
多级细节信息融合的人脸表情识别
2021-04-29 03:37陈文绪薛晓军许江淳史鹏坤何晓云
重庆邮电大学学报(自然科学版) 2021年2期
陈文绪,薛晓军,许江淳,史鹏坤,何晓云
(昆明理工大学 信息工程与自动化学院,昆明 650500)
0 引 言
未来人工智能将会越来越受到重视,服务业也会加入人工智能的元素,比如在医学、心理学以及服务性机器人等领域。由于在真实大自然场景下,摄像头的拍摄会受到光线等因素的影响,故而如何使人脸与过曝的背景分离,并分析出此时的人脸表情信息是一个巨大的考验。
早在2002年,文献[1-2]首次使用独立分量分析法(independent component analysis,ICA)和特征脸主分量分析法(principal component analysis,PCA)[3]在美国军方FERET(face recognition technology)数据集上对人脸表情进行实验,其识别率分别接近90%和85%。后来文献[4]通过线性分类器并结合隐马尔科夫模型法(hidden markov model,HMM)对人脸面部特征进行学习分类,之后通过该算法在CK+数据集上进行测试,人脸表情识别率为90.9%。可看出早期的人脸表情识别方法在准确率方面存在不足。在2012年的ImageNet之后出现了许多经典的神经网络模型,文献[5]使用了AlexNet模型进行人脸表情识别,并对该模型进行参数的优化,在CK+数据集上的7种表情的识别率为94.4%。为了增加网络的深度和广度,且提高研究对象的识别率,文献[6]对VGGNet模型改进为FaceNetExpNet模型,此网络模型在CK+数据集上的8种表情识别率为96.8%。文献[5]采用GoogLeNet模型在CK+数据集上的识别率为95%,其提出的基于神经网络的PPDN(peak-piloted deep network)方法在CK+数据集上的表情识别率为97.3%。
