
机器学习在多相反应器中的应用进展
2021-04-20 10:31朱礼涛欧阳博张希宝罗正鸿
化工进展 2021年4期
朱礼涛,欧阳博,张希宝,罗正鸿
(上海交通大学化学化工学院化工系,金属基复合材料国家重点实验室,上海200240)
多相反应器广泛应用于催化裂化[1-3]、费托合成[4-5]、甲醇制烯烃[6-8]、聚合反应[9-10]等工艺过程,是化工过程的关键装备之一。其内部存在着复杂的多相流动、传递及反应行为,并且这些非稳态非线性行为在时空尺度上相互耦合、相互影响,极大增加了理解并准确预测这些多尺度特性的难度,对反应器设计、优化及放大提出了挑战。近些年来随着高性能计算机的快速发展,以机器学习为代表的人工智能技术逐渐应用于化学化工领域。目前已有较多文献系统介绍了机器学习在多相催化及催化剂设计、反应性能预测、反应动力学建模、化工过程智能控制与优化、物性估算、化学合成优化等方面的应用进展[11-17]。然而,本文作者调研文献后发现,目前较为全面地回顾及展望机器学习在多相反应器中的应用进展的综述较少见诸公开报道。本文旨在回顾并评述机器学习在多相流设备(尤其是多相反应器)中流动、传递及反应特性的研究现状,以促进其更好地应用于多相反应器的学术研究及工业应用发展。
1 机器学习简介
1.1 常用的机器学习方法
机器学习通常分为有监督、半监督及无监督学习,其算法可部署在Caffe、MXNet、TensorFlow 等开源平台上。这些平台框架里内嵌有多种可供用户选择的机器学习算法程序。常用的机器方法包括神经网络模型(例如深度神经网络[18]、卷积神经网络等[19])、支持向量机模型[20]、树模型(例如随机森林模型[21]、梯度提升决策树模型[22])、聚类算法[23]等,如图1所示。其中,神经网络模型也被称为人工神经网络模型(ANN),起源于20世纪50年代对大脑工作机理的模仿,广泛流行于20 世纪80 年代。其具有极强的非线性映射能力及学习能力,目前已成为最为强大的机器学习算法之一。ANN 通常包括输入层、隐藏层及输出层,如图2所示。支持向量机模型来自于统计领域,20 世纪60 年代提出,是二元广义线性分类器,一定程度上是对逻辑回归方法的一种强化;也可通过该学习方法进行非线性分类。树模型是一种基本的分类与回归方法,包括随机森林模型、深度森林模型、决策树模型等。其中决策树包括根节点、内部节点(决策节点)及叶节点,主要涉及三个学习步骤,即特征选择、生成及修剪决策树,旨在寻找最纯净的划分方法,从而生成一棵泛化能力强的树,对未见案例拥有强大的预测性能。聚类算法是针对大量未知标签的数据集,根据数据集内在的相似度把数据集划分成多个类别,使类别内的数据元素相似性较大,而类别间的数据元素相似性较小。关于机器学习方法更为详尽的介绍,可参考相关综述文献[24]。
1.2 机器学习建模过程
机器学习建模的流程性很强,主要包括数据集建立、特征选择、模型调优、模型验证与测试等。下面以机器学习辅助反应器介尺度建模为例具体说明,如图2所示。
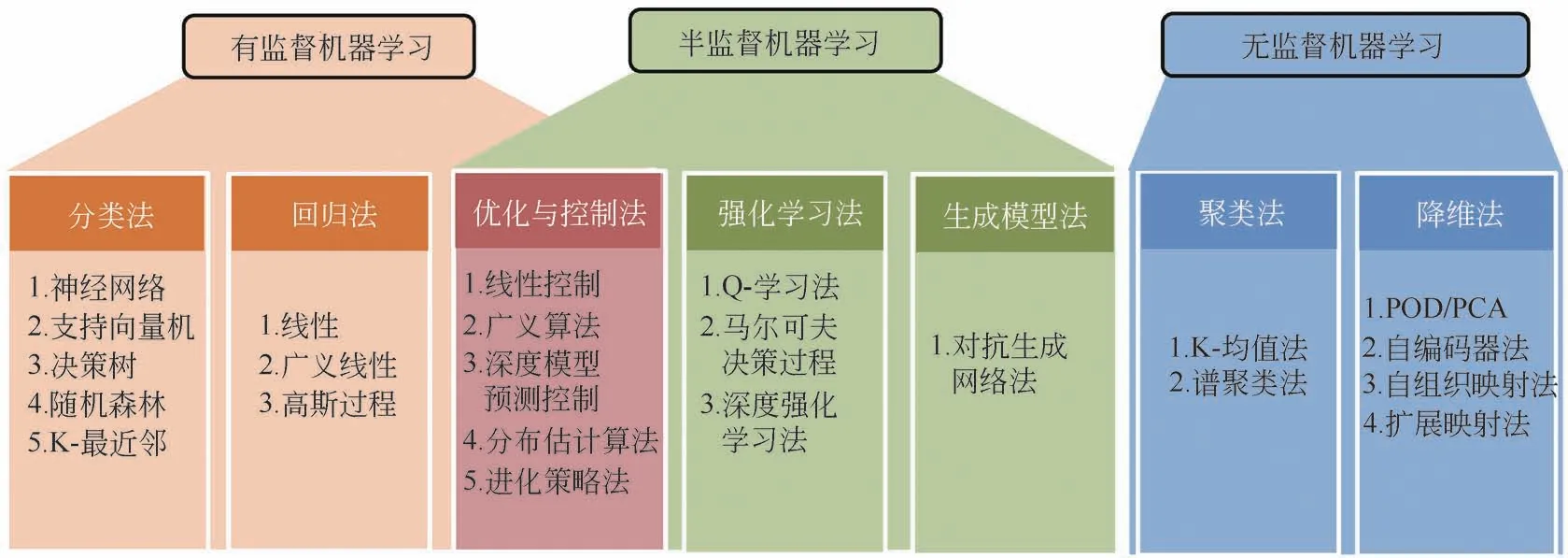
图1 常用机器学习方法分类[24]

图2 机器学习辅助反应器介尺度滤波模型开发步骤[22]
(1)数据集建立 包括数据的采集、预处理(包括检查数据集的合理性与有效性、数据缺失及异常处理等)、标准化(包括归一化、标准化)、数据集划分。归一化是将属性缩放到规定的极大及极小值(一般为1~0)之间;标准化是把数据集根据比例缩放,使之在一个较小的特定区间内,处理后的数据可负可正,绝对值一般不会太大。上述方法可以防止特征输入参数间的量级差异过大。然后还要将数据集按一定比例(例如9∶3∶1)分割为训练集、验证集、测试集。另外,若数据集分布不均,还要对数据集做均衡处理,例如数据集按一定规则做补点处理。对于少数可能不符合物理约束或常理经验的异常特征输入输出值,可能会降低模型预测的鲁棒性及精确性,需做适当的处理。数据集的工况涵盖范围(丰富程度)对于机器学习模型性能尤为重要,在选取及划分数据集时要特别注意。
(2)特征选择 是影响预测结果好坏的关键之一。特征选取个数过多会导致训练时间指数增加,且有过拟合的风险;特征数量过少则缺少足够的信息量用于模型的训练;优质的特征选取会直接提升模型的预测效果。在选取特征输入参数时,主要考虑两个方面:特征参数是否会导致发散。特征参数与目标输出变量是否具有较强的相关性,这决定了所选择的特征参数是否有助于提升模型性能及表达数据的能力。特征选择的方法主要有过滤法、嵌入法及打包法。目前在多相流及多相反应器领域,特征输入参数的选择很大程度上依赖于使用者的物理知识或经验进行筛选,应用上述几种较为理论的选择算法还相对较少,后续需加强此方面的研究。
(3)模型调优 超参数优化是指在验证集上表现性能最佳的参数,例如随机森林模型中树的棵数,神经网络中的学习率、迭代次数、神经网络层数、神经元数、优化器、激活函数及损失函数等超参数的选取和优化,是机器学习算法成功实施与否的关键之一。为达到模型预测最优化,一般需要反复调试。例如,针对机器学习方法应用于气固多相流反应器中固含率、固相循环速率等关键流动参数预测时,若流动数据量较少,则神经网络层数及神经元数一般设置较少即可满足预测精度需求;否则不仅会增加机器学习过拟合的风险,可能也会使得模型训练的时间成本增加、模型泛化预测能力减弱。再比如,应用机器学习方法预测气固多相流反应器中颗粒相介尺度应力时,若仅使用单个损失函数用于数据训练学习,预测效果可能不佳,甚至出现训练发散报错的情形,此时若能将两个不同的损失函数(比如Huber 与MAPE 作为损失函数)耦合使用,有望解决上述问题。与此同时也有一些超参数优化技术,例如网格搜索、贝叶斯优化、梯度提升机等。其中,网格搜索法是一类超强搜索算法,可为待调整的每个超参数获得一组可能的值,然后由模型评估每种组合的预测性能;最后,返回最优预测效果的选择。
