
基于多特征融合的行人检测方法
2021-05-12 13:47李菲菲
电子科技 2021年5期
顾 伟,李菲菲,陈 虬
(上海理工大学 光电信息与计算机工程学院,上海 200093)
行人检测作为一个典型的目标检测问题,是近年来研究的热点。行人检测被广泛应用于智能交通、自动驾驶、视频监控、行为分析等领域。行人检测的目的是利用计算机视觉技术判断图像或视频序列中是否存在行人并给予精确定位。目前,大部分行人检测方法将行人检测问题作为一个二分类问题,即判断目标图像中的所有候选窗口是否为行人,然后进行非极大值抑制。
目前行人检测方法大致可以分为两大类:传统的机器学习方法和深度学习方法。传统的机器学习特征是手工设计的特征,包括提取特征和使用分类器进行分类两个步骤。但是在行人检测任务中,与分类器的选择相比,特征的选择更为重要。为了克服行人身体的形变性以及行人的外观容易受到姿势、穿着、光照变化和背景影响等问题,研究人员分别使用图像的轮廓、纹理和颜色特征完成行人检测任务。因此,Haar-like[1]、方向梯度直方图(Histogram of Oriented Gradient,HOG)[2]、Shapelet[3]、本地二进制模式(Local Binary Pattern,LBP)[4]、颜色自相似性特征 (Color Self Similarities,CSS)[5]与积分通道特征(Integral Channel Feature,ICF)[6]等特征成为了行人检测任务中较为常见的机器学习特征。由于上述特征在行人检测中具有良好表现,研究者在原有特征的基础上提出了FHOG(Felzenszwalb HOG)[7]、本地三单元模式(Local Ternary Pattern,LTP)[8]、有效局部二进制模式(Significant Local Binary Pattern,SLBP)[9]、聚合通道特征(Aggregate Channel Feature,ACF)[10]、局部去相关通道特征(Locally Decorrelated Channel Feature,LDCF)[11]以及过滤通道特征(Filtered Channel Features,FCF)[12]等特征。
