
多尺度细节增强的红外图像去混合噪声研究
2021-05-06 06:11:52王春平
火力与指挥控制 2021年3期
赵 斌,王春平,付 强
(陆军工程大学石家庄校区电子与光学工程系,石家庄 050003)
0 引言
红外成像系统具有结构轻巧、隐蔽性好、不易受烟雾尘埃干扰、全天候全天时工作等优点,被广泛应用于军事、民用的无源探测中。但由于探测环境及红外成像器件本身的影响,红外图像往往会受到多重噪声干扰,这会干扰到目标特征提取、检测识别和分割等工作的效果。特别在军事上,存在恶意的敌对干扰,严重影响对战场态势的判断。因此,对复杂噪声的有效抑制是红外图像处理中的重要环节,是提高红外探测系统性能的重要手段。
传统的红外图像降噪主要利用噪声高频的特性,通过低通滤波、扩散滤波等方法实现降噪。中值滤波[1]、均值滤波[2]等方法通过平滑图像来缓解噪声干扰,但会损失细节信息;文献[3-5]利用不同的扩散策略平滑图像,在抑制噪声的同时保留了图像的边缘特征;文献[6]提出能自适应调节拉格朗日乘子和惩罚参数的Split Bregman 算法,具有更快的收敛速度;文献[7]针对红外图像中的条纹噪声干扰问题,提出利用相邻行之间灰度值的继承性完成图像校正。
上述提到的方法将重点集中在处理某一种或某一类噪声上,缺乏同时处理多种噪声干扰的能力。然而,实际环境中的红外图像噪声干扰多种多样,要求降噪算法应具备更强的鲁棒性和普适性。为此,本文借助深度卷积神经网络在自动提取图像特征上的优势,提出一种具有多尺度细节增强能力的卷积自编码器网络,用于剔除红外图像中的混合噪声干扰。该方法通过在自编码器模型中堆叠卷积神经网络,实现图像特征的自动提取,避免了复杂的人工特征设计过程,一旦确定好编码器结构后,仅需在其前后端分别给定噪声图像和原始图像作为模型的训练数据即可,完全由网络自主学习,去噪性能与网络结构相关,不受噪声类型限制。
1 红外图像噪声分析与建模
在实际的红外图像中,各种噪声混杂在一起,不同噪声呈现出不同的概率密度分布规律,因此,为了丰富样本、方便实验研究,建立了噪声生成模型,通过在图像上生成噪声来模拟含噪图像[8]。
1.1 高斯噪声
由红外背景辐射的光子起伏、红外探测器光电转换和信号读出与处理电路等引起的噪声在时间和空间上都呈现随机分布的特点。它们相互之间独立分布,如果将这些噪声叠加起来,可简单将其建模成高斯噪声。通过生成与图像矩阵大小相同且服从正态分布的灰度值数据作为噪声,直接叠加到原图像上模拟产生受高斯噪声污染的图像。噪声的概率密度分布函数为

其中,x 表示每个像素点上的灰度值,μ 和σ 分别是所有像素灰度值的期望和标准差。
1.2 椒盐噪声
在凝视型成像器件产生红外图像时,器件直接让焦平面上的感光元器件发生光电反应,在某些像素点上会出现盲元,这在图像上呈现出亮暗点噪声,其表现类似于椒盐噪声,因此,可将其建立成椒盐噪声模型,其概率分布密度可表示为
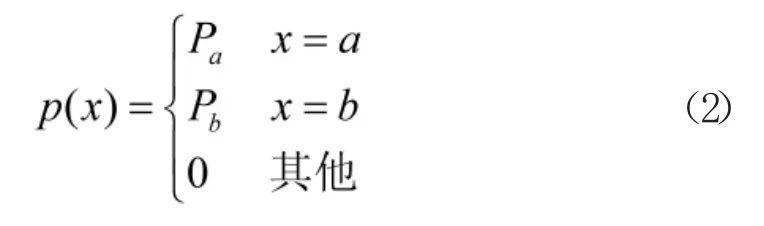
其中,a、b 都是灰度值,当a<b 时,a 在图像中就会呈现成一个暗点,b 将显示为一个亮点,在红外图像中,一般将它们设为饱和值,即图像允许的最小和最大灰度等级值;Pa和Pb表示亮暗点的出现概率。
1.3 条纹噪声
条纹噪声是红外图像中另一种较为常见的噪声,多存在于扫描型成像器件产生的红外图像中。扫描型成像器件的焦平面呈现一维的线状分布,在成像时,只能同时采集一行数据,然后按照一定频率移动焦平面来产生多组数据,最终拼组完整的图像。当扫描型成像器件存在盲元时,会在图像中产生沿扫面方向的亮暗线。其构造原理类似于椒盐噪声,只是将其中的点换成整行。
2 卷积自编码器
2.1 自编码器原理
自编码器[9]是一种神经网络,其设计理念为:通过对比网络的输入输出差异,实现网络参数的自动调整,最终使输入输出近似相等。它属于无监督学习,不需要标注样本,实现起来也十分简单。最简单的自编码器由3 层网络组成,如下页图1 所示。在训练期间,每个样本经由输入层传递给中间层并在此对数据进行压缩,相当于一个编码过程;再将中间层的数据传递给输出层进行还原,相当于解码过程,那么为了收敛,网络必须学习到可以表征输入数据最重要的特征。
假设输入为x,输入层到中间层的权值矩阵为W,偏置为b,非线性激活函数为f(·),那么中间层的输出可表示为

