
面向源代码可信证据的航天软件可信度量评估方法
2021-04-22 02:45:26陶红伟陈仪香
空间控制技术与应用 2021年2期
刘 晗, 陶红伟, 陈仪香*
1. 华东师范大学软件工程学院,教育部软硬件协同设计技术与应用工程研究中心,上海 200062 2. 郑州轻工业大学计算机与通信工程学院,郑州 450002
0 引 言
近年来,航天技术迅猛发展,软件作为航天技术中必不可少的部分,其功能越来越复杂,规模越来越大,航天软件已经成为人们关注和研究的重点之一.但是,作为安全攸关领域,航天软件日益复杂化带来很多潜在安全问题,一旦软件发生事故,其损失无法估计.因此,航天软件可信性研究不容忽视.
自1972年Anderson JP首次提出可信系统的概念[1],人们便开始研究可信系统.早期,人们对可信系统的研究主要集中在硬件环境和操作系统,直到美国国防部首先在可信计算机系统测评标准中提出可信计算机系统的软件也要是可信的[2],人们才更加关注软件可信性.此后,LAPRIE[3]给出软件可信性与可靠性的区别,认为软件可靠性是可信性的一个子集,可信性比可靠性复杂得多.美国科学与技术委员会 (national science and technology council, NSTC)也在之后提出高可信系统[4],他们认为高可信系统主要关注功能正确性、防危性、容错性、实时性和安全性等性质,并且他们强调用户体验,认为高可信系统必须能在任何情况下都能按照用户预期的情况运行.美国国家研究委员会(national research council, NRC)也认为可信系统需要强调用户体验,可信系统必须在任何情况下都能按照用户预期的目标运行,但是他们提出的可信定义主要关注正确性、私密性、可靠性、防危性、可生存性和安全性,其中安全性包括机密性、完整性、可用性[5].德国奥尔登堡大学可信软件研究院在2006年提出软件可信性应该包括正确性、安全性、服务质量、保密性和隐私性,其中服务质量又包括可用性、可靠性和性能[6].
我国自2000年以来也有很多软件可信研究团队提出了软件可信性定义.陈火旺院士认为高可信性质包括可靠性、防危性、安全性、可生存性、容错性和实时性[7].刘克等[8]也认为可信性是软件诸多属性的综合反映,提出可信软件是指软件系统的动态运行及其结果总是符合人们预期,并且在受到干扰时仍能提供连续服务.
由于软件可信性是多种属性的综合反映,对其量化评估往往非常困难.国内外学者从各种不同角度提出一系列方法来度量评估软件可信性.SANDRO等[9]通过将问卷调查和多元统计分析技术相结合的方法,建立兼顾主观评价和客观度量的软件可信性度量模型.美国国家标准与技术研究院(National Institute of Standards and Technology, NIST)提出一个评估软件可信性的初步框架,它以自上而下的方式,使用形式化的方法得出可信因素的确切数值[10-12].ALEXOPOULOS等[13]以贝叶斯概率和Dempster-Shafer证据理论为基础,提出M-STAR模块化软件可信性体系结构框架.JIN等[14]提出一个可容纳四个子度量标准的系统级信任度度量标准框架STRAM,该框架提供一种分层结构,其中每个子度量定义一个子本体.
