
融合RGB 与灰度图像特征的行人再识别方法
2021-04-29 03:21:30姜国权肖禛禛霍占强
计算机工程 2021年4期
姜国权,肖禛禛,霍占强
(河南理工大学计算机科学与技术学院,河南焦作 454000)
0 概述
行人再识别(Re-Identification,ReID)技术是目前智能图像检索、视频监控等领域的热门研究方向,由于该技术与社会公共安全密切相关,因此可与目标检测与跟踪等技术相结合应用于疑犯追踪、灾难预警和智能安防等任务中[1]。行人再识别要求在跨设备条件下对已知身份行人库中的特定身份行人进行搜索并找到与其匹配的所有结果[2],主要包括行人图像预处理、特征提取和相似性计算3 个步骤,其中,图像预处理包括图像翻转、裁剪、缩放及像素归一化等操作,特征提取对算法性能起到决定性作用,相似性计算通过计算特征之间的欧式距离实现。
近年来,研究人员提出了大量行人再识别方法并取得了重要研究成果。现有方法可大致分为基于特征设计和基于多任务学习的行人再识别方法两类。基于特征设计的行人再识别方法的关键在于设计可靠且具有判别力的模型以提取行人图像的鲁棒特征。该模型可以是人工设计模型与基于端到端的深度学习模型,人工设计模型获取的特征主要是HSV 颜色直方图[3]、尺度不变局部三元模式描述符(SILTP)[4]等低层次特征。文献[5]为每个图像局部块提取11 维颜色命名的描述符,并使用词袋模型将其聚合为1 个全局向量。文献[6]提出一种特征表示方法(LOMO),该方法分析局部特征水平并将其最大化后针对视点变化进行稳定表示。
随着卷积神经网络(Convolutional Neural Network,CNN)的发展[7],基于深度学习的特征设计方法不断被提出。文献[8]利用PCB 网络将行人特征统一划分为多个水平区域,并输出由这些区域特征共同组成的卷积特征。文献[9]设计一种多级因子分解网络(MLFN),将人的视觉表象分解为多个语义层次因子,通过因子选择模块对输入图像内容进行解释。文献[10]提出区域对齐的行人再识别方法,通过定位行人身体节点划分特征区域,并将各个特征区域融合得到特征表示。为学习更具判别力的特征,一些研究人员在特征提取过程中引入注意力机制[11-13],如文献[12]提出Mancs 深层网络,该网络利用注意力机制解决行人图像的不对齐问题,从而获得更稳定的行人特征。这些深度学习模型通过设计网络模型以获取高层次的行人特征,此类特征一般比低层次特征具有更强的表征能力。
基于多任务学习的行人再识别方法通过结合行人属性预测[14-16]、图像分割[17-19]和图像生成[20-22]等任务来增强算法性能。文献[14]提出一种简单的CNN 模型,其在学习行人表征的同时对行人属性进行预测,能有效提升ReID 算法性能。文献[19]利用二值分割掩码生成RGB-Mask 图像对,然后设计掩码引导的对比注意力模型(MGCAM)分别学习行人主体和背景区域的特征。为避免深度网络模型训练过程中的过拟合现象,文献[21]使用生成式对抗网络(Generative Adversarial Network,GAN)生成训练数据并为这些数据分配统一的标签,然后与原始数据共同进行模型训练。以上方法均是利用RGB 行人图像提取特征,并未考虑颜色因素对ReID 算法的影响,但实际应用场景中存在相同身份的行人图像颜色不一致、不同身份行人图像颜色相近、行人图像分辨率不一及遮挡和背景杂乱等问题,使得整体识别性能受到较大影响。本文提出一种基于RGB 图像特征与灰度图像特征相融合的行人再识别方法,从图像颜色角度出发提升行人再识别方法的平均精度均值(mean Average Precision,mAP)和首位命中率(Rank-1 accuracy)。
1 行人再识别方法
1.1 问题描述
假设一组测试图像被分为待查询图像集Query和候选行人图像集Gallery,Query 表示为,Gallery 表示为,将Q与G对应的特征向量分别用FQ和FG表示,表达式如式(1)和式(2)所示:

其中,m表示Query 包含的图像个数,n表示Gallery包含的图像个数,d表示图像特征维度。Query 图像qi和Gallery 图像gi之间的距离为:

