
深度域适应综述:一般情况与复杂情况
2021-04-24 12:33范苍宁唐降龙
自动化学报 2021年3期
范苍宁 刘 鹏 肖 婷 赵 巍 唐降龙
机器学习已经在许多领域中成功应用,但是收集并标注与测试集具有相同分布的样本的代价是高昂的.当训练集和测试集的分布存在差异时,由训练集得到的模型不能在测试集上取得良好的预测结果.迁移学习就是解决训练集(源域)与测试集(目标域)之间存在分布差异的机器学习方法,其核心是找到源域和目标域之间的相似性,并利用相似性将在源域中获得的知识应用于目标域.迁移学习按照问题的背景设置可以划分为两类,第1 类是源域目标域标签空间和特征空间都相同的域适应,即一般情况下的域适应;第2 类是复杂情况下的域适应,其包含多个子方向,如标签空间不一致的域适应,复杂目标域情况下的域适应等.一般情况下的域适应问题是背景条件约束更严格的迁移学习问题.复杂情况下的域适应问题可以通过对一般情况下的域适应方法改进加以解决,例如,文献[1]对多对抗领域适配网络[2]进行改进来解决部分域适应问题,文献[3-4]对领域分离网络[5]进行改进来解决多目标域的域适应问题.域适应问题是迁移学习领域中的研究重点,是迁移学习的基本问题.
深度学习是近年来机器学习领域的研究热点.深度学习算法从大规模数据中提取知识,其性能显著超越传统机器学习方法.深度学习取得优异性能的原因在于深度神经网络具有很强的特征提取能力.多层的网络结构意味着可以获得关于样本的更高层次的语义信息,这种信息可以帮助网络更好地完成任务.应用在域适应问题中的深度学习方法称为深度域适应,其中心思想是用深度神经网络对齐源域与目标域的数据分布.与传统方法相比,深度域适应方法获得的特征不仅有更强的泛化能力还有更好的可迁移性.深度域适应方法正是在这个背景下兴起的.
近10 年来,一些文献[6—18]对包括域适应问题在内的迁移学习的研究进展进行了综述.文献[6]综述了传统迁移学习方法,将传统迁移学习方法划分为直推式迁移学习、归纳式迁移学习和无监督迁移学习.文献[7]按照迁移层次的不同从特征层面和分类器层面综述了迁移学习方法.文献[11]按源域和目标域特征是否同构将迁移学习分为同构迁移学习和异构迁移学习,并且对于源域和目标域特征空间维数不同情况下的异构迁移学习方法进行了综述.文献[12]对视觉应用中的域适应方法进行了综述.文献[13]对同构迁移学习和异构迁移学习方法进行了对比,并从样本、特征、参数和关系四个方面综述了同构迁移学习.文献[14]对域适应方法进行了综述,从分类损失、分布差异损失和对抗损失三个方面介绍了深度域适应方法.文献[15]将域适应划分为单步域适应和多步域适应,将深度域适应方法归纳为基于分布差异的方法、基于对抗的方法和基于重构的方法.文献[16]对深度域适应方法进行了综述,将深度域适应方法归纳为基于样本的方法、基于映射的方法、基于网络的方法和基于对抗的方法.文献[17]对单源域单目标域的同构域适应方法进行了总结,并将域适应方法归纳为领域不变性特征学习、领域映射、归一化、集成方法和目标判别方法.文献[18]对传统域适应方法和深度域适应方法进行了整体总结,从数据和模型两个层面对域适应方法进行了综述.文献[8]对迁移学习领域中近些年产生的新方向进行了综述,新方向包括传递式迁移学习、终生迁移学习、迁移强化学习和对抗迁移学习.文献[9-10]则对自然语言处理领域中的迁移学习方法进行了综述,其中,文献[9]专注于机器翻译领域.
本文从深度域适应开始进行综述,逐步扩展到更加通用的场景,即复杂情况下的域适应问题.复杂情况下的域适应问题包括标签空间不一致和复杂目标域情况下的域适应.文献[6-7,11-12]专注于对传统域适应方法的总结,而本文专注于对深度域适应方法的总结.深度域适应是当前域适应领域研究的主流方向,与文献[6-7,11-12]相比,本文总结的域适应方法是近几年出现的新方法,对读者有着更大的借鉴意义.虽然文献[8—10,13,15,18]的内容都包含了深度域适应,但它们的侧重点各有不同.文献[13]侧重于异构迁移学习,文献[15]侧重于多步域适应方法,文献[18]侧重于对域适应方法的整体总结,文献[8]侧重于传递式迁移学习、终生迁移学习、迁移强化学习和对抗迁移学习,文献[9-10]侧重于自然语言处理领域中的域适应方法.而本文的侧重点在于标签空间不一致和复杂目标域情况下的域适应方法,这是更复杂、更接近于实际情况的域适应问题解决方法.此外,虽然本文与文献[13-14,16—18]都对一般情况下的深度域适应方法进行了综述,但是本文与文献[13-14,16—18]对一般情况下的深度域适应方法的分类方式不同.不同的分类方式不存在优劣之分,只是分类的出发点不同,本文根据迁移方法的不同对一般情况下的深度域适应方法进行分类.文献[15]在对一般情况下的深度域适应方法的分类上与本文最为相似,其将深度域适应方法分为基于领域分布差异的方法、基于对抗学习的方法和基于重构的方法.本文除了这三种分类以外,还额外地分出了基于样本生成的方法.在前三种分类中,本文与文献[15]的区别表现为:1)在基于领域差异的方法中,本文归纳总结了基于图准则的方法,这是文献[15]所没有的;2)文献[15]将基于对抗学习的方法分为生成方法和非生成方法,而本文按照对抗方式的不同将其分成单对抗方法、多对抗方法以及基于注意力机制的对抗方法;3)本文按照重构的不同作用,将基于重构的方法分为三类,这也是与文献[15]不同的.文献[8]与本文同样展望了迁移学习领域中新的研究热点,但本文总结的标签空间不一致和复杂目标域情况下的域适应是文献[8]中没有的.文献[9-10]是对自然语言处理领域中的迁移学习方法进行的总结,而本文所涉及的方法都是计算机视觉领域中的.一般情况下的域适应是复杂情况下的域适应问题的基础,本文对一般情况下的深度域适应方法进行归纳总结,并使用其引出复杂情况下的域适应问题.该问题是将域适应技术应用在生产和生活中所需要解决的难点.对复杂情况下的域适应问题的研究对于域适应技术的应用起着至关重要的作用.对复杂情况下的域适应方法进行归纳总结,探究其局限性,并对其未来发展趋势进行展望,是本文的贡献之一.
域适应问题根据目标域有无标签可以分为有监督域适应和无监督域适应.无监督域适应方法可以很容易地被扩展应用到有监督域适应中,因此在域适应领域,无监督域适应方法是研究的重点.本文所综述的工作以无监督域适应方法为主.下文中提到的域适应问题均默认为无监督域适应.本文从域适应问题开始,逐步扩展到更加通用的场景,即复杂情况下的域适应,其包括标签空间不一致和复杂目标域情况下的域适应问题.该问题是域适应领域中新兴的方向但缺少相关的综述工作.所以本文对其进行归纳总结.本文的主要内容有:1)介绍了影响目标域泛化误差的因素对域适应算法设计的指导作用和抑制负迁移的方法.2)对深度域适应方法进行了综述,从领域分布差异、对抗学习、信息重构和样本生成四个方面对深度域适应方法的最新进展进行了归纳总结.3)源域和目标域的标签空间不一致是现实中的常见现象,本文重点介绍了标签空间不一致的域适应方法.4)目标域包含多个子目标域或者目标域不可知是域适应领域中两个具有挑战性的问题,本文对这一类复杂目标域情况下的域适应方法进行了综述.5)对域适应的应用进行了介绍并展示了一部分域适应方法的实验结果.6)对深度域适应方法和复杂情况下的域适应方法进行了展望和总结.总而言之,域适应,特别是深度域适应是机器学习研究领域的下一个研究热点,同时,复杂情况下的域适应问题也是将机器学习技术更广泛地应用于复杂环境下不可或缺的技术手段.本文的结构框架如图1 所示.
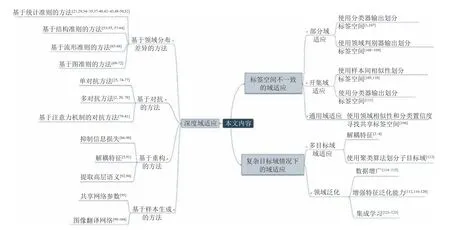
图1 本文的组织结构Fig.1 The structure of this article
1 迁移学习概述
在对深度域适应方法进行综述之前,本节首先介绍迁移学习中的术语和有关概念,包括问题的形式化定义、影响目标域泛化误差上界的因素和负迁移.
1.1 迁移学习、域适应以及深度域适应的形式化定义
在很多问题中,目标域数据的标签是不可得的,这种情况下只能使用无监督迁移学习来解决问题.与有监督迁移学习相比,无监督迁移学习更难解决.实际上,目前迁移学习领域的研究工作大部分关注的是无监督迁移学习.本文所综述的工作默认是在无监督的条件下进行的,对问题的形式化描述同样也是在无监督的情况下进行的.

域适应与迁移学习都是在源域与目标域边缘概率分布不同条件下解决如何使用源域数据来预测目标域数据标签的问题.与迁移学习相比,域适应还需要保证源域与目标域的标签空间和特征空间都相同且条件概率分布相同.域适应是一种背景条件约束更加严格的迁移学习问题.域适应问题是迁移学习问题的子集.因为域适应的条件约束更多且域适应方法能够被稍加改变来适应迁移学习中的其他问题,所以域适应是当前迁移学习问题的研究重点.
1.2 影响目标域任务性能的因素
探究影响目标域任务性能的因素十分重要,清楚各因素与目标域任务性能之间的关系可以指导域适应算法的设计.模型在目标域上的泛化误差可以作为衡量目标域任务性能的标准,探究影响目标域任务性能的因素也就是探究影响目标域泛化误差的因素.影响目标域泛化误差的因素有三个,分别是源域泛化误差、领域间差异和最优联合泛化误差.域适应探索源域和目标域之间的关系,用在源域中学习到的知识为目标域任务提供支持.在源域中获得的知识的质量将影响目标域的任务性能,知识质量越高,目标域任务性能越好;知识质量越低,目标域任务性能越差.衡量源域知识质量的一种方式是源域泛化误差.源域泛化误差是影响目标域泛化误差的因素之一.源域和目标域之间的相似性表现为源域和目标域数据分布之间的差异.当源域和目标域的分布差异大时,在源域获得的知识向目标域迁移的效果就会降低.如果域适应方法对齐了源域和目标域的数据分布,那么源域的知识向目标域迁移的效果就会增强.领域间差异同样会影响目标域泛化误差.文献[19]给出了目标域泛化误差∈t(h) 的上界:
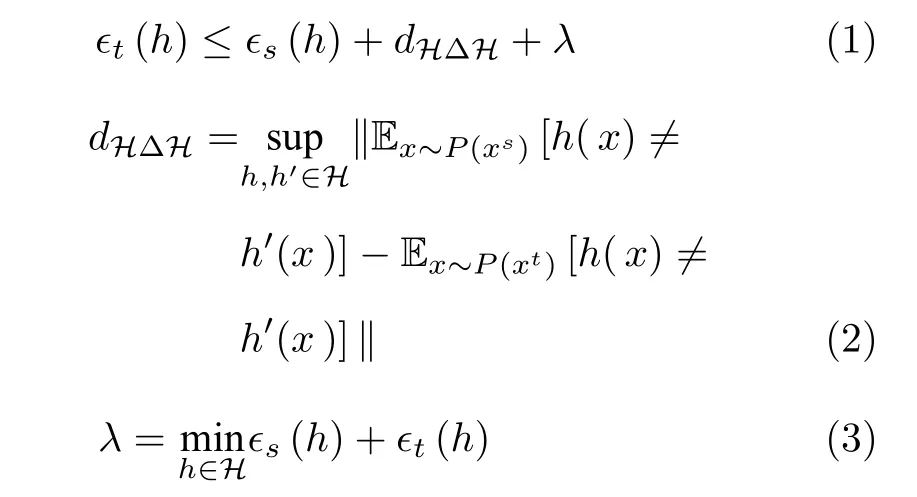
其中,∈t(h)为目标域泛化误差,∈s(h) 为源域泛化误差,dHΔH为领域间差异,λ为最优联合泛化误差,H为假设空间,h为假设空间中的某一假设.∈s(h),dHΔH和λ之和决定了目标域泛化误差的上界.式(1)可用于指导域适应算法设计,降低式(1)右侧的任何一项都可以提高域适应的性能.虽然减少源域泛化误差∈s(h) 也可以减少目标域泛化误差∈t(h)的上界,但这仅是源域中的学习任务,与知识迁移没有关系.例如将特征提取器从浅层网络替换为深层网络虽然可以提高源域任务性能,但并没有进行知识迁移.当前域适应方法研究主要关注领域间差异dHΔH,通过减少dHΔH来获得更小的目标域泛化误差上界.学习领域不变性特征[20]和生成符合目标域分布的假样本[21]是减少领域间差异dHΔH的通用做法.文献[2,22-23]的研究表明除了要对齐源域和目标域的数据分布以外,还需要考虑源域和目标域的类别信息.按类别对齐两个域能进一步减少领域间差异dHΔH. 文献[2,22-23]获得了相当程度的性能提升.文献[24]对文献[2,22-23]的思想做了总结.文献[25]对式(1)中最优联合泛化误差λ进行了分析,分别使用ResNet (Residual network)[26]、DANN (Domain adaptive neural network)[27]和MCD (Maximum classifier discrepancy)[28]三种方法对源域和目标域样本提取特征,并训练源域目标域联合分类器,用联合分类器的错误率来近似λ.文献[25]的研究结论是,知识迁移会导致λ增大.这是因为域适应既破坏了源域特征中的可判别性信息也破坏了目标域特征中的可判别性信息.在域适应过程中保持特征的可判别性不被破坏是提高域适应方法性能的一种措施,也是域适应问题的一个研究方向.
1.3 负迁移
域适应方法建立在源域和目标域具有相似性的基础上,域适应方法寻找两个域的相似性并将其利用到目标域任务中.如果不能找到正确的相似性,从源域迁移到目标域的知识就会对目标域任务起到负面作用,即在源域上学习到的知识,对目标域的学习产生了负面作用[6],这种现象称为负迁移.
描述和避免负迁移是域适应研究的关键问题之一.文献[29]建立了样本选择模型,只使用与目标域相似的源域样本进行知识迁移.目标域损失的期望等于密度比与源域损失乘积的期望:

其中,Gf和Gy分别代表特征提取器和分类器.为目标域损失期望,P(xs,ys)和P(xt,yt) 分别为源域联合概率分布和目标域联合概率[分布,P(xt,yt)/P(xs,ys) ]为密度比,Ex,y~P(xs,ys)为密度比与源域损失乘积的期望.密度比可以用来描述源域样本的可迁移性.用密度比来衡量每一个源域样本在损失函数中的重要性,以此作为权值对源域样本进行选择.Chen 等[30]提出的渐进特征对齐网络也是建立在样本选择的思想上,不同的是它对目标域样本进行选择.首先,对源域特征计算源域类别原型(类别原型是指属于该类别所有特征的均值).然后,根据目标域特征与各源域类别原型的距离对目标域样本赋予伪标签,并根据距离的大小判断其可迁移性.最后,使用源域样本与可迁移性较高的目标域样本训练网络.
如果源域和目标域之间不具备相似性,那么就无法根据可迁移性进行样本选择.在这种情况下,一些研究提出使用中间域作为桥梁连接分布差异较大的源域和目标域.这一类方法称为传递式域适应方法[31-32].
2 深度域适应
本节中的深度域适应是指使用深度学习技术来解决一般情况下的域适应问题,即单源域单目标域的无监督同构域适应问题.这一类问题是迁移学习领域中的研究重点,而且也同样是复杂情况下的域适应问题的特殊情况.本节将对深度域适应方法进行归纳总结.深度学习已经成功地应用在了许多领域,并取得了惊人的效果.对深度神经网络的可解释性研究表明网络的浅层提取模式的基本组成结构,如图像中的点、线、拐角等特征;网络的深层提取与任务相关的高层语义信息.一个训练好的网络的浅层可以作为新任务的初始模型,这种训练方式称为预训练.使用浅层网络权重初始化一个新任务网络的训练方式相当于将已有知识迁移到新的任务中,这是深度学习在知识迁移中最朴素的应用.Yosinski 等[33]研究了深度神经网络的可迁移性,并提出了两种知识迁移的方式.一种是用源域网络浅层权重初始化目标域网络,然后以微调方式训练目标域网络;另一种是冻结网络浅层权重,从头训练目标域网络深层权重.这两种方式都在迁移源域中与基本组成结构相关的知识.值得注意的是,微调技术使用了目标域中带标签的样本,即微调技术只适用于有监督迁移学习,而不能用来解决无监督迁移学习.与微调技术相比,域适应的重点在于更充分地挖掘源域与目标域的相似性,并且更灵活地在目标域任务中应用两个域之间的相似性,使在源域训练获得的知识在目标域任务中发挥更大的作用.根据深度神经网络在域适应方法中发挥的不同作用,深度域适应方法可以分为四类:基于领域分布差异的方法、基于对抗的方法、基于重构的方法和基于样本生成的方法.这四类深度域适应方法的基本特点如表1 所示.
2.1 基于领域分布差异的方法
由第1.2 节可知,领域间差异dHΔH是影响目标域泛化误差上界的因素之一.基于领域分布差异的域适应方法通过减少两个领域间的差异来减少目标域泛化误差.基于领域分布差异的方法根据对分布差异衡量准则的不同又可分为基于统计准则的方法、基于结构准则的方法、基于流形准则的方法和基于图准则的方法.
2.1.1 基于统计准则的方法
基于统计准则的方法使用均值或者高阶矩来度量领域间差异.常见的距离如下所示.
1) 最大均值差异(Maximum mean discrepancy,MMD)

表1 深度域适应的四类方法Table 1 Four kinds of methods for deep domain adaptation
MMD 是最常用的对源域和目标域分布间差异的度量,对于两个域Ds和Dt,MMD 定义为
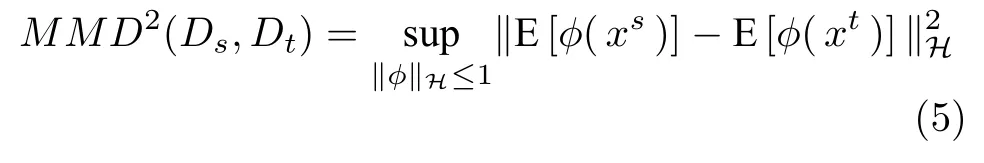
其中,φ为映射函数,将原数据映射到再生核希尔伯特空间(Reproducing kernel Hilbert space,RKHS)中.‖φ‖H ≤1 定义了一组在再生核希尔伯特空间中的单位球中的函数.MMD 的本质是在再生核希尔伯特空间中对齐源域与目标域的样本均值.在实际计算中,由于源域与目标域的真实分布是未知的,所以通常使用经验估计近似,MMD 的经验估计为
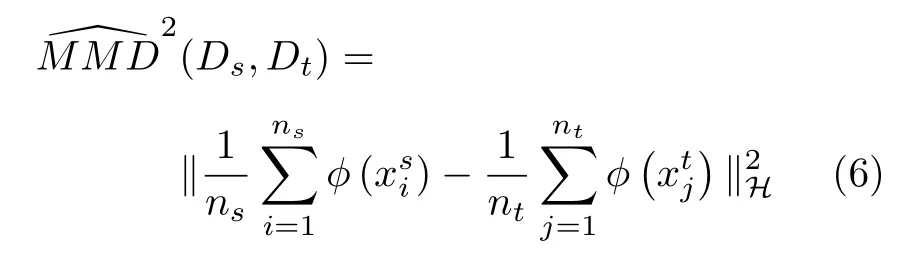
其中,ns与nt分别为源域样本数量和目标域样本数量.
领域适应神经网络(Domain adaptive neural network,DANN)[34]、深度领域混淆方法(Deep domain confusion,DDC)[35]以及深度适配网络(Deep adaptation network,DAN)[20]是最早的一批基于MMD 的深度域适应方法.这些方法将MMD 引入到神经网络当中,将源域特征与目标域特征之间的MMD 作为领域分布间距离度量加入到目标函数当中.这些方法的优化目标都由两部分组成:源域分类误差lc和MMD 损失项ld.源域分类误差lc帮助网络学习分类,而MMD 损失项ld使网络学习到分布相似的源域特征和目标域特征.DANN的结构简单,共包含两层:特征层与分类器层.由于DANN网络太浅,特征表示能力有限,故迁移知识的能力也十分有限.虽然DANN 只使用了两层的神经网络,两层的神经网络并不能称作深度神经网络,但是,DANN 是将MMD 与神经网络相结合的域适应方法,它的基本思想与随后的基于MMD的深度域适应方法基本相同.DDC 使用预训练好的Alex-Net[36]作为特征提取器,因此与DANN 相比,DDC的特征提取能力有了很大的提升.但是DDC 存在许多不足之处.首先,DDC 使用线性核计算MMD,线性核等价于两个域的均值匹配,无法实现对分布的完全匹配.其次,Yosinski 等[33]的工作已经指出AlexNet 的不同层都是可以迁移的,而DDC 只适配了一层网络,适配程度不够.最后,DDC 只采用了单个核计算MMD,单一固定的核有可能不是最优的核.DAN 基于AlexNet 搭建,其网络结构如图2(a)所示,由于AlexNet 的三个全连接层都偏向于领域专属,为提高网络的迁移能力,DAN 对Alex-Net 的三个全连接层都进行了适配.此外,DAN 为了解决如何确定最优核的问题,提出了多核MMD,多核MMD 使用多个核来构造总核,总核定义为
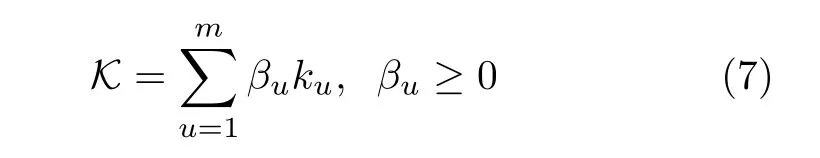
其中,βu是权重,ku代表第u个核,总核本质上是单个核的加权和.除了多层适配和多核MMD 以外,DAN 还做出了很多重要贡献:1)为了解决核方法二次复杂度的问题,DAN 提出了线性复杂度算法;2) DAN 进行了泛化误差分析,梳理了MMD 与泛化理论的关系;3) DAN 还首先形式化了域适应领域中的min-max 问题,min-max 已经成为深度域适应领域中的主流方法,在基于对抗学习的域适应方法中最为常见.
之后的一些方法通过引入类别信息改进MMD来提高域适应的性能.Long 等[23]在使用多核MMD的基础上,将特征与标签的联合概率分布考虑进来,并将这种方法称为联合适配网络(Joint adaptation network,JAN),其结构如图2(b)所示.JAN不仅对齐了两个域的边缘概率分布还对齐了两个域的条件概率分布,从而在性能上获得了更大的提升.Zhang 等[37]提出的深度迁移网络(Deep transfer network,DTN)同样在域适应过程中引入类别信息.DTN 使用MMD 同时对齐两个域的边缘概率分布和条件概率分布.DTN 使用判别器的输出计算条件MMD,即按类别计算多个MMD,通过最小化条件MMD 来对齐条件概率分布,条件MMD 的定义为

图2 部分使用MMD 的深度域适应方法Fig.2 Some deep domain adaptation methods based on MMD
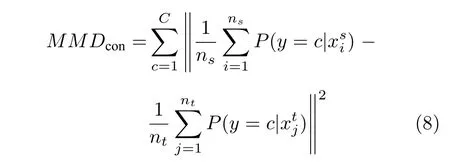
其中,c是类别,C是类别总数.由于条件MMD 引入了类别信息,从而提升了域适应的性能.
还有一些方法通过改进MMD 的不足获得了性能的提升.针对有些数据集中各类别样本的比例差异比较悬殊的问题,Yan 等[38]提出了加权MMD.MMD 可以度量两个领域之间的差异,但是源域分类器与目标域分类器之间的差异则被忽略.Long等[39]提出了残差迁移网络(Residual transfer network,RTN),RTN 使用残差层的输出来模拟源域分类器与目标域分类器之间的差异,从而将源域分类器适配到目标域分类器,其网络结构如图2(c)所示.皋军等[40]认为MMD 作为一种全局度量方法一定程度上反映的是区域之间全局分布和全局结构上的差异.针对这个问题,他们将局部加权均值引入到MMD 中,形成了一种具有局部保持能力的投影最大局部加权均值差异度量.
2) 关联对齐距离(Correlation alignment,CORAL)
以CORAL[41]作为领域间差异的深度域适应方法通过减小两个领域协方差矩阵的差异来迁移知识.CORAL 的定义为
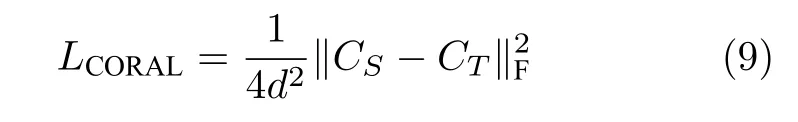
3) 中心矩差异(Central moment discrepancy,CMD)
文献[44]证明了MMD 的本质是两个域的所有阶统计矩加权和之差.Zellinger 等[45]根据文献[44]中的结论提出对齐两个域分布的高阶矩来进行知识迁移,两个域分布的高阶矩之差称为CMD,其经验估计为

4)“搬土”距离(Wasserstein distance)
除了MMD、CORAL 和CMD,Wasserstein distance 也在基于统计准则的深度域适应方法中运用,Wasserstein distance 的定义为

其中,Γ是P(xs) 和P(xt) 的所有可能的联合分布,d(xs,xt)为xs与xt之间的距离.与使用MMD 的方法类似,这一类方法通过减小领域间的搬土距离来对齐领域分布[46].文献[47]提出在优化源域联合概率分布Ps(x,y)和目标域联合概率分布Pt(x,y) 之间的搬土距离的同时学习一个目标域的预测函数f.值得注意的是,文献[46-47]将搬土距离带入到域适应问题中,但并不属于深度域适应方法.文献[48]以深度神经网络为架构,在减少源域与目标域分布之间的搬土距离的同时引入了类别信息,从而提升了模型的准确率.更进一步,Lee 等[49]提出将高维分布映射到多个方向上,分别计算搬土距离,然后再求和来计算切片搬土距离(Sliced Wasserstein distance).文献[50]受到沃瑟斯坦生成对抗网络(Wasserstein generative adversarial network,WGAN)[51]的启发,利用判别器来估计源域与目标域间的搬土距离,并以对抗学习的方式优化特征提取器来最小化这个距离.
基于统计准则的方法在统计度量最小化的约束下将数据从样本空间变换到特征空间,从而使领域分布差异在特征空间中最小化.这类方法大多数情况下都可以成功,但也存在一些缺陷.举一个极端的例子,如果将所有源域与目标域样本映射到特征空间中的一个点,源域与目标域分布之间也不存在差异,但是这种映射是没有意义的.因为在这个特征空间中,所有样本的特征表示都是相同的,网络不能进行分类任务.针对这个问题,文献[52]提出领域间最大统计量差异最小化方法,网络中包括两个特征提取器,它们在领域差异最小化的约束下分别将源域与目标域数据映射到特征空间,然后混淆网络将已得到的特征再映射到一个新的特征空间中去,并使领域差异在新的特征空间中尽可能大.在新的特征空间中,计算两个领域间差异,并使用该差异与分类损失训练网络.该方法以最大化最小领域差异的方式避免了特征提取器将所有样本映射到空间中同一点的情况的发生.
基于统计准则的方法以源域和目标域之间的分布距离作为损失函数,使用深度神经网络提取领域不变性特征.这类方法已经取得了许多研究成果,发展空间有限.从提取领域不变性特征这方面来看,对抗学习是一个更有发展潜力的方向.原因是:一方面,与设计一个复杂的领域间距离相比,对抗网络更加容易实现;另一方面,对抗学习避免了人为设计距离,网络在训练的过程中自发地学习两个领域应该对齐什么以及对齐到什么程度,通常能够获得更好的效果.
2.1.2 基于结构准则的方法
基于结构准则的方法通过约束网络参数或者改变网络结构的方式来达到迁移知识的目的.这一类方法大体上是沿着两个方向进行发展的.1) 通过正则项保证源域与目标域网络参数之间具有相关性.这种做法是受到域适应问题中数据集特点的启发而产生的:源域与目标域数据分布相关,那么源域网络与目标域网络的参数也应具有相关性.2) 通过增设领域专属的批归一化层来减小领域之间的差异.这种做法与基于统计准则的方法具有相似性.它们都希望得到具有相同分布的领域特征.不同的是,基于统计准则的方法需要明确度量准则,而这种方法并不需要.此外,还有一些方法通过改变网络结构来进行知识迁移.这类方法的思路各不相同,但都可以归类于基于结构准则的方法中.本节将对这些方法进行详细介绍.
基于统计准则的方法通常使用同一个特征提取器对源域与目标域的样本提取特征,但实际上源域数据与目标域数据分布虽然不同,但存在相关性,因此,两个领域使用的特征提取器虽然不同,但也应存在相关性.一些基于结构准则的方法使用两个特征提取器分别处理源域样本和目标域样本,并保证两个特征提取器之间存在相关性.这类方法使用相同的方式搭建两个域的特征提取器,并对网络参数的相关性进行约束,从而建立起两个领域之间的关系.Rozantsev 等[53]使用权重正则项rw(·) 来衡量网络参数之间的差异,权重正则项rw(·) 可以表示成指数函数的形式,即
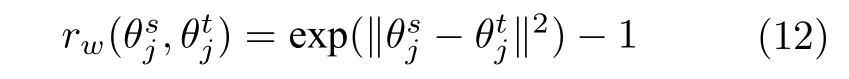

