
细菌特征分析的革兰氏阴阳性判别算法
2021-04-12 10:13张劲松
小型微型计算机系统 2021年4期
袁 健,赵 桦,张 明,张劲松
1(上海理工大学 光电信息与计算机工程学院,上海 200093) 2(海军军医大学 教研保障中心,上海 200433) 3(中国科学院 上海生命科学研究院,上海 200031)
1 引 言
自然界存在多种多样的病菌,如何有效地将人类新发现的细菌快速加以鉴别、分类,以便选择有效药物进行治疗,在生物医学领域具有重要意义.革兰氏染色法用于鉴别细菌[1],可以把众多的细菌分为两大类,革兰氏阳性菌和革兰氏阴性菌[2].大多数化脓性球菌属于革兰氏阳性菌,它们能产生外毒素使人致病,而大多数肠道菌属于革兰氏阴性菌,它们产生内毒素,靠内毒素使人致病.在治疗上,大多数革兰氏阳性菌都对青霉素敏感,而革兰氏阴性菌则对青霉素不敏感,却对链霉素、氯霉素等敏感.所以区分出病原菌是革兰氏阳性菌还是阴性菌,在选择抗生素方面意义重大.
目前细菌分类方法主要是革兰氏染色法.然而,染色时会发现某些革兰氏阳性菌褪色,某些革兰氏阴性菌会由于菌龄或培养基的不同而产生黑色的染色粒,同时染色程序较为复杂,由于细胞培养时间过长可能导致部分细胞发生死亡或自溶,从而导致染色结果为假阴性.革兰氏染色法借助细菌不同的细胞壁结构引起的染色性差异来进行分类,但是涂片的厚薄和脱色时间的掌握制约着该方法的准确性,这已成为未知细菌的准确和快速分类的瓶颈.随着第3代测序技术和质谱技术的成熟,大家已能够很方便和快速地获得细菌的蛋白质序列.因此,本文开创性地研究了利用计算机对细菌的蛋白质序列进行特征分析和提取来进行细菌的革兰氏阴阳性判别的算法,经实验证明效果良好.
本文主要完成以下3项工作:
1)提出利用细菌蛋白质序列进行细菌的革兰氏阴阳性判别算法GCBPS算法;
2)用实验验证选用闭合邻接序列模式(FCloConSP)的GCBPS算法进行细菌革兰氏阴阳性判别的准确性以及可行性;
3)用FConSP替代GCBPS算法中的FCloConSP后生成GCBPS-X算法,比较GCBPS和GCBPS-X的准确性,以及FCloConSP相比FConSP的精简性,验证GCBPS算法的优化性.
2 相关工作
目前对细菌的分类方法主要有以下几种,其中由丹麦医生革兰于1884年发明的革兰氏染色法为主要的鉴别染色法[1].革兰氏染色法根据细菌体内含有特殊的核蛋白质镁盐与多糖的复合物与燃料的吸附性进行分类,但是,该方法结果容易受许多因素的影响,比如菌龄和乙醇脱色时间对染色结果的影响.针对革兰氏染色法操作复杂以及容易脱色的缺点,有一些可克服上述缺点的辅助方法,如氨肽酶法、吖啶橙染色法.此外还有利用氢氧化钾溶液对细菌进行分类[3],此类辅助方法相比革兰氏染色法而言操作更加简便,时间较快.此外,基于声光可调滤光片(AOTF)的高光谱显微镜成像(HMI)方法具有从细胞水平上快速鉴定微菌落中食源性致病细菌的潜力,文献[4]利用高光谱显微镜成像方法对革兰氏阳性和革兰氏阴性食源性致病菌进行分类以及文献[5]利用利用拉曼光谱法对革兰氏阴阳性细胞结构所接受的拉曼散射强度不同来进行细菌对革兰氏阴阳性判别.鉴于序列特征研究的广泛应用[6],为了更快速、方便地实现细菌的革兰氏阴阳性判别,本文研究对细菌的蛋白质序列进行智能分析来判别其革兰氏阴阳性的算法.
近年来,利用序列来分类在很多领域应用颇多,尤其在基因组研究中引起了广泛的关注[7,8],比如,利用朴素贝叶斯对rRNA序列进行分类[9]归到Bergey的《原核生物分类大纲》.在一条生物序列中,每一项(核酸或氨基酸)都有着不同的关系,并不同以往的频繁项集与关联规则中的项出现的顺序[10],这种序列分析工作又被称为序列模式挖掘,主要研究如何有效地发现序列中能代表核心特征的一般序列模式(General Sequential Pattern)或精简序列模式(Compact Sequential Pattern)[11,12].由于,精简序列模式可以产生相对少量但分类效果、信息承载能力与一般序列模式相当的序列模式[13,14].所以本文采用精简序列模式来分析蛋白质序列.
