
一种结合序列和主题信息的无监督方面词提取模型*
2021-05-20 12:07殷润达
通信技术 2021年5期
殷润达
(昆明理工大学,云南 昆明 650500)
0 引言
从评论中提取不同类别的方面词将有助于方面级情感分析(Aspect-Based Sentiment Analysis,ABSA)、意见总结(Opinion Summarization)、热点话题追踪[1-3]等研究。对于来自同一领域的一组数据集,方面词提取的主要目的是发现不同的方面类别,每一个类别由一组方面词表示[4],具体任务为:
(1)挖掘和聚类评论数据集中能代表方面类别的方面词。例如挖掘出Restaurant 数据集中“waitstaff”“busboy”“server”等方面词,并将上述方面词聚为Staff 类别。其中类别的含义通常需要人工推断。
(2)根据数据集中每一条评论的主题分布确定其方面类别。例如,“The waitress,seems to be more concerned of looking good than actually waitressing”一句,在主题分布中,Staff 类别所对应的概率最大,预测其属于Staff 类别。
方面词提取主要分为有监督和无监督两类方法。监督方面词提取方法将该任务视为一个序列标记任务,主要采用基于统计、图以及语义分析的方法:基于统计的方法关注单词在评论中的特征,通过对评论中单词出现的频次进行统计分析和权值计算,将高权值的单词作为方面词[5];基于图的方法将文本中的单词视为图中的节点,以节点的投票排名为依据对方面词进行提取[6];基于语义信息的方法重点关注单词与方面类别之间的关系,并通过此关系获得单词与评论之间的语义信息,实现方面词提取[7]。序列标记通常需要耗费较多的标注成本,并且在标注过程中存在主观性强的问题。无监督方法则可以使模型避免人工标注问题。
Zhu 等人[8]和Li 等人[9]将未标注的评论给予一组能够代表各类别的种子词,通过非种子词与种子词之间的共现模式来提取方面词。Blei 等人[10]提出的潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)是无监督方面词提取中较经典的模型。很多研究者基于LDA 进行改进[11-13]。近年又有学者提出神经主题模型,代表性的有He 等人[4]提出的方面词提取模型和Dieng 等人[14]提出的嵌入主题模型(Embedded Topic Model,ETM)。在评论中含有停用词或低频词的情况下,这两种模型也能较好地提取方面词。但这类模型并没有考虑评论的序列信息。
本文提出一种结合序列和主题信息的无监督方面词提取模型:首先,对评论进行编码,分别获得评论的局部序列信息和全局主题信息;其次,将序列信息与主题信息通过注意力进行结合,生成含有序列信息的主题向量,并通过此主题向量获得相应的主题分布;最后,利用方面词分布矩阵对该主题分布进行重构,用于目标函数的计算,通过反向传播优化整个模型。模型输出方面词分布矩阵及每个评论的主题分布,通过方面词分布矩阵提取方面词,同时,通过主题分布推断评论的方面类别。在来自不同领域的两个数据集(Restaurant 和Laptop)上的实验结果表明,本文模型可以提取一些含有潜在主题信息的方面词,在主题一致性、困惑度等性能上优于其他基线模型。同时,本文还对模型的方面类别分类性能进行了评估,在两个数据集上,F1值平均提升了6.82%。
