
基于多层局部信息融合的在线论坛用户心理危机识别
2021-04-12 09:50:46刘德喜鲍力平万常选刘喜平廖国琼
小型微型计算机系统 2021年4期
刘德喜,鲍力平,万常选,刘喜平,廖国琼
1(江西财经大学 信息管理学院,南昌 330013) 2(江西财经大学 数据与知识工程江西省高校重点实验室,南昌 330013)
1 引 言
心理健康问题一直是社会关注的焦点,它严重威胁着家庭和睦与社会稳定[1,2].据报道有超过2/3的自杀事件是由心理疾病导致的[3].及时发现有抑郁、焦虑、自杀等有心理危机问题的个体,有助于对其进行心理干预及治疗,因此心理危机识别对后期干预起着关键作用[4].
传统的心理危机识别主要采用填写自评量表的方式[5,6],但这种侵入型的方法会由于受试者的抵触而增加误报率.同时,这种方法适时性不高,且难以大规模并持续地开展.研究机构We Are Social在最新发布的《2020年4月全球数字报告》(1)https://wearesocial.cn/blog/2020/04/23/digital-around-the-world-in-april-2020上指出,全球使用社交媒体的用户已突破38亿大关,预计到2020年年底,世界一半以上的人口将使用社交媒体.已有研究表明,利用Reddit、微博等社交媒体数据已经成为发现心理危机用户的新手段[7,8].这些研究成果有利于将心理危机的干预时机提前,并增强干预的主动性,具有重要的社会意义.
本文以CLPsych2019 shared task评测任务为研究内容,针对论坛中用户心理危机识别问题,构建了基于多层局部信息融合的在线论坛用户心理危机风险识别模型Multi-layer Partial Information Fusion Model(MPIF).CLPsych2019 Shared Task评测任务是根据输入的用户帖子判断该发帖用户的心理危机程度,其中,每个用户的心理危机严重程度从轻到重依次分为4个等级a:无风险(No Risk),b:低风险(Low Risk),c:中度风险(Moderate Risk),d:高危风险(Severe Risk).示例1给出一个心理危机等级被标注为“d”的用户帖子.
示例1.(用户ID 1307)Help.Why should I live if my Acnes so bad,if the girl I asked to homecoming said no,if I get made fun of so much,if I′m not smart and my mom says I won′t go to college or do anything in my life like my sister,if all my friends have stopped asking me to hang out,if all I do is look in the mirror andcry,if Ineversmileanymore or laugh or have a good time with my friends or family.WhyshouldIliveifIcan′tfindhappinessnomatterwhereIlook.Why should I live if I have no talents,or anything special about me.Why should I live if I haven′t lived up to my own expectations.Anybody′s expectations.
通过对数据的观察发现,用户帖子中经常出现较长的唠叨、叙述等与心理危机关联不大的信息,且情感表达较隐晦,而能够反映心理危机的信息往住出现在某些局部的词、短语和句子上.例如示例1中的“cry”,“never smile”以及“Why should I live if I can′t find happiness no matter where I look”等反映出该用户有非常高的心理危机等级.MPIF模型正是基于“有利于判断心理危机的核心信息往往体现在局部内容上”这一观察,使用深度分层LSTM网络,将句子层面的LSTM网络和词语层面的LSTM网络相结合,挖掘帖子中句子层面和词语层面的特征.同时,使用CNN网络并结合多种大小不同的卷积核来提取帖子中短语层面的局部信息.本文提出了多层局部信息融合模型MPIF分别从词、短语和句子3个层面提取帖子中的局部特征,从而使模型达到更加准确的判断.
本文主要贡献在于:
1)提出基于多层局部信息融合的心理危机识别模型MPIF,该模型分别从词层面(使用词层LSTM网络)、短语层面(使用CNN网络)、句子层面(使用句子层LSTM网络)来对帖子进行特征提取,并通过词语层LSTM中的注意力、句子层LSTM中的注意力、以及CNN中的最大池化层提取帖子中的重要局部信息,并将其融合用于户心理危机程度识别.
2)使用BERT对用户帖子中的句子进行向量化表达.与传统的词向量方法相比,它充分考虑了句子中词语的之间的相互关系,以及词语在其上下文中的语义,使得语义表达更准确.
3)采用注意力机制和最大池化层,使得MPIF不仅能够有效利用局部信息,同时具有较强的可解释性.该模型不仅可以给出心理危机程度的判断,同时可以将这些局部信息展示给心理咨询专家,辅助心理咨询专家更快了解患者.
4)与CLPsych2019 shared task的参赛方法相比,本文提出的模型具有较强的竞争力.相比排名第1的模型,MPIF的官方评测指标All-F1值(心理危机程度a,b,c,d 4个类别的F1值取平均)和准确度Accuracy高出了3.9%和11.2%.
2 相关工作
心理危机识别是依据心理学的理论和方法对人的心理品质及水平所做的一种鉴定,在应用心理学中经常用心理诊断的概念,指对人的心理活动和人格特征做出实质性的判断.在本文中,心理危机识别是利用机器学习、深度学习、自然语言处理等技术对人的抑郁、自杀意念、焦虑及与心理状态有密切关系的人格障碍、情绪困扰等心理问题和现象状态的鉴定和识别.
