
一种新联合损失函数优化的迁移学习神经网络磨粒识别研究*
2021-04-20 09:07赵春华胡恒星陈小甜谭金铃
润滑与密封 2021年4期
赵春华 李 谦 胡恒星 陈小甜 谭金铃,3
(1.三峡大学水电机械设备设计与维护湖北省重点实验室 湖北宜昌 443002;2.三峡大学机械与动力学院 湖北宜昌 443002;3.三峡大学大学生素质教育中心 湖北宜昌 443002)
近年来对齿轮齿条故障的研究主要是基于磨粒铁谱分析的状态识别[1-3]和基于振动信号的故障诊断[4]。而大模数齿轮齿条长期处于正常的运行状态,监测到的故障状态数据较少,而且其运行速度低,不利于使用振动信号对其进行故障诊断。因此,齿轮齿条的磨粒识别在其故障检测中具有极其重要的作用。大模数齿轮齿条传动装置润滑系统中的润滑油或者润滑脂中包含大量磨损故障颗粒信息,对这些磨粒进行分析有助于发现异常磨损的部位和类型。但大模数齿轮齿条实际工程应用中监测到的数据仍存价值密度低、可利用率低等问题。
针对大模数齿轮齿条的磨粒数据收集困难、标记成本高、训练数据少等问题,本文作者采用了基于一种新的联合损失函数优化的迁移学习的集成模型,从而提升对磨粒的诊断能力。迁移学习主要通过对原域的学习解决目标域问题的一种新的方法,是一种能有效地把已经在大规模带注释数据集上训练的卷积神经网络,转移到有限训练数据量的磨粒图像识别方法。集成模型是将多个模型的优点集成到一个模型来提高目标的识别结果,但是一般化的集成神经网络的成本较高,难以发挥其真正的效能[5-7]。通过文中的训练方法可以有效地实现2个预训练模型的集成。
1 理论基础
1.1 卷积神经网络
卷积神经网络是一种深度模型,其结构分为输入层、卷积层、激活层、池化层、全连接层及输出层,如图1所示。
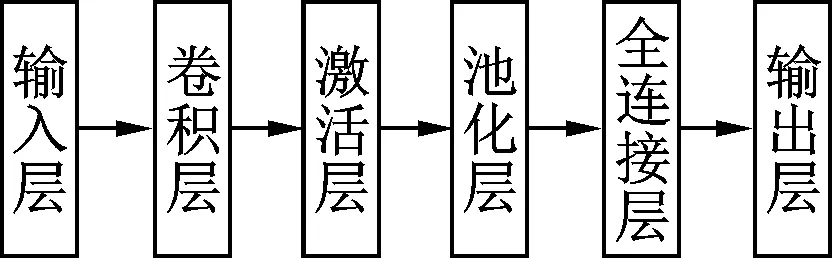
图1 卷积神经网络结构
卷积层是该结构中的主要特征提取部分,卷积核与上一级输入层的局部区域进行逐一滑动窗口的卷积运算,经过卷积过程提取到的特征称为特征图(Feature map)。为了提取更多的表示特征,使用多个不同的卷积核来获取多个不同的特征图。具体的卷积运算如下:
(1)
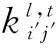
1.2 迁移学习
