
基于U-Net融合的保留纹理的图像去噪方法
2021-04-12 09:50陈钧荣林涵阳陈羽中
小型微型计算机系统 2021年4期
陈钧荣,林涵阳,陈羽中
1(福州大学 数学与计算机科学学院,福州 350105) 2(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
1 引 言
图像的采集、存储以及传输过程中不可避免的给图像引入不同的噪声,噪声的存在使得完整的图像信息无法被获得,这将严重影响图像显著性检测[1,2]、图像分割[3]、图像分类[4-6]等高级视觉理解任务,特别是在医学领域,医学图像只要被噪声污染,就有可能影响医生对病人的病情的判断和后期治疗,因此,研究图像去噪的方法具有重要的现实意义.噪声的来源复杂,且噪声的类型多样,图像一旦染上噪声就很难恢复出其原有的内容和纹理,因此,图像去噪的目的是利用一张可观测的噪声图像,尽可能恢复出其原有的内容和纹理.对图像去噪的研究方法大致可被分为两类:1)传统方法;2)基于卷积神经网络的方法.传统的方法主要有空域像素特征去噪算法[7-9]、变换域去噪算法[10-12]和空域与其它域结合的去噪算法[13]等.例如三维块匹配滤波算法BM3D[14],WNNM[15],CSF[16]等,他们通常利用图像中像素间的特征,自相似性、稀疏性和平滑性等噪声图像的先验信息,以此来达到去噪的目的,虽然能产生一定的去噪效果,但由于先验信息手工获取复杂,得到的传统去噪方法通常时间复杂度较高,并且存在纹理丢失等问题,因此,难以应用在实际生活中.
近些年来,由于卷积神经网络(CNN)表现出强大的自动提取特征的能力,并且能用图形处理器加速处理,基于卷积神经网络的方法受到广泛的关注和用于图像去噪的任务的研究.在基于CNN的去噪方法早期,一个性能与BM3D相媲美的三层卷积神经网络[17]最先被提出,它不仅能达到与BM3D相同的去噪性能,而且处理速度大幅度提升,引起了业界的关注以及学术界的研究.Mao等人提出了一个端到端的网络[18],有效地利用编码-解码网络去除噪声,并且使用跳级连接,有效的防止梯度消失,该方法有效的降低图像的噪声的同时,仍存在重建出的图像过于平滑的问题.Zhang等人提出了一个结合残差学习和批归一化操作的网络DnCNN[19],该方法的去噪性能提升了,但是恢复出的图像纹理信息并没有得到较好的恢复尤其是在噪声幅度越高时越明显,因此,Liu等人提出了一个新的基于空洞卷积的多尺度图像去噪方法[20],该方法从输入中提取多种不同尺度的特征图,增加了网络的视野域,一定程度上对恢复图像的纹理信息有帮助.此后,Zhang等人提出[21],利用可以恢复的上下采样,将噪声图像下采样成多张,在小图上实现去噪,使得网络不增加消耗的同时扩展了视野域.Zhang等人也提出了一个基于非局部注意力机制的网络RNAN[22],该方法有效的利用图像的非局部的先验信息,恢复出的图像的纹理得到进一步优化.虽然所提到的这些基于CNN的去噪方法都表现出现有的先进的去噪性能,但是它们在去除噪声的同时,对图像纹理会引入一定程度的破坏,导致去噪后图像无法保留图像的纹理.
为了克服以上的缺点,本文在基于CNN的U型网络U-Net[23]的基础上,构建了一个能有效的重建出更多图像纹理的图像融合去噪网络,考虑到不同输入图像的含有不同的图像信息,本文提出使用两个参数独立的编码器来分别提取更多有用的信息,并提出了一个串联连接方式的融合模块,来更好的利用它们所提取的信息和去除冗余信息,最后使用解码器重建图像,网络中在对称的卷积层上均使用U-Net的对等连接,并采用均方误差来训练网络.所提出的网络均由卷积层,批归一化操作(BN)和非线性函数(LeakyReLU)构成,每一层输出的特征图都作为下一层的输入.编码器和解码器是对称的,分别由两层卷积层构成,融合器包括一层卷积层和多个残差块.
