
基于ResNet-50 深度卷积网络的果树病害智能诊断模型研究
2021-05-08 11:09李洪磊
农业图书情报学刊 2021年4期
金 瑛,叶 飒,李洪磊
(1.辽宁师范大学大数据与商务智能实验室,大连 116029;2 中国农业科学院农业信息研究所,北京 100081)
1 引言
果树病害因受到全球气候和环境条件变化呈现出爆发式上升趋势。由于病害的传播速度取决于环境条件和植物的易感染性,果树在生长周期中容易受到多种疾病的入侵。在实际的果树病害检测识别中,种植户通常依赖于人眼观察和靠经验诊断,这种方法不仅耗时、主观性强、而且误判率高。因此能够使用高科技手段,在复杂的农业生态环境中及时准确的诊断果树所患疾病具有积极意义。
互联网的普及应用,以及与机器学习技术的结合,为果树病害的远程诊断提供了有力支撑。相关研究表明,利用机器学习,特别是深度学习技术自动识别果树病害图像是可行的。如祁钊等提出了主成分分析和支持向量机组合的方法识别室外玉米叶部病害的图像,并用Retinex 算法,对图像进行了增强,总识别精度达到90.74%[1]。刘浩洲等使用K-means 聚类图像分割方法,识别猕猴桃花朵,该算法成功率为92.5%[2]。毕傲睿提出了利用改进的中值滤波方法去除噪声,并有效的保留了边缘信息的预处理方法,采用直方图均衡化方法,对图像进行了增强,提高动态范围和比较高的对比度,将受到不同影响的图像转化为较统一的形式;使用模糊C 均值聚类算法分割病斑图像,对图像的特征提取方法上选择15 类特征参数,最后选用基于支持向量机的病害识别模型[3]。屈赟等对病斑图像分割时运用了最大类间方差法(Otsu)提取出重要的颜色、纹理和形状特征,最后利用支持向量机(SVM)方法分类病斑,并且建立了苹果叶部病害特征库[4]。刘双以Gentle AdaBoost 算法为基础,从梯度和纹理的角度更全面地描述,筛选出最佳的特征后,将训练好的各层分类器按照一定的筛选率组合成级联检测器,快速排出背景值;最后引入SIFT 模板匹配算法对检测出的结果进行二次筛选确定检测目标[5]。卢柳江等应用机器学习理论,利用Haar-like 提取的图像特征构建弱分类器,并通过AdaBoost 算法将弱分类器集合升级为强分类器,运用级联的方法合成AdaBoost 分类器来识别农作物虫害。根据背景的复杂程度,模型的识别率保持在95.71%和86.67%区间内,解决了农作物虫害的预防工作强度大、耗时长、效率低的问题[6]。