近年来,深度学习尤其是卷积神经网络在人脸识别、图像分类、行人检测等领域表现出较强的优势受到研究者的广泛关注[13-16]。早期卷积神经网络的结构比较简单,例如经典的LeNet-5模型[17],主要用于手写体识别和图像分类。手写体识别和图像分类是相对单一的计算机视觉应用。随着研究的不断深入,特别是在2012年ILSVRC比赛中AlexNet模型[18]以远远超过第二名的识别率获得冠军后,卷积神经网络的应用领域逐渐扩大。卷积神经网络作为一种深度学习方法,通过建立深度神经网络而不是人工设计特征来模拟人脑的学习过程。该方法改变了传统的机器学习且能够独立提取特征,达到了减少人工干预的目的。卷积神经网络接受灰度图像或彩色图像作为神经网络的输入,具有连续的卷积层和可训练的权重。每个卷积层可以建立多个特征图,通过不同的卷积核可得到不同特征的不同描述。
本文在传统的卷积神经网络模型VGG19模型的基础上,提出了一种结合传统机器学习特征和深度学习特征的行人检测模型—多通道特征模型。多通道特征模型由3个分支组成:非深度学习分支、整体分支和肢体分支。其中整体分支以及肢体分支是通过多层卷积通道特征得到的。为了通过有效的搜索方法来减轻使用卷积神经网络滑动窗口穷举搜索带来的计算负担,并提高计算效率,本文使用了非深度学习分支。本文在多层卷积通道特征之前级联了目前最先进的非深度学习行人检测器之一的LDCF行人检测器。多层卷积通道特征将传统的通道特征方法从基于HOG+LUV的特征扩展到卷积特征映射,以有限的计算量增长为代价获得性能提升。同时,由于不同层的特性不同,这些层可以提供更丰富的特征提取。并且在多层卷积通道特征中利用两个分支分别通过人体整体信息和人体部位的语义信息来检测行人。在肢体分支中,肢体的语义信息可以通过长短时记忆网络(Long Short-Term Memory,LSTM)[23]相互通信。结合各分支的输出,本文开发了一种强互补的行人检测器。该检测器具有较低的漏检率和较高的定位精度,尤其适用于行人形变以及遮挡行人等情况下的检测。
1 相关研究