本文的图像融合去噪方法首先选取一个去噪方法的两个含有不同去噪参数(其中一个参数与噪声图像的噪声幅度相同,另一个略小于噪声图像的噪声幅度)的预训练模型,再将同一张噪声图像分别放入两个预训练模型中得到两张初始去噪结果;通过上述方法得到的两个初始去噪结果中一个结果中去噪效果比纹理保留效果好,另一个结果中纹理保留比去噪效果好;接着将两张初始去噪结果分别放在不同的编码器中抽取图像的特征,得到包含不同信息的特征图,然后利用残差块组合而成的融合器融合两种特征,最后由解码器重建出无噪声图像.图1给出了一个例子,(a)为σ=70的噪声图像,(b)为σ=70的去噪参数得到的DnCNN[19]的去噪结果,(c)为σ=67.5的去噪参数得到的DnCNN[19]的去噪结果,(d)为本文的融合去噪方法融合(b)(c)得到的去噪结果,图1中可以看出,图(b)在低频区域恢复出的图像更好,图(c)在高频区域能保留更多的纹理信息,从(d)图中明显的看出本文的方法能由(b)和(c)图融合出包含更多图像纹理的更好的去噪图像.
论文结构如下:第2节中,简要介绍U-Net网络、残差块与卷积神经网络的基础知识;第3节中,详细介绍本文的图像融合去噪方法;在第4节中,将本文的图像融合去噪方法与现有的几种先进的基于卷积神经网络的图像去噪方法进行主观视觉和客观指标的实验对比;第5节中,对本文的工作进行总结.

图1 融合特征的图像去噪结果Fig.1 Image denoising results of fusion features
2 U-Net与卷积神经网络
2.1 U-Net网络
U-Net[23]最初用于语义分割领域,整体的框架是编码-解码,它在编码和解码的对称的卷积层上加上对等连接使得网络能更好更快捷的学习,整个网络多达20层的卷积层和多个池化(pooling)操作以及4次对称的上下采样,由于U-Net取得不错的性能,很多分割问题都会先尝试使用U-Net解决.其中的编码-解码框架可以用于压缩图像和去噪,下采样可以增加视野域以及减少过拟合的风险,从输入图像中提取有用的特征,上采样可以将特征重建成图像,因此,本文将在U-Net的基础上进行去噪,并且由于在浅层的卷积层提取的特征包含更多高频信息,随着网络变深高频信息将减少,因此本文的方法仅使用U-Net的前两层和后两层以及对等连接,前两层下采样层用于抽取图像的特征,经过融合模块后,由后两层上采样层重建出图像.
2.2 残差块
残差网络(ResNet)[24]是在经典的VGG分类网络提出之后的又一个在分类任务上的突破,目前已经广泛用于各种计算机领域的应用中,它的主要贡献就是提出了残差块.残差块的目的是解决一种由深度增加引起的退化问题,即随着网络的层数增加,达不到理论上的高分类性能,反而性能更低.残差块的优点是在上下层之间引入跳级连接,使得不同层之间的特征能够相互传递,避免了增加网络的层数会引起梯度消失的问题,实际上残差块能得到不同层之间信息的融合,残差块的使用能增加网络的深度和视野域,利于得到更好的性能,因此,在本文所提出的方法中,提出使用由残差块组合而成的融合模块来达到融合不同分支的特征图的目的,并有效的避免了梯度消失的问题,实验证明了它的有效性.
2.3 卷积神经网络
近年来,卷积神经网络(CNN)能自动提取图像的特征,只要网络设计得当,它能自动学习到问题的解.CNN是一种可以使用反向传播算法来训练的前馈神经网络,广泛应用于深度学习的各种算法中,包括的结构有卷积层(Conv)、池化层(pooling)、线性整流层和损失函数层.卷积层可以获得图像中每个部分的权重,池化层可以用来作为下采样操作并防止过拟合,但是由于池化操作将损失部分信息,图像去噪任务需要尽可能多恢复图像信息,因此,在本文中不使用池化操作,线性整流层的函数可以增加网络的对非线性的拟合能力,损失函数用于指导网络优化权重的方向,并且CNN的参数共享机制,大大降低了网络的复杂度,在本文中,将利用CNN的优点,结合U-Net和残差块,提出一种基于卷积神经网络的图像融合去噪方法.
