
推荐系统中的隐私保护矩阵分解算法研究
2021-05-14 03:58崔炜荣徐龙华杜承烈
计算机应用与软件 2021年5期
崔炜荣 徐龙华 杜承烈 李 宝
1(安康学院电子与信息工程学院 陕西 安康 725000) 2(西北工业大学计算机学院 陕西 西安 710072)
0 引 言
当今社会,互联网中的各类信息都在以难以预知的速率爆炸式地增长,人类社会也随之从“信息匮乏”状态步入到“信息过载”状态。越来越多的用户在超过其处理能力的大量信息面前显得无所适从,很容易迷失在信息的海洋中。为了解决“信息过载”这一问题,使得用户可以在海量的数据中快速、准确地得到有用的信息,推荐系统应运而生。推荐系统能够根据用户的历史行为构建模型,预测用户对特定物品的态度并根据其预测向用户进行推荐。在推荐算法不断成熟和推荐系统被广泛应用的同时,其面临的隐私安全问题也日益凸显[1]。本质上,为了获得满意的推荐服务,用户需要向推荐系统提供个人信息。因此,相比其他网络信息服务,推荐系统更加具有天然的隐私不友好性。推荐系统面临的隐私安全风险主要在于:(1) 服务提供商可以直接利用用户所提交的数据获得用户的个人信息,从而确认用户的身份、兴趣爱好等敏感信息;(2) 由于推荐系统所收集的数据的稀疏特性,利用推荐系统发布的聚合数据,攻击者可以有效推测出用户的敏感信息[1-2]。在如今人们越来越关心个人隐私安全的大背景下,如何在保证可用性的前提下引入合理的隐私保护机制也成为了有关推荐系统研究的热点问题。
当前,基于矩阵分解的协同过滤(Matrix Factorization Collaborative Filtering,MFCF)[3]是最为主流的推荐算法,该类算法从用户-物品评分矩阵中挖掘出潜在的用户特征向量及物品特征向量,并通过向量相似度预测用户对物品的评价。相比其他方法,MFCF方法能够提供更高的预测准确度、更快的计算效率,以及更高的可扩展性。
本文针对MFCF推荐系统中的隐私保护问题展开研究, 提出一种基于分布式计算架构和梯度混淆的隐私矩阵分解算法,称之为DGCMF(Distributed Gradient Confusion Matrix Factorzation)。与现有的隐私保护MFCF方法相比,DGCMF不仅可以防止用户评分和模型泄露,还可以防止用户“评价行为”是否存在这一信息的泄露,从而为用户隐私提供更强有力的保障。
1 相关工作
在先前的研究中,在推荐系统中增强隐私保护的方式主要分为以下三类:
1) 混淆和扰动。该方式通过在用户数据中增加伪造值以达到隐藏真实用户数据的目的。文献[4-5]中所提出的隐私保护推荐算法均基于该方式构建,使得用户可以对数据在本地进行加扰,从而对服务器隐藏真实的数据。但上述方法主要的问题在于:从安全性角度,上述加扰效果并未得到严格证明;从可用性角度上,上述方法在增强隐私保护的同时较大地牺牲了系统的推荐准确度。
2) 差分隐私。差分隐私保护的本质也是通过在计算过程中引入特定分布的噪声以达到保护原始数据的效果。但与简单的混淆和扰动不同,差分隐私保护可以提供能被度量和证明的隐私保障。文献[6]首次将差分隐私保护的概念引入了推荐系统,随后多项研究在其基础上展开[7-11]。
3) 同态加密。同态加密技术可以使得用户在不必解密的情况下对密文内容进行计算,被广泛应用于各类隐私保护场景中。文献[11-13]所设计的推荐系统均基于同态加密技术方案实现了隐私保护。使用同态加密最大的障碍在于其相对较高的计算开销。特别是当数据量较大时,效率和能耗成为限制其可用性的关键因素。
上述文献中的方法主要针对用户评分和推荐模型的保护。然而,它们共同缺乏的是对“存在性”的保护。也就是说,即便是无法得知用户的具体评分,服务器也依然可以在与用户的交互计算过程中知道用户对哪些物品进行了评价。利用这些信息,服务器仍然可以推测出用户的偏好、个人特征等隐私信息。与上述方法相比,本文方法除了能够实现对用户数据以及模型的保护外,也能够实现对用户评分“存在性”的保护。
与本文最为相似的工作来自文献[14],作者提出了名为SDMF的隐私保护矩阵分解方法。SDMF通过在梯度更新过程中引入随机响应机制实现对用户评分、模型、存在性的保护。然而,这种方法在梯度下降优化过程中造成梯度更新损失,降低了所生成模型的预测准确性。与之相比,DGCMF中的梯度混淆是无损的,因此既能够有效保护用户隐私,也能够保证系统的推荐准确性。
2 系统模型与问题描述
2.1 系统模型与假设