近几年来,在农业领域中深度学习备受广大研究者的青睐,相对于传统机器学习,深度学习(Deep Learning,DL)可以从原始数据中自动提取特征,将较低层次的特征组合成高层次的特征[7]。该网络的特征提取和结构化数据的显著优势,有效地推动了农业智能机械装备的开发,其相应研究成果不断涌现[8]。黄双萍等针对水稻穗瘟病的图像检测问题,采用了深度卷积神经网络GoogLeNet模型,模型的最高识别准确率达到92%[9]。李艳等使用卷积神经网络对马铃薯疾病进行了分类,该算法成功应用于农作物病害的识别,显示了深度学习技术在农业任务中的潜力[10]。李淼等利用了ImageNet 数据集和PlantVillage 网络公开数据集,以黄瓜和水稻病害为研究对象开展研究,通过采用知识迁移和深度学习方法,提高了相关领域的图像识别效率[11]。王细萍等通过引入卷积、采样算子的方法,提出时变冲量学习的苹果病变图像识别方法,正确率高达97.45%[12]。张建华等提出了棉花病害的识别模型,采用微型迁移的策略共享模型中的卷积层和池化层的参数,以此来优化VGG 的结构和权值,并且用6 标签分类器实现图像识别,总体准确率达到89.51%[13]。蒋丰千等通过对病害图像的二值化和轮廓分割等预处理,利用Caffe 框架对优化后的网络模型进行了识别率等方面的实验验证,开发了大豆疾病检测系统[14]。王梅嘉等在苹果叶部病害识别方面通过扩展对比度,去除叶面绒毛,锐化图像,去除光照影响完成预处理。利用遗传算法优化模糊C 均值聚类,提取了8 个参数作为有效特征。通过构建BP、RBF、DBN三种网络和支持向量机(SVM)实现病斑识别[15]。邱靖等利用深度卷积网络建立3 种水稻病害的识别模型,对数据归一化处理,并运用深度学习框架Keras 进行深度CNN 训练,统一用9×9 卷积核尺寸和最大池化函数,经过一定次数的迭代,其识别准确率达到90%以上,以较高的识别率实现了3 种水稻分类,泛化能力较强、准确率较高、鲁棒性较好[16]。
综合上述研究,虽然在图像识别方面广大研究者已经相应地取得了进展,但多集中于单一病种的诊断识别。部分研究是基于公共数据集训练的,数据质量可靠度不高,导致模型在实际应用中出现较大偏差。
本研究基于卷积神经网络中的ResNet-50 模型,以梨黑斑病、梨锈病、苹果花叶病、苹果锈病这4 种患病叶片图像为对象进行模型训练,实验数据集数量达到近10 000 张,数据来源真实可靠,图像本身上具有全面性和完整性,以此训练的诊断模型可靠性更具说服力。随后在果树病害图像识别模型的基础上开发相应的应用软件,通过互联网提供诊断服务。
2 实验数据与实验环境
2.1 样本数据