3 本文的图像融合去噪方法
本文的融合特征并保留纹理的图像去噪方法(Texture-Preserving Image Denoising Method Based on U-Net Fusion,IFDNet)的结构图如图2所示,它分为特征提取(编码器)、特征融合(融合模块)和图像重建(解码器)3个部分.IFDNet方法的步骤如下:
1)选取一个现有的去噪方法,使用一张噪声图像预训练出该方法的两个不同去噪参数的预训练模型即图2中的预训练模型A和预训练模型B;
2)将步骤1所得的初始去噪结果1和初始去噪结果2放入IFDNet中的两个相同的但参数独立的编码器中提取不同的图像特征;
3)将步骤2所得的特征放入融合模块进行特征融合,去除冗余的特征得到更有用的特征;
4)利用解码器从步骤3所得的特征图中重建出最终的融合去噪图像.
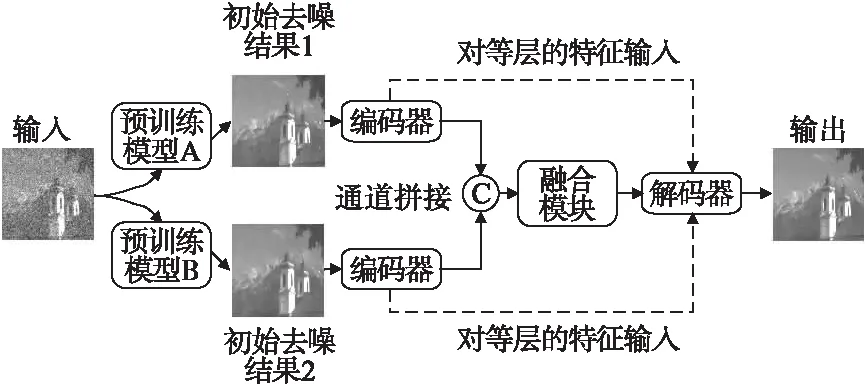
图2 基于U-Net融合的保留纹理的图像去噪方法的结构图Fig.2 Structure of texture-preserving image denoising method based on U-Net fusion
3.1 图像融合去噪网络
IFDNet的网络由特征提取、特征融合和图像重建3个模块组成,由于网络层数越深,所包含的特征中高频信息越少,特征越抽象并且容易梯度消失,IFDNet的特征抽取模块包含两层下采样层,且无池化操作.如图1所示,不同的去噪参数的去噪模型得到的去噪结果所包含的信息不同,较小的去噪参数的模型的初始去噪结果在高频区域保留较多的图像纹理,而较大的去噪参数的模型的初始去噪结果在低频区域的去噪性能更好,为了更好的从初始去噪结果1和初始去噪结果2中分别提取出有用的信息,本文使用两个参数独立的编码器来分别提取输入图像的特征图.为了融合不同分支的特征,本文提出了一种基于ResNet残差块[24]的融合模块,如图3所示,它包括对称的上采样卷积层和下采样卷积层、通道拼接操作以及多个串联的残差块,残差块包括两个卷积-批归一化层和特征相加操作,通道拼接操作将不同分支的特征拼接起来得到不同的有用信息,虽然有冗余但是它能提供更多的信息,拼接的特征经过一个卷积层,将得到的特征进行整合后,送入多个串联的ResNet残差块中,从冗余的特征中进一步提取更重要的特征,在最后的融合部分为了保持输出的分辨率不变,加上了一个上采样卷积层.最后,为了保持输出的图像的分辨率和输入是一样的,图像重建部分使用与特征提取器对应的两层上采样卷积卷积,它的输入是特征融合后的融合特征图.本文的图像融合去噪网络的各层参数如表1所示.
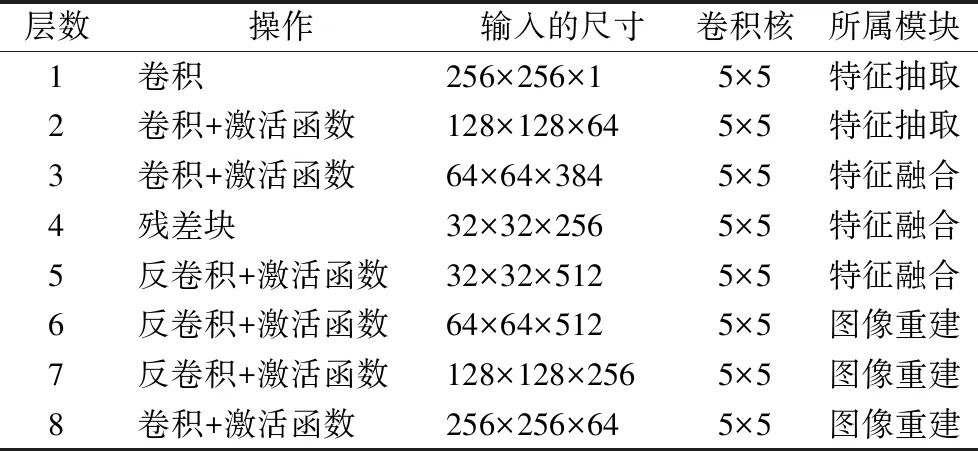
表1 本文的图像融合去噪网络各层参数Table 1 Parameter for the layers of the proposed IFDNet
表1中的激活函数,前4层为leakyrelu,后4层为relu,融合模块包括以下几个操作:下采样卷积+激活函数函数、通道拼接操作、多个串联的残差块和上采样卷积+激活函数,其中,残差块包括两个卷积+批归一化操作和特征相加操作.