以上神经网络在对研究对象识别时均有一个特点,首先是对研究对象的特征进行提取,其次对所需要的特征进行学习,最后则是对选择后的特征进行分类,这样便形成了一个一个端到端的识别过程。关于特征识别的神经网络一般由5个部分组成:卷积、激活函数、池化、全连接以及分类。卷积在数学中的作用主要用来对输入函数进行加权累加,在神经网络中主要用来对输入图片的特征进行提取,所提取特征的数量和种类取决于卷积核数量和种类。但是卷积操作之后如果不进行激活操作,那么前面的卷积操作就只是一个简单的线性拟合问题。传统的激活函数常用sigmoid函数,但是sigmoid激活函数只能保证在0附近时函数的斜率才会很大,根据梯度调整后参数才符合要求。但远离0的部分,斜率变化会趋近于0,这样会导致梯度消失,进而影响参数的调整。为了解决这些问题,研究者们使用了Relu激活函数。由于人脸表情识别需要多种特征,则需要多种卷积核,这样会导致通道数变得很多,最后会大大增加网络的计算量。这时则可以使用池化操作对特征进行降维,同时池化操作还具有特征拥有平移不变形的性质,尽量减少特征在处理过程中的损失。由于全连接层的参数众多,许多学者目前在寻求一个替代全连接层的方案。
基于以上问题,本文提出在VGGNet16网络的侧面加入一些侧输出层(监督模块),通过上采样的方法放大特征图像,然后将网络从低级到高级进行特征融合,这样能够确保特征复用,进而减少参数量以及特征在卷积过程中的损失,并且缓解了梯度消失等问题,从而提高表情的识别率。
1 基于VGG改进的多级细节信息融合算法
1.1 VGG网络模型的改进
以VGGNet16网络结构为主,上采样和下采样操作为辅的神经网络结构,该结构中使用上采样操作中的去卷积方法,从而实现输入任意大小的图片保证输出符合要求,然后再结合下采样操作使本层特征减小一半。具体操作方法如图1。该方法在减小特征损失的同时,又大幅度减少了网络的参数量。并且使用下采样方法使侧输出层的特征图缩小一半,然后与下一层的侧输出层的特征图进行融合操作,这样能够使上层的特征图的一些特征能够尽可能保留下来。
图1中的C表示特征融合操作,卷积核后面的数字表示卷积核的个数,2个卷积核的堆叠表示进行了2次卷积操作。D表示下采样操作,U表示上采样操作,GLOBAL表示全局特征卷积操作,并对GLOBAL进行up×32操作,LOCAL表示局部特征卷积操作,SCORE表示对全局特征和局部特征进行加权融合操作。图中的3×3和5×5等卷积核是为了丰富特征映射,1×1的卷积核则是为了降低参数量,提高网络的计算效率。使用不同的卷积核来丰富网络的特征,并通过上采样方法(图中的粗箭头)把下层侧输出层的特征图放大2倍,这样使不同级之间的特征图大小保持一致,方便后面的融合操作。其中2×2 pooling为池化中的最大池化操作。
