
面向海量星表数据的高效的时序数据生成方法研究
2021-04-15 03:47熊聪聪付立艳
计算机应用与软件 2021年4期
熊聪聪 付立艳 赵 青
(天津科技大学人工智能学院 天津 300457)
0 引 言
时序数据生成是天文学家进行天体时域分析的基础,所谓时序数据生成是将来自不同拍摄时间、不同星表中数据,通过交叉证认方法对确定为同一星体的数据,按照时间顺序排序生成每个天体时间序列数据[1]的过程。
时序数据的生成的难点主要包括两点:(1) 随着时域观测设备的发展,数据的采集能力越来越强,具有在时间轴上频繁采样的特点,这导致数据量巨大[2]。如南极AST3望远镜,其每天数据采集量高达360 GB。再如兴建中的宽视场瞬变源巡天设备地面广角相机阵[3](GWAC),每15 s产生1.1 GB数据,每个观测夜入库仅星表数据高达2 TB。面对庞大的数据量,高效的时序数据生成方法成为难点,数据的存储、查询、证认计算等方面均需要优化设计[4]。(2) 时序数据生成需要对时间轴上每两次观测的数据进行证认计算,计算量高于普通天体交叉证认计算。为了实现大规模星表的交叉证认,高丹[5]提出了基于HTM索引和kd-tree的交叉证认方法,文献[6-7]针对漏源问题,采用基于HTM和HEALPix两种分区的混合证认计算算法,Zhao等[8-9]提出了基于MPI的多核并行交叉证认算法,通过基于位运算的快速相邻块编码推导算法高效地取得误差半径范围内全部需证认数据,解决了边缘漏源问题,但仍然无法满足批量多星表间的证认需求。徐洋等[10-11]提出基于等经纬分区二维空间网格的方法,万萌等[12]采用列存储内存数据库MonetDB提高数据访问性能,在关系型数据库方法中取得了较好的效率。徐洋等在面向GWAC的小天区数据上实现了实时交叉证认,实时性良好,但仍难以解决千万条以上星表数据的证认问题。赵青等[13]实现了海量数据的并行天文交叉证认,但时序数据生成的过程中的交叉证认计算不同于传统多波段交叉证认计算,需要对时间轴上每两次观测的数据进行证认计算,计算量增加[5],效率要求更高。因此,在数据预处理、分布式算法设计等方面需要更精准的优化。
综合以上问题,本文提出一种面向海量星表数据的高效的时序数据生成方法ETSDGM(Efficient Time Series Data Generation Method),其整体的设计框架图如图1所示。
