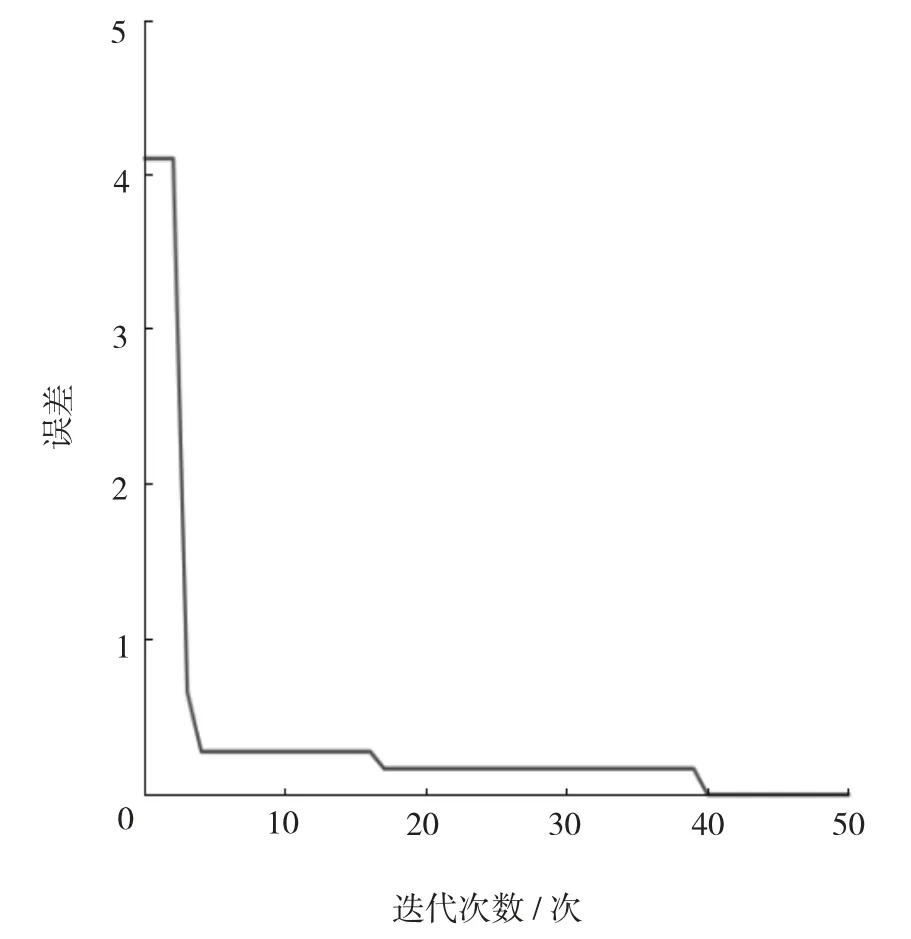
图1 遗传算法寻优过程
3 应用研究
内蒙古某330 MW 四角切圆粉煤燃烧锅炉为超临界参数复合滑压运行螺旋管圈直流煤粉炉,单炉膛、四角切圆、一次中间再热、平衡通风、固态排渣、全钢构架悬吊结构、紧身封闭Π 型燃煤锅炉。锅炉采用摆动式四角切圆燃烧方式,采用低NOx同轴燃烧系统,20 只直流式燃烧器分5 层布置于炉膛下部四角,煤粉和空气从四角送入,在炉膛中呈四角切圆方式燃烧。在额定负荷条件下投用A~D层一次风,E 层一次风备用。配备5 台中速磨煤机和5 台给煤机组成的直吹式制粉系统,每台中速磨供一层一次风,额定负荷下投用5 套制粉系统。
3.1 训练BP 神经网络模型
本文收集了25 000 组运行参数数据,数据采集时间间隔为1 min,对数据进行了初步整理作为训练样本,同时又选取50 组数据进行预测对比;每次采集28 项数据,其中前28 项作为网络的输入层数据,最后1 项作为网络的输出层数据,通过BP 算法训练已采集的各项数据,经过20 000 次训练,耗时18 min,误差趋于稳定,建立锅炉燃烧优化数据模型,运用建立的优化模型进行NOx排放浓度预测,结果如图2 所示。