近年来在行人检测方法的研究中,在传统的机器学习特征方面HOG[2]、LBP[3]等特征起着非常重要的作用,尤其是方向梯度直方图特征(HOG)[2]。HOG法利用图像的局部方差来检测行人,并使用线性支持向量机分类器达到了很好的分类效果。研究人员在HOG的基础上通过级联AdaBoost分类器,提出了ICF[6]。积分通道特征的具体过程如下:首从原始的RGB图像中提取6个方向的HOG特征通道和LUV颜色通道;然后利用6个方向的HOG特征通道和LUV颜色通道训练AdaBoost分类器。为了进一步加快检测速度,研究人员提出了ACF[10],该方法可将图像通道的采样率降低4倍。由于通道特征在行人检测的优秀表现,研究者们在ICF[6]之后,还提出了LDCF[11]、FCF[12]。LDCF[11]在ACF[10]的基础上提出,其通过将pca-like滤波器与HOG+LUV图像通道进行卷积计算去相关通道特征。FCF[12]在HOG+LUV图像通道的基础上卷积过滤器 (例如随机过滤器、棋盘格过滤器等)来生成候选特征池。结果表明,使用简单的棋盘格过滤器就可以获得很好的性能。ICF[6]、ACF[10]、LDCF[11]以及FCF[12]都使用相同的图像通道(即HOG+LUV)作为图像通道。
基于深度卷积神经网络(Convolutional Neural Network,CNN)的方法在行人检测方面[13-16]也取得了很大的成功。CNN模型的两个特性在它的成功中发挥了关键作用:(1)特征表示是通过分层方式习得的,其代表能力随卷积层深度的增加而增强;(2)CNN特征具有良好的泛化能力。具体地说,深度CNN特征可以在不进行微调的情况下转移到一般的识别任务中。一般来说,使用卷积神经网络进行检测首先需要生成候选对象窗口,然后使用训练好的CNN模型对这些窗口进行分类。文献[19]使用基于手工特征的方法提取候选行人建议窗口,然后将广义CNN模型例如AlexNet以及ImageNet等用于行人检测。使用手工特征例如边缘特征[20]提取候选行人建议窗口在计算效率方面是十分有效的。文献[15]使用最先进的非深度学习分类器提取候选行人建议窗口,减少了候选行人建议窗口,在减小计算量的同时提高了检测精度。文献[21]通过引入与检测网络共享全图像卷积特性的区域建议网络(Region Proposal Network,RPN),提出了Faster R-CNN。