
语义驱动下水面场景中AR效果提升方法
2021-04-15 03:48余思雨李逸文
计算机应用与软件 2021年4期
余思雨 齐 林 李逸文 帖 云
(郑州大学信息工程学院 河南 郑州 450001)
0 引 言
近几年增强现实技术(Augmented Reality,AR)由于硬件门槛显著降低、资本逐渐聚焦和政府政策支持等因素而逐渐兴起,成为移动互联网向人工智能时代演变的发展重点。除了几何一致性的要求外,大多数AR应用中越来越注重真实和虚拟对象之间的视觉一致性,这可以使增强现实效果更加逼真[1]。然而各种复杂的户外环境始终是AR应用场景不断拓展所面临的一个挑战[2]。水面是生活中不可缺少的景观,在这样的场景下改善增强现实效果可以极大地丰富用户体验并进一步拓宽AR的应用领域。
同时定位与地图构建(SLAM)被认为是传统AR跟踪方法的一个很好的替代方法,因为它避免了先验信息的必要性[3]。将语义与现实环境中的真实物体相关联也已经成为一个流行的研究领域。Sünderhauf等[4]利用深度学习目标检测方法SSD与ORB-SLAM2相结合,输出带有语义信息的语义地图,但场景中的动态物体会影响SLAM定位和建图。Zhong等[5]通过目标检测去除动态点,由于目标检测方法无法达到实时,因此只在关键帧进行检测以保证目标检测线程和SLAM线程同步,然后通过特征匹配和扩展影响区域的形式进行运动概率的传播,并在SLAM过程中去除动态点的影响,只利用静态点进行追踪。Kaneko等[6]注意到了天空对SLAM精度的影响,采用DeepLab v2[7]与单目ORB-SLAM[8]相结合,通过语义分割得到天空和动态物体的掩膜,使ORB特征点的提取范围在掩膜之外分布即天空和动态物体上无ORB特征点。对于大多数基于特征的单目SLAM系统,水面的反射将导致视觉误差,而且它无法区分特征点是在真实物体上还是在反射上,所以需要语义信息的辅助[9]。因此检测出水面区域是十分有必要的。赵一兵等[10]针对静态水面特征呈现出的较高亮度、较低饱和度以及平滑的纹理特征,提出将饱和度亮度比值颜色特征和从灰度共生矩阵中提取的纹理特征融合的野外水体障碍物检测方法。此类方法受环境条件影响较大,面对不同水域、不同天气条件不具有普适性。另一类方法采用对称检测的方法[11-13],通过边缘检测,再把实物与倒影进行镜像匹配计算对称轴,从而检测出倒影。此类方法在物体与水面倒影完全对称时的效果较好,但是不适合在视频中应用于全景图片。总体来说,相关研究还处于起步阶段,对传统检测方法来说水面的形态颜色等特征多变、由于波动纹理复杂并且水面由于物理光学特性会发生反射而产生倒影等不确定因素,水面检测始终是一个难题。随着深度学习的发展,语义分割的结果得到了极大的改善。
