
基于DeepSORT算法的肉牛多目标跟踪方法
2021-05-19 01:50:10张宏鸣董佩杰孙红光李书琴王红艳
农业机械学报 2021年4期
张宏鸣 汪 润 董佩杰 孙红光 李书琴 王红艳
(1.西北农林科技大学信息工程学院, 陕西杨凌 712100; 2.宁夏智慧农业产业技术协同创新中心, 银川 750004;3.西部电子商务股份有限公司, 银川 750004)
0 引言
牛肉是人类主要肉食之一[1]。肉牛的行为可以反映其健康状况[2-3],进而反映牛肉的品质。近年来,随着人们对牛肉需求的不断增加,肉牛的养殖规模不断扩大,精细化管理难度增加。实时感知肉牛的运动行为、掌握其运动状态有助于及时发现肉牛异常,从而保证牛肉质量和产量。多目标实时跟踪是肉牛行为实时感知的基础,对于肉牛养殖具有重要意义。
目前,众多学者在动物行为的实时感知方面进行了诸多研究。部分学者研制了可穿戴设备,利用安装在动物身上的追踪设备收集动物的运动信息,获取其行为数据[4-6],再借助机器学习[7-8]、深度学习[9-10]方法分析数据,从而实现对动物行为的监测。由于动物行为的不确定性,可穿戴设备的损坏率较高[11],导致制作、维护成本增加,不能满足大型养殖场的使用需求。相比之下,利用养殖场已有的监控视频对牲畜进行管理具有使用便利、普及度高、成本低的优点,非常适合大型养殖场对牲畜的精细化管理。
利用监控视频对牲畜进行跟踪需满足实时性要求,而多目标跟踪的速度在很大程度上取决于其检测到目标的速度。传统的目标检测算法如背景减法[12]、帧间差分法[13]和光流法[14-15]无法满足实时性的要求。目前,基于深度学习的目标检测算法不断成熟,该算法可划分为One-stage和Two-stage检测算法两类。One-stage算法主要有YOLO系列算法[16-18]、SSD[19-21]、RetinaNet[22]等。何东健等[23]采用YOLO v3算法,通过优化锚点框和改进网络结构实现了对挤奶奶牛的个体识别,识别准确率达95.91%,mAP为95.16%。Two-stage算法主要有R-CNN[24]、Fast R-CNN[25]、Faster R-CNN[26]等。SUN等[27]利用Faster R-CNN算法对猪进行多目标跟踪,该算法具有良好的抗遮挡能力,能较为精准地跟踪多个目标。相对于Two-stage算法,One-stage算法速度更快、实时性更高,而YOLO v3算法精度高于大部分One-stage算法中的其他检测算法。
在多目标跟踪算法方面,基于匈牙利算法(KM匹配)的后端追踪优化算法,如SORT[28]、DeepSORT[29]算法,能够满足实时跟踪的要求,其中DeepSORT算法在SORT算法的基础上,通过提取深度表观特征明显提高了多目标的跟踪效果。然而其跟踪效果依赖目标检测器的精确度和特征区分程度,其跟踪速度与目标检测速度密切相关。
基于此,本文提出一种改进YOLO v3算法和Mudeep目标重识别算法相结合的DeepSORT肉牛多目标跟踪方法,针对YOLO v3算法在多尺度环境下识别效果较差的问题,通过添加长短距离语义增强模块(Long-short range context enhancement module,LSRCEM)进行多尺度融合,建立LSRCEM-YOLO模型,提高YOLO v3算法的检测精度,通过修改YOLO v3模型的网络结构,简化模型复杂度,增强实时性,通过Mudeep目标重识别算法提取肉牛具有鉴别性的特征,减少标号变化现象,以期实现肉牛多目标实时跟踪。
1 材料与方法
1.1 视频采集
实验视频采集于某肉牛养殖场,为其养殖场内部监控设备所拍摄视频,拍摄对象为成年安格斯牛与西门塔尔牛,摄像机位于矩形肉牛养殖棚短边的天棚上,斜向下俯视拍摄,能够拍摄到牛棚内的大部分肉牛活动区域。
