
基于注意力机制和可变形卷积的鸡只图像实例分割提取
2021-05-19 01:50郝宏运李腾飞王红英
农业机械学报 2021年4期
方 鹏 郝宏运 李腾飞 王红英
(1.中国农业大学工学院, 北京 100083; 2.北京城市学院北京3D打印研究院, 北京 100083)
0 引言
人类对畜牧业产品的消费需求逐年上升,同时,畜牧业所需的生产资料(土地、水资源、劳动力等)却不断萎缩[1],生产力与社会需求的矛盾日益凸显。在这种情况下,精准畜牧业[2-3]理念以其可持续、高效、低耗的特点应运而生。获取动物的个体行为、健康、福利信息对精准畜牧业管理决策十分重要[4-5]。机器视觉技术广泛应用于动物监测中,而基于视觉的监测技术的前提是实现对动物图像的提取和分割,只有对动物轮廓信息进行精准分割,才能对动物个体进行生长评估[6]、体况评价和行为分析[7-8](如发情行为、产前行为)等方面的研究。
机器视觉技术具有采集速度快、识别精度高的特点,同时更具有无接触、对动物应激小的优势,在鸡只体况监测[9-12]、鸡只行为识别[13-14]和鸡只福利状态监测[15-16]等方面都有广泛的应用。相关研究在很大程度上依赖于图像的分割,显然,图像分割的准确性和精度对基于机器视觉的鸡只监测技术至关重要。然而,传统的基于颜色空间[17]、帧差或者光流[18]的分割方法难以在复杂养殖环境中实现高精度、高鲁棒性的图像分割。
近年来,具有很强特征学习能力的深度卷积神经网络在计算机视觉领域得到了广泛应用。通过大量经过人工标注的图像数据的训练,神经网络可以充分提取携带丰富空间和语义信息的图像特征,并将其用于图像分割,其分割效果良好[19]。作为一种像素级识别分割目标轮廓的目标检测算法,实例分割最早在2014年提出,并迅速得到发展,先后出现了DeepMask[19]、SharpMask[20]等实例分割算法,但均存在精度不高、模型泛化性不够的缺点。文献[21]提出的Mask R-CNN框架在模型泛化能力、分类精度和分割精度上均有优异的表现。研究表明,通过深度卷积神经网络实现养殖环境下鸡只轮廓的提取和分割是可行的。
为了实现叠层笼养环境下鸡只图像的高精度分割和轮廓提取,本文提出一种基于Mask R-CNN的鸡只图像分割和轮廓提取方法,先对原始图像进行增强,以提高图像品质,随后进行鸡只图像的分割和轮廓的提取。
1 图像采集与图像增强处理
以叠层笼养环境下的白羽肉鸡为研究对象,进行识别分割试验。于2019年7月9—11日在山东省烟台市蓬莱区民和牧业股份有限公司肉鸡养殖场采集了27~29日龄的肉鸡图像。试验鸡舍为一栋全封闭的8层叠层笼养肉鸡舍,舍内平均光照强度为8 lx,共饲养罗斯308肉鸡114 240只。
图像采集所用设备主要包括:Sony XCG-240C型彩色数字相机,分辨率为1 920像素×1 200像素,匹配焦距6 mm的Ricoh FL-CC0614A-2M型定焦镜头;立式三脚架,最大拍摄高度可达2.2 m。拍摄时相机参数设定为:采集帧率3 f/s,曝光时间80 ms。
将工业相机安装在立式三角架上,固定相机的工作距离、拍摄高度和拍摄角度,在笼门前方位置对笼内鸡群进行拍摄。将采集的视频按帧提取成静态图像,人工挑选出800幅肉鸡图像建立样本集。由于舍内照度较低,采集的图像亮度不够,为便于后续的图像标注和图像特征提取,先对采集的图像进行Retinex增强。同时,为减少计算量,降低模型训练时间,将原图像调整为448像素×256像素。随后,在Labelme图像标注工具中用多边形标注出鸡只的外轮廓,共标注目标11 034个,制作成COCO(Common objects in context)格式的数据集。在样本集中随机选取70%(560幅)图像作为训练集,用于模型的训练,选取20%(160幅)图像作为验证集,用于训练参数的调优,选取10%(80幅)图像作为测试集,用于评估最终模型的识别能力。采集的原图及Retinex增强后的图像如图1所示。
2 基于Mask R-CNN的鸡只轮廓实例分割模型优化