其中,aj和bj是线性关系的参数.Shu 等[54]提出弱参数共享层,弱参数共享层中的每一个领域都有专属的网络参数,惩罚项 Ω 控制参数之间的关联程度.
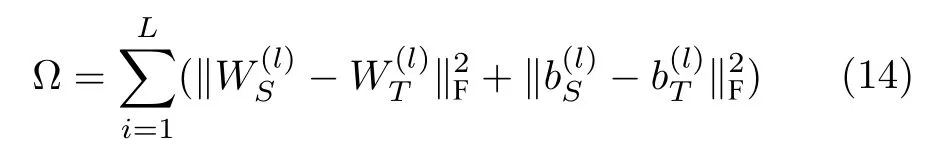
在深度神经网络训练过程中,网络参数的变化会导致下一层输入的分布变化.当某一层的输入过大或者过小时,其对应的激活函数的导数就会变得很小,导致网络的训练变得缓慢.这个问题称为内部协变量偏移(Internal covariate shift).Ioffe 等[56]提出批归一化(Batch normalization,BN)方法来解决这个问题.批归一化方法对网络中每一个激活函数的输入进行归一化.每个输入都位于0 的附近,避免了激活函数导数过小的情况,提高了训练速度.然而,这个方法只适用于数据服从同一分布的传统机器学习问题,而不适用于域适应问题.为了解决域适应问题中的协变量偏移,研究者们提出了一系列方法对批归一化层进行改进.对批归一化层进行改进的方法不仅可以解决协变量偏移问题,还可以有效地减小领域间分布差异,其思想是借助批归一化层将源域分布与目标域分布映射到相似的分布上.Chang 等[57]提出了一种名为领域专属批归一化的方法,在网络中使用两个领域专属的批归一化层代替共享的批归一化层,使得网络能够更加适应对应领域的数据.批归一化层独立地对特征的每一个维度进行标准化而并不考虑特征之间的相关性.Roy等[58]认为这种归一化方法不足以对齐源域与目标域分布,故而提出使用领域专属白化层来代替网络中的批归一化层,白化层的定义为
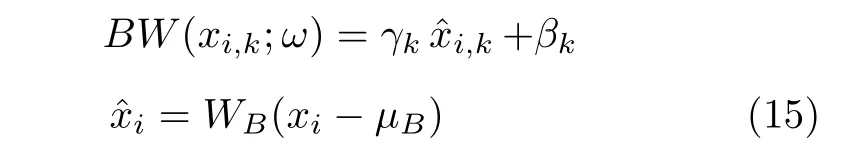
式中,γk和βk是从目标域学习到的参数,μB是均值,是B的协方差矩阵,ω=是B的一阶矩和二阶矩.与批归一化层相比,特征白化层由于考虑了每一个维度特征间的关系而获得了更好的对齐效果.Li 等[59]认为与类别相关的信息都存储在网络的权重矩阵中,而与领域相关的信息则存储在批归一化层的统计量中,文献[59]提出批归一化层对每一个特征通道的均值和标准差都进行归一化,从而使得无论数据来源于哪一个域,每个层所接收到的数据都服从一个相似的分布.
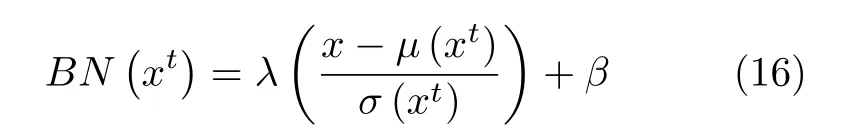
其中,λ和β是从目标域学习到的参数,μ(x) 和σ(x)是每一个特征通道的均值和标准差.文献[60]进一步提出使用样本归一化层来代替批归一化层,样本归一化层对每一个通道、每一个样本都计算一个μ(x) 和σ(x) .这种方式可以使得域适应的效果获得很大的提升.另外一些研究者提出赋予批归一化层一系列的对齐参数[61],这些参数可以自动学习并且可以决定网络不同位置的领域对齐程度.
还有一些方法不能被归为一类但同样属于基于结构准则的方法.文献[62]提出领域偏见的概念:并不是所有的神经元在迁移的过程中都是有用的,某一些神经元捕捉到的特征可能只适用于源域而不适用于目标域.文献[62]提出了领域引导dropout,这种方法将与当前域无关的神经元舍去,根据损失增益来决定是否使用这个节点,增益定义为
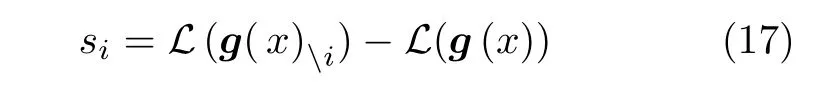
其中,L是损失函数,g(x)为特征向量,g(x)i是将第i个神经元的输出置为0 后的特征向量.Wu 等[63]将协同学习引入到域适应问题中,该方法除了包含一个适配网络之外还包括一个目标域专属网络.适配网络指导目标域专属网络的输出.这样做的好处是目标域专属网络可以学习出目标域专属信息.Zhang 等[64]提出了领域对称网络(Domain-symmetric network,DSN).DSN 不仅共享特征提取器还共享分类器.分类器的最后一个全连接层被一分为二,一半用于源域分类器,另一半用于目标域分类器,整个全连接层用来作为源域目标域整体的分类器.DSN 使用源域样本来训练源域分类器与目标域分类器,并使用领域标签训练整体分类器.
2.1.3 基于流形准则的方法
测地线是在格拉斯曼流形上连接两个点的最短路径.基于流形准则的方法将源域空间与目标域空间作为格拉斯曼流形上的两个点,并在源域与目标域之间构建一条测地线来度量两个领域之间的分布差异.基于流形准则的方法或通过对齐特征或通过生成中间样本进行知识迁移.对齐特征的方法通过在测地线上采样有限个[65]或无限个[66]子空间来建立源域与目标域之间的联系,这种方法将源域和目标域映射到中间子空间来对齐分布;生成中间样本的方法采用数据增广的思想生成一系列介于源域和目标域之间的样本进行知识迁移.Chopra 等[67]提出了一种域间插值的深度域适应方法(Deep learning for domain adaptation by interpolating between domains,DLID),DLID 产生一系列的中间数据集,数据集中的样本样式从与源域样本相似逐渐变化到与目标域样本相似.每一个数据集都是测地线上的一个点.每当一个中间数据集产生之后,该方法都会使用预测稀疏分解方法来训练一个特征提取器.文献[68]提出了领域流生成模型,将源域数据与领域变量(控制中间域与源域的相似性)作为输入,将源域图像翻译成中间域图像,通过使用中间域图像作为额外的训练样本使源域模型逐渐适用于目标域任务.
2.1.4 基于图准则的方法
基于图准则的方法将样本与样本间关系抽象成图结构,并使用图之间的差异来度量领域间分布差异.如果把样本看作点,样本间的相似度看作边,那么数据集就可以视为一个无向图.以这个思想为基础,研究者们提出减小源域图与目标域图之间的差异来迁移知识.如果源域数据所表示的图与目标域数据所表示的图相似,则认为源域模型可以很好地适配目标域.基于图准则的方法在知识迁移过程中由于考虑了领域分布结构从而获得了更好的知识迁移效果.Xu 等[69]提出使用样本间距离来描述样本间的近邻关系,对于每一个目标域样本,计算它与每个源域样本之间的相似度,并以此来描述该目标域样本与源域各类别的近邻关系,将相似度作为优化目标的一部分来训练网络.经过训练的网络最终会生成与源域样本近似的特征表示.在对齐图的基础上,文献[70]将类别信息引入到了迁移过程中,提出了一种无监督图对齐方法.这种方法将图中的边分为两类:一种是类内边,类内边连接属于同一类别的两个样本;另一种是类间边,类间边连接属于不同类别的两个样本.训练的目标是类内边尽可能小,而类间边尽可能一致.这种方法不仅对齐了源域与目标域的分布还增强了特征的类别可区分性.文献[71]同样将类别信息引入到了迁移过程中,它使用目标域分类器生成目标域样本的伪标签,然后通过对齐两个领域类别质心的方式来对齐条件概率分布.还有一些方法使用神经网络以样本为输入直接输出图结构.Yang 等[72]提出了关联图预测网络.关联图是一个矩阵,用来描述数据单元之间的关系,其本质是一个相似性矩阵,源域样本以及关联图被用来训练关联图预测网络.由于源域与目标域之间存在关联性,源域关联图预测网络可以直接使用在目标域上.在迁移阶段,使用关联图预测网络对目标域数据输出关联图,并使用关联图与特征共同分类目标域样本.
图神经网络是一类基于深度学习的处理图信息的方法.由于其较好的性能和可解释性,图神经网络已成为一种广泛应用的图分析方法.到目前为止,图神经网络还没有应用于基于图准则的域适应方法中,在未来的研究中,图神经网络与域适应问题相结合将能进一步推动域适应领域的发展.
2.2 基于对抗学习的方法
基于对抗学习的域适应方法将生成对抗网络(Generative adversarial network,GAN)[73]的思想引入到域适应问题当中.对抗域适应的训练过程是特征提取器与领域判别器之间的博弈过程:领域判别器通过学习来区分源域特征与目标域特征,而特征提取器通过学习具有领域不变性的特征来混淆领域判别器.训练完成后的网络就可以提取出既具有类别区分性又具有领域不变性的特征表示.基于对抗学习的方法按照对抗方式的不同可以分为单对抗域适应和多对抗域适应.此外,还有一些方法没有在对抗方式上进行改进,而是将注意力机制引入到对抗域适应中,这一类方法同样被归类到基于对抗学习的方法中.
2.2.1 单对抗方法
单对抗方法是指使用单个领域判别器的对抗域适应方法.Ganin 等[27]首先将对抗学习应用到域适应问题当中,提出领域对抗神经网络(Domain adversarial neural network,DANN),网络结构如图3 所示.在对抗域适应中,领域判别器的优化目标是最小化领域判别器的分类损失,而特征提取器的优化目标是最大化领域判别器的分类损失.为了在训练过程中同时满足这两个截然相反的优化目标,Ganin 等[27]提出了梯度反转层(Gradient reversal layer,GRL),其作用是当领域判别器的分类损失的梯度反向传播经过判别器之后,对梯度取反,然后将其继续反向传播到特征提取器.梯度反转层使网络能够保证在领域判别器最小化领域混淆损失的同时特征提取器最大化领域混淆损失.DANN 的目标函数可以表示为

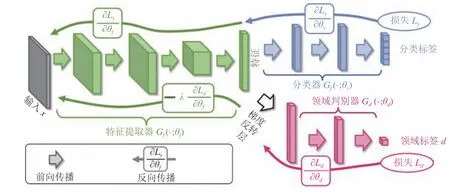
图3 领域对抗神经网络的网络结构Fig.3 The network structure of DANN
其中,θf,θy,θd分别为特征提取器、分类器与领域判别器的参数,Gf,Gy,Gd分别为特征提取器、分类器与领域判别器,ns,nt分别为源域样本与目标域样本的数量,yi,di分别表示类别标签与领域标签,λ为权重系数.值得注意的是,DANN 同时也等价于最小化源域特征和目标域特征的詹森—香农(Jensen-Shannon)散度.从这个观点来看,DANN也可以归为基于统计准则的域适应方法.Chen 等[74]发现对抗域适应方法虽然能够增强特征的可迁移性,但是会降低特征的类别可区分性,该研究从谱分析的角度说明了特征的可迁移性主要存在于特征矩阵特征值较大对应的特征向量中,而特征的可区分性则依赖于特征矩阵的大部分特征向量.所以他们提出在训练过程中加入批谱惩罚项来保证特征值之间的差距不会过大,即保证特征的可区分性.在DANN 中,对特征提取器的共享导致了特征提取器不能提取源域和目标域的领域专属信息.针对这个问题,对抗判别域适应(Adversarial discriminative domain adaptation,ADDA)[75]采取了权重不共享的方式,源域特征和目标域特征独立提取.源域和目标域的网络结构相同,目标域模型参数使用源域预训练模型的参数初始化.相对于DANN 来说,由于参数不共享,特征提取器可以提取更多的领域专属特征.ADDA 以迭代的方式最小化以下函数来最小化源域特征与目标域特征之间的距离.
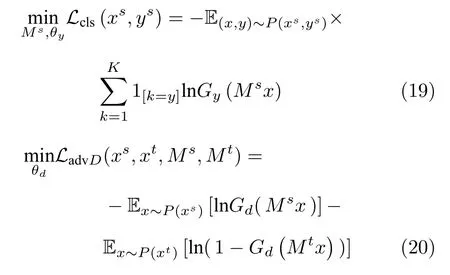
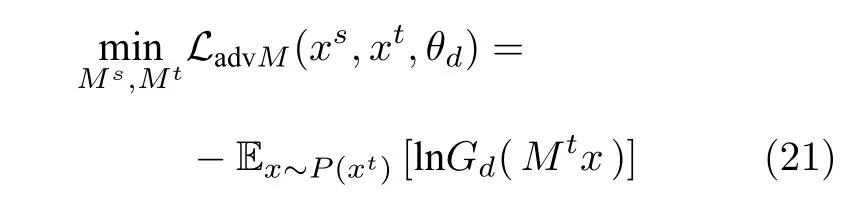
其中,映射Ms,Mt分别从源域数据xs和目标域数据xt中学习,Gy代表源域分类器,分类损失Lcls使用源域数据最小化,LadvD用来训练领域判别器,LadvM用来学习领域不变性的特征表示.Volpi 等[76]使用特征生成器在源域特征空间中进行数据增广,并且使用领域判别器区分生成特征与真实特征来对齐生成样本与目标域样本的分布.Vu 等[77]提出了一种基于对抗熵最小化的语义分割域适应方法来对齐源域与目标域的标签结构信息.该方法使用分割图(图中元素代表像素属于某个语义标签的概率) 生成加权自信息矩阵,将分割图的熵(加权自信息矩阵的元素之和)作为网络损失项的一部分来优化网络,使网络输出置信度更高的语义标签预测.网络最终使用领域判别器在源域与目标域的加权自信息矩阵间进行对抗.单对抗方法使用单个领域判别器,意味着单对抗方法只能对源域和目标域的整体分布进行对齐,这是单对抗方法的一个缺陷.
2.2.2 多对抗方法
多对抗方法是指使用多个领域判别器的对抗域适应方法.单对抗方法的分布对齐能力有限,只能够对齐源域与目标域的边缘分布,并不能够保证条件概率分布同样被对齐.而多对抗方法除了能够对齐边缘分布以外还在对抗学习的过程中引入类别信息来对齐条件概率分布.
Pei 等[2]提出了多对抗域适应(Multi-adversarial domain adaptation,MADA),使用多个类别领域判别器来对齐两个域的数据分布.每一个类别领域判别器只负责对齐其对应类别的概率分布.还有一些方法虽然没有使用多个领域判别器,但通过引入类别信息获得了与使用多个领域判别器方法同样的效果,故也被归类到多对抗方法中.Long 等[22]提出了条件领域对抗网络(Conditional domain adversarial networks,CDAN),其结构如图4 所示.CDAN 的创新点在于将特征与分类器输出的外积作为新的特征输入到领域判别器中,新的特征能够捕捉到隐藏在复杂数据分布下的多峰结构,该方法取得了良好的效果.Tzeng 等[78]将源域中属于同一类别样本的分类器输出均值作为类别软标签.在训练目标域分类器时,使用一部分带标签的目标域数据得到目标域分类器的输出,通过对齐输出与对应类别的软标签达到了对齐条件概率分布的目的.
2.2.3 基于注意力机制的对抗方法
图像的不同区域的可迁移性是不同的,可迁移性低的区域在训练过程中会造成负迁移.域适应方法需要着重对图像中与任务相关性高的区域进行知识迁移而忽略其他不相关的背景信息.在对抗域适应中,有一类方法将重点集中在寻找特征图中可迁移性较高的区域.Kurmi 等[79]使用贝叶斯分类器和贝叶斯领域判别器分别输出分类器的不确定性和领域判别器的不确定性,通过反向传播算法使用不确定性来反推特征图中每个区域的领域不确定性.领域不确定性高的区域被认为可迁移性较高,将会被着重对齐.Wang 等[80]将注意力机制引入到对抗域适应方法中,使网络能够自动学习到在迁移的过程中需要注意哪些部分.特征图被划分为k个区域,每一个区域都对应一个领域判别器.在训练结束之后,领域判别器难以区分的部分被认为是可迁移性较好的部分,通过对这些部分赋予更大的权重,网络实现了在训练中着重对迁移性好的区域进行对齐.参数k通常不会设定比较大的值,划分过多的区域会增加训练的复杂度,因此该方法只能获得有限的性能提升.Luo 等[81]提出了一种基于协同学习与类别对抗的语义不变性域适应方法,其网络结构包括特征提取器、两个分类器以及领域判别器.该方法应用在图像语义分割中.训练过程约束两个分类器的参数是不同的,从而保证分类器能够从不同视角给出图像中每一个像素的语义标签.对于源域数据来说,两个分类器使用集成学习的方式给出预测图用来计算分割损失以及领域对抗损失.对于目标域数据,网络使用距离函数计算两张预测图中对应像素的距离,并生成注意力图,注意力图被送到领域判别器中进行领域对抗.这样做的目的是迫使领域判别器着重处理在目标域中两个分类器不一致的区域.已有的深度神经网络的可解释性研究[82—84]探究的是特征图中的不同区域对网络预测结果的影响.目前,深度域适应还缺少对网络可解释性的研究.如果有研究能够发现特征图中的不同区域对迁移效果的影响.那么这个研究成果就可以直接应用到基于注意力的对抗域适应方法中.
2.3 基于重构的方法
基于重构的方法是指使用自编码器提取具有可迁移性特征的方法.自编码器[85]是实现重构的基本网络结构,是一种可以用来抑制信息损失的无监督学习方法,由一个前馈神经网络组成,包括编码解码两个过程.自编码器首先将输入映射为编码,然后又将编码重构回输入,通过使用输入作为标签来解决“没有老师的反向传播”问题.自编码器通过最小化信息损失来重构输入,保证编码保持数据原有的特性.基于重构的域适应方法的优点是能够保证迁移过程不会破坏数据原有信息.在域适应问题中重构可以起到三种作用:1) 域适应过程会破坏样本中的可判别信息[25],而重构方法可以降低信息的损失;2) 重构方法可以将特征解耦为领域专属特征和领域不变性特征,领域不变性特征用来迁移知识,而领域专属特征则用来辅助完成目标域任务;3) 重构可以提取特征的高层语义,研究者们可以通过重构将输入分解为多个具有具体语义的部分,并重构回输入.下面,本文根据重构的不同作用将基于重构的方法分为三类依次介绍.