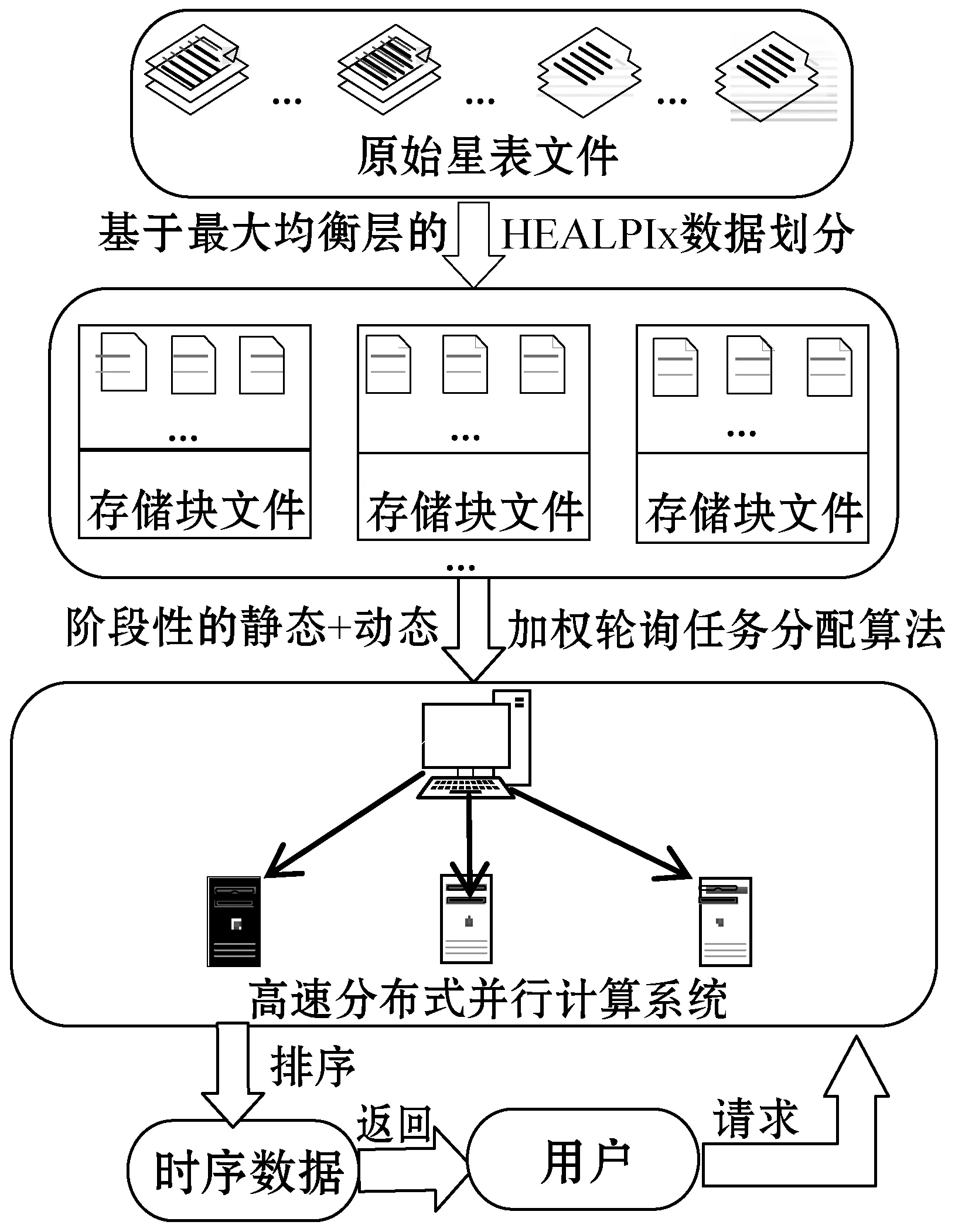
图1 ETSDGM整体的框架图
本文方法的设计重点分为两个阶段:
第一阶段为预处理期间的访存优化设计,重点在于基于“最大均衡层”的HEALPix数据划分[14-15]以及分布式系统中的阶段性“静态+动态”加权轮询任务分配算法的设计。预处理阶段的设计保证索引的均衡性,实现数据的快速定位和集群中各节点负载均衡性以及节点的高度并发性,为后续实现快速证认计算提供一定的支持。
第二阶段为证认计算算法优化,包括HEALPix数据过滤策略以缩减证认数据的范围和基于传输与计算重叠的边缘数据处理方法,以减少数据通信耗时。图2为ETSDGM整体的设计内容及意义。

图2 ETSDGM整体的设计内容及意义
1 原始星表数据预处理阶段的访存优化研究
在海量的天文数据面前,当只有数据的一个子集对天文学家的特定研究工作真正有用时,处理整个数据既耗时又浪费空间。通过访存优化,快速提取时空子集,为实现指定区域高效时序生成条件。图3给出了此阶段的整体步骤。原始星表文件中每一行代表一个星体,提取证认计算需要的几列信息定义一个适合生成时序数据的元数据文件格式。
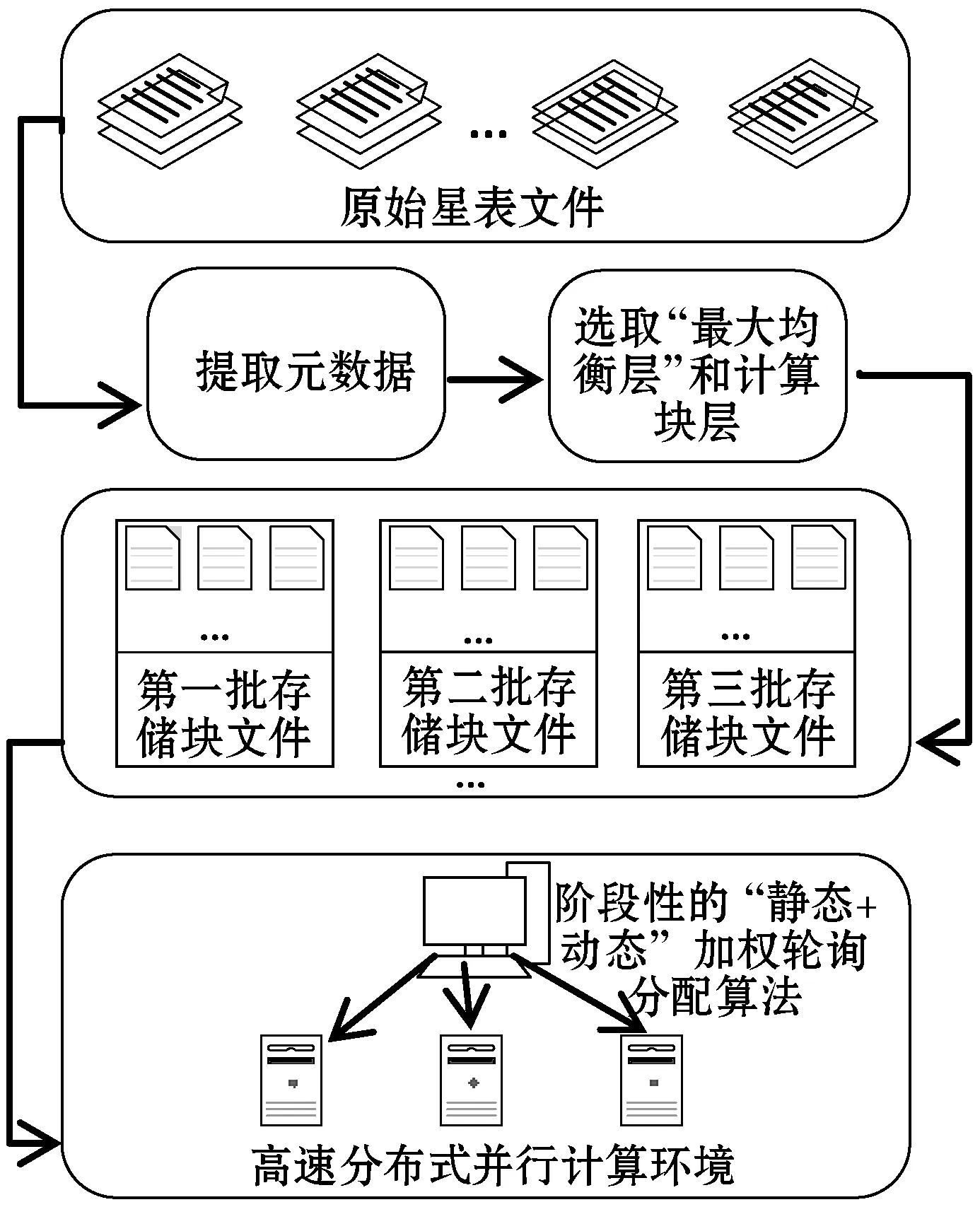
图3 原始星表文件的预处理过程
1.1 基于“最大均衡层”的HEALPix数据划分策略
基于“最大均衡层”的HEALPix数据划分方法,保证索引的均衡性,从而实现时空数据的快速提取。数据划分将原本复杂度为N×N的证认计算,通过分块将其局限在同一位置分块内,降低了算法复杂度;同时实现分布式并行计算,充分利用集群高性价比的存储和计算能力,提高证认计算的效率,当用户请求特定的时空范围内的时序重构数据时,合理的分块布局可以使集群中的各个计算节点负载均衡地提供所需的数据查询、证认计算服务。
选择HEALPix[16]伪球面索引方式,HEALPix在不同层级(Nside)下的网格划分图如图4所示。其具有层次化结构、等面积划分、等纬度分布的特点。初始层级被划分为12个面积相等的基准球面四边形,后续层级在此层级上进行递归四等分。
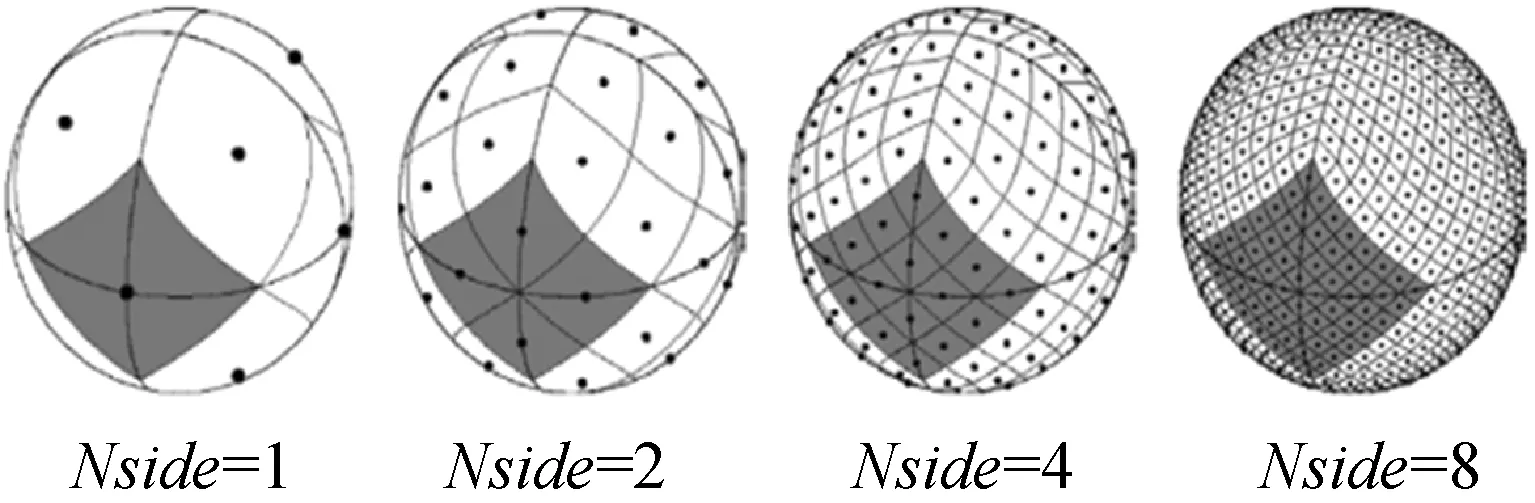
图4 HEALPix天球分区示意图