1 相关研究
早期的方面词提取方法主要集中在人工设计的规则或特征上[15]。Hu 等人[16]通过名词和名词短语的词频来提取不同产品的特征,并通过WordNet 查找有关意见种子词的同义词和反义词来提取有关意见的方面词。在此基础上,Zhuang 等人[17]提出一种基于多知识特征的方面词提取方法,该方法提取电影评论中的方面词并生成一种方面词的特征摘要。早期的方法严重依赖于预定义的规则,这些规则只有在方面词被限制为一组较少名词时才有效。
此外,较多方面词提取方法集中在序列标记任务上。Li 等人[18]将方面词提取任务定义为一个结构标记问题,针对此问题提出一种新模型,该模型在条件随机场的基础上进行改进,经过大量实验,验证此模型的有效性。Toh 等人[19]将语义和句法分析与条件随机场结合对方面词进行提取。Nguyen 等人[20]认为含有潜在信息的特征可以较好地提升模型的整体性能,因此在模型中集成了含有潜在信息的特征,并在主题一致性、方面词聚类和方面类别分类上验证此模型的性能。Poria 等人[21]将方面词提取过程看作一个序列标记问题,提出一种统计神经网络模型,在提取方面词任务上,可达到较理想的效果。Li 等人[22]认为短文本携带有限的信息,在使用传统方面词提取模型时会造成严重的信息稀疏问题,他们利用共现单词对帮助模型提取更有意义的方面词,并能够较好地识别在短文本中很少同时出现的两个单词之间的关联性。
虽然大部分模型可获得较好的性能,但是为了获取标签,首先不能避免昂贵的标注过程,其次很难扩展到新领域的数据集中。因此,出现了很多无监督的方面词提取模型。
Blei 等人[10]提出的LDA 生成模型将得到的概率分布视为主题分布,通过分析此主题分布推断评论所对应的方面类别。Lin 等人[23]基于LDA 模型框架提出一种既可对数据集的情感极性进行分类,又可以从数据集中提取方面词的混合模型,此模型可以提取有用且含有丰富主题信息的方面词。Zhao等人[24]针对LDA 模型进行改进,提出一种方面词和意见词的联合建模方法,使用句法分析来帮助模型提取方面词和意见词。基于LDA 的变体模型并没有考虑单词之间的相关性,使得提取出的方面词与方面类别之间几乎是不相关的;因此Yan 等人[25]提出biterm 模型,在进行方面词提取时用模型生成的共现单词对来增强方面词与方面类别之间的相关性。Wang 等人[26]提出了受限玻尔兹曼机模型,增强方面词与方面类别之间的相关性,使用先验知识帮助模型提取方面词和相关情感极性。Liu 等人[27]构建一组与方面类别相关的数据集,并用于初始训练,而后利用已训练的数据集来建立一个基于最大期望算法的朴素贝叶斯分类器进行方面词提取。