同理,可得到输出层的输出为

通常,权值矩阵W2是W1的转置,即W2=W1T,优化目标就是通过调整网络权值来改变输出z,使得它与输入x 之间的差异最小化。假设将欧式距离作为它们差异的衡量标准,则目标函数为


图1 自编码器
2.2 去噪卷积自编码器网络设计
基本的自编码器各网络层之间采用了全连接的形式,虽然网络层数少,但参数量却十分庞大,无法处理图像数据。卷积自编码器[10]综合了卷积神经网络与自编码器的优点,采用了局部连接和权值共享的策略,大幅削减了网络参数量,使得网络能够处理大尺度图像数据,并集成了自编码器的无监督学习特性,符合图像预处理简单高效的需求。
2.2.1 卷积模块
卷积模块由二维卷积层、批归一化层和非线性激活层组成。卷积层用于提取图像特征,该过程中最重要的是卷积核大小、步长的设计以及数量的选择。卷积核的大小影响网络结构的识别能力;步长决定了卷积后特征图的大小;数量关乎特征提取的丰富程度,但数量越多,网络的复杂度也会随之增加。
批归一化层[11]与卷积层相连,用于将数据归一化至均值为0、方差为1,然后再输入下一层。在训练深度网络时,网络参数必然会发生变化,如果不进行归一化处理,那么除了输入层外,网络后面每一层的输入数据分布都会一直发生变化。神经网络的本质就是为了学习数据的分布特性,一旦每批训练数据的分布各不相同,网络在每次迭代中都要去学习适应不同的分布,这会大大降低网络的训练速度,这也是需要归一化预处理数据的原因。
对每批训练数据神经元输出数据使用下面的公式进行预处理:

非线性激活函数用于增强网络非线性描述能力,建立输入与输出之间复杂的非线性映射关系。模型中采用的激活函数——修正线性单元(Rectified Linear Unit,ReLU)。
2.2.2 Inception 模块
考虑到图像与噪声的多样性与复杂性,在构造卷积特征提取网络时,借鉴了Inception[12]结构的优点,设计了一个简化版的Inception 模块,其结构展示在下页图2 右边的虚线框Inception Block 中。该模块包含3 条并联的支路,分别由平均池化层(Avg Pooling)与1×1 卷积模块串联、1×1 卷积模块与3×3 卷积模块串联以及单个1×1 卷积模块构成。这样设计的好处是能增加网络的深度和宽度,通过融合不同分支的特征图,可以提高对特征的收集能力。加入更多1×1 卷积模块的目的是调整特征图维度及提高网络的非线性描述能力,虽然1×1 卷积直观上几乎不改变输入的值,但每次卷积计算都会经过一个非线性激活函数(文中采用了Relu),那么每经过一次卷积计算,都能在一定程度上提高一些非线性表达能力。在整个网络中总共加入了18个1×1 卷积模块,因此,能有效增强网络应付多样复杂图像和噪声的能力,提高鲁棒性。
2.2.3 跳跃连接