供试视频拍摄时间为2019年7月21—29日,共1 328段视频,平均时长为35 min,经筛选,剔除夜间、无目标、镜头污染等无效片段,保留有效视频66段,MP4格式,分辨率为1 920像素(水平)×1 080像素(垂直),视频帧率为24 f/s,视频场景如图1所示。
1.2 技术路线
本研究旨在利用深度学习方法通过视频监控对肉牛进行实时跟踪,本文方法技术路线如图2所示,包括5部分:
(1)数据集构建:筛选可用视频,对视频进行剪切,提取视频关键帧,通过对关键帧进行标注、裁剪,分别构建肉牛目标检测、目标重识别、目标跟踪数据集。
(2)肉牛目标检测模块训练:利用肉牛目标检测数据集训练LSRCEM-YOLO模型用于肉牛目标检测,作为多目标跟踪的检测器。
(3)肉牛重识别网络构建:利用肉牛重识别数据集训练Mudeep[30]用于肉牛目标重识别。
(4)肉牛多目标实时跟踪的实现:结合LSRCEM-YOLO模型、Mudeep模型与DeepSORT模型,实现肉牛的多目标实时跟踪。
(5)结果分析:通过对目标检测效果、重识别效果、多目标跟踪效果进行评价,全面评估肉牛多目标跟踪模型的效果。
1.3 数据集构建
构建3个数据集分别用于训练目标检测模型、重识别模型和验证多目标跟踪效果。视频中的肉牛个体之间花色差别较大、姿态复杂,为了增强数据集的多样性,将有效视频分为两部分处理,第1部分使用DarkLabel进行视频标注,每10帧提取1帧加入数据集。第2部分首先使用ffmpeg进行关键帧提取,使用LabelImg进行人工标注。两部分数据集构成了肉牛目标检测数据集,最终确定了7 456幅图像作为训练集,1 491幅图像作为测试集。肉牛目标检测部分数据如图3所示。
为了提高重识别结果的准确性,首先需要通过对视频数据进行人工筛选,保证所有视频中的肉牛个体都是唯一存在的,不同视频中不能出现同一头牛,再使用DarkLabel对视频进行标注,根据标注过程中的不同标号来区分不同个体,最后按照Market-1501[31]数据集格式构建肉牛重识别数据集。肉牛重识别数据集包含99头不同肉牛的共6 195幅图像,平均每头牛约30幅图像为训练集,30幅图像为测试集。肉牛重识别数据如图4所示。
为验证本文提出的肉牛多目标跟踪方法的有效性,选取实际场景下的监控视频进行测试,视频长度为54 s,来验证本文方法追踪效果。
1.4 多目标跟踪方法
本文结合DeepSORT算法实现肉牛多目标跟踪,DeepSORT算法流程如图5所示,主要包含4个步骤:①对视频进行预处理,使用OpenCV将视频处理成视频帧,然后使用目标检测算法提取深度特征得到候选框,使用非极大值抑制(NMS)算法去除重叠框,得到最终检测结果。②使用卡尔曼滤波算法对目标在视频中下一帧的位置和状态进行预测,对比检测器提供的检测框,将置信度更高的检测框作为预测结果。③使用匈牙利算法对前后两帧之间若干目标进行最优匹配,得到目标在视频中的轨迹,其中利用重识别算法计算余弦距离来度量表观特征的距离,减少标号变化(ID switch)的发生。④输出结果,同时对跟踪器进行参数更新,重新开始目标检测。
DeepSORT算法是一个两阶段的算法,目标检测算法关系到其跟踪的准确度与速度,重识别算法可以减少跟踪过程中ID switch的发生,因此可以将其中的目标检测模型和重识别模型分别进行优化,最终得到优化后算法。
1.4.1目标检测
YOLO v3是一个比较成熟的单阶段目标检测算法,其在匹配过程中将目标图像分为S×S个格子,每个单元格负责检测中心点落于此单元格的目标,每个单元格需要预测出B个边界框,每个边界框包含5个预测输出量(x、y、w、h、conf),其中x、y为目标框中心坐标值,w、h表示边界框的长和宽,conf表示框中含有目标的可信度。若检测类别总数为C,则每个单元格需预测B×(5+C)个值。YOLO v3借鉴残差网络结构,在YOLO v2中Darknet19的基础上,通过不断堆叠3×3、1×1的卷积和残差连接构成了含53个卷积层的深度神经网络Darknet53[32]。考虑到本文采集的视频中肉牛经常处于远离摄像头位置以及YOLO v3对小目标检测的良好效果,本文采用YOLO v3作为肉牛多目标跟踪模型的目标检测模块,同时,为了提高模型在边缘设备上的运行速度,本文对YOLO v3模型进行了改进:
(1)使用MobileNet v2替换Darknet53作为YOLO v3的骨干网络。MobileNet v1利用深度可分离结构在牺牲较小检测精度的情况下,大幅降低了计算量与网络层参数,降低了模型内存。MobileNet v2在MobileNet v1的基础上,使用残差结构(图6),进行先升维、再卷积、再降维的策略,在保持计算量变化不大的情况下获得了更高的检测精度。
(2)利用长短距离语义增强模块(LSRCEM)(图7)融合YOLO v3的3个检测分支结果的同时自适应学习目标的多尺度特征。LSRCEM参考ThunderNet[33]中的CEM模块,CEM通过扩大模型感受野,融合多尺度局部信息和全局信息来获取更有鉴别力的特征。但是骨干网络中不同层所包含的语义信息并不相同,浅层网络包含物体的边缘、颜色、角点等信息;深层网络包含抽象的语义信息,然而CEM使用的特征融合方式是将各个模块的特征相加,相当于将所有层视为平等,忽略了各个层的不同,故引入长距离注意力机制和短距离注意力机制,通过两者配合来扩大模型感受野,并通过动态调整高层信息与浅层信息的分配来完成特征融合。
短距离注意力机制启发自YOLO v3-SPP中的SPP模块,在空间最大池化模块(Spatial MaxPooling Module)中,3个分支各自使用了3个13×13的池化核来进行特征提取;长距离注意力机制使用压缩激活模块(SE),将特征金字塔高层提取到的信息以相乘的方式融合到浅层网络,以深层网络的语义信息引导低层网络的语义提取。YOLO v3模型与LSRCEM-YOLO结构如图8所示。
1.4.2肉牛重识别
Mudeep模型主要由多尺度层、降维层和显著性融合层组成(图9)。多尺度层由Multi-scale-A和Multi-scale-B组成,使用多分支结构实现多尺度特征的提取,每个分支的感受野不同,提升了特征的鉴别力和多样性。降维层(Reduction)位于两个多尺度层之间,用来降低特征的空间分辨率,同时使用了多分支的方式,综合最大池化层和步长卷积以弥补由于减少层数带来的空间信息损失。显著融合层(Saliency-based learning fusion)用来融合多尺度层的输出,使用显著性的学习策略筛除多尺度层输出的冗余信息,将多尺度层的输出通过相加的方式进行融合,然后将特征图通过全局平均池化得到一个归一化后的特征向量。Mudeep通过引入空间可分离卷积,将普通的3×3卷积分解为1×3和3×1卷积,降低了模型所需的运算量,提高了模型的运算速度,且在CUHK01、CUHK03、VIPeR数据集上都有优秀的表现。
由于Mudeep相对于Wide ResNet具有更小的运算量,能够更好实现肉牛的实时跟踪,故本文选用Mudeep取代Wide ResNet作为DeepSORT中的重识别模块,通过肉牛的重识别,获取不同肉牛之间更有区分性的特征,降低跟踪过程中ID switch发生的次数。
1.5 评价指标
1.5.1目标检测评价指标
目标检测与分类任务不同,检测模型输出的结果是非结构化的,无法事先得知检测得到的物体数量、位置、大小等,因此检测任务需要引入交并比(IoU)来量化预测框A和真实框B的贴合程度,设置阈值为0.5,若IoU大于0.5,则认为正确检测,否则认为是错误检测,交并比计算公式为
(1)
式中SA∩B——预测框与真实框重叠区域面积
SA∪B——预测框与真实框覆盖区域面积
IoU——预测框与真实框的交并比