RPN是一个全卷积网络,其经过端到端训练能够快速生成高质量的区域建议窗口,并能够同时预测每个位置的对象边界和对象得分。尽管基于CNN的行人检测取得了成功,但仍有一定的改进空间:首先,通过利用行人建议窗口的得分信息来提高检测性能;其次,CNN的每一层都包含一些判别特征。本文在通道特征的基础上将手工制作的通道特征替换为不同层的卷积通道特征。目前已经有一些作品尝试将CNN与流行的通道特征联系起来,例如卷积通道特征(Convolutional Channel Features,CCF)[21]。CCF将预训练的CNN模型作为低层特征提取器,并且使用决策树作为分类器。卷积通道特征结合了CNN的特征,传统的通道特征相比,CCF具有更丰富的特征表示能力。然而卷积通道特征仅仅使用了一层低层卷积特征,忽略了CNN的每一层都包含一些判别特征尤其是CNN的深层卷积特征。此外,卷积通道特征并没有使用通道特征快速的拒绝非行人检测窗口,这样会增加卷积通道特征方法的计算量。
2 多通道特征模型
本文在多特征融合的基础上提出了一个多通道特征模型。多通道特征模型由非深度学习分支、整体分支以及肢体分支组成。为了通过有效的搜索方法减轻滑动窗口穷举搜索带来的计算负担,提高计算效率,该模型使用了非深度学习分支。该模型所使用的非深度学习分支是LDCF行人检测器。与仅仅使用LDCF行人检测器完成行人检测任务不同的是,本文在整体分支以及肢体分支之前级联LDCF行人检测器的目的是提供高质量的行人候选窗口,而不是最终的行人检测结果。因此,本文将行人检测的得分值稍稍降低,即可得到更多的高质量行人候选窗口,而在整体分支以及肢体分支中则使用是多层卷积通道特征。多层卷积通道特征将传统的通道特征方法从基于HOG+LUV的特征扩展到卷积特征映射,以有限的计算量增长为代价获得性能提升。由于不同层的特性不同,这些层可以提供更丰富的特征提取。在多层卷积通道特征中本文分别利用两个分支分别通过人体整体信息和人体部位的语义信息来检测行人,其中肢体分支可以认为是对于遮挡或者形变行人的再次检测。因此,在肢体分支中,我们将一个行人候选窗口分为有重叠的3×3的区域,分别为左肩、头、右肩、左臂、躯干、右臂、左腿、膝盖以及右腿。