Angelidis 等人[28]在传统的方面词提取模型中引入种子词,引导模型能够提取与种子词有关的方面词,并生成相应的摘要。Yin 等人[29]提出一种可自动学习方面词特征的无监督方面词提取模型,此模型将单词以及单词之间的依存关系作为特征,有效地提取了含义相同但句法功能不同的方面词。He 等人[4]提出一种简单有效的无监督提取模型,结合注意力进行方面词提取。由于模型结构简单,易于理解,因此它较好地替代了基于LDA 的变体模型。Dieng 等人[14]将评论转换为含有主题信息并服从高斯分布的低维向量,利用词向量矩阵来获取有关方面词的分布,通过大量实验证明此模型有较好的鲁棒性。
然而,以上无监督方面词提取模型没有考虑评论中的序列信息,不能较好地提取评论中含有潜在主题信息的方面词。因此,本文提出一种新颖的无监督方面词提取模型,充分利用了评论中的序列信息,并通过注意力将其与主题信息结合。
2 本文模型
本文提出的方面词提取模型框架如图1 所示。所提出的模型包含3 个部分,分别是序列和主题信息编码模块、主题和序列信息结合模块、主题解码模块。
2.1 序列和主题信息编码模块
2.1.1 序列信息编码
使用长短期记忆网络(Long Short-Term Memory,LSTM)对输入评论进行序列编码[30]。如图1 所示,将词序列xseq通过嵌入层(Embedding Layer)转换成词嵌入矩阵E作为LSTM 的输入。通过LSTM 获得每一个单词所对应的隐藏状态hn:
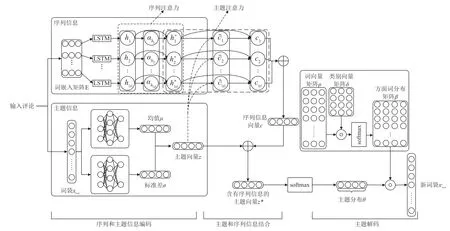
图1 模型整体框架

式中,词序列xseq∈R|x|,|x|表示评论的长度,en∈Rde表示第n个单词对应的词嵌入,de表示单词在嵌入空间中的维度,词嵌入矩阵,fLSTM(·)表示LSTM 神经元,隐藏状态,dh表示隐藏状态的维度。
在进行编码时,本文为了使LSTM 可自动聚焦于整条评论中含有重要序列信息的单词,对隐藏状态hn使用序列注意力[31]。
首先获得每个隐藏状态hn所对应的序列注意力权重分布ahn:

之后使用隐藏状态hn与注意力权重分布来重构新的隐藏状态:

2.1.2 主题信息编码
使用变分对输入评论的词袋表示(Bag-of-Words,BoW)进行编码。以xbow作为输入,其是词表中所有单词的集合,在xbow中每个单词都是相对独立的[32]。此模块进行编码时,首先使用神经网络对xbow进行采样,提取xbow中有用的信息,之后将所提取的信息分别编码成均值和标准差:

式中,词袋xbow∈Rv,v代表词表的大小,fe(·)、fu(·)、fσ(·)分别代表不同的神经网络,均值μ∈Rk,标准差σ∈Rk,k代表方面类别的个数。
通过μ、σ求出主题向量z:

式中,wz∈Rk是模型随机初始化参数向量,主题向量z∈Rk。
2.2 信息结合模块
本文模型结合评论中每个单词的信息来推断评论所表达的潜在主题信息,使用注意力将主题信息与序列信息进行结合。首先通过主题向量z与含有序列信息的隐藏状态hn*来获得主题注意力权重分布∂n:

式中,∂n是衡量评论中含有的序列信息与主题相关程度的权重。通过式(8)计算经过主题注意力更新后的序列信息向量c:

将序列信息向量c与主题向量z进行结合,得到含有序列信息的主题向量z*:

式中,主题向量z*∈Rk。
2.3 主题解码模块
在进行变分解码时,首先将主题向量z*通过softmax 分类器得到主题分布θ:

式中,主题分布θ∈Rk作为本文模型的一个输出,通过每个评论的θ中最大概率来推断评论的方面类别。
然后,参考文献[14]的做法,先对数据集进行Word2Vec 词向量预训练,得到整个数据集的词向量矩阵ρ,模型在整个训练过程,词向量矩阵ρ保持不变。将词向量矩阵ρ与类别向量矩阵δ进行内积并输入到softmax 分类器,得到输入评论的方面词分布矩阵β:

最后,使用输入评论的主题分布θ与方面词分布矩阵β来重构新的词袋表示:

2.4 优化目标函数
本文使用变分推断(Variational Inference)作为目标函数[14],通过反向传播优化模型的参数Θ={hn,whn,u,σ,wz,δ}:
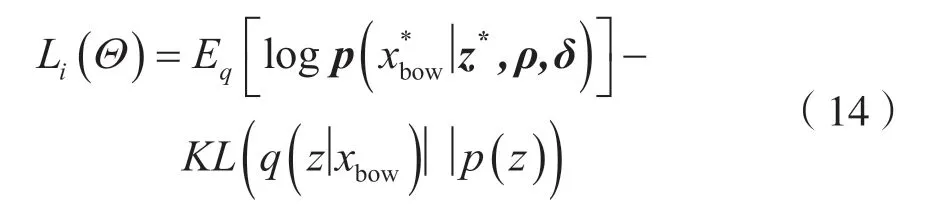
式中,Li表示第i次迭代的目标函数值。KL散度(KL Divergence)是衡量近似分布q(z/xbow)偏离真实分布p(z)的程度,KL 散度越小证明p(z)与q(z/xbow)偏离程度越小。第一项似然估计用于计算解码过程的损失,而第二项表示编码的损失。
利用上述目标函数训练模型,待参数优化完毕后,从方面词分布矩阵β中可以提取不同类别的方面词,从每个评论对应的主题分布θ可推断其所属的方面类别。
3 实验设置
3.1 数据集
本文在两个公共数据集上进行了实验。表1 显示了数据集的统计信息。

表1 实验数据集
Restaurant 数据集总共包含50 000 多条评论,其中包括Ganu 等人[33]提供的3 400 条包含有6 种标 签(Food、Staff、Ambience、Price、Anecdotes、Miscellaneous)的评论。
Laptop 数据集是SemEval2014[34]、2015[35]语义评测比赛中ASBA 任务所使用的数据集,该数据集总共包含8 000 多条评论,其中包括949 条包含19种标签(LAPTOP、DISPLAY、MOUSE 等)的评论。
本文将这些带标签的评论作为模型的测试集。
3.2 实验参数设置
借用NLTK 工具将数据集中所有单词进行写法的规范化,并构建相应的词表。将所有单词转换成对应的小写形式并移除所有标点、停用词以及低频词汇。使用Word2Vec 预训练好的词向量矩阵作为序列信息模块中嵌入层的初始权重[36],并将嵌入层输出维度设置为300。此外,在主题信息模块中,将词向量矩阵作为学习方面词分布矩阵的一个固定常量。将主题数目k设置为14,batch size 设置成250,使用Adam 作为模型的优化器,将优化器中权值衰减设置为1.2×10-6,学习率设置为0.01,迭代次数epochs 为15 次。为了防止过拟合,引入dropout 层。
3.3 评价指标