本研究数据来源于农业专业知识服务系统的果树病害图谱库[17]。该图谱库包含10 000 张果树病害叶片图像,其中包括梨黑斑病、梨锈病、苹果花叶病、苹果锈病各2 500 张,样本数据分布平衡。这4 种果树疾病是常见多发疾病,其中梨锈病发生普遍,是梨树的重要病害类型,在发病严重时,个别梨园梨树感病品种的病叶率在60%以上。梨锈病主要危害叶片、新梢和幼果。叶片受害,叶正面形成橙黄色圆形病斑,并密生橙黄色针头大的小点,后期小粒点变为黑色;梨黑斑病也是梨树重要的病害,在中国主要梨区普遍发生。西洋梨、日本梨、酥梨、雪花梨最易感病,发病严重时会引起早期落叶和嫩梢枯死,致使裂果和早期落果;苹果花叶病在各地均有发生,陕西关中地区有些果园的病株率高达30%以上,危害较严重。病叶表现5 种症状:斑驳型、花叶型、条斑型、环斑型和镶边型,诊断有一定困难;苹果锈病近年来在一些地区发生有明显上升趋势。苹果锈病可引起落叶、落果和嫩枝折断,各苹果产区均有发生。主要为害幼叶、叶柄、新梢及幼果等幼嫩绿色组织。初期叶片正面产生橙黄色有光泽的小斑点,随后发展成直径为0.5~1.0cm 的橙黄色圆形病斑,病斑边缘常呈红色,稍肥厚。严重时,一片叶子上可有十几个病斑。
该图谱库中的叶片图像由专业人士在果树展叶期从果园采摘,根据上述病症表现,精心挑选病斑清晰的叶片,在室内摄影棚内拍摄。背景为纯白色。色温在5 200~5 500。每个叶片分全景、局部、正位拍摄。图片库图片分辨率高,细节清晰,达到高分辨率标准,但对于机器学习而言,场景不够多样化、自然化,会影响诊断模型的泛化能力。为了弥补这个缺陷,本文通过在线收集的方式,收集到100 余张关于4 种病害的网络图像,与上述图谱库相结合,进行样本数据增强。这些图像包括梨黑斑病25 张、梨锈病27 张、苹果花叶病28 张、苹果锈病24 张。图1 为农业知识服务系统图谱库样例,图2 是线上收集的公共图像数据集,并经过专业人士鉴别后用于数据增强。
上述数据集按8∶2 比例分割为训练集、验证集。网络收集的数据做测试集。其中训练集用于模型训练,验证集用于模型参数调优,测试集用于测试模型的泛化能力。为了降低数据规模,加快模型训练过程,在本研究中所有图像被统一压缩至640×480 尺寸。
2.2 数据增强

图1 样本数据图像(农业知识服务系统图谱库)Fig.1 Image samples(Agricultural Knowledge Service System Image Library)

图2 果树病害公共图像(源于网络)Fig.2 Public images of fruit tree diseases(from the Internet)
鉴于本研究获取的图像均为采摘后在纯净环境中拍摄,背景不够丰富,图像过于精美和标准,色彩、亮度多样性差,将会对模型的泛化能力产生很大影响[18,19]。因此本研究对上述样本数据进行了数据增强处理,提高图像样本数据的多样性水平,从而在一定程度上保证了模型的泛化能力。这些处理包括如下方式。