(4)模型验证与测试 预测效果除了关注训练性能,还要做验证及测试评估,防止模型可能出现过拟合或欠拟合。同时评价模型性能好坏的指标除了准确率以外,还包括相关系数、均方根误差、平均绝对百分比误差等。以机器学习方法辅助反应器介尺度模型构建为例[22],评价模型性能(尤其是泛化能力)的强弱,主要包括两方面:一是对离线未见数据的预测能力;二是对在线未见预测数据的预测能力(面向应用)。图2 中机器学习模型的最终目标是实现反应器CFD 模拟时,实时在线预测输出计算过程中的本构参数值(例如曳力、固相应力、相间传热等)。另外,训练学习过程中数据集的涵盖范围及数据质量也直接决定了后期机器学习模型应用时的泛化能力,在模型构建与验证测试时,要着重予以关注。
1.3 机器学习与计算流体力学(CFD)集成耦合框架
Rosa 等[72]采用电阻探针测得73 组竖直管中空气-水上升流的流场数据,将所测流场信号转换为统计矩和概率密度函数用于表征目标流型,并划分为6 种不同的流型,即气泡流、弹状流、栓塞流、不稳定栓塞流、半环状流及环状流。研究者进一步比较了单输出及多输出下不同的神经网络模型,包括多层感知、径向基函数与概率神经网络。结果表明,多层感知模型更符合试验数据。进一步与基于k均值聚类算法的无监督机器学习方法比较发现,该方法具有概念简单、开发成本低、计算速度快的优势。
2 机器学习在多相反应器流场中研究现状
2.1 机器学习辅助反应器内流场本构模型构建
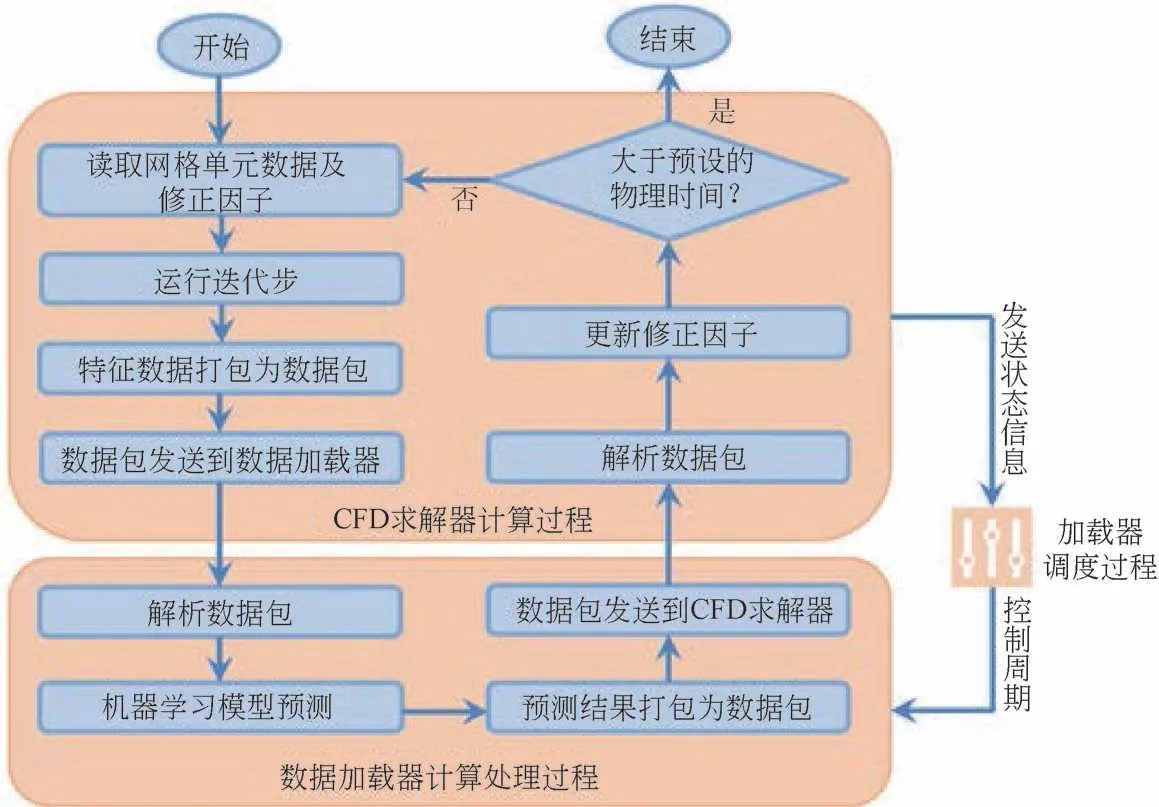
图3 机器学习耦合CFD并行架构流程及数据交换[22]
Shen 等[62]考虑到液-液两相流动易受到大量参数(例如进料速度、物性、设备内径及混合单元结构等)的影响,因此需要一个高通量输出的试验系统来自动采集与分析流型数据。这样不仅可以减轻泵的繁琐操作及流型识别的工作量,而且可以快速准确地收集数万组流型数据。如何在无需人工干预的情况下实现流型的自动识别是构建此类系统的最大挑战。针对此,研究者采用高速摄像机拍摄了5000张液-液两相微通道内流场图,作为训练学习的数据集,用于卷积神经网络模型中。建立了相对通用的流型自动识别平台,可对不同流型进行精准辨别。研究者最后提出了两个量纲为1参数作为段塞流识别的判据。该流型识别系统与进样泵自动控制系统耦合,克服了需要人工干预才能自动识别与控制的问题,实现了流型数据实时在线识别与智能自动控制。该研究为微流控及微反应器技术平台的开发提供了思路。
亚格子滤波模型是目前几种主要的介尺度方法之一,其通过对高精度细网格模拟数据进行滤波统计处理,可以产生大量数据。传统的滤波建模方法首先对数据集进行分桶统计操作,然后再将桶内数据作平均化处理,最后对桶内数据进行关联构建滤波模型。该分桶操作可能导致滤波得到的介尺度信息被平均化而部分失真,不能完整地表达流场特征;并且传统的方法即使针对原始滤波数据做关联构建,由于数据量庞大,也可能会存在数据分析处理效率低、关联预测效果差的问题。针对此,Jiang等[30]考虑到机器学习方法具有高效精确的大数据处理优势,实施了基于颗粒动理学的两相流细网格模拟(网格尺寸为3 倍粒径),并将细网格模拟数据用于ANN 训练开发稠密颗粒流下的介尺度滤波曳力模型。具体而言,研究者根据直接可用的亚格子变量(包括滤波固相体积分数、滤波气固相间滑移速度和滤波流体相压力梯度)对亚格子漂移速度进行了建模;进而利用漂移速度估计亚格子曳力。该研究表明ANN 模型预测性能优于传统滤波建模方法[31]。本文作者课题组在前期介尺度反应器模型开发的系列研究工作中,曾报道:①在介尺度曳力模型中引入“多子域浓度梯度”这一表征局部非均匀性的关键因素,提出了更准确的“抛物线分布”函数,建立了梯度依赖的三参数介尺度曳力模型[26-27];②提出基于“拟稳态”思想,构建了流体与颗粒材料性质依赖的介尺度曳力模型[28-29]。近期基于两类典型的机器学习方法(人工神经网络ANN、极端梯度提升决策树模型Xgboost)[22],提出了机器学习辅助反应器CFD 模型开发的完整步骤(图2)。通过空间滤波方法,提取高分辨细网格两相流模拟大数据(网格尺寸为1.3倍粒径),构建了用于封闭气固相间动量传递的介尺度本构曳力模型。该研究工作定量评估了不同类别的亚格子特征参数对训练预测输出的影响,并证明了三参数是预测未知测试集的最优选择。进一步,研究者们开发了一个并行数据加载器,可实现将机器学习模型与CFD框架集成耦合,如图3所示。研究表明,粗网格CFD 模拟与多工况下反应器流体力学试验吻合较好。该研究为机器学习辅助反应器模型开发提供了易于扩展的途径,有望进一步推动介尺度理论发展的新研究范式。Zhang 等[32]研究发现相邻粗网格信息可提高滤波曳力预测精度,并且包含卷积层的ANN模型预测性能优于多层感知器模型(multilayered perceptron,MLP)及传统滤波方法。此外,也有研究者将机器学习方法用于球形或非球形颗粒系统中构建微尺度曳力模型[33-34]。
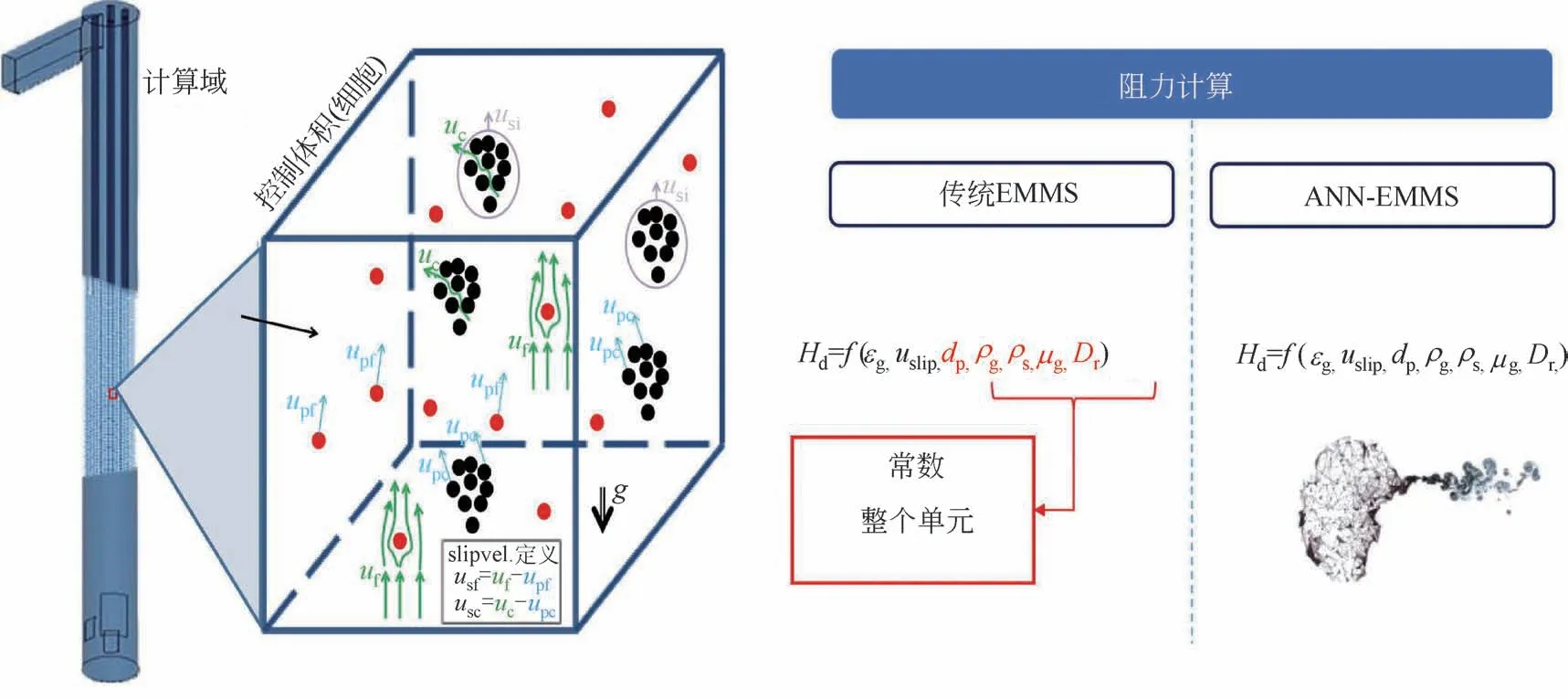
图4 对人工神经网络-能量最小多尺度模型(ANN-EMMS)的一种概念性描述[35]
除了通过机器学习辅助底层数值模拟构建介尺度曳力的方法外,近期Nikolopoulos 等[35]提出了一种机器学习辅助基于著名的能量最小多尺度(EMMS)方法[36-38]的介尺度模型开发思想,如图4所示。研究人员开发了一个ANN 模型来更好地表征介尺度结构的影响。通过定制的FORTRAN代码求解EMMS方程生成数据集用于模型开发、训练及验证。模型输入参数中,除了介尺度参数外,还引入了宏观尺度参数,例如物性参数。在中试尺度循环流化床(CFB)碳酸化炉中的测试结果表明,基于ANN-EMMS 介尺度曳力方法的CFD 模型与纯EMMS介尺度曳力模型相比,预测的平均压降差异为11.29%,反应器出口处二氧化碳浓度的预测差异则小于1%。