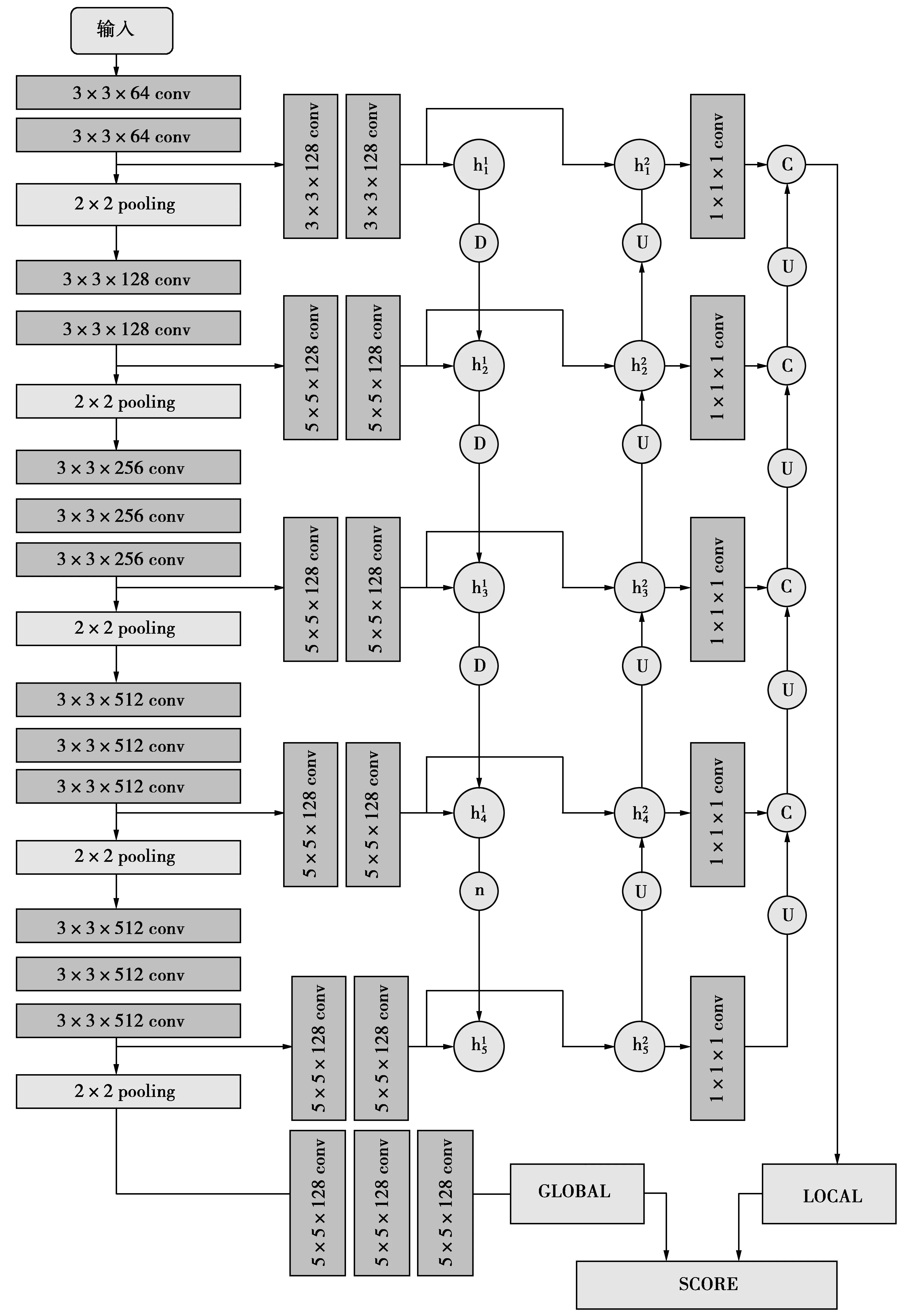
图1 基于多级细节信息融合方法结构图Fig.1 Structure diagram based on multi-level detail information fusion method
图1第1列(VGGNet16)中,输入的图像经过卷积之后得到的特征图分为2路,一路到输出层,另一路进入池化层。进入池化层的这一路经过多次的卷积和池化之后得到的特征图,最终进入GLOBAL层进行卷积操作。第2列中每个模块有2个卷积层,该卷积层的主要作用是进行特征的提取操作,丰富从低级到高级的空间特征信息。第3、第4层的侧输出层都由2层卷积核组成,卷积后的特征图一路与上一层下采样操作后的特征图进行融合,另一路则与下一层上采样操作后的特征图进行融合。第5层同样通过2层卷积核进行卷积。
1.2 融合算法
下采样的融合算法表示为
(1)
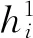
上采样的融合算法表示为
(2)
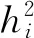
1.3 参数计算和权重训练
第l层侧输出层的激活值用Oside表示,更新后的侧输出层激活值被定义为Nside。
(3)
fusion loss函数可表示为
(4)
(4)式中:h()表示标准的softmax loss;P表示所有标准网络层参数的集合;Nside是第1层侧输出的激活值。
测试阶段中融合多个特征映射图,由融合层产生的预测值计算可以表示为
(5)
(5)式中,σ()表示softmax函数。
2 实 验
2.1 人脸表情数据集
CK+人脸表情数据集,是一个拥有2 000个左右灰度照片的人脸表情数据集。该数据集主要是在实验室中采集的,包含了其中基本的面部表情(中性、蔑视、高兴、悲伤、生气、厌恶、惊讶、害怕)。
RAF-DB[7]人脸表情数据集,由北京邮电大学的邓伟洪教授等人于2017年建立的。该数据集共收集了29 672张从真实的自然界中拍摄的照片,并不仅限于实验室和统一的灰度图像。这些图片中主要有7种基本面部表情、复合面部表情和一些研究人脸其他属性的标签图片(人的年龄范围和性别等),故而在研究人脸时具有很高的价值。