(1)旋转方向。即通过旋转和位移等方式提高病变叶子的图像相对位置的多态性,该多态性采用与标准图像的夹角或矢量位移的描述。本研究每隔30 度进行一次旋转采样,即1 张原始图片会产生12 张旋转后的图片。
(2)颜色抖动[20]。由于不同空间相对位置和日照条件不同,同一对象会采集得到不同亮度、饱和度、对比度等模式,在颜色平衡区间上呈现出不同图像的复杂性,提升算法的鲁棒性。本研究对每张图片进行3次颜色抖动的随机处理。
(3)随机切割。在保留足够病害叶子主要信息的情况下,对图片进行裁剪,减少部分背景信息,从而增加形态上的多样性,提高模型的泛化能力。本研究对每张图片进行3 次切割处理。
(4)污化处理。对多所采集的图像进行随机污化,以防训练中出现过拟合的现象,降低模型的泛化能力。本文对污化处理添加了随机污化、1∶1 污化和不放回污化。本研究对每张图片各进行3 次污化处理。
(5)增噪处理。由于深度神经网络模型是高度非线性的,图像的一个像素微调可影响对抗样本,因此本研究引入了随机白噪声来模拟拍摄不同清晰度的样本数据。本研究对每张图片进行1 次随机增噪处理。
(6)背景叠加。将果树叶片与其生长背景进行叠加,丰富图片的背景信息。本研究对每张原始图片进行1 次背景叠加。
2.3 实验环境
本研究在大型计算机服务器上进行。该服务器8核CPU,内存128G,运行Linux 操作系统。在Python3.6 的环境下,安装了TensorFlow[21]、Keras 深度学习软件包和OpenCV 图像处理软件包。
TensorFlow 是谷歌公司推出的基于数据流编程(Dataflow Programming)的符号数学系统,被广泛应用于各类机器学习(Machine Learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。TensorFlow 拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU 和TPU 高性能数值计算。TensorFlow的Python 版本支持LInux、Windows、macOS操作系统。TensorFlow 提供Python 语言下的4 个不同版本:CPU 版本(Tensorflow)、包含GPU 加速的版本(Tensorflow-Gpu),以及它们的每日编译版本(Tf-Nightly、Tf-Nightly-Gpu)。安装Python 版TensorFlow 可以使用模块管理工具Pip/Pip3 或Anaconda 并在终端直接运行。
