
基于AB-CNN-BiLSTM心衰死亡率预测模型
2021-04-15 03:48帅仁俊李文煜
计算机应用与软件 2021年4期
郭 汉 帅仁俊 马 力 李文煜
(南京工业大学计算机科学与技术学院 江苏 南京 211816)
0 引 言
对重症监护室(Intensive Care Unit,ICU)患者进行死亡率预测有助于医疗方案的制定、资源的配置以及诊断效果的鉴定[1]。ICU数据集样本数量及复杂程度近年来不断增长,并且相比普通的电子病历维度更高、更密集,给机器学习方法提供了有利的条件[2]。医院对ICU患者在人员、设备及技术上都予以最佳保障,医疗费用也比较昂贵[2-3]。心力衰竭是各种心血管疾病的终末阶段,侵袭身体重要肝脏器官,导致其丧失正常功能,是死亡的主要原因之一。心衰患者一般病情危急、病情多变,仅通过有丰富经验医生的主观经验及医学手段来做出重大决策进行诊疗已经显露出一些局限性。尽管付出了巨大的努力,但每天仍然有很多生命逝去,因此迫切需要将大量重症监护数据库利用起来,通过建立数据与疾病之间的联系,来辅助医生决策,对ICU心力衰竭患者死亡的死亡率做出更快、更准确的预测。对于死亡率较高的患者,制定针对性强的诊治手段以避免错失最佳治疗时机;对于死亡率较低的患者,避免过度用药,也更有益于患者和卫生保健资源的合理分配。
对机器学习的预测模型来说,特征的选择十分关键,需要找到最有利于模型预测的特征组合,同时剔除无价值或冗余特征。现有的研究主要是手工构建特征工程。随着计算机性能的快速提升以及数据的急剧增长,机器学习中的深度学习影响越发广泛,其可以有效地提取特征,已经涉及各种领域。CNN与LSTM在深度学习应用比较多,但也存在一些不足[4]:(1) 特征选择方面:卷积神经网络可以很好地提取时间或空间局部特征,但是缺乏学习序列相关性的能力,无法解决较长信息的长期依赖问题;LSTM在特征选择方面准确率高,但误报率也偏高;LSTM能够解决长期依赖问题,但由于LSTM只能读取一个方向的序列数据,没有充分考虑到属性后信息的影响。(2) 特征学习方面:如何有效实现特征与类别标签相关性的可解释性。(3) 自适应性方面:即在不降低准确率与不提高误报率的同时,让模型具有自适应更新的能力,来应对多变的心衰死亡情况。本文提出了一种融合卷积神经网络和双向长短期记忆的CNN-BiLSTM模型,并引入注意力机制,充分利用其各自的优势,弥补了以上三个方面的缺点。
本文贡献主要如下:
1) 当前大多数分类方法需要经过复杂的数据处理或特征工程。首次在ICU患者心衰死亡率预测研究中构建一种基于注意力机制的卷积神经网络(CNN)联合双向长短期记忆网络(BiLSTM)的神经网络预测模型,在改善优化性能的同时也极大地提高了模型的性能,有助于更准确、更快地预测心衰死亡率。
2) 引入注意力机制,对各个特征赋予权重来评价特征的重要程度并选取有效特征。
3) 在真实的ICU病患数据集上验证本文方法的有效性。
1 相关工作