Mask R-CNN作为一种实例分割算法,集成了目标检测和语义分割两大功能,可以同时完成目标分割、分类和检测任务,且在这3种任务上均有较优的表现,是一种综合性能很优异的实例分割方法。因此,本文选择在Mask R-CNN模型框架下进行鸡只图像实例分割模型的研究,其网络结构如图2所示。
整体上,Mask R-CNN网络分为主干网络、区域生成网络(Region proposal networks, RPN)和头部网络。主干网络主要进行图像特征的提取,区域生成网络主要通过提取的图像特征生成感兴趣区域(ROI),而头部网络则在此基础上完成之后的目标分类、边框回归及掩膜预测生成工作。
针对本文待分割图像的特点,在现有Mask R-CNN网络基础上进行了调整和优化,构建了一种鸡只图像分割和轮廓提取网络。主要对主干网络做出3点优化:①调整卷积层结构。②构建基于注意力机制的卷积层。③引入可变形卷积。
2.1 主干网络卷积层结构调整优化
目前,通用的Mask R-CNN网络以深度残差网络[22](ResNet)和特征金字塔网络(Feature pyramid networks, FPN)相结合的方式作为主干网络,负责输入图像的特征提取。ResNet网络作为一种深层网络,可以有效解决常规网络堆叠到一定深度时出现的梯度弥散问题,通过深层次的网络达到较好的特征提取效果,其基本结构为残差模块(Residual block),通过模块的堆叠,使网络达到较大深度。
现有研究表明,浅层网络的感受野较小,能够捕获更多的图像细节,提升检测的精度;而深层网络输出的特征更加抽象,更加关注图像的语义信息,有利于目标的检出[23]。本文研究对象为笼养状态下的鸡只,目标单一,类别少,目标检出相对容易。因此对现有主干网络卷积层数量和残差学习模块堆叠方式进行调整,适当削减卷积层的数量,增加浅层网络深度,减小深层网络深度,使网络更加关注图像的细节信息。网络由原来的101层卷积层减少为41层,降低网络计算量;同时网络第3阶段卷积层数量从12层增加为15层,第4阶段卷积层数量从69层减少为9层,第5阶段卷积层数量从9层减少为6层,降低图像特征损耗。调整后的ResNet网络结构如图3所示。图中只包含卷积层和池化层,每个卷积层后还有批量正则化层和激活层未画出;第1~5阶段分别为ResNet网络的5个阶段;2x、4x为模块重复次数;Conv(64, 256,k=(1,1),s=1,p=0)中,k为卷积核尺寸,s为滑动步长,p为填充像素数,256为卷积核通道数,64为上一层卷积层输出的通道数,其余卷积层类似。主干网络由残差学习模块堆叠而成,残差学习模块首端和末端为1×1卷积核,中间为3×3卷积核。在网络每个阶段的第1个残差模块,除了3个卷积层的串联,输入和输出之间还通过一个卷积层旁路相连,以增加输入特征图的通道数,便于和输出特征图融合,而后面接的残差学习模块输入和输出特征图的通道数一致,故可以不通过卷积层升高维度而直接进行加操作。这种结构可以有效降低特征损耗,提升模型训练效果。
FPN[23]网络结构如图4所示。输入图像自下而上分别经过ResNet网络5个阶段的处理,输出5种不同尺度的特征图(C1~C5)。输出的特征图分别通过一个1×1的卷积操作后与自上而下的上采样操作生成的特征图进行融合,生成特征图M5、M4、M3和M2,随后经过3×3的卷积操作消除上采样的混叠效应,生成特征图P5、P4、P3和P2,P5经过一次下采样操作生成P6,特征图P2、P3、P4、P5和P6分别独立地输入到RPN网络,生成若干个感兴趣区域(ROI)。FPN网络将ResNet网络每一阶段输出的特征图融合,既利用了高层特征图的强语义信息,又利用了低层特征图的强空间位置信息,大大提升了主干网络的特征提取能力。
2.2 基于注意力机制的卷积层构建