OpenCV 是一个基于BSD 许可(开源)发行的跨平台计算机视觉和机器学习软件库,主要倾向于实时视觉应用。OpenCV 可以运行在Linux、Windows、Android 和Mac OS 操作系统上。OpenCV 由一系列C函数和少量C++类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。OpenCV 具有轻量级、高效率、便于应用的优点,因而深得图像处理专业人士青睐。
在图像和视觉智能处理领域,TensorFlow 与OpenCV 组合使用非常流行。本研究将TensorFlow 用于诊断模型训练,而OpenCV 用于实现图像样本的数据增强处理以及其他预处理操作。
3 模型训练
3.1 ResNet 简介
传统的深度学习算法一般采用数据初始化(Normalized Initialization)和正 则 化(Intermediate Normalization)[22]来解决计算资源消耗高、模型容易过拟合和梯度消失/梯度爆炸问题。这种方法虽然在一定程度上解决了梯度问题,但是后续又出现了网络退化等现象,于是HE 等提出了一种残差学习框架ResNet[23]。随着网络深度的增加,使用ResNet 有助于模型预测性能的显著提高,同时模型训练时间没有明显增加,因此ResNet 成为目前应用最为广泛的卷积神经网络。
ResNet 通常设置18、34、50、101 等多种层数选择,考虑到实验环境和数据规模,本研究选择50 层的ResNet。
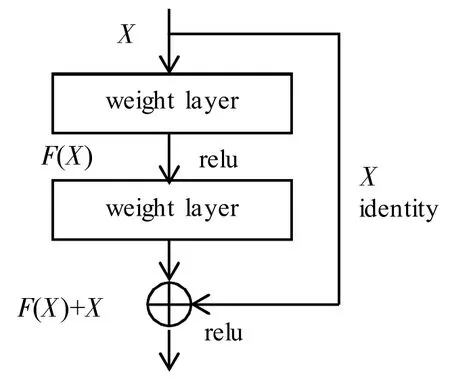
图3 残差网络示意图Fig.3 Diagram of a residual network
ResNet-50 包括一个跨层连接,如图3 所示[24]。该跨层连接通过快捷连接Shortcut 跨层传递输入信息,然后将其添加到卷积输出中以完全训练底层网络,相当于直接执行了恒等映射。在恒等映射函数中,假设残差网络的最优结果输出为H(X),经过卷积操作后的输出F(X),由于F(X)=H(X)-X,因此最优结果为H(X)=F(X)+X。假设残差映射比原映射更易优化,那么在极端情况下就很容易将残差推至0,即F(X)=0,这就变成了恒等映射函数H(X)=X,这比将映射逼近另一个映射要简单得多,可以从时间、效果等多方面满足要求。因此ResNet 在训练中额外的参数和计算复杂度不会因此而增加,模型相当于退化为一个浅层网络,从而随着深度的增加而大大提高了准确性,不用过多地担心网络的“退化”问题。只要训练数据足够,逐步加深网络,就可以获得更好的性能表现。换而言之,ResNet 可以在网络深度增加时,预测偏差减小(准确度上升),而方差也不会显著增加(泛化能力不受影响)。方差与偏差同时被优化,这在机器学习算法中极为难得。
3.2 四分类函数