在利用社交媒体数据进行心理危机识别的早期研究中,大多是基于传统的机器学习方法.这类方法在对数据统计分析的基础上提取和选择有利于区分类别的特征,特征工程的效果直接影响分类结果.已有的研究表明[9],通过选择合适的特征以及对多种特征组合,可以提高性能.Bridianne等人[10]通过对Twitter的数据分析处理,利用词频-逆文档频率(TF-IDF)特征,使用SVM分类器来识别Twitter用户是否有自杀倾向.针对相同的任务,Braithwaite等人[11]提取数据集中的用户属性特征与LIWC情感词典的特征,分别采用多个分类模型进行评估,最后得出结论,决策树模型的分类效果最好.Tsugawa等人[12]利用词袋特征、LDA主题模型特征、情感词典特征以及用户属性特征相结合,并使用SVM分类器对Twitter论坛用户是否有抑郁倾向进行评估.Li等人[13]使用用户属性特征、SCLIWC词典特征以及TextMind工具来分析新浪微博用户是否有自杀倾向.Malmasi等人[14]考虑了N-grams特征、句法特征、LIWC词典特征、上下文特征,并用逻辑回归模型分析用户的心理危机严重程度.Ji等人[15]利用LIWC情感词典特征、LDA主题模型特征、词性特征、TF-IDF特征以及Word2Vec词嵌入特征等多种特征相结合,最后使用XGBoost以及随机森林分类器分别对Reddit论坛和Twitter中有自杀倾向的用户进行识别,取得了不错的效果.
随着深度神经网络在其他领域取得了重大突破,近年来,有学者将深度神经网络模型用于心理危机识别中.与传统机器学习分类模型相比,使用词嵌入的深度学习方法十分便捷,即使没有复杂的特征工程通常也能获得较好的结果.卷积神经网络CNN作为深度学习中最常用的网络结构,在心理危机识别领域应用较多.Orabi等人[16]为了预测Twitter论坛中有抑郁心理状态的用户,预训练了Word2Vec的词嵌入模型,送入卷积神经网络中进行分类预测.Lin等人[17]使用特征工程与卷积神经网络相结合的方法,利用LIWC情感词典特征、图像特征以及用户属性特征再送入卷积神经网络预测新浪以及腾讯微博有心理压力的用户.Yates等人[18]使用卷积神经网络,对Reddit和ReachOut论坛用户进行抑郁和自我伤害倾向检测,从而避免了繁琐的特征构建工作.
其他一些经常使用的深度神经网络架构是长短时记忆网络(LSTM)模型,它对噪声的鲁棒性强,并且能够较好地捕捉序列中的长期依赖关系.Sawhney等人[19]在Twitter自杀用户数据集中,通过实验发现LSTM能够获得了最高的召回率;Ambalavanan等人[20]使用了BERT方法作为向量表示,并使用LSTM网络,对有自杀倾向的网络用户进行预测;Gui等人[21]使用Word2Vec进行向量表示,并使用双向LSTM网络对Twitter论坛中的抑郁用户进行预测.Orabi等人[16]为了比较CNN以及LSTM的效果,在Word2Vec词嵌入基础上构建了4个神经网络模型:最大池化层的CNN、多通道CNN、多通道池化CNN、带有注意力机制的双向LSTM,在两个不同数据集上的实验表明,基于CNN的模型性能优于基于RNN的模型.Mohannadi等人[22]将CNN与LSTM网络相结合预测Reddit论坛中有自杀倾向的用户,分别选用GloVe和ELMo方法作为帖子的文本表示,并将其输入CNN、Bi-RNN、Bi-LSTM、Bi-GRU 等4个经典的神经网络模型中提取特征,最后通过SVM进行分类预测,该模型在CLPsych 2019共享任务中获得排名第一的结果.
词向量在训练的过程中能够获取语义和句法信息,在自然语言处理任务至关重要[23].目前,基于深度学习的社交媒体用户心理危机识别已有方法中,词向量大都采用Word2Vec、ELMo,近期的研究工作开始采用BERT.Word2Vec是经典的词向量表示方法,其缺点在于同一个单词在不同的上下文语境具有相同的词向量表示.针对该问题,Peters等人[24]提出了ELMo(Embeddings from Language Models),该模型运用两层双向的LSTM结构,将上下文无关的静态向量变成上下文相关的动态向量.此外,Radford等人[25]提出了GPT(Generative Pre-Training)模型,GPT使用Transformer编码结构,舍弃了LSTM的循环式网络结构,完全基于自注意力(self-attention)机制,其主要思想是计算句子中的每个词对于其他词的相互关系,从而调整每个词的重要性来获取上下文相关的词向量.由于自注意力机制可以实现计算资源的并行化,使得GPT模型更高效.Devlin等人[26]在GPT模型的基础上,提出BERT模型,采用双向Transformer编码结构,以掩码单词预测和下一句预测作为训练目标,捕获文本中词级别和句子级别的语义表示.