注意力机制最早由MNIH等[24]提出并引入图像分类领域,随后在机器学习领域迅速发展,众多应用于不同领域的注意力模型相继提出。注意力机制模仿人类视觉系统的处理机制,人类在进行视觉信息处理时会自动过滤不重要的信息,而把更多注意力资源用于需要重点关注的目标区域,大大提高了视觉信息处理效率与准确性。而当注意力机制引入基于神经网络的图像处理领域时,其本质是一种资源的重新分配机制,即对不同重要程度的信息赋予不同的权重,大大提高神经网络效率,用很小的计算量换取网络性能的显著提升。
为提升鸡只轮廓实例分割模型网络性能,本文在ResNet网络中引入注意力机制。在原有网络结构中添加1个通道注意力模块和1个空间注意力模块[25]。
通道注意力模块结构如图5a所示,输入的特征图经过1个全局最大池化层和平均池化层后,分别得到1个通道描述,随后这2个通道描述送入1个2层的神经网络,得到2个特征向量,2个特征向量通过逐元素累加的方式合并成1个,通过1个激活函数输出通道权重系数,权重系数与输入特征相乘即得到新的特征图。空间注意力模块结构如图5b所示。
本文在ResNet网络的每一个残差模块中串联插入1个通道注意力模块和1个空间注意力模块。卷积运算通过将跨通道和空间信息融合在一起来提取信息特征,既考虑了不同通道像素的重要性,又考虑了同一通道不同位置像素的重要性。其在ResNet网络残差学习模块的位置如图6所示。每个残差学习模块中,在第2个1×1卷积层之后串联接入1个通道注意力模块和1个空间注意力模块。
2.3 引入可变形卷积层
在图像检测任务(目标检测、实例分割)中,通常需要网络对同一目标的不同姿态,如位置的偏移、角度的旋转及尺度的变化都具有相同的识别能力。然而,受限于卷积操作本身的固定性,卷积神经网络并不具有尺度不变性和旋转不变性,基本没有对目标几何形变的适应能力[26]。实际中,神经网络对目标变化的适应能力几乎完全来自于数据本身的多样性。现有研究表明,标准卷积中的规则格点采样是导致网络难以适应几何形变的主要原因,为此DAI等[27]提出了一种可变形卷积网络,用可变形卷积取代神经网络中的标准卷积,众多研究表明,该方法在目标检测领域表现优异[28-30]。
标准的卷积操作具有非常固定的几何结构,很难与目标复杂的外形相匹配。而可变形卷积拥有可变化、不规则的形状,感受野灵活多变,可以很好适应不同尺寸、外形的目标。在标准的二维卷积过程中,对于输出特征图中的每一个位置P0,其特征值y(P0)计算式为
(1)
式中w(Pn)——该采样位置的卷积核权重
x(P0+Pn)——采样位置的输入特征值
Pn——感受野区域中的所有采样位置
R——感受野区域
教师在开展中长跑运动时,单一的以训练为主,没有合适的方式方法,无法引导学生去摆脱抵触情绪,所以学生的畏难心理日益严重,对中长跑运动的兴趣也直线下降。
而在可变形卷积中
(2)
式中x(P0+Pn+ΔPn)——采样偏移位置的输入特征值
ΔPn——采样点位置的偏移量
可见,可变形卷积就是在传统的卷积操作上加入了一个采样点位置的偏移量,使卷积变形为不规则卷积,从而拥有更大、更灵活的感受野。
为分割出图像中鸡只的轮廓像素,本文在ResNet网络中加入可变形卷积层,通过引入偏移量,增大感受野,同时使感受野可以适应不同尺寸、形状的鸡只轮廓,达到更好的分割效果。将ResNet网络的第3、4、5阶段的3×3卷积调整为可变形卷积,而第2阶段保留为标准卷积层,以减小引入可变形卷积带来的网络参数量的增加对网络负荷的影响。
3 鸡只轮廓识别分割试验
3.1 试验条件及配置
试验在Ubuntu 18.04系统下进行,试验所用机器配置:处理器为Intel(R) Core(TM) i7-9700K,主频3.6 GHz,内存16 GB,显卡为NVIDIA GeForce RTX 2080(16 GB),使用GPU加速计算,采用Python作为编程语言,选择Pytorch框架来实现网络模型的搭建、训练和调试。训练集为560幅图像,验证集为160幅图像,测试集为80幅图像。