HEALPix索引方式的划分具有等面积性,考虑到星体数据分布不均匀,即在同一层级中有些编码块中星体数据量很大,有些则很小,容易导致索引结构失衡,进而使查询效率低下[17]。为了解决这一问题,本文采用“最大均衡层”下的HEALPix数据划分策略,保证每个存储块文件中数据量尽可能均衡。具体的计算方法如下:
(1) 计算不同层级k下的包含数据的总块数n以及相同HEALPix编码的星体个数Xi(即每块星体数,i=1,2,…,n)。
(3) 计算每层中HEALPix编码个数的标准差SK:
(4) 根据平均值和标准差计算变异系数CVK,CVK最小的为最大均衡层:
1.2 阶段性“静态+动态”加权轮询任务分配算法
原始星表文件经过预处理之后,需要利用分布式计算来提高时序数据的生成性能。天文星表数据量往往达到了TB甚至PB级,交叉证认计算属于典型的数据密集型计算任务。这里数据量分配的多少直接决定任务量。
为了保证分布式系统中各节点任务量均衡性。采用加权轮询任务分配算法。该算法根据服务器的不同处理能力为之分配不同权值,使其能够接受相应权值数的服务请求,但由于该算法是一种静态平衡算法,需要人为设置权值,难以反应服务器的实时性能,这导致负载不均衡。但如果采用纯动态轮询分配方法,每次分配后都计算当前负载,时间消耗较大,效率不高,考虑到集群节点的异构情况以及应用的实际情况,提出一种阶段性“静态+动态”加权轮询算法。即在阶段内采用“静态”轮询的思想,阶段与阶段之前引入“动态”性,修改各节点权值,增强算法对集群当前状态的适应性。
1.2.1算法思想
(1) 根据实际的情况找初始化到各节点的初始权值SWi。
(2) 根据初始权重SWi对第一批存储块文件进行静态轮询分配。
(3) 当第一批存储块文件执行完成时,计算当前节点的实时剩余性能率Wi。
(4) 计算每个阶段完成后的实时权值WWi。
(5) 根据实时权值,对下一批存储块的数据进行静态分配,重复以上步骤,直到数据分配完成。
1.2.2算法具体过程
1) 初始权重的计算。
Ci、Di、Mi、Bi(i=1,2,…,n表示节点个数)分别为各节点初始状态下CPU的剩余性能、磁盘IO的剩余性能、内存的剩余性能、网络带宽的剩余性能。集群中的所有节点的初始状态剩余性能总和为:
SWi表示各节点的初始化的权重:
式中:KC、KD、KM、KB分别表示的是CPU、磁盘IO、内存、网络带宽的权值,且满足KC+KD+KM+KB=1。
2) 静态加权轮询分配过程。
根据初始权重开始对第一批存储块进行静态分配:
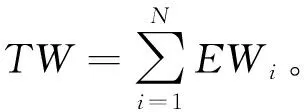
(2) 节点当前权重会一直变化,CWi=CWi+EWi,CWi等于EWi初始状态下的选出所有节点中CWi最大的一个节点作为选中节点。
由表8可知,定芽数3、4、2之间无显著性差异,但它们与定芽数5和定芽数1之间存在显著性差异,定芽数5和定芽数1之间也存在显著性差异。其中定芽数3均值最高。
(3) 选中节点的CWi=CWi-TW。
例如:假设有三个节点{A,B,C},初始权重{EW1=3,EW2=4,EW3=2},TW=3+4+2=9,现在请求7次的分配情况如表1所示。
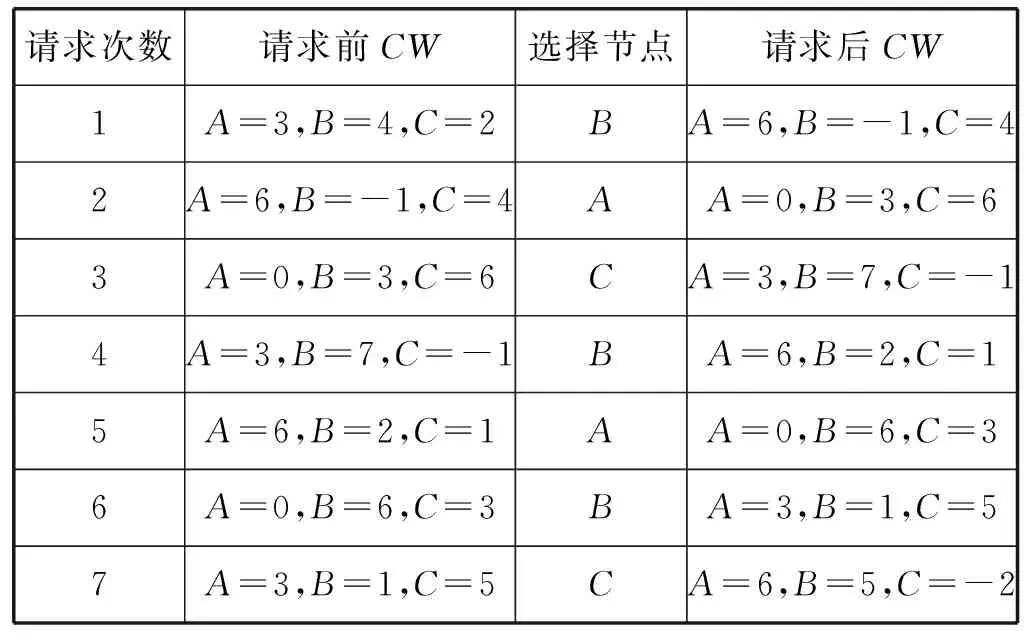
表1 静态分配实例表
具体解释:
第一次请求:A=3+3(EW1)=6,B=4+4(EW2)=8,C=2+2(EW3)=4,当前权重最大的B节点,所以B=8-9(TW)=-1。第二次请求:A=6+3(EW1)=9,B=-1+4(EW2)=3,C=4+2(EW3)=6,A节点为当前权重最大的点,所以A=9-9=0;以此类推。
3) 当前节点实时权重计算。
分配到节点的存储块进行计算任务,当计算任务快完成时计算当前节点的实时剩余性能率,根据计算出的实时权值WWi,对下一批存储块文件进行第二步处理,以此类推直达数据全部分配完成。
各节点的剩余性能率为:
各节点使用过程中的实时权重为:
WWi=Wi×SWi
2 证认计算算法优化
2.1 HEALPix数据过滤策略提取时空子集
为了生成时序数据,需要交叉证认来确定两条星体是否为同一星体的数据,其原理可以概括为:星表中有两个天体A和B。A的坐标为(ɡ1,β1),B的坐标为(ɡ2,β2)。它们之间的角距离d为:
d=arcos(sinβ1sinβ2+cosβ1cosβ2cos(g1-g2))
(1)
(2)
式中:r1和r2是两个星表的误差半径。当A与B之间的角距离d满足式(2)时,即证认成功。本实验是同源星表不同拍摄时间数据间的证认,沿时间轴进行两两星表间的证认计算,计算量更大。为了解决这个问题,在布局算法完成时设计了存储在内存中位置索引表,如表2所示,使用基于存储块文件的HEALPix数据过滤策略,快速定位、提取所需时空子集,减少两两距离计算的数据范围,提高整个交叉证认过程的效率。
表2 索引表的结构