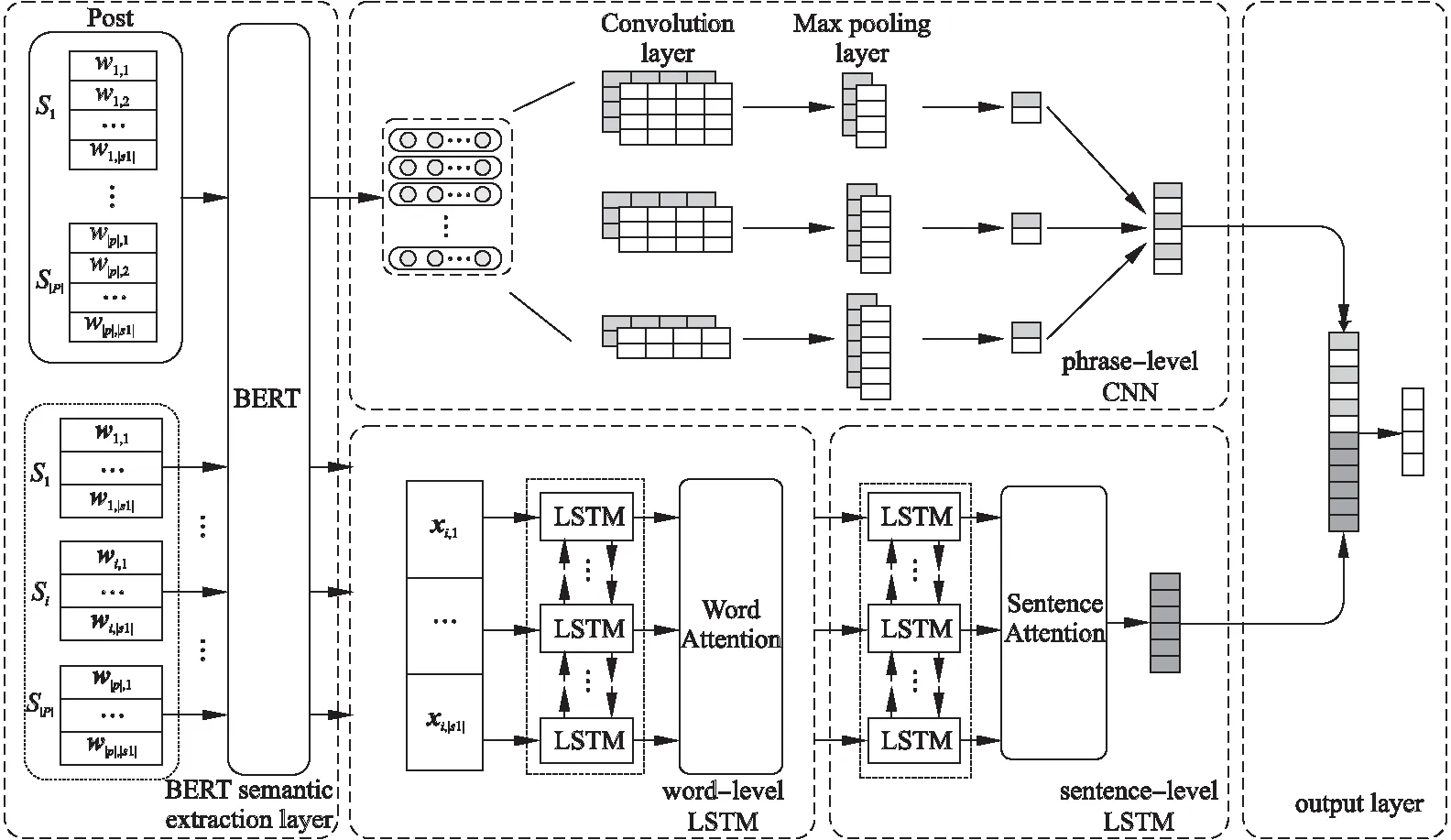
图1 多层局部信息融合模型网络框架Fig.1 Architecture of multi-layer partial information fusion model
3 多层局部信息融合模型MPIF
CLPsych2019Shared Task评测任务定义如下:给定用户一定时间范围内在论坛中所发的N个帖子构成的帖子序列P={p1,p2,…,pi,…,pN},其中帖子pi由|pi|个句子构成,pi={si,1,si,2,…,si,j,…,si,|pi|},句子si,j由|si,j|个词构成,si,j={wi,j,1,wi,j,2,…,wi,j,|si,j|}.心理危机识别任务是根据用户发布的帖子判断用户的心理危机程度.其中,每个用户的心理危机程度由轻到重依次分为4个等级(a:无风险,b:低风险,c:中度风险,d:高危风险).由于本文的工作利用了用户在一定时间范围内发布的全部帖子内容,且未在帖子粒度上对内容进行区分,即不区分句子所属的帖子,因此,将用户发布的帖子序列表示为P={s1,s2,s3,…,s|P|},其中|P|为帖子序列中句子的总数,且按其所在帖子的发布时间先后及其在帖子中的位置前后依次排列,形成句子序列.句子si={wi,1,wi,2,…,wi,|si|},其中|si|为句子si中的单词个数.为了方便表达,在不引起混淆的情况下,我们也可以将某一用户的帖子序列集合简单看成词的序列,P={w1,w2,w3,…,wn},n表示该用户帖子集合中单词数.
多层局部信息融合模型MPIF如图1所示,主要由5个部分组成.
1)词语语义提取层BERT
MPIF利用BERT对用户的帖子序列进行语义提取,充分考虑句子中每个词在不同上下文中对其他词的影响,以及同一词在不同上下文中的不同语义.考虑到后续模块对帖子语义的使用方式不同,MPIF分别以帖子序列P和句子s两种粒度作为BERT层的输入.以帖子序列P为输入粒度,是将某一用户的帖子序列集合P={w1,w2,w3,…,wn}送入BERT预训练语言模型,得到该用户的帖子序列集合的语义表示矩阵PB=[x1,x2,x3,…xn],其中PB∈Rz×n,z为词向量的维数.以句子s为输入粒度,是将用户帖子的各个句子分别送入BERT预训练语言模型,得到各个句子的语义表示矩阵.对于第i个句子si={wi,1,wi,2,…,wi,|si|},得到siB=[xi,1,xi,2,…,xi,|si|],其中siB∈Rz×|si|.最后将语义表示矩阵PB和siB(i=1,…,|P|),分别作为短语层CNN网络和词语层LSTM网络的输入.