对于方面词提取任务,使用两种评价指标来评价模型性能。
(1)主题一致性。主题一致性得分是根据方面词之间是否存在共现关系来衡量模型所提取方面词的质量。主题一致性计算过程如下。
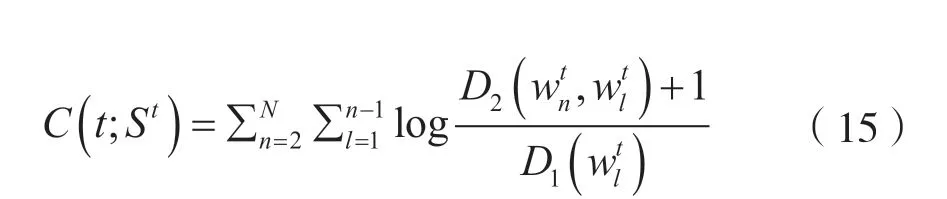
式中,t代表某个类别。St是类别t的前N个方面词集合。分别代表St中第n个方面词和第l个方面词。表示出现方面词的评论个数。表示共同出现的评论个数。主题一致性得分已经被证明与人类的判断有很好的关联性[37]。一般情况下,该得分越高,证明提取的所有方面词越能表达某个类别。
本文使用平均主题一致性来评价模型:
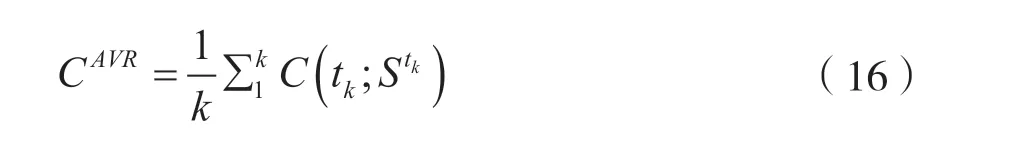
(2)困惑度。使用困惑度对模型的泛化能力进行评估。其定义如下:
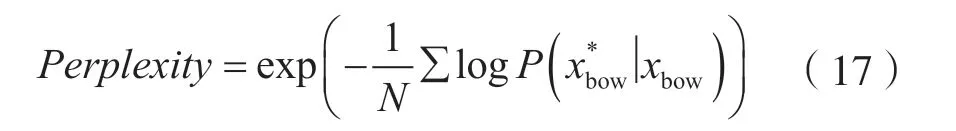
式中,N是测试集中含有的评论个数。是模型重构xbow的概率。困惑度与概率相关,重构概率随着模型泛化能力的提高而变大,因此当模型的泛化能力越好时,困惑度就会越小,证明模型越好。
当模型训练完之后,对测试集进行分类,并用分类结果与数据集给出的标签进行比较。本文采用3 个评价指标对分类性能进行定量评价,分别是各个类别的精确率(Precision)、召回率(Recall)和F1值(F1-score)。计算公式分别为:

式中,TP、FP、FN分别表示真阳性、假阳性、假阴性的数量。以上3 个指标取值范围均在0 到1之间,并且值越大模型分类性能越好。
3.4 基线模型
为了验证本文模型的性能,本文选取其他5 种基线模型进行比较。
(1)k-means。基于欧式距离的聚类算法,其算法认为两个主题向量的欧式距离越近,相似度越大[38]。本文实验中对模型不同的质心迭代10 次。
(2)LDA。LDA 是最常用的基于贝叶斯概率的方面词提取模型,它可以将数据集中的每个主题分布以概率的形式给出,从而通过分析数据集提取出相应的方面类别[10]。本文实验中将模型迭代次数设置为2 000 次,设置Distribution 的参数alpha=0.1,beta=0.01。
(3)BTM。与传统LDA 模型相比,BTM 直接对数据集上共同出现的无序单词对进行建模。实验证明在提取相关方面词上比传统的LDA 模型有更好的表现[25]。本文实验中将模型参数设置为alpha=50/k,beta=0.1。其中,k为方面类别数。
(4)ABAE。He 等人[4]针对方面词提取任务,第一个提出基于注意力的无监督自编码模型。ABAE已被证明比LDA 等早期模型,可更好进行方面词提取。本文实验中将模型学习率设为0.001,迭代15 次,将正交系数λ设置为1,使用Adam 做此模型的优化器。
(5)ETM。Dieng 等人[14]在2020 年国际计算机语言学协会(the Association for Computational Linguistics,ACL)发表一篇文献,提出的一种嵌入主题模型,将传统模型预设的主题分布变为高斯分布。本文实验中将模型学习率设为0.002,迭代15 次,使用Adam 作为优化器。