基于存储块文件的数据过滤具体步骤如下:
(1) 用户给出检索圆点与检索半径。
(2) 确定圆点在最大均衡层层级下的HEALPix编码块。
(3) 根据编码块的长度大小找到略大于检索半径的向外扩展的区块对应的HEALPix编码。
(4) 根据HEALPix编码和内置的索引表定位到数据。
(5) 提取数据,进行锥形验证。即计算每条数据与圆点的角距离,找到小于等于检索半径的数据即为提取的时空子集。数据量的减少和数据重新布局有利于计算效率的提升。
图5为数据过滤的原理,假设索引的区域的半径SR=4,这一层的每块边长大概为2,索引区域的经纬度(Ra,Dec)为锥形圆点(即图中块1所在中心大黑点),找到圆点所在的HEALPix块号(图中整个方格区块),验证数据。

图5 数据过滤原理
2.2 基于传输与计算重叠的边缘处理方法
由于望远镜观测误差的存在,不同时间拍摄的同一个星体的数据可能会落入相邻的两个不同块中,所以在进行证认计算时,为了提高证认计算的准确度,必须考虑边缘漏源问题。边缘漏源问题中面临的就是数据传输问题,常用的解决方法是数据冗余,以空间存储量的增加换取通信时间的减少。考虑到数据的海量性,本文提出一种基于传输与计算重叠的边缘数据处理方法,此方法可以减少数据之间的跨节点传输,还可以使数据传输时间尽量与计算时间重叠,减少证认计算过程中等待传输数据的系统空闲时间,提高证认计算的速率与准确度。
实验中设计两种块:一种是存储块,即最大均衡层对应的存储块;另一种即计算块,计算块就是交叉证认计算的块单位,即在同一个计算块内的星体数据都需要进行两两交叉证认计算。数据存储是以存储块为单位进行存储,证认计算是以计算块为基础进行计算,根据HEALPix四叉树结构,当计算块的层级足够大时,一个存储块中会包含很多的计算块,使得许多计算块与其边缘块在同一个节点上,无须跨节点传输,减少节点间的数据传输。
存储块与计算块的结合使用,减少了跨节点传输的数据量,只有部分边缘数据需要跨节点传输,为了减少数据传输所需时间占比,提高总体证认速度,提出了传输时间与计算时间重叠的边缘处理方法。也就是说当计算块内的数据证认计算完成时节点间的数据传输也已经完成了,继续进行边缘块的证认计算。通过对不同层级下边缘数据传输时间以及不同划分力度下的计算块证认计算的对比,找到证认计算时间略大于边缘块数据传输时间的层级,即为HEALPix计算块层,进行证认计算。