2.2 软件平台
实验所用电脑Intel i7,系统Ubuntu 16.04 Linux,语言Python,使用的神经网络模型为Tensorflow和Keras,未使用GPU加速。
Tensorflow是Google开源的深度学习机构,其具有节省时间,应用广泛,研究团队技术实力强等优点,且该架构支持目前常用的LSTM(long short-term memory)、CNN(convolutional neural networks)和RNN(recurrent neural network)等算法。
Keras神经网络框架比较容易上手,能够堆积python中关于Keras的库,且能和Tensorflow框架配合使用。
2.3 相关参数设置
神经网络训练之前必须对参数进行初始化。为了避免简单的链式计算法在进行一些具有复杂结构的神经网络时不能达到理想的效果,本文将在链式法则中采用随机梯度计算算法。
将权重初始化为接近于0的值,即保持初始参数为很小的值。由于当神经元初始参数是随机的但不相等,所以这样可以保证参数在更新后也不相同,近而保证网络的各个部分都不相同。其中权重的更新实现方法表示为
(6)
(6)式中:α表示训练过程中的学习率;W表示训练过程中的权重;J(W,b)表示整体损失代价函数。
对偏置进行初始化,通常会把偏置初始化为0。其中偏置的更新方法表示为
(7)
(7)式中,b表示偏置。
对于神经网络中的参数训练,主要参数有:初始学习速率(initial learning rate,ILR)、当前迭代次数(iterations)、批量大小(batch_size)、权重衰减(weight decay,WD)、数据集轮训次数(epoch)、惯性冲量(momentum)等。初始时学习速率设置α为0.01,并且在学习过程中通过渐变下降的方法不断更新学习速率的大小。其变化方法表示为
v=βv-αdx
(8)
x←x+v
(9)
(10)
(8)—(10)式中:β表示中惯性冲量;ηd表示学习速率衰减;v表示由3个参数量(梯度、惯性冲量、学习速率)决定的幅度;η0表示初始学习速率;s表示当前训练过程中的迭代次数。
