
基于卷积LSTM 的视频中Deepfake 检测方法
2021-04-20 01:36李永强
网络安全与数据管理 2021年4期
李永强,白 天
(中国科学技术大学 软件学院,安徽 合肥230026)
0 引言
近年来,基于深度学习技术的图像生成技术迅速发展,视频人脸伪造技术也随之日趋成熟。 利用此类技术的人脸伪造技术已经可以欺骗普通人类[1]。但这些技术的滥用也引发了一些社会问题,因为这些技术可以利用公众人物公开的视频、图像素材,伪造公众人物出场的虚假视频,发布虚假的言论,或伪造色情影片,破坏名誉。 由于Deepfakes 项目[2]的广泛流传,这一类技术常被通称为Deepfake。 为了避免Deepfake 技术的滥用,许多研究团体做出了卓越的贡献。 ROSSLER A 等人发布了包含大量Deepfake 数据的公开数据集FaceForensics++[1],以帮助研究人员研究检测算法。 Facebook 开展了DFDC(Deepfake Detection Challenge)比赛并公布了训练数据集[3]。
早期的研究主要是从视频中随机提取帧,使用基于卷积神经网络(Convolutional Neural Networks,CNN)的二分类器进行检测[1]。 这样的方法存在两个问题。一是只使用了单帧信息,忽略了Deepfake 技术的动态缺陷,在低质量场景下容易出错。 二是分类器与训练数据高度相关,不具备通用性,在对数据的生成模型未知的情况下,效果将会大打折扣。
另外有研究从频域角度出发试图解决问题。KORSHUNOV P[4]等人通过构造图片的频率特征或统计特征等方法,构造图像质量指标(Image Quality Measures,IQM),作为特征供支持向量机(Support Vector Machine,SVM)学习,但是通过构造特征的方式需要大量专业知识,不能很好地泛化问题。 QIAN Y[5]等人从频域提取到Deepfake 模型留下的特定频率特征,在特定数据集上获得了较好的效果。 然而无法保证不同的模型能产生类似的频率特征,并且不同的有损压缩方式也会带来频率噪声,对频域特征存在干扰,缺乏鲁棒性。
针对以上问题,本文提出了一种基于深度学习的视频中Deepfake 检测方法。
本文的主要工作如下:
(1)提出卷积LSTM 的模型架构,结合CNN 和长短期记忆网络(Long Short-Term Memory,LSTM)的模型架构,融合了存在于帧间的时间信息,用于视频中Deepfake 检测。
(2)提出一种帧抽取方法,提高了Deepfake 动态缺陷的显著性。
(3)提出一种基于人脸特征点进行cutout 的数据增强方法,抑制了模型学会特定脸的现象。
(4)在公开数据集上进行测试,并与文献中其他算法进行对比。
1 本文方法
通过对相关数据的分析可以发现,使用Deepfake伪造人脸的视频在动态过程中会出现异常抖动。 对于帧之间独立分析的方法无法发现这种抖动,仅局限于发现单帧画面中的瑕疵。 而视频质量较差或使用有损视频压缩算法也会带来许多瑕疵,当模型无法区分这两类瑕疵时,模型的性能将大大降低。 本文提出卷积LSTM 架构,将CNN 与LSTM 进行融合,用于解决传统模型忽略时序特征的问题, 并提出一种基于人脸标记点(landmarks)的cutout 方法,以抑制模型学会特定脸的现象。
1.1 模型架构
卷积LSTM 分为CNN block 和LSTM block,CNN block 负责获取空间信息,LSTM block 则从特征图序列中获取时间信息。 如图1(a)所示,从视频中提取N帧后,使用现有的人脸提取器对这些帧进行人脸提取,得到人脸图片序列,调整大小到CNN block 对应的大小,在训练时,还需进行动态数据增强。假设使用的CNN block 输出512 维的特征图,那么将得到N个512 维向量,在训练阶段,每个向量还将经过多层感知机得到标签的独热编码, 用于约束特征图。 将N个512 维的向量输入LSTM block 中,模型最终按独热编码的形式输出预测标签。