图6为存储块与计算块之间的关系,整个图6是两个不同拍摄时间的同一个存储块,整个存储块被划分为许多小的计算块,白色计算块的所有边缘块都包含在此存储块中,即在同一个节点上,只有灰色计算块的边缘块上的数据需要跨节点传输,同样显示了由于观测误差的存在,同一星体A落于不同计算块中的情况。
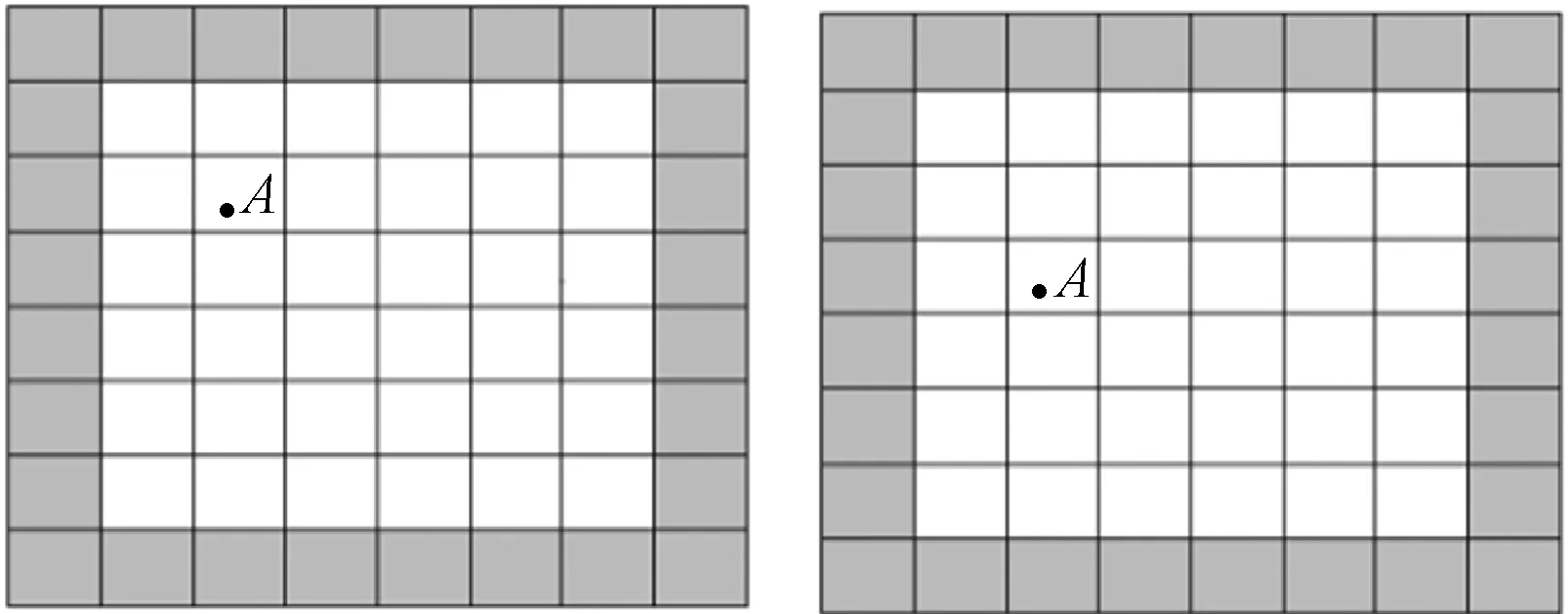
图6 计算块与存储块的关系图
3 实验分析
3.1 软硬件环境
本文实验的数据选取了中国虚拟天文台网站上公开的AST3上的一部分数据集,用来验证TSDGM方法的性能。数据大小为24.1 GB,包含4千万条星体信息。实验中,使用了一台Intel Core i5-4790 3.60 GHz的计算机作为Master CPU,它有8 GB内存;3台Intel Core i5-4590 3.30 GHz的计算机作为Worker CPU,内存为4 GB。操作系统是Ubuntu 14.04 LTS(64位),Linux内核为4.4.0-31-generic。基于MPI技术实现分布式集群系统。
3.2 预处理阶段访存优化提取时空子集的测试
最大均衡层保证存储块中数据量相对均匀分布,保证索引结构均衡性和查询效率,实现时空子集的快速提取。本文实验的原始数据是从AST3数据集中提取的,经过对原始文件的预处理得到了按最大均衡层HEALPix编码排序的存储块文件,利用阶段性的“静态+动态”轮询式任务分配算法存入各节点。根据1.1节给出的实验方法,通过对原始数据每层块内星体数据量平均值和标准差的计算,根据图7变异系数CV的显示,整体数据量分布最好的为8层,所以实验测定第8层作为“最大均衡层”是最优的选择。

图7 不同层级下对应的变异系数
图8中三条曲线分别为不同层级下当搜索半径等于0.2 rad、0.1 rad、0.05 rad下经过10次实验提取时空子集的平均时间,提取时空子集的时间等于相邻HEALPix编码计算时间、数据定位提取时间与锥形检索验证时间之和。当锥形检索半径弧度等于0.2时,第8层提取时空子集时间最少,原因是第8层的编码块长度略大于检索半径0.2 rad,只需要提取锥形圆点相邻一圈的HEALPix编码块进行锥形检索验证即可。