使用Torchvision视觉库中的ResNet预训练模型作为初始输入权重,采用随机梯度下降法对鸡只轮廓分割网络进行训练。设置学习率为0.001,采用热身策略,初始学习率为0.000 18,采用线性增加策略,训练5个epochs后增加到0.001;动量为0.9,权值衰减系数为0.000 1,训练迭代100个epochs,每5个epochs保存一个权重,取精度最高的模型为最终模型。
3.2 试验结果与分析
采用不同的主干网络进行鸡只轮廓分割试验:①现有的ResNet 101网络。②调整现有网络卷积层结构后得到的ResNet 41网络。③ResNet 41网络中添加注意力机制(简称为ResNet 41+cbam)。④ResNet 41网络中添加注意力机制并将部分卷积层替换成可变形卷积(简称为ResNet 41+cbam+dcn)。⑤ResNet 50网络中添加注意力机制和可变形卷积层(简称为ResNet 50+cbam+dcn)。
模型对鸡只图像的分割结果如图7所示。由图7可知,分割模型可较准确地将鸡只轮廓之间的粘连区域分割开,可实现笼养鸡只轮廓的提取分割。
以准确率A(Accuracy)、召回率R(Recall)和精确率P(Precision)、平均检测时间t作为评价指标,衡量分割模型的性能。
不同模型的性能如表1所示。由表1可知,将主干网络卷积层数从101层减小为41层,模型各指标未有显著降低,说明原有的101层卷积网络对本文研究的鸡只轮廓分割提取任务有较大冗余,降低其卷积层数不影响模型性能,但可以大幅降低运算量,其单幅图像检测时间从0.32 s减小为0.18 s,降低了44%。在ResNet 41网络的基础上引入注意力机制,模型各指标性能有较大提升,其精确率和准确率分别从77.01%、82.34%大幅提升至85.49%、88.35%,召回率略有下降,而检测时间却没有显著增加,注意力机制的引入使模型用很小的资源开销换取了较大的性能提升。在引入注意力机制的基础上,将部分3×3卷积层调整为可变形卷积层,模型性能较优化前有一定程度的提升,精确率和准确率分别从85.49%、88.35%提升到88.60%、90.37%,与现有的Mask R-CNN网络相比,其精确率和准确率分别提高了10.37、5.89个百分点。但同时,可变形卷积的引入增加了模型的参数量,其检测时间从0.24 s增至0.41 s,对模型的实时性有所影响。在ResNet 50 网络中引入注意力机制并添加可变形卷积层,模型在验证集上的精确率和准确率分别为87.23%、89.80%,均略低于在ResNet 41网络中引入注意力机制及添加可变形卷积层的模型性能,说明本文设计的41层网络结构有利于提升分割网络的性能。
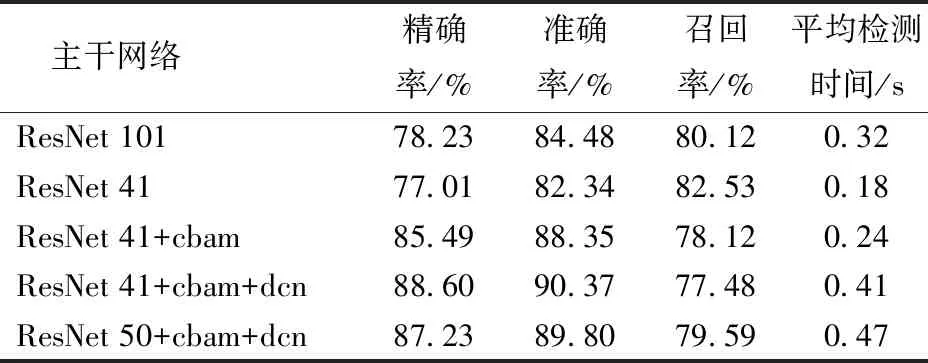
表1 不同网络性能对比Tab.1 Performance comparison of different networks
3.2.2不同模型损失曲线分析
对上述5个网络训练过程中的损失函数变化进行分析。损失函数衡量的是模型训练过程中预测值和真实值之间的差异变化。在基于Mask R-CNN网络的鸡只轮廓实例分割模型的训练中,损失函数L主要由分类损失、检测损失和分割损失3部分组成,定义式[21,31]为
L=Lcls+Lbbox+Lmask
(3)
式中Lcls——模型的分类损失
Lbbox——检测损失(边框回归损失)
Lmask——分割损失
分类损失Lcls计算式为
(4)
式中Ncls——类别数量
pi——目标被预测为正样本的概率
检测损失Lbbox计算式为
(5)
其中
(6)
Nreg——特征图的像素值
ti——预测边框的坐标向量
分割损失Lmask计算式为
Lmask=Sigmoid(Ck)
(7)
式中Ck——第k类目标
网络对于每一个ROI都有k×m2维度的输出,k为类别数,共输出k个分辨率为m×m的二值掩膜。对于第k类目标(Ck),Lmask定义为对掩膜中的每一个像素执行Sigmoid函数得到的平均二值交叉熵损失。