近期,也有研究者将机器学习用于构建单相湍流模型或模型参数优化的研究,在单相湍流中得到了诸多实际应用[39-44]。然而到目前为止,大多数雷诺平均方程(RANS)的封闭都是基于单相湍流模型的扩展,尤其当两相之间的双向耦合很重要时,这些模型无法准确捕捉复杂的两相流体动力学特性。针对此,Beetham等[45-46]采用欧拉-拉格朗日模拟生成数据集,并耦合稀疏回归方法(sparse regression method,SRM)用于模型封闭。研究者具体对曳力产生项、曳力交换项、应力应变项及黏性耗散项进行建模,并提出了一个最小张量集作为建模的基础。结果表明,基于SRM 的机器学习方法可获得流动条件下紧凑而精确的代数模型,且用作SRM 的训练数据具有很好的鲁棒性。该代数模型易于集成到常见的CFD 解算器中,为机器学习辅助多相流模型提供了易于延展的新途径。
2.2 机器学习辅助反应器数值建模的不确定度量化分析
多相反应器CFD 数值建模过程中,封闭模型、半经验参数、雷诺应力以及系综平均化计算等因素与物理实际及高分辨率流动结构存在一定的差异,导致数值计算结果存在一定的不确定度。因此,完整的CFD 数值建模过程除了模型的开发(development)、 确 认 (verification) 及 验 证(validation) 外, 还 应 包 括 不 确 定 度 量 化(uncertainty quantification,UQ)分析,以此保证模拟仿真在实际应用中的有效性与可信度。其中UQ分析在计算流体力学学科中发展得相对比较成熟完善,例如飞机、船舶及核反应器等领域[47-50]。近期在上述领域中,机器学习辅助数值建模UQ分析也获得了较多的关注[51]。然而,在化工多相反应器数值建模中,不确定度分析尚未引起足够的重视[52-54]。
Kotteda 等[55]利用开源多相流体力学软件MFiX对气固流化床内的流动特性进行了模拟,并开发了一个基于C++的加载器,用以实现不确定度分析工具包Dakota 与MFiX 框架的耦合,从而在二者之间交换不确定度的输入参数和输出参数。同时,研究者还开发了一个数据驱动框架来获取可靠的统计数据,利用Dakota-MFiX模拟生成的数据,应用采样大小为500 的拉丁超立方体方法(Latin hypercube method)训练机器学习算法。训练和测试的深度神经网络算法通过加载器与Dakota 集成,从而获得床层高度和床层压降的低阶统计量。
Liu 等[51]提出了一种基于贝叶斯算法的数据驱动两相流CFD 不确定度分析方法。该方法利用贝叶斯推理对参数不确定度和模型形式不确定度进行量化,然后将得到的不确定度通过求解器传递输出。为了使贝叶斯模型适用于复杂的双流体CFD模拟,该方法采用了参数空间约简和代理建模两种方法。高分辨率局部变量使得该框架能够同时考虑多个关键参数,并验证了该方法的适用性。
Bao 等[56]为估计粗网格CFD 的模拟误差,实现高效的CFD 两相流预测,通过学习训练以往的模拟数据,建立了一个基于深度前馈神经网络的代理模型。对于鼓泡两相流,所建立的模型可以很好地捕捉并校正粗网格结构中靠近壁面的速度和空隙率分布中的非物理“峰值”。研究结果证明了基于深度学习方法的粗网格CFD 模拟的可行性,对于高效工业设计具有潜在的应用价值。
Ansari等[57-58]采用非侵入式UQ方法对气固多相流CFD 模拟中的不确定度进行分类和量化。为了降低UQ分析所需的计算成本,研究者采用人工智能和数据挖掘领域的常用技术来构建智能代理模型(smart proxy models,SPM),从而降低大规模数值模拟的计算成本。通过观察流化床内的流动和颗粒行为,探究了利用人工智能构建气固多相流SPM的可行性。具体而言,采用多相流求解器MFiX 生成模拟数据,进而利用人工神经网络构建了CFDSPM框架。该SPM能够以合理的误差(约10%)复现CFD 结果,与SPM 未见过的CFD 案例结果吻合较好。该模型可用于任意给定几何形状及不同入口速度情况下,流化床内流动状况的快速预测。
总体而言,机器学习模型预测性能依赖于数据量的大小、模型参数的优化、特征输入参数的选取、异常参数的去除等方面。对这些方面的变化较为敏感,直接影响模型的泛化能力,这可能与机器学习的模型参数较多有关。后续研究需要从机器学习模型框架本身的参数出发,进一步强化模型的鲁棒性及准确性,提高其工况适用性。
目前,绝大多数机器学习工作多聚焦于多相流动特性方面研究,对于多相反应器内部的反应行为研究也相对较少。Serrano等[92]针对实验室规模鼓泡流化床反应器内,生物质气化中焦油浓度数据的收集和分析难度大、缺乏预测气化过程中焦油生成模型等问题,开发了一个人工神经网络用来预测气化过程中焦油的生成。研究者首先通过收集文献数据创建了一个数据库用于学习训练。研究表明,模型结果与文献相符,验证了流场参数变化时产品气中的焦油含量变化规律。与其他模型相比,所建立模型具有更高精度,说明此数据驱动建模方法可有效预测焦油含量,有望为煤气化过程提供了一种有效的预测工具。
2.3 机器学习辅助反应器内流场重构及流型识别
2.3.1 流场图像识别与重构
图像重构是多相反应器内流场检测系统的关键环节之一。然而多相流场往往是一个非线性非平衡的复杂动态系统,给利用传统方法识别与重构流场空间分布图像带来了挑战,例如存在重构图像容易失真、重构速度较慢、在线监测难等问题。近些年来,由于机器学习方法(尤其是深度学习算法)具有重构效果好及速度快等优势,研究者们逐渐将机器学习方法引入到流场图像识别与重构中,并对流场图像背后的机理进行了较为深入的研究[19,59]。Wang 等[60]利用卷积神经网络(CNN)深度学习算法,对方形涓流床反应器中流场图像进行了识别研究,并定量提取了床层中的气液相含率。进而将此方法用于流型辨识中,如图5所示。结果表明:利用平均液相含率可清晰地辨识涓流、脉冲流、鼓泡流等流型间边界;并且在滴流-脉冲流过渡过程中,滴流可以进一步阐释为稳定滴流和加速滴流两个子过程。