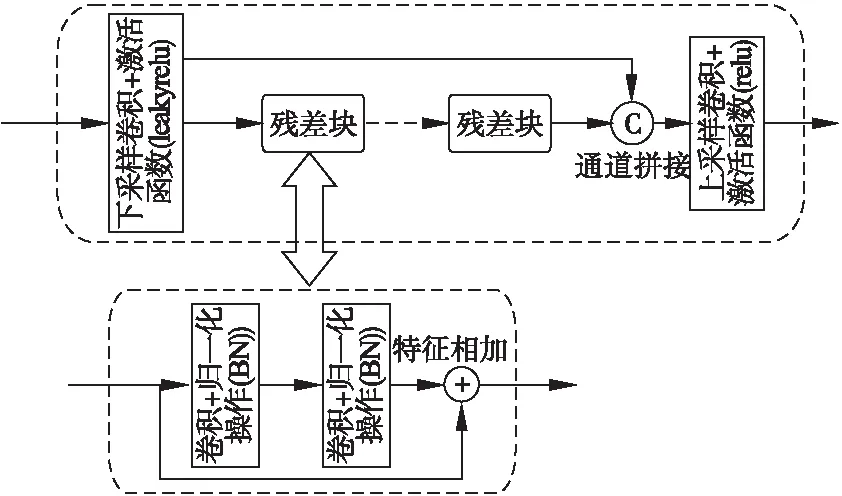
图3 融合模块结构图Fig.3 Structure of the proposed fusion module
3.2 图像融合去噪网络的损失函数
损失函数是本文的图像融合去噪方法中重要的一部分,为了优化本文所提出的方法,寻找一个合适的损失函数来训练IFDNet是必要的,在图像去噪任务中,常见的损失函数有L1损失和L2损失,并且训练的约束越多,训练得到的网络参数并不一定是最优的,因此,本文的网络使用的损失函数为输出与原图间像素层的L2[25]损失,见公式(1):
(1)

4 实验结果与分析
高斯噪声是目前图像去噪领域中研究比较广泛的噪声之一,本文所有的实验使用高斯噪声作为图像的噪声.为了验证本文所提出的方法的有效性,在人工合成的噪声图像做了几组实验.将实验结果与现有的主流图像去噪方法Zhang等人提出的DnCNN[19]以及Zhang等人提出的FFDNet[21]作比较,并进行视觉效果和定量指标的对比,为了公平起见,两种方法的代码均由作者发布的,不做参数的修改.
4.1 数据集
本文所提出的基于CNN的网络需要噪声图像和对应的无噪声图像的图像对作为训练集.由于这样的图像对数据集难以获取,因此,需要手工合成训练集,过程如下:首先,选取BSD500[26]中的400张训练图像和ImageNet[27]中400张验证图像,总共800张作为干净的无噪声图像,然后利用高斯函数产生均值为0,方差为σ的高斯噪声,最后将产生的高斯噪声加到干净图像图像中,即可完成训练集的制作.本文的对比实验包括7组不同方差(σ=10,20,30,40,50,60,70),验证和测试使用与训练数据同种加噪方式,其中验证集是BSD500中减去BSD400的400张训练集和BSD68[28]的68张测试集所剩下的32张,多个测试集的使用可以有效的防止在一个数据集上过拟合,因此,测试集使用BSD68和Set14[29]两个不同的数据集.