图4 条件领域对抗网络Fig.4 Conditional domain adversarial network
2.3.1 使用重构抑制信息损失
域适应通过寻找领域不变性信息进行知识迁移,将输入映射到领域不变性特征的过程会丢失领域专属信息.丢失的信息是有可能有益于任务的,因此需要使用重构抑制信息损失.文献[86-87]使用源域和目标域的所有样本来训练自编码器,然后在源域编码上训练分类模型,并将分类模型直接应用在目标域上.这类方法简单易用,但是由于自编码器不能提取领域不变性的特征,故迁移能力有限.
文献[86-87]之后的方法通过增加各种约束来增强编码的表示能力.深度重构分类网络[88]将源域样本标签信息嵌入到编码中,在训练自编码器的同时训练一个以编码为输入的分类器,增强了编码的类别可区分性.基于深度自编码器的迁移学习方法(Transfer learning with deep autoencoders,TLDA)[89]使用自编码器对输入进行两次编码:输入首先被映射成一次编码,然后一次编码被映射成二次编码.重构过程也分为两个步骤:二次编码被重构回一次编码,然后一次编码被重构回输入.与文献[88]将标签信息引入编码的方式不同,TLDA 直接将二次编码作为分类结果,将二次编码与样本标签的差异作为损失项来引入类别信息.另外,TLDA在训练过程中通过减少源域样本与目标域样本一次编码的KL (Kullback—Leibler)散度来对齐领域分布.除了减小两个领域编码间的距离之外,有的研究还使用其他的方式来对齐分布.例如Sun 等[90]的工作使用对抗学习来对齐分布,在领域判别器区分源域重构样本和目标域重构样本的同时,自编码器生成难以区分的重构样本.重构样本分布差异最小化使得编码分布差异也最小化.通过这种方式,自编码器可以提取领域不变性的编码.
2.3.2 使用重构解耦特征
使用自编码器解决域适应问题的初衷是在特征提取的过程中不损失可迁移性信息.但抑制信息损失也会引入新的问题:特征不仅仅包含领域不变性信息,同时也包含领域专属信息,源域专属信息不仅不能用于迁移甚至还会造成负迁移.为了减轻源域专属信息造成的负迁移,一些重构方法提出将领域专属信息与领域不变性信息分离[5,91].在领域分离网络(Domain separation network,DSN)[5]中,源域和目标域样本都使用领域共享编码器和领域专属编码器进行编码.该网络使用子空间正交约束来保证领域专属信息和领域共享信息没有交集.
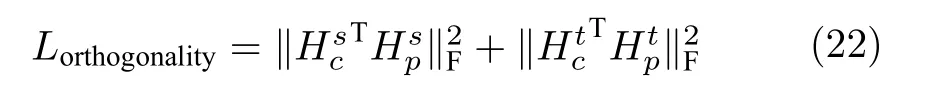
2.3.3 使用重构提取高层语义
自编码器学习一个包含输入所有信息的编码,编码中每一个值所代表的含义是不明确的,研究者们为网络提供训练数据,并设定损失项,接下来的学习过程完全是网络自发进行的.怎样提取特征以及提取什么样的特征,这一整套逻辑隐含在网络的结构与参数中而不为人所知.在认知科学领域,科学家发现人们通过少量学习来进行有意义的概括,将观察对象解析为各个部分并从各个部分中生成新的概念.受到人类学习过程的启发,研究者们试图让自编码器能够将输入解析为多个有实际意义的部分,并依据这些部分重构回输入.物体部件之间的迁移性总是好于两个物体之间的迁移性,这种先分解再重构的概念学习模式适用于域适应问题.Zhu等[92]使用多注意力卷积神经网络(Multi-attention convolutional nerual network,MACNN)[93]寻找样本间共有的且具有类别区分性的视觉部件原型,然后使用自编码器将输入分解为多个视觉部件,每个视觉部件都由已知的部件原型的高斯混合分布来描述,最后由视觉部件重构回输入,其网络结构如图6所示.Zhao 等[94]的工作同样使用自编码器学习具有语义信息的编码.与文献[92]不同的是,Zhao 等[94]不利用网络来获取语义信息,而是要求数据集中每一个样本都对应有一个语义向量,在自编码器训练过程中,将语义向量作为编码的监督信息,学习具有语义信息的编码.
2.4 基于样本生成的方法
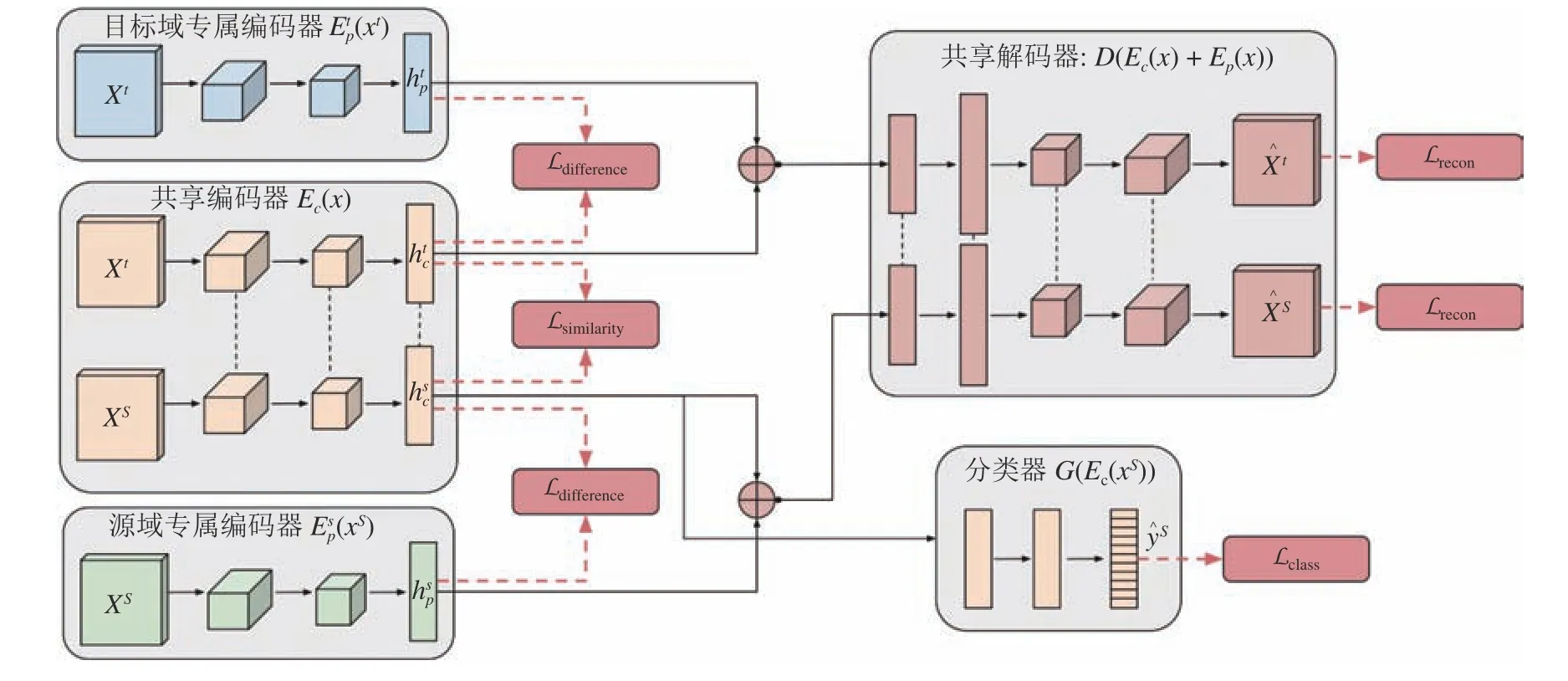
图5 领域分离网络Fig.5 Domain separation network

图6 文献[92]所使用的网络结构Fig.6 The network structure used in [92]
域适应将从源域中学到的知识迁移到目标域,上文中总结的域适应方法或者寻找一个从源域特征到目标域特征的映射或者寻找两个域的领域不变性特征.尽管这些方法取得了一些效果,但是仍然不及目标域有标签时的监督学习方法取得的性能.基于样本生成的域适应方法是指使用源域样本合成带标签的目标域样本,并使用合成样本训练目标域网络的方法.从理论上来说,基于样本生成的域适应方法在训练过程中可以使用无限的数据.充足的数据正是获得一个性能优良的模型的关键之一.与其他的域适应方法相比,这一类方法的可解释性更强,通过观察合成的目标域样本与真实目标域样本之间的差异就可以判断当前方法是否学习到了一个较好的从源域到目标域的映射.而其他的域适应方法就只能间接地通过目标域任务网络的性能来推测使用的方法是否有一个很好的迁移效果,这显然不够直观.
最常用的生成模型就是生成对抗网络(GAN).GAN 包括生成器和判别器.生成器用来合成图像,判别器用来区分真实图像与合成图像.GAN 的训练过程就是生成器与判别器之间相互博弈的过程.当判别器已不能将合成图像从真实图像中区分出来时,生成器就已经具备了合成逼真图像的能力.在GAN 中,生成器的输入是噪音,而输出则是合成图像.由于GAN 不能生成合成样本的标签,所以只使用GAN 不能够完成目标域中的任务.基于样本生成的域适应算法的关键是建立起源域样本与合成样本之间的关系,并利用这个关系从源域样本标签推测出合成样本的标签,继而使用合成样本训练模型.共享网络参数和图像翻译网络是样本生成的主要方式.其中,基于图像翻译网络的方法是主流方法.
2.4.1 共享网络参数
Liu 等[95]提出在生成器中,浅层网络在解码语义信息,深层网络在解码细节信息,而在判别器中,信息处理的方式恰好是相反的,即浅层网络在提取细节信息,深层网络在提取语义信息.他们提出使用两个生成器,一个用于生成源域样本而另一个生成目标域样本.通过共享两个生成器的浅层网络参数来生成具有相同语义信息的样本.由于两个域的同类别样本共享相同的语义信息,具有相同语义信息的样本具有相同的类别标签,所以目标域合成样本的标签可以通过源域样本的标签得知.
2.4.2 图像翻译网络
除了使用共享网络参数的方法之外,更多的方法使用翻译网络来建立源域样本与目标域样本之间的关系.翻译网络是指将源域样本作为输入来生成符合目标域分布的合成图像的网络.实际上,翻译网络在被引入迁移学习问题之前就已经应用于风格迁移等诸多计算机视觉应用.翻译网络是一种很常见的监督学习方法,其使用样本对(Sample pair)作为训练数据.域适应问题的数据集不包含样本对,所以研究者们在网络的训练过程中添加特殊约束来保证翻译网络输入输出的类别标签一致性.文献[96]提出对偶学习方法,在最小化重构损失的同时学习两个方向相反的翻译器.对偶学习使两个翻译器在训练过程中形成一个闭环,两个翻译器相互促进学习得到了比训练单个翻译器更好的模型性能.以CycleGAN 为代表的一类方法[21,97-98]引入对偶学习来达到这样一个目的:在没有样本对的情况下,捕获目标域数据集的特征,并将该特征转化到源域数据集上.在这类方法中,翻译网络将源域数据变换到目标域,再从目标域变换回源域.原数据与重构数据之间的差异称为循环一致性损失.CycleGAN 通过最小化循环一致性损失使网络学习到如何在源域数据与目标域数据相互转化,对偶学习的训练过程如图7 所示.由于生成模型很难训练,Sankaranarayanan 等[99]提出了生成适应方法(Generate to adapt,GTA),该方法不仅利用GAN 来合成图像,也利用GAN 的训练过程来对齐源域与目标域的特征分布.其好处在于即使合成数据失败,也能得到领域不变性的特征表示用于迁移.
Yoo 等[100]在翻译网络的基础上使用对抗学习来保证合成样本和输入样本的标签一致性.Yoo 等[100]提出的网络结构包括三个模块,即翻译网络、真/假判别器以及领域判别器.翻译网络将源域数据转换为符合目标域分布的合成数据;真/假判别器用来对齐合成数据与目标域数据的分布;领域判别器的输入是合成数据和源域数据,其目的是在合成数据与源域数据之间建立联系,使得翻译网络在将源域数据映射到目标域之后仍能保持高层的语义信息.
还有一些方法使用任务网络的输出来保证合成样本和输入样本的标签一致性.既然输入样本和合成样本具有相同的语义,那么它们对各自领域专属任务网络的输出应该完全相同.Chen 等[101]将两个领域专属网络的输出差异作为跨领域一致性损失,该损失可以保证合成样本与输入样本的语义一致性.
除了上述关注如何建立样本标签关系的方法以外,还有一些方法通过改进网络训练过程来增强合成样本的质量.在合成样本的过程中,翻译网络随机抽样出一批源域样本,并将源域样本变换到目标域,判别器对合成样本和目标域样本进行分类,分类损失反向传播更新判别器和翻译网络的参数.每一次迭代之后,翻译网络的参数都发生了变化,这意味着在每一次迭代中,翻译网络对源域数据的变换方式都是不同的.判别器在训练过程中只会关注最新的合成样本,缺少对合成样本的记忆会导致训练过程难以收敛.Shrivastava 等[102]提出在网络中设置一个缓冲器来存储之前迭代中的合成样本来解决这个问题.此外,还有一些方法从不同角度出发来进行改进,例如,Li 等[103]针对序列学习迁移知识有限的缺点提出将双向学习引入到训练过程中,让翻译网络与判别器彼此推动相互促进来进一步减小分布差异.Bousmalis 等[104]将样本生成模块与任务模块进行分离,来解决测试集中出现未知类别的情况,增强模型的泛化能力.