Yadav 等[61]采用非侵入式放射粒子示踪技术检测速度场数据。其中,快速的位置重构算法是该技术用于流化床及鼓泡塔等传统反应器设备检测的一个重要挑战。为此,研究者采用了ANN、支持向量机(SVR)及相关向量机(RVR)三种机器学习方法用于速度场的重构。数据集包括“虚拟”鼓泡塔仿真数据集、真实鼓泡塔数据集(共计276组数据)。结果表明,就重构精度方面而言,SVR 性能最佳;就重构速度方面而言,由于RVR 模型更稀疏,其重构速度明显快于SVR。总体上,基于SVR和RVR的重构算法可加快位置重建的速度。
理论上,当时间步长及数值网格足够小时,底层纳维-斯托克斯方程(Navier-Stokes equation,N-S)即可完全解析出反应器内的细致流场结构,例如全解析直接数值模拟(DNS)[25]。然而现实是,即使对于100m 数量级的周期性流场区域,所需要的计算成本仍然十分巨大。为了解决这样的问题,在模拟实际反应器时研究者往往对流体相采用雷诺时均化的N-S 方程形式,例如欧拉-欧拉两相流模型(Eulerian-Eulerian two-fluid model)、欧拉-拉格朗日模型(Eulerian-Lagrangian);但N-S方程在退化为上述两种模型时,会产生额外的未封闭项(例如曳力、升力、湍流耗散力、流体相应力、分散相应力等)。这两种模型可以显著降低DNS数值计算成本,但在使用细网格的情况下计算量仍然十分巨大。因此,目前而言使用粗网格模拟宏观反应器内流场比较经济。然而,在使用粗网格的时候,由于局部非均匀流动结构不能完全解析准确而造成局部信息失真,又带来了计算精度下降的问题[26-29]。因此,有必要在使用粗网格时考虑局部细致流动信息带来的影响,并进行局部流动信息的数值建模,即为亚格子建模(又称介尺度建模)。
Poletaev 等[63]应用卷积神经网络模型识别两相鼓泡射流中的重叠、模糊及非球形气泡信息。该方法的独特之处在于采用与试验中采集的真实照片相似的合成图像训练神经网络。湍动气泡射流试验表明,与传统识别方法相比,该方法可以提高识别精度,减少各类误差,并减少处理时间。此外,利用此方法,可计算出近喷嘴区域气泡喷射的主要物理参数,例如气泡尺寸分布及局部气含率,所得结果与试验数据吻合较好。
近期,Nnabuife 等[64]利用深度神经网络研究了较大气速下约12m 高度S 形提升管内的流型情况:环状流、搅拌流、段塞流、鼓泡流。为增加连续波多普勒超声所获取的样本数量而又不丢失关键分类信息,研究者提出了一种双窗口特征提取方法。为了进一步评估此方法的性能,将其与4种常规机器学习分类器(即自适应提升分类器、装袋分类器、额外树分类器和决策树分类器)进行了比较。结果表明,基于双窗口特征提取方法的分类器实现了更高识别准确度,并且对于过拟合问题具有更好的鲁棒性。
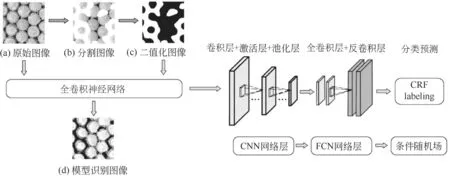
图5 卷积神经网络图像识别过程[60]
上述研究多集中于图像识别用以划分流型的研究,近期研究者对于气泡图像识别也表现出了越来越高的兴趣。Haas等[65]提出了一种基于卷积神经网络的工作流程,试验条件适用范围更为广泛。该方法被称为BubCNN,其采用一个基于区域的CNN检测器来更快地定位气泡,并将气泡形状数据回归用于预测气泡形状参数。研究者系统分析了超参数及神经网络结构,BubCNN在多工况下仍可获得较精确的结果。
Torisaki 等[66]探究了基于人工智能方法如何获取气泡尺寸以及流型转变准则。研究者利用基于CNN 的目标检测方法来提取泡状流的特征。该模型网络能够提取多相流系统内实时气泡流特征。根据检测到的气泡坐标信息,可以快速获取诸如空隙率、气泡数及平均气泡大小等流场特征参数。该方法为通用的全自动两相流特征提取提供了新思路。
服务设计具有创新与创意、活动质量提升、不断跟踪读者需求变化是保持独特的主要方法。这种独特性同样是品牌维护的重要环节。
Effect of exogenous pressure on growth and physiological characteristics
蔡声泽等[67]采用人工生成的粒子图像测速(PIV)数据开展有监督的机器学习及训练,从而建立适用于湍流流体速度预测的深度神经网络模型。该模型可高效地输出单像素级别分辨率的速度流场,射流流场PIV测速试验对深度神经网络的实用性(包括精度、分辨率及计算效率)进行了验证。
上述研究主要针对气-液两相流流场识别与重构,气-固两相流方面的研究相对较少。孙先亮等[59]开发了一种基于卷积神经网络的电容层析成像技术(ECT)的图像重建方法。研究者通过数值模拟手段随机抽取了60000 组具有气-固两相流流型特点的气-固介质浓度分布图像,进而基于有限元法建立了介质分布与电容向量对应的数据集。利用卷积神经网络对数据集进行了学习训练、验证及测试。研究结果表明,所建立的模型可以较好地与ECT流场图像重构的颗粒介质浓度分布吻合。
在气-固两相系统中,颗粒间或颗粒与壁面的碰撞、摩擦会导致固相颗粒积聚大量的静电荷。通过检测和处理感应到的脉动电荷信号,静电传感器检测系统可以获得两相流的流型、浓度及速度等流场信息。为提高气固两相流系统的识别效率,研究者提出了一种将声音识别特性引入到流型识别中的新方法[68]。具体而言,将提取检测到的静电脉动信号的3个特征参数作为后向传播(BP)神经网络的输入层,用于识别流型。结果表明,基于BP 神经网络方法可识别水平管内3 种气-固两相流流型,识别率达到97%,远高于基于单一特征的流型识别方法。Guo 等[69]针对气固流化床内流场ECT 图像重构耗时、在线监测困难且相似流型复现等问题,基于高通量的试验数据样本,训练学习得到了一种可用于在线监测的机器学习模型。研究结果表明:所开发的模型对于固相浓度及等效气泡直径具有较好的预测性及通用性,可为流域划分与识别提供可靠的流场参数。