国内许多研究团队同样在软件可信性度量领域取得系列成果.郑志明院士和李未院士等人将动力学统计分析引入到软件可信性度量,通过动力学基本方法研究软件可信性及其演化过程[15-17].杨善林院士等[18]将效用理论和Dempster-Shafer证据理论相结合,提出一种基于可信指标树的证据推理算法.王怀民院士等[19]提出一种分层的软件可信分级模型,并通过验证方法对软件进行评估.沈昌祥院士从软件行为角度出发,提出基于并发理论的软件可信性度量方法[20-21].王德鑫等[22]则专注于软件过程,将可信证据融入软件开发的全过程,建立基于过程的软件可信度评估方法.田俊峰等[23]通过检查点来捕获软件行为轨迹,并通过机器学习和余弦相似性的方法来预测软件可信性.陈仪香等[24]则基于公理化方法,将软件属性进行分解,提出基于属性分解的软件可信度量模型.此外,陈仪香等人还通过Extensive结构,研究了面向源代码的软件可信性度量模型.
本文在文献[24]的基础上,从源代码角度入手,建立面向航天型号软件C语言可信证据规范,该证据规范区分关键证据和非关键证据以及可信正证据与可信负证据.此外,本文提出了一种面向源代码可信证据的航天软件可信度量模型和可信性分级模型,最后,本文在NASA开源软件Core Flight Executive 上验证了度量方法的有效性和实用性.
1 软件失效模型与可信证据
1.1 软件失效模型
文献[25]中指出软件失效是指程序动态运行结果与预期结果不一致,这种情况是在软件运行过程中触发软件缺陷造成的.为了更好地描述这一过程,本文首先给出一个软件失效模型来描述不同因素对软件失效的影响,如图1所示.
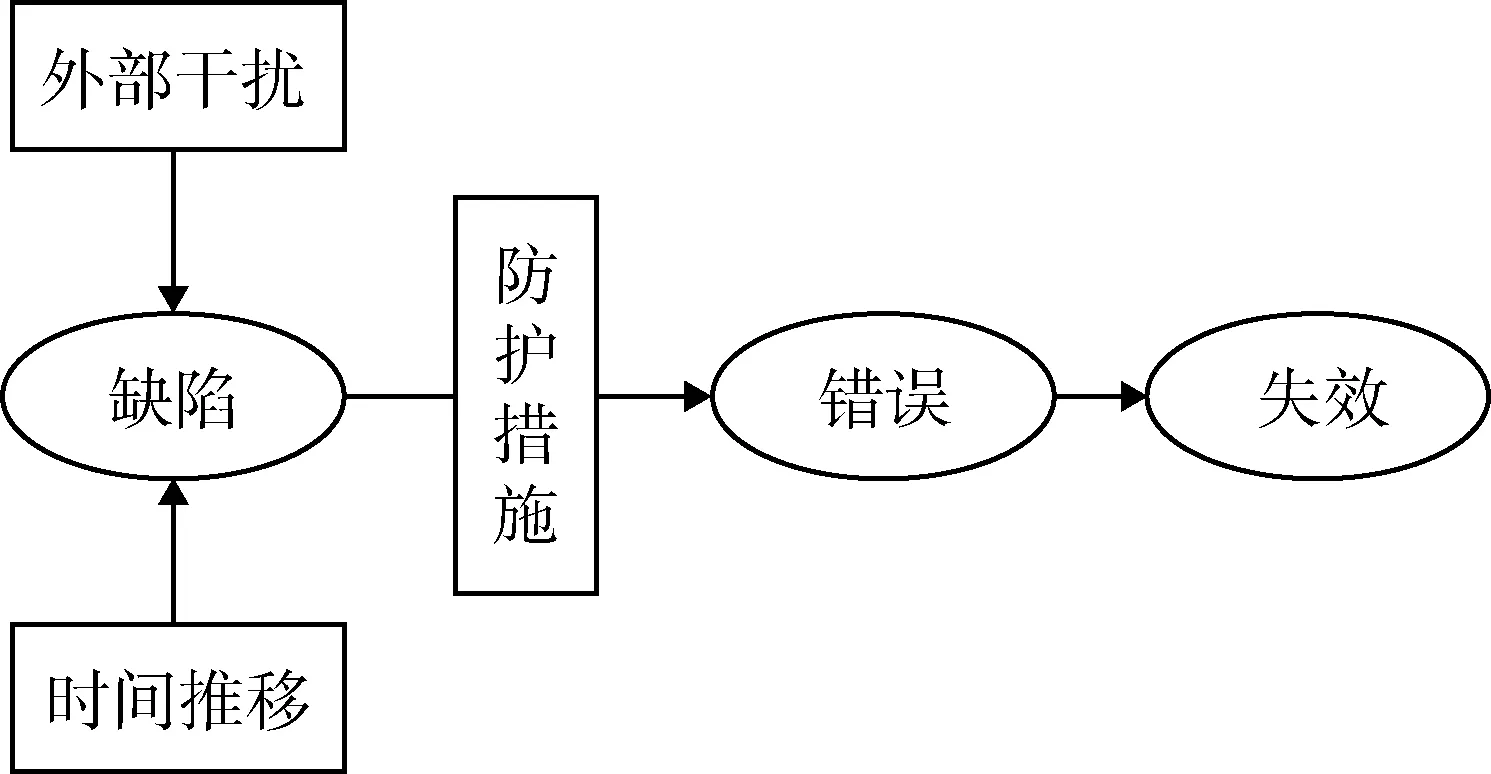
图1 软件失效模型Fig.1 Software failure model
软件在编码开发过程中难免会留下一些缺陷,这些缺陷在正常情况下不会影响软件的预期功能,随着时间的推移或者在某些外部干扰情况下,这些缺陷极有可能被激活,成为错误,导致软件失效,从而使得软件失信,其可信性降低.
1.2 可信证据
国防科技大学的Trustie团队在文献[26]中给出可信证据的一种定义,该定义指出任何与软件相关并能反映其某种可信属性的数据、文档或者其他信息都称为软件可信证据.
由此可见,可信证据是软件可信性的反映,而软件可信性由软件诸多属性的综合构成.本文主要面向源代码来度量软件可信性,因此,本文将软件代码中用来衡量软件可信性的指标依据定义为可信证据.
定义1(源代码可信证据).源代码可信证据是指在软件源代码中用来衡量软件可信性指标的依据,包括表达式类可信证据、声明定义类可信证据、语句类可信证据和参数注释类可信证据.
不同的可信证据对软件可信性有着不同的影响,有些可信证据的出现可能会对软件产生致命的影响,例如,航天类软件代码中一旦出现数组越界情况,软件的运行便很可能偏离用户预期.鉴于此,本文把证据分为关键证据和非关键证据,用来区分不同证据对软件可信性的影响.
定义2(关键证据与非关键证据).关键证据是指源代码中一旦出现或缺失会对软件产生巨大影响的可信证据,非关键证据是除关键证据外的所有可信证据,其出现或缺失不会对软件产生致命影响.
对于不同类别、不同应用场景的软件,用户所期望的预期结果往往不同,相应源代码中会产生致命影响的证据也不完全相同,很难通过统一的关键证据集来衡量.因此,不同类型的软件需要根据软件自身的特性来定义关键证据和非关键证据.表1展示了三个不同类别软件的关键证据.