图1 系统模型
2.2 隐私保护需求
本文算法应满足如下隐私保护需求:
2) 评分保护:在模型的计算过程中,服务器无法获知每个用户的历史评分。
3) 存在性保护:在模型的计算过程中,服务器无法获知用户是否对某个物品作出评分。
3 算法设计
3.1 总体设计
本文算法实现了分布式架构下的贝叶斯概率矩阵分解。算法架构如图2所示,主要符号及其含义见表1。

图2 算法框图

表1 主要符号及含义

计算过程由初始化和迭代优化两部分组成。客户端和服务器端分别对W和H完成初始化后便进入迭代优化环节。本文算法采用了SGLD(Stochastic Gradient Langevin Dynamics)优化算法。SGLD所增加的高斯噪声为系统引入了差分隐私保障,能够有效防止模型泄露。
在迭代优化环节的每一轮迭代过程中,每一个用户ui首先从服务器端下载更新后的H,之后根据自己的评分数据ri计算和wi每一个hj(rij≠∅)的更新梯度grad(wi)和grad(hj)。接着,ui利用grad(wi)对wi进行更新。对grad(hj)进行梯度混淆后将其发送至服务器端。服务器收到每一个用户发来的梯度更新信息后,将其聚合并最终更新H。
由于每轮迭代中,服务器只收到用户发来的物品隐藏因子向量梯度信息,从而防止了用户评分泄露。梯度混淆的加入进一步隐藏了梯度信息中用户和被评分物品的联系,实现了“存在性”保护。
3.2 梯度更新算法
p(W,H|R,λr,Λw,Λh)∝
p(R|W,H,λr)p(W|Λw)p(H|Λh)
(1)
式中:λr为全局正则化参数,Λw和Λh是基于Gamma分布生成的对角矩阵,用于隐藏因子向量wi和hj的正则化处理。采用正态分布假设,则式(1)的对数形式为:
F(W,H)=lnp(R,λr,Λw,Λh)=
lnp(R|W,H,λr)+lnp(W|Λw)+
lnp(H|Λh)+C=
(2)
式中:C为常数;N表示正态分布。为了求得W和H的最大后验估计,本文采用SGLD优化算法进行迭代求解。具体而言,在第t次迭代中:
(3)
(4)
(5)

(6)