在精简序列模式分析下,本文提出了基于蛋白质序列特征分析的细菌革兰氏阴阳性判别算法(Gram Classification algorithm for Bacteria based on Protein Sequences,GCBPS),从而实现对蛋白质序列进行精简序列模式的挖掘和特征的提取以及对革兰氏阴阳性的判别.此算法仅需对细菌的蛋白质序列进行计算机软件处理,无需再进行生物实验.该方法对硬件条件要求低,判别时间短,准确性较高.
3 相关定义与问题陈述
3.1 相关定义
定义1.(邻接子序列)
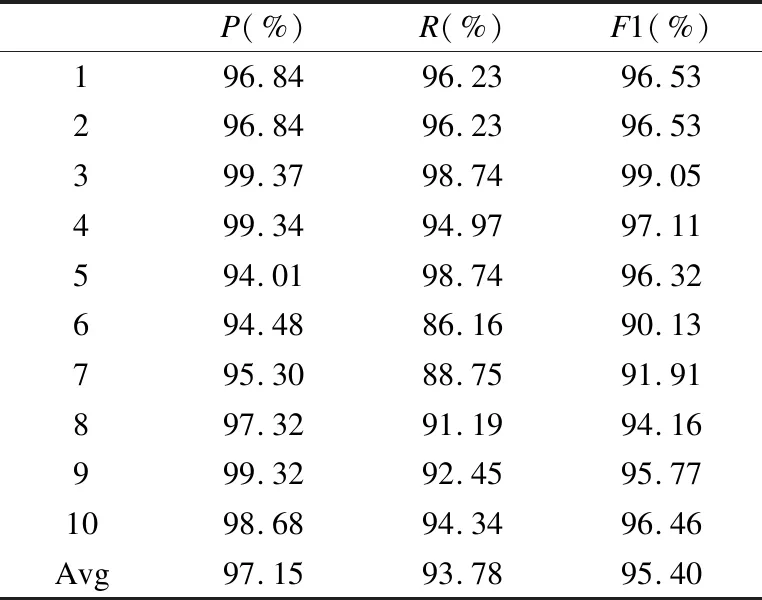
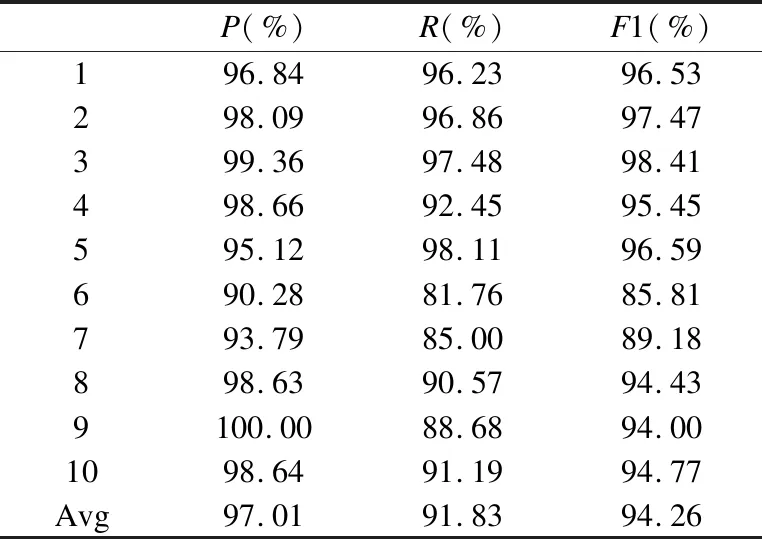
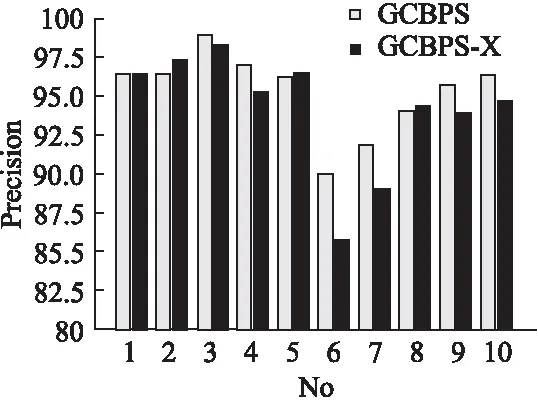
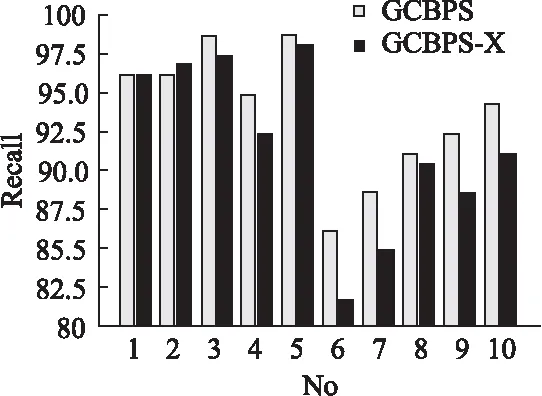
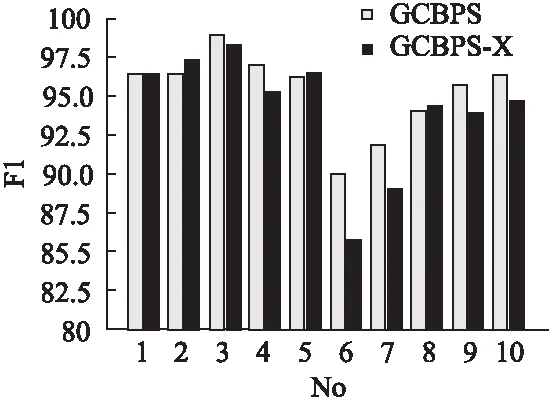
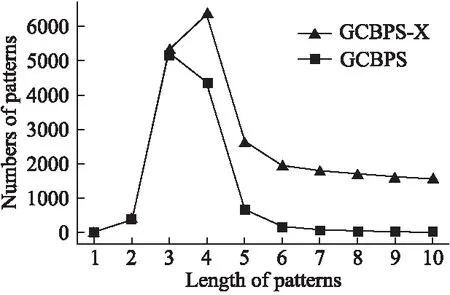
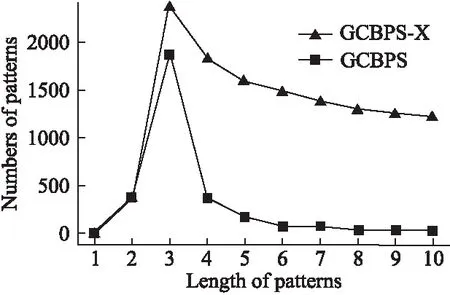
若序列S1= 定义2.(邻接序列模式) 指定一个支持度阈值σ,若一个邻接子序列s满足SupD(s)≥σ,其中SupD(s)表示s支持度,则s为邻接序列模式. 定义3.(闭合邻接模式) 若一个邻接序列模式s满足不存在一个邻接序列模式s1,同时使s⊂s1和SupD(s)=SupD(s1)成立,则s为闭合邻接序列模式. 定义4.(前后子序列) 给定两个序列s1= 需解决的问题如下: 采用第3代测序技术和质谱技术可轻松得到细菌的蛋白质序列,因此先把若干已知阴阳性的细菌蛋白质序列组成序列数据库Seq-D,如表1中1条蛋白质短序列组成的序列数据库Seq-D所示(第1列为序列的ID,第2列为某细菌的蛋白质序列.示例中的序列由A、B、C,3种不同项(核酸或氨基酸)组成,长度为13.)然后挖掘Seq-D中的精简序列模式,找出细菌的革兰氏阴阳性判别的特征,并提出细菌的革兰氏阴阳性判别算法. 表1 含一个序列的数据库Seq-D样例Table 1 An example sequence database Seq-D 精简序列模式又分为频繁模式(FSP)、邻接序列模式(FConSP)、闭合邻接模式(FCloConSP)3种.若设定支持度σ为2,分别用上述3种模式对表1中的序列进行挖掘,结果如表2所示.