在机器学习领域,传统的机器学习方法要求训练数据和测试数据服从独立同分布。当训练数据和测试数据的特征分布不同时,就必须利用新数据集重新训练模型。然而,重新采集数据在实际应用中需要耗费巨大人力物力。自1995年迁移学习兴起以来,不断有学者将传统机器学习应用到迁移学习领域,并提出了包括基于核学习的迁移学习[8]、基于流形学习的迁移学习[9]、基于强化学习的迁移学习[10]和基于深度学习的迁移学习等方法[11-12]。
文中采用文献[12]中关于迁移学习一些术语的定义。
定义领域:一个领域D可以形式化地表示为
D={X,p(X)}
(2)
式中:X表示特征空间;p(X)表示X={x1,......,xi,......,xn}∈X(i=1,2,......,n)的边缘分布。
定义任务:给定某一个具体的领域D={X,p(X)},可以将其任务T形式化地表示为
T={Y,f(·)}
(3)
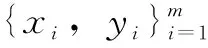
1.3 一种新的联合损失函数

(4)
式中:θD={w,b}为迁移学习模型待训练参数集。
将卷积核参数wD分为公共特征参数和具体域特征参数:
w=w0+vs+vt
(5)
式中:w0、vs和vt分别为迁移学习模型的公共特征参数、仅在源域出现的参数和仅在目标域出现的参数。
迁移模型训练阶段,源域Ds对应的样本中,vt对应的特征取值均为0;目标域Dt对应的样本中,vs对应的特征取值均为0。2个领域通过共享w0来实现相互学习。
迁移学习在实际应用中,Ds和Dt对应的数据量通常存在较大差别,在模型迭代训练时,可以调整不同领域对应的迭代轮数,或对数据进行采样,或通过定义代价敏感的损失函数来调节。同时需要注意的是,迁移学习仅关注目标领域Dt的学习效果,文中通过修改损失函数,来重点学习Dt对应的学习任务Tt。
修改后新的损失函数为
λ2‖w0‖2
(6)
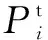
对新的联合损失函数采用AdamW优化算法[13],与Adam相比较,在实际更新参数时按照权重衰减的方式进行更新,即添加权重衰减项。通过这一简单的改进大大加强了Adam算法的泛化性能,且允许它在图像分类任务中获得像带动量的SGD方法那样的性能。另外,AdamW方法可以耦合学习率与权重衰减,即超参数之间不再相互依赖,这使得超参数优化更加优秀;它还将优化器的实现和权重衰减的实现分离开,因此能实现更简明与可复用的代码。
2 优化后的LCNNE模型