对于第8层以前的层级,编码块的长度是8层编码块的长度的两倍,即与第8层一样只需要提取周围一圈编码块,即相邻的HEALPix编码的计算时间相近,但是,根据HEALPix四叉树结构,上一层级的编码块面积是下一层级的4倍,同样提取锥形圆点一圈周围编码块,提取区域面积增加了4倍多,数据量相对也增加4倍多,导致数据定位提取时间和锥形验证时间增加。8层以后的层级,编码块长度小于检索半径的长度,导致提取相邻编码块的计算时间增加,层级划分越细,每次数据量相差不大,所以提取的数据和检索验证时间不会发生太大的变化。当检索半径弧度等于0.1 rad时,9层边长略大于检索半径,为提取时空子集时间最少的层级。当检索半径弧度等于0.05 rad时,10层边长略大于检索半径,为提取时空子集时间最少的层级。还可以看出,在最大均衡层(第8层)时,搜索区域越大,相对的搜索时间却相对减少,即在最大均衡层下每个存储块文件的数据均衡分布,根据索引表进行数据定位时较好地实现了快速定位并进行数据提取的目的。
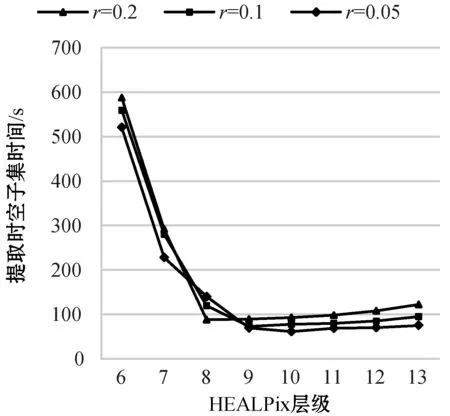
图8 不同层级下提取时空子集的时间
3.3 证认计算优化的测试
存储块与计算块的结合使用直接提取边缘数据,边缘数据总的传输时间等于边缘数据的提取时间与数据的传输时间的总和,图9为不同HEALPix层级下计算块的边缘数据的传输完成时间,图10为不同层级下的计算块证认时间与边缘数据传输时间对比,实验结果显示第11层时计算块的证认计算时间略大于数据传输时间。即选取11层为计算块层,存储块与计算块结合使用直接提取边缘数据,不会出现多余的节点之间的通信时间,节点不会出现空闲的时间等待数据传输,减少了时间消耗,提高了证认速度。
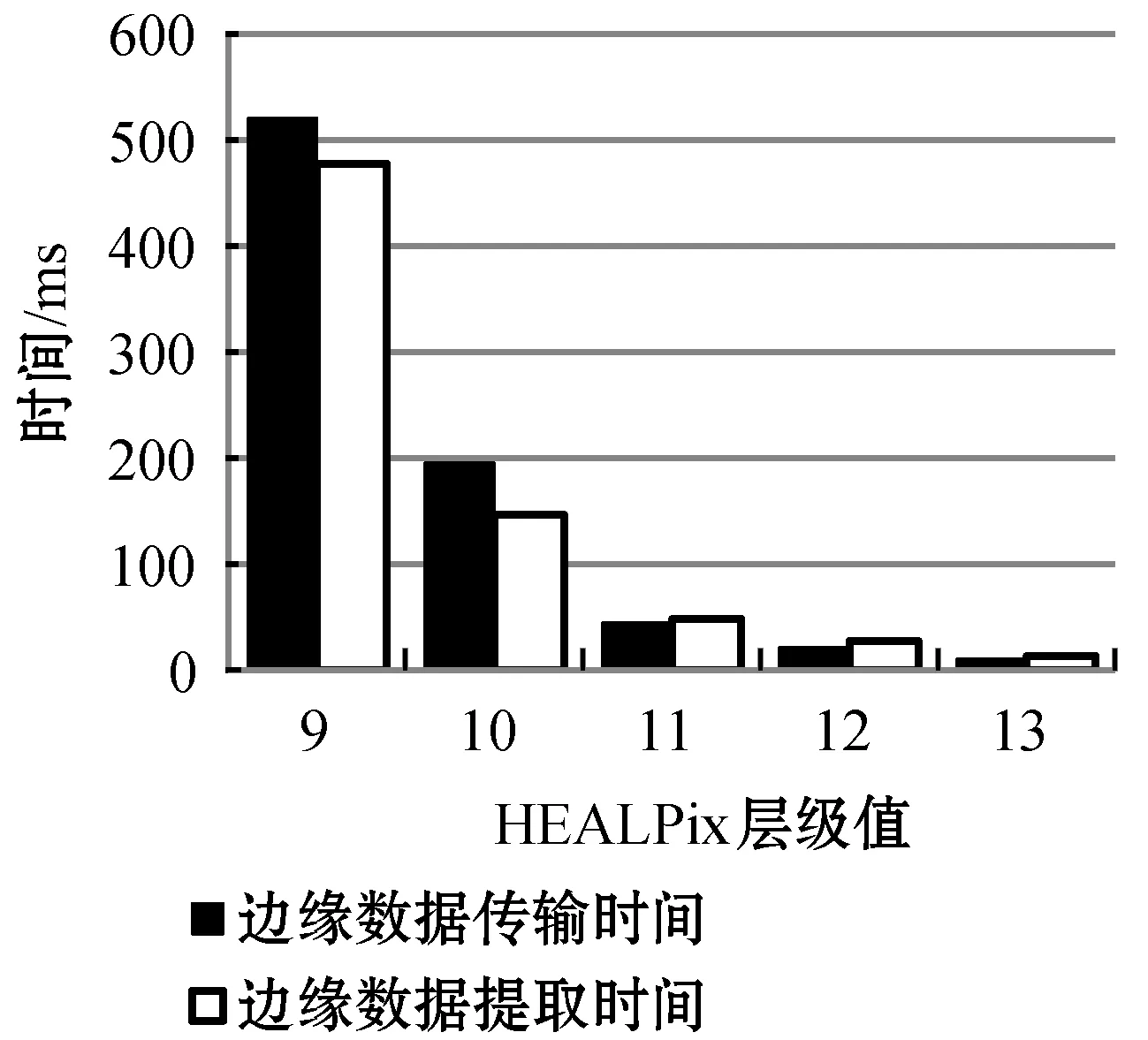
图9 不同层级下一个计算块边缘数据传输完成时间
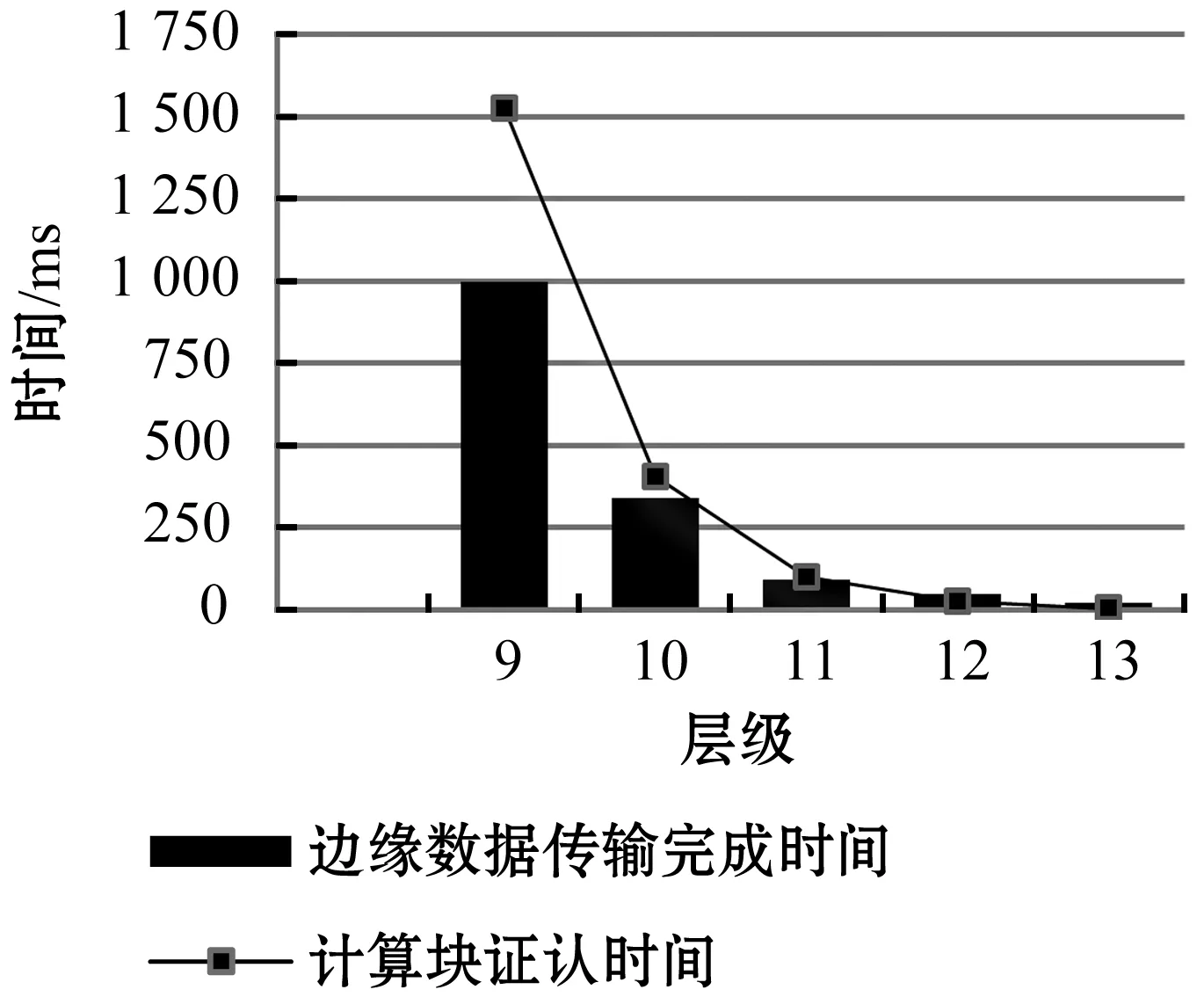
图10 不同层级下计算块证认时间与边缘数据传输时间
3.4 综合测试
时序数据生成传统方法是将FITS文件导入数据库,并在此过程中对不同时间的数据通过交叉证认的结果对天体记录进行matchID标记,再从数据库中找到具有相同匹配ID的记录,并将它们导入到文件中。最后可以根据这些文件中生成时序数据。为了显示ETSDGM方法的性能,选取了AST3拍摄的HD88500、HD117688、HD136485文件中数据量分别为2.30 GB、6.38 GB、8.30 GB的数据,采用一个节点的情况下,与传统时序数据生成时间进行了对比测试。结果如表3所示。