对ICU死亡率预测的研究工作主要从临床和机器学习两个领域进行。临床上依靠构建有效的评分系统评估患者病情。临床常用的评分系统有急性生理和慢性健康状况评分系统(Acute physiology and chronic health evaluation,APACHE)、简明急性生理功能评分系统(Simplified acute physiology score,SAPS)、序贯器官衰竭评分系统(Sequential organ failure assessment,SOFA)、死亡概率模型(Mortality prediction model,MPM)[5]。APACHE与SAPS是临床上普遍采用的评估系统。APACHE经过改善有4个版本,即APACHEⅠ~APACHE Ⅳ[6-8]。SAPSⅠ系统是在APACHEⅠ系统的基础上改进的,其需要的一些生理指标更易获取,同时不需要考虑患者进行的诊断[9]。
临床上的评分系统依靠人工获取各项生理参数,一旦有新的数据出现则需耗费大量精力,无法实现实时更新及自动计算[10]。大量的生理参数是时间序列的格式,包含病情变化的信息,仅凭借人工是无法有效挖掘的。将机器学习应用于医学领域,能够充分利用海量数据,挖掘出有效信息,有助于医学分析,辅助医生诊疗。文献[11-15]均采用逻辑回归模型进行预测。Macas等[16]采用线性贝叶斯预测ICU患者病情。Johnson等[17]组合上百个弱学习器,得到贝叶斯集成模型,与SAPS 系统评分实验对比,发现该集成模型预测准确率更高。人工神经网络因其非线性学习、多维映射及噪声容限等优点被应用于多变的预测情景中。例如Xia等[18]构建人工神经网络的患者病情预测模型。Pollard等[19]在特征提取时参考太阳物理分析的方法,之后考虑到多个ICU类型,有针对性地训练多个前反馈神经网络,最后将BP网络用于分类,也取得了一定的效果。
基于现有研究,为了避免人工提取特征过程,在本文数据特征提取中,不仅需要关注不同参数之间的空间联系,也要关注到序列数据在时间维度上的变化,本文提出了一种基于注意力机制的BiLSTM-CNN心衰死亡率预测模型。
2 模型设计
为了优化心衰死亡率预测模型,提升死亡率预测的准确率和降低模型误报率,本文首先对MIMICIII数据集进行一系列预处理;然后利用CNN-BiLSTM 模型进行特征提取,为了更全面地提取局部特征,利用CNN提取局部平行特征;为了解决各属性特征点的前、后特征对该属性特征点的影响,采用由四个记忆模块构成的BiLSTM模型对长距离依赖特征进行特征提取,每个模块由两个细胞的拓扑结构构成;最后利用注意力机制计算出各属性特征的重要性,通过Sigmod分类器获得分类结果,提高了准确率,降低了误报率。本文模型如图1所示。
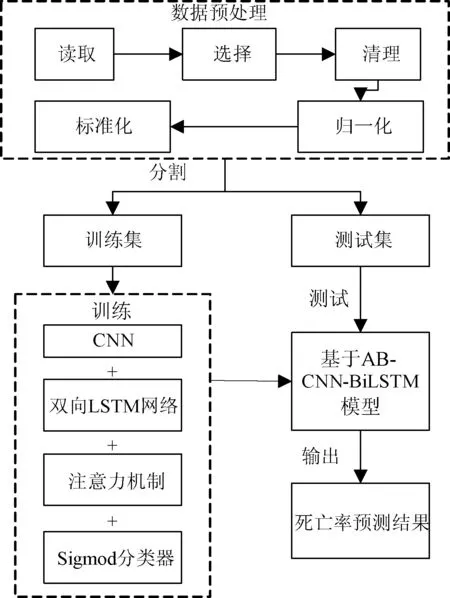
图1 基于AB-CNN-BiLSTM心衰死亡率预测模型
2.1 卷积神经网络
卷积神经网络借助卷积运算操作的优势,能够对原始数据进行更高层次和更抽象的表达,在提取输入数据的局部特征方面具有良好特性。CNN 结构包含输入层、卷积层、池化层、全连接层四部分。网络层数越多,提取的特征也越抽象。CNN将局部感受野、共享权重和空间或时间采样思想等都融合在一起,在处理局部有关联或者统计平稳的数据时,具有独特的优势。CNN基本结构如图2所示。
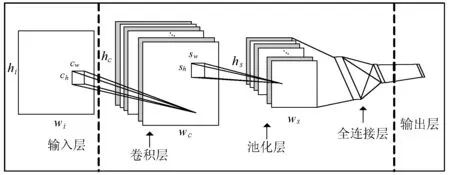
图2 CNN基本结构