几个世纪以来,流体流动可视化虽然理论上可以用N-S方程描述,但直接从图像中提取速度场和压力场仍是一个巨大的挑战。Raissi 等[70]开发了一种基于深度学习框架的隐藏流体力学(HFM)方法,能够将N-S方程编码到神经网络中,同时不受几何条件、初始工况及边界条件的影响。研究者通过提取可能无法直接试验测量的定量信息,证明了HFM 在一些物理和生物医学问题中的应用潜力,并且对低分辨率和强噪声的观测数据具有很强的鲁棒性。该工作为复杂多相流体流动可视化问题的解决提供了新思路。
2.3.2 流型及流型转变识别
准确判定并识别多相流设备内部流型及其转变,对于理解流体力学特性,并进一步设计优化与控制多相流设备具有重要的理论指导意义。Trafalis等[71]将支持向量机模型分别用于辨识竖直及水平管内两相流型转变。研究表明,流域转变主要取决于管径及气液相表观气速。与传统理论关联式相比,支持向量机模型预测的流型转变区与多工况下试验数据更为接近。
图3 给出了机器学习算法与计算流体力学(CFD)求解器框架双向耦合集成的一个案例[22],涉及耦合架构、数据流以及CFD 计算过程。要实现二者的集成耦合,首先需要设计一个host数据加载器,负责控制和调度CFD 求解器与机器学习算法之间的数据交换与传递,该加载器支持多核并行分布式计算。当需要部署该数据加载器时,只需要保证每台计算机上运行一个该host数据加载器调度系统即可根据计算机上CFD 求解器的数目自动调度计算。具体的耦合计算过程为:首先读取计算区域内网格单元节点里的流场数据以及相应的亚格子曳力修正因子(初始修正因子设置为1),然后CFD数值程序开始运行迭代计算;在完成一个迭代时间步长后,将机器学习所需要的特征标记参数打包为数据包的形式,并发送到数据加载器;数据加载器接收到数据包后对其进行解析,并将解析后的特征标记参数输入到机器学习模型进行预测;预测结束后,将预测结果(即修正因子)再次打包为数据包的形式,并发送到CFD 求解器;然后解析数据包,将修正因子更新后用于CFD 求解器计算。若未达到预先设置的物理时间,则进入第一步,重新开始新一轮的循环计算;若达到设定的物理时间,则结束计算。
Manjrekar等[73]采用光学探针测得鼓泡塔反应器中流场数据并结合部分文献中数据(70 组数据点),用于数据驱动模型开发。研究发现,检测信号中的两个关键参数,即气泡时间及特征时间,包含了丰富的流域信息,可用于基于向量机的数据驱动模型中,从而识别不同试验工况下所对应的流型图。
教学目标是教学的起点也是终点,一个确切的教学目标有利于数学教学课程的顺利进行。确定目标后会使学生学习有了动力,所以,学习目标的确定是十分重要的。例如,将本学期的教学目标定为教会学生所有的基础知识,将以前的学习成绩这个目标放弃。教学目标的确立,要在调查研究学生的学习能力、对数学课的感兴趣程度、学生的个性的基础上来进行制定,不可好高骛远,达不到的教学目标会使学生对学习数学没有了兴趣,所以在制定教学目标时要贴近实际生活,教学目标与学生的学习目标相统一,将教学目标具体化会对数学课堂起到推动作用,指导教学的开展。
终于盼来了葡萄上市的时节,二叔满怀希望带了葡萄收购商到田里,可是,收购商到田里转了一圈,抽样翻开了部分纸袋,最终都无一例外地摇摇头,总结式地说:“你这个葡萄,串头散,颗粒小,烂果多。”有的收购商连价都不给就走了,有给价的,也是低得让人大跌眼镜。
Mask等[74]收集分析了超过8000组气-液两相流数据,基于3种树模型(即随机森林模型、装袋模型、极端梯度提升决策树模型)研究了气液流型特性。结果表明,流型图主要受流体性质(包括气液相密度、黏度等)、液体和气体的原位流速、流道几何形状及机械性能等参数影响。研究者为减少参数个数,采用量纲分析的方法,提出了3个具有特定物理意义的量纲为1变量用作机器学习的特征输入变量。结果发现,量纲为1变量可显著改善机器学习预测准确性。
Liu等[75]利用高速摄像机获取空气-水旋流管内流场图像。在提取气液相含率后,采用自组织神经网络模型研究了气液螺旋环状流下的流动特性,给出了通用的旋流流域图,用于识别不同工况下的旋流流型,包括旋流鼓泡流、旋流间歇流、旋流环状流。
以上研究主要针对宏观多相流设备。近期研究者也对多相微流体设备开展了机器学习研究。Bar等[76]从文献中收集了561 组微通道内空气-水两相流试验数据点用作机器学习特征输入参数,研究发现反向传播算法、Levenberg-Marquardt非线性最小二乘方法及支持向量机方法均可以较好地用于流型识别。
总体而言,研究者们在将机器学习用于多相流设备内流型识别及流场图像重建研究时,多数体系主要集中在空气-水两相流冷模体系,针对非空气-水两相体系的研究有待加强。例如,通过添加剂调节水相黏度,使之更接近实际体系状况。另一方面,大多体系针对常温常压体系,而对较高温较高压力等体系研究需要加强。需要指出的是,高温高压体系对试验测量设备的制造往往要求更高,测量难度更大。同时,相较于常温体系,机器学习算法需要相应的调整,优选额外的最佳特征输入变量。此外,多数研究集中在与已有试验及半经验关联式的对比,这对于保证机器学习模型可靠性的验证至关重要,但同时应加强将所学习到的物理现象进一步上升到简单易用的显式代数模型层次。
2.4 机器学习辅助反应器内流场关键参数预测
2.4.1 流动及传递参数预测
垂体瘤转化基因[17](PTTG),通常存在于恶性肿瘤中,属于一种较为严重的癌基因,其其能够使细胞增殖、细胞转化等得以有效增加,并致使肿瘤出现浸润性的增长[18]。根据相关研究可知,AM患者的子宫内膜的侵袭以及浸润都与PTTG表现具有直接关联,PTTG蛋白呈现升高趋势,其属于该疾病发展的主要因素。