其中第2列中,具体的模式项以及模式对应的支持度以“:”分隔,各模式项间用“,”分隔,其FSP有17个模式项,FConSP有7个模式项,而FCloConSP有5个,由以上结果可见,同一支持度下,FSP的模式项数目最多,FCloConSP的模式项数目最少. 由一般经验可知,3种序列模式中,所包含的模式项数目越多其保留的特征也越多,故应选择FSP来分析.但是从表2可看出FSP的模式项数目远大于其它两种模式,而表2所分析的序列只包含了3种氨基酸,长度只有13,实际的蛋白质序列的氨基酸可多达20种,一个序列长度可能长达上千.可想而知,选择FSP分析序列,后续的计算量巨大,这不是一种好的选择.因此,若能保证正确率的情况下,选择更精简和有效的模式,即性价比更高的序列模式,其处理时间短,更具有实用价值.故考虑从FConSP或FCloConSP产生的模式项中寻找特征完成判别.FConSP的数据量大于FCloConSP,若FCloConSP数据无法支撑准确性,则需考虑FConSP.若FConSP和FCloConSP均能保证准确性,则选择FCloConSP更优.本文经过大量实验,最终设计了使用FCloConSP模式的数据分析的判别算法. 表2 3种序列模式对比Table 2 Comparison of three sequential patterns GCBPS算法的流程图如图1所示. 该算法先对给定的已知阴阳性的序列数据库Seq-D进行数据预处理,将Seq-D中的序列处理为特定的数据结构(S.id,S),然后针对蛋白质序列分析的特点改进了闭合邻接模式的挖掘算法CCSpan,对训练集数据库中每条序列通过候选集生成、剪枝操作、闭合性筛选来挖掘FCloConSP,可以分别累计得到阴性的训练集闭合邻接模式特征集合和阳性的训练集闭合邻接模式特征集合.接着对阳性训练集特征集合进行标准化和向量化,得到阳性特征向量. 对待测蛋白质序列进行挖掘FConSP,得到待测邻接序列模式特征集合,再经过向量化处理得到待测序列特征向量.先计算待测向量与阳性特征向量的相似度,结果若在区间[0.8,1],则待测序列为阳性.若相似性结果不在此区间,则初步判定为阴性,其实这些序列并不一定全是阴性,还存在假阴性(阳性).因此,需进行去假阴性处理.经实验发现直接把待测序列向量与前述方法得出的阴性特征向量比对,其正确率受限,因此经过大量试验后修正了阴性特征库,即把原求出的阴性特征集中长度为2的模式项去掉作为修正的阴性特征集合,再进行标准化和向量化,得到阴性特征向量.将非阳性待测向量与阴性特征向量进行相似度计算,若相似性结果在区间[0.8,1],则为阴性序列,否则为阳性序列.由此可得出最终的阴阳性判定结果. 