卷积层利用多个不同卷积核对输入进行计算,产生新的特征。池化层对卷积输出进行采样,每次池化特征图深度不变,通过去掉每个特征图中不重要的特征实现降维,同时减少参数数量,防止过拟合。全连接层将卷积层、池化层、激励函数层等操作后的特征图映射为固定长度的特征向量。
本文利用CNN 抽取原始数据特征,挖掘多维数据之间的相互关联并从中剔除噪声和不稳定成分,将处理后的模式相对稳定的信息作为整体传入LSTM 网络进行长序列预测。
2.2 长短期记忆网络
循环神经网络(Recurrent Neural Networks,RNN)擅长处理持续的数据序列,不仅仅利用某一个时刻的数据获取结果,能有效处理临床数据序列。长短期记忆网络(LSTM)是RNN中的一种。虽然RNN擅长处理序列数据,但在训练过程中存在梯度消失或梯度爆炸及长期依赖的问题。LSTM由于其设计的特点,长短期记忆模块可以解决RNN引发的长期依赖问题,可以很好地实现对时序数据的建模。LSTM模型包含多个LSTM单元,如图3所示,每个LSTM单元包含遗忘门(ft)、输入门(it)、输出门(ot)3种门结构,以及一个细胞状态更新共同进行控制,以此来保持和更新状态信息并进行传递。xt指代第t个输入序列元素值;c指代记忆单元(cell)或称为细胞状态,控制信息的传递;输入门决定当前xt保留多少信息给Ct;遗忘门决定保存多少前一时刻的细胞状态Ct-1至当前的Ct;输出门决定Ct传递多少至当前状态的输出ht;ht-1指代在t-1时刻的隐层状态。

图3 LSTM单元结构
LSTM的记忆模块是LSTM模型的核心,在处理长距离依赖信息过程中起着至关重要的作用,决定每条记录信息中的特征是否进行遗忘。合适的记忆模块会改善其错误率偏高的现象。
2.3 注意力机制原理
专家学者根据对人类视觉的研究,提出了注意力机制,实现信息处理资源的高效分配。由于长时间序列的短子序列中特征重要程度存在差异,重要的显著特征往往会包含更多信息量,对实际需求量的趋势影响程度更大。假若赋予CNN更关注高重要度特征的能力,可以更好实现短期模式的有效提取和LSTM输入信息的优化。因此本文在死亡率预测过程中,为更好实现短期模式的有效提取和LSTM输入信息的优化,并对于重要属性给予更多关注,引入了注意力机制。注意力机制主要是模仿人注意力的功能。每个属性特征对死亡率预测的贡献是不同的,引入注意力机制记录对死亡率有重要影响的属性特征,并汇总这些属性特征,形成新的属性表示。
2.4 基于AB-CNN-BiLSTM模型结构
引入注意力机制的CNN-BiLSTM模型结构主要由数据预处理层、CNN层、Bi-LSTM层、注意力机制层组成,模型结构图如图4所示。

图4 基于AB-CNN-BiLSTM架构
(1) 数据预处理层。首先对MIMICIII原始数据集进行过滤、清洗,再对特征进行标准化和归一化处理,将标准化后的数值归一化到[0,1]区间。数据预处理后Xi为输入样本的第i个参数,T为样本的时间长度。

(1)
式中:⊗为卷积操作符;W为卷积核的权重向量;b为偏置项;f(·)为一个非线性的激励函数。本文所有隐藏层的激活函数选用ReLU,与其他函数相比,它能有效避免梯度缺失带来的收敛速度过慢和局部最值等问题。为了更加全面地提取特征,设置k个不同的卷积核,完成卷积后输出特征为:
Cm=[c1,c2,…,cn-k+1]
(2)
之后对特征序列Cm进行池化操作。常用的池化分为平均池化和最大池化两类。本文采用最大池化的方法充分提取不同卷积映射属性的显著特征,具体过程如下:
Pm=max(Cm)
(3)
(3) BiLSTM层。双向LSTM(BiLSTM)是由前向LSTM与后向LSTM组合而成,如图4所示。正向LSTM隐层负责正向特征提取;反向LSTM隐层负责反向特征提取。利用BiLSTM模型能够更好地考虑到序列数据中每个属性点的前后属性对其影响。第t个时间的特征通过前向传播LSTM单元后得到后向。
为了捕获长距离依赖特征,将Pm输入到BiLSTM 模型中,该模型由两个方向上的LSTM模块连接而成,具有多个共享权值。在每个时间步t上,每个门都由前一模块的输出和当前时刻的输入Pt表示,三个门共同工作来完成对属性信息的选择、遗忘和细胞状态的更新。BiLSTM模块的正向过程如下:

(4)

(5)
(4) 注意力机制层。为了获取更加准确的分类精度,将BiLSTM 的输出结果输入到注意力机制层。在注意力机制中,计算公式如下:
α=softmax[wT·tanh(H)]
r=HαT
(6)
A=tanh(r)
式中:w是一个训练的参数向量。
最后将注意力机制层的输出结果输入到Sigmod分类器中,得到取值在0到1范围内的结果概率p,设置阈值对结果进行分类。
3 实 验
3.1 实验环境
本文的实验环境为Anaconda 5.2, 脚本语言使用Python 3.6.5,硬件处理器为AMD Ryzen2700X,内存32 GB,运行Linux操作系统,同时配备GTX1080Ti显卡。
3.2 实验数据集
为了验证本文方法的有效性,本文实验数据集采用麻省理工学院计算生理学实验室开发的公开数据集MIMICIII[20]。其原始数据集包含了2001年至2012年60 000多次住院相关的数据,包括人口统计学、生命体征、实验室测试、药物等。
3.3 数据预处理
本次实验选用了MIMICIII 数据集中的六张表。这些数据集通过SUBJECT_ID 或者RAW_ID 互相连接映射。本文死亡率预测为出院死亡率,需要对患者出院后的存活时间进行计算,并给数据集增加标签完成监督学习。大致分为以下几个步骤:
1) 对原始数据集进行读取与处理,将心力衰竭患者筛选出来。使用ICD_9代码从PostgreSQL数据库查询患者表,并筛选所有诊断为心力衰竭的患者。
2) 对每个SUBJECT_ID生成一个目录,并将ICU停留信息写入。
3) 对一些数据缺失严重的事件进行删除。
4) 将每个SUBJECT_ID的信息处理为时间序列并存储。时间序列格式为n×14。其中n为该患者做的实验室测试的时间点的总数。Hours计算方法为:events[′HOURS′]=(做该实验室测试的时间点-入院时间)/60/60。14个变量分别为Diastolic blood pressure、Glascow coma scale eye opening、Glascow coma scale motor response、Glascow coma scale verbal response、Glucose、Heart Rate、Height、Mean blood pressure、Oxygen saturation、Respiratory rate、Systolic blood pressure、Temperature、Weight、pH。最后根据Hours大小升序。