(7)
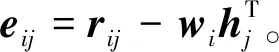
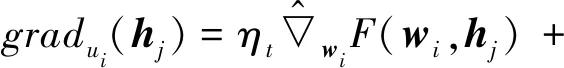
(8)
用户ui发送gradui(hj)至服务器。由于服务器仅得知梯度信息,因此防止了用户隐藏因子向量的泄露。
3.3 梯度混淆算法
采用上述架构,虽然在迭代优化过程中服务器仅能从客户端得到H的加扰梯度更新信息且无法从中推断出用户的隐藏因子向量,然而服务器依然可以根据这些信息获知用户对哪些物品进行了评价。例如当服务器收到来自用户ui的梯度更新信息gradui(hj)时,根据hj和物品vj的对应关系,可知用户ui一定对vj进行了评价。为了避免这种“存在性”用户信息泄露,本文基于安全求和思想设计了梯度混淆过程。
在梯度混淆的过程中,对于每一个计算出的梯度更新信息gradu(hj),用户u以一定概率选择将其值发送给随机选取的另一用户,并随后将其置零。收到gradu(hj)的用户u′将其与自身的gradu′(hj)相加。举例而言,假设用户u计算出的梯度值分别为gradu(hj1),gradu(hj2),…,gradu(hjq),SG为空集,则u依据算法1实施混淆。
算法1梯度混淆
fort=j1tojq
据概率f选取gradu(ht)
ifgradu(ht)被选中then
SG←SG∪{gradu(ht)}
gradu(ht)←0
end if
end for
经过上述的梯度混淆处理后,u将筛选出来的梯度更新值集合SG发送给随机选取的用户u′。收到SG后,对于每一个gradu(hj)∈SG,u′将其与自身的对应梯度更新值进行合并,即计算混淆梯度:
(9)
图3描述了这一个过程。其中行向量表示用户在第t次迭代过程中所计算并分解的梯度更新信息。值为0表示用户并未对hj进行过单类评价。曲线箭头表示以一定的概率选取并发送。以u2为例,在该轮迭代中,其根据概率fu2选取了梯度更新值gradu2(h1),并将其发送至随机选取的用户u1。同时,u1根据概率fu1选取了梯度更新值gradu1(h3),将其发送给u2。u3根据概率fu3选取了梯度更新值gradu3(h2),也将其发送给了u2。最终,u2生成混淆梯度(0,gradu3(h2),gradu2(h2)+gradu1(h3),0)。每轮迭代完成后,u2将混淆后的梯度更新值发送至服务器。
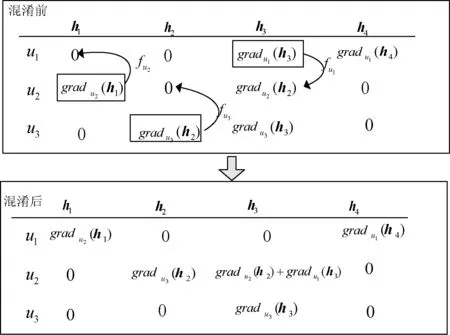
图3 梯度混淆过程
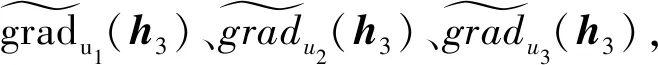
(10)
h3=h3+grad(h3)
(11)
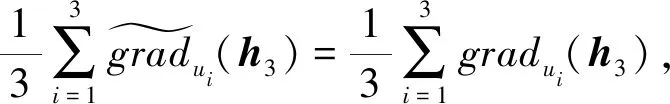
3.4 算法流程
基于分布式架构,本文算法由客户端算法client(u,t)和服务器端算法server两部分组成,流程分别如算法2和算法3所示。
算法2client(u,t)
输入:Ri,η0,r,Λw,Λh。
1. ift=0 then初始化wi
2. ift>0 then
3. 从服务器下载H
5.count▽u←0
//count▽u用来对值不为0的Rij进行计数
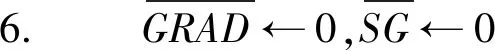
9. ifR≠0 then

11.count←count+1
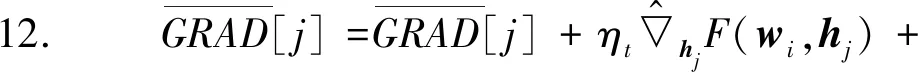
13. end if
14. end for
16. 生成概率参数f∈[0,1]
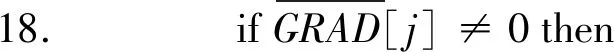
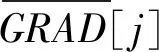

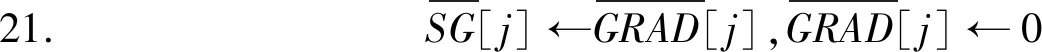
22. end if
23. end if
24. end for
26. for每一个收到的来自其他用户的SG:

29. end for
30. end for
32. end if
算法2中,用户首先更新了学习速率(第7行);接着根据评分向量Rij、wi和H计算出wi的更新梯度和被评分物品对应的hj的更新梯度(第8至14行);之后更新wi(第15行)并进行梯度混淆(第16至29行);最后将经过混淆的梯度值发送给服务器(第31行)。
算法3server
输出:物品隐藏因子矩阵H。
1. 初始化H
2.t←0

4. 远程调用client(ui,t)
5. end for
6.t←1
7. while 没有收敛 do:
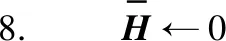