在肢体分支中,我们将肢体的语义信息通过LSTM相互通信。在肢体分支中即使由于遮挡或者行人自身的形变导致行人某个部位的得分值很低也可以通过其他部位的得分值去增加此部分的得分值,从而让行人候选窗口有更高的得分值。因此,结合各分支的输出,本文开发的是一种强互补的行人检测器,它具有较低的漏检率和较高的定位精度,适用于行人形变以及遮挡行人。本文所使用的多通道特征模型示意图如图1所示。
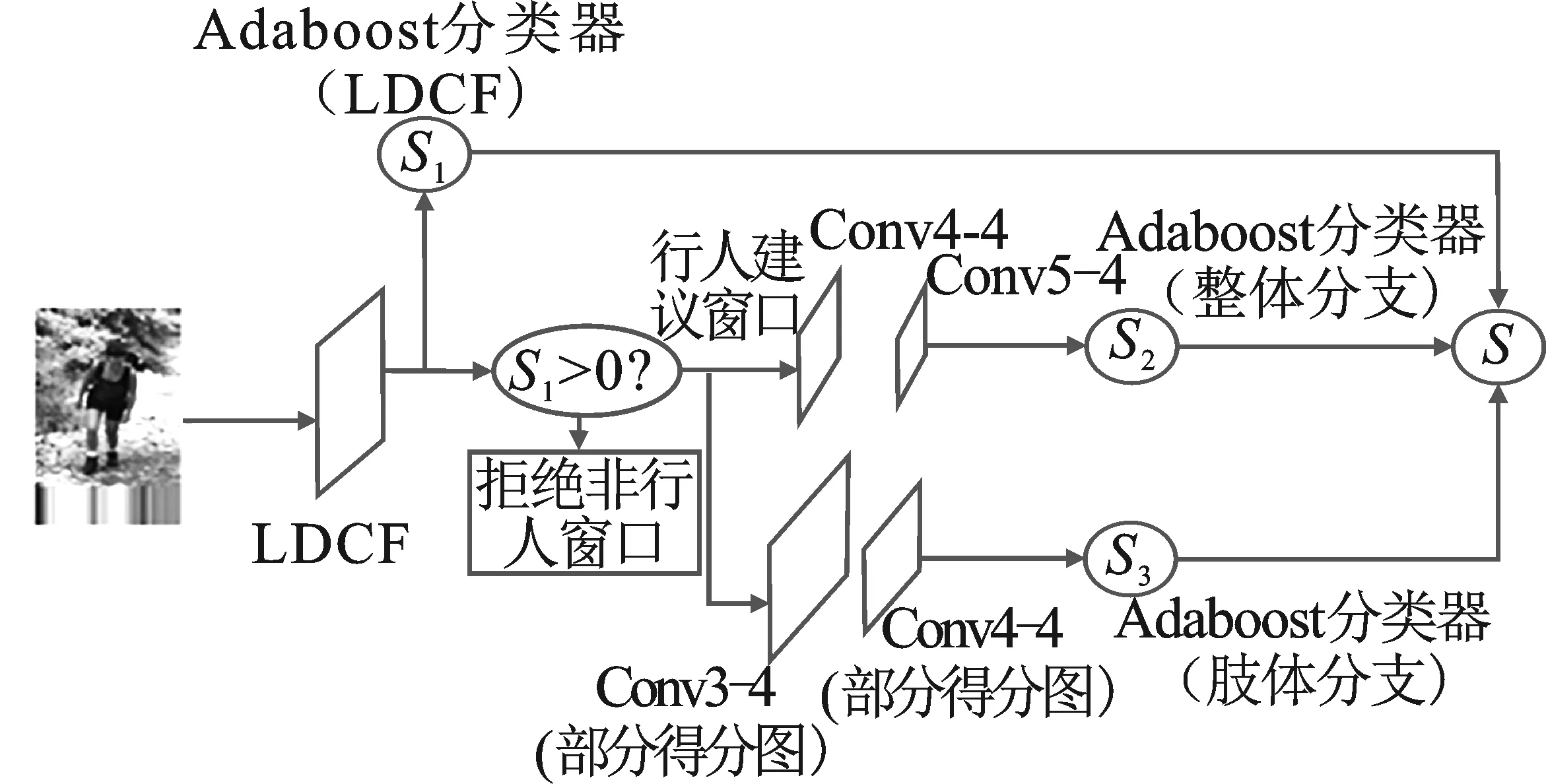
图1 多通道特征模型
2.1 整体分支
整体分支由卷积特征提取部分和AdaBoost分类器两部分组成。在卷积特征提取部分,由于较大的过滤器会丢失局部线索(例如,Edge Boxes[20]),使得卷积特征提取部分更适合表示整个图像而不是小块图像。因此,本文选择与卷积通道特征相同的预训练的VGG19模型作为卷积通道特征的提取器。在整体分支的卷积特征提取部分,本文通过从ImageNet数据集中预训练的VGG19网络中提取多层卷积通道特征。多层卷积通道特征将传统的通道特征方法从基于HOG+LUV的特征扩展到多层卷积特征映射,以有限的计算量增长为代价获得性能提升。虽然在仅选用某一层卷积特征作为通道特征中的卷积特征已经达到了很好的特征表示,但是由于不同卷积层的特性不同,与仅使用某一层卷积特征,或者某一部分相似的卷积特征相比,使用多层大跨度的卷积特征可以提供更丰富的特征表示。由于在不同层的卷积特征图大小并不一致,所以本文选择在不同尺寸的特征图中使用规定区域内像素求和的方法提取卷积特征。在整体分支的AdaBoost分类器部分,本文采用1 000个深度为2的决策树作为弱分类器。本文在INRIA数据库中利用非深度学习分支和整体分支检测行人,得到了表1中的数据。根据表1中的数据,最终在整体分支中选择了Conv4-4和Conv5-4作为整体分支的多卷积通道特征。

表1 整体分支中使用不同卷积通道效果对比
2.2 肢体分支
肢体分支主要由两个部分组成:行人肢体得分图生成部分和使用LSTM进行肢体得分图通信部分,详细信息如图2所示。
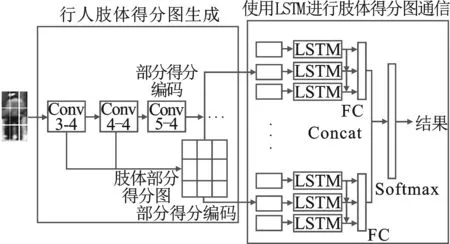