本文提出一个基于深度学习进行语义分割驱动SLAM在水面场景下进行增强现实的方法。深度学习模型采用ICNET[14],用于实时的语义分割,提供水面的分割标签图传入ORB-SLAM2系统[15]的前端,语义指导SLAM对地图中不同区域的特征点进行分类,在实际的空间中将SLAM三维立体信息与语义标签结合起来,从而可以在不同类别的物体上进行增强现实。最后根据水面的反射特性,增添虚拟物体相应的倒影,改善虚实一致性,使物体水面上的增强现实效果更加逼真。结果表明,该系统使用单个GPU加速实时性达每秒27帧以上,满足增强现实实时性的要求,且水面检测率达87%,满足基本要求,最终增强现实效果也得到了提升。
1 基于ICNet的水面场景语义分割
1.1 ICNet网络模型
由于增强现实实时性的要求,传统方法对水面的检测大多基于单幅图片,且速度难以达到实时性要求。目前深度学习中的卷积神经网络(CNN)使用最为广泛,相比传统方法表现出强大的特征提取能力。目标为语义分割的CNN网络模型中,ICNet、ENet[16]、SegNet[17]均达到实时性的要求,但就Cityscapes[18]数据集上的分割精度来看,ICNet远远高于其他两种模型[14]。因此选用ICNet网络模型,在TensorFlow框架下进行训练。
ICNet在PSPNet[19]模型基础上继续使用金字塔池化模块,之后引入级联特征融合模块,并使用三个分支进行特征融合形式的训练,实现快速且高质量的分割模型,该模型结构如图1所示。
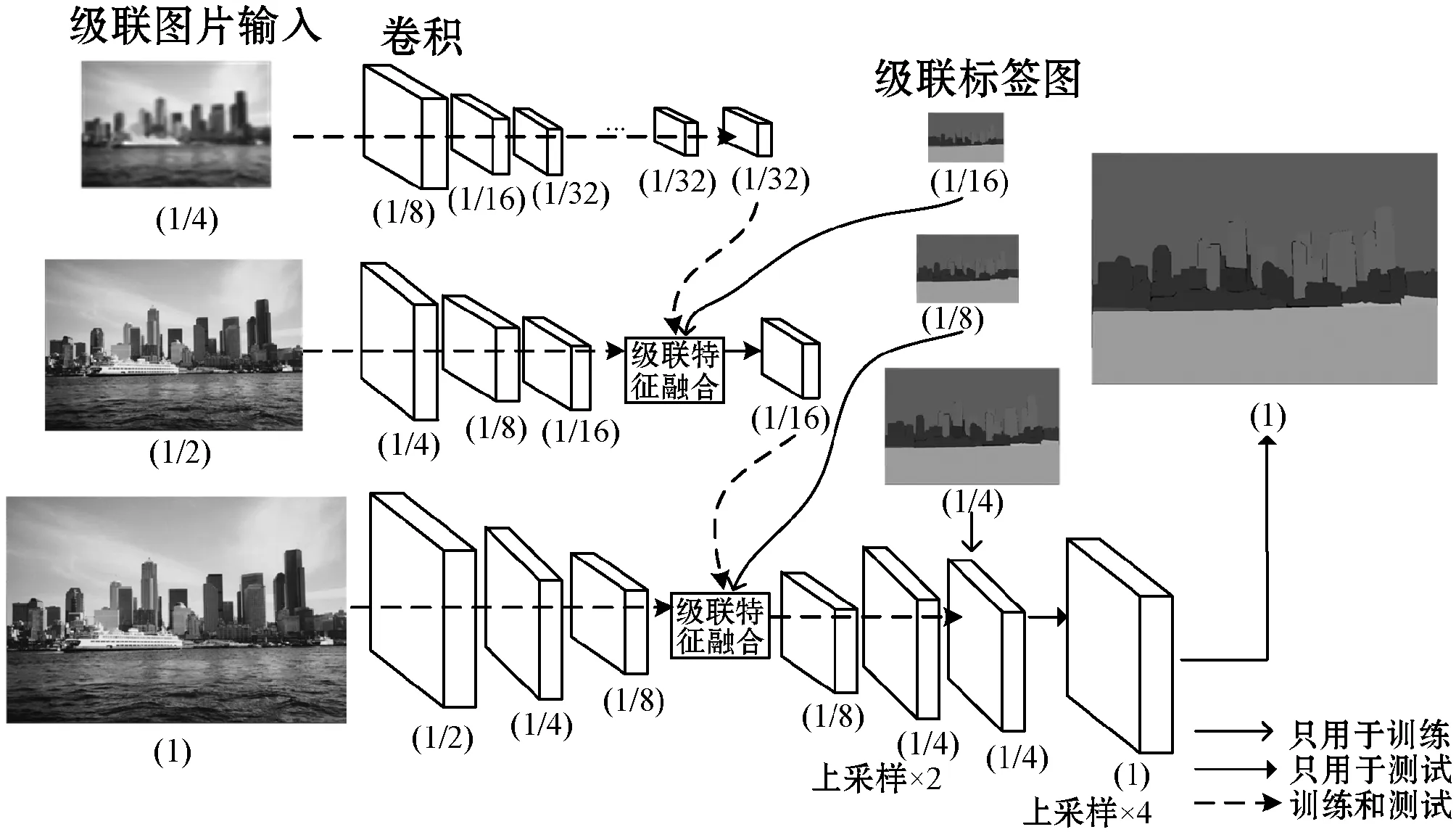
图1 ICNet网络模型结构
1.2 数据集的制作与训练策略
系统需要输入连续视频帧,目前有关水场景的动态视频的数据集很难搜集,因此人工采集了城市内一些常见的水场景,例如校园、公园等。数据集内含40段视频,每段时长在1~2分钟之间。每段视频通过抽帧的方式选取不同角度的场景进行标注,共1 000幅。数据采集过程如下:
1) 拍摄阶段。选择光线良好的有水面的室外场景,手持imx498摄像头,以步行的运动方式,缓慢平移或旋转以拍摄周围环境的视频,尽量保证视频无模糊、少抖动。
2) 标注阶段。对选出的图片集进行人工像素级的标注,统一使用labelme多边形标注工具,将水面区域标注为1,背景(其他区域)标注为0。