其中,fqi和fgj表示图像qi和gi对应的特征。行人再识别任务的目标是使相同身份行人之间的距离更小,而不同身份行人之间的距离更大。根据式(3)得到的距离获取Query 在Gallery 中的相似度排序结果。
1.2 网络结构
1.2.1 网络结构设计
本文提出一种融合RGB 图像和灰度图像特征的双分支残差网络,其结构如图1 所示。首先,将RGB 图像和灰度图像输入网络,RGB 分支和灰度分支所使用的主干网络均为在ImageNet 上预训练的ResNet-50,并去除其原有的全连接(Fully Connected,FC)层。受PCB 网络结构[8]的启发,在两个分支中ResNet-50 最后一个卷积层的步长均由2 变为1,目的是使网络能够学习更多的细节信息。然后,使用全局均值池化(Global Average Pooling,GAP)和1×1卷积(1×1 Conv)对特征进行降维。最后,使用FC 做行人身份预测,FC 的维度为对应数据集中训练数据所包含的不同行人身份数。为对RGB 图像和灰度图像特征进行有效融合,将RGB 分支和灰度分支中最后一个卷积层输出的特征沿通道方向进行拼接得到融合特征。对融合特征采用统一水平划分策略,将其划分为多个水平条并分别使用GAP、1×1 Conv和FC 操作,之后将3 个分支中1×1 Conv 后的特征进行拼接得到更鲁棒的组合特征F,对组合特征F 也使用FC 进行行人身份识别。

图1 双分支残差网络结构Fig.1 Double branch residual network structure
为更清晰地展示本文网络模型中不同阶段所获得的特征尺寸以及分类向量维度,表1 给出输入图像在不同分支中经过不同网络阶段后获得的特征尺寸和分类向量维度,其中RGB 图像和灰度图像的输入图像原始尺寸均为3×384×128。由于在Market1501[5]、DukeMTMC-ReID(简称Duke)[23]和CUHK03[24]3 个数据集的训练集中包含不同身份的行人数目不同,因此在经过FCs 后得到的表示分类结果的向量维度也不同(751/702/767)。由于组合特征F 是经过3 个分支中1×1 Conv 后的特征拼接而成,因此其维度为2 048(256×8)维。
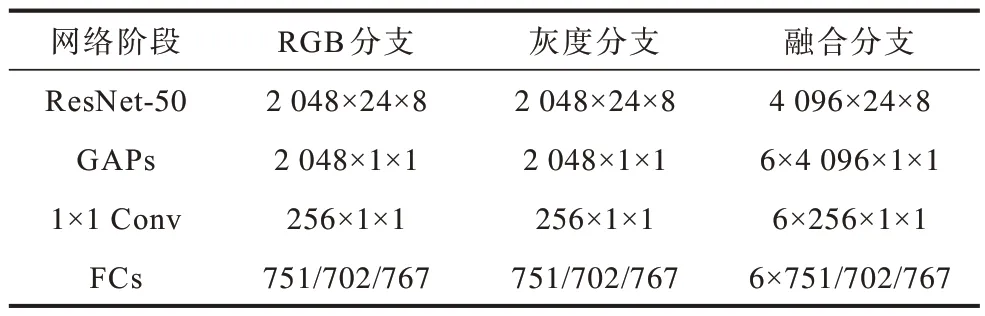
表1 3 个分支中不同网络阶段获得的特征尺寸和分类向量维度Table 1 Feature sizes and classification vector dimensions obtained at different network stages of three branches
1.2.2 图像特征提取
图像特征提取步骤具体如下:
1)RGB图像特征提取。RGB图像特征是现有ReID算法中最常用的特征,与其他类型的视觉特征相比,RGB图像特征不容易受图像尺寸、旋转和分辨率等因素的影响,能提供更具判别性的颜色信息。本文利用预训练的ResNet-50提取RGB行人图像特征,然后使用GAP获取全局均值向量,再利用1×1 Conv 降维,最后采用FC 获取行人身份分类的结果向量。
2)灰度图像特征提取。虽然使用RGB 图像特征可以很好地表示颜色信息,但颜色不一致以及颜色相近问题也会给ReID 算法带来不利影响,因此本文利用灰度图像特征解决该问题,其原因为灰度图像会在一定程度上过滤图像的颜色信息,使模型避免受颜色信息的干扰。本文采用加权平均法获取灰度图像,其定义如式(4)所示:
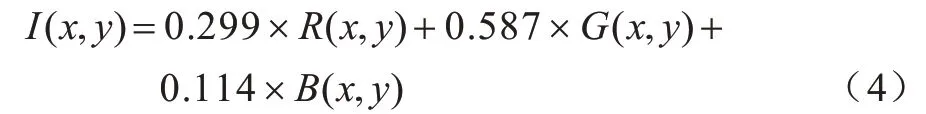
其中,I(x,y)表示转换得到的灰度图像在(x,y)位置处的像素值,R(x,y)、G(x,y)和B(x,y)分别表示RGB 图像三通道上对应位置的像素值。为便于使用ResNet-50 提取灰度图像特征,将式(4)得到的单一通道灰度图像进行三通道复制,然后输入预训练的ResNet-50 提取特征并做后续处理。
3)融合特征提取。为提取更鲁棒的行人图像特征,RGB 图像和灰度图像经过ResNet-50 最后一个卷积层提取特征后,将两个特征按照特征维度方向进行拼接得到融合特征,然后按照PCB 中统一水平划分策略对该特征进行学习。融合特征既包含丰富的颜色信息,又过滤了部分颜色的干扰信息,使模型在训练过程中能学习颜色信息与结构、形态、纹理等重要信息。
4)特征组合。将上述3 个特征进行水平方向的拼接,获得用于行人再识别的最终特征表示。
1.3 损失函数
行人再识别任务中常用的损失函数为:1)基于预测行人身份的分类损失函数,如交叉熵损失函数[25];2)基于欧式距离的度量损失函数,如对比损失函数[26]和三元组损失函数[27]等。本文网络模型在训练过程中采用交叉熵损失函数,该损失函数定义如式(5)所示:

其中:N表示训练批次的大小;C表示训练集中不同身份的行人类别数;p(c)由网络模型中Softmax 函数计算得到,其表示输入图像被预测为类别c的概率,定义如式(6)所示;q(c)表示数据真实类别标签的分布,在训练集中每个样本都只属于一个真实的身份类别,若该类别用y表示,则q(c)可表示为式(7)的形式,此时式(5)则被重新定义为式(8)的形式,式(8)表示最小化Lcross,等价于最大化某个样本被预测为真实标签类别的概率。

在本文方法中,每个特征都使用独立的交叉熵损失函数进行训练,RGB 特征、灰度特征以及融合特征的损失函数分别用LRGB、LGray和表示。为提高组合特征F 的鲁棒性,对其使用全局分类损失函LGlobal进行优化,整个网络模型的损失函数如式(9)所示:

2 实验与结果分析
2.1 数据集和评估指标
2.1.1 数据集
本文在Market1501[5]、Duke[23]和CUHK03[24]3 个数据集上进行实验。表2 给出了数据集的统计信息,其中,IDs 表示数据集中行人所属的不同身份数目,Cams 表示图像采集时使用的摄像机数目,Images 表示数据集包含的行人图像总数,Identity Split 和Image Split 分别表示训练和测试阶段分割得到的行人身份数目和图像数目。