2)短语层局部特征提取模块
短语层局部特征提取模块采用CNN网络,主要分为卷积操作和池化操作两部分,卷积操作主要是捕获文本特征中的局部信息,池化操作则完成局部重要特征的提取[27].在自然语言处理任务中,CNN无需对文本进行大量的预处理工作,有效减轻了特征工程的工作量[28].
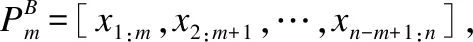
(1)
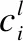
(2)
其中,wl是卷积核的权重,按照均匀分布随机初始化,并在模型训练过程中不断学习,bl∈R是偏置变量.
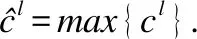
考虑到短语的长短不同,本文采用长度不同的多个卷积核.对于q个卷积核得到的结果如下:
(3)
3)词语层局部特征提取模块
词语层局部特征提取模块采用BiLSTM网络.循环神经网络RNN已广泛应用于处理变长序列输入的NLP问题中,它能动态地捕获序列中的特征信息,将信息更新保存在循环隐藏向量中.由于过于依赖前一个隐藏向量,在算法的实现上容易出现梯度消失问题.为了能够缓解该问题,Hochreiter等人[29]提出了LSTM模型,增加了记忆单元和控制门的机制,在此基础上Graves等人[30]进行了改良与推广,使模型更高效.双向LSTM(BiLSTM)通过在两个方向上处理序列,一个按正向处理输入序列,另一个按反向处理输入序列,利用了正向和反向的上下文,生成两个独立的LSTM输出向量序列.每个时间步长的输出是两个方向上输出向量的串联.本文采用的BiLSTM模型与Graves等人的方法相似.词语层面的BiLSTM网络主要分为词编码器以及词级别的attention机制.LSTM接收一个以词语为单位的句子作为网络的序列化输入.给定一个句子s={w1,w2,…,w|s|},其BERT预训练结果为sB=[x1,x2,x3,…,x|s|],当前时刻LSTM单元的输入为第t个单词的向量xt∈Rz以及t-1时刻的隐藏向量ht-1,t时刻各状态和门控信号更新方式如公式(4)-公式(8)所示:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(4)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(5)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
(6)
ot=σ(Wxoxt+Wxfht-1+Wcfct-1+bf)
(7)
ht=ottanh(ct)
(8)
其中LSTM主要由3个门结构来控制模型,分别是输入门it、遗忘门ft、输出门ot,ct为t时刻记忆单元的状态,σ为sigmoid函数,tanh为双曲正切函数,W为的权重,b为偏置值.
我们使用双向LSTM得到单词的双向序列表示,其中双向LSTM包含前向LSTM读取顺序由x1到x|s|,以及后向LSTM读取顺序由x|s|到x1,将双向LSTM两个方向上的隐藏向量进行拼接,得到隐藏层的输出,具体公式如式(9)-式(11)所示:
(9)
(10)
(11)
经过词语层面的LSTM网络之后,获得各个词的新的向量编码序列ht,它包含了单词wt周围两个方向的信息.
词级别注意力机制的目的是要把句子中对判断心理危机更有帮助的词赋予更大的权重.本文通过将ht输入到一个单层的感知机(MLP)中得到的结果ut作为ht的隐含表示.单词的重要性用ut和一个随机初始化的上下文向量uw的相似度来表示,然后经过softmax操作获得归一化的attention权重矩阵αt,代表句子s中单词wt的权重.最后将句子向量o看作组成句子s中词向量的加权求和.具体公式如式(12)-式(14)所示:
ut=tanh(Wwht+bw)
(12)
(13)
(14)
4)句子层局部特征提取模块
通过词语层局部特征提取模块,得到帖子中各个句子的句子向量,将这些句子向量送入句子层BiLSTM网络,并使用句子级别的注意力机制,使得模型区别对待不同句子在判断心理危机上的作用.设帖子的第i个句子si的句子向量为oi,使用类似词语层BiLSTM网络模型,获得隐藏层的输出向量,如式(15)-式(17)所示.
(15)
(16)
(17)
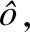
ui=tanh(Wshi+bs)
(18)
(19)
(20)
5)输出层
将短语层CNN网络的序列化输出和句子层LSTM的序列化输出进行拼接,构成新的序列化特征,通过一层全连接层和softmax层将帖子P分类到心理危机的4个不同程度(类别)上.计算方法如式(21)、式(22)所示:
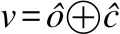
(21)
y=softmax(Wmv+by)
(22)
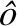
(23)
与已有的心理危机识别模型相比较,本文提出的多层局部信息融合模型MPIF具有以下特点:
1)输入层的语义表示更准确.由于BERT预训练语言模型在大规模语料上学习所得,它充分考虑了句子中每一个词语对上下文中其他词语的影响,以及同一个词语在不同语境中的不同含义表达.
2)强化局部信息在心理危机识别中的作用.由于在用户发布的帖子集合中,反映用户心理危机状态的信息通常局限在特定的句子、短语以及词语上,MPIF模型从这3个层面抽取局部信息.带注意力机制的词语层LSTM网络不仅能有效表示整个句子的语义,还能挖掘句子中的词语层面上的局部特征.带注意力机制的句子层LSTM网络不仅能有效表示全部帖子内容的语义,还能挖掘帖子中的重要句子.在一些用户帖子中,某些句子长度较短或情感表达较隐晦,仅利用词语层面的LSTM网络难以获取足够的特征信息来对帖子进行判断,但同一帖子中不同句子之间却有密切的情感联系.所以,MPIF模型将句子层面的LSTM网络和词语层面的LSTM网络相结合,通过词语层面的LSTM获取句子内部的语义信息,通过句子层面的LSTM网络挖掘整个帖子中句子之间的情感联系.同时,使用短语层面的CNN网络,通过多种大小不同的卷积核,挖掘帖子中词组和短语的语义信息,以弥补词层面和句子层面在刻画帖子内容时粒度过小和过大的问题.