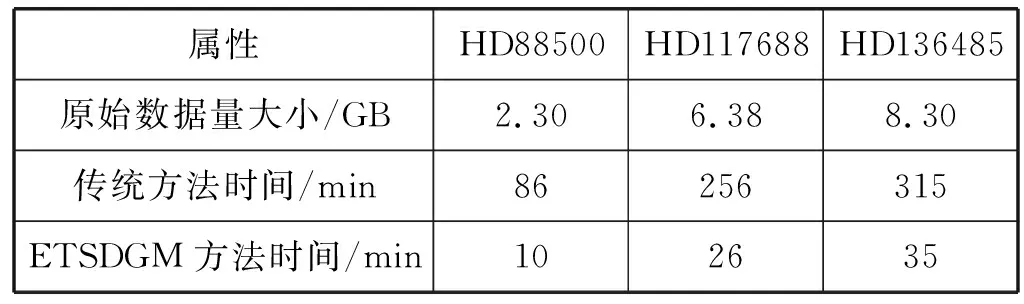
表3 ETSDGM方法和一般方法的时间比较
表3中的时间是形成时序数据的总时间,可以看出即使在一个节点的情况下,TSDGM方法形成时序数据也比传统方法更加有效,数据量越大TSDGM方法效果越明显。在一个节点的情况下,不用考虑任务分配算法,在预处理阶段,最大均衡层的设计让存储块文件中的数据量均衡分布与HEALPix区块过滤策略,确保了索引结构的合理性,快速定位提取时空子集,计算阶段存储块与计算块文件的结合使用,减少了跨节点传输的数据量,减少了系统等待数据传输的空间时间,两个阶段的结合提高证认速度,减少了时序数据总的生成时间。
图11为对不同节点下生成时序数据的时间测试。图12为不同节点下不同数据量的加速比。
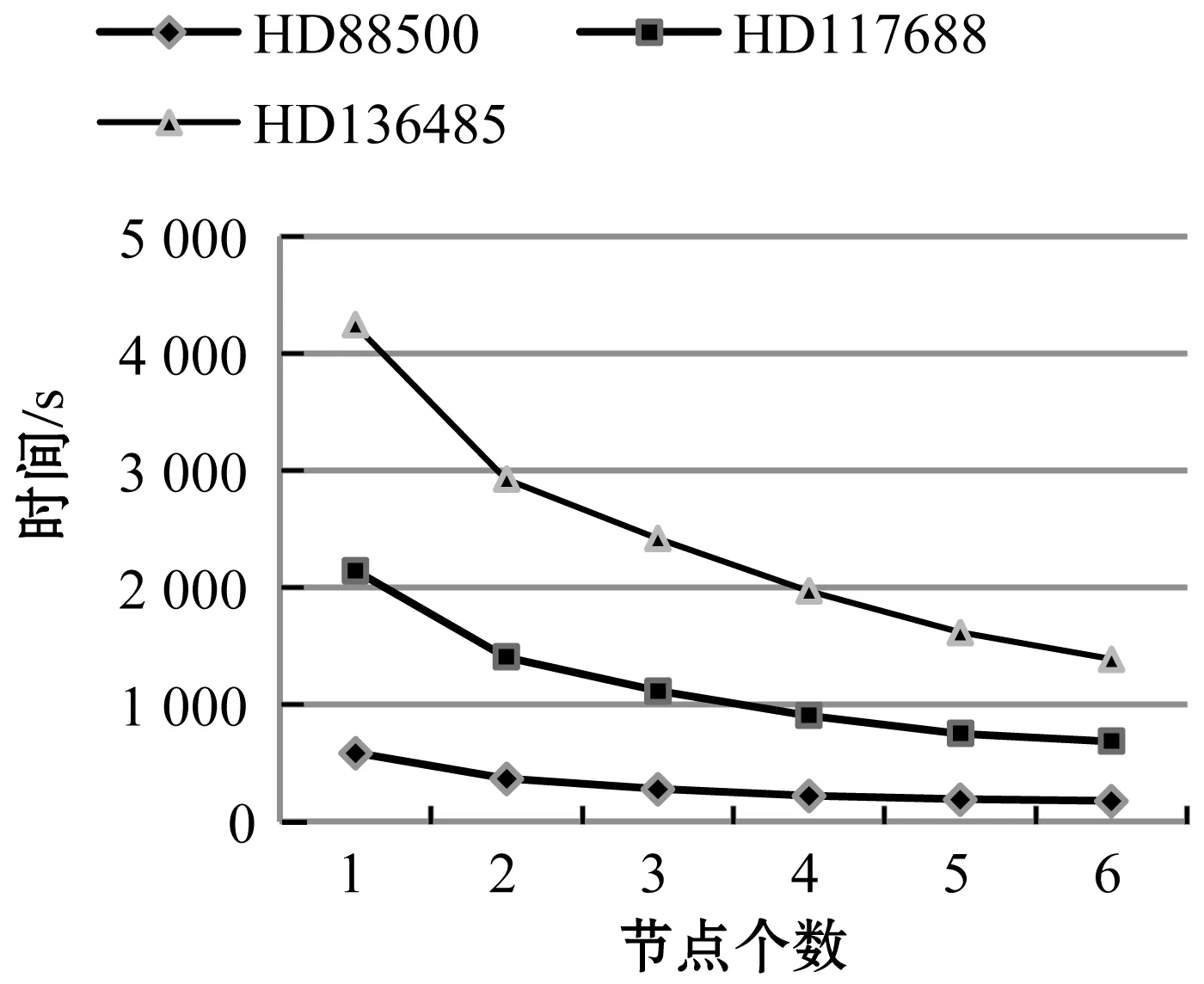
图11 不同节点下ETSDGM运行时间
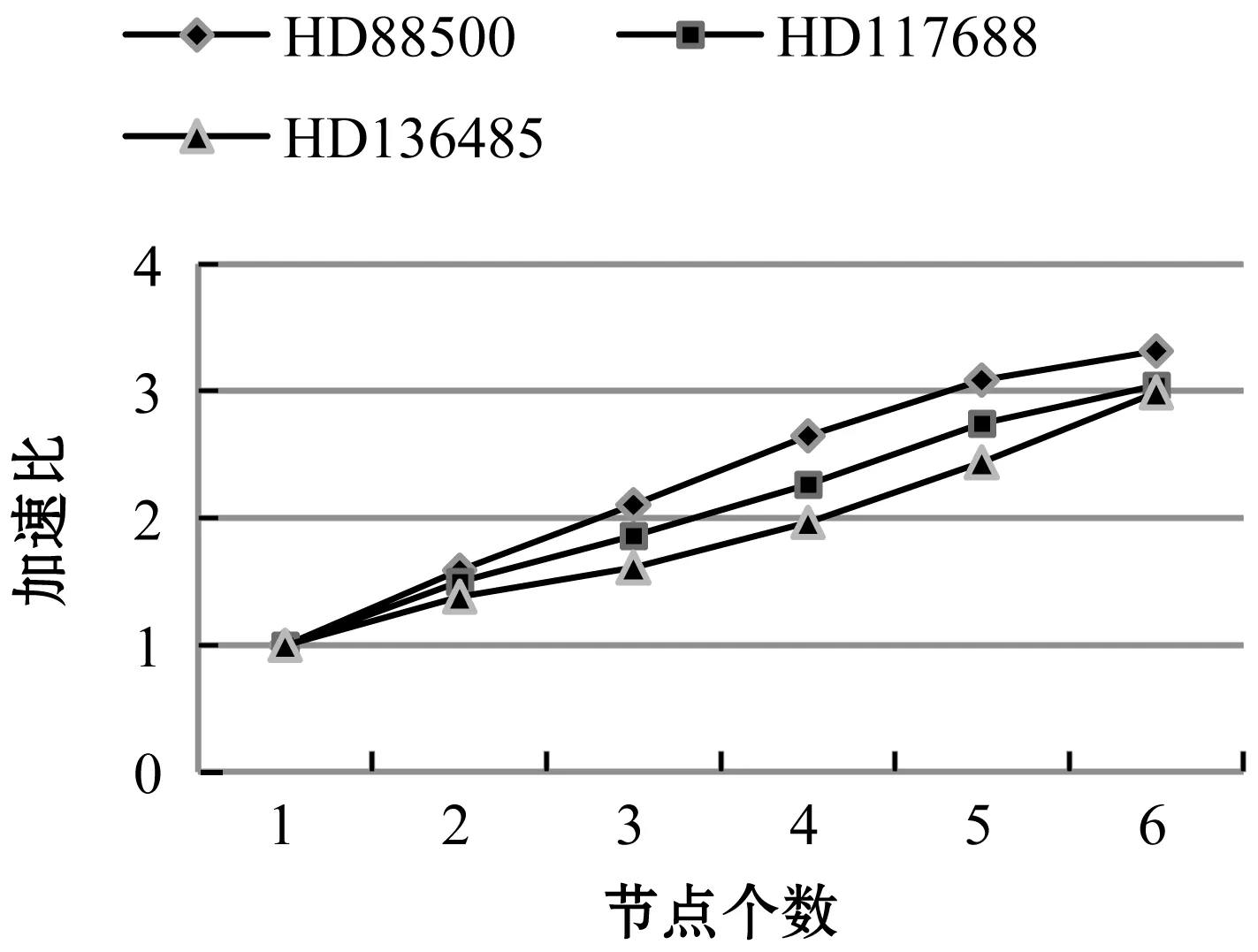
图12 不同节点下加速比
4 结 语
本文设计一种面向海量星表数据的高效时序数据生成方法ETSDGM,整体分为两个阶段,预处理阶段的访存优化设计与证认计算算法的优化设计。其中第一阶段对原始星表文件进行了访存优化,主要是进行数据划分和集群中任务均衡分配,实现数据的快速提取;第二阶段主要是针对证认计算过程优化传输与计算耗时,进一步提高证认计算速率。实验结果表明,与以往的工作相比,ETSDGM可以实现更好的性能改进,特别是在数据量较大的情况下。本文设计的高效时序数据生成方法对加快天文学家进行时域分析具有良好的应用价值。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
中国典型病例大全(2022年13期)2022-05-10
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
中华养生保健(2021年18期)2021-02-13
意林·作文素材(2021年23期)2021-01-22
电脑爱好者(2020年19期)2020-10-20
廉政瞭望(2019年5期)2019-06-10
软件导刊(2018年3期)2018-03-26
学习导刊(2017年8期)2017-11-02