表2 数据集统计信息Table 2 Statistics of datasets
Market1501 数据集包含由6 台摄像机(5 台高分辨率摄像机和1 台低分辨率摄像机)采集的1 501 个不同身份的行人,共有32 668 张图像,这些图像由DPM 算法[28]检测得到,其中:训练集有12 936 张图像,包含751 个身份;Gallery 集有19 732 张图像,包含750 个身份;Query 集有3 368 张图像。Duke 数据集包含由8 台摄像机采集的1 404 个身份的34 183 张图像,训练集有16 522 张图像,Query 集有2 228 张图像,Gallery 集有17 661 张图像,训练和测试过程中包含的行人身份数均为702。
CUHK03 数据集由手工标记特征和DPM 算法检测结果构建而成,并分别命名为CUHK03-labeled和CUHK03-detected 数据集,该数据集包含由6 台摄像机采集的1 467 个不同行人的13 164 张图像,其中:训练集在CUHK03-labeled 和CUHK03-detected中分别有7 365 和7 368 张图像,训练集和测试集的身份数分别为767 和700;Query 集有1 400 张图像;Gallery 集有5 332 和5 328 张图像。由于CUHK03-detected 数据集中图像边界框错位和背景杂波比较严重,对ReID 识别要求更高。以上3 个数据集在ReID 测试阶段均使用单查询设置,即将同一身份的单个待查询图像作为待查询图像。
2.1.2 评估指标
行人再识别任务常用的评估指标包括累积匹配特性(Cumulative Matching Characteristic,CMC)曲线和mAP。CMC 通常以Rank-k击中率的形式表现,表示在Query 集中的行人图像与Gallery 集中相似度最高的k张图像内命中该行人的概率。给定一个Query 集图像qi,假设其与Gallery 集中所有图像的相似度降序排序结果为r=(r1,r2,…,rn),则该qi的Rank-k计算方式如式(10)所示:
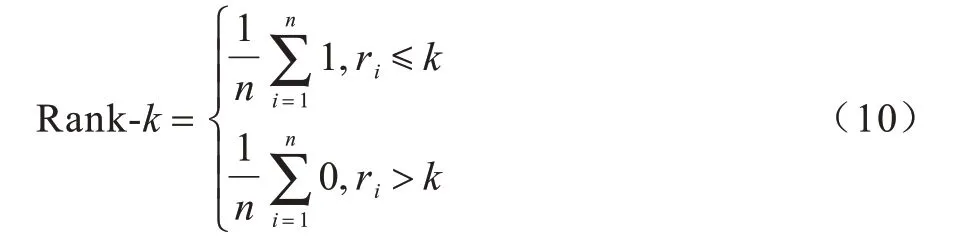
mAP 表示算法在全部测试数据上的平均性能,其与准确率(P)和召回率(R)有关。P指返回的样本中正确匹配的样本数占总样本的比例,R指返回的正确匹配的样本数占所有正确样本的比例。给定一个待查询图像qi,其AP 计算方式如式(11)所示:AP 表示求对应P-R曲线下面积,对Query 集中所有图像的AP 值求均值即可得到mAP。

2.2 实验设置
本文实验基于深度学习框架Pytorch 并在PCB网络模型[8]的基础上对PCB 方法进行优化,网络模型的输入数据大小被重新调整为384×128,数据预处理包括随机水平翻转和像素归一化等方式。训练批次大小为64,使用随机梯度下降(Stochastic Gradient Descent,SGD)算法对PCB 网络模型进行改进,网络训练周期数为100。初始学习率和预训练网络层参数的学习率分别为0.1 和0.01,在第61 个和第81 个周期学习率分别下降为0.01、0.001 和0.001、0.000 1。在测试阶段,利用已训练的模型提取特征,使用组合特征F 计算ReID 任务中的Rank-k 和mAP。在Market1501、Duke 和CUHK03 数据集上的实验均采用相同设置。
2.3 融合特征的有效性分析
为证明融合特征的有效性,在Market1501 数据集上对以下3 组特征对进行mAP 和Rank-1 实验验证:1)RGB 特征(RGB)及其与融合特征(Fusion)的拼接特征(RGB&Fusion);2)灰度特征(Gray)及其与融合特征的拼接特征(Gray&Fusion);3)RGB&Gray特征及RGB&Gray&Fusion 特征(组合特征F)。图2分别给出了3 组特征对的mAP 和Rank-1 结果,可以看出:1)单独灰度特征的mAP 和Rank-1 结果最差,但灰度特征和RGB 特征融合后可有效提高ReID 性能,证明了灰度特征能对RGB 特征进行有效补充;2)RGB 特征、Gray 特征及RGB&Gray 特征与融合特征进行拼接后,mAP 分别提升了4.4、23.6 和1.3 个百分点,Rank-1 分别提升了2.4、13.5 和0.7 个百分点,说明三者与融合特征结合后有助于提升识别准确率,证明了融合特征的有效性。3)使用组合特征F可取得最优的mAP 和Rank-1,进一步证明了融合特征可提升识别性能。