表1 人工标注示例Table 1 Manual annotation examples
3)具有更强的可解释性.采用注意力机制和最大池化层,使得MPIF模型不仅能够有效利用局部信息,同时具有较强的可解释性.该模型不仅可以给出心理危机程度的判断,还可以将这些局部信息展示给心理咨询专家,辅助心理咨询专家更快了解患者.
4 实验与结果分析
4.1 数据描述与评测指标
实验使用CLPsych2019 Shared Task中的子任务A,即通过用户在特定论坛版块上发布的帖子,识别用户的自杀风险等级.数据集来源于Reddit论坛SuicideWatch(2)https://www.reddit.com/r/SucideWatch/板块中用户2015年发表的帖子集合,包括帖子id、匿名用户id、发帖时间、论坛名称、帖子标题以及帖子内容等信息.数据集包括训练集以及测试集,训练集中人工标注了496个用户(共发布了919条帖子)的心理危机程度;测试集中人工标注了125名用户(共发布了186条帖子)的心理危机程度.人工标注的心理危机程度共分4个等级,用a、b、c、d表示,分别表示帖子作者的自杀风险程度为“无风险”、“低风险”、“中度风险”和“重度风险”.人工标注示例及标注说明简要介绍如表1所示,各类别样本分布情况如表2所示.
表2显示,各类样本分布不均衡,标记为低风险和中度风险的帖子较少,只占帖子总数的25%,再加上这两类帖子自杀风险程度较为接近,辨识难度大.为了让模型能够更好的识别这两类帖子,本文使用过采样技术,将低风险和中度风险的帖子适当增加.
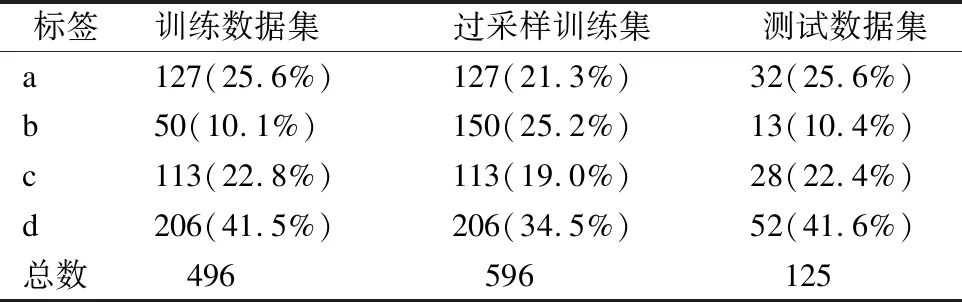
表2 标签样本分布表Table 2 Label sample distribution
评测的指标采用CLPsych2019 共享任务的官方评测指标[31],其中包括:
1)All-F1:a,b,c,d 4类样本分类结果F1值的宏观平均.该指标反映了所有样本的综合识别能力,是CLPsych2019对各参赛统进行排名的指标.
2)Flag-F1(Flagged F1):将所有非a类的样本视为一个大类,称为flagged类,a类和flagged类样本分类结果F1值的宏观平均.该指标反映模型对有、无自杀风险的区分能力.
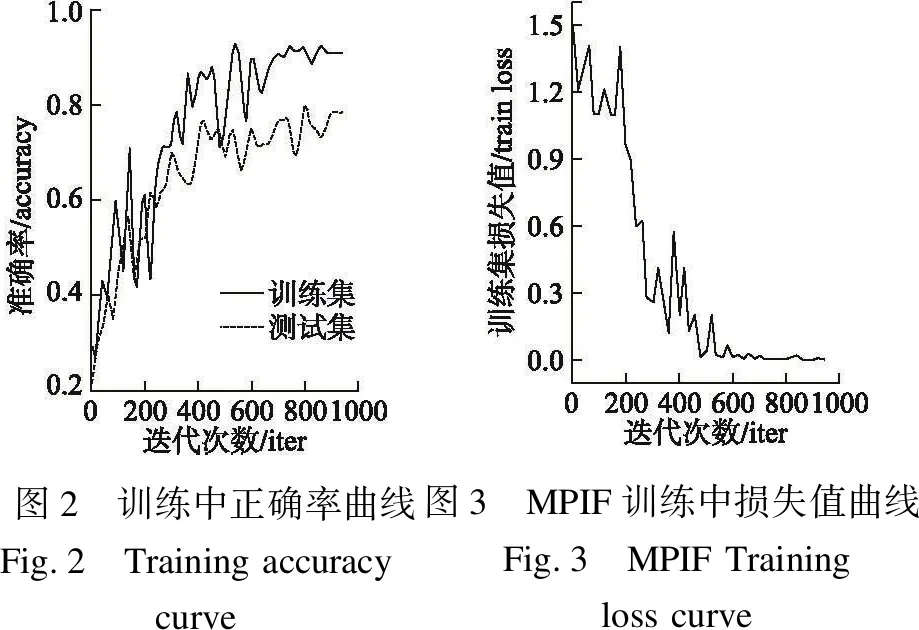
图2 训练中正确率曲线Fig.2 Training accuracy curve图3 MPIF训练中损失值曲线Fig.3 MPIF Training loss curve
3)Urg-F1(Urgent F1):将所有d类和c类的样本视为一个大类,称为urgent类,a类和b类的样本视为非urgent类,urgent类和非urgent类样本分类结果F1值的宏观平均.该指标反映模型对需要紧急处理和不需要紧急处理的用户的区分能力.