基于一种新联合损失函数优化的迁移学习神经网络LCNNE(Convolutional Neural Network Ensemble Based on the New Joint Loss Function)集成模型结构与深度卷积神经网络(DCNN)基本结构类似,都是有卷积层、激活层、池化层、全连接层和Softmax作为最后分类层,区别在于前者是基于新的联合损失函数的VGG19[14]和GoogleNet[15]2个预训练模型的集成。该方法包括4个主要步骤:(1)先将VGG19和GoogleNet预训练模型独立地微调;(2)使用单个微调网络的权重和偏差对集成模型进行初始化;(3)利用联合损耗函数对CNN集成模型进行磨粒图像的微调;(4)最后利用所探讨的基于联合损失函数优化的迁移学习网络集成模型对磨粒进行诊断分类,也可以作为特征提取器提取特征输入SVM进行分类。对于每个预训练CNN的微调过程,使用隐含层神经元个数为100和Softmax层单元数为10的两层替换网络全连接层的最后两层。新替换的层是随机初始化的,在微调之后,最后一个隐含层可以得到特征维数为100的特征向量,可以将其输入Softmax层进行分类,也可以利用SVM进行分类。其结构如图2所示。
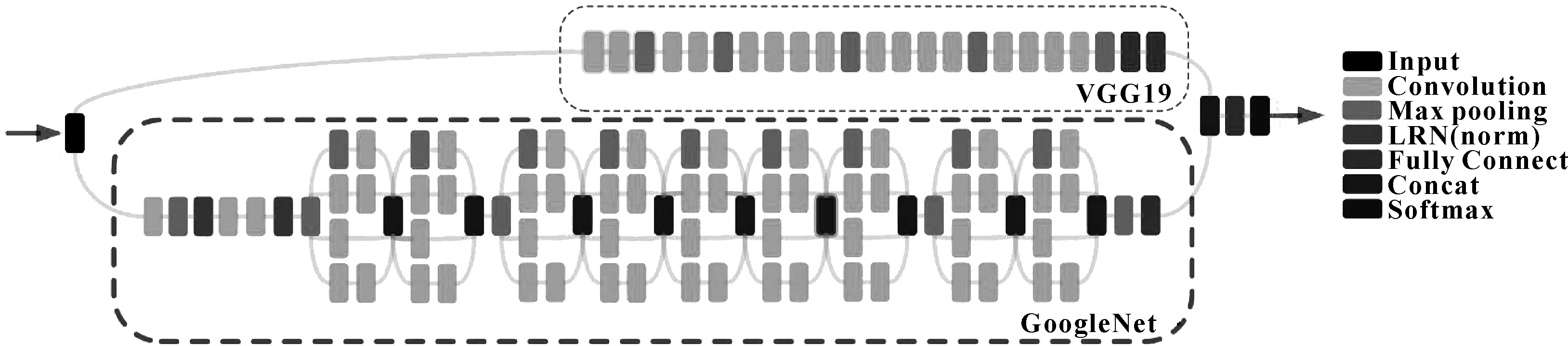
图2 优化后的LCNNE模型结构
3 磨粒诊断试验
文中试验使用的深度学习框架为Google公司的Tensorflow[16]。在Tensorflow环境中使用Python3构建迁移学习网络模型,利用磨粒数据训练模型,将训练好的模型对验证集和测试集磨粒图像进行识别。
3.1 试验数据与预处理
文中所使用的数据源是通过旋转式铁谱仪对齿轮齿条各类磨粒图像进行采集而来。磨粒图像是通过安装在铁谱议铁镜上的索尼3CCD彩色摄像机拍摄的。再利用Synoptics Grabber软件加载到计算机上,在显示器上生成实时图像。
试验中共采集了64张原始磨粒图像,在文献[17]探讨的基础上将磨粒划分为正常磨粒、球状磨粒、严重滑动磨粒、疲劳块磨粒、层状磨粒、氧化物磨粒、切削磨粒、摩擦点蚀磨粒、非铁有色金属磨粒和非金属磨粒共10种类别,采样数分别为6、6、5、5、6、5、10、7、7、7,并分别用0、1、2、3、4、5、6、7、8、9表示对应的类别标签。部分原始磨粒图像如图3所示。

图3 部分原始磨粒图像