表1 关键证据示例Tab.1 Examples of key evidence
通过关键证据和非关键证据,可以区分不同证据对软件可信性的不同程度影响,并且可以建立应用于不同领域的可信证据.
此外,可信证据对软件可信性的影响还有正面和负面两种.因此本文还将可信证据分为正证据和负证据,正证据对软件可信性有着正面影响,负证据对软件可信性有着负面影响.
在软件失效过程中,代码中存在的缺陷可以被防护或者可以减轻其影响使得程序按照预期运行.这些防护措施或者减轻缺陷影响的方法的可信证据即为正证据.
定义3(正证据).正证据是指在源代码中所有对缺陷进行防护或者使得缺陷不影响程序按照预期运行的可信证据,它与软件可信性正相关,防护缺陷程度越高或者使得缺陷不影响程序按照预期运行的能力越大,软件可信性就越高.正证据可以用如下的三元组表示:
PositiveEvidence=
其中,Name表示正证据的名称,Metric表示正证据的度量元,分别用A、B、C、D四个等级表示,每一等级包含不同要求,MetricValue表示正证据的度量值,取值范围为[1,10],由度量元的评级映射得到,其中A级映射为10,B级映射为7,C级映射为4,D级映射为1.例如,表2展示了Name为“过程体、循环体、then/else中语句必须用括号括起”的正证据.