图1 模型架构图
1.1.1 帧抽取
由于生成模型的训练过程中没有唯一标准的答案,因此生成结果具有一定的不确定性。 即对于相似的输入,模型可能生成不相似的结果,尤其是处理毛发、斑点等特征的情况下,无法保证每次随机生成的结果相同,从而导致了视频中的抖动现象。记Ri表示原视频的第i帧,Fi表示Ri经过Deepfake处理过的图像,dr(i,j)表示原始视频中第i和j帧的差异,即Ri和Rj的差异,df(i,j)表示Fi和Fj的差异。通常,dr(i,j)主要受视频中人脸的姿态、光照等条件影响,而df(i,j)还额外受到模型不确定性error(i,j)影 响,如 式(1)所 示。 若|i-j|过 于 小,dr和df均 很 小,造成信息冗余。若|i-j|过于大,则df主要取决于dr,模型的抖动将难以捕捉。 因此,应当在保证一定最小间隔的前提下,选取相对紧凑的选取帧,本文实验中,采用在视频中随机选取时间点,以0.2 s 为间隔采样,采样总长度不超过32 帧。
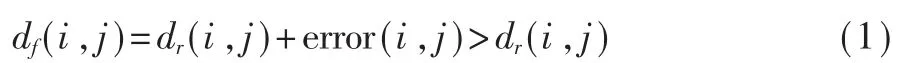
1.1.2 人脸提取
现有的人脸提取算法已经能满足实际需要。 常见的人脸提取器有MTCNN[6]、dlib 等。 本文后续实验中,将使用MTCNN 提取人脸框及人脸特征点。
1.1.3 CNN-block
ImageNet 竞赛极大推动了深度卷积网络的发展,即使ImageNet 早已结束,图像领域的新模型都会在ImageNet 上进行基准测试,并发布预训练模型。基于这样的预训练模型在其他任务上训练,可以加快训练收敛的速度,并且一般会使得模型最终效果更好、更稳定。针对不同的应用场景,有许多开箱即用的模型可以使用。 Resnet[7]系列因为其普遍性,具有良好的可移植性,几乎所有平台都能使用。Mobilenet[8]系列针对边缘节点算力较弱的场景,在可接受的准确率损失的前提下,极大地减少了计算力。 Efficientnet[9]则相反,使用更大的模型,更大的输入尺寸,获得更好的拟合效果。 本文提出的架构设计中,可以根据实际场景轻松地切换CNN-block。 为了后续模块中能保留充足的信息,CNN-block 将会向后输出一个较大维度的向量,如512 维向量,同时为了保证这个向量中包含了有关于训练目标的信息,在训练过程中,对于每个向量,都会经过一个浅层神经网络,输出单帧的标签预测值, 从对特征向量本身进行约束,以提高特征本身对于标签的相关性。
1.1.4 LSTM-block
单独使用CNN-block 无法处理变长数据和有序数据,因此需要结合使用循环神经网络(Recurrent Neural Network,RNN)来处理时间信息。LSTM 是一种特殊的RNN,如图2 所示,本文所用的结构在原始LSTM 的基础上加入了实例正则化(Instance Normalization,IN),这是由于不同的数据可能使用的替换人脸不同,每个图像实例之间独立地进行正则化,可以加快模型收敛。 结合CNN 与LSTM 后,模型拥有融合时空信息的能力,能同时挖掘数据中Deepfake的动态缺陷和静态缺陷,提升了数据信息利用率。
1.2 数据处理
1.2.1 数据增强
常规的数据增强方法依然适用,但是需要注意一点的是,部分增强方法在同一组数据中需要保持一致。 除了1.2.3 节中将要介绍的cutout 方法,本文实验中使用到的数据增强方法如表1 所示。

表1 数据增强方法及参数说明
1.2.2 基于人脸特征点的cutout
cutout[10]是一种数据增强技术,在图像中随机选择一个正方形区域,进行全0 填充。Deepfake 伪造的痕迹主要存在于面部及交界处,直接使用cutout 技术,有可能将面部覆盖,从而引入有害噪声,影响模型的学习。人脸标记点用于定位人脸不同的区域,dlib能检测68 个特征点,如图3(a)所示。 本文实验中,利用这些点划分了6 个区域,如图3(b)所示,区域所用的特征点序号如表2 所示。 每个区域按均等概率进行cutout。