图7 CycleGAN 的训练过程((a)源域图像通过翻译网络G 变换到目标域,目标域图像通过翻译网络F 变换到源域;(b)在源域中计算循环一致性损失;(c)在目标域中计算循环一致性损失)Fig.7 The training process of CycleGAN ((a) source images are transformed to target domain through translation network G,target images are transformed to source domain through translation network F;(b) calculate the cycle-consistency loss in source domain;(c) calculate the cycle-consistency loss in target domain.)
2.5 小结
本节对一般情况下的深度域适应方法进行了综述,按照实现域适应方式的不同将深度域适应方法划分为基于领域分布差异的方法、基于对抗学习的方法、基于重构的方法和基于样本生成的方法.
基于领域分布差异的方法一直以来是深度域适应的主流方法.研究者们提出了许多的距离度量来量化两个领域之间的差异.当前,衡量不同距离度量优劣只能通过模型在目标域上取得的性能来估计.在这一领域,还缺乏理论研究来证明哪一个距离度量才最适合域适应问题,以及不同的距离度量为什么会产生不同的迁移效果.
基于对抗的域适应方法的发展沿着一条清晰的脉络,从最初使用单个领域判别器,到使用一组类别领域判别器,直至到现在使用注意力机制选出图像中可迁移性高的部分进行对抗学习.虽然对抗学习的思想起源于GAN,但它的思想很适合域适应问题.从基于对抗的域适应研究的发展路径来看,只要模型能够更加准确地寻找到可迁移区域以及两个领域之间的对应关系,并在此基础上进一步对齐分布,那么就可以取得更加良好的迁移效果.
基于重构的迁移学习方法的优点是可以抑制特征中可迁移信息的损失,缺点是受限于自编码器的特征表示能力.即使是由多个自编码器串联而成的堆叠自编码器,其特征表示能力也不及当前常用的深度神经网络(如ResNet).深度神经网络的特征提取能力对于域适应的效果起着至关重要的作用.已知性能最好的域适应方法都使用深度神经网络作为特征提取器.只因为自编码器可以保证信息不受损失而将特征提取器替换为自编码器是得不偿失的.在当前的域适应研究领域,基于重构的域适应方法只占少数.可以预见,在未来的研究中,自编码器会更多地以一种辅助迁移的方式出现,例如在一些需要对特征解耦的方法中,可以使用自编码器保证解耦出的各部分包含特征的所有信息.
基于样本生成的域适应方法将域适应问题转换为有监督学习问题,此类方法的关键是如何将源域样本变换到目标域.成功地合成符合目标域分布的样本是一个难点.当数据表示的内容比较简单时(例如MNIST 数据集),合成样本相对容易;当数据集表示的内容比较复杂时(例如Office 数据集),合成样本就相对困难.生成模型的性能是影响基于样本生成的域适应方法性能的主要因素.这类方法的研究潜力在于未来是否能够出现性能更好的生成模型或训练方式.
3 标签空间不一致的域适应问题
与经典域适应方法相比,标签空间不一致的域适应方法的通用性更好,可以解决源域与目标域标签空间不一致的实际问题.本节将着重对标签空间不一致的域适应方法进行综述.第2 节综述的深度域适应属于闭集域适应.闭集是指空间或集合相同,闭集域适应是指源域和目标域标签空间相同(两个域包含相同物体类别)的域适应问题.在实际应用中,寻找到与目标域具有相同标签空间的源域比较困难.在多数情况下,源域的标签空间与目标域标签空间之间存在很大差别.差别可以分为很多种情况,例如源域标签空间是目标域标签空间的子集,目标域标签空间是源域标签空间的子集,或者无法得知两个标签空间确切的集合关系.为了使域适应算法能够适用于上述情况,研究者们对标签空间不一致的域适应问题进行了研究,这类问题的特点和典型方法如表2 所示.为了下文能够对标签空间不一致的域适应问题进行更准确的描述,首先明确一些数学符号的意义:使用Ys表示源域标签空间,使用Yt表示目标域标签空间,C=Ys ∩Yt代表两个域的共享标签空间,Cs=YsC和Ct=YtC分别表示源域私有标签空间和目标域私有标签空间.由于闭集域适应问题和标签空间不一致的域适应问题面临不同的挑战,闭集域适应方法不能直接应用在标签空间不一致的域适应问题上.闭集域适应问题面临的主要挑战是领域间的分布差异.而标签空间不一致的域适应问题除了需要解决领域间的分布差异,还需要解决两个域标签空间的差异.如果将整个源域分布与目标域分布进行对齐,那么属于私有标签空间的样本没有对应的类别去适配,属于共享标签空间的样本的对齐效果就会受影响,从而造成负迁移.解决标签空间不一致的域适应问题的首要是抑制私有标签空间中的样本所造成的负迁移,其次才是匹配共享标签空间中的两个域的特征分布.标签空间不一致的域适应问题由经典域适应问题发展而来,深度神经网络不仅广泛应用于经典域适应问题,也是解决标签空间不一致域适应问题的主要方法.标签空间不一致的域适应问题的形式化描述如下:

表2 标签空间不一致的域适应问题Table 2 Domain adaptation with inconsistent label space

3.1 部分域适应
在大数据时代,越来越多的具有丰富标注信息的大型数据集变得可用,研究者们有着很强的动机将深度模型从现有的大域迁移到未知的小域.由于大型数据集的数据量庞大,包含的物体类别丰富,假设目标域的标签空间是大型数据集的标签空间的子集是非常合理的.在这个背景下,域适应问题变换为目标域标签空间是源域标签空间子集的域适应问题.这种问题称为部分域适应问题.部分域适应中存在两个挑战.首先,部分域适应需要抑制源域私有标签空间Cs中的样本所造成的负迁移.其次,部分域适应需要促进共享标签空间C中两个域的分布对齐.没有目标域的标签无法确定目标域中包含哪些物体类别,这就导致了无法得知源域所包含的类别中哪些是共享类别,哪些是源域私有类别.只有先确定私有类别,才能避免它们造成的负迁移.部分域适应的核心在于如何正确地划分标签空间.部分域适应可以分为基于分类器输出的方法和基于领域判别器输出的方法.这两种方法的不同之处在于对标签空间划分的依据不同.部分域适应的形式化描述如下:

图8 选择对抗网络的网络结构Fig.8 The network structure of SAN

3.1.1 使用分类器输出划分标签空间
使用分类器输出划分私有标签空间和共享标签空间是一种常见的方法.文献[107]提出将目标域样本在源域分类器上的输出均值记为γ,并使用γ划分私有标签空间和共享标签空间,其网络结构如图8 所示.目标域样本只属于共享标签空间,故而γ中对应于共享类别的维度的数值比较大,而对应于源域私有类别的维度的数值比较小.文献[107]设定一个阈值t,将γ中大于t的维度所对应的类别记为共享标签,将γ中小于等于t的维度所对应的类别记为私有标签空间.Cao 等[1]在文献[107]的标签空间划分思想的基础上在对齐过程中引入了类别信息,在网络中设立了一组领域判别器,组中的每一个判别器负责判别对应类别样本的领域标签.分类器的输出是源域标签空间上的一个概率分布.这个分布刻画了样本属于每一个类别的可能性大小.由于目标域样本没有类别标签,所以Cao 等[107]使用分类器输出来决定每一个样本分配到哪一个领域判别器上.这种做法使得每个目标域样本只与最相关类别的源域样本进行对齐,从而将源域私有类别在对齐过程中剔除出去,避免了负迁移.
3.1.2 使用领域判别器输出划分标签空间
领域判别器的输出同样可以作为划分标签空间的依据.文献[108-109]提出在网络结构中设立一个不参与对抗过程的领域判别器,不参与对抗的领域判别器在误差反向传播过程中只计算判别器的梯度而不计算特征提取器的梯度,这类领域判别器只学习如何区分源域特征与目标域特征而不会改变特征提取方式.这类领域判别器的输出可用于判断样本的可迁移性.在部分域适应问题中,共享标签空间中的样本的可迁移性要高于源域专属标签空间中的样本的可迁移性.文献[108-109]设置阈值t,当领域判别器对一个样本的分类置信度较低时,该样本的可迁移性比较高,若分类置信度低于t,该样本则属于共享标签空间;当领域判别器对一个样本的分类置信度较高时,该样本的可迁移性比较低,若分类置信度高于t,该样本则属于源于私有标签空间.对共享标签空间中的源域和目标域的样本分布进行对齐就可以完成域适应.
3.2 开集域适应
由于需要从大型数据集向目标域迁移知识,研究者们提出了部分域适应.但在某些应用中已经存在与目标域非常相近的数据集.根据域适应理论,源域与目标域越相似,迁移效果越好,所以这时就没有必要使用大型数据集作为源域.与目标域相近的数据集类别通常不如大型数据集丰富,目标域中可能会出现私有类别,这就需要一类新的域适应算法来解决这个问题.解决这种源域标签空间是目标域标签空间子集的域适应问题称为开集域适应.开集域适应需要解决两个问题.首先,开集域适应需要消除分布偏移的影响;其次,由于源域中没有样本与目标域私有类别中的样本相对应,直接对齐两个域的整体分布会造成负迁移,所以需要确定共享类别与目标域专属类别之间的界限,并降低目标域专属类别在对齐过程中的影响.与部分域适应不同的是,开集域适应不仅需要对共享标签空间C中的目标域样本进行分类,还需要将所有的目标域私有标签空间Ct中的样本划分为“未知”类别,从而增加了开集域适应问题的难度.开集域适应的核心同样在于如何正确地划分标签空间.开集域适应可以分为基于相似性的方法和基于分类器输出的方法.这两种方法的不同之处在于对标签空间划分的依据不同.开集域适应的形式化描如下:


3.2.1 使用目标域样本与源域类别间相似性划分标签空间一些方法计算目标域样本与源域类别间的相似性,并使用该相似性作为划分标签空间的依据.Liu等[105]训练多个二分类分类器来估计目标域样本与各源域类别的相似性,选用高相似性的样本和低相似性的样本作为共享类别样本和目标域私有类别样本,再训练一个二分类分类器,让该分类器可以区分目标域中的未知类别样本.Busto 等[110]提出使用目标域样本与源域类别中心的距离来划分共享类别和目标域私有类别,距离也可以看作是一种相似性,距离越小则样本属于共享类别的可能性越大;距离越大则样本属于目标域私有类别的可能性越大.Busto 等[110]设定阈值t,将距离小于t的目标域样本归为共享标签空间,将距离大于t的目标域样本归为目标域私有空间.对共享标签空间和目标域私有标签空间进行划分后,使用域适应方法对共享标签空间中的特征进行分布对齐,并将属于目标域私有空间的样本的类别标记为“未知”.
3.2.2 使用分类器输出划分标签空间
还有一些方法使用分类器输出来划分标签空间.Saito 等[111]使用分类器学习如何划分共享类别和目标域私有类别.假设共享类别的个数为k,Saito等[111]将分类器的输出维度设置为k+1,其中前k维表示样本在共享标签空间上的概率分布,第k+1维则表示样本属于目标域私有标签空间的概率,其网络结构如图9 所示.针对分类器的第k+1 维输出,设置阈值t并采用对抗学习的方式训练分类器,使得第k+1维的输出远离t.第k+1 维的输出要么接近于0,要么接近于1.当输出为0,则表明样本位于共享标签空间,其真实类别由前k维输出给出;当输出为1,则前k维输出均为0,样本位于目标域私有标签空间,样本被标记为“未知”类别.
3.3 通用域适应
域适应方法通过克服领域间差异来迁移知识,并且需要事先就知道源域与目标域的标签空间关系.由于域适应问题的数据集通常没有目标域样本的标签,所以与源域目标域标签关系相关的先验知识也无法得知.对于标签空间关系这一先验的需求限制了域适应方法的应用.通用域适应就是要解决在标签空间关系未知情况下的域适应问题.通用域适应要求对在共享标签空间C中的目标域样本进行分类,并对其他的目标域样本标记为“未知”.由于标签空间关系未知,无法决定用源域中哪一部分数据去适配目标域中哪一部分数据,所以通用域适应的关键在于寻找共享标签空间C.通用域适应的形式化描述如下:


图9 文献[111]中的网络结构Fig.9 The network structure in [111]
文献[106]在定义通用域适应问题的同时也提出了一个名为通用适配网络的方法,其网络结构如图10 所示.该方法通过整合领域相似性与分类置信度来量化样本的可迁移性,可迁移性在这里是指样本属于共享标签空间的可能性.该方法通过具有高可迁移性的样本来确定共享标签空间.领域相似性是指样本与源域的相似程度.领域相似性由非对抗领域判别器给出.对于源域样本来说,领域相似性越大,可迁移性就越差;而对于目标域样本来说,领域相似性越大,可迁移性就越好.分类置信度由分类器输出的熵衡量.熵越小分类置信度越高.分布适配的过程会破坏特征的类别可区分性,而在标签空间不相同的情况下,分布对齐只在共享标签空间中发生.对于源域样本来说,分类置信度低的样本就可以被认为位于共享标签空间之中.对于目标域样本来说,分类置信度高则说明这个样本与源域相似,只有在共享空间中,两个域的样本才会有一定的相似度.故而分类置信度高的样本可以被认为位于共享标签空间之中.通过上述分析,源域样本与目标域样本的可迁移性分别定义为
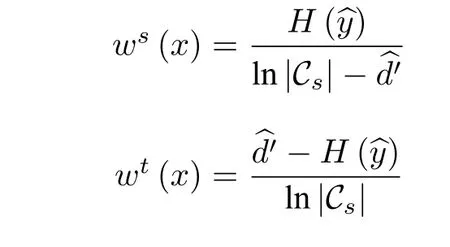
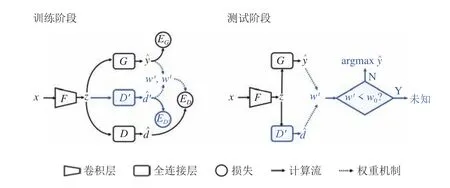
图10 通用适配网络的训练过程Fig.10 The training process of univerial adaptation network
3.4 小结
本节对标签空间不一致的域适应问题进行了综述.根据标签空间关系的不同,这类域适应问题可以分为部分域适应、开集域适应以及通用域适应.
标签空间不一致的域适应问题的关键在于共享标签空间和私有标签空间的划分.多数方法通过设定阈值来对标签空间进行划分.阈值设定的大小在很大程度上决定了确定共享标签空间的宽松程度.在不同任务中,源域与目标域标签空间的共享程度不同,最优的阈值也不尽相同.如何根据标签空间的共享程度来自动地设定阈值是一个值得研究的问题.另外,很多方法没有完全消除私有标签空间中的样本产生的负迁移,这些方法不能明确地区分样本属于共享类别还是属于私有类别,仅仅将样本的可迁移性作为损失项权重来降低私有标签空间样本在训练中的影响.这样做虽然避免了阈值的设定,但对负迁移的抑制效果有限,如何在设定阈值与抑制负迁移之间取得平衡也是值得关注的问题.
通用域适应是一个崭新的研究方向,其问题背景更加符合现实情况.通用域适应的研究将会对域适应算法在实际应用中的部署起到促进作用.无论是域适应方法还是部分/开集域适应方法都很容易地扩展到通用域适应问题中.可以预见在未来几年,通用域适应领域将会出现更多的的成果.
标签空间不一致的域适应问题是一个比较新的研究领域.成果不是很多,值得探索的内容还很丰富.这类问题将会成为域适应领域中新的研究热点.
4 复杂目标域情况下的域适应问题
复杂目标域情况下的域适应用来解决存在多个目标域或者目标域不可得的域适应问题.经典域适应问题默认目标域样本从同一个分布中采样,但这是对实际情况的简化.实际应用中更有可能遇到需要从源域同时迁移到具有不同分布的多个目标域的情况.甚至在某些情况下,目标域样本是不可得的,这时只能从源域中训练泛化性能足够好的模型来满足目标域中的任务需求.这类问题称为复杂目标域情况下的域适应问题,其问题特点和方法归纳如表3所示.复杂目标域情况下的域适应问题由经典域适应问题发展而来,广泛应用于域适应问题中的深度神经网络同样也是解决复杂目标域情况下的域适应问题的主要方法.本节将复杂目标域情况下的域适应问题划分为多目标域域适应和领域泛化,下文对其研究现状分别进行介绍.
4.1 多目标域域适应
经典域适应关注的是仅有一个源域和一个目标域的迁移场景,目标域样本从同一个分布中采样,然而更常见的场景是目标域样本来自于不同的分布.例如,由仿真平台训练的机器人应用在现实生活中,现实生活包括许多的场景并且同一场景的环境也会随着时间的推移而变化.在这个例子中,目标域可以按照场景和时间划分为多个子目标域,子目标域之间的统计特征不同但却有着相同的高层语义.多目标域域适应考虑了一种更加符合真实情况的迁移场景:目标域由多个子目标域组合而成,而且目标域样本没有子目标域的领域标签.在解决域适应问题时,研究者们的通常做法是寻找到两个领域的“交集”,并利用“交集”将源域模型迁移到目标域中 .这个思路同样适用于多目标域域适应.多目标域域适应的形式化描述如下:


表3 复杂目标域情况下的域适应问题Table 3 Domain adaptation in the case of complex target domain
4.1.1 使用特征解耦获得领域不变性特征
特征是领域不变性特征和领域专属特征的耦合.对特征进行解耦可以获得源域与各子目标域之间的领域不变性特征,领域不变性特征作为领域间“交集”将源域知识迁移到目标域.文献[3]使用对抗学习和自编码器将特征解耦为领域不变性特征和领域专属特征.使用源域中的领域不变性特征训练的模型被直接应用到各子目标域中.文献[4]在文献[3]的基础上将领域不变性特征再次解耦为类别无关特征与类别相关特征.二次解耦将领域不变性特征中与判别物体无关的信息剔除,从而进一步提升了特征的类别可区分性.文献[3-4]使用领域不变性特征进行知识迁移,缺点是忽略了领域专属特征中的有用信息,造成了信息的浪费.
4.1.2 使用聚类算法划分子目标域
多目标域域适应问题中的难点在于目标域样本没有子目标域领域标签.如果目标域可以准确地划分为多个子目标域,多目标域域适应问题就可以转化为域适应问题来解决.Chen 等[113]使用自编码器对目标域样本进行聚类,每个簇中的样本被认为是来自同一个子目标域.随后,Chen 等[113]使用对抗域适应方法在源域和每一个子目标域之间进行知识迁移,网络结构如图11 所示.该方法的优点是避免了领域专属特征中的信息损失,缺点是迁移效果取决于聚类效果,不准确的聚类结果会造成负迁移.
4.2 领域泛化
领域泛化是指目标域样本不可知的域适应问题.上文中的多目标域域适应具有明确的目标,即降低模型在多个目标域上的误差.领域泛化则要求模型的泛化性能足够高,以便可以适用于任何未知目标域.领域泛化是多目标域域适应问题的一个递进学习范式.由于在训练过程中目标域样本不可知,所以需要由源域训练的模型的泛化性能足够好来完成目标域上的任务.提升模型泛化性能的方法有:数据增广、增强特征泛化能力和集成学习.这三种方法分别从数据层面、特征层面和模型层面增强网络的泛化能力.领域泛化的形式化描述如下:

4.2.1 数据增广
在机器学习问题中,训练样本越丰富模型的泛化性能就越好.领域泛化也利用这个思想来增强模型的泛化能力.实现数据增广的方式有两种:扩大数据集和生成样本.由于扩大数据集需要消耗大量的人力物力,所以生成样本是领域泛化的首要选择.使用生成样本提升泛化能力的难点在于获取生成样本的类别标签.针对这个问题,文献[114-115]提出计算损失项对样本的梯度,并将梯度与样本相加得到扰动样本.由于在样本空间中,扰动样本的位置靠近原样本的位置,所以扰动样本具有和原样本一样的类别标签.数据集规模的扩大提升了模型的泛化性能,使之能够应用于领域泛化问题.
4.2.2 增强特征泛化能力

图11 文献[113]中的网络结构Fig.11 The network structure in [113]
有的方法[112,116—120]通过增强特征泛化能力来解决领域泛化问题.Li 等[112]使用元学习通过构建特征评价网络来增强特征泛化能力.特征评价网络输入特征并输出评价项.在该方法中,只使用分类损失训练的特征提取器称为“旧”的特征提取器,使用分类损失和评价项训练的特征提取器称为“新”的特征提取器.元损失定义为“新”、“旧”两种特征提取器提取的特征的分类性能的差值.元损失参与到网络的训练过程中.网络通过元损失学习泛化性能强的特征表示,其结构如图12 所示.除了元学习以外,多任务学习也可以帮助网络学习到泛化性能强的特征表示.受到人类学习过程的启发,Carlucci 等[119]提出在学习任务的同时学习图像的内在规律有助于提升特征的泛化性能.具体的做法为将图像均匀切分并将图像块打散,由排列序号给出图像块的真实位置.网络在学习任务的同时,也学习识别出打散的图像块的真实位置.文献[120]构建了一种多任务自编码器,它可以学习到对真实图像(视角旋转、尺度缩放、光照条件变化)变化鲁棒的特征表示.该方法构建了两种重构任务:自领域重构和领域间重构.自领域重构任务中的输入与输出是同一个样本,而领域间重构任务中的输入与输出是不同源域中的同类别样本.对于一个含有M个源域的数据集,该方法会构建M个自领域重构任务和M(M-1) 个领域间重构任务.领域间重构任务使得编码构成了连接不同源域之间的桥梁.这种“桥梁”作用使得编码成为一种泛化能力优异的特征.
4.2.3 基于集成学习的方法
文献[121—123]利用集成学习来提升特征的泛化性能.Xu 等[121]通过融合多个分类器的分类结果来解决领域泛化问题.文献[122-123]在文献[121]的基础上对源域样本提取多视角的特征表示,并训练多个分类器.目标域样本的分类结果由分类器投票产生.源域样本的数量有限,而深度神经网络对数据的需求很大,使用有限的数据训练多个不同的分类器是比较困难的,这类方法的提升效果有限.
4.3 小结
本节对复杂目标域情况下的域适应问题进行了综述.复杂目标域情况下的域适应问题可以分为多目标域域适应问题和领域泛化.多目标域域适应方法通过寻找源域与子目标域之间的“交集”来迁移知识,但这种方法不会总是有效的.可以使用集合论的概念说明这个问题:假设有k个集合,其中有一个集合与剩余的k-1 个集合的交集都为空.那么即使剩余的k-1个集合都完全相等,这k个集合的交集也为空.类似的,假如有某个子目标域的分布与其余的子目标域相差过大,不能够找到一个领域间的“交集”来迁移知识,那么多目标域域适应方法就会失效.如何在子目标域之间分布差异较大时进行知识迁移是多目标域域适应未来需要解决的问题.领域泛化中已经出现了一些优秀的成果,是一个域适应问题中的研究热点.领域泛化的未来趋势是更多地与新的学习模式相结合.例如文献[112]就使用元学习来解决领域泛化问题.
5 应用
机器学习的成功离不开大量的标注数据.在一些领域,对数据进行标注需要大量的人力物力.例如用于语义分割的数据集需要像素级的标注,每一幅图像都需要数小时的时间才能完成标注,因此严重阻碍了机器学习在语义分割领域的应用和普及.域适应技术的出现有效地缓解了这个问题.域适应可以使一个标注好的源域数据集应用在多个目标域上.域适应问题的研究对机器学习在实际问题中的应用有着重大意义.
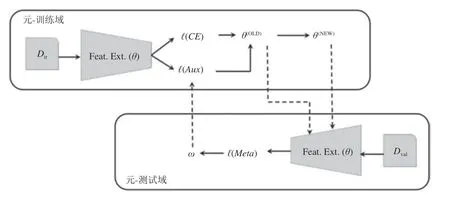
图12 文献[112]使用元学习来提取泛化性能优异的特征Fig.12 Reference [112]uses meta learning to extract features with excellent generalization performance
域适应技术在目标检测领域发挥了重要作用.文献[124]通过对抗学习来减小源域与目标域在图像层和目标层的领域差异,提高了目标检测的准确性.文献[125]使用源域样本生成符合目标域分布的人工样本,并使用人工样本对目标检测器进行微调.游戏行业中视觉技术的发展提供了大量带标注的逼真数据,这在很大程度上解决了语义分割中标注数据昂贵的问题.但游戏图像与真实场景之间存在领域差异.域适应成为解决该问题的主要手段.文献[126]使用教师学生网络通过减少两个领域的预测图差距来减少领域差异.文献[90]基于分层区域选择思想进行语义分割,分别在像素层、区域层、图像层寻找可迁移性高的区域进行知识迁移.文献[101]使用图像翻译网络将样本在源域目标域之间映射,并使用结果一致性约束保证网络对两个域的样本具有相同的分割结果.此外,在医学图像领域,文献[127]提出一种协同适配技术将心脏的核磁共振图像转化为CT 图像.在深度估计领域,文献[128]使用对抗域适应技术对ToF (Time of flight) 数据进行去噪.域适应技术还广泛地应用于自主导航/自动驾驶[129-130]、行人再识别[131—134]、手势识别[135]、人脸识别[136]、疾病诊断[137—140]、工业测量[141]等.
实际需求具有多样性,实际应用中目标域数据集的构成也千差万别.在很多情况下,并不存在与目标域具有相同标签空间的源域数据.在这种情况下,标签空间不一致的域适应技术就能够派上用场.首先,当缺乏源域数据时,最方便的做法是使用ImageNet 数据集作为源域.ImageNet 数据集共有20 000余个类别,包含了绝大多数常见物品的种类.假设目标域标签空间是ImageNet 标签空间的子集是合理的,那么这时就可以使用部分域适应技术[107—109]来解决实际问题.此外,在一些实际应用中,如行人再识别,目标域数据类别是随着时间而增加的.当目标域数据出现新的类别时,之前训练好的模型会对新样本产生误分类.在确定新的任务目标之前,模型需要能够将新类别的样本识别出来并标记为“未知”.这时开集域适应[110-111]就可以用来解决这一问题.最后,还存在一种情况,即虽然可以找到与目标域相关的源域数据集,但无法确定源域与目标域标签空间关系,这时通用域适应[106]就能够派上用场.标签空间不一致的域适应技术是域适应技术的通用形式.在标签空间不一致的情况下,可以使用通用域适应代替域适应技术来解决诸如目标检测、语义分割等一系列应用.
实际应用中,目标域的情况通常会比域适应问题定义中的情况更加复杂.首先,在源域训练的模型可能需要适用于多个目标域.例如,由不同相机从不同角度在不同时间拍摄的同一批物体就可以看作不同的目标域.一个好的域适应方法应该能够通过一次训练就可以使分类器识别不同目标域中的物体类别.其次,目标域的分布可能会随着时间的推移而逐渐变化.例如,使用仿真平台来训练机器人并应用到现实生活中,然而现实生活中可能包括多种情景,甚至在同一情景下环境也会随着时间的推移而不断地变化.最后,某些情况下,在训练阶段目标域样本是不可得的,例如深空探测任务中,在卫星发射之前人们无法得到未探知的深空区域图像.目标域样本的缺乏将导致训练阶段无法进行领域对齐.在这些情况下,只能尽可能训练一个泛化性能足够好的模型来适用于目标域.多目标域域适应[3-4,113]以及领域泛化技术[116—123]可以在这些应用中发挥作用.具体的应用实例有,文献[142]收集不同的人在不同环境下的睡眠数据并使用领域泛化来推测未知的人在不同环境下的睡眠质量,文献[120]使用去噪自编码器来增强物体识别的泛化性能.
6 实验
本节展示了具有代表性的域适应方法在各公开数据集上的性能.本节将首先介绍数据集,并随后介绍深度域适应方法、标签空间不一致的域适应方法以及复杂目标域情况下的域适应方法的性能.
6.1 数据集
本小节使用的数据集包括Office-31[143],Office-Home[144],MNIST.
1) Office31 数据集[143]
Office31 数据集包含Amazon (A),Webcam(W),DSLR (D) 三个域,三个域分别具有2 817,498,795 个样本,每个域都涵盖了31 个物体类别.Amazon 中的样本来自于线上电商网站;Webcam 中的样本为网络摄像机拍摄的低分辨率图像;DSLR 为单反相机拍摄的高分辨率图像.
2) OfficeHome 数据集[144]
OfficeHome 数据集包括Art (A),Clipart (C),Product (P),RealWorld (R)四个域,四个域分别具有2 427,4 365,4 439,4 357 个样本,每个域都涵盖了65 个物体类别.Art 中的样本为绘画/素描;Clipart 中的样本为剪贴画;Product 中的样本为去除背景的实物图像;RealWorld 中的样本为使用相机拍摄的常规图像.
3) MNIST 手写数字数据集
MNIST 数据集为手写数字图像数据集,包含0~9 共10 个类别.其训练集包括60 000 个样本,测试集包括10 000 个样本.
6.2 深度域适应方法的实验结果
本小节在Office31 数据集和OfficeHome 数据集上对具有代表性的深度域适应方法的性能进行了比较.所有基于深度学习的方法均使用预训练过的ResNet50 作为特征提取器,同时使用ResNet50 网络作为基线系统.所有算法的参数都设置为默认值或者原论文所提供的推荐值.表4 展示了Office31数据集上的实验结果.表5 展示了OfficeHome 数据集上的实验结果.
首先,从表4 中可以发现,基于对抗学习的域适应方法(CDAN,MADA,ADDA,DANN)取得了最好的性能,基于样本生成的域适应方法(GTA)也取得了很好的性能,而基于领域分布差异的域适应方法(JAN,RTN,DCORAL,DAN)取得了最坏的性能.对抗学习在知识迁移方面取得了良好的效果,基于对抗学习的域适应方法也是当前域适应领域的研究重点.其次,同样可以发现在 A→W与D→W这两个任务上,性能最好的域适应方法(CDAN)的准确率已经超过90%,而没有进行域适应的方法(ResNet50)的准确率不足70%.这意味着域适应领域的研究已经取得了非常大的进展.最后,通过观察较难任务 D→A与 W→A 的实验结果,可以发现当前的域适应方法的性能还不尽人意.在这两个较难任务上,基于样本生成的域适应方法(GTA)都获得了最优的性能.这意味着基于样本生成的域适应方法更加适用于知识较难迁移的情形.
表5 展示了域适应方法在OfficeHome 数据集上的性能.OfficeHome 数据集包含了更多的类别,因此知识迁移更加困难.从表5 中可以发现,在OfficeHome 数据集上基于对抗学习的域适应方法依然获得了最优的迁移效果.此外,虽然Office-Home 数据集上的任务比较困难,与基线方法相比,域适应方法依然获得了较大的性能提升.
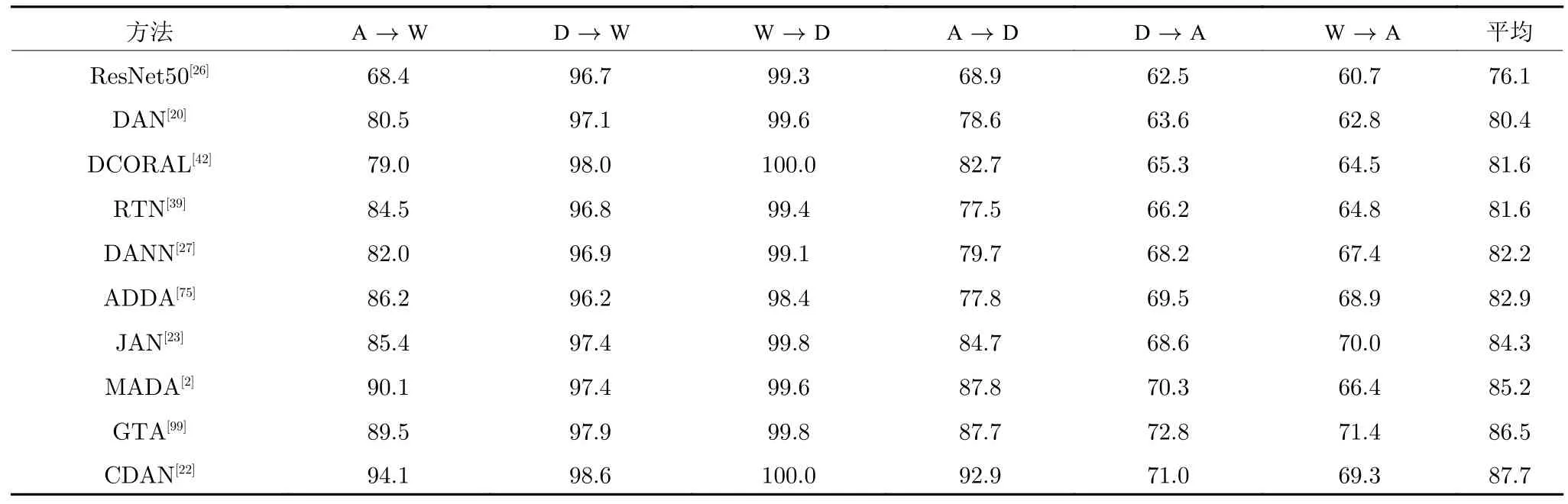
表4 在Office31 数据集上各深度域适应方法的准确率 (%)Table 4 Accuracy of each deep domain adaptation method on Office31 dataset (%)