为了高效准确的识别常见果树病害的图像,本研究将分类器改进为4 目标Softmax 分类器。Softmax 分类器是把一种目标变量分成多个种类的算法,可以接受全连接层输入的特征矩阵,输出输入目标对应的每个种类的不同概率值。例如,有N 个输入目标,每个目标的标记 yi∈{1,2,3……},k 为模型输出类别的种类数(k≥2)。本文做梨黑斑病、梨锈病、苹果花叶病、苹果锈病的四分类器,k 值取值为4。对于给定的输入xi,用假设函数fθ(xi)估计对应类别概率j 值P(yi=j|xi)。则函数为
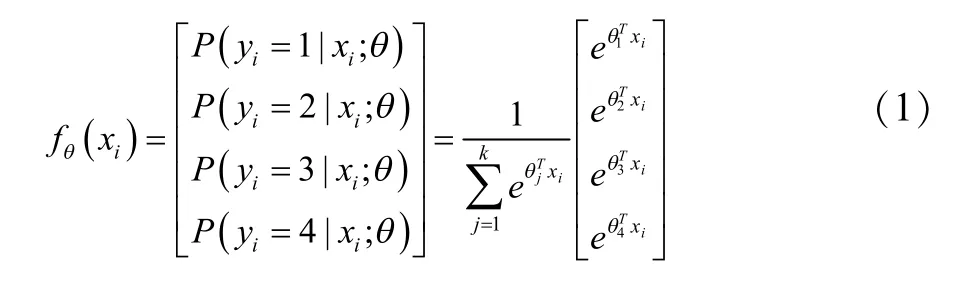
θ 是Softmax 分类器的参数,为保证概率和为1,使用

进行归一化,Softmax 分类器的损失函数为
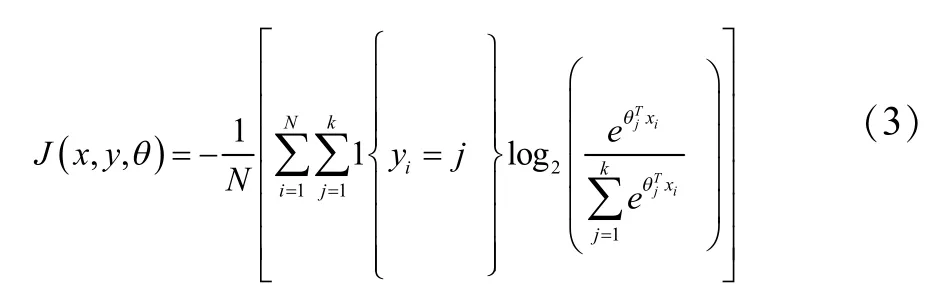
其中(yi=j)为指示性函数,其取值与括号内的真值保持一致,即yi=j 成立时函数值为1,否则为0。
3.3 参数设计
本研究经过多次试验对比后,对模型的参数设置如下表所示。模型优化器为Adam。Adam 优化算法采用框架默认参数,其所占内存少,计算效率高,适用于非稳态目标等诸多优势,由于本研究对象果树病害样本数据规模大,非常适合本研究对象果树病害样本的大规模图像数据[25]。
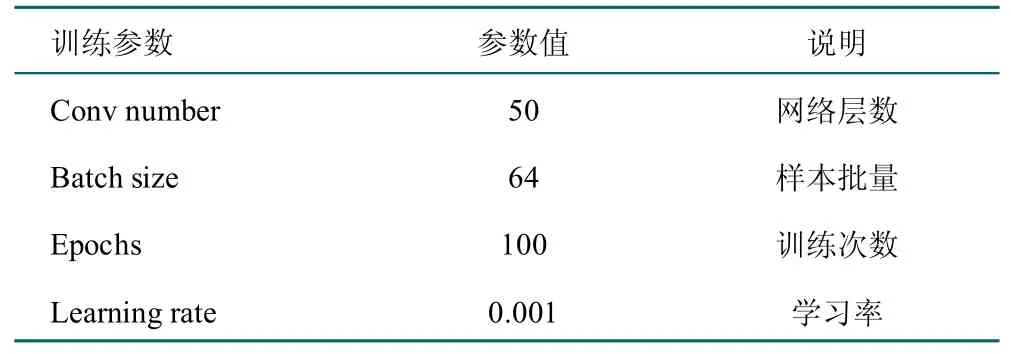
表1 模型参数设计表Table 1 Model parameters
4 实验结果及分析
4.1 查准率
查准率(Precision)指的是预测为正例的集合中真正例的比例,其定义如下:

公式(4)中TP(True Positive)指模型识别出的正类数量、TN(True Negative)指模型识别出的负类数量、FP(False Positive)指模型误报的数量,即将负类图像预测为正类的数量、FN(False Negative)指模型的漏报数量,即未识别出的正类数量。
4.2 查全率
查全率(Recall Ratio),也叫召回率,是预测结果中真正例与实际所有整理的比值。

4.3 F-Score
在实际应用中,查准率和查全率会出现悖反现象,即此消彼长。F-Score 是查准率与查全率的加权调和平均,在评价模型预测性能时综合性更强。

应用实践中,常设置α=1,即F1 指标。

4.4 Accuracy
模型精度(ACC)是分类正确的样本数占总样本数的比例,可从总体上反应一个模型的预测能力,其定义如下:
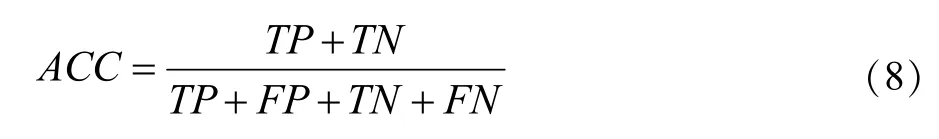
4.5 实验结果分析