4)Acc(Accuracy):指模型分类正确的样本个数占总样本个数的比例.
4.2 实验环境与超参数设置
本文所提出的模型采用Ubuntu上的PyTorch进行搭建,实验采用的环境如表3所示.
实验中采用的是Google提供的预训练语言模型“BERT-Base,Ucased”,模型采用了12层Transformer,隐藏大小为768,Multi-head Attention的参数为12,对于每一个输入的词,它分别从词向量(token embeddings)、分段向量(segment embeddings)和位置向量(positions embeddings)进行表征.模型超参数设置如表4所示.

表3 实验配置Table 3 Lab environment
4.3 训练过程
MPIF在训练集和测试集上的准确率随迭代次数的变化如图2所示,其在训练集上的损失随迭代次数的变化如图3所示.因此,本文取迭代次数为1000时的模型进行实验.
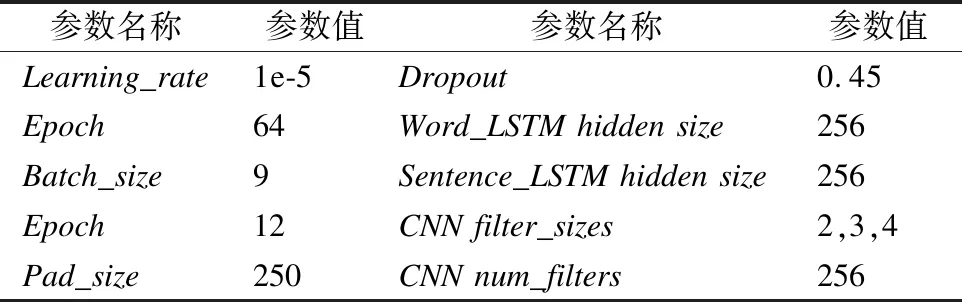
表4 超参数列表Table 4 Hyperparameter List
4.4 对比模型
1)BERT:采用Devlin等人[26]提出BERT预训练模型,利用BERT模型在语料库上预训练得到文本表示,并将其直接输入到全连接层和softmax层进行分类.
2)BERT+BiLSTM:利用BERT预训练得到文本特征表示之后,输入到Wang等人[32]提出的BiLSTM中完成特征训练及分类.
3)BERT+HLSTM:深层注意力机制模型HLSTM由Yang等人[33]提出,作者设计了一个多层的attention机制.其中第1层是word-level的attention,依据不同单词的贡献,聚合成句子级别的表示.第2层是sentence-level的attention,依据不同句子的贡献,聚合成帖子级别的表示.该方法能够有效获取句子内部的依赖关系,同时可以获取同一条帖子中不同句子的相互关系,适合用于长文本的用户帖子与评论中.实验中通过只使用MPIF中的词语层面LSTM以及句子层面的LSTM层来模拟HLSTM.
4)BERT+TextCNN:TextCNN网络是2014年Kim等人[34]提出的使用卷积神经网络来处理NLP问题的模型.该模型利用BERT预训练得到文本特征表示之后输入到TextCNN模型中完成特征训练及分类.实验中通过只使用MPIF中的CNN短语层来模拟TextCNN.
5)BERT+DPCNN:DPCNN由腾讯AI-lab在ACL2017年提出[35],由于CNN不能通过卷积获得文本的长距离依赖关系,而DPCNN通过不断加深网络,可以抽取长距离的文本依赖关系.利用BERT预训练得到文本特征表示之后,输入到DPCNN中进行分类.
除将本文提出MPIF模型与现有比较经典的模型对比外,为了验证MPIF模型的竞争力,我们将其与CLPsych2019排名前4的模型进行对比,他们分别是:
6)CLAC[22]:Mohannadi等人将传统方法与神经网络相结合,选用GloVe和ELMo方法作为帖子的文本表示,并将其输入CNN,Bi-RNN,Bi-LSTM,Bi-GRU 4个经典的神经网络模型中提取特征,最后通过SVM实现分类.
7)ASU[20]:Ambalavanan等人使用了较为先进的BERT方法作为他们的神经网络模型,通过相应的微调,对用户帖子进行分类.
8)IDLab[36]:Bitew等人采用传统特征工程的方法,使用帖子的词频逆向文件频率(TF-IDF)特征、情绪特征以及自杀风险特征,并送入SVM实现分类.
9)SBU-HLAB[37]:Matero等人的模型使用了双向transformer架构的BERT嵌入方式,从主题、词向量、用户所发帖的论坛等特征构建逻辑回归模型.
4.5 实验结果分析
各模型在测试集上的实验结果如表5所示.