表2 不同区域所用特征点序号
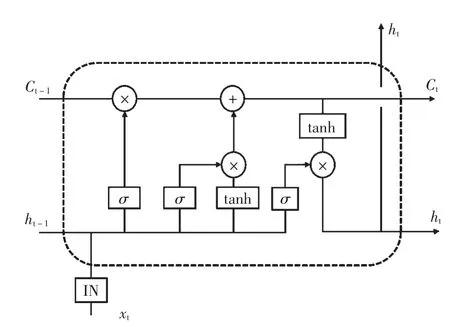
图2 LSTM 单元结构图
2 实验结果及分析
本文实验使用了2 个数据集,FaceForensics++和DFDC。 实验中,将利用DFDC 数据训练CNN 模型,使用迁移学习技术,在完整模型架构中,使用Face-Forensics++对应数据子集进行模型微调,最后在Face-Forensics++对应的子集上进行效果验证。
2.1 数据集介绍
FaceForensics++数据集包含了1 000 个从YouTube上筛选的视频片段,片段以单人视频为主,视频物理分辨率从480p 到1 080p 不等。 通过Deepfakes[2]、Face2Face[11]、FaceSwap[12]以及NeuralTextures[13]四种算法生成伪造视频以及对应的模型。 对于每个视频,根据H264 编码时使用的参数分为无损 (RAW)、低压缩(C23)和高压缩(C40)三种版本,对于伪造视频,还提供了伪造区域的mask 信息。
DFDC(Deepfake-Detection-Challenge)数据集来源于Kaggle 上的算法竞赛,由AWS、Facebook 等共同创建,其中的伪造视频由视频、音频以及音视频同时伪造。 数据集共471.84 GB,分为50 个相互独立的分卷,每个分卷中有若干视频和一个标签文件,每个文件对应的标签中标明了数据是否是造假视频, 对于伪造视频, 还提供了其原视频的标签,相比FaceForensics++, 没有公布进行伪造的算法和模型,也没有提供伪造区域的mask 信息。
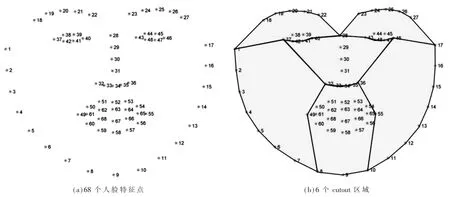
图3 人脸特征点及cutout 区域
2.2 训练细节
为了方便对比基线,实验的CNN 模型选用了Xception[14],单帧输入大为224×224,对应输出feature map 的大小为512。 使用带有梯度裁切的adam 优化器进行优化,学习率设置为0.000 1,损失函数使用focal loss[15],其 表 达 式 为 式(2),αt设 置 为0.25,γ 设置为2,focal loss 可以缓解数据中的不平衡,使模型更专注于难样本。 训练时存在两种约束,需要交替训练。训练CNN 的阶段,设置batch size 为128,迭代次数为10 个epoch,使用DFDC 数据作为预训练。综合训练阶段,使用FaceForensics++的某个子集进行训练,设置batch size 为32,迭代次数为20 个epoch。
2.3 实验结果及对比
本文方法使用DFDC 数据预训练CNN 模块,然后迁移到FaceForensics++对应的数据子集上进行后续的完整训练。 数据子集包括无损、低压缩和高压缩三种质量下的四种算法生成的伪造视频和对应的真实视频进行混合的12 种集合。 结果如表3 所示。 相比于文献[1]中给出的基于Xception 的基线算法,在12 种集合上的效果均有提升,尤其是在低视频质量的情况下,提升较为明显。

表3 在FaceForensics++数据集上准确率对比(%)
3 结论
本文提出了一种用于检测视频的Deepfake 检测方法。 提出将CNN 和LSTM 结合的卷积LSTM,充分利用了视频中帧的空间信息和Deepfake 的动态缺陷这一时间信息。 针对任务目标,提出了一种帧提取方法,提高了Deepfake 动态缺陷的显著性。 提出一种基于人脸特征点的cutout 方法用于数据增强,同时抑制模型学会特定脸的现象。 在FaceForensics++数据集上的实验表明,算法在各种压缩质量和换脸算法下,对比基线算法均有提升。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2016年9期)2016-05-14