11. 远程调用client(ui,t)
12. end for
13. while Ture do:
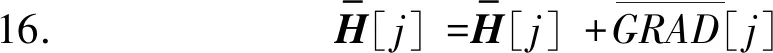
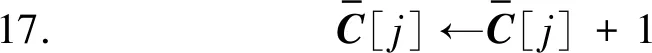
18. end for
20. break
21. end if
21. end while
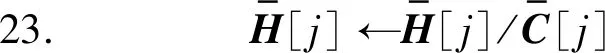
24. end for
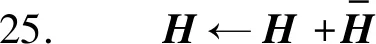
26.t←t+1
27. end while
算法3中,服务器在初始化H之后,远程启动每个客户端的初始化过程(第1至5行)。之后进入迭代优化环节。在每轮迭代中,首先下发H并调用客户端的梯度更新方法(第10至12行)。待全部用户完成更新计算并回传物品隐藏因子向量梯度更新值后,对其进行聚合并完成H的更新(第13至25行)。
4 安全性分析
根据2.2节所述,本文算法应当满足模型、评分和存在性三方面的隐私保护需求。
4.1 模型保护
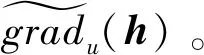
4.2 评分保护
与采用集中式架构的MF算法不同,在本文中,作为最为重要的隐私数据的用户历史评分并没有被服务器所收集,而是分别被保存在各个客户端。在迭代计算过程中,用户ui的历史评分ri只参与了预测误差eij的计算,且服务器无法从接收到的混淆梯度更新信息中推导出ri。根据以上分析,在模型的计算过程中,服务器无法获知每个用户的历史评分。
4.3 存在性保护
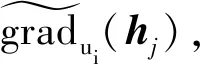
此外,由于每一个用户在每一轮迭代末都依据实时随机生成的选择概率f进行了混淆(算法2第16行)。因此服务器无法从所收集的用户梯度更新值序列中推测出用户是否对某一物品进行过评价,从而实现了存在性保护。
5 实 验
在算法2和算法3的基础上,使用Python开发了系统原型。为了评估系统的可用性,将其与文献[15]中提出的SDMF方法进行了对比。
5.1 原型构造方法
协议原型基于Python3.6+TensorFlow2.0开发,主要由Server类和User类组成,Sever类是对服务器的模拟,其中主要包含的属性有物品隐藏因子矩阵H,主要包含的方法有聚合梯度更新(针对H)。User类是对用户的模拟,其中主要包含的属性有用户ID、评分向量r和隐藏因子向量w,主要包含的方法有梯度更新和梯度混淆方法。梯度更新方法中调用了TensorFlow框架Stochastic Gradient Langevin Dynamics模块实现SGLD优化过程。
模拟运行的每一轮迭代中,服务器实例依照算法3依次调用每一个用户实例的梯度更新方法。每一个用户实例依照算法2进行w梯度更新,并将经过混淆后的h梯度传回给服务器实例,由服务器实例进行聚合并调用梯度更新方法更新H。