4 实验结果与分析
4.1 主题一致性
计算各模型在Restaurant、Laptop 数据集上针对每个方面类别提取的前10、20、30、40、50 个方面词的平均主题一致性得分,如图2 所示。
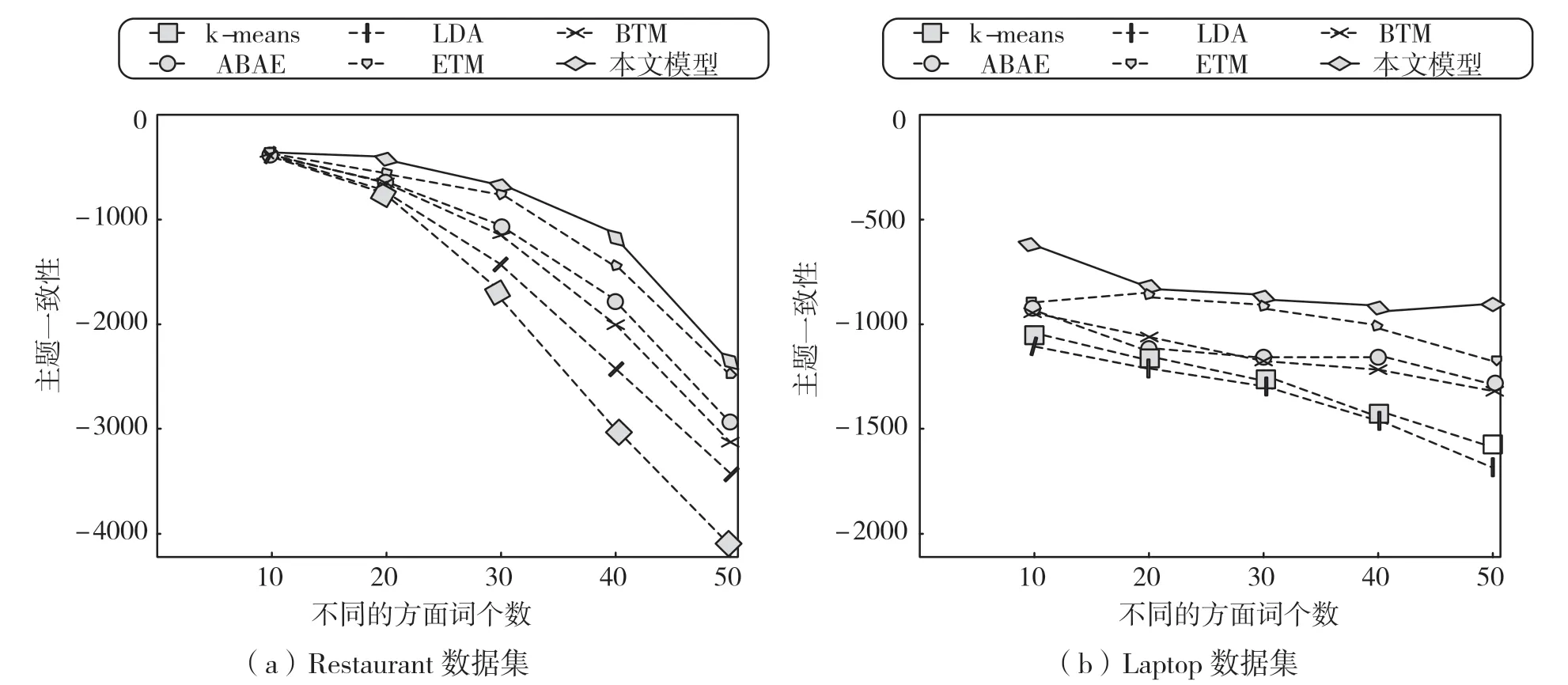
图2 主题一致性得分
从图2 中可以看出,在两个数据集上提取不同数目的方面词,本文模型的主题一致性得分均好于其他模型。这是因为本文模型通过将主题信息与序列信息进行结合,可更好地将代表某个类别的方面词聚类,提取出与方面类别更相关的方面词。此外,随着方面词个数的增加,所有模型的主题一致性得分都呈下降趋势。这是因为当提取的方面词个数增多时,与某个方面类别无关的噪声词也随之变多,导致主题一致性下降。相比Restaurant 数据集,Laptop 数据集中,每个模型的主题一致性得分变化较平缓。分析Laptop 数据集发现,Laptop 数据集较小,且方面词分布稀疏,大部分模型不能充分学习到方面词共现信息。而本文模型在方面词分布稀疏的情况下,有效利用了评论的序列信息,能在数据集较少的情况下也能较好地提取方面词。
4.2 困惑度
图3 展示了在Restaurant、Laptop 数据集上针对方面类别数为10、15、20、25、30 时各模型的困惑度。从图3 中可以看出,本文模型在不同的数据集以及类别数不同的情况下,困惑度都要较好于其他模型。(1)由于LDA 和k-means 两个模型容易受噪声词影响且较不稳定,因此在两个数据集上,困惑度较高于其他模型。(2)BTM 提取方面词时,直接对共现的单词对进行建模,较好解决了LDA 在对短评论进行方面词提取时容易出现的稀疏性问题。但是,BTM 在使用单词对进行建模时,会获得很多冗余信息,使模型并不能就较准确地预测出有用的信息,降低了模型的泛化能力。(3)ABAE 借助注意力过滤评论中与方面词无关的单词,并保留与方面类别有关的大部分信息,因此在两个数据集上都提供了较好的性能。(4)ETM 将LDA 与词嵌入结合,较好的生成与方面类别相关的评论,在很大程度上性能要优于ABAE 模型。(5)ETM 没有考虑评论中的序列信息,而本文模型通过重构主题向量来获得评论中含有的序列信息,因此在两个数据集上的表现较好于ETM模型以及其他模型。
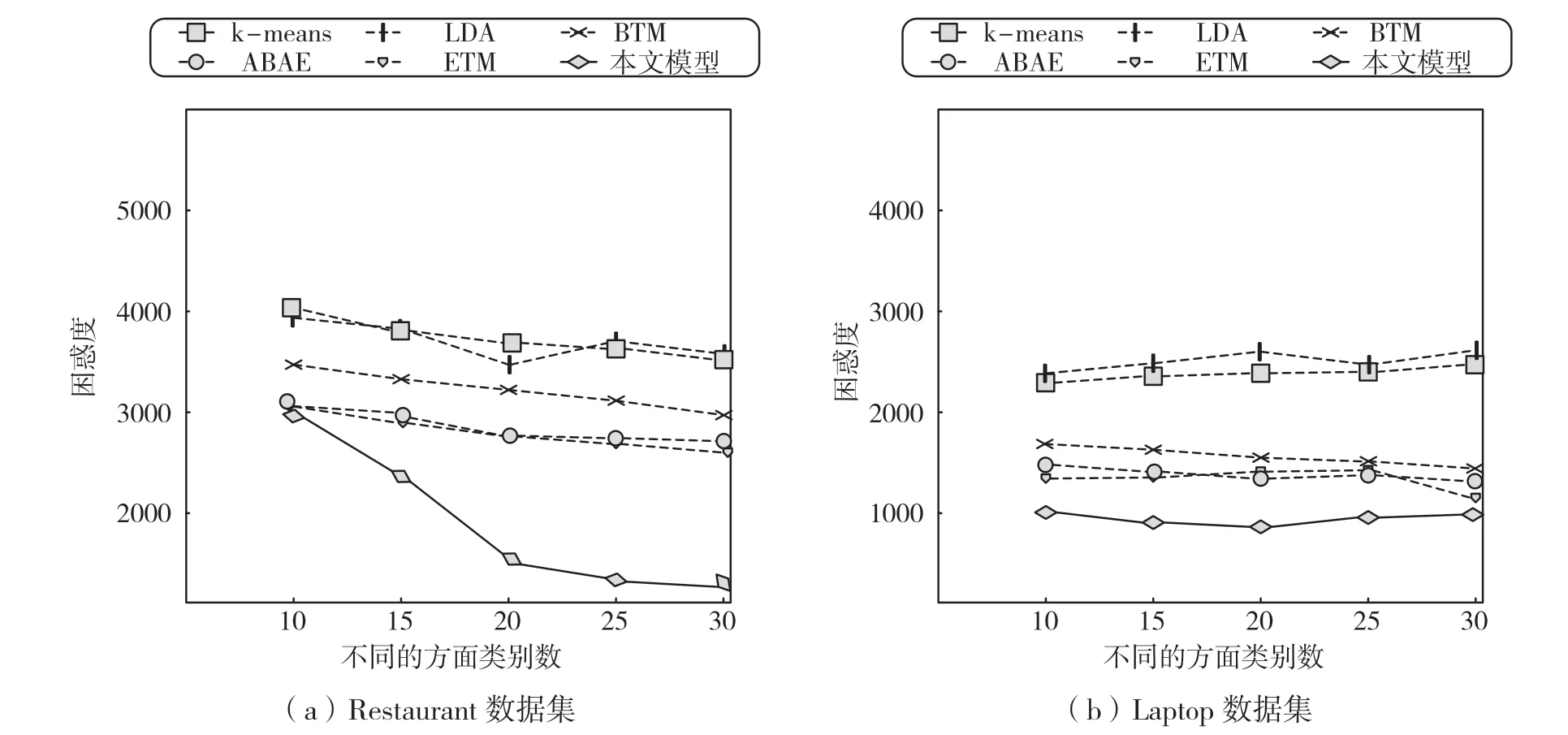
图3 困惑度
此外,从图3 的Restaurant 数据集中可以看出,大部分模型的困惑度都随着方面词个数的增加呈下降的趋势,而本文模型通过使用预训练的词向量矩阵来构建方面词分布矩阵,这种先验知识使模型重构更容易,因此本文模型的困惑度下降趋势要较快于其他模型。
4.3 方面类别推断
将本文模型与ABAE 在Restaurant 数据集进行方面词提取的比较,如表2 所示。本文模型与ETM在Laptop 数据集上进行方面词提取的比较,如表3所示。
