
基于神经模糊推理法的复合地层盾构推力预测
2021-04-23 07:28:40杨克形董凌岳
北方交通 2021年4期
杨克形,董凌岳,刘 涛,姜 磊
(1.浙江工业大学 土木工程学院 杭州市 310012; 2.中铁七局集团第三工程有限公司 西安市 710032)
0 引言
目前盾构施工的掘进参数界定方法主要以开挖前采用理论方法[1-3]预估土仓压力,再根据掘进过程中提取的土样性质、监测地面沉降大小调整总推进力。但理论方法预估的土仓压力存在较大误差,根据推进后的监测数据来修改掘进参数具有滞后性,特别是在复合地层中难以及时调整出适合当前掌子面的掘进参数。自适应神经模糊推理系统(ANFIS)结合了神经网络法的数据自我学习能力和模糊规则的知识表达性能。李兴春等[4]利用工程实测盾构掘进参数与地表沉降组成的样本数据,训练得到盾构施工地表沉降的ANFIS模型,经测试表明ANFIS能够高效预测盾构施工引起的地表沉降。施虎等[5]研究了盾构土仓压力与掘进参数的关系,建立ANFIS土仓压力预测模型,并采用该模型实现参数控制的在线优化,实时调整土仓压力平衡。
1 自适应神经元模糊推理原理
自适应神经模糊推理系统(ANFIS)是根据1985年Takagi[6]所提T-S模糊模型建立。T-S模型的主要功能是令神经网络系统中各节点权值分配更加合理,物理意义更加明确,模糊预测规则:
If x is A and y is B Then z=f(x,y)
(1)
式中:A和B为前件模糊数,z=f(x,y)为结论中的精确数,是关于x,y的多项式。
1.1 ANFIS结构分析
以典型的ANFIS网络结构为例,如图1,该模型结构共5层,位于同一层的节点功能相同[7]。

图1 ANFIS网络结构
第一层为计算输入的模糊隶属度,该层共4个计算节点,节点计算函数为:
O1,i=gxi(x,ai,bi) i=1,2
(2)
O1,j=gy(i-2)(y,cj-2,dj-2) j=3,4
(3)
式中,O1,i为第一层第i个的输出值,ai、bi、cj-2、dj-2为前提参数,根据输入变量和输出值的映射关系确定,gxi(x)为隶属函数,选取高斯隶属函数,如下:
(4)
第二层为每条规则适用度的计算,即模糊规则中的“and”运算,一般采用乘积算法。该层节点函数为:
O2,1=w1=O1,1×O1,3= g1,1(x,a1,b1)×g1,3(y,c3,d3)
(5)
O2,2= w2=O1,2×O1,4= g1,2(x,a2,b2)×g1,4(y,c4,d4)
(6)
式中:wi为每条模糊规则输出的适用度值。
第三层为适用度值的归一化运算,节点函数为:
(7)
(8)
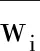
第四层为每条规则输出值的计算,节点函数为:
O4,i=zi=pix+qiy+ri
(9)
式中:zi为输出值,pi、qi、ri为结论参数。
第五层为模糊系统结果输出,该层节点为求和算法节点,输出值为各规则加权平均求和值。节点函数为:
(10)
式中:z为模糊系统输出值。
ANFIS网络结构中的前提参数ai、bi、cj-2、dj-2和结论参数pi、qi、ri决定了输入变量与输出变量映射关系的准确性,通过网络训练进行不断调整,从而实现自适应学习。
1.2 训练结构
ANFIS的训练结构的生成主要有两种方法,即人为指定法和减法聚类法[8]。减法聚类方法能够估计一组数据中聚类个数以及聚类中心位置,是一种高效的数据自然分簇技术。它假定每个数据点都是聚类中心,再通过各个数据点周围数据的密度来判定该点是否为聚类中心。根据减法聚类方法得到的聚类数据的个数和聚类中心,能够按照每一个数据聚类自动划分模糊规则,使模糊规则的数目降为最少而达到最优的数据行为表达。减法聚类法解决了大量高维数据难以处理的问题,并提高了神经网络学习的速度。
2 复合地层盾构参数神经模糊预测系统
依托杭州地铁3号线科(科技学院站)-工(工业大学站)区间隧道工程背景,采用自适应神经元模糊推理系统对区间隧道开挖过程中盾构机掘进参数进行预测与分析。盾构掘进参数预测流程如图2。
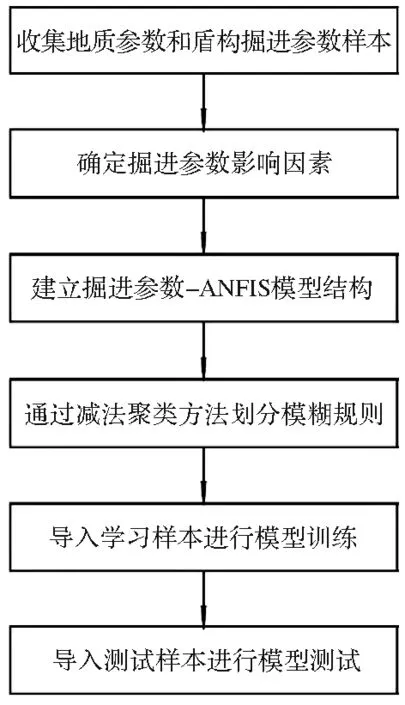
图2 掘进参数预测流程图
2.1 输入参数界定
自适应神经元模糊推理系统将已知数据资料分为两类,一类为输入变量,盾构隧道空间参数及地层参数,包括隧道埋深、洞顶覆土重型动力触探试验值、掌子面土体凝聚力及内摩擦角。隧道埋深为隧道顶部距地表的垂直距离,地下水埋深为地下水位与盾构刀盘顶部距离,洞顶覆土重型动力触探试验值为隧道顶部以上各土层标贯值按层厚取加权平均值,复合地层土体凝聚力及内摩擦角按各地层所占掌子面垂直高度比例取均值。
2.2 系统模型建立
根据ANFIS网络模型原理,建立以4个输入变量和1个输出变量为基础的复合地层盾构推力神经模糊预测系统(F-ANFIS),模型结构如图3。
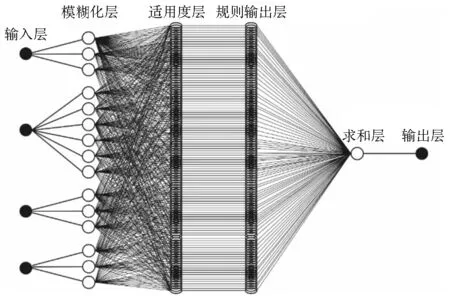
图3 F-ANFIS模型结构
2.3 系统训练与测试
选取科(科技学院站)-工(工业大学站)区间隧道盾构掘进15~74环的盾构机控制参数为预测系统学习样本的输出变量,选取75~94环盾构机控制参数为测试样本的输出变量,根据每环所处空间位置及地质条件选取对应输入变量组成样本。
将训练样本与测试样本分别输入模型进行迭代分析,各模型的训练结果与测试结果的误差随迭代次数的变化如图4,训练样本和测试样本在迭代第93次出现最小误差,最小值分别为1.643和2.781,之后随着迭代次数的增加,误差趋于稳定,故F-ANFIS模型迭代次数选取为93次即可保证推进力预测误差最小。