从实验数据集中抽取80%的数据作为训练集,20%数据作为验证集,经过迭代后训练效果如图4 所示。横轴为训练周期(Epochs),纵轴为误差/ 精度(Loss/Acc)。由图4 可知,随着迭代次数越多,模型的精度越来越高,误差越来越低,大约在第22 代训练周期后趋于平稳,误差逐渐趋向于0,而精度逐渐趋向于1。训练集和验证集的两项指标近似重合,说明模型的偏差、方差和精度均收敛于理想水平。
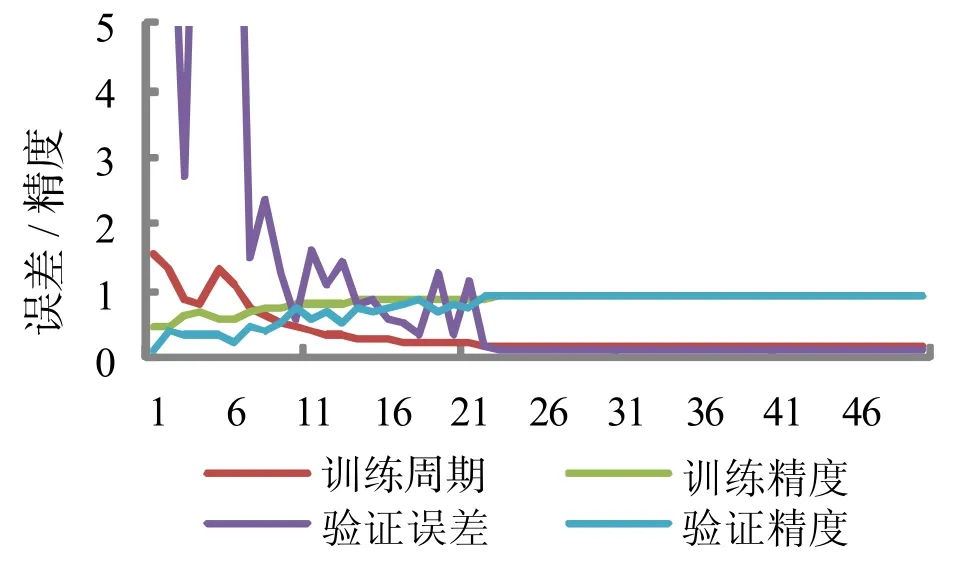
图4 模型收敛过程Fig.4 Model convergence process
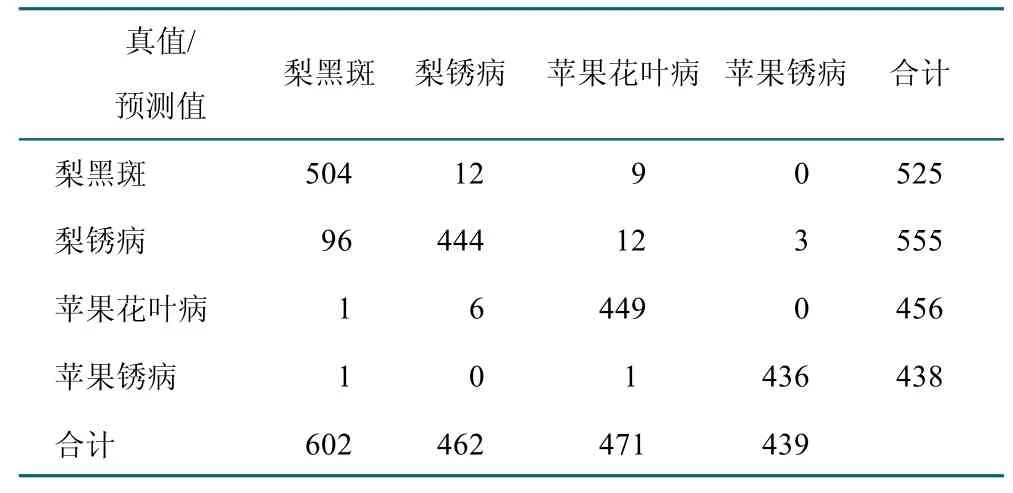
表2 混淆矩阵Table 2 Confusion matrix
在表2 的混淆矩阵中,行表示预测类别,列表示真实类别。从混淆矩阵中可以看出,基于当前的样本集合,梨锈病和梨黑斑病表征有一定的相似性,在梨黑斑识别过程中容易误判为梨锈病。
表3 显示模型的性能指标。苹果花叶病和苹果锈病的识别准确度较高,而梨锈病与梨黑斑的识别性能稍微逊色,模型的总体精度ACC 为92.9%。
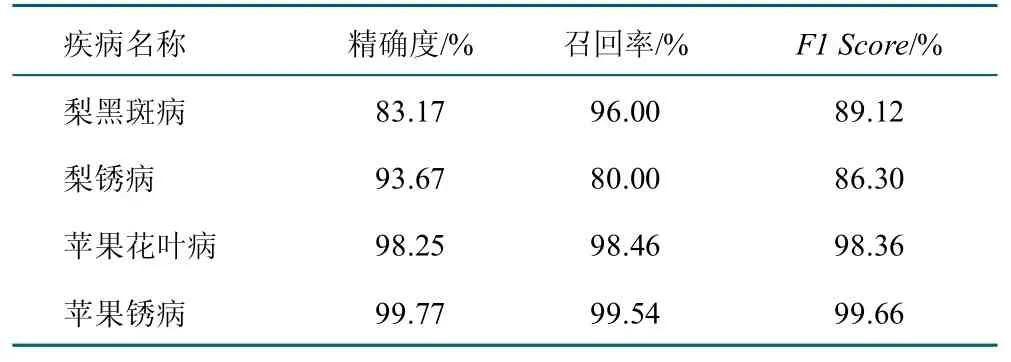
表3 模型评价指标(数据增强)Table 3 Model evaluation metrics(data augmentation)
而对于未经图片增强的原始数据集,本研究使用相同的参数进行ResNet-50 模型训练,结果发现模型的精确度、召回率、和F1 Score 显著下降。如表4 所示。
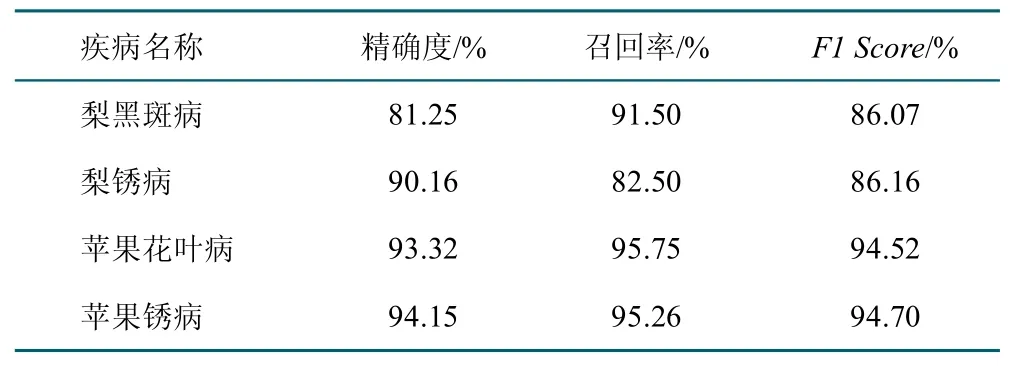
表4 模型评价指标(原始数据)Tab.4 Model evaluation metrics(raw data)
5 果树病害图像识别系统开发
该软件系统基于上述ResNet-50 模型,使用Java和Python 语言开发,采用B/S 系统构架。系统技术结构如图5 所示。

图5 果树病害识别系统技术结构图Fig.5 Technical structure diagram of fruit tree disease recognition system
用户交互子系统使用Java 开发,其主要功能为建立用户与系统的交互界面。使用该子系统,用户可以上传需要诊断的图片,并获得诊断结果。模型服务子系统则提供样本图片处理、模型训练和模型应用服务(图片诊断)。该系统采用复合技术构架是为了充分发挥Java 与Python 在网络计算和模型运算方面的各自优势,同时较好地实现了运算负载的均衡。
该系统的两个子系统可以共用1 台硬件服务器,也可以分别安装到不同的服务器,两个子系统通过http 协议进行数据通信。