4.2 实验细节
使用4.1所提到的800张加上噪声的图像的训练集,训练时,首先选定两个噪声参数分别为σ和σ′=σ-k的DnCNN[19]去噪模型,得到同一张噪声图像(噪声方差为σ)的不同初始去噪结果;然后,分别在图像的同一位置将初始去噪结果和原图裁剪成相同的256×256大小的图像块,作为网络的输入来训练所提出的IFDNet网络,其中使用的数据增强方式为随机翻转和随机旋转,batchsize大小设置为10,使用ADAM[30]优化器来优化IFDNet,并将学习率设置为0.0002,其它设置为默认设置.训练的epoch大小设置为20,最终得到的模型为训练时在验证集上取得的性能最好的模型.测试时,网络能适应任意大小的噪声图像.所提出的方法使用TensorFlow框架和matlab来实现算法.
4.3 评价指标
为了评估所提出的IFDNet的有效性,本文使用两种常见的客观评价指标和主观视觉效果来评价IFDNet生成的图像的质量,两个客观评价指标分别为峰值信噪比(PSNR)和结构相似性(SSIM).
PSNR是最普遍的用于评价图像画质的指标,理论上,只要PSNR的值越高,那么生成的图像的质量就越好,它的定义如下:
(2)
式中:
(3)
其中,MAX表示图像中所有像素中的最大差值,MSE为干净图像G与IFDNet输出的去噪后的图像D的像素间的均方误差,H,W表示图像的高和宽,G(i,j)和D(i,j)分别表示干净图像G和IFDNet输出的去噪后的图像D的像素点(i,j),理论上,MSE的值越小,证明IFDNet输出的去噪后的图像D的像素值与干净图像G之间的像素值越接近,PSNR的值就越高,图像的质量就越好.
不同于PSNR的比较,SSIM是广泛使用的用于评价生成图像与参考图像之间的相似性的指标,一定程度上更能反映出更符合人眼的评估系统,它的定义如下:
(4)
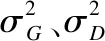
4.4 参数k的选择
为了使本文的方法能有效地融合不同的特征并产生更多纹理,选择一个合理的σ′=σ-k的参数k是必须的.若参数k选择太小则其对应模型的去噪结果与参数为σ的模型的去噪结果相近,无法提供足够多的纹理用于方法的融合,若参数k选择太大则其对应模型的去噪结果在保留纹理的同时也保留了更多的图像噪声,不利于方法的特征融合,因此,选择一个k值适中的参数σ′能使得所提出的方法性能更佳.针对k值的选择,本文做了一个不同k值下的图像去噪性能的对比实验,实验的第1个DnCNN模型的噪声参数均采用σ=50的高斯噪声,第2个DnCNN模型的噪声参数σ′的参数k分别选择1.5、2.5、3.5和4.5,并在验证集上评估它们的PSNR和SSIM值,如表2所示,参数k选择1.5、2.5或者3.5,所得到的PSNR值的差别并不明显,k为3.5时略微有下降趋势,但三者具有相近的SSIM,然而参数k选择4.5时,PSNR和SSIM明显有下降趋势,因此,[1.5-3.5]为参数k的合理取值范围.综上所述,本文选择参数k为1.5和3.5的中值即参数σ′=σ-2.5.

表2 不同参数在IFDNet上的性能比较Table 2 Comparison performance of different parameters on IFDNet
4.5 对比实验
4.5.1 实验1.主观视觉效果对比
为了证明IFDNet的去噪性能,图4和图5展示了两张不同图像由不同去噪方法得到的去噪结果的视觉效果对比.为了使视觉对比效果更明显,本文使用测试后的图像经过裁剪的部分图像作为对比区域.图4展示了当噪声等级为σ=40时,不同方法BSD68[28]上的Test011图像的去噪结果的视觉效果对比,图4(a)为无噪声图像,图4(b)为噪声图像,图4(c)为传统方法BM3D[14]的去噪结果图,图4(d)为DnCNN[19]的去噪结果图,图4(e)为FFDNet[21]的去噪结果图,图4(f)为所提出的方法的去噪结果图.一方面,首先可以看到BM3D的去噪结果图是模糊的,DnCNN的去噪结果图的楼层的结构并没有恢复出来,而FFDNet的左边的楼层结构虽然恢复出来了,然而右边的楼层结构仍然与参考图像相差甚远,并且所恢复出来的树是模糊的,另一方面,本文的IFDNet在恢复图像细节和结构方面表现出了很好的性能,并且能够获得比其他方法更好的视觉效果.图5展示了当噪声等级为σ=70时,不同方法BSD68[28]上的Test009图像的去噪结果的视觉效果对比,图5(a)为无噪声图像,图5(b)为噪声图像,图5(c)为传统方法BM3D[14]的去噪结果图,图5(d)为DnCNN[19]的去噪结果图,图5(e)为FFDNet[21]的去噪结果图,图5(f)为所提出的方法的去噪结果图.可以很明显的观察到BM3D的去噪结果图有很多瑕疵没有去除干净,并且纹理丢失相当严重,DnCNN的去噪结果的眼角纹理和老虎的胡须没有被恢复出来,整张图像的噪声去除的不干净,视觉效果更模

图4 不同方法在σ=40时的去噪结果的视觉效果对比Fig.4 Comparison of visual effects of denoising results computed by different methods at σ=40

图5 不同方法在σ=70时的去噪结果的视觉效果对比Fig.5 Comparison of visual effects of denoising results computed by different methods at σ=70
糊,而FFDNet的去噪效果甚至改变了老虎眼睛的纹理,耳朵也是模糊的,本文的IFDNet能更好的恢复出耳朵、眼睛和胡须等纹理信息,整体视觉效果清晰.综合图4和图5的视觉效果对比,本文的IFDNet的去噪图像噪声去除的更干净,且更能保存图像纹理.