图2 肢体分支原理图
行人图像中的遮挡问题以及姿势形变是行人检测中重要的问题。因此本文在多通道特征模型的基础上提出了由部分检测器组成的具有语义信息的行人肢体得分图,并且利用语义信息进行相互通信来解决这个问题。部件检测器可以看作是使用分类器得到的部件网格特征,它将决定是否应该将肢体信息不明确的候选窗口检测为行人的窗口。如图3所示,行人候选框被分为了几个部分网格,且对于每个部分网格使用一个分类器检测获得一个检测分数。部分检测器的所有置信度得分集合成肢体得分图。因此,肢体得分图可以显示肢体的语义信息,并可估计肢体的可见性。该模型需要将卷积特征分成几个部分网格,而Conv5-4由于特征图较小无法提供丰富的特征表示,因此本文利用卷积层Conv3-3和Conv4-3得到一个大小为3×3的肢体得分图。肢体得分图具有较强的行人语义信息,例如右上角的网格表示右肩-头部分,并且使用肢体得分图进行下一步通信。
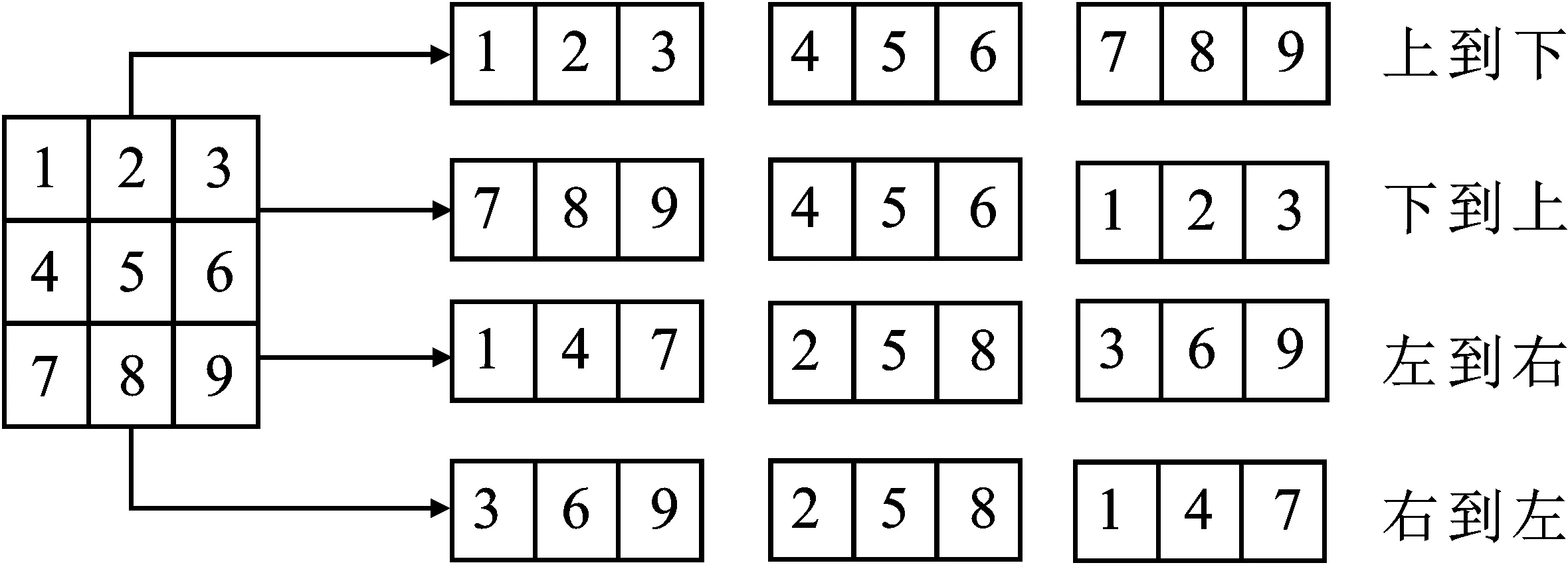
图4 肢体分支得分编码
LSTM进行肢体得分图通信部分如图4所示,为了得到不同的肢体语义信息进行通信,本文对肢体部分得分图进行了排序。本文将肢体部分得分图输入LSTM时分别沿着左、右、上、下4个方向移动肢体部分得分图,对部件得分进行编码,并进行语义交流。这样就可以通过语义信息降低肢体得分较低部分的影响。例如,当右手被遮挡或者姿势的严重形变导致相应的部位得分很低。然而,右肩和身体中间可见的部分可以传递信息来支持右手的存在。因此,身体部位的评分可以通过这种复杂的信息交流来提高。
3 实验验证
3.1 数据集
3.1.1 INRIA数据集
INRIA行人数据集由文献[1]提出,包含有正样本2 416个和负样本1 218个。由于INRIA数据集中负样本与正样本在图片大小上存在着巨大的差距,为了使INRIA数据集更适合多通道特征的训练,本文在训练集的负样本中随机裁剪10个128×64像素的图像作为训练集的负样本,并且使用训练好的LDCF进行检测提取困难样本,故本文使用训练集中负样本的个数是12 326个。测试集包含了589个行人的288张大尺寸图片。
3.1.2 Caltech行人数据集