图2 去噪卷积自编码器结构
在解码器重构图像过程中存在多次上采样(即Deconv,通过反卷积扩大特征图尺度,直到与输入图像尺度相同),导致最终的降噪图像存在较严重的平滑问题,很多细节信息随同噪声一起被剔除了,因此,在对称的不同尺度高低特征层之间构建了跳跃连接,将编码器中的特征信息与解码器相应尺度的特征图进行融合,实现不同尺度上的细节增强。低层特征图中包含大量边缘纹理等细节特征,高层特征图中包含的则是抽象的语义信息,仅利用高层特征图重构图像显然不利于恢复图像的细节信息,因此,利用了Skip connection 补偿解码器中的细节特征。
图2 展示了融入Inception 模块和跳跃连接的去噪卷积自编码器(Inception and Skip Cone Denoising Convolutional AutoEncoder,IS-DCAE)的网络结构。为了处理高效,统一将训练集图像调整为200×200 的原始参考图像。训练时,在参考图像上叠加混合噪声作为网络的输入数据,经卷积和池化操作后,将分辨率为200×200 的输入图像经3 次池化后处理成一组分辨率为25×25 的特征图,其中,卷积层实现特征的自动提取,池化层实现下采样及增强局部不变性。这是一个输入图像不断被压缩的过程,因此,可将其视为编码过程。同理,在解码过程中,通过反卷积上采样和卷积整合后,特征图被不断放大,直至与输入图像尺度相同,然后利用输出图像与原始图像之间的差异计算网络损失,调整卷积核参数至符合训练终止条件。
为了增强网络对不同噪声的鲁棒性,在训练时,随机生成每个批次训练图像的噪声强度。测试时,直接将测试集数据作为输入图像,送入网络进行处理,输出图像则是经过降噪重构后的图像。
3 实验结果及分析
为了验证降噪卷积自编码器在降噪方面的有效性,实验选取了2 000 张以天空为背景、以飞机为目标的红外图像作为训练集,实验环境为Tensorflow,编程语言为Python 3.6,计算机配置为64 G 内存、Inter(R)Xeon(R)CPU E5-2630 v3@2.4 GHz、NVIDIA GeForce GTX TITAN X GPU。
3.1 红外混合噪声图像生成实验
本文对高斯噪声、椒盐噪声和条纹噪声这3 类在红外图像中比较有代表性的噪声进行了建模仿真,其流程如图3 所示。高斯噪声在图像中表现为一种加性噪声,通过在原始图像上直接叠加一个同等大小、元素呈正态分布的噪声矩阵来模拟仿真,噪声的强度由噪声矩阵的系数α 决定。图4(a)是一个仿真产生高斯噪声的实例。

图3 噪声建模流程
不同于高斯噪声可能影响每个位置像素点的值,椒盐噪声只改变了图像中某些像素点的值,在实验中,设置了“椒”数m 和“盐”数n 两个参数来决定产生椒盐噪声的强度,通过随机选取m 个点将其值置为0、选取n 个点将其值置为1(已经将图像的像素值归一化0 到1 范围内)来模拟椒盐噪声。图4(b)展示了在200×200 图像中m,n 分别为100 时的椒盐噪声。

图4 噪声仿真
条纹噪声是红外图像中的一种特殊噪声,在仿真时,设置了条纹数s 作为强度参数,通过随机选择s 行像素并将整行像素置为1 来模拟条纹噪声。图4(c)是s=5 时的条纹噪声,图4(d)是3 种噪声叠加在一起的情况。
3.2 红外图像混合噪声去噪结果
实验利用去噪卷积自编码器对训练集所有图片进行20 轮训练,学习率为0.01,梯度下降优化算法为A dam,每个批次选取16 张图片同时训练。选取了5 幅不同目标状态和背景条件下的测试图像展示模型的去噪效果,并将传统去噪算法中性能优异的BM 3D 方法作为对比算法,其结果如图5 所示。测试图像的高斯噪声强度参数α 为0.2,椒盐噪声强度m、n 都为500,条纹数s 为5。图中第1 列是原始图像,第2 列是噪声图像,第3 列是利用BM 3D[13]算法去噪的结果,第4 列是本文所提的去噪卷积自编码器(IS-DCAE)的去噪效果。
虽然输入图像受到多种混叠噪声的严重干扰,图像中目标的大小和姿态各异,并且背景也不尽相同,但所提的IS-DCAE 方法都能有效地降低噪声干扰、重构出清晰干净的图像。BM 3D 算法虽然能滤除大部分的高斯噪声和椒盐噪声,但清除条纹噪声能力较差,此外,BM 3D 算法在重度噪声干扰条件下的图像细节保存能力也不足。得益于Skip connection在不同尺度上对特征信息的补充以及Inception 模块更强大的特征收集能力,IS-DCAE 可以更好地保留图像的边缘和纹理信息,得到更接近原始图像的去噪结果。

图5 不同目标和背景条件下的去噪结果
为了定量衡量模型的去噪效果,采用了均方误差(Mean Square Error,MSE)、峰值信噪比(Peak Signal Noise Ratio,PSNR) 和 结 构 相 似 性(Structural SIMilarity,SSIM)作为定量实验评价指标,实验中使用的噪声参数依然为α=0.2,s=5,m=n=500。表1 给出了噪声图像、BM 3D 去噪后图像和所提IS-DCAE方法去噪后图像相对于原始干净红外图像的评价结果。从结果上看,IS-DCAE 方法在各个指标上都明显优于BM 3D,有两方面的原因:一是之前针对图像去噪的研究大多假设噪声是高斯分布且噪声强度相对较低,导致传统方法在高强度混合噪声图像上的去噪性能急剧退化;二是IS-DCAE 方法能自主学习数据分布特性,提取图像不变特征能力突出,加之细节信息得到了补偿,因此,表现出更优异的去噪性能。