为了防止拟合现象的发生,利用Python对所有原始磨粒图像进行随机水平移动、旋转、翻转、改变对比度、色度等处理对原始数据样本进行扩充,最后共得到64×256=16 384张磨粒图像。最终选取了12 400个样本作为数据集,其中训练集为10 800个样本,验证集为800个样本,测试集为800个样本。
3.2 试验设置
使用已经在ImageNet数据集上训练好的预训练模型VGG19和GoogleNet,利用二者的集成模型针对目标领域任务磨粒图像数据集进行诊断。将磨粒微批量大小设置为128,学习率为0.001,迭代训练次数为2 000。同时,设置了3组对照模型,分别为DCCN、单个VGG19与GoogleNet迁移模型。3个对照模型结构如图4所示。
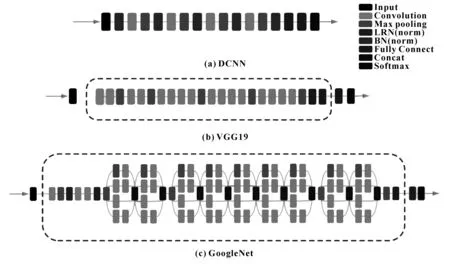
图4 3种对照模型的结构
3.3 新的联合损失函数对试验结果的影响
在保留迁移学习神经网络整个模型的结构不变的情况下,分别测试使用新的联合损失函数以及使用普通交叉熵损失函数2种情况下,模型在不同训练样本数下对磨粒的诊断识别率。
试验结果如图5所示,新的联合损失函数对磨粒图像测试集的识别率普遍比交叉熵损失函数高出0.5%左右,而误差也更低一些,说明使用新的联合损失函数对迁移学习神经网络模型有较大影响。
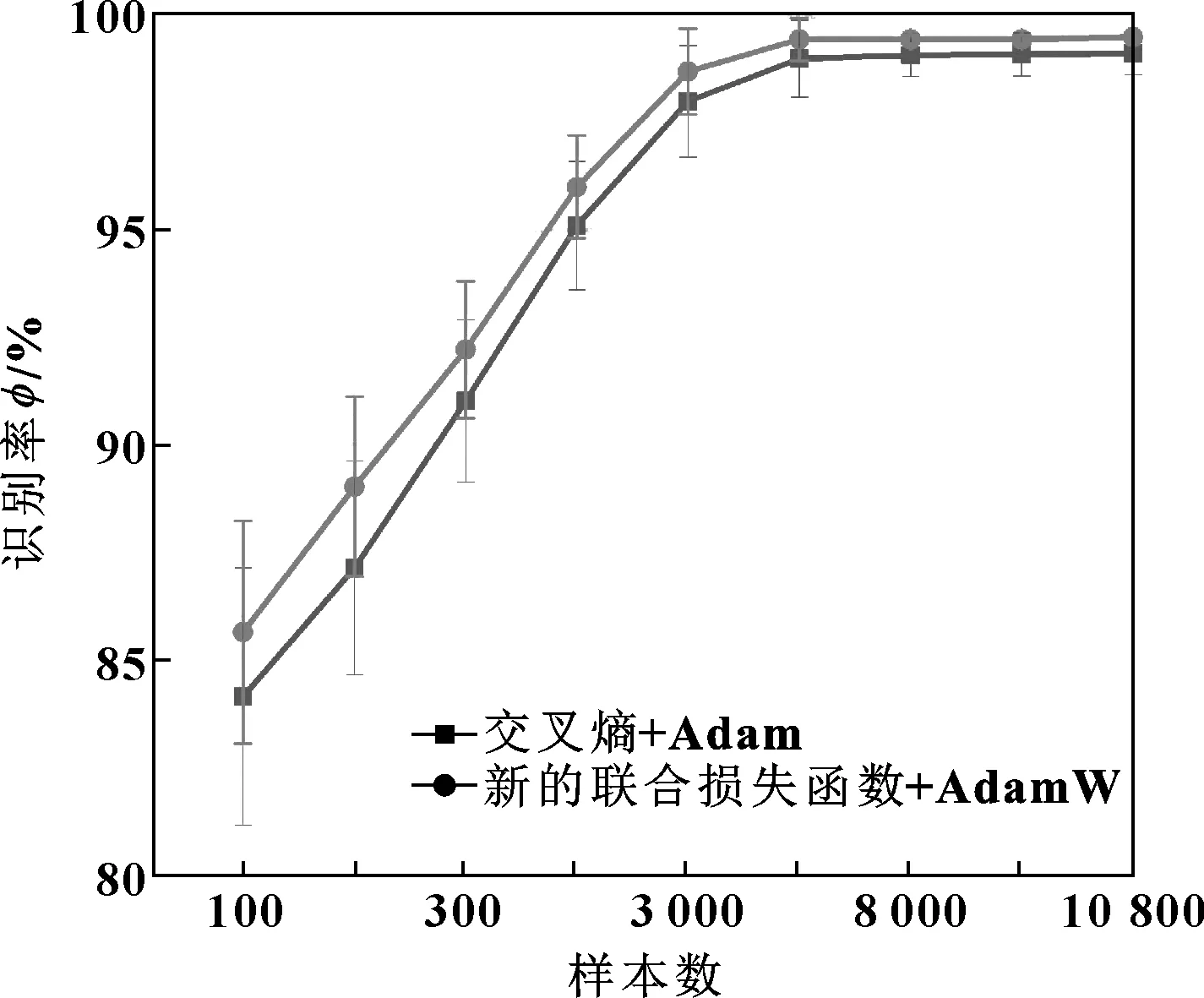
图5 LCNNE模型在不同模式下的识别率
3.4 性能比较
为比较LCNNE与深度神经网络模型DCNN、VGG19迁移模型以及GoogleNet迁移模型在不同训练样本总数下对磨粒图像的诊断识别率,训练集样本总量分别设置为100,150,300,1 000,3 000,5 000,8 000,10 000和10 800,进行了识别试验。由于神经网络的参数是随机初始化的,为了验证模型的稳定性,每个试验重复进行10次,试验结果如图6所示。
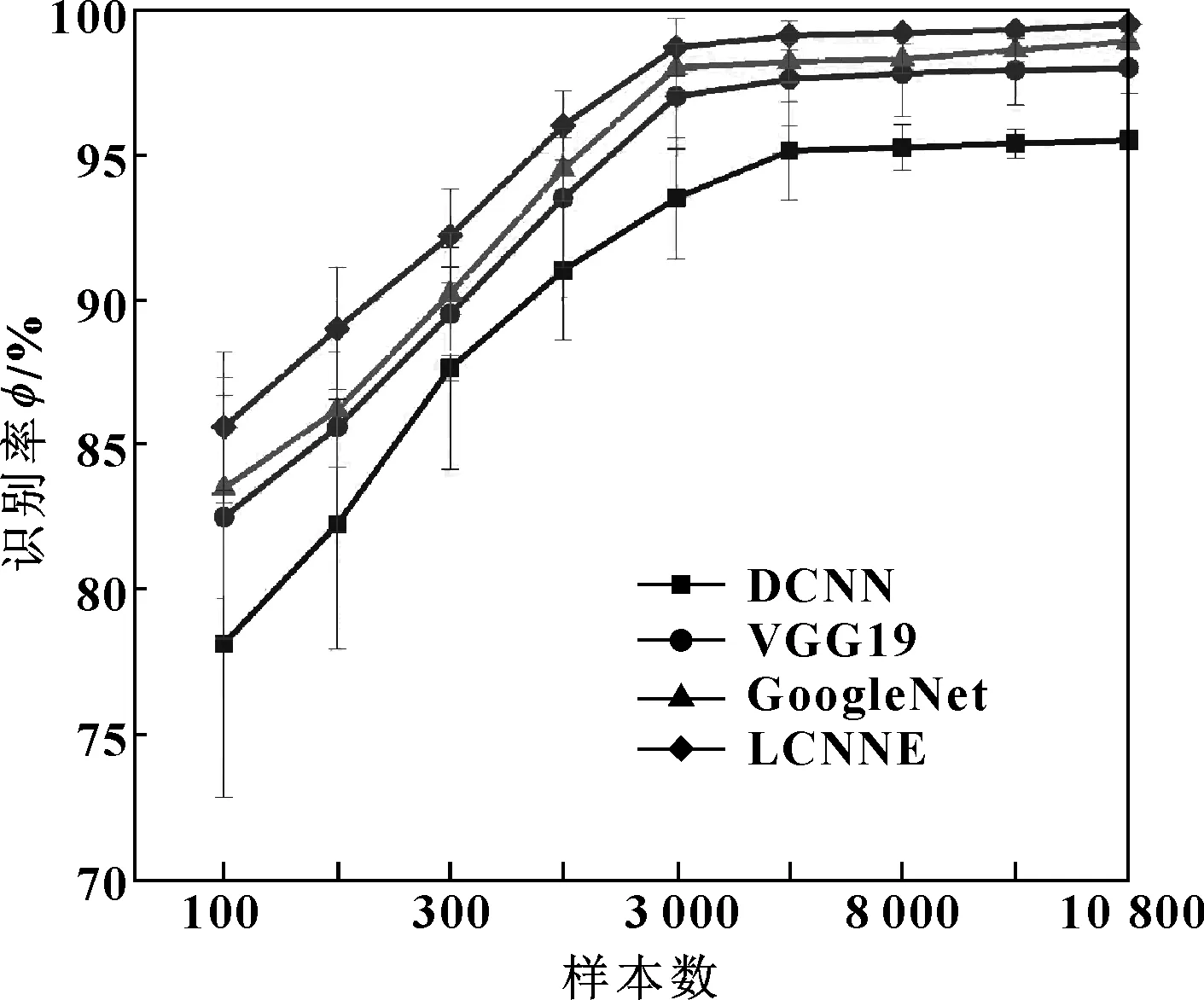
图6 优化后LCNNE与其他模型对磨粒测试集识别率对比
从图6可以看出,模型DCNN、VGG19、GoogleNet以及优化后的LCNNE模型都随着训练样本数的增加,识别率逐渐上升,10次试验标准差也逐渐下降;但是优化后的LCNNE对磨粒图像诊断识别率比另外3种模型都要高,当训练样本数为10 800时,对磨粒图像测试集识别率能达到99.5%,并且误差仅为0.13%,比DCNN的误差0.42%、VGG19的误差0.36%以及GoogleNet的误差0.2%都要低,即优化后的LCNNE的稳定性最好。