图2 Market1501 数据集上融合特征的实验结果Fig.2 Experimental results of fusion features on Market1501 dataset
2.4 分支损失函数和全局损失函数的有效性分析
在本文网络模型训练过程中,各分支都采用独立的交叉熵损失函数,而组合特征F 也使用该损失函数作为网络全局损失函数。为验证各分支损失与全局损失函数的重要性,通过分别移除RGB 分支、灰度分支、融合分支和组合特征F 的损失函数进行实验验证。表3 给出Market1501 数据集上移除各分支的损失函数后的mAP 和Rank-1 实验结果。可以看出,移除任意一个分支的损失函数都会不同程度地降低算法性能,说明在训练过程中对每个分支都使用独立损失函数的重要性和有效性,同时对组合特征F 使用全局损失函数也能提升算法性能,验证了全局损失函数对算法性能的促进作用。
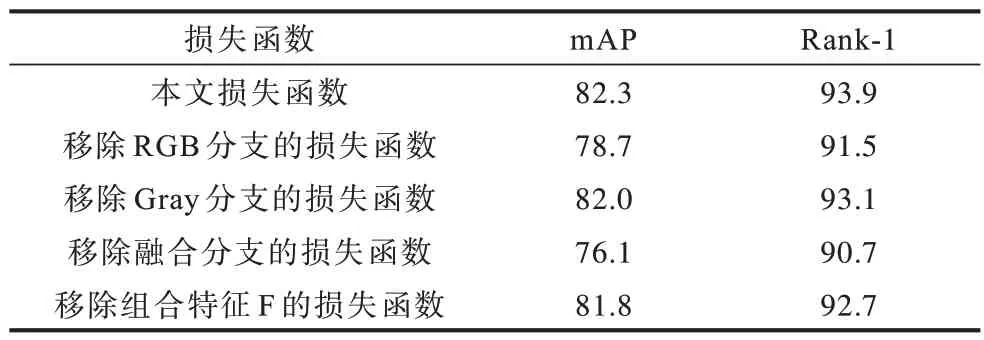
表3 Market1501 数据集上移除各分支损失函数后的mAP 和Rank-1 结果Table 3 mAP and Rank-1 results of removing the loss function of each branch on Market1501 dataset %
2.5 行人再识别方法比较
在Market1501 和Duke 数据集上得到本文行人再识别方法的mAP、Rank-1、Rank-5和Rank-10实验结果,在CUHK03 数据集上得到mAP 和Rank-1 实验结果,并与现有行人再识别方法进行比较。表4 为本文方法与对比方法在Market1501数据集上的实验结果,其中“—”表示原文献中没有该项实验结果。对比方法分为两类:1)基于特征设计的行人再识别方法,包括BoW+Kissme[5]、SpindleNet[25]、SVDNet[29]、GLAD[30]、MLFN[9]、HACNN[11]、PCB[8]、PCB+RPP[8]和Mancs[12];2)基于多任务学习的行人再识别方法,包括APR[14]、GAN[21]、Pose Transferrable[20]、MGCAM[19]、MaskReID[18]、CA3NeT[15]和SPReID[17]。可以看出,本文方法的mAP 和Rank-1分别为82.3%和93.9%,优于对比方法,比PCB 方法分别高出4.9 和1.6 个百分点,说明融合图像的RGB 特征和灰度特征能够提升识别性能。

表4 在Market1501 数据集上不同行人再识别方法的性能比较Table 4 Performance comparison of different pedestrian re-identification methods on Market1501 dataset %
表5 为本文方法与对比方法在Duke 数据集上的实验结果,其中对比方法分为两类:1)基于特征设计的行人再识别方法,包括BoW+Kissme[5]、LOMO[6]、SVDNet[29]、GLAD[30]、MLFN[9]、HA-CNN[11]、PCB[8]、PCB+RPP[8]和Mancs[12];2)基于多任务学习的行人再识别方法,包括GAN[21]、Pose Transferrable[20]、APR[14]、MaskReID[18]、CA3NeT[15]和SPReID[17]。可以看出,本文方法的mAP 和Rank-1 分别为71.3% 和84.7%,仅次于Mancs[12]方法,出现该结果的原因可能为Duke 数据集的相机视角更多变且场景更复杂,使得图像融合特征未能提供较好的判别信息,但本文方法的mAP 和Rank-1 依然比PCB 方法高出5.2 和2.9 个百分点。