加州理工学院的数据集是目前最流行的行人检测数据集,其由大约10小时的视频(大小为640×480像素)组成。这些视频是从一辆行驶在正常城市交通中的汽车上拍摄的。该数据集包含11个视频序列,每个视频序列的大小约为1 GB。数据集中共有35万个边界框,约2 300个不同的行人。注释包括边界框和详细的遮挡标签。将前6个视频序列作为训练集,最后5个视频序列作为测试集,并且在数据集中每30帧取一次。因此在Caltech行人数据集中训练集共有4 250幅图像,测试集中共有4 024幅图像。本文利用这些图像进行漏检率(Miss Rate,MR)评价。
3.2 实验结果与分析
为验证本文算法对行人检测的准确率与可靠性,本文分别INRIA和Caltech行人数据集中将本文算法与传统经典算法VJ[24]、HOG[1]、ACF[10]、LDCF[11]、SPatialPooling[25]和SCCPriors[26]等多种行人检测算法进行检测性能比较,并采用ROC(Receiver Operating Characteristic,ROC)曲线作为评估协议。ROC曲线的纵坐标为漏检率,即没有检测出的行人占行人总数的比重;横坐标为误检率,即每张图片中被误判为行人的数目。除此以外,本文使用和文献[27]中相同的评估方法,通过使用不同算法的实际检测对比图来证明本文所提出方法的有效性。图5显示了INRIA数据集上的检测结果,由图可知本文所开发的多通道特征模型的误检率一直低于其他的算法。此外,在误检率为0.1也就是每10张图片会出现一个误检窗口的情况下,本文的多通道特征模型的漏检率为8.24%,与仅使用LDCF相比降低了5.55%,与其他算法相比也有明显降低。
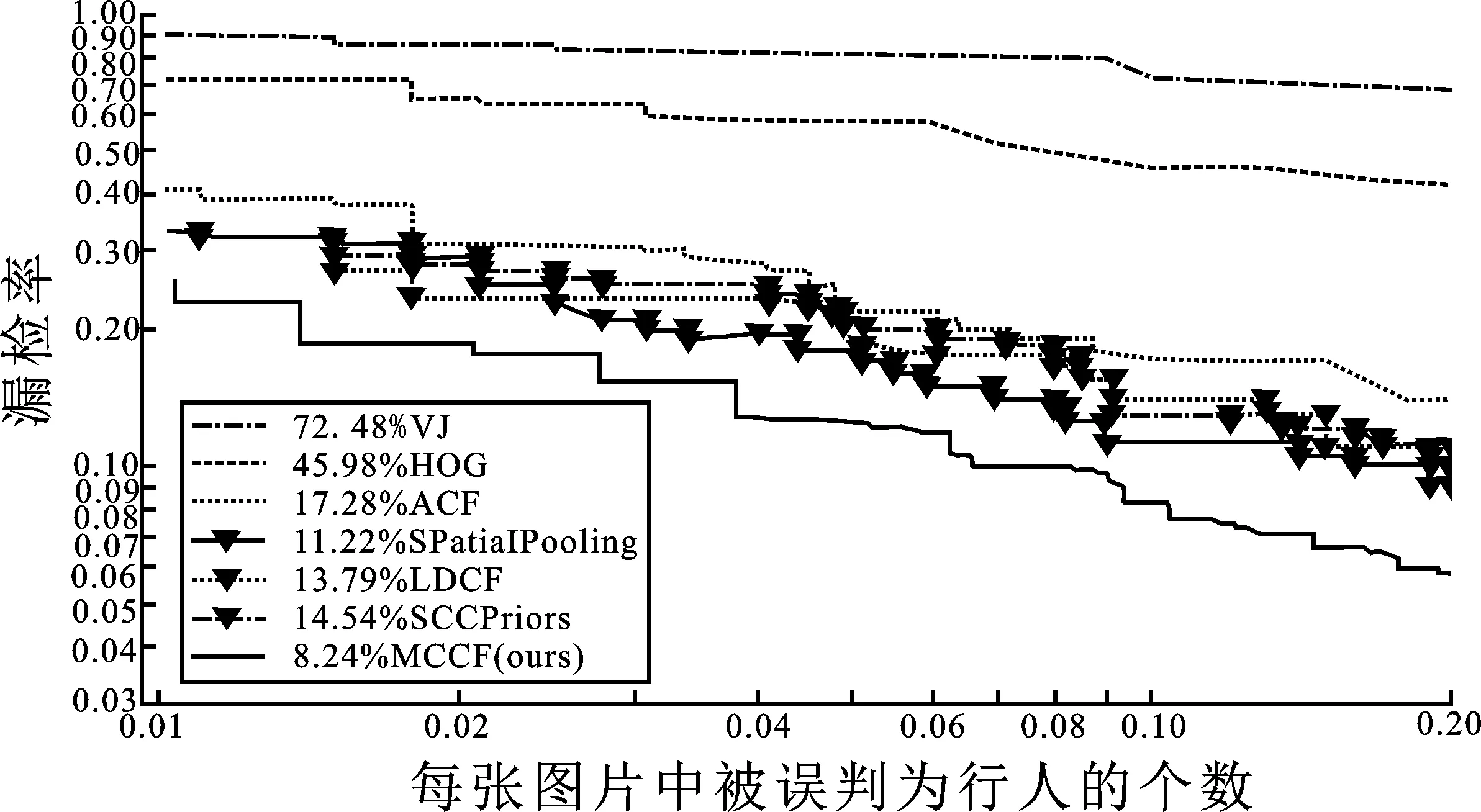
图5 INRIA数据库的结果
图6显示了VJ[24]、HOG[1]、ACF[10]、LDCF[11]、SPatialPooling[25]、SCCPriors[26]与本文的多通道特征模型在Caltech数据集上的检测结果。当误检率为0.1也就是每10张图片会出现一个误检窗口的情况下,本文的多通道特征模型漏检率为19.78%,与仅使用LDCF相比降低了5.02%,与其他算法相比也有明显下降。