一般目标图中存在背景和目标,预测框也分为正确和错误,因此产生4种样本,真正例(True positive,TP)表示预测框与真实框正确匹配,假正例(False positive,FP)表示模型对正例进行错误分类,一般指IoU小于阈值的检测目标,假反例(False negative,FN)表示模型未检测到的真实框,真反例(True negative,TN)表示本身是背景,也未被检测出来。
根据以上4种样本,引入准确率(Precision,P)和召回率(Recall,R)来评价分类效果,准确率表示被分为正例的所有实例中真正例占比,值越大说明分类越精确;召回率表示被分为正例的实例占所有真实框的比例,值越大表示检测覆盖程度越好。然而准确率与召回率是对立的关系,若准确率提高,召回率会有一定的下降,为了平衡两者,引入准确率和召回率的调和平均数F1(F1-score)和平均检测精度(mAP)来综合衡量。以召回率为横轴,准确率为纵轴,绘制准确率-召回率(PR)曲线,则PR曲线与坐标轴围成的面积为mAP。mAP是目标检测中重要的评价标准,能够较好地评价目标检测模型。
此外,引入模型的参数量(Params)来评价模型的复杂程度,参数量越小,模型所需计算量越少,越适用于边缘设备。
1.5.2肉牛重识别评价指标
DeepSORT模型中使用的重识别模型的主要功能是用于提取具有鉴别力的特征,能够让前后两帧属于相同目标的对象相似度更高,让不同目标间的相似度降低,以降低多目标跟踪中ID switch现象的发生。Rank-n表示检测结果中置信度最高的n幅图像中有正确结果的概率,因此本文使用Rank-n作为重识别模型的评价指标。
1.5.3多目标跟踪评价指标
本文选用4个指标评价多目标跟踪效果:
(1)ID switch表示一条跟踪轨迹中改变目标标号的次数,值越小越好。
(2)多目标跟踪准确率(Multiple object tracking accuracy,MOTA),主要考虑跟踪过程中所有对象的匹配错误,主要是FP、FN、ID switch。MOTA给出的是非常直观的衡量跟踪算法在检测物体和保持轨迹时的性能,与目标检测进度无关,MOTA值越大表示模型的性能越好。MOTA计算公式为
(2)
式中AFP——假正例出现次数
AFN——假反例出现次数
MOTA——多目标跟踪准确率
AID——ID switch次数
AGT——标注的目标个数
(3)多目标跟踪精确度(Multiple object tracking precision,MOTP),用来量化检测器的定位精度,MOTP的值越大表示检测器的精度越大,计算公式为
(3)
式中ct——当前帧匹配成功的数目
di,t——检测框和真实框的交并比
i——当前检测目标
t——帧序号
MOTP——多目标跟踪精确度
(4)FPS,模型每秒处理的图像帧数,值越大处理效果越好。
2 结果与分析
2.1 目标检测结果分析与精度评价
对比YOLO v3算法、YOLO v3-tiny算法以及LSRCEM-YOLO算法在肉牛目标检测数据集上的实验结果如表1所示。
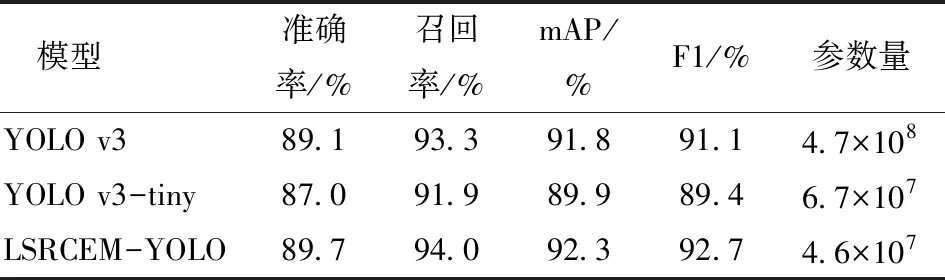
表1 不同算法的目标标检测结果对比Tab.1 Comparison of target detection results of different algorithm
LSRCEM-YOLO的mAP为92.3%,比YOLO v3高0.5个百分点,比YOLO v3-tiny高2.4个百分点,其模型参数量仅为YOLO v3的10%,为YOLO v3-tiny的68%。LSRCEM-YOLO算法不仅在性能上相较YOLO v3和YOLO v3-tiny有整体的提高,也降低了参数处理规模。
YOLO v3-tiny与LSRCEM-YOLO的mAP和损失值随迭代次数的变化情况如图10、11所示。
由mAP变化曲线可知,LSRCEM-YOLO的精度高于YOLO v3-tiny,收敛速度更快,且其mAP稳定性高于YOLO v3-tiny。