模型服务子系统还动态存储了用户上传的图片,这样模型训练模块就可以根据系统在使用过程中图片数据的积累对模型进行重新训练,使模型得到持续完善,诊断性能获得不断提升。系统的工作流程如图6所示。
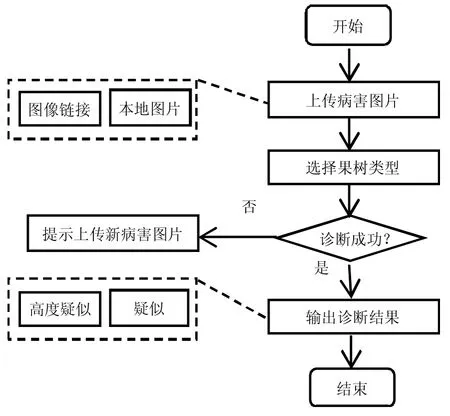
图6 果树病害识别系统流程图Fig.6 Flow chart of the fruit tree disease recognition system
用户采集到病害图像后,可通过上传本地图片或指定图片地址,模型即可获得输入的图片,之后再进行预测。ResNet-50 模型使用了Softmax 函数,输出4种分类的概率。本文选择其中最大概率分类作为诊断结果。诊断结果根据不同概率水平分为高度疑似(大于0.75)、疑似(大于0.3)和不确定3 种水平,为用户判断提供参考价值。系统工作界面如图7 所示。
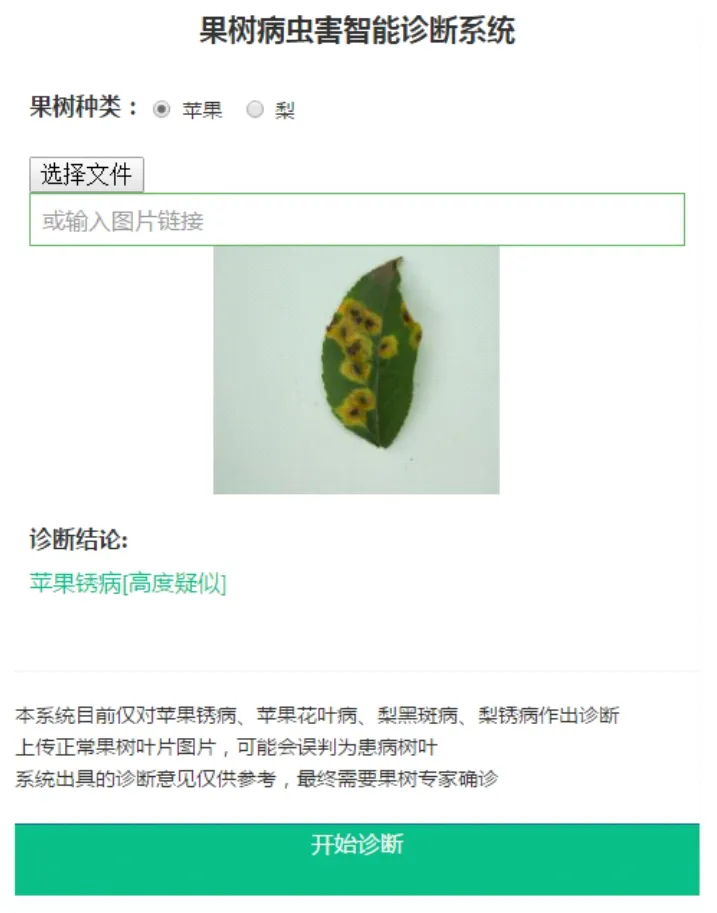
图7 果树病害智能诊断系统界面Fig.7 The interface of the intelligent diagnosis system for fruit tree diseases
6 结语
本研究使用ResNet-50 训练了病害智能诊断模型,为果树病害图像识别提供了一种可操作可借鉴的试验经验。鉴于样本图像拍摄场景单一、色彩、清晰度、亮度趋同、多样性差的特点,该研究采用数据增强技术对样本图像进行了预处理,提高了样本数据的多样化水平。实验证明,该做法显著提高了模型的预测性能。基于上述诊断模型,开发了果树病害智能诊断系统,在线提供果树病害诊断服务。
实验还发现,受图像数据集样本多样性不足的影响,该模型的泛化能力还需进一步提高。通过搜集到的互联网公共图像测试,该模型的整体精度下降到85.2%水平。这说明尽管本研究对样本进行了数据增强操作,但样本的多样性水平仍然没有达到理想水平,这需要在今后的研究中进一步丰富样本多样性,同时在模型训练中,进一步优化参数设置,从数据优化和模型优化两个方向出发,努力提高诊断模型的预测精度。
猜你喜欢
现代农村科技(2022年5期)2022-11-18
今日农业(2022年1期)2022-11-16
今日农业(2022年16期)2022-11-09
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
上海农业科技(2020年5期)2020-12-18
今日农业(2020年23期)2020-12-15
云南农业科技(2020年1期)2020-06-10
电子技术与软件工程(2019年18期)2019-11-18
电子技术与软件工程(2017年14期)2017-09-08