图8为以ResNet 41为主干网络的鸡只轮廓分割模型训练过程中检测损失、分类损失、分割损失和总损失的变化。各损失均在训练开始的很短时间内下降到较低值,随后随着迭代步数的增加缓慢下降,训练过程中各损失曲线波动较小,模型收敛较好,说明各超参数配置较为合理。当迭代步数达到10 000次(100个epochs)左右时,各损失均趋于稳定,不再持续下降。
图9为不同网络的总损失随迭代步数的变化情况。5个网络的总损失均随着网络的迭代逐步下降,最终趋于稳定,模型收敛。ResNet 101和ResNet 41网络的损失曲线在训练后期基本重合,最终训练损失分别为0.85和0.87左右,一定程度上说明2个模型具有相似的性能表现。而ResNet 41+cbam网络和ResNet 41+cbam+dcn网络最终训练损失分别稳定在0.63和0.31左右,较优化之前的网络有较明显的下降,将部分卷积层替换成可变形卷积后,模型性能有一定提升。ResNet 50+cbam+dcn的网络最终训练损失在0.43左右,略高于ResNet 41+cbam+dcn网络,ResNet 41+cbam+dcn网络在所有试验网络中性能最优。
3.2.3不同模型输出特征可视化分析
为更好地解释本文采用的优化方式对模型性能的提升,利用GRAD-CAM[32]对不同网络进行可视化分析,通过梯度来衡量卷积层中空间位置的重要性,分别输出不同网络、不同阶段输出特征的类激活热力图(Class activation heat map),可以清楚地显示网络在进行预测时重点关注的图像区域。本文将5种网络第2阶段和第5阶段的特征可视化结果进行了比较,结果如图10所示。图中红色区域的范围越大,说明网络提取的特征更多地覆盖到了需要识别的目标上。由图可知,ResNet 101网络和ResNet 41网络均只有少部分特征覆盖到了鸡只轮廓上,而ResNet 41+cbam网络、ResNet 41+cbam+dcn及ResNet 50+cbam+dcn网络提取的特征更好地覆盖了目标对象区域,说明在网络中引入注意力机制确实加强了网络对重点信息的关注程度,提升了网络性能。而可变形卷积使网络具有更大、更灵活的感受野,提升了网络对不同尺寸、不同外形目标的适应能力,提升了网络对鸡只轮廓的分割能力。对比ResNet 41+cbam+dcn网络和ResNet 50+cbam+dcn网络的可视化结果,可以发现ResNet 41+cbam+dcn网络特征提取效果略好。从第2阶段和第5阶段的特征图可以看出,随着网络的加深,网络提取的特征越来越多地覆盖到了鸡只轮廓上,同时网络也过滤掉了一些不属于鸡只轮廓的特征,提升了模型的检测精度。模型输出特征的可视化分析结果与上文中模型性能指标和训练损失分析结果一致,进一步说明本文对网络进行的优化是有效的。
4 结论
(1)以叠层笼养下的肉鸡为研究对象,将Mask R-CNN网络引入鸡只轮廓的分割提取中,构建了一种鸡只图像分割和轮廓提取网络。该网络以基于注意力机制、可变形卷积的41层深度残差网络和特征金字塔网络相融合的方式作为主干网络,可以实现笼养状态下肉鸡图像的分割和轮廓提取。
(2)优化后的模型在验证集的精确率、准确率和召回率分别为88.60%、90.37%和77.48%,与现有的Mask R-CNN网络相比,其精确率和准确率分别提高了10.37、5.89个百分点,而单幅图像的检测时间仅增加了0.09 s,说明注意力机制和可变形卷积的引入有效提高了网络的综合性能。
(3)特征图可视化分析表明,网络中引入注意力机制和可变形卷积后,网络提取的特征更多地覆盖到鸡只轮廓上,提高了检测精度。本文算法模型对笼养状态下的鸡群分割效果较好,能准确分割提取鸡只个体轮廓。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
小天使·二年级语数英综合(2019年10期)2019-11-08
时代英语·高一(2019年5期)2019-09-03
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
大灰狼(2009年7期)2009-08-26