表5 在OfficeHome 数据集上各深度域适应方法的准确率 (%)Table 5 Accuracy of each deep domain adaptation method on OfficeHome dataset (%)
6.3 标签空间不一致的域适应方法的实验结果
本小节包括部分域适应方法、开集域适应方法以及通用域适应方法的实验结果.
6.3.1 部分域适应方法的实验结果
我们在Office31 数据集上对具有代表性的部分域适应方法的性能进行了比较.所有基于深度学习的方法均使用预训练过的ResNet50 作为特征提取器,同时使用ResNet50,DAN 和DANN 作为基线系统.所有算法的参数都设置为默认值或者原论文所提供的推荐值.我们对Office31 数据集中的31 个类别按照字母表顺序进行排列,并取前10 个类别的样本构建目标域.由此,源域包含31 个类别,目标域包含10 个类别,且目标域类别为源域类别的子集,符合部分域适应问题的设定.表6 展示了部分域适应方法的实验结果.
观察表6 中的实验结果,可以得到以下结论:首先,DANN 和DAN 在6 个任务上的平均准确率不如ResNet.这是由标签空间不一致带来的负迁移造成的.其次,部分域适应方法(IWAN,SAN,PADA,ETN) 的准确率要高于经典域适应方法(DAN,DANN)和深度神经网络(ResNet50).这是由于部分域适应方法只对齐共享标签空间的分布,从而抑制了源域专属标签空间中的样本产生的负迁移.最后,ETN 在绝大部分任务上都取得了最好的性能.这意味着在域适应领域,对抗学习不仅可以很好地对齐分布还很适用于划分标签空间.
6.3.2 开集域适应方法的实验结果
我们在Office31 数据集上对具有代表性的开集域适应方法的性能进行了比较.所有基于深度学习的方法均使用预训练过的ResNet50 作为特征提取器,同时使用ResNet50,RTN,DANN 和开集识别方法OpenMax 作为基线系统.所有算法的参数都设置为默认值或者原论文所提供的推荐值.我们对Office31 数据集中的31 个类别按照字母表顺序进行排列,并取前10 个类别作为共享类别,取第21~31 个类别作为目标域专属类别.由此,源域包含10 个类别,目标域包含21 个类别,且源域类别为目标域类别的子集,符合开集域适应问题的设定(对开集域适应的定义有两种,第1 种定义中源域包含源域私有类别;第2 种定义中源域不包含源域私有类别而只具有共享类别,本文只考虑第2 种定义).此外,我们对两种情形下的域适应方法进行了实验.1)需要对目标域私有类别进行分类,并且将目标域私有类别为“未知”的情形标记为OS;2)不需要对目标域私有类别进行分类,只对共享类别进行分类的情形标记为OS*.表7 展示了开集域适应方法的实验结果.
从表7 中可以观察到,在一些任务中,经典域适应方法(RTN,DANN)的准确率甚至低于深度神经网络ResNet50.这是由于目标域私有类别与共享类别之间的错误对齐产生了负迁移.相反,与基线系统相比,开集域适应方法(ATI-λ,OSBP,STA)获得了较高的准确率.这意味着只对齐共享标签空间中的样本可以有效地抑制目标域私有类别带来的负迁移.
6.3.3 通用域适应方法的实验结果
我们在OfficeHome 数据集上对通用域适应方法的性能进行了测试.所有基于深度学习的方法均使用预训练过的ResNet50 作为特征提取器.所有算法的参数都设置为默认值或者原论文所提供的推荐值.通用域适应方法用来解决标签空间关系未知情况下的问题.为了便于实验,我们仅在一种情形下对方法的性能进行测试:源域和目标域都包含私有类别,且存在共享类别.我们对OfficeHome 数据集中的65 个类别按照字母表顺序进行排列,并取前10 个类别作为共享类别,取第11~15 个类别作为源域私有类别,取第16~65 个类别作为目标域私有类别.我们对通用域适应方法的性能与部分域适应方法、开集域适应方法和深度神经网络均进行了对比.此外,对分类结果设置了置信度阈值,将分类置信度小于阈值的样本标记为“未知”来解决部分域适应方法不能应对目标域中存在私有类别的问题.表8 展示了通用域适应方法及其他方法的实验结果.