4.5.2 实验2.IFDNet在数据集BSD68上的实验性能
实验2的主要目的是测试所提出的IFDNet在数据集BSD68[28]上的实验性能.表3和表4分别为不同方法在数据集BSD68上的PSNR和SSIM结果,表3中的行分别为噪声参数为σ=10,20,30,40,50,60,70时不同方法所产生的PSNR数值,列分别为同一方法在不同去噪参数时的PSNR数值,所包含的方法有:去噪参数为σ时的BM3D[14]模型,去噪参数为σ时的DnCNN[19]模型,去噪参数为σ-2.5的DnCNN模型,FFDNet[21]模型和本文的IFDNet.从表3中首先可以看出所提出的IFDNet的平均PSNR值比BM3D高出2.48dB,比DnCNN(σ)高出1.26dB,比DnCNN(σ-2.5)高出1.81dB,比FFDNet高出1.08dB,然后每个噪声参数的模型得到PSNR值均比所对比的方法高,尤其是在噪声参数为20时,本文的方法比所对比的方法高出3dB左右.表4中的行分别为噪声参数为σ=10,20,30,40,50,60,70时不同方法所产生的SSIM数值,列分别为同一方法在不同去噪参数时的SSIM数值.从表4中可以看出,IFDNet的结构相似度大部分都在所对比的方法中取得最高值,只有在噪声参数为30时,略低于FFDNet,并且所得到的平均结构相似度也是最高的.因此,综合PSNR和SSIM两个客观评价指标,本文所提出的方法在去噪的性能上是优于所对比的方法的.
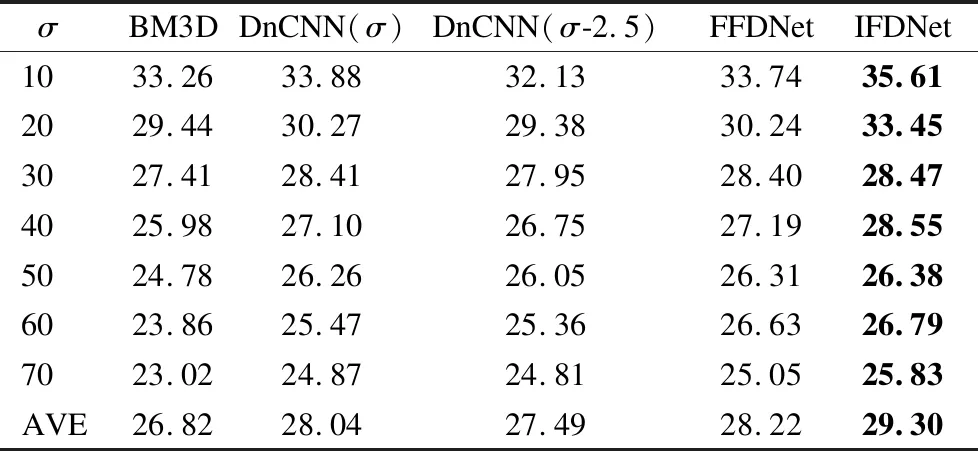
表3 不同方法在数据集BSD68上的PSNR(dB)结果(最优结果用粗体表示)Table 3 PSNR results of different methods on the dataset BSD68 (the best performance value in each row is shown in bold)