将标注好的图片集打乱顺序,选择前800幅作为训练集,后200幅作为测试集。测试集用于检验模型的泛化能力,对模型语义分割的性能进行评价。由于本实验仅将图片标注为水域和背景两类,而且数据集相对较少,因此引入迁移学习的概念,在对数据集进行训练时,采用ICNet在Cityscapes上的预训练模型。
2 融入语义分割的SLAM建图
提出的语义SLAM系统如图2所示。在ORB-SLAM2原有的基础上增添了语义分割线程和语义驱动下的增强现实模块。将原视频帧和经过深度学习语义分割后得到的标签图送入SLAM的前端作为输入。标签图中水中的像素点亮度值为1,背景中的像素点亮度值为0。进入追踪线程对原视频帧提取ORB特征点。根据相邻帧间特征点的匹配进行姿态估计或通过全局重定位来初始化位姿。然后跟踪已经重建的局部地图进一步优化位姿,根据规则确定新的关键帧。在局部地图构建的过程中,将地图点进行分类,根据地图点对应的已缓存入追踪线程的ORB特征点在标签图中的同位置的像素值赋予不同类别的标签,再使用局部捆集调整(Local BA)进行优化。最后再对插入的关键帧进行筛选,去除冗余的关键帧。闭环检测线程分为闭环检测和闭环矫正两个过程,通过这两个过程对SLAM整体建图进行图优化。
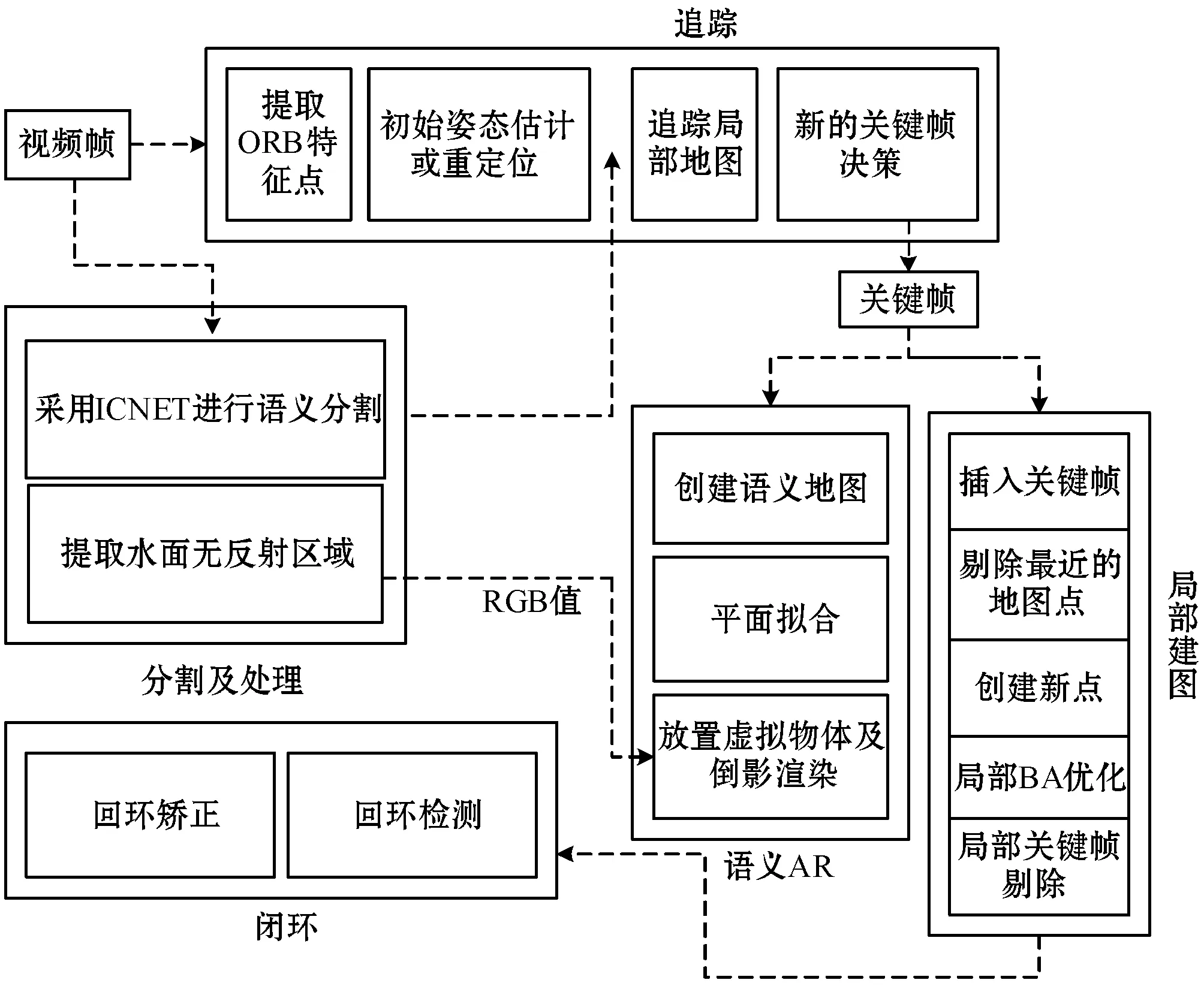
图2 系统架构图
3 语义驱动下的增强现实
光照一致是增强现实研究中实现虚实融合的一个重要方面。光照一致性主要关注真实场景中的光照对虚拟对象的作用,包括明暗、反射、阴影等。在水面反射的场景下,虚拟物体受到户外复杂环境光的作用下应该在水面产生反射。这个反射的颜色同时受到水体颜色和虚拟物体本身颜色的影响。
3.1 3D模型倒影的生成
得到带标签的3D地图后,系统图选择标签为1(水域)的地图点,并采用随机采样一致(RANSAC)算法进行平面的拟合[20]。该算法假设平面模型的方程为Ax+By+Cz+D=0,每次从标签为1的地图点中随机选取三个点,计算由这三个点构成的平面模型,然后按照给定的阈值去拟合其他点,重复该过程直至达到最大迭代次数,选取包含最多点对应的平面模型作为最优估计。该平面作为放置3D模型的平面,显示出3D模型放置在水面的效果。
水面反射遵循镜面反射原理。成像原理遵循光的反射定律。倒影具有与真实物体相同的大小,且它们对应点的连线垂直于反射面,且真实物体到反射面的距离与倒影到反射面的距离相等。因此,为达到虚实一致性,将3D模型在关于平面对称的位置生成等大的倒影。
3.2 提取水面无反射区域
光线在水面上发生反射的同时也产生折射。部分光线在水面上发生反射并进入人的眼睛,但部分光线被折射到水中,人眼无法看到。因此,倒影的亮度比岸上的景色更暗。事实上,由于水中存在悬浮物质,水的颜色会发生变化。因此需要提取水面上无反射区域的颜色。