对于参数batch_size的选定,用改进的网络模型在CK+数据集进行实验,首先设置最大迭代次数为50,并保持该值在训练过程中不变,研究batch_size的大小对训练总时间和收敛速度的影响,以及保证在指标相同的情况下该神经网络模型找到最优值所需要的迭代次数,并选择8个batch_size进行实验,实验结果如表1。由表分析可得,该算法的batch_size合适值应为128左右。
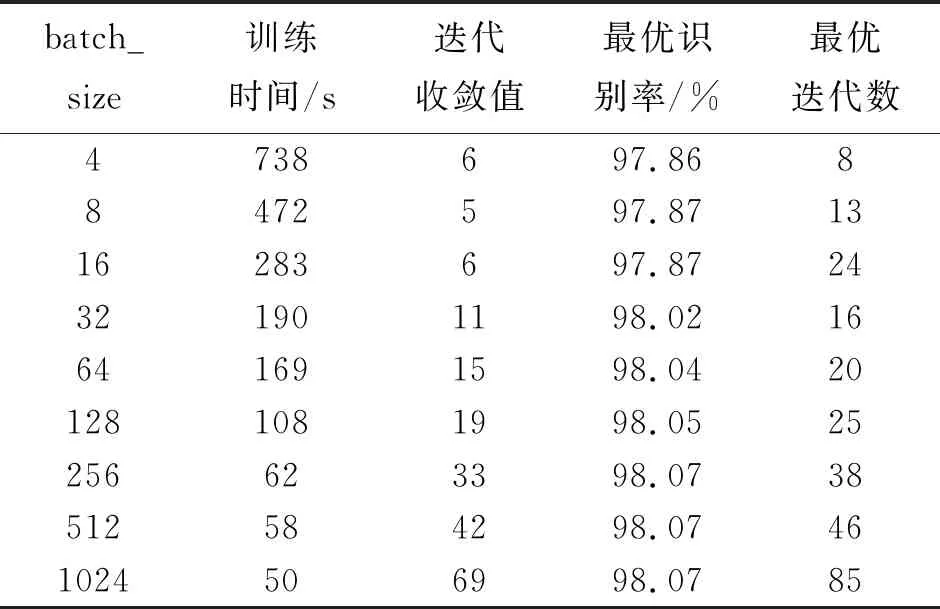
表1 关于参数batch_size的选定实验
对于epoch的选定,在CK+数据集上进行实验,首先将CK+数据集的五分之四用来作为训练数据集,五分之一作为测试数据集。然后选定epoch为70,对该数据集进行实验,发现当epoch的值为40以后训练误差train loss几乎没有改变,实验结果如图2。
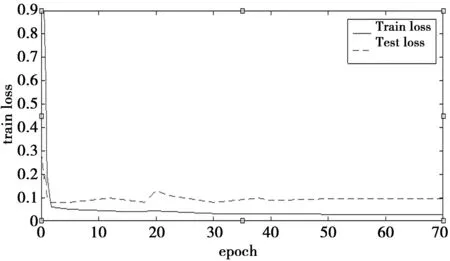
图2 训练过程中的Epoch参数的选取Fig.2 Selection of Epoch parameters during training
由以上实验结果可得主要参数设置如表2。

表2 网络相关参数设置
2.4 实验结果
2.4.1 在CK+人脸表情数据集进行实验
使用本文模型在CK+人脸表情数据集进行实验,得到验证结果如图3。图中的数字分别代表0-生气,1-蔑视,2-恶心,3-害怕,4-高兴,5-悲伤,6-惊讶。图中左侧的0到6表示样本中含有每种表情的实际样本值,下侧的0到6表示预测值,预测值表示训练模型在测试样本中测试出的每种表情所占的比例。图3中的混合矩阵表示训练模型预测出的每种表情在实际表情样本中所占的比例。通过图3中数据可以分析出,生气和蔑视等表情的识别率相对较低。图中颜色越深表示表情识别率越高,颜色越浅表示表情识别率越低。
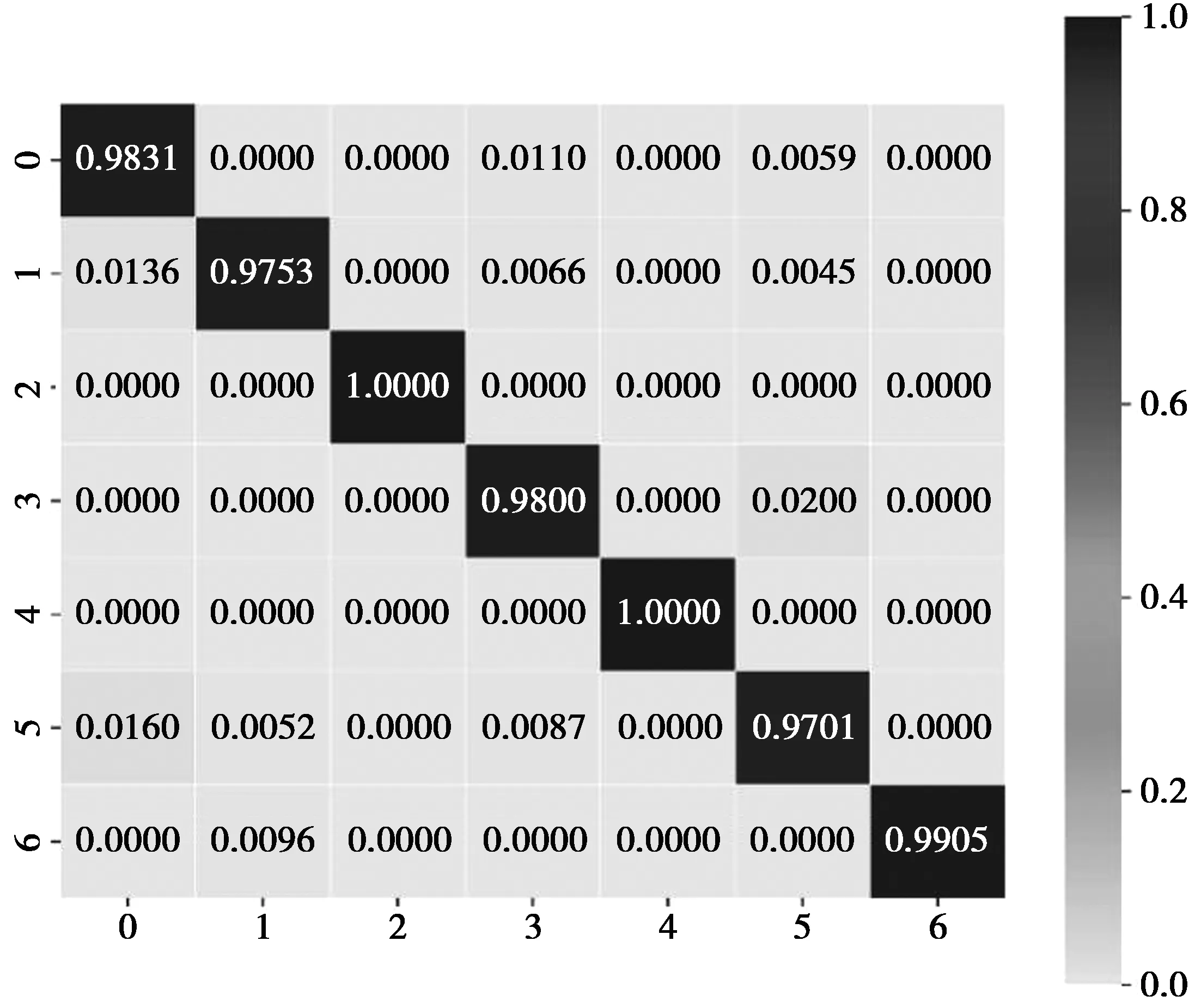
图3 CK+表情分类混合矩阵Fig.3 CK+ expression classification hybrid matrix
使用本文改进算法与其他算法在CK+数据集的实验结果进行对比,结果如表3。
本文模型与其他模型在CK+数据集上实验的迭代一次时间对比如表4。