由表5可以看出,总体上,本文提出的MPIF模型在各个评测指标上都显著优于其它模型,All-F1和准确率分别为0.520和0.616,比CLPsych2019SharedTask参赛模型中的第1名[22]高出了3.9%和11.2%
具体地:
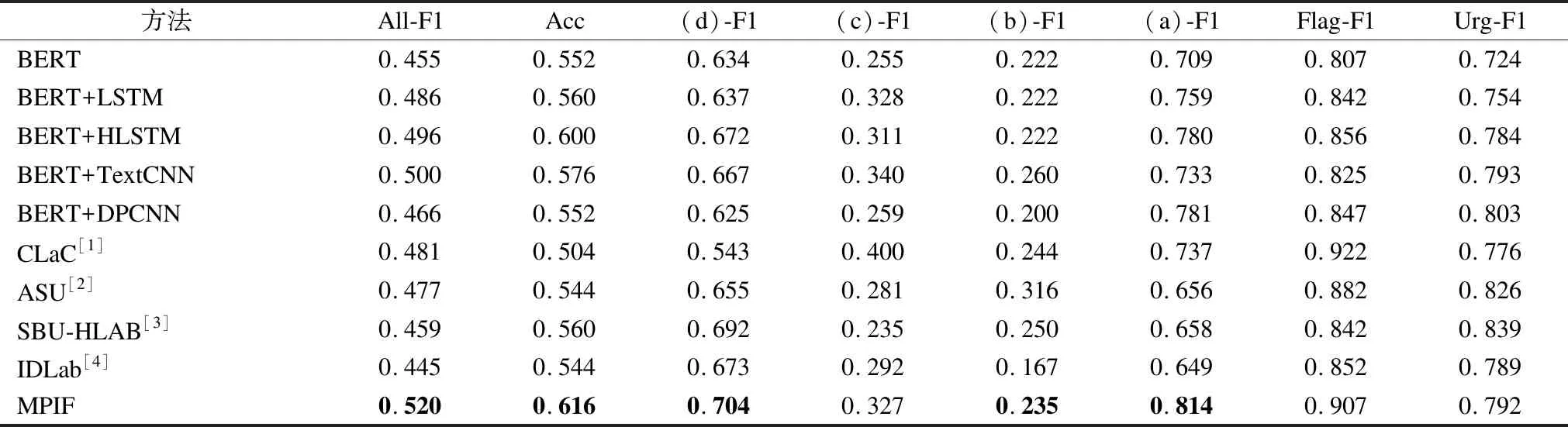
表5 实验结果Table 5 Experimental results
BERT模型在All-F1上比MPIF低6.5%,原因是仅使用BERT时,无法考虑帖子中句子内部和句子之间的依赖关系,以及词、短语、句子层的局部信息.
BERT+DPCNN模型在All-F1上比MPIF模型低5.4%,原因是,尽管BERT+DPCNN试图通过深层CNN模型抓住更长距离的语义依赖,但无法显式地考察句子之间的依赖关系,且考察整个帖子内容的做法尽管在其它诸如文本主题分类任务上有效,但心理危机的识别更倾向于关注局部信息.
BERT+LSTM模型虽然可以保留帖子中词语之间的长距离依赖关系,但由于没有结合注意力机制,无法捕捉到对分类更有帮助的局部信息,其All-F1值和准确率Acc分别为0.486和0.560.
加了分层注意力机制的BERT+HLSTM模型比BERT+LSTM有更好的表现,其All-F1值和准确率Acc提升了1%和4%,达到0.496和0.600.但与MPIF相比,尽管BERT+HLSTM模型考虑到了帖子中单词以及句子层面的局部信息,但没能考虑到帖子中短语的作用.
相比其它参考模型,BERT+TextCNN模型效果较好,All-F1值相达到0.500,原因是TextCNN网络使用多种大小不同的卷积核,能够有效挖掘提取帖子中短语层面的局部信息,但该模型无法关注句子内的词语之间以及句子之间的语义依赖,因此其All-F1值较MPIF仍低2%.
为进一步说明多层局部信息融合模型MPIF的性能及其与其它模型的差异,表6给出了数据集中的几个示例.其中3表示BERT+HLSTM模型识别结果,4表示BERT+TextCNN模型识别结果,M表示MPIF模型识别结果,L为人工标注的类别.
从表6结果可以看出,用户15232的帖子有“tired”“depr-ession”“anxiety”“self harm”等与心理危机相关的词汇,但该帖子相对较长,导致与心理危机相关的语义淹没在其它信息中.用户44772和用户51307的帖子中没有明显的心理危机相关的词汇,但用户15232的帖子中存在如“Why should I live if I can′t find happiness”这种与心理危机程度高度相关的短语或子句.针对用户15232,BERT+HLSTM模型识别错误,可能的原因是,深层HLSTM考虑了整个帖子的内容,但对局部信息的作用突显不够,使得与心理危机相关的信息被冲淡.BERT+HLSTM对于用户51307能够识别正确,说明该模型对较长句子的语义理解是非常有效的.与BERT+HLSTM形成互补的是BERT+TextCNN,后者对于用户15232的帖子中的局部信息的捕获能力较强,但对用户51307的帖子中长句的语义理解存在不足,导致BERT+TextCNN对用户15232的识别正确,却对用户51307识别错误.

表6 模型结果对比Table 6 Comparison of model results
对用户44772的识别更有挑战性,“lost”“My heart breaks”等局部信息或子句会诱使BERT+TextCNN和BERT+HLSTM模型做出错误判断,但如果把该帖子的前后语义综合考虑,即因为“I lost a good friend”导致“My heart breaks”,并不是用户本身有心理危机.而MPIF在融合了局部信息及多个句子的语义关联后,做出了正确的识别.
4.6 消融实验
为了验证本文提出的MPIF模型各个模块的有效性,我们对MPIF模型进行了消融实验,在模型参数不变的前提下,去除词语层LSTM模块(-wLSTM)、短语层CNN模块(-pCNN)、句子层LSTM模块(-sLSTM),实验结果参数如表7所示.