表1 测试图像去噪性能指标对比
此外,在相同处理平台上,分别对BM 3D 和IS-DCAE 的处理时间进行了统计。BM 3D 对于5 幅测试图像的平均处理时间约为35.82 s(CPU),IS-DCAE 对5 幅图像处理完成后的平均时间约为0.43 s(GPU),这相比于NL-Means[14]和BM 3D 动辄几十秒的处理速度具有明显优势。当然,这一优势主要得益于GPU 以及卷积神经网络在处理图像问题上的高并行性,还可以通过增大每个批次的图像数量进一步降低IS-DCAE 的平均处理时间。
3.3 不同模块对去噪性能的影响
在朴素卷积自编码器的基础上,加入了Inception 模块与Skip connection 改善去噪性能,为了验证各模块对于整个去噪网络的贡献,实验分别对各个模块进行了性能评价。结果如表2 所示,从上到下依次为朴素DCAE、仅加入Inception 模块的DCAE、仅加入Skip connection 的DCAE,以及同时加入Inception 和Skip connection 的DCAE(即IS-DCAE)在5 张测试图像上的去噪性能指标值。整体上看,IS-DCAE 性能最优,Inception 和Skip connection 从不同侧面改善了去噪性能。
为了可视化各模块去噪性能,选取了包含细节更为丰富的测试图像img2 进行展示。图6(a)是原始干净图像,图6(b)~(e)是利用不同方法的去噪结果。朴素DCAE 虽然优于BM 3D,但重构后的图像存在较为严重的平滑问题,细节信息缺失较多。加入Inception 模块后虽然有所改善,但图像细节仍得不到有效补偿。Skip connection 能明显提高图像细节恢复能力,但直观上与原始干净图像仍有一定差异。通过综合利用Inception 模块与Skip connection的不同能力,可以有效增强DCAE 的去噪性能,得到更优的重构图像。

表2 不同模块去噪性能指标对比

图6 不同模块去噪效果对比
3.4 不同噪声强度下的去噪性能
为了进一步验证算法的鲁棒性和处理重度噪声的能力,在实验中增加了测试图像的噪声强度,图7 展示了不同噪声强度下IS-DCAE 的去噪效果。其中,图7(a)是噪声强度为α=0.2,s=10,m=n=500时的两幅测试图像及其去噪结果,该实验检验模型对高强度条纹噪声干扰的处理能力;图7(b)对应的噪声强度为α=0.2,s=5,m=n=2 000,检验模型对高强度椒盐噪声干扰的处理能力;图7(c)对应的噪声强度为α=0.4,s=5,m=n=500,检验模型对高强度高斯噪声干扰的处理能力;图7(d)对应的噪声强度为α=0.4,s=10,m=n=2 000,检验模型对高强度混合噪声干扰的处理能力。

图7 不同噪声强度下的去噪效果
表3 是IS-DCAE 和BM 3D 在不同噪声强度下对5 幅测试图像的去噪性能评价结果对比情况,表中每个指标的值都是对5 幅测试图像评价结果取平均得到的。

表3 不同噪声强度下的去噪性能指标平均值
从去噪效果来看,虽然噪声对图像造成了极大的干扰,特别是小目标图像,几乎被淹没在噪声中,但本文设计的模型仍然能在一定程度上还原出原始图像,重构出图像的主要成分,这说明了所提方法鲁棒性较强,能够用于处理重度混合噪声污染的图像,而如此低信噪比的噪声环境是其他文献[3-6,15-16]所没有采用的。进一步对比3 种噪声对重构图像的影响,发现高斯噪声对重构结果影响最大,这是因为高斯噪声会对每个像素点的像素值都产生影响,而椒盐噪声和条纹噪声只影响图像中的部分点。
4 结论
本文提出一种利用卷积自编码器实现红外图像去噪的方法,针对自编码器结构单一、细节缺失等问题,引入了简化Inception 模块和Skip connection 构造了一个新的IS-DCAE 模型,在实现红外图像特征无监督学习的同时,拓宽了网络结构、增强了网络的非线性描述能力,并且在多个尺度上补充图像细节,提高了去混合噪声能力。在表2 的噪声条件下能平均提高测试图像的峰值信噪比约18.18 dB。在面临表3 的恶劣噪声环境时,该模型依然取得了明显的去噪效果,证明了模型具有较好的鲁棒性。未来还可以在数据集丰富性、噪声模型和网络结构上作进一步优化。
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
金桥(2021年4期)2021-05-21 08:19:20
电子制作(2019年7期)2019-04-25 13:17:14
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
光学精密工程(2016年3期)2016-11-07 09:03:43
电子器件(2015年5期)2015-12-29 08:42:24
饮食科学(2014年5期)2014-06-18 09:42:17
电测与仪表(2014年13期)2014-04-04 12:04:18
电视技术(2014年19期)2014-03-11 15:37:54