由表3和表4可看出本文方法在保证速率的情况下,识别率超过常用的人脸表情识别方法。
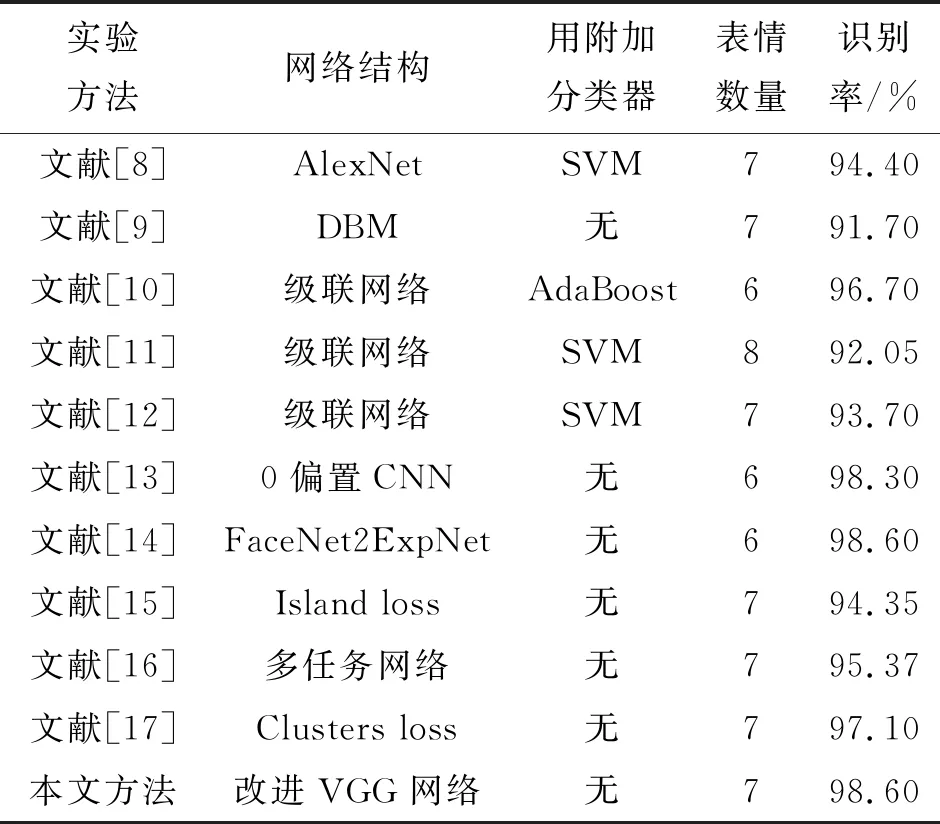
表3 常见模型与本文模型在CK+数据集上的结果对比

表4 常见模型与本文模型时间对比
2.4.2 在RAF-DB数据集进行实验
使用本文模型在RAF-DB数据集进行实验,得到实验结果的表情识别率如图4。

图4 RAF-DB表情分类混合矩阵Fig.4 RAF-DB expression classification hybrid matrix
通过图4中数据可以看出,高兴的准确率比较高,恶心和害怕在幅度较浅时比较类似,故这几种表情的识别率较低。
对比本文算法在RAF-DB数据集上的准确率与目前主流算法在RAF-DB数据集上的识别率,结果如表5。
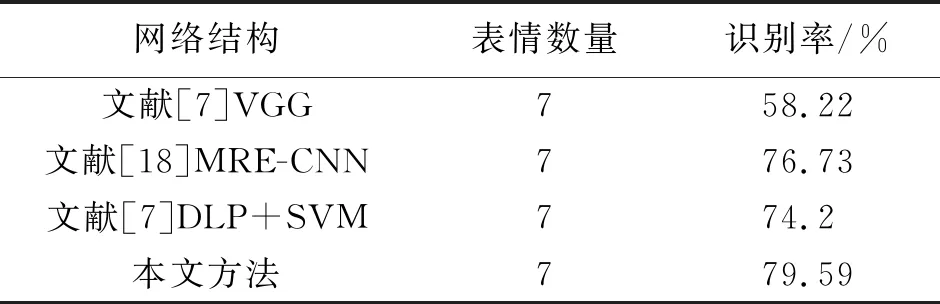
表5 常用算法与本文算法识别率对比
通过以上对比分析可以发现,本文的算法在人脸表情识别方面具有一定的优势。
3 结束语
本文提出基于VGGNet16改进的多级细节信息融合的人脸表情识别方法,选择2种人脸表情数据集CK+(在实验室中采集的)和RAF-DB(来自于真实的大自然中),通过分析和查阅文献选择合适的网络参数,使用本文方法在这2种人脸表情数据集上进行实验,使得出的结果与常用方法在数据集上的实验结果进行比对。最终实验结果表明,本文所提出的方法能够提高人脸表情匹配的识别率。但是,目前的算法对实验的硬件和软件环境有一定的要求,且缺少与微表情相关的数据集,所以下一步应该试着解决这些问题,更加丰富对人类表情的研究。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
数学年刊A辑(中文版)(2020年2期)2020-07-25
计算机工程(2020年3期)2020-03-19
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
中国听力语言康复科学杂志(2019年3期)2019-06-24
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