表6 在Office31 数据集上各部分域适应方法的准确率 (%)Table 6 Accuracy of each partial domain adaptation method on Office31 dataset (%)
在该实验的设置中,共享类别数量仅为10 个,源域私有类别与目标域私有类别的数量分别为5和50.源域数据和目标域数据之间的交集很小,这对域适应方法来说是一个非常大的挑战.从实验结果上看,除了UAN 方法的绝大多数方法仅取得了与ResNet 相似的性能,甚至性能不如ResNet.大量的私有类别的样本使得域适应方法不能够取得很好的迁移效果.而通用域适应方法UAN 则很适合处理这种情况.UAN 在进行特征对齐的过程中可以很好地抑制私有类别样本产生的负迁移,而且可以给出一个恰当的标准来衡量样本是否应该属于“未知”样本.这种能力对处理标签空间关系未知的域适应问题是非常重要的.
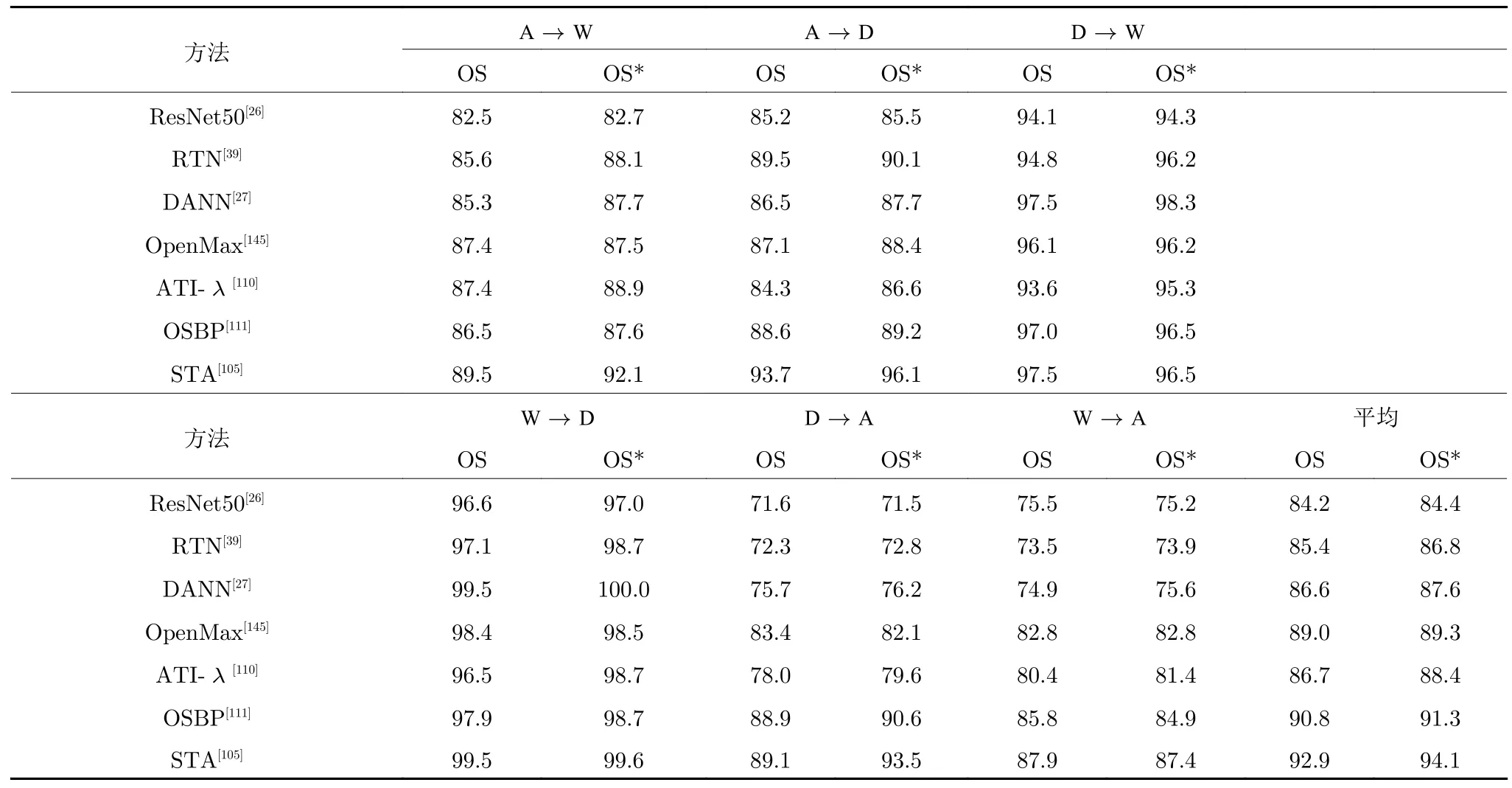
表7 在Office31 数据集上各开集域适应方法的准确率 (%)Table 7 Accuracy of each open set domain adaptation method on Office31 dataset (%)
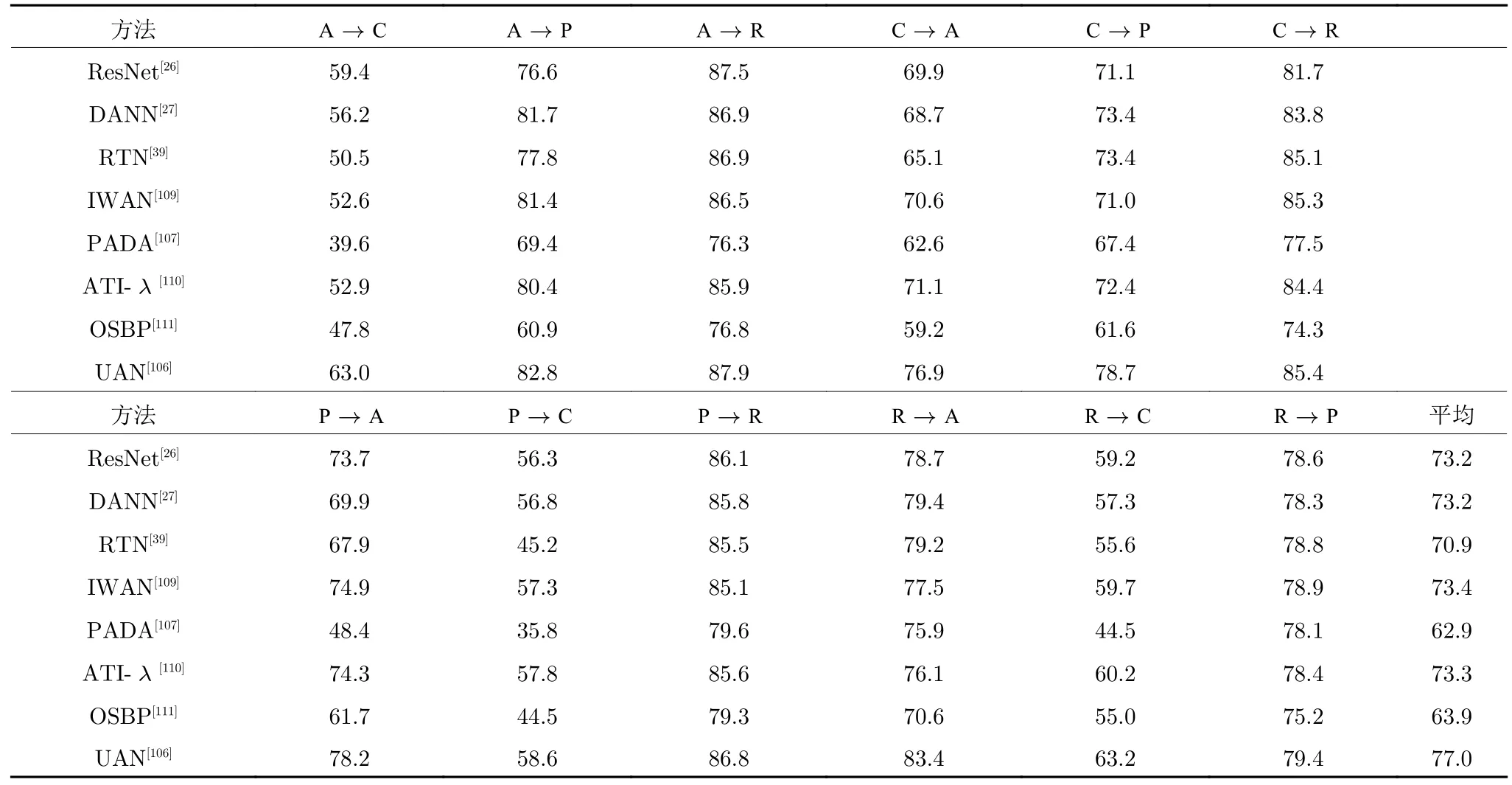
表8 在OfficeHome 数据集上通用域适应及其他方法的准确率 (%)Table 8 Accuracy of universal domain adaptation and other methods on OfficeHome dataset (%)
6.4 复杂目标域情况下的域适应方法的实验结果
本小节包括多目标域域适应方法以及领域泛化方法的实验结果.
6.4.1 多目标域域适应方法的实验结果
我们在Office31 数据集上对具有代表性的多目标域域适应方法的性能进行了测试.所有基于深度学习的方法均使用预训练过的ResNet50 作为特征提取器.所有算法的参数都设置为默认值或者原论文所提供的推荐值.表9 和表10 展示了多目标域域适应方法的实验结果.
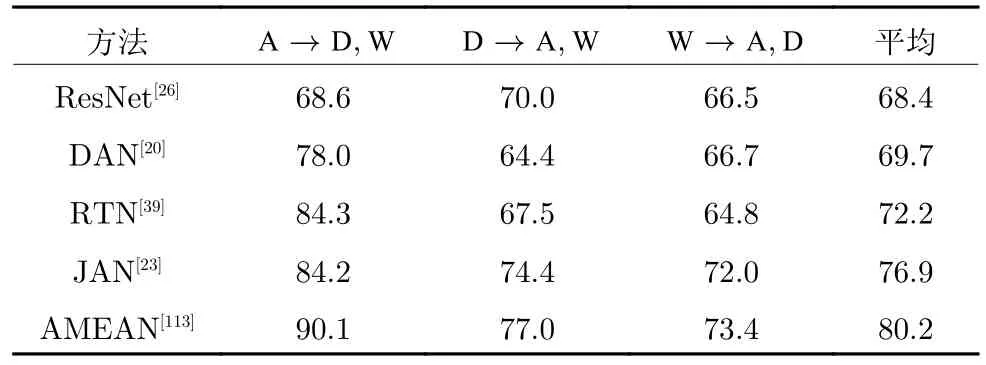
表9 在Office31 数据集上AMEAN 及其他方法的准确率 (%)Table 9 Accuracy of AMEAN and other methods on Office31 dataset (%)

表10 在Office31 数据集上DADA 及其他方法的准确率 (%)Table 10 Accuracy of DADA and other methods on Office31 dataset (%)
从表9 和表10 中可以发现,与基线系统相比,AMEAN 和DADA 都取得了一定程度上的性能提升.这种提升要归功于多目标域域适应方法寻找多个目标域之间共性的能力.能够在多目标域之间寻找到共性可以抑制目标域分布之间差异所产生的负迁移.
6.4.2 领域泛化方法的实验结果
我们在MNIST 数据集上对具有代表性的领域泛化方法的性能进行了比较.使用去噪自编码器(Denoising autodecoder,DAE)作为基线系统.所有算法的参数都设置为默认值或者原论文所提供的推荐值.我们在MNIST 数据集中的每个类别中随机选取1 000 幅图像,并将该图像集记为M0,随后,将M0中的图像分别逆时针旋转15°,30°,45°,60°和 75°,由此得到的数据集分别记为M15,M30,M45,M60和M75. 表11 展示了MNIST 数据集上的实验结果.
从表11 中可以发现,MMD-AAE 获得了最好的效果.DICA 与MMD-AAE 同样使用MMD 进行领域泛化.MMD-AAE 的性能更为突出的原因在于两个方面:1) MMD-AAE 的网络结构更深.更深的网络结构对应着更强的特征提取能力.2) MMDAAE 通过对抗学习引入了对特征分布的先验知识,从而避免了对源域数据分布的过拟合.此外,从表11中还可以发现,D-MTAE 获得了接近于MMDAAE 的性能.
7 展望
两个领域之间存在的相似性,是知识迁移的必要前提.从源域中学习知识并运用到目标域必须保证源域与目标域之间存在“交集”.尽管研究者已经提出了许多衡量领域间差异的度量,但是针对度量的优劣目前还没有深入的研究成果,寻求理论上最优的度量将是一个值得研究的问题.基于对抗的方法使用对抗学习获得领域不变性特征.这类方法没有利用到特征中领域专属信息,在基于对抗的方法中引入领域专属信息将获得更好的性能;基于重构的方法基于自编码器实现,自编码器的特征提取能力远不如深度神经网络,如何在保持基于重构的方法的优点的基础上提升特征的表示能力是一个值得研究的方向;基于样本生成的方法通过合成符合目标域的假样本来训练目标域模型.合成复杂的真实样本是困难的,与建立起源域样本标签和合成样本标签之间的关系相比,提升翻译网络合成样本的能力是更加值得研究的方向.
当前域适应研究主要集中于一般情况下的深度域适应方法上,最近两年的域适应研究开始逐渐重视实际应用中可能遇到的场景,即复杂情况下的域适应问题,如源域与目标域标签空间关系未知的域适应问题[106],数据中存在噪音的域适应问题[146]等.域适应问题虽然仍是研究热点但方法已经接近于成熟.实际场景中的域适应问题可能更加值得研究者们关注.除了迁移场景的问题之外,在目前大数据背景下,已有的算法还不能满足实际的应用需求,处理的数据量还比较小,而且算法复杂度也比较高.高效算法的设计以及确实满足实际需求仍然需要大量的研究才可以将域适应技术落地.此外,现在的域适应方法更多地是应用在分类和识别任务上,针对一些比较困难的任务,例如目标跟踪、人脸识别、行人识别等,如何在域适应问题的背景下完成这些任务将会是未来的研究趋势之一.最后,随着传感器在手机、汽车、建筑物、道路和电脑上的广泛应用,人们正在收集更大、更多样的信息.数据集的多样性使对标签空间不一致的域适应问题的深入研究更加迫切.

表11 在MNIST 数据集上领域泛化方法的准确率 (%)Table 11 Accuracy of domain generalization methods on MNIST dataset (%)
8 结束语
迁移学习利用源域与目标域之间的相似性将源域中的知识迁移到目标域当中.域适应是指源域与目标域标签空间相同并且条件概率相同的迁移学习问题.域适应是迁移学习领域中的研究重点,迁移学习中的其他问题常对域适应方法加以改进来解决.深度神经网络具有强大的特征提取能力,深度域适应方法已经成为解决域适应的主流方法.影响目标域泛化误差上界的因素包括源域泛化误差、领域间距离和最优联合泛化误差.探究影响目标域泛化误差的因素可以指导域适应算法的设计.当前绝大多数域适应算法通过减小领域间距离来解决域适应问题.如果迁移的知识不是源域和目标域共有的,那么这部分知识就会造成负迁移.抑制负迁移是迁移学习领域的研究重点.避免负迁移的关键在于在源域和目标域中寻找到正确的相似性.
根据深度域适应方法使用的迁移方式的不同,可以将深度域适应分为基于领域分布差异的方法、基于对抗的方法、基于重构的方法和基于样本生成的方法.按照对领域间差异衡量标准的不同,基于领域分布差异的方法又可以分为基于统计准则的方法、基于结构准则的方法、基于流形准则的方法和基于图准则的方法.无论基于哪一种准则,这类方法都是通过最小化领域间分布差异来寻找领域不变性的特征表示.基于对抗的方法使用对抗学习来对齐领域分布.与单对抗方法相比,多对抗方法使用多个领域判别器将类别信息引入到训练过程中,获得了更好的性能.近年来,基于对抗的方法的研究中心转向了基于注意力机制的对抗方法,通过忽略图像中可迁移性低的区域抑制负迁移的产生.基于重构的方法将自编码器引入到域适应过程中,这类方法有两个优点,一个是可以抑制信息损失,另一个是可以将特征解耦为领域不变性特征和领域专属特征,领域专属特征可以增强目标域网络的性能.基于样本生成的方法通过生成符合目标域分布的假样本来训练目标域网络.这类方法通常使用翻译网络来合成样本.基于样本生成的方法的关键是建立起源域样本标签和合成样本标签之间的关系.
标签空间不一致的域适应问题包括部分域适应、开集域适应以及通用域适应.部分域适应是指目标域标签空间是源域标签空间子集的域适应问题.这类问题通过对源域标签空间进行划分来转变为域适应问题.通常依据分类器的输出或者领域判别器的输出来对标签空间进行划分.开集域适应是指源域标签空间是目标域标签空间子集的域适应问题.这类问题通过对目标域标签空间进行划分转变为域适应问题.与部分域适应类似,开集域适应也可以通过分类器输出对标签空间进行划分.此外,这类方法还利用目标域样本和源域类别间相似性来寻找共享标签空间.通用域适应是指源域与目标域标签空间关系未知的域适应问题.通用域适应是域适应问题中一个新兴的研究领域,成果还比较少,已有的方法是使用领域相似性和分类置信度来寻找共享标签空间,从而进行知识迁移.
复杂目标域情况下的域适应问题包括多目标域域适应和领域泛化.多目标域域适应是指目标域样本来自多个子目标域的域适应问题.解决多目标域域适应的方法有两种,一种是对特征解耦得到领域不变性特征,通过领域不变性特征在源域和多个子目标域之间迁移知识;另一种是使用聚类算法将目标域划分成多个子目标域,再使用域适应算法对齐源域和每一个子目标域的分布.领域泛化是指目标域不可知的域适应问题.解决这个问题的关键在于提取泛化能力足够强的特征.领域泛化可以从样本层面、特征层面以及分类器层面来解决.样本层面是指通过数据增广扩大数据集的大小,从而提升模型泛化能力;特征层面是指使用正则项增强特征的泛化能力;分类器层面是指使用集成学习融合多个分类器的分类结果来增强模型的泛化能力.
域适应技术在许多应用领域都发挥了重要的作用,如语义分割、目标检测等.此外,域适应还广泛地应用在医学图像、深度估计、自动驾驶、人脸识别等领域.在实际应用中,源域与目标域标签空间不一致是非常常见的.例如,在应用中,可能会出现没有现成可用源域的情况,这时就可以选用涵盖较多类别的数据集(如ImageNet 数据集)作为源域.在这种情况下,可以认为目标域标签空间是源域标签空间的子集.或者,在其他一些情况中,需要在目标域中增添属于新的类别的样本.这时,源域标签空间是目标域标签空间的子集.根据标签空间之间的不同关系,可以选择使用部分域适应、开集域适应来解决问题.当标签空间关系未知时,可以使用通用域适应来解决问题.当目标域数据分布会随着时间变化时,目标域可以被认为是包含了多个子目标域.多目标域域适应方法适合解决存在多个目标域的域适应问题.此外,在一些情况下,如深空/深海探测,目标域数据在训练过程中是不可得的,这就要求域适应方法必须从源域中学会泛化性能较好的模型.领域泛化技术此时就可以派上用场.
本文展示了一般情况和复杂情况下的域适应中具有代表性的方法在Office31、OfficeHome 和MNIST 三个数据集上的实验结果,并对实验结果进行了分析解释.通过分析对比,读者可以对各域适应方法的性能有一个大致的了解.
最后,本文对深度域适应的未来发展进行了展望,对一般情况下的域适应中的基于领域分布差异的方法、基于对抗的方法、基于重构的方法和基于样本生成的方法的未来发展趋势进行了预测,对这四种方法当前面临的缺陷和可能的解决方案进行了描述,同时还对域适应算法部署在实际应用中面临的问题,即复杂情况下的域适应问题进行了描述.
猜你喜欢
计算机技术与发展(2020年11期)2020-12-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
新校长(2016年8期)2016-01-10
电子与信息学报(2015年12期)2015-08-17
少儿科学周刊·少年版(2015年2期)2015-07-07
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
食品科学(2013年8期)2013-03-11