从表2 中可以看出,相较于ABAE,本文模型提取的方面词较容易推断出方面类别。例如,第一个类别是关于Food,第二个类别是关于Staff,第三个类别是关于Ambience。ABAE 提取了一些与方面类别弱相关或无关的方面词,而本文模型在不同方面类别下提取强相关的方面词最多,且排序较靠前,例如针对第一个类别,本文模型提取了“salmon”“mascarpone”等关于Food 的方面词。
此外,本文模型可以将含义相似的方面词聚集在一起,比如表2 的Restaurant 数据集中的“dark”和“dim”以及表3 的Laptop 数据集中的“keyboard”和“screen”等词。含义相似的方面词常常出现在含有相似语义信息的语境中。本文模型通过结合主题、序列信息增强了模型捕获语义信息的能力,因此能获得语义连贯的方面词。
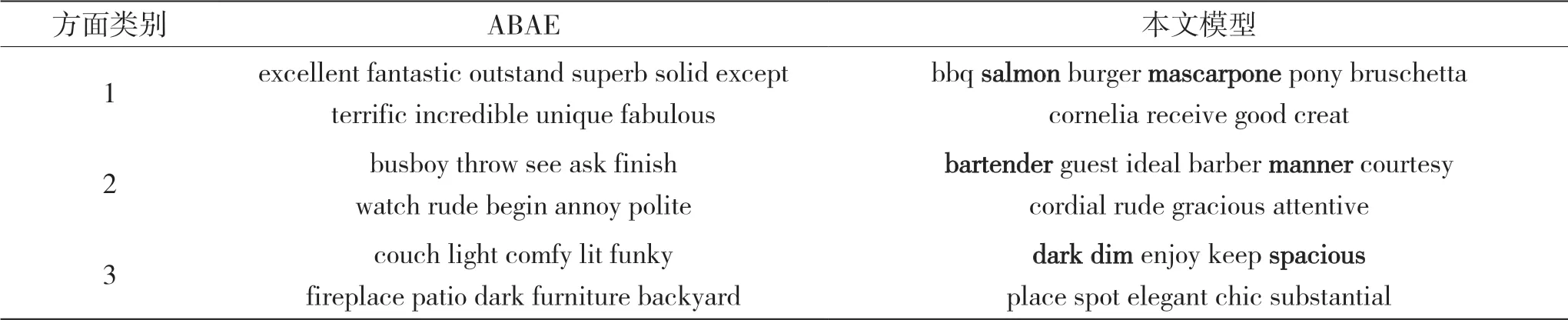
表2 提取Restaurant 数据集中前30 个方面词

表3 提取Laptop 数据集中前30 个方面词
4.4 分类性能
本文使用带标签的评论来评估模型的分类性能。在使用Restaurant 数据集时,参考文献[4]的做法,使用含有一个标签的评论进行性能评估,只评估与Food、Staff、Ambience 这3 个类别有关的评论,结果如表4 所示。在使用Laptop 数据集时,只评估出现次数最多的LAPTOP、DISPLAY、MOUSE 这3个类别对应的评论,并用宏平均作为此数据集的评价指标,结果如表5 所示。
如表4 所示,在对Food、Staff 类别进行分类评估时,本文模型较ETM 的F1值平均提升6.7%,Recall值平均提升了7.65%。而在对标签为Ambience 的评论进行分类的时候,除了Precision 指标,其他两个评价指标都没达到最好。将本文模型对Ambience预测错误的评论输出并进行分析,发现模型无法分类的评论,例如“great group great date great early brunch nightcap”,都是含糊的表达,并没有出现与Ambience 类别有关的词汇。
从表5 中可以看出,本文模型较ETM 的Recall、F1宏平均分别提升了9.7%、7.7%。通过分析数据集,发现Laptop 数据集中有很多含有潜在主题信息的方面词,由于本文模型中结合了序列信息,可更好地学到方面词的潜在主题信息,因此提升了模型的分类性能。
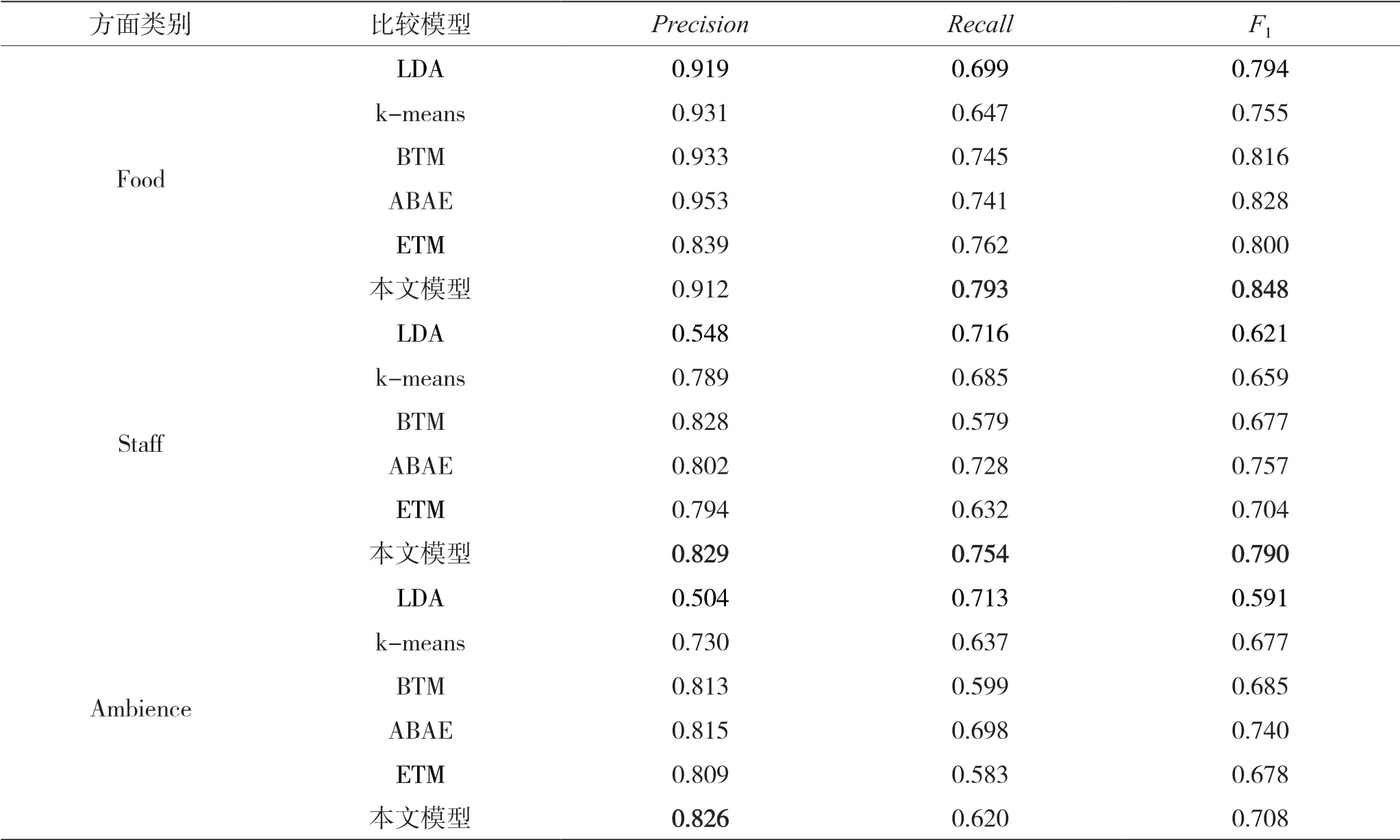
表4 Restaurant 数据集的分类结果
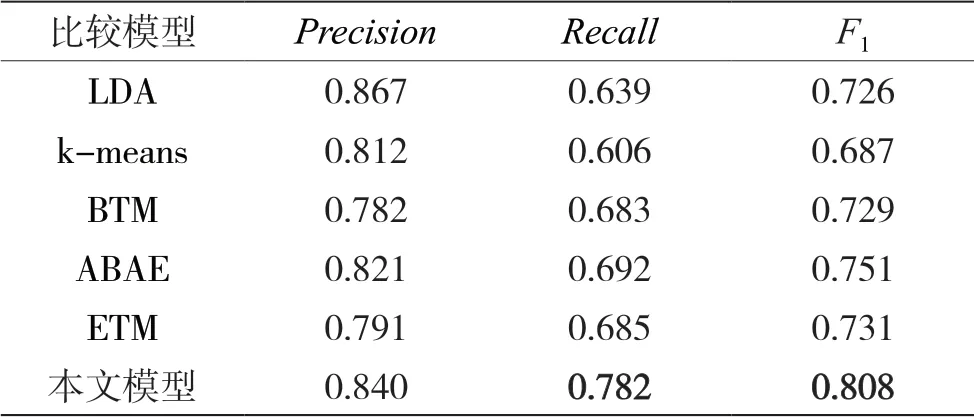
表5 Laptop 数据集的分类结果
从表5 中可以看出,本文模型较ETM 的Recall、F1宏平均分别提升了9.7%、7.7%。通过分析数据集,发现Laptop 数据集中有很多含有潜在主题信息的方面词,由于本文模型中结合了序列信息,可更好地学到方面词的潜在主题信息,因此提升了模型的分类性能。
4.5 消融实验