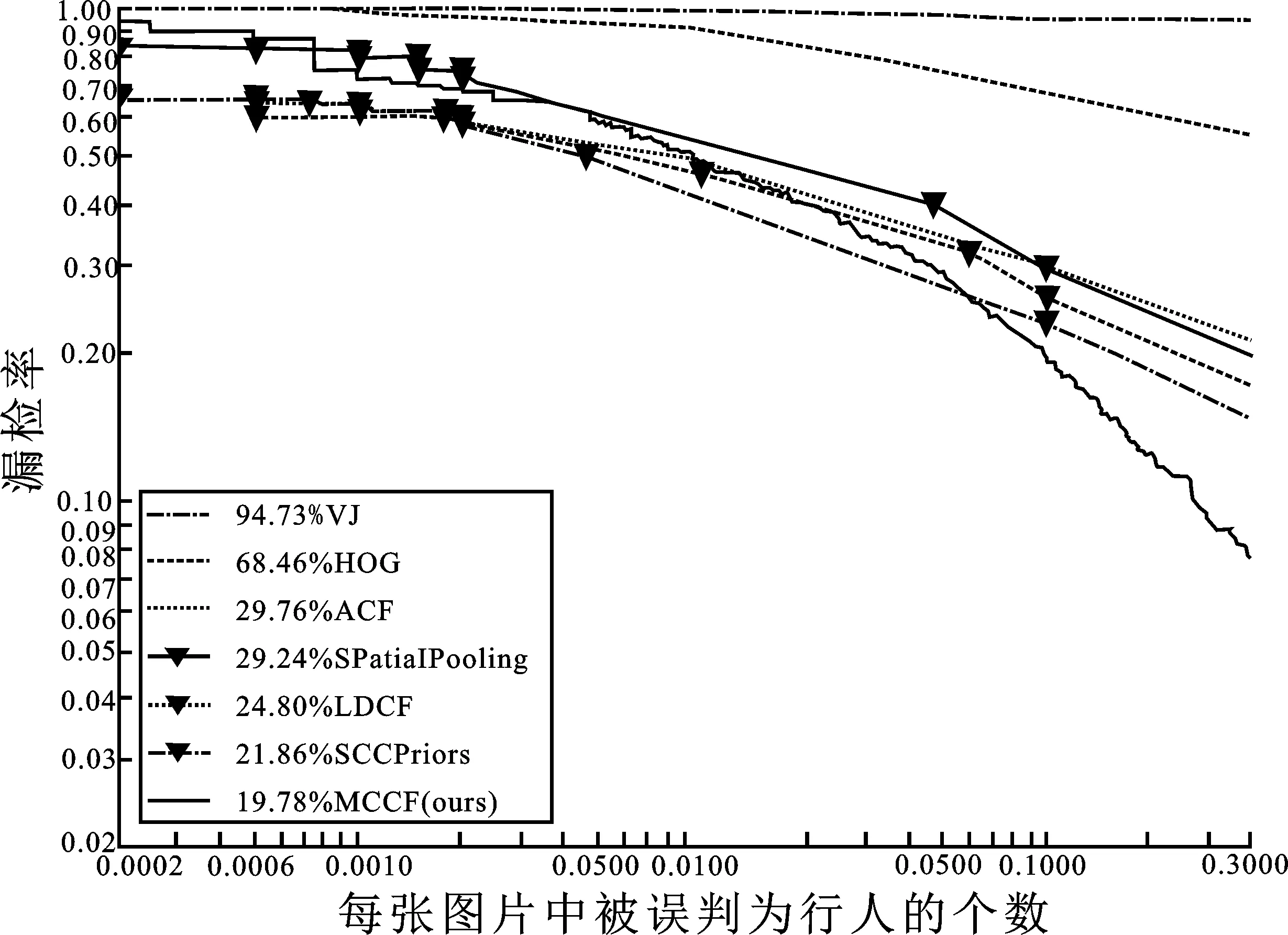
图6 Caltech数据库的结果

(a) (b)

(a) (b)
由图7和图8可以看出,本文所提出的模型与开发的行人检测器具有较低的漏检率和较高的定位精度,适用于行人形变以及遮挡行人。在INRIA和Caltech数据库中,误检率为0.1时,LDCF和本文所提出算法的对比如图7和图8所示,图中左图为LDCF的检测结果,右图为本文模型的检测结果。在INRIA和Caltech数据库中,本文所提出的模型都可以检测出更多的行人,尤其是具有遮挡以及形变的行人。
4 结束语
本文在多特征融合的基础上提出了一个由非深度学习分支、整体分支以及肢体分支组成的多通道特征模型。该模型通过非深度学习分支提取出数量少、质量高的行人候选区域,减轻了滑动窗口穷举搜索带来的计算负担,提高了计算效率。该方法根据多层卷积通道特征得到的整体分支以及肢体分支,分别通过人体整体信息和人体部位的语义信息来检测行人。此模型分别在Caltech和INRIA数据集中进行训练和检测。实验结果表明,结合各分支的输出,本文所开发的行人检测器具有较低的漏检率和较高的定位精度,适用于形变行人以及遮挡行人。
本文所提出的模型仍存在以下问题:(1)多通道特征模型的检测速度有所下降。由于本文使用的是一个二段式的行人检测方法,故与仅使用非深度学习模型相比增加了行人检测的时间;(2)无法解决行人高度重叠的情况。多通道特征模型使用非深度学习分支提取行人待检窗口,因此本文的方法尚无法解决当检测图像中行人高度重叠的问题,降低了检测效率。接下来,研究人员将针对这两方面的缺陷进行进一步改进,以期获得更好的行人检测效果。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
意林(2021年5期)2021-04-18
学生天地(2019年28期)2019-08-25
扬子江(2019年1期)2019-03-08
计算机应用(2017年4期)2017-06-27
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