传统的流场关键参数预测方法主要对采集到的流型数据进行离线分析处理,较难通过瞬态流场数据实时在线预测流场关键参数,因而无法实时在线调控流场。机器学习方法的明显优势之一是可实时在线快速预测并控制流场参数。近些年来,研究者们也逐渐将机器学习方法用于流场关键参数预测,对流场进行了定量分析与表征[77-91]。Gandhi 等[78]较早地开展了支持向量机模型用于鼓泡塔内气液两相流总体气含率的预测。研究者从40 篇公开报道中收集了约1810 组试验数据,特征输入变量包括表观气液速度、气液相密度、气体分子量、分布器类型、喷孔直径及数目、液体黏度及表面张力、操作温度及压力、塔内径等,目标变量为总体气含率。与文献中传统关联式相比较,所开发的机器学习模型泛化能力得到了增强,精确度得到显著提升(平均绝对相对误差约为12.11%)。后续研究采用激光多普勒测速技术(LDA)获取鼓泡塔内数据集,仍采用支持向量机模型得到了回归关联式,可用于总体气含率的在线预测及自动控制[79]。
第四,团队协作的主要内容要由以商为本转为以资本运作为本。以往闽商的团队协作主要集中在如何寻找市场空缺,从而弥补空缺并从中获利,主要在商品流通领域从事买卖活动。现在也有一些人成功转向生产制造,创立了不少的成功企业与品牌。但总的来说,闽商团队在经营理念上主要是以生产与贸易为主,赢利的主要来源是从事商品的制造与买卖。而现代商业环境要求企业不仅能制造优质的产品,善于营销,还要有很强的资本运作意识与能力,赢利不仅靠生产与贸易,也要靠资本运作。所以闽商团队需要实现以商为本精神内涵的转化,在经营理念上既要注重生产营销,也要树立资本经营意识,既注重积累财富,又要注重运用财富。〔1〕13
采用重复测量方差分析法,对两组被试在不同时间点(前测、后测、追踪)的IAS得分进行比较.采用Mauchly球形检验,满足协方差矩阵球对称(P>0.05).从表3可知,IAS的时间效应和交互效应均有统计学意义(P<0.05).经简单效应分析可知,与干预前相比,两组被试的IAS得分都有所下降,但与对照组相比,实验组IAS得分呈现显著降低,其中后测和追踪测试结果显著低于前测(P<0.05).
Bansal 等[80]针对滴流床中关键参数(例如压降、相间传递系数及润湿效率等)对应的工程关联式通用性不高的问题,提出应用支持向量机算法预测关键变量参数。与文献中众多的传统半经验关联式相比,该方法可显著强化预测效果。
Pourtousi 等[81]探究了基于自适应神经模糊推理系统建模,采用CFD 模拟鼓泡塔反应器内流场,提供训练、验证所需的数据集。对不同空间位置的液相速度、湍动能及气含率进行了学习训练,预测结果较好地吻合CFD 原始流场数据,提高了传统方法的预测精度。
煤气化是指通过在大气或高压下将空气和蒸汽的混合物吹入煤床而获得低热值燃料气体(主要包括CO、H2和CO2等)的过程。Chavan 等[94]利用18台稳态运行FBG 的煤气化数据,分别建立了两种基于多元回归(MVR)和多层ANN 策略的数据驱动FBG 模型,对产气率和产气热值进行预测。这两种模型均包含6个特征输入变量,即固定碳、挥发分、矿物质、单位煤的空气供给量、单位煤的蒸汽供给量及温度。结果表明,ANN 模型预测精度优于MVR 模型。该模型有助于设计灰分含量变化的煤气化炉。
黄正梁等[83]基于卷积神经网络(CNN)的深度学习模型,开发了一种气-液-固多相反应器图像分析方法,应用此方法可提取三相反应器中局部气液相体积分数及相应的空间分布等流动参数。进一步采用时间序列信号、小波分析等方法可获取二次参数,用于预测压降与局部相含率等。研究者应用此方法检测涓流床内流场参数,发现平均液相含率可较准确地预测涓流区的压降(平均相对偏差约为15%)。
以上研究多集中在机器学习方法应用于相含率及压降的学习预测。Shaban等[84]应用差压传感器从两相流竖直管中检测的流场变量作为特征输入,以气液相流率为目标输出函数,采用多层反向传播神经网络算法对数据集进行学习训练。与以往方法相比,在竖直管中全流域下,该方法预测气液两相流动速率仍可得到较好的性能。
Chew等[85-86]将随机森林方法应用于循环流化床(CFB)提升管,开展了流场参数敏感性分析研究。结果表明,径向位置对局部固相通量及偏析的影响最为显著,总体固相通量对局部颗粒浓度的影响最大,而对局部颗粒聚团的影响可忽略。此外,如果进行训练时使用足够的数据量,并且特征输入变量充分考虑了所有的影响因素,则可以训练得到预测能力良好的神经网络,而不依赖于任何机理性的认识与理解。此研究强调了机器学习方法有助于理解流态化中流动特性及提供有效预测的价值。
Zhang 等[87]将机器学习方法用于水平气流输送管中固相颗粒流率的在线预测。研究者优化了模型输入参数,并对这些参数进行了基本的标准化处理,从而显著提高了模型的预测性能。进一步将离线所建立的机器学习模型用于在线监测与控制固相流率,提高了模型的工况通用性预测能力。
目前研究者在流场流动特性方面开展了较多的工作,对于流场中热质传递及多相反应过程的研究较少。Gandhi等[88]从10篇公开报道中收集了约366组鼓泡塔内气-液两相流传热数据。基于支持向量机模型开发了一个通用性的传热系数预测模型,其中特征输入变量为操作参数及结构设计参数。Zaidi[89]采用支持向量机方法开展了气-液沸腾设备内传热系数(努塞尔数形式)的学习训练研究,收集了文献中300组有机物试验数据,在模型参数最优化基础上,重点强化了模型泛化能力。Kojić等[90]通过支持向量机回归模型计算不同流型下的流体力学参数及气-液传质系数。该模型能更好地预测气升式外环流反应器内的气含率、降液管液速及气液传质系数。此外,为验证此模型的适用性,将其应用于多篇文献中不同数据上。统计误差分析表明,广义SVR 模型对流体力学参数的平均绝对相对误差可控制在10%以内。