利用深度学习语义分割出来的水域范围,将其中水面无反射区域和倒影区分开。在室外水面无反射区域其实是反射了天空,由于天空总是具有高亮度、低饱和度的特征,因此这部分水的亮度也很高,饱和度很低[21]。而倒影区域一般亮度较低且因反射了周围建筑或树木同时也具有较高的饱和度。因此,首先需要将原图片由RGB转化为HSV颜色空间。HSV空间中,H代表色调,范围为0~360,用以描述颜色;S代表饱和度,可以被视为光谱颜色和白光的混合比,并且值的范围为0~1;V代表亮度,范围为0~1。RGB与HSV的转换关系如下:
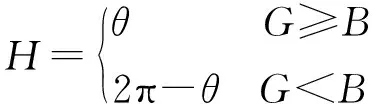
(1)
(2)
(3)
(4)
式中:R、G、B分别代表RGB颜色空间中的像素值,并且范围被归一化为R,G,B∈[0,1]。通过转换,H∈[0,2π],S∈[0,1],V∈[0,1]。
然后统计水域范围内高亮度低饱和度区域像素的平均R、G、B值。
3.3 渲染倒影颜色
采用Darker混色模型[22],将水面无反射区域的平均RGB值作为源色,将3D模型本身的颜色作为目标色,选取两色中较暗的颜色作为结果色。也就是说,选出RGB对应通道中的较低值。混色规则如下:
Cs=(Rs,Gs,Bs)
(5)
Cd=(Rd,Gd,Bd)
(6)
Cr=min(Cs,Cd)
(7)
Ar=1
(8)
式中:Rs、Gs、Bs分别是水面无反射区域的平均RGB值;Rd、Gd、Bd分别是3D模型的RGB值;Cr是结果色,作为3D模型倒影的颜色;Ar代表透明度。
4 实 验
4.1 实验环境
使用Ubuntu 14.04操作系统,CPU为四线程Intel Core i5- 4590,GPU为单个Nvidia K2200。ICNet网络训练使用TensorFlow框架,开发工具是Python 2.7+Anaconda。基于ORB-SLAM2改进的系统的开发工具是C++,使用Pangolin(一个对OpenGL进行封装的轻量级图形/视频显示库)实现可视化界面。
4.2 水面场景语义分割及语义地图结果分析
在实际应用中,实时性能是评估增强现实系统的关键指标。实验统计了一些主要模块处理一幅图片(尺寸为960×540)所需的时间,结果如表1所示。

表1 各部分模块时间统计表