为了验证序列信息及使用不同的注意力对模型分类性能的影响,本文在Laptop 数据集中进行了相应的消融实验。表6 列出了使用不同注意力以及是否结合序列信息的消融实验结果。其中,-seq_att/o、-top_att/o 表示本文模型在进行训练时,不使用序列注意力、主题注意力;-seq/o 表示本文模型在进行训练时,没有结合序列信息。
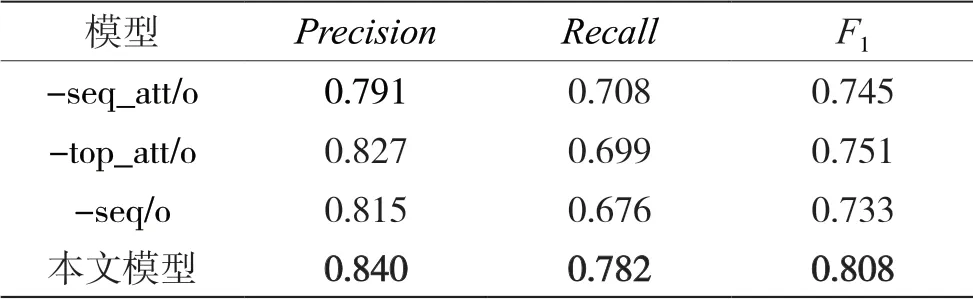
表6 使用不同注意力以及是否结合序列信息的消融实验结果
从表6 中可以看出,本文模型相较于不结合序列信息的F1值提升了7.5%,而相较于不使用序列注意力和主题注意力的F1值分别提升了6.3%、5.7%。原因可能是,在没有结合序列信息的情况下,仅通过主题信息并不能较全面地获得评论中每一个单词与方面类别之间的相关性。此外,通过使用序列注意力使得模型能够更好地关注含有潜在主题信息的方面词,而使用主题注意力能更好地将主题信息与序列信息进行结合。因此,在模型中使用两种不同的注意力能进一步提升模型的整体性能。
4.6 实例分析
上述实验证明结合序列信息可有效地提高模型的整体性能,本文还针对所使用的注意力机制进行了实例分析。图4 展示了ABAE 和本文模型通过注意力机制对评论中所有单词进行权值分配。
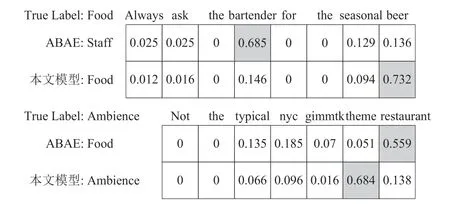
图4 评论中单词的权值分配
从图4 中可以看出,ABAE 为“bartender”“restaurant”赋予较高的权值,从而错误地将这两条评论预测为“Staff”“Food”。相比之下,本文模型为“beer”“theme”赋予较高的权值,能够将其正确预测为“Food”“Ambience”。通过分析发现,本文模型可根据序列注意力对评论中单词持有不同的关注,有助于更好地提取方面词;通过主题注意力获得的潜在主题信息,使模型可以更加准确地推断评论所属的方面类别。即使针对描述较含糊且没有明显特点的第一条评论,本文模型都可以较好地对其进行分类。
5 结语
本文提出一种新的无监督方面词提取模型,该模型将主题信息与序列信息通过注意力进行结合,借助注意力使模型能较好地提取含有潜在主题信息的方面词。在两个数据集上进行实验,验证了本文模型在提取方面词任务上优于其他模型,且可获得关联性较好的方面词,此外,验证了使用注意力机制将主题、序列信息进行结合,可提升模型的整体性能。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
陶瓷学报(2021年4期)2021-10-14
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
少儿画王(3-6岁)(2020年4期)2020-09-13
阅读(快乐英语高年级)(2020年8期)2020-01-08
智慧少年·故事叮当(2018年11期)2018-05-14
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
小学生时代·大嘴英语(2014年9期)2014-11-04
微型计算机(2009年4期)2009-12-23