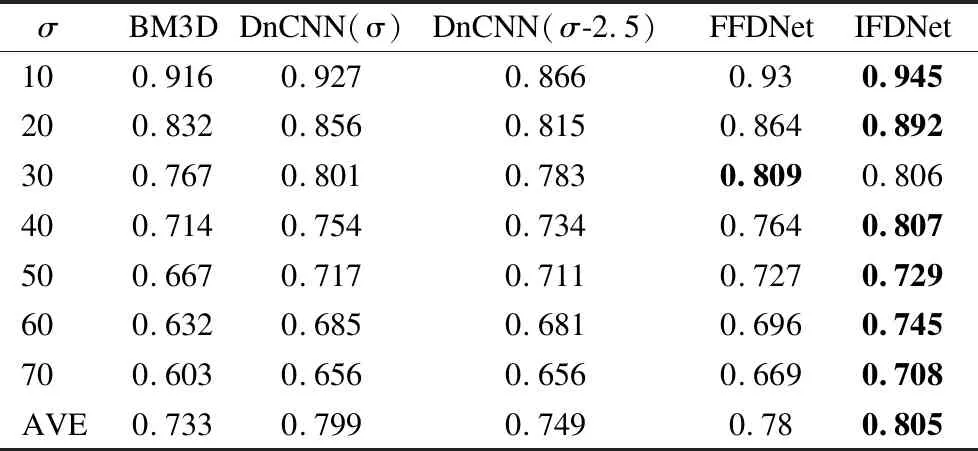
表4 不同方法在数据集BSD68上的SSIM结果Table 4 SSIM results of different methods on the dataset BSD68
4.5.3 实验3.IFDNet在数据集Set14上的实验性能
为了验证所提出的方法具有泛化能力,实验3使用与实验2完全不同的数据集Set14[29]对IFDNet的实验性能进行测试.所对比的指标为与实验2相同的PSNR和SSIM.表5为不同方法在数据集Set14上的PSNR结果,表6为不同方法在数据集Set14上的SSIM结果.表5中的行分别为噪声参数为σ=10,20,30,40,50,60,70时不同方法所产生的PSNR数值,列分别为同一方法在不同去噪参数时的PSNR数值.从表5中可以看出IFDNet在各个噪声水平时的PSNR值均比BM3D高,尤其在噪声水平越高时越明显,在噪声参数为10时略低于FFDNet[21]和DnCNN[19]的PSNR值,在噪声参数为30和50时,IFDNet的PSNR值比FFDNet低,但与DnCNN高,在其它噪声参数时,所提出的方法的PSNR值均比两个对比的方法高,7组对比实验的平均PSNR也比所对比的两个方法高.表6中的行分别为噪声参数为σ=10,20,30,40,50,60,70时不同方法所产生的SSIM数值,列分别为同一方法在不同去噪参数时的SSIM数值.从表6中可以看出,IFDNet的SSIM值在噪声参数为30和50时比FFDNet低,但比DnCNN高,在其它噪声参数时比两个对比的方法高,平均值也比DnCNN和FFDNet高,并且各个噪声水平上的SSIM值也都高出传统的BM3D算法.因此,综合表5和表6的数值对比,实验3证明了,所提出的方法在不同数据集上具有较强的泛化能力.