表2 正证据示例Tab.2 An example of positive evidence
代码的缺陷受到外部干扰或者随着时间推移,这些缺陷在没有防护的情况下就可能导致软件失效,从而使得软件失信,这些缺陷所对应的证据即为负证据.
定义4(负证据).负证据是指隐藏在源代码中使得软件受到外部干扰和时间推移可能导致软件失信的证据,它与软件的可信性负相关,其风险程度越高,出现的次数越多,软件的可信性越低,可以用如下的二元组表示:
NegativeEvidence=
其中,Name表示负证据的名称,RiskValue为负证据的风险值,取值范围为[1,10],表示该负证据一旦被激活,所产生的负面影响,风险值越大,其产生的负面影响越大.例如,表3列举了三个风险值不同的负证据.

表3 负证据示例Tab.3 Examples of negative evidence
本文在标准[27]给出的航天型号软件C语言安全子集和文献[24]中提出的面向源代码的软件可信规范基础上,建立面向源代码的航天型号软件C语言可信证据规范.该可信证据规范分为表达式类、声明定义类、语句类、参数与注释类等四类,共109个正可信证据,其中,正证据共57个,负证据共52个,关键证据36个,非关键证据73个,具体各类数目如表4所示.

表4 负证据示例Tab.4 Trustworthy evidence statistics
2 面向源代码的航天软件可信性度量模型
2.1 面向源代码的航天软件可信性度量模型框架
为了便于从源代码角度对航天软件可信性进行度量,本文提出了一个面向C语言源代码可信证据的航天软件可信性度量模型框架.该框架如图2所示,首先对源代码进行分析,结合证据集,找出其中存在的正证据和负证据;根据基于正证据类的航天软件可信性度量模型和基于负证据类的航天软件可信度度量模型分别计算基于每类证据的软件可信值;然后根据基于混合证据的航天软件可信性度量模型对得到的可信值进行融合得到最终的软件可信值;最后根据软件可信性分级模型得到软件的可信等级.

图2 面向源代码的航天软件可信性度量模型框架Fig.2 Aerospace software trustworthiness measurement framework oriented to source code
2.2 基于正证据的航天软件可信性度量模型
在面向源代码的软件可信性度量中,从源代码出发得到正证据,这些正证据按照其特点划分为多种类别,在本文中,我们将其划分为4个类别,分别为表达式类、声明定义类、语句类、参数与注释类等4类.根据每类中每个关键正证据和其所占权重计算出关键正证据可信度量值,每个非关键正证据的度量值和其所占权重计算出非关键正证据的可信度量值,由此计算出这一类正证据的可信度量值,基于此本文给出如下基于正证据的航天软件可信性度量模型.
假设正证据共有cp类,第p类正证据共有m个关键证据,s个非关键证据,则基于正证据类的航天软件可信性度量模型计算公式为:

其中,α表示所有关键正证据在正证据中所占权重,β表示所有非关键正证据在正证据中所占权重,yi(1≤i≤m)为关键正证据可信度量值,yj(m+1≤j≤m+s)为非关键正证据可信度量值,αi为关键正证据ei在所有关键正证据中所占权重,βj为非关键正证据ej在所有非关键正证据中所占权重.
该模型符合文献[24]中基于公理化方法所提出的非负性、比例合适性、单调性、凝聚性、灵敏性、替代性和可期望性7个度量属性.该模型还符合“木桶原理”,即单个正证据的度量值较高,最终的度量值不一定很高,但是如果有一个正度量值很低,那么最终的度量值一定很低.
2.3 基于负证据的航天软件可信性度量模型
负证据出现次数越多,软件失效可能性就越大,软件就越有可能向用户预期之外的情况运行,软件可信性就越低.此外,如果源代码中出现的负证据风险值较高,该负证据被激活产生的影响就越大,软件的可信性也就越低.因此,本文给出如下基于负证据的航天软件可信性度量模型.
假设负证据共有cn类,第q类负证据集中共有l条负证据,则此软件在第q类负证据影响下的总风险值为:

(2)
其中,ni为负证据ei在程序中出现的次数,RiskValuei为负证据ei风险值.
软件的风险值表示软件会向用户预期之外运行的风险程度,软件风险值越大,软件可信性就越小.文献[28-29]中提出了一个基于失信证据的软件可信性度量模型,本文在此基础上,将软件在该类负证据影响下的风险值SRValue作为自变量,该类负证据的可信度量值TNq作为因变量,可得到基于负证据的航天软件可信性度量模型计算公式为

(3)
其中,λ为参数,用来调节软件风险值对软件可信性影响大小,一般选择使用软件行数来调节影响.
考虑到式(1)的取值范围是[1,10],而式(3)的取值范围是[0,1],为了使得式(3)的取值范围和式(1)一致,通过分段函数将软件可信度的取值范围映射到[1,10],即

(4)
该模型综合考虑了负证据的出现次数和其风险程度,而且当总风险值较低的情况下,其可信度随总风险值下降幅度较大.反之,当总风险值较高的情况下,其可信度随总风险值下降幅度较小.
2.4 基于混合证据的航天软件可信性度量模型
软件可信性是由源代码中所有可信证据共同决定的,仅通过某类正证据或者某类负证据来度量软件可信性都会忽略源代码中很多要素,因此软件可信性度量要综合考虑软件中所有可信证据.根据每类正证据和负证据所占的权重对正负证据所计算出的软件可信值进行融合,得到基于混合证据的软件可信值,然后根据每类证据所占的权重对各个类的正负证据所计算出的软件可信值进行融合,得到基于混合证据的可信值.基于此,本文给出如下基于混合证据的航天软件可信性度量模型.
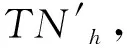

(5)
其中,ωh为第h类证据所占权重,γ为参数,表示正证据和负证据对软件可信度的不同影响.
该模型综合考虑了正负证据的共同影响,而且在由各类证据可信度计算整体可信度时,计算公式同样符合木桶原理.
3 软件可信性分级模型
王靖等[30]在航天嵌入式软件可信性评估时根据计算出的软件整体可信值和各个属性的可信值把软件分为5个等级.在王婧等人的基础上,结合之前所给出的计算模型和关键证据与非关键证据的定义,给出面向源代码的软件可信性分级模型,如表5所示,其中line表示程序行数.

表5 软件可信性分级模型Tab.5 Software trustworthy classification model
该软件可信性分级模型满足以下性质:
性质1.门限性
门限性是指某一可信等级的软件可信值必须要达到此等级所要求最低可信值,其所有正证据都要达到某一等级,出现负证据的风险值不能超过最高要求的风险值.该性质表明要达到某一可信等级的软件,除了其可信值需要达到要求以外,还需要满足正证据的度量值不能太低,出现负证据的风险值不能太高.因此,仅仅某一个正证据度量值或负证据风险值改变不一定能提高软件可信等级,还要提高可信值最低的正证据度量值和避免风险值较高的负证据出现.
性质2.关键性
关键性是指某一可信等级的软件需要满足其关键证据的可信值或总风险值要满足一定的要求.由于不同类型的软件关键证据和非关键证据不同,该性质对于不同类型提出了不同要求.
4 实验与分析
NASA作为美国国家航空航天局,负责规划和实施美国国家航天计划,并展开科学研究.自其成立以来,NASA实施了多项成功的太空计划,其成功必然离不开其高可信软件.本文选取了NASA在代码开源托管平台Github上开源的Core Flight Executive代码(https:∥github.com/nasa/cFE),它是Core Flight System的框架组件.本节将以该系统代码的msg模块为度量对象,验证本文所提出的面向源代码的航天软件可信性度量方法的有效性与实用性.该模块代码行数1256行,包含11个文件,文件结构如图3所示.

图3 文件结构Fig.3 File structure
4.1 证据提取
本文已经根据标准[27]和文献[24]建立了面向航天嵌入式C语言代码的可信证据规范,区分关键证据与非关键证据以及可信正证据与可信负证据.
本文首先依照可信正证据对该源代码进行评估,得到各条正证据的评估结果,其结果如表6所示.其中表达式类共有13个证据被评为A,4个证据被评为B;声明定义类共有10个证据被评为A,4个证据被评为B;语句类所有15个证据都被评为A;参数注释类共有8个证据被评为A,2个证据被评为B.数组下标越界关键证据评为B,其他为A.