流化床具有良好的热质传递性能,在干燥过程中应用广泛。方黄峰等[91]为了实时监测流化床内生物质颗粒的干燥过程,首先应用弧形静电传感器阵列在实验室尺度的流化床干燥器上开展了多工况试验,测得训练及测试所需数据,然后基于优化的长短期记忆(LSTM)神经网络方法,实现对床层内生物质颗粒湿度较为准确地预测。此研究为流化床干燥过程在复杂多工况下的优化运行提供了参考方案。
总体而言,研究者们多聚焦于机器学习用于多相反应器内流动特性相关方面参数的预测研究,而传热传质方面的研究相对较少。热质传递具有同等的重要性,对于理解反应器内部的传递特性,并进一步对反应器的设计优化以及稳定运行具有重要的作用,此方面的研究还有待加强。此外,目前多数研究聚焦在机器学习模型与文献关联式及试验数据对比验证,较少将学习训练所得模型进一步用于流场参数的优化、多相反应器的设计及优化等。
2.4.2 反应参数预测
暂态功角弱稳定模式辨识及其协调紧急控制策略//崔晓丹,张红丽,方勇杰,李碧君,李威,牛拴保//(1):91
Guo等[93]以蒸汽作为常压流化床气化炉(FBG)内的流化介质,对几种生物质反应物进行了气化研究。为获得每种类型生物质的气化曲线,采用了一种混合神经网络模型来预测该过程。研究结果表明,生物质气化过程中,模型预测的生成气体产率与试验数据吻合,可正确描述生物质气化过程。同时,生物质的种类对于气化反应行为有重要的影响。
Azizi等[82]采用人工神经网络探究了垂直和倾斜管内,油-水两相流中的水含率预测。研究者从文献中收集了468个数据点,以油水表观速度及管道倾角作为输入参数,以两相流水含量作为输出参数,对多层前馈神经网络进行训练及测试。该方法在流型类别未知的情况下,仍具有较高的预测性能。
Patil-Shinde 等[95]利用高灰分煤在中试规模的FBG中开展了大量的煤气化试验,收集到的数据用于遗传规划(GP)和ANN 建模,重点研究了8 个煤气化炉内工艺参数对CO+H2生成率、合成气产率、碳转化率及合成气热值等气化性能的影响。具体而言,采用主成分分析将上述八维变量输入空间简化为三维变量输入空间,并将变换后的3个变量作为特征输入参数。结果表明,GP和ANN模型在预测精度和泛化性能上效果均较为理想。此外,研究者还开展了参数敏感性分析,以确定工艺参数对FBG性能的定量影响。
对于机器学习模型框架中涉及到的超参数,目前大多数研究工作基于研究者经验确定。Pandey等[96]采用多层前馈神经网络对固体废弃物在流化床气化过程中的气体低热值、气化产物的低热值(焦油及夹带焦等)、合成气产率进行了预测。使用Levenberg-Marquardt反向传播算法训练具有不同结构的ANN,并进行交叉验证,以确保结果可推广到其他工况。值得注意的是,该研究采用多重蒙特卡罗方法对神经网络中的隐藏层数、神经元数及激活函数等超参数的优化选择进行了细致的探究。结果表明,基于ANN的FBG性能预测方法较为有效。
Jalalifar 等[97]首先建立了气固鼓泡流化床反应器内生物质快速热解过程的CFD 模型,并用实验室规模的鼓泡流化床反应器进行了验证。随后进行了细致的CFD 参数研究,主要影响参数包括操作温度、生物质流量、生物质与砂粒径、载气流速、生物质喷射器位置及预处理温度。然后基于粒子群优化算法的支持向量回归模型来预测生物油产率最大的工艺条件,进而利用该算法得到的最优参数进行了CFD 模拟,最后将CFD 结果与机器学习模型预测的产物收率值进行了比较,吻合较好。
春光这样明媚,花儿万紫千红,这一切居然无人欣赏,没人理会,她伤感了,难道自己就像无人爱惜的春天,悄悄流逝,年华虚度吗?“没乱里春情难遣,蓦地里怀人幽怨”中,杜丽娘做了个梦,在梦中她见到手持柳枝的少年书生,大胆地和他幽会了。《惊梦》之后,家教已锁不住她,她不顾母亲的教训,第二天又去后花园寻梦。
Zhong 等[98]为了减少生物质快速热解反应器设计和优化的计算量,基于多流体CFD 模型模拟获取了气-固鼓泡流化床生物质快速热解的流场数据,然后应用后向传播人工神经网络算法(BPANN)建立了生物质快速热解反应器的降阶模型。具体而言,模拟了9 种不同热解温度下的产物产率,与试验结果吻合较好。研究者利用BP-ANN将CFD模拟的组分质量含率数据映射到反应器内各计算节点对应的热解温度和坐标上。在优化神经元数目与激活函数基础上,研究了所开发的BP-ANN在训练温度和测试温度下预测物种流场分布的能力。该研究为CFD降阶建模技术的发展提供了新思路。
二语报纸专栏评论写作互动元话语使用考察 ……………………………………………………… 鞠玉梅(4.37)
网络用语大多幽默风趣、风格鲜明,是互联网语言生活方式的代表性特征之一。这十个流行网络用语,生动描绘了网民2018年的关注关切和喜怒哀乐。
由于反应器内局部反应组分信息的检测具有巨大的挑战性,因此机器学习研究所使用的数据集多来自反应器进出口,而基于局部流场信息的研究相对较少。目前可直接检测反应组分信息的检测手段较少,磁共振成像技术作为一种非侵入式检测手段,可准确测得详细的多维瞬态流场信息[99],尤其是反应组分信息的获得,可为机器学习提供高精度的训练学习数据集。此方面的研究后续需要进一步加强。
2.5 机器学习在基于数字孪生的多相反应器工程平台中的应用