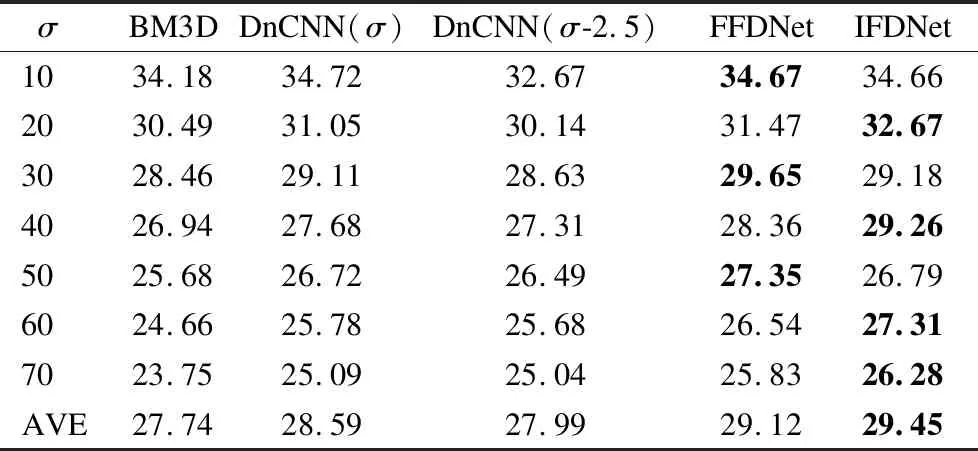
表5 不同方法在数据集Set14上的PSNR(dB)结果Table 5 PSNR results of different methods on the dataset Set14
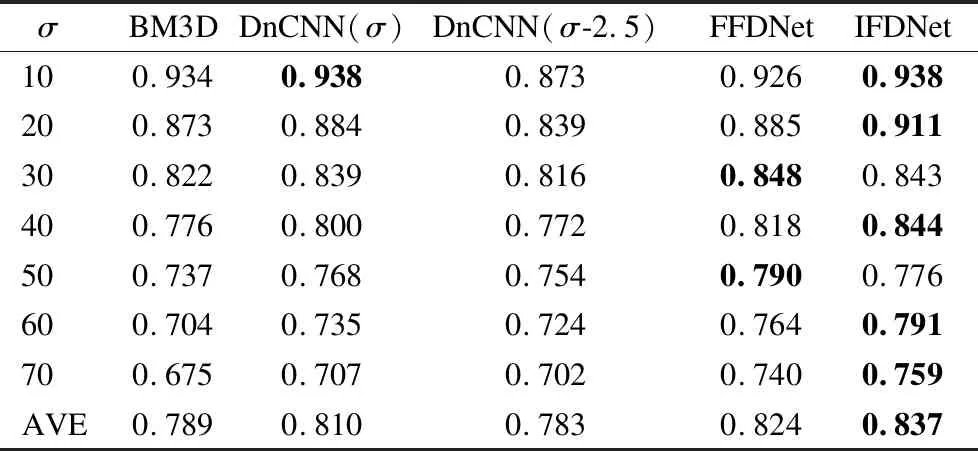
表6 不同方法在数据集Set14上的SSIM结果Table 6 SSIM results of different methods on the dataset Set14
4.6 鲁棒性测试
对比实验的结果表明,本文的方法在不同数据集上具有良好的去噪性能和泛化性能,为了证明本文的方法具有一定的鲁棒性,本文做了一个噪声图像的噪声方差与训练网络的噪声方差不一致时的鲁棒性测试实验.实验中训练网络的噪声方差σ=50,σ′=47.5,测试的噪声图像的方差选用50±1.5,在测试集测试的结果的PSNR值和SSIM值如表7和表8所示,当测试的方差为51.5时,IFDNet的去噪结果的PSNR值分别高于融合前的两个分支0.09和0.67,SSIM值分别高于融合前的两个分支0.006和0.032,当测试的方差为48.5时,IFDNet的去噪结果的PSNR值和SSIM值相较于融合前也略有提升.综上所述,当噪声图像的噪声方差与训练网络的噪声方差有偏差时,本文的方法仍然有效,可以实现对两个分支的融合并提高去噪性能.

表7 鲁棒性测试实验的PSNR值Table 7 PSNR values of the robustness test

表8 鲁棒性测试实验的SSIM值Table 8 SSIM values of the robustness test
5 结 论
本文针对现有的基于卷积神经网络的图像去噪方法在去除噪声的同时,对图像纹理会引入一定程度的破坏,导致去噪后图像无法保留图像的纹理的问题,提出了一种融合特征并保留纹理的图像去噪方法.该方法首先选取一种去噪方法,利用该去噪方法的两个不同去噪参数的预训练模型分别得到同一张噪声图像的不同初始去噪结果,然后为了增加可以融合的信息,利用两个编码器分别提取不同去噪结果的特征,并同时放入融合模块融合图像的特征,最后利用解码器重建出无噪声图像.实验证明,所提出的方法在不同数据集上具有较强的泛化能力,产生的无噪声图像所恢复出来的纹理信息更符合其原本的纹理,也证明了所提出的融合的方法能够有效的利用图像的先验信息,融合出更清晰的图像纹理.与两种现有的流行的图像去噪方法相比,所提出的方法无论在视觉效果还是在客观指标上皆优于这两种主流方法.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
电脑报(2022年24期)2022-07-01
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
舰船科学技术(2021年12期)2021-03-29
保健与生活(2019年7期)2019-07-31
小资CHIC!ELEGANCE(2018年33期)2018-11-08
Coco薇(2017年8期)2017-08-03
饮食科学(2016年7期)2016-07-27
