
基于多特征融合的多目标跟踪算法研究*
2021-05-08 06:10王帅,苍岩
通信技术 2021年4期
王 帅,苍 岩
(哈尔滨工程大学,黑龙江 哈尔滨 150000)
0 引言
视频监控技术是现代社会中一种有效的安防手段,目前的视频监控系统主要以人工监控为主,需要很大的时间和人力成本,而且其中的一些人为因素可能导致丢失重要目标。如何智能且高效率地处理监控视频成为一个热门的研究问题。一个完整的智能视频监控系统中最关键、设计最困难的部分是目标检测和目标跟踪两个部分。
大多数目标跟踪算法以检测为基础,根据检测的结果进行数据关联,数据关联算法分两大类,传统算法和深度学习算法,常见的传统方法有光流法、均值漂移法和粒子滤波法。近年来,深度学习技术迅速发展,多数算法偏向于使用深度学习。比如经典的POI[1]和DeepSORT[2],在2019年之前出现的算法都是检测和关联两个部分相互分离的,多数算法使用数据集提供的公版检测结果,只研究数据关联部分。2019年JDE[3]算法提出,率先将检测和数据关联合二为一,之后便出现了一些类似的算法。2020年腾讯提出了一种链式跟踪算法CTracker[4],其设计的网络每次输出一对节点,形成一条链。该算法强调的是简洁性,处理遮挡问题时使用常速运动模型,而且没有使用外观特征进行关联,因此没有复杂的计算,跟踪速度较快。
1 算法概览
本文设计了一种特征提取算法,并以FoveaBox[5]检测算法为基础,使用mmdetection框架搭建了一个目标检测和数据关联结合的多目标跟踪网络,使用端到端的训练方式。在数据关联部分,除关联分支提取出的外观特征外,本文还使用卡尔曼滤波算法[9]融合了目标的位置及运动特征来匹配轨迹与目标。对二者均未匹配上的部分,使用IoU重叠度匹配,以最大限度地保证跟踪性能。
本文的实验选取了MOT16[7]数据集进行训练与测试,使用FPN[6]作为主干网络得到特征金字塔,后为金字塔中各特征图限定了负责的尺度范围,再根据目标的尺度,为其匹配相应的特征图,以提高检测精度。为应对拥挤场景下小目标的漏检问题,在训练阶段,首先使用专注于密集行人场景的数据集CrowdHuman[8]进行预训练,再在其他数据集上对网络进行调整。本文还对比了关联分支的三元组损失和交叉熵损失,以及轨迹匹配中的外观特征匹配、卡尔曼滤波和IoU匹配3种策略。
2 网络结构
本文的网络结构可以分为检测和关联(ReID)两大部分,两个部分联合学习,使用端到端的方式来训练。在目标检测子任务中,多数算法使用基于anchor的方式,但其有一些缺陷,anchor要根据实际情况来设计,比如检测常规物体,anchor的宽高比一般要设置三种比例,而到检测行人的具体问题就仅需要一种比例,这就缺少了泛化能力;根据anchor和真值的IoU确定anchor的正负也会给网络增加一些超参数。本文的检测部分使用的是FoveaBox,这是一种受人体视觉系统启发的anchorfree检测方式,不需要放置anchor,本文还使用FPN进行多尺度预测,同一目标可以在多个特征图上预测。
网络结构也可以分为4个部分:主干网络、分类分支、边界框回归分支和关联(ReID)分支。整体网络结构如图1所示。其中灰色的部分是关联分支,其具体结构如2.4节图2所示。
2.1 主干网络
网络的输入为单张图片,以及其中行人目标对应的边界框、边界框的中心点,图片首先要经过的是主干网络,主干网络的选择对于后续的分类匹配等有极其重要的影响,一个好的网络能够提取到目标的各种特征,本文采用FPN作为主干网络,不同于一般的卷积网络在最后一层提取特征,该网络使用具有横向连接的自上而下的结构来构建特征金字塔,融合了高层丰富的语义特征和低层丰富的位置特征,从而使得后续的目标检测结果更加精确。
利用FPN进行目标检测时,先生成特征金字塔,其中的每一层用来检测特定尺度的目标。将不同的层使用横向连接结合,提取到了不同层次的特征后,将各层特征图送入3个分支:目标分类分支、边界框回归分支和关联(ReID)分支。目标分类分支预测每对边界框的得分,该分支仅区别前景(行人)和背景,输出的分数表示前景置信度。边界框回归分支用于得到每个目标的边界框。关联分支用来提取目标的外观特征,以在跟踪时进行匹配。
2.2 分类分支
假设一张图片中的一个目标边界框的真值为(x1,y1,x2,y2),则其对应在特征金字塔的第Pl层,对应的坐标为:

sl表示Pl层的下采样因子,训练过程上述坐标包围的区域被标注为正值,其他区域都标注为负值,分类分支输出的特征图中,表示有目标的区域Rpos为:


特征图的大小为H×W×C,C为通道数,表示目标的种类,本文只需要检测行人这一种目标,所以输出的特征图为一维,图上每个点的值表示该处存在目标的可能性。
若需要对多种类别的对象进行区分,其损失函数最好选用Focal Loss,但本文中只对行人目标感兴趣,因此分类分支使用交叉熵损失。
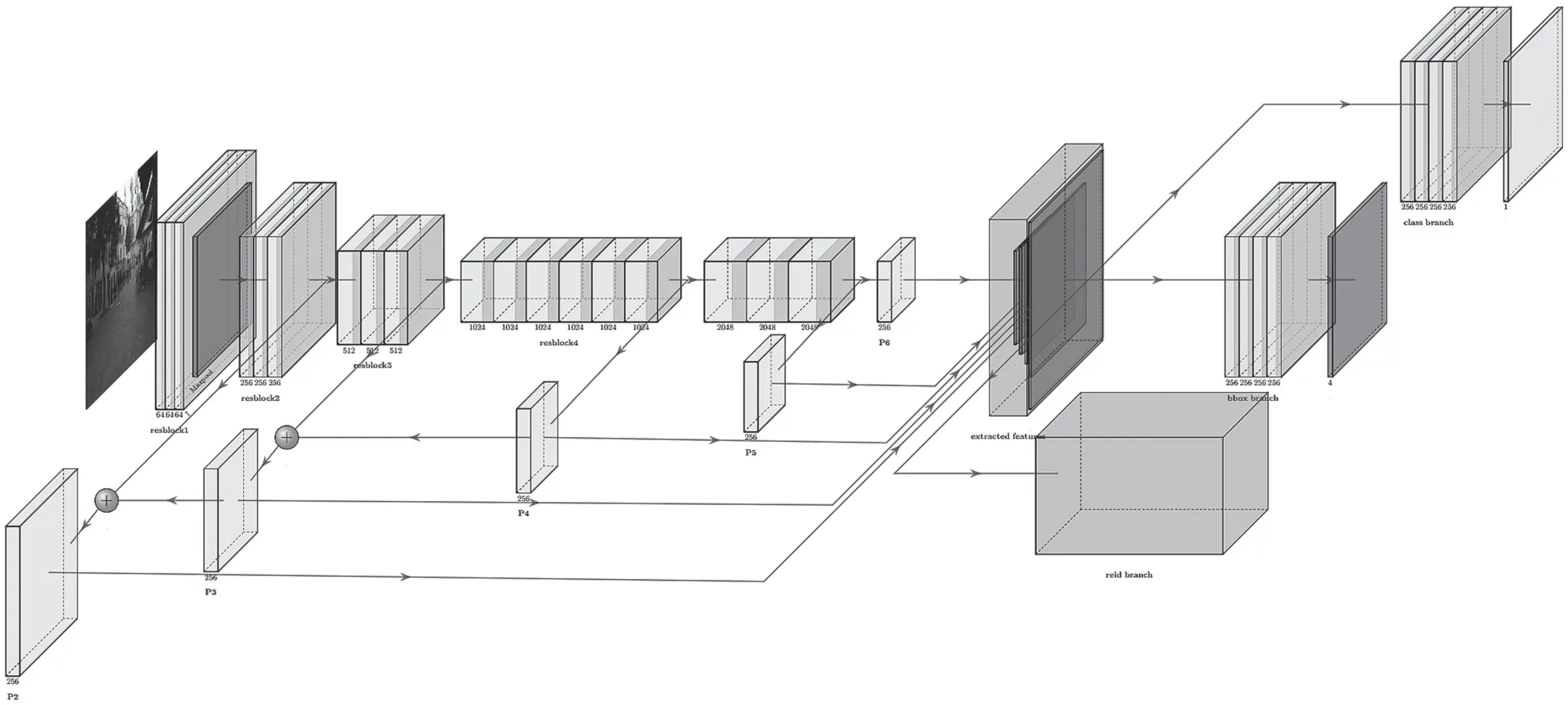
图1 整体网络结构
2.3 边界框回归分支
本文检测部分参照FoveaBox,使用anchor-free的方式,不需要放置anchor,直接根据语义特征图计算某个点存在对象的可能性,再对可能存在目标的点进行边界框回归,提高了检测精度,从而在跟踪过程中能更精确地提取目标特征。
为了解决目标尺度的变化问题和适应各种不同尺度的目标,边界框回归分支根据特征金字塔中不同的层次来预测不同尺度的目标,每个层有一个基准尺度rl该层负责的尺度范围为(rl/η,rl×η),实验中η设置为2,FPN金字塔的P3~P7层的基准尺度分别为(16,32,64,128,256)。若一个目标的边界框映射到某一个金字塔层中时,其尺度没有在该层的尺度范围中,那么就会被这一层所忽略。也有可能一个目标被映射到了多个层,这样就可以更好地对该目标进行预测,因为相邻的特征层具有相似的语义特征,这个目标也可以在不同的特征图中被预测。传统的FPN网络只会根据目标的尺度,将其映射到一个特征层。
Rpos区域的每一个点{x,y}都对应一组边界框的偏移量,偏移量的计算方法如下:


对于其中一个特征金字塔层,边界框回归分支输出的特征图大小为w×h×4,其中w和h为特征图宽度高度,通道数4对应其4个坐标偏移量,偏移量的真值计算方法是:Rpos区域对应的每一个点的4个值按照式(4)~式(7)来计算,其他位置的值为0。边界框回归损失函数选择

分类分支和边界框回归分支负责行人检测,并称为检测分支。为了减少密度高场景中的漏检现象,本文使用专注于密集行人检测的数据集CrowdHuman对检测分支进行了预训练。
2.4 关联分支
数据关联的主要任务是识别不同帧中的同一个目标,需要提取每个目标特征,且提取的特征要具有表现力。特征提取方法可以是anchor中心提取、RoI Pooling、目标中心提取,使用在目标的中心提取的方式。
若一帧中包含M个目标,FPN输出的5个特征图均为256维,取特征图的第一层,送入关联分支,为了提取更多的目标的特征,关联分支中共有4个卷积层,每经过一层卷积提取一次,4个分支中输出的特征维度分别为80、60、40、20,将这些特征拼接,则每个目标可以提取的特征维度为200。该分支输出的维度为M×200。将这些特征送入一个线性分类器,每个特征的输出维度为当前所使用的训练数据集中所有目标的ID总数。将线性分类后的特征与目标ID的真值计算损失。其原理图如图2所示。

图2 关联分支结构


式中,[x]+表示最大值函数max(0,x)。
交叉熵损失是分类问题中常用的一类损失函数,假设一个目标x的真实概率分布和预测概率分布分别为p(x),q(x),则交叉熵损失可以表示为:

2.5 算法流程



α是先前特征所占的权重,本实验设置为0.9。
算法的整体流程如图3所示。

图3 整体算法流程
3 实验分析
本文使用MOT16数据集进行训练和测试,该数据集采集自不同的场景,比如广场、街道、商场等,场景中存在光照、背景变化等多种不确定的因素,为了增强鲁棒性,在送入网络之前,图片首先经过了一系列的预处理,包括光度失真、归一化、水平翻转和随机通道转换。
MOT16数据集没有单独提供验证集,本文将训练集划分为两部分,每个场景的一半为训练集,一半为验证集。
3.1 损失函数比较
在训练关联分支时,本文选用了三元组损失和交叉熵损失分别训练了网络,网络整体的损失函数用3个分支的损失函数加权和表示如下:

式中,i={cls,bbox,reid}。
二者对比实验结果如表1所示,每项指标后标注↑的表示值越高,性能越好,标注↓的表示值越低,性能越好。
根据对比结果,可以看出虽然二者各占3项优势,但MOTP和IDF1两指标基本持平。而对于MOTA和IDSW两指标,使用交叉熵损失训练出的模型要优于三元组损失。因此,在测试集上运行时,选用交叉熵损失训练的模型进行测试。
3.2 关联方法比较
本节做了3组实验,对比了不同的关联方法之间的性能。第1组实验中仅使用外观特征匹配,第2组实验使用外观特征配合卡尔曼滤波,第3组实验则同时使用外观特征、卡尔曼滤波以及IoU匹配。
第2组实验中,外观特征与卡尔曼滤波结合的方法是:首先使用提取到的一帧中所有目标的外观特征,计算其与当前所有轨迹特征的余弦距离,组成亲和力矩阵Mdist再根据卡尔曼滤波计算所有轨迹状态之间的马氏距离,得到另一矩阵Mmaha,计算两矩阵之间的加权和:

实验中的λ根据经验取0.98。对于未匹配上的轨迹Tu与边界框Du,第3组实验中,再使用IoU匹配,计算Tu的最后一个边界框与Du的重叠度。得到一个矩阵Moverlap,根据该矩阵匹配上一步中匹配失败的轨迹与边界框。3组实验的结果如表2所示。