表5 在Duke数据集上不同行人再识别方法的性能比较Table 5 Performance comparison of different pedestrian re-identification methods on Duke dataset %
表6 为本文方法与对比方法在CUHK03 数据集上的实验结果,其中对比方法分为两类:1)基于特征设计的行人再识别方法,包括BoW+Kissme[5]、LOMO[6]、SVDNet[29]、HA-CNN[11]、MLFN[9]、PCB[8]、PCB+RPP[8]和Mancs[12];2)基于多任务学习的行人再识别方法,包括Pose Transferrable[20]和MGCAM[19]。在CUHK03-labeled 和CUHK03-detected 数据集上,本文方法的mAP 和Rank-1 分别为64.1%、60.9%和69.3%、66.2%,优于对比方法,在CUHK03-detected 数据集上,本文方法比PCB 方法的mAP 和Rank-1 分别高出6.7 和4.9 个百分点,进一步证明融合图像的RGB 和灰度特征可以提升识别性能。

表6 在CUHK03 数据集上不同行人再识别方法的性能比较Table 6 Performance comparison of different pedestrian re-identification methods on CUHK03 dataset %
2.6 行人再识别结果的可视化分析
为更直观地展示融合特征在行人再识别过程中能够有效减少图像颜色信息带来的干扰,利用PCB方法和本文方法将Market1501 数据集中部分Query图像在Gallery 中排名靠前的匹配结果进行可视化。图3 显示排名前八但有错误匹配的结果图像,表明颜色相近对不同身份行人识别结果的影响。需要注意的是:在每组对比结果中每行的第1 张图像表示Query 待查询图像,之后是匹配结果图像;实线框表示与待查询图像的身份相同;虚线框表示与查询图像的身份不同;彩色效果见《计算机工程》官网HTML 版。从图3 可以看出,PCB 方法得到的匹配结果中匹配错误的多数是与Query 颜色非常相近的图像,说明不同身份行人图像之间的相近颜色对识别结果造成了干扰。如图3(a)所示,PCB 方法得到排名前八的结果中只有2 个正确匹配结果,而本文方法获得了4 个正确匹配结果,具有更高的识别准确率。

图3 Market1501 数据集上的部分可视化结果(相近颜色干扰)Fig.3 Partial visualization results on Market1501 dataset(interference of similar colors)
图4 显示排名前十且均为正确匹配的结果图像,表明颜色不一致对相同身份行人识别结果的影响。从图4 可以看出,在排名前十的正确匹配结果中PCB 方法得到的匹配结果容易受颜色不一致的影响,与Query 颜色不一致的图像排名较靠后。如图4(c)所示,PCB 方法中与Query 颜色不一致的图像排名为第十,而本文方法中该图像的排名为第三,说明本文方法能够有效减少颜色不一致问题所带来的干扰,即使相同身份行人图像之间存在较大的颜色差异,其排名也较靠前。

图4 Market1501 数据集上的部分可视化结果(颜色不一致干扰)Fig.4 Partial visualization results on Market1501 dataset(interference of inconsistent colors)
3 结束语
本文基于双分支残差网络,提出一种结合RGB图像特征与灰度图像特征的行人再识别方法。该方法在提取RGB 图像特征和灰度图像特征的同时,过滤掉了部分图像颜色的干扰信息,通过将行人图像的颜色特征与结构、形态、纹理等特征进行融合学习,使得行人再识别模型能提取更具判别力的特征,从而提升行人再识别准确率。在Market1501、DukeMTMC-ReID 和CUHK03 数据集上的实验结果表明,该方法具有较高的mAP 和Rank-1 准确率。后续将扩展融合RGB 图像特征与灰度图像特征的行人再识别方法的应用范围,进一步提高其适用性与鲁棒性。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02 02:00:02
高技术通讯(2021年3期)2021-06-09 06:57:48
意林(2021年5期)2021-04-18 12:21:17
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
扬子江(2019年1期)2019-03-08 02:52:34
数学物理学报(2017年5期)2017-11-23 07:51:31
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
自动化学报(2017年5期)2017-05-14 06:20:56
光学精密工程(2016年1期)2016-11-07 09:01:59