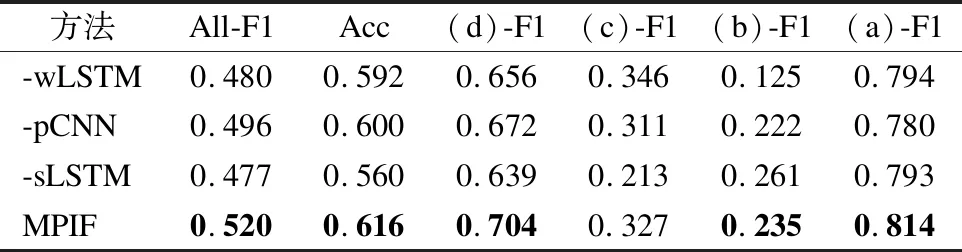
表7 消融实验结果Table 7 Ablation experiments results
表7显示,去除词语层LSTM后,MPIF的All-F1值下降4%,准确率Acc下降2.4%;去除短语层CNN后,MPIF的All-F1值下降2.4%,准确率Acc下降1.6%,;去除句子层LSTM后,MPIF的All-F1值下降4.3%,准确率Acc下降6.6%.
4.7 可视化
为了验证本文提出的MPIF模型中的词语LSTM层和句子LSTM层能够有效提取关键信息的能力,我们针对几个用户贴子,分别从词语和句子的角度进行了可视化,如图4所示.其中,每一行表示一个句子,句前阴影部分表示句子的权重,句中阴影部分表示句子中单词的权重,颜色的深浅表示MPIF中相应注意力的权重越大.

图4 MPIF模型词语和句子层面热力图示例Fig.4 Word and sentence level thermal diagrams
MPIF模型通过词层注意力机制注意到带有自杀倾向的词汇,例如图4(a)中的词“lost”、“ruin”、“hopeless”,图4(b)中的词“difficult”、“depressed”等.它还通过句子层注意力机制注意到反映心理危机的句子,例如,在图4(a)中的句子“i have no motivation left”、图4(b)中的句子“I am very depressed and lonely ”等.对于句子“i have no motivation left”(“我没有动力再留下”),如果单纯地看其中的每一个单词,可能会认为它们都是一些平常的表达,然而,MPIF模型通过观察这句话的完整语义及上下文后,给这句话更高的权重.
4.8 错误示例分析
为了探究MPIF模型的不足及其改进方向,我们分析了部分被MPIF识别错误的例子,代表性的示例如表8所示.示例帖子来自用户50962,内容是倾述学习压力较大,贴子中出现较多的与心理危机相关的词如“therapy”、“medication”等,但他并没有自杀倾向,因此人工标签为a(无风险),但在MPIF模型看来,“therapy”、“few friends”、“I′m spending another night crying to myself”等内容在词、短语和句子上都显示出了丰富的心理危机线索,导致MPIF模型将其识别为类别d(高危风险).由于不同种类的心理危机是相互关联的,比如焦虑、抑郁、自杀倾向等,但本文用于实验的任务只是识别是否有自杀倾向这类心理危机,有自杀倾向的用户通常会表现出焦虑、抑郁、压力等,但有焦虑、抑郁或压力不意味着一定会有自杀倾向.然而,MPIF模型无法区分这些心理危机之间的联系,而仅通过数据集的训练难以对用户50962的贴子内容进行正确判断.对于这类问题,充分利用心理学知识,将不同类型心理危机之间的区别和联系引入模型,并结合多任务学习,可能是一个有效的解决途径.

表8 MPIF识别错误的示例Table 8 Example of identifying errors
用户44876的帖子中,“trouble”、“debts”等内容可能诱导了MPIF将其识别为类别b(低风险),但该帖子的人工标签却是a(无风险).在错分的样本中,大部分是将帖子的心理危机等级错误地识别为比较接近的等级.这是一个极具挑战性的任务,因为人工在对心理危机程度进行判断时,同样也面临着类似的挑战,特别是当可利用的用户帖子较少时(CLPsych2019子任务一的数据集中,平均每个用户可利用的帖子不到两条帖子,496名用户共919条帖子).一个可能的解决思路是,利用用户更多的帖子,在更丰富的信息上综合判断.
5 总结展望
本文提出了一个多层局部信息融合的MPIF模型,并应用于在线论坛用户心理风险识别任务中.通过与有代表性的深度神经网络以及与CLPsych2019排名前4队伍所提出来的模型其进行对比,验证了MPIF模型的有效性.MPIF模型利用BERT对评论信息的句子进行向量化表达,充分考虑句子中每个词在不同上下文中对其他词的影响,以及同一词在不同上下文中的语义.模型分别从词语、短语、句子3个层面挖掘反映用户心理危机状态的信息.采用深度分层LSTM网络和注意力机制相结合的方式来获取帖子中词语层面以及句子层面的局部信息,利用CNN网络中多种大小不同的卷积核来提取帖子中短语层面的局部信息,并将词语、短语、句子3个层面得到的局部信息进行融合.词语和句子层面的热力图显示,MPIF有效地抓住了能反映用户心理危机的局部信息,这些信息有利于心理咨询专家快速了解用户的心理危机状况.
通过对错分样本的分析,发现可以从以下几个方面对模型进行改进:
1)考虑引入心理学特征,并利用多任务学习将不同类型的心理危机识别任务联合训练;
2)充分利用用户发布的帖子,包括未标注的数据,在更丰富的信息上判断用户的心理危机状况;
3)将用户及其帖子放在用户网络和帖子网络中,充分利用用户之间以及帖子之间的互动关系.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
英语文摘(2019年4期)2019-06-24 03:46:08
少年博览·小学低年级(2017年5期)2017-06-09 16:23:58
小雪花·成长指南(2016年11期)2016-12-07 06:14:37
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
汽车观察(2016年3期)2016-02-28 13:16:35
新高考·高二数学(2015年11期)2015-12-23 18:17:44
女性天地(2012年11期)2012-04-29 00:44:03
小品文选刊(2009年7期)2009-05-25 09:59:52