此外,当训练样本数为100时,DCNN、VGG19、GoogleNet以及优化后LCNNE在测试集上的识别率分别为79.35%、82.5%、83.5%和85.63%,而误差分别为9.88%、4.25%、3.88%和2.62%,即探讨的集成模型LCNNE的性能要比基于单个预训练网络的微调迁移模型好,单个预训练网络微调迁移学习性能比DCNN好。
3.5 模型可视化分析
为了深入理解特征提取对模型性能的影响,利用t-SNE[18]将3.4中4个模型提取的最后一个隐含层的维度为100的特征降为二维后进行可视化,如图7所示。

图7 t-SNE方法对4种模型的最后一个隐含层提取特征的可视化结果
可以看出,从模型DCNN、VGG19、GoogleNet到优化后的LCNNE,最后一个隐含层提取特征的可分性越来越好,这也是文中所提出的模型对磨粒的诊断识别率要高于另外3种模型的原因,其提取的特征表达性最强,有利于分类器对其进行分类。此外4张图中的非金属磨粒类别可分性最强,这与实际操作中非金属类磨粒较其他磨粒类别更易区分的情况是相符的。
4 结论
(1)提出了基于一种新的联合损失函数优化的LCNNE模型对大模数齿轮齿条的磨粒进行识别,并通过试验,验证了优化后的LCNNE模型处理磨粒图像诊断识别问题的强大性能,证明了利用该模型直接做分类要比将单个预训练模型VGG19和GoogleNet提取的特征组成联合特征输入SVM分类性能要好。
(2)通过t-SNE可视化技术,分析了优化后的LCNNE模型能够获得高性能的原因。该模型利用迁移学习的方式,只需要小样本就可以完成目标域任务,为大模数齿轮齿条这种特殊设备的智能自动诊断提供了新的思路。
猜你喜欢
中国机械工程(2022年2期)2022-01-27
数学小灵通·3-4年级(2021年5期)2021-07-16
计算机工程(2020年3期)2020-03-19
表面工程与再制造(2019年3期)2019-09-18
中国听力语言康复科学杂志(2019年3期)2019-06-24
今日农业(2019年15期)2019-01-03
中国交通信息化(2018年3期)2018-06-13
制造技术与机床(2017年4期)2017-06-22
中国交通信息化(2016年2期)2016-06-06
共产党员(辽宁)(2015年2期)2015-12-06