表6 正证据度量结果Tab.6 Positive Evidence measurement results
然后根据可信负证据,在源代码中判断负证据的出现次数,结果如表7所示.其中,表达式类负证据没有出现;声明定义类负证据出现3次,总风险值为15;语句类负证据出现17次,总风险值为51;参数注释类负证据没有出现;没有出现关键负证据.

表7 负证据度量结果Tab.7 Negative Evidence measurement results
4.2 可信度计算
本小节通过4.1节中得到的证据度量结果和本文提出的度量方法对msg模块进行可信度计算.本文采用的参数和权重值如表8所示.

表8 参数和权重值表Table 8 Parameters and weight values
其中,为了便于计算,在正证据可信度计算中,由于关键证据每类均是5个,令关键正证据ei在所有关键证据中所占的权重αi均相等,因此αi的值均取1/5,令每类非关键正证据ej在每类所有非关键正证据中所占的权重βj均相等,因此,表达式类权重为1/12,声明定义类权重为1/9,语句类权重为0.1,参数注释类权重为0.2.每类正证据所占的权重均为1/4,每类负证据所占的权重均为1/4.
通过每个正证据的度量结果计算出的此类正证据的可信度量值为:
TP1=0.6×10+0.4×8.87=9.55,
TP2=0.6×9.31+0.4×8.53=9.00,
TP3=0.6×10+0.4×10=10.00,
TP4=0.6×10+0.4×8.67=9.47,
通过各类负证据计算的此类负证据的可信度量值为:
TN1=e0=1.000,
TN2=e-0.015=0.985,
TN3=e-0.051=0.950,
TN4=e0=1.000,
基于混合证据计算的软件可信度为:
T1=9.550.5×10.000.5=9.77,
T2=9.000.5×9.850.5=9.42,
T3=10.000.5×9.500.5=9.75,
T4=9.470.5×10.000.5=9.73,
T=9.770.25×9.420.25×9.750.25×9.730.25=9.6
最终计算得出软件的可信度为9.67,可信度量值大于9.5,但是关键正证据“数组下标越界检查”度量值为B,因此该软件的可信等级为Ⅳ级.
Core Flight Executive作为NASA Core Flight System的核心软件,在开源社区Github获得较多好评,并且NASA在开源该代码之前也使用其作为部分飞行器的代码,因此其可信性较高,本文的可信量化评估结果符合该软件的实际情况.
5 结 论
作为安全攸关的领域之一,航天软件的可信性至关重要.通过有效的方法评估航天软件可信性,并用形象易懂的方式体现出软件的可信程度可以为提高软件可信性和减少因软件不可信而导致的灾难提供依据和参考.
本文首先建立了面向航天型号软件的C语言可信证据规范,并提出了一种面向源代码的航天软件可信性度量方法,分别计算在每类可信正证据和可信负证据的可信度量值,然后使用基于混合证据的软件可信度量模型计算最终的软件可信度.在此基础上,本文提出了一种面向航天领域的软件可信分级模型,用来展现软件的可信程度,并且使用NASA的开源软件Core Flight Executive验证了本文所提出的可信量化评估方法具有很好的有效性和实用性.
猜你喜欢
技术与市场(2024年4期)2024-05-09 00:51:12
——以某大厦地下停车场第二层开挖管道工程为例*
项目管理技术(2023年11期)2023-12-06 03:06:54
中国交通信息化(2023年10期)2023-11-30 06:04:22
计算机仿真(2023年8期)2023-09-20 11:23:42
中国特种设备安全(2022年1期)2022-04-26 14:16:06
现代信息科技(2021年21期)2021-05-07 21:44:50
电脑爱好者(2020年15期)2020-09-12 14:22:28
廊坊师范学院学报(自然科学版)(2020年1期)2020-04-17 07:32:12
山西建筑(2019年10期)2019-04-01 11:02:48
疯狂英语·新读写(2018年3期)2018-09-07 11:10:56