系统运行时主要线程包含语义分割、视觉里程计、建立稀疏三维语义地图以及增强现实模块(三维图形渲染使用Intel Core i5-4590集成显卡),总体处理一幅视频帧的平均时间为58.4 ms。视频帧在可视化界面显示的帧率为每秒34帧。增强现实模块包含平面拟合以及3D模型的渲染等主要部分。实验表明系统运行耗时主要集中在3D模型渲染过程,其运行速率与GPU固件图形渲染能力有关,以NVIDIA k2200显卡为例帧率可达每秒27帧以上。
图3展示了本文数据集中的一段视频传入所改进系统后经过语义分割线程分割后得到的分割结果图。分割精度经测试集测试结果为87%,满足要求。将原视频帧与图3中分割结果图一同送入SLAM系统后所建语义地图如图4所示。语义地图中点分为水和背景,用了两种颜色(灰度表示)进行区别。

图3 融合语义信息的SLAM建图示例

图4 SLAM语义地图
4.3 语义驱动下增强现实的结果分析
图5展示了实验过程中的增强现实效果与原ORB-SLAM2系统的增强显示效果的对比。图5中:(a)是原始视频帧。(b)是原ORB-SLAM2系统,未融入语义信息,仅使用RANSAC算法进行平面拟合后插入3D模型的效果。可以看出,拟合的平面是随机的,虚拟物体大多悬浮在半空中而且水面中无相应的倒影,显得不真实。(c)使用了改进的系统,融合了语义信息,3D模型安放在水面,但无倒影,仍有悬浮感。(d)是使用改进的系统并完善了对3D模型在水面下倒影的渲染,消除了虚拟物体在真实场景的悬浮感。倒影的颜色随光线和水体的颜色会发生相应的变化,也使增强现实效果更加逼真。

图5 实验过程及效果对比图
5 结 语
本文将深度学习语义分割的信息与SLAM追踪及建图过程相融合,使机器能够理解高级的语义信息,也使所建SLAM地图更有意义。结合现实场景中的物理规则,可以在水面上实现更好的增强现实效果,这些在原来仅有特征点组成的无意义的地图中是不可能实现的。本文所提出的系统流程合理且各部分算法简单、计算复杂度低,可以满足增强现实的实时性要求。未来可以将其移植到移动设备上进一步丰富户外场景中的增强现实体验。本文的不足之处在于未考虑水面悬浮物与3D模型倒影之间的遮挡关系,为进一步增强真实感,可以对此展开下一步的研究工作。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中外文摘(2022年2期)2022-03-01
中外文摘(2020年9期)2020-06-01
课外生活(小学1-3年级)(2020年2期)2020-03-09
新少年(2017年3期)2017-03-23
科普童话·百科探秘(2015年6期)2015-10-13
长江学术(2015年1期)2015-02-27
滇池(2014年5期)2014-05-29
流行色(2009年12期)2009-01-08