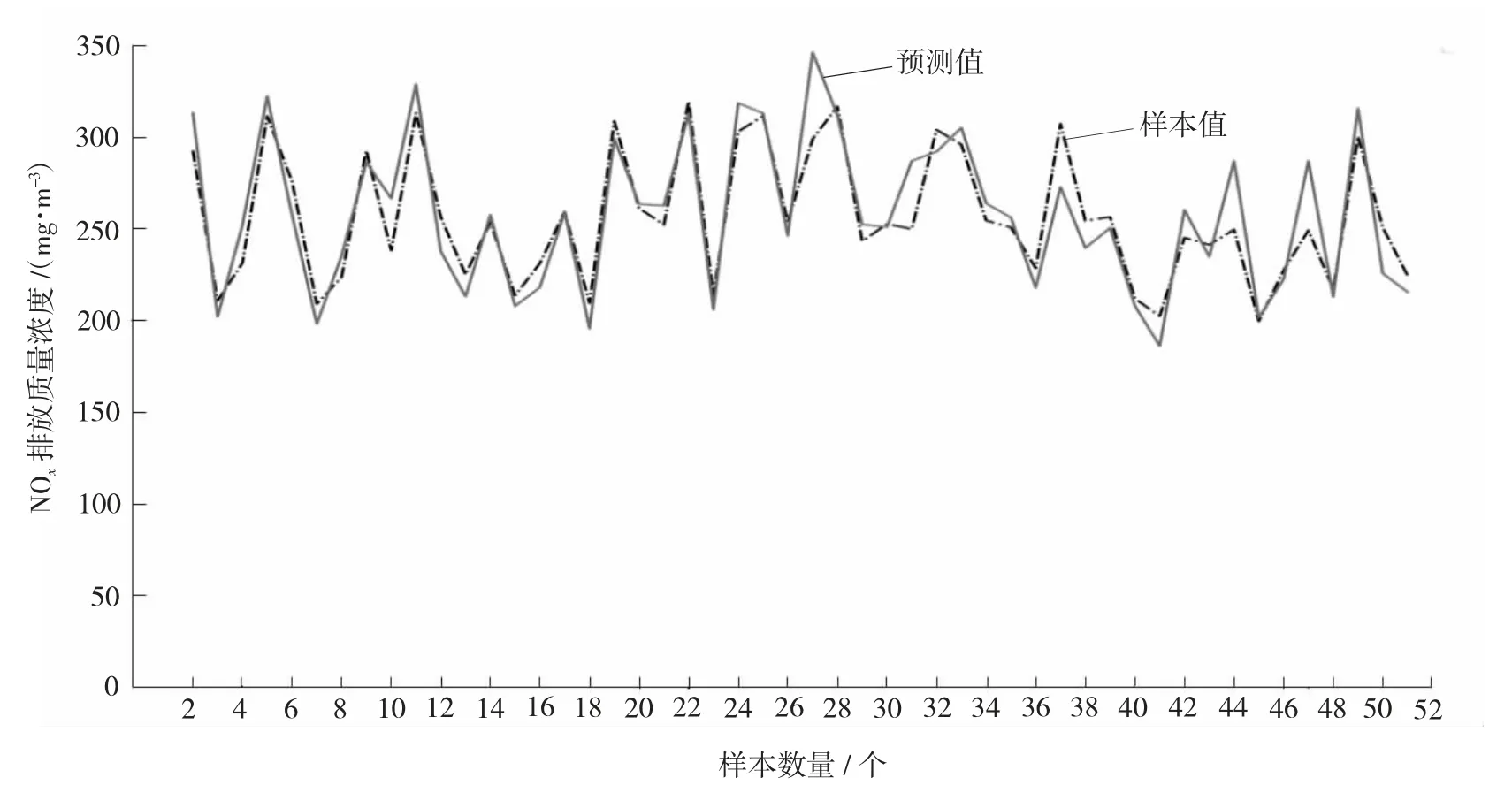
图2 网络模型预测值与样本值对比图
由以上可知,BP 神经网络的泛化能力很强,训练样本预测值与样本值非常接近,NOx排放值预测相对误差最大为6.1%,最小为0.01%,平均相对误差为2.8%,预测精度达97.2%以上,证明网络模型具有很好的拟合性,利用网络模型预测燃烧优化是可行的,能够较为准确地预测锅炉NOx排放值,为后续的锅炉运行参数优化奠定了可信的基础。
3.2 优化调整热态工况
根据机组运行状况,从中选择10 种不同工况,应用遗传算法优化的BP 神经网络模型进行燃烧优化计算,指导现场燃烧调整,具体工况调整参数略。分析具体工况调整参数可知,遗传算法—反向传播GA-BP(genetic algorithm-back propagation)极值寻优模型指导运行调整时,同时减小了上层D 磨、E磨的燃料风和二次风,增加了下层B 磨、A 磨的燃料风和二次风,促使炉膛燃烧区域配风方式趋近于束腰型,使炉内燃烧区形成三级燃烧区,下层区域富燃料,中层区域形成还原性气氛区,上层区域为燃烬区域,这样就减少了NOx生成量。优化前后参数如图3 所示。
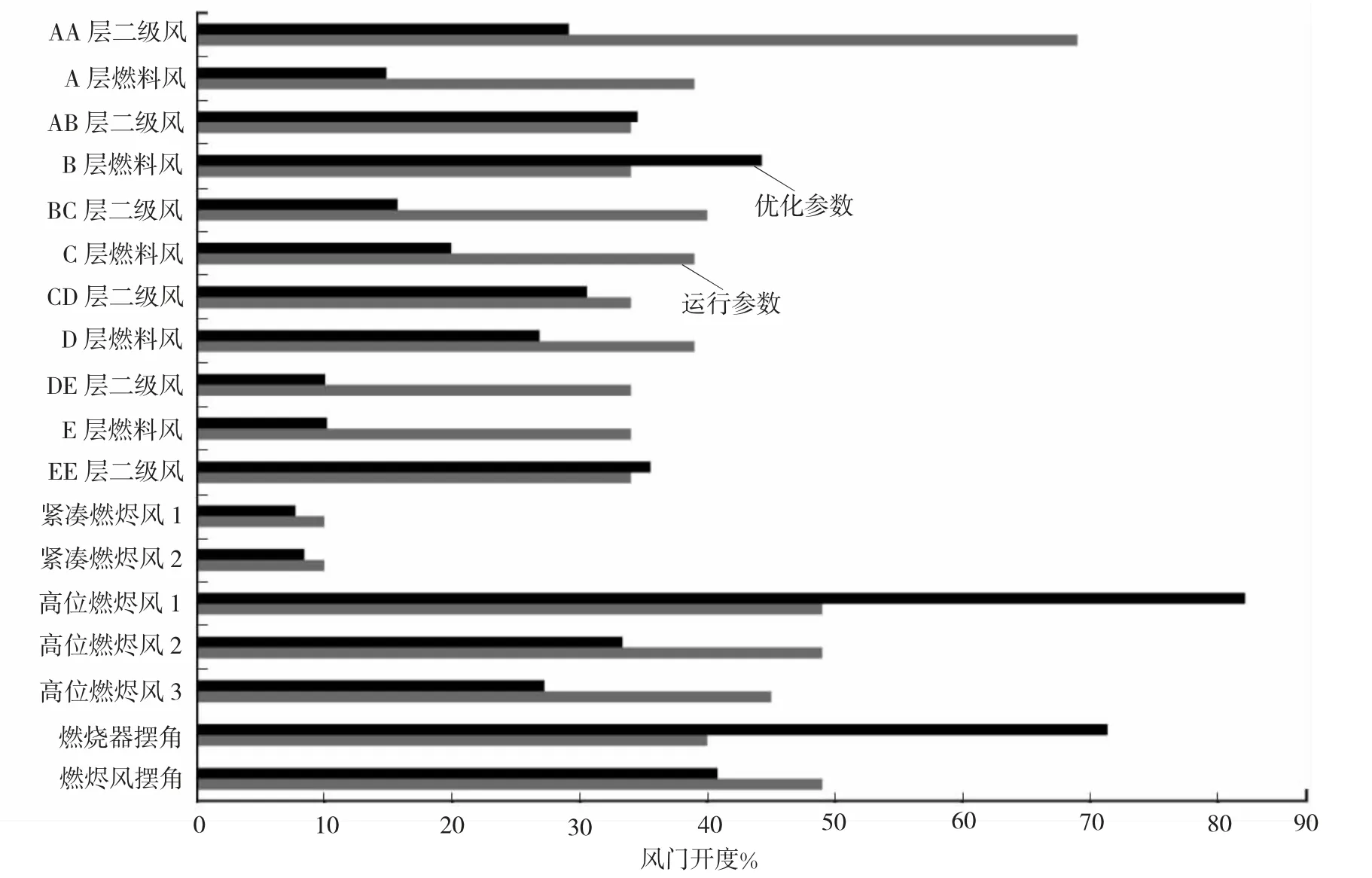
图3 GA-BP 模型寻优参数与运行参数对比图
4 结束语
根据遗传算法优化的BP 神经网络模型,能够很好地吻合330 MW 超临界机组锅炉运行特性。用归一化处理输入输出数据,权值和阈值初始化采用正态分布法,同时给输出样本增加噪声,达到一定的正则效果,提高输出数据的鲁棒性,使神经网络的泛化能力大大增强,训练精度和预测精度也大为提高,在对锅炉运行参数优化的过程中,实现了锅炉运行参数的实时优化指导,有效降低了锅炉NOx的排放,提升了电厂的运行水平。
猜你喜欢
上海理工大学学报(2021年3期)2021-07-20 08:04:04
科学与财富(2021年33期)2021-05-10 16:54:38
北京汽车(2021年2期)2021-05-07 03:56:26
电站辅机(2021年4期)2021-03-29 01:16:52
环境卫生工程(2021年1期)2021-03-19 05:22:30
水上消防(2020年2期)2020-07-24 09:27:06
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
统计与决策(2017年2期)2017-03-20 15:25:24
智能系统学报(2015年4期)2015-12-27 09:38:39