5.2 数据集及实验方法
使用了3个公共评分数据集进行实验,具体包括:两个MovieLens数据集(ML-100K和ML-1M),一个Netflix数据子集(包含10 000个用户和5 000个物品)[16]针对上述每一个数据集,将其随机划分为占比80%的训练集和占比20%的测试集,训练集中的20%作为验证集。具体的超参数设置为:k=50,r=0.6,(Λw,Λh)~Gamma(1,100)。初始学习速率η0分别为5×10-6(ML-100K)、5×10-7(ML-1M)、5×10-7(Netflix)。对于SDMF,选取了(εI=0.25,εg=4)和(εI=0.25,εg=1)作为两组差分隐私配置参数。
5.3 结果及分析
在ML-100K、ML-1M和Netfilx数据集上的学习曲线如图4所示。
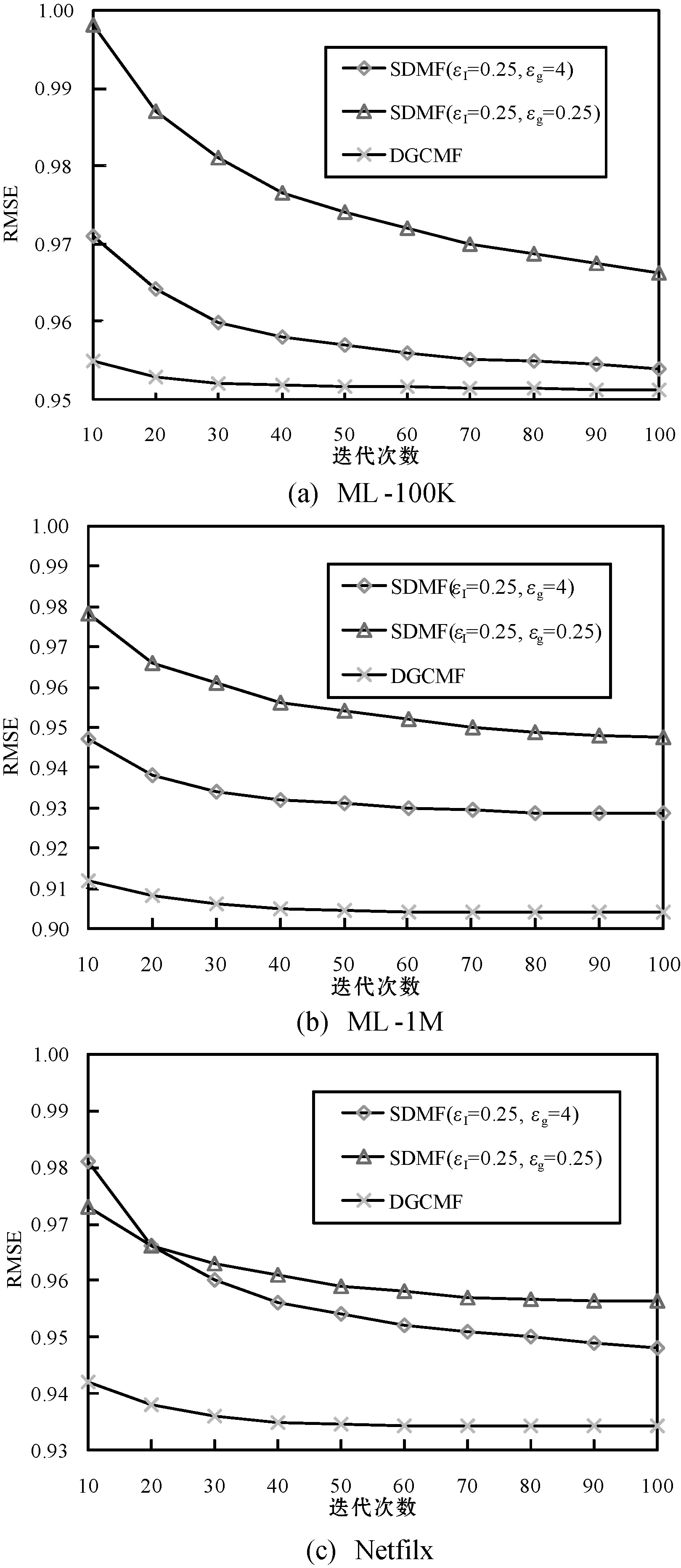
图4 实验结果
可以清楚地看到,对于SDMF而言,参数ε值越小,则系统可以提供越强的差分隐私保障,但其预测准确度就越低。此外,尽管SDMF和DGCMF都可以实现模型保护、用户评分保护和存在性保护,但可以看出,DGCMF所生成的模型预测准确性明显高于SDMF所生成的模型。这是由于本文所设计的DGCMF和SDMF在存在性保护方面采取了不同的混淆机制。SDMF采用基于随机响应的方式模糊用户的评价行为。在每轮迭代中,用户根据一定的概率设定,选择是否计算某一已打分物品的隐藏因子向量梯度。此外,用户还有可能伪造未打分物品的隐藏因子向量梯度。这种混淆方式本质上是有损的,因此会对系统的准确性造成负影响。而DGCMF所采用的方式能够在隐藏“存在性”的同时确保其混淆行为是无损的,从而在实现隐私保护的同时最大限度地保障推荐准确度。
6 结 语
针对协同过滤推荐系统中的隐私保护问题,本文设计DGCMF算法。在DGCMF中,矩阵分解过程由各个客户端和服务器共同配合完成。由于服务器只能收到来自客户端的物品隐藏因子向量梯度,从而避免了用户评分和模型的泄露。此外,客户端对所要上传给服务器的梯度更新信息进行了混淆,实现了对用户评分“存在性”的保护。与现有方法相比,DGCMF的梯度混淆过程不会造成梯度更新损失,在实现隐私保护的同时能够提供更好的推荐准确度。今后,将针对如何进一步提高模型的准确度和生成效率展开研究,以期在安全性和效率两方面达到更优的权衡。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
中国计算机报(2018年12期)2018-10-08
中学生数理化·高三版(2016年9期)2016-05-14
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
网络与信息(2009年4期)2009-04-26