图4 F-ANFIS训练与测试误差
通过对样本的学习与测试,F-ANFIS模型能够建立起输入变量与输出变量的有效映射关系,即确定第一层各模糊节点的隶属度函数和前提参数,各节点函数和前提参数见表1。

表1 F-ANFIS模糊节点函数与前提参数
3 预测结果对比分析
利用训练和测试完成的自适应神经元模糊推理系统对第95~110环盾构参数进行预测。推进力的预测结果与预测误差如图5、图6,由图可知,推进力预测最大误差为8.27%,每环推进力预测结果与实际施工中推进力的变化曲线基本吻合,说明F-ANFIS模型能够根据地质条件较为准确地预测盾构推进力。
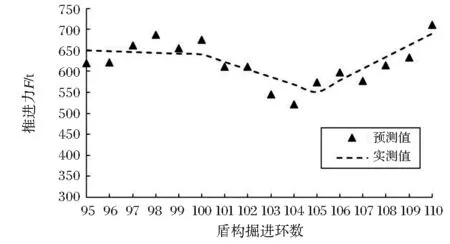
图5 推进力预测值与实测值

图6 推进力预测误差
4 结论
(1)自适应神经元模糊推理系统结合了神经网络法的数据映射能力和模糊规则的数据推理功能,对地质参数和隧道空间结构(隧道埋深、洞顶覆土重型动力触探试验值、掌子面土体凝聚力及内摩擦角)等样本参数的分析和判断,通过建立输入数据与输出数据的模糊映射关系,实现盾构参数的预测。
(2)训练过程中隶属函数和前提参数的选择是ANFIS模型建立的关键,根据训练样本和测试样本中输出数据的分布选取适当的隶属函数类型,通过60个训练样本初步确定,再经过20个测试样本检验得到前提参数。迭代次数的选择会直接影响到数据拟合的优劣以及系统泛化能力,通过对训练样本和测试样本多次的迭代分析,最终确定F-ANFIS的迭代次数为93次,此时训练样本和测试样本的误差最小,分别为1.643和2.781。
(3)F-ANFIS模型预测盾构推力的最大误差为8.27%,说明该模型预测精度较高,能够为实际盾构施工过程中盾构推力设定提供参考。
猜你喜欢
机械设计与制造(2021年8期)2021-08-26 10:55:56
电子测试(2017年15期)2017-12-18 07:19:27
东方法学(2017年4期)2017-07-13 16:45:07
中国房地产业(2016年9期)2016-03-01 01:26:36
工程建设与设计(2016年4期)2016-02-27 10:51:09
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
中国质量与标准导报(2014年7期)2014-02-28 22:24:36
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
城市道桥与防洪(2014年6期)2014-02-27 07:27:25