近些年伴随着以数字化为基础的人工智能、工程仿真、大数据分析等新兴技术的迅猛发展,数字孪生[100]作为一种数字化转型技术越来越多地受到人们的关注。数字孪生是指通过数字化的方式建立物理实体的动态虚拟模型,实现物理实体真实的多维、多尺度、多物理量等属性及行为信息在虚拟空间中的仿真与映射[101-102]。数字孪生目前已在航天航空等领域取得实际工业应用[103],并引起了以石化行业为代表的流程工业的重视[101]。其中,数字孪生也引起了CFD 与机器学习领域的重视[104-106]。Molinaro 等[104-105]提出了一种用于开发流体物理数据的新范式,包括使用机器学习来扩大模拟数据库,以涵盖更广泛的操作条件范围,并直接提供快速响应。研究人员将这种基于物理信息约束及数据驱动的混合建模方法称为仿真数字孪生(SDT)。研究者使用CFD 工具及数据分析平台,高效地实现了SDT的生成。据本文作者所知,目前从多相反应器工程的角度,结合CFD 仿真及机器学习的数字孪生平台较少见诸于文献报道。为此,本文作者提出了一种基于数字孪生技术的多相反应器工程平台的初步概念图,如图6所示。首先,大数据共享与调度平台主要负责接收虚拟反应器平台及实际反应器内产生的数据流,并基于人工智能技术完成数据分析。虚拟反应器平台在机器学习辅助下,完成对实际反应器的建模、仿真及预测。该多相反应器工程平台主要有两个主要功能:①基于小试、中试试验数据(包括反应器结构、物性、流场行为等数据),在虚拟反应器平台上完成反应器的数字孪生建模与仿真,并进而指导反应器的设计及放大规律研究,这将有助于建立更为可靠的数字孪生反应器放大技术平台,有望缩短反应器多级放大周期;②实际运行的工业反应器数据(包括反应器结构、物性、实时流场行为等数据)经大数据平台分析后送入虚拟反应器平台;虚拟反应器在机器学习辅助下完成建模与仿真,然后用于辅助工业反应器的智能控制、质量检测、故障诊断及产品优化等。关于上述基于数字孪生的多相反应器工程平台的概念思路,后续仍有待进一步的研究及完善。
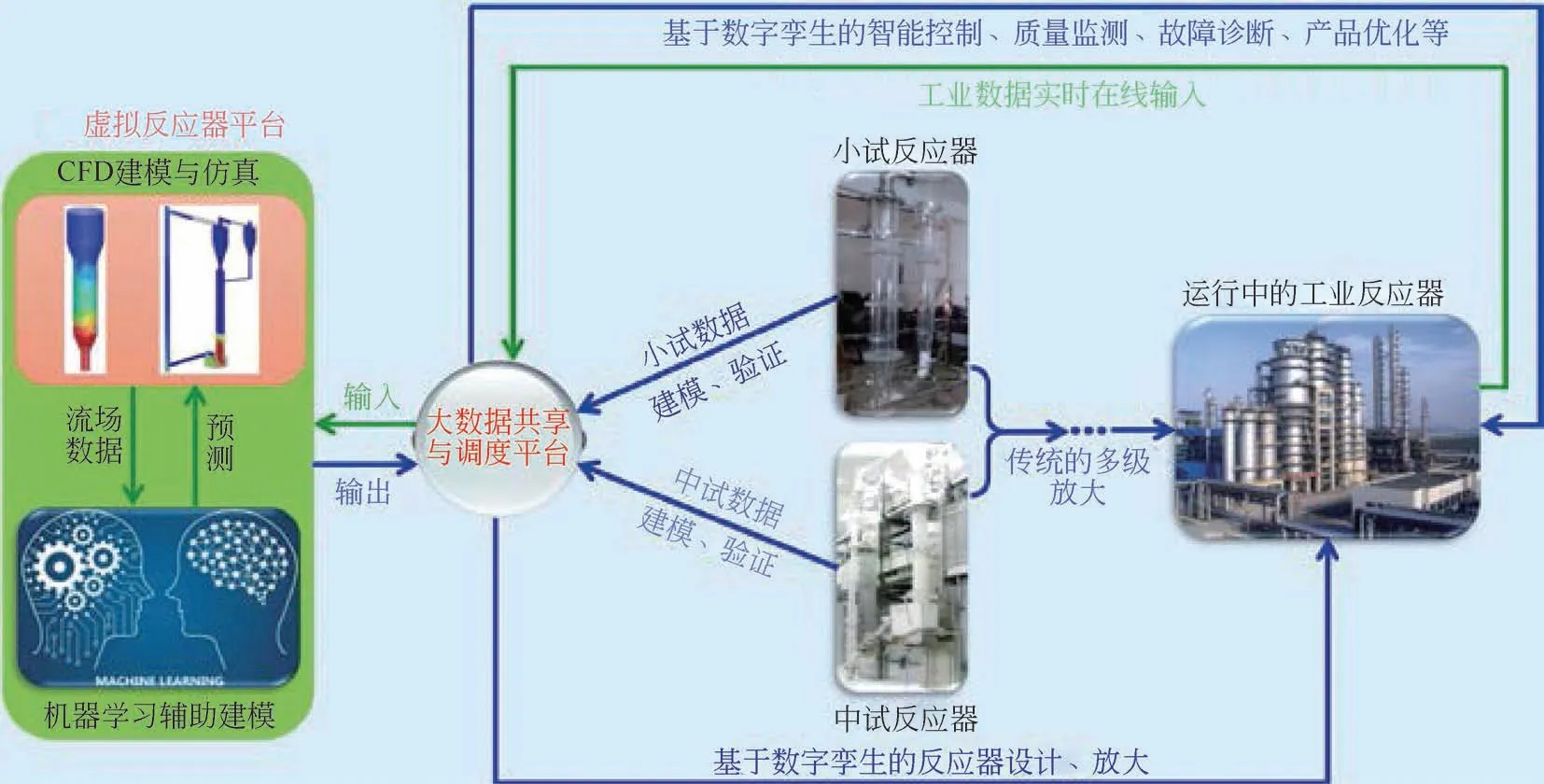
图6 基于数字孪生技术的多相反应器工程平台概念图
3 结语与展望
综上所述,近些年来机器学习越来越多地应用于多相反应器内流动、传递现象及反应特性的研究中,发挥了越来越重要的作用,具有良好的应用前景。本文回顾了机器学习辅助多相反应器中流场本构模型开发、流场图像重构、流型识别、流场关键参数预测及优化、不确定度分析及数字孪生技术平台等方面的应用进展。近些年来随着计算机技术的快速发展,机器学习方法可用于辅助计算流体力学模型开发及应用,构建更加符合实际的多相流动与传递模型,从而为多相反应器的设计优化及智能运行控制等提供理论依据与指导。总体而言,机器学习可以高效精确地处理大数据,较好地表达非线性流场数据特征,易于实时在线预测并控制流场参数,因而在多相反应器中流场本构模型构建、流场图像重构与流型识别、流场关键参数预测等方面具有明显的优势。机器学习可以弥补传统试验与数值方法中的一些不足,对传统方法是一种有益的补充及辅助。希望本文可为机器学习方法后期进一步应用于多相反应器中更多潜在的场景提供借鉴思路及研究范式。
目前,机器学习用于多相反应器的研究也同时面临着诸多挑战,还存在如下可能有待加强拓展的方面:
(1)部分试验研究使用的数据量从几十、几百到几千,一方面数据集的丰富程度较低时可能使工况范围涵盖相对较窄,同时也未发挥机器学习方法大数据处理能力的优势,可能削弱其模型泛化能力。因此有必要建立高精度、高可靠性的大数据共享平台。
(2)文献中多数体系主要集中在空气-水两相流冷模体系,针对非空气-水两相体系的研究有待加强。例如,通过添加剂调节水相黏度或者提高操作温度及压力,使之更接近多相流实际工况。
(3)目前流动特性的研究较多,然而热质传递具有同等的重要性,加强此方面研究对反应器的设计优化以及稳定运行具有重要的作用。此外,多数研究聚焦在机器学习模型与文献关联式及试验数据的对比验证,较少将机器学习训练所得模型进一步用于流场参数的优化,这方面也需要引起研究者们的重视。
(4)近几年,气-液多相设备的研究较多,对于气-固流化床的研究相对较少。气固流化床中往往存在着丰富复杂的非均匀介尺度现象。机器学习辅助气-固流态化领域的研究,可能会为介尺度这一挑战性问题提供新的范式与研究思路。
(5)虚拟过程工程[107]是未来的一个重要发展方向。机器学习模型在离线训练开发以后,需要与多相流检测手段或者CFD 模型求解器耦合,发挥其实时在线预测、智能自动控制与优化的优势,为工程技术人员提供可供参考的运行策略与问题诊断依据。
(6)工程模型(工程关联式)往往要求易理解、参数易获得,且便于工程师及科研人员使用;然而目前多数机器学习模型为黑箱模型,工程师很难将所得黑箱模型直接用于工程设计、放大及优化中,这限制了机器学习模型的实际推广应用。后续可能需加强能提供显式代数模型的机器学习研究。
当然,这其中也离不开对一些基础规范的确立和相关核心指标、拓展指标甚至合作指标的定义。另外,对于基于云的系统必须考虑其安全性问题,即要有相应的基于身份认证、访问控制以及日志服务的数据安全体系建设。
在试验区田间、排水沟道的进水口(前段)、中段、出水口处(尾段)及传统排水的退水洞出水口处采集水样。本试验中的传统排水是指农田的地表水不是汇入渗滤沟道而是汇入传统土沟,再经过退水洞(管涵)直接排入下级沟道或农田周边塘堰。试验期8月中旬至10月上旬,定期监测水质,水稻生育期内每5天取样一次,遇灌溉、降雨、施肥等则需要加测。
(7)在加强上述几个方面研究基础上,综合CFD建模与仿真、大数据共享与分析调度、机器学习等技术手段,本文作者提出了一种基于数字孪生技术的多相反应器工程平台的初步概念图。此概念思路有望建立更为可靠的数字孪生反应器放大技术平台及实现工业反应器的在线监测诊断优化等功能,不过后续仍有待系统的研究及完善工作。
猜你喜欢
汽车实用技术(2022年19期)2022-10-19
原子能科学技术(2022年8期)2022-09-06
制冷技术(2022年2期)2022-08-01
节能与环保(2022年4期)2022-06-02
浙江大学学报(农业与生命科学版)(2021年6期)2022-01-08
科学技术创新(2021年7期)2021-03-23
山东工业技术(2016年15期)2016-12-01
舰船科学技术(2016年1期)2016-02-27
汽车实用技术(2015年8期)2015-12-26
专用汽车(2015年8期)2015-03-01