5) 对特征进行标准化和归一化处理,将标准化后的数值归一化到[0,1]区间,并将其拆分为训练集和测试集。实验数据统计表见表1。
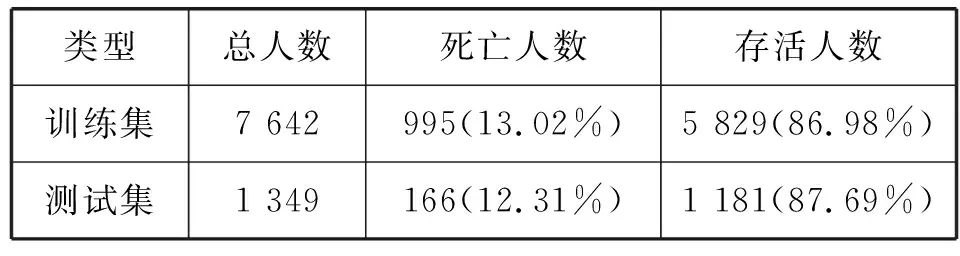
表1 实验数据统计
3.4 实验结果分析
据表2所示的混淆矩阵,可以使用正确率,精确率(查准率) 、召回率(查全率) 、F值等评价指标对本文方法进行评估。
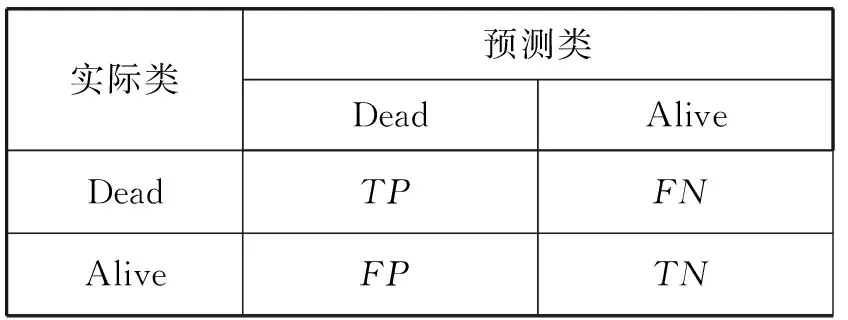
表2 混淆矩阵

确定评价指标后,通过多次试验确定实验参数。本文提出的预测网络参数设置见表3。本文的输入数据结构为76×14,padding方式选用SAME,经过CNN层后输出为76×14,再将其输入到BiLSTM网络中,整个模型通过最后的全连接层输出结构为1×1 024的数据,最后通过Sigmod函数进行分类。
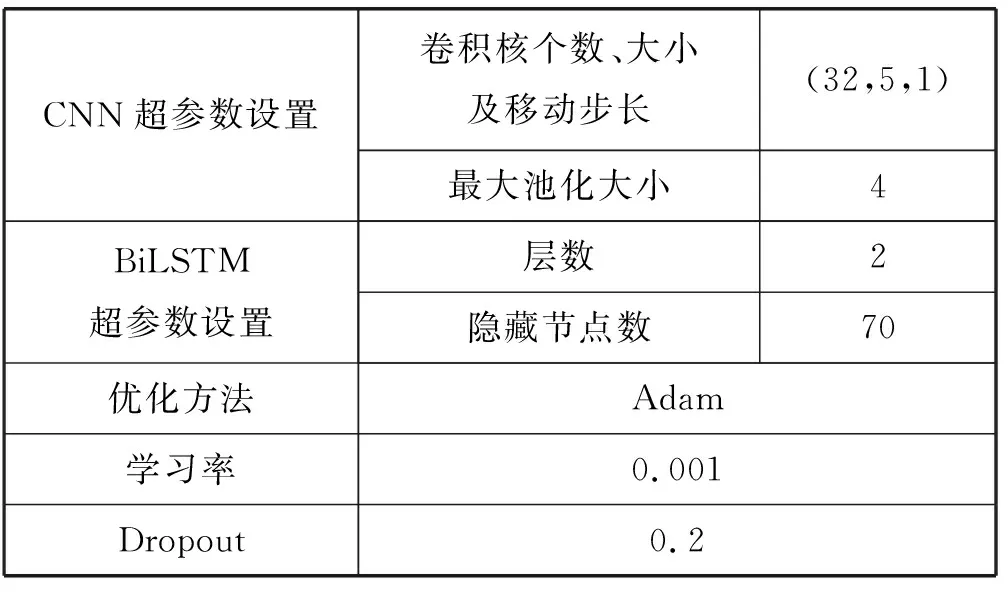
表3 网络参数设置
首先将该模型与其他常见的CNN和LSTM网络进行比较,对比模型有CNN、LSTM、BILSTM、基于注意力的CNN和CNN-BILSTM。实验采用5倍交叉验证,每组15个实验,并记录多个实验结果的平均值。实验结果如表4所示。结果表明,本文提出的基于AB-CNN-BiLSTM的ICU患者心力衰竭死亡率预测模型能更有效地预测ICU患者的心力衰竭死亡率,预测准确率达到89%。这是因为在数据特征提取中,不仅要考虑不同参数之间的空间关系,还要考虑数据在时间维度上的变化,同时引入注意力机制可以降低死亡率预测的假阳性率。

表4 与其他CNN及LSTM模型对比
此外,为了更好地说明本文提出的死亡率预测模型的优越性,在当前机器学习领域中选择了具有代表性的逻辑回归(LR)、贝叶斯(Bayes)、人工神经网络、支持向量机(SVM)和Adabost等模型进行预测ICU病人的情况。图5展示了比较结果。可见,本文提出的模型达到了最佳分类性能。
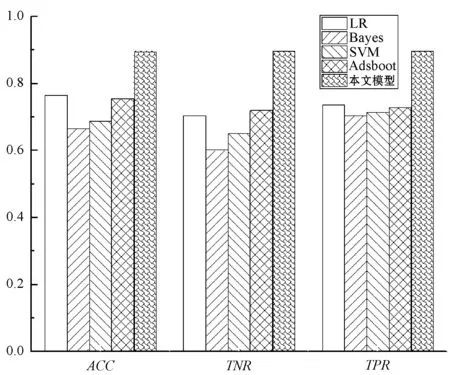
图5 不同方法性能对比
4 结 语
为了帮助医生做出决策,更快更准确地预测重症监护室心力衰竭患者的死亡率,本文提出了一种基于AB-CNN-BiLSTM心力衰竭死亡率预测模型。与现有方法相比,本文模型具有更好的性能。在给出大量训练数据集的情况下,该模型可以扩展到其他的数据集,研究更深入的神经网络结构。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
科学之谜(2020年6期)2020-08-11
智富时代(2017年7期)2017-09-05
智富时代(2017年7期)2017-09-05
健康管理(2017年4期)2017-05-20
第二课堂(课外活动版)(2016年2期)2016-10-21