表1 交叉熵损失和三元组损失对比

表2 不同匹配方式实验结果
根据3组实验的结果可以得出,使用多特征融合的方式进行跟踪性能要优于使用单一特征的性能,因此最后在测试集上运行时本文同时使用了3种特征。
3.3 MOT16数据集测试结果
本节中的实验使用 MOT16 的测试集评估跟踪结果的性能,其测试结果如表3所示。在测试时,一般将未匹配到的轨迹保留20帧,若还未匹配上,则认为该条轨迹已经消失。如果这个值设置得太大,可能会将新生的目标误识别成已消失目标,还会造成内存压力。MOT16-12场景中出现一个特殊情况,440帧左右时发生严重遮挡,一个从摄像机后方出现的行人几乎完全挡住了摄像机的视线,持续了20帧后才减轻,如图4所示,若保留的最大帧数为20,就会发生严重错误,因此这段视频中轨迹最大保留30帧。
3.4 本文与其他算法比较
本文算法与其他算法的对比结果如表4所示。
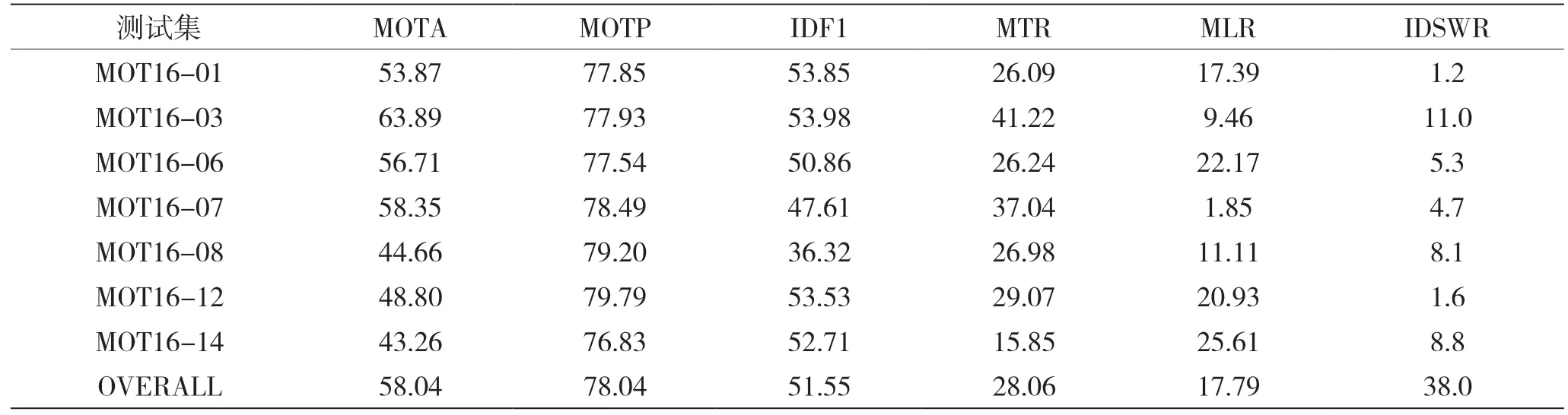
表3 MOT16测试集运行结果

表4 不同算法比较结果

图4 MOT16-12测试结果
通过对比实验发现,本文提出的算法在 MOTA与MT两项指标上超过了其他算法。MOTA是多目标跟踪评价指标中最重要的一个,衡量的是算法的准确度,MT指标表示的是最大丢失,即一个目标在整个轨迹中超过80%没有被覆盖。本文的MT指标是最低的,说明算法稳定性较好,不易丢失目标。
4 结语
本文使用深度学习方法,以FoveaBox检测器为基础,使用目前流行的深度学习框架mmdetection设计了一种特征提取方法,用于提取出具有较强表现力的特征,进而构建了一个目标检测与数据关联相结合的多目标跟踪网络,实现了一步跟踪。在跟踪过程中,除提取出的特征外,本文还结合了卡尔曼滤波器以及IoU匹配方式对轨迹与目标进行匹配,以最大限度地保证跟踪性能。本文使用的是公共数据集,后续可以根据实际场景自行构建数据集,以对算法进行应用。对数据集中出现的干扰,如行人倒影、海报人物等可以专门采集相应的数据集进行训练,增强鲁棒性。还可以使用模型蒸馏对模型进行压缩,从而提高运行速度。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
故事作文·高年级(2022年2期)2022-02-24
计算机系统应用(2021年10期)2022-01-06
纺织科学研究(2021年7期)2021-08-14
现代装饰(2020年4期)2020-05-20
当代陕西(2019年15期)2019-09-02
学生天地(2019年28期)2019-08-25
学苑创造·A版(2018年11期)2018-02-01
小猕猴智力画刊(2017年6期)2017-07-03
读者(2017年5期)2017-02-15