通过损失值的变化曲线可以看出,LSRCEM-YOLO的收敛速度快于YOLO v3-tiny,且收敛后的损失值小于YOLO v3-tiny。
YOLO v3-tiny和LSRCEM-YOLO在相同置信度(0.5)下进行结果对比,黄色虚线表示漏检目标(图12),漏检对象多为目标过小或者存在遮挡的情况,当目标数量变多,YOLO v3-tiny相较于LSRCEM-YOLO的检测效果变差,由于LSRCEM-YOLO选择了3个不同尺度的特征进行融合,因此其更能兼顾浅层网络关注的小目标与深层网络关注的大目标。
实验结果表明,LSRCEM-YOLO算法兼顾速度与精度,适用于肉牛目标检测。
2.2 肉牛重识别结果分析与精度评价
Mudeep模型对相同或不同个体肉牛的识别结果进行可视化(图13),若是同一目标,热图集中于需要关注的区别于其他肉牛的特征信息。若是不同目标,模型通过关注不同肉牛之间的表观特征如花纹等,从而区别出特征信息属于不同个体。说明Mudeep模型可以动态学习不同尺度、不同位置的有区分度的特征,自动聚焦于不同目标之间最有区分度的区域。
Mudeep重识别模型的Rank-1、Rank-5、Rank-10达到96.5%、98.6%、99.1%,具备提取到具有高鉴别力特征的能力。
训练后的Mudeep模型参数量为3.5×106,远小于Wide ResNet模型的参数量4.4×107。
2.3 多目标跟踪结果分析与精度评价
为验证本文方法在肉牛多目标跟踪方面的表现,在肉牛多目标跟踪数据集上进行了测试,并将结果与YOLO v3-DeepSORT算法进行了对比,结果如表2所示。
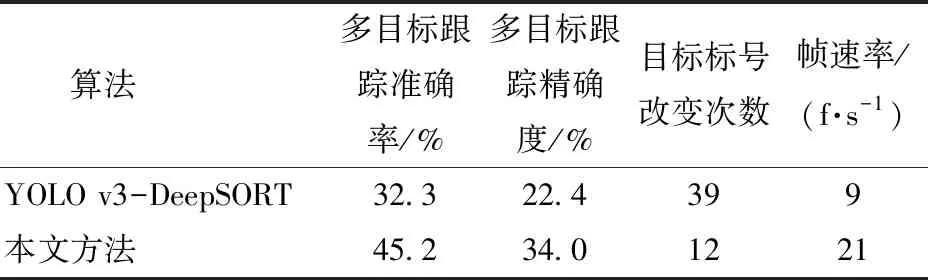
表2 本文方法与YOLO v3-DeepSORT实验 结果对比Tab.2 Experimental results of this algorithm compared with YOLO v3-DeepSORT
由表2可知,本文方法的多目标跟踪准确率为45.2%,较YOLO v3-DeepSORT算法提高了12.9个百分点,多目标跟踪精确度提高了11.6个百分点,目标标号改变次数降低了69.2%,视频处理速度也由9 f/s提高到了21 f/s。
将同一视频片段用两种不同算法进行跟踪,结果如图14所示。黄色虚线框为YOLO v3-DeepSORT漏检目标,可以看出,相较于YOLO v3-DeepSORT算法,本文方法的漏检目标明显较少,检测框更加贴合肉牛目标,对于遮挡度高的肉牛有更好的检测跟踪能力。
3 结论
(1)在YOLO v3模型的基础上,将模型的骨干网络Darknet53替换为MobileNet v2,并增加长短距离语义增强模块(LSRCEM),提出了基于LSRCEM-YOLO的肉牛多目标跟踪方法。
(2)本文方法目标检测的mAP值达92.3%,采用Mudeep模型的肉牛重识别Rank-1指标为96.5%,多目标跟踪准确率提高到了45.2%,目标标号改变次数降低了69.2%。
(3)构建的融合了LSRCEM-YOLO和Mudeep模型的DeepSORT肉牛多目标跟踪模型能够实现实际养殖环境下的肉牛多目标实时跟踪,可为实现肉牛大规模养殖的精准管理提供良好的技术支持。
猜你喜欢
今日农业(2022年2期)2022-11-16 12:29:47
今日农业(2022年1期)2022-06-01 06:17:58
今日农业(2021年21期)2021-11-26 05:07:00
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
中国交通信息化(2018年5期)2018-08-21 03:37:40
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