图1 GCBPS算法流程图Fig.1 GCBPS algorithm flowchart CCSpan算法[15]用于挖掘一个序列数据库的指定支持度模式集合,GCBPS算法中的序列模式挖掘部分引入了CCSpan算法的主要思想,与原CCSpan算法不同的是,GCBPS算法只挖掘单条序列的FCloConSP,更有利于保持源序列库中每条序列的特征.在取得Seq-D中每条序列的FCloConSP后,依次输入该序列数据库中的下一条序列继续挖掘,直至该序列数据库循环结束.此算法设计了以下几种特殊的数据结构,便于实验计算: 1.作为输入的序列数据库Seq-D由一个二元结构(S.id,S)组成,其中S.id为此序列的ID编号,S则为序列本身. 2.闭合邻接序列模式与非闭合邻接序列模式以一个三元结构组成(s,s.count,B),其中f表示模式,s.count表示该模式在序列数据库D上的频数,即实际支持度,而B中有两种值:“Y”代表模式闭合,“N”代表非闭合模式. 3.一条序列F可以分割成若干个不相交的子集合,即{{F1},{F2},…,{Fn}},其中n是最大的模式长度,F中每个子集仅仅包含单一长度(n)的模式. 本文通过以下3步来实现FCloConSP的挖掘: Step 1.取数据库Seq-D的每一个序列S(S.id,S)按照设定的切分长度切分成一系列的片段,这些片段中所有的项均保持原有的顺序和邻接属性.初始切分长度为2,当一轮切分片段结束后,再把上一轮切分长度+1进行下一轮切分,一直到切分长度等于原始序列长度时,切分结束.得到的片段为候选片段.此时切分序列产生的集合为{{F1},{F2},…,{Fn}},其中每个子片段为邻接序列模式,其结构为(s,s.count,B). Step 2.采用CCSpan算法中的剪枝方法(前后子序列剪枝、支持度剪枝)对Step 1产生的候选片段进行剪枝,删除已经出现过的片段和不满足支持度要求(s.count<σ)的片段.经剪枝后的候选片段仍为邻接序列模式. Step 3.对Step 2得到的邻接序列模式进行闭合性检查[15],则筛选出所有的非闭合邻接序列模式并标识即(s,s.count,B)中B标识为“N”,从而以B=“Y”可筛选出该序列的闭合邻接序列模式. Step 4.取数据库Seq-D中的下一条序列重复Step 1-Step 3得到该条序列的FCloConSP.将所有的上述序列的FCloConSP按照已知的阴阳性放入阴性特征库与阳性特征库.若阳性特征库内或阴性特征库内中有若干相同的模式项s时,则把s.count进行累加后合并为一个模式项.合并处理后每个模式项只出现1次.最终的结果就是阴性训练集特征库和阳性训练集特征库.记为: LCloConSPs=[s1:s1.count,s2:s2.count,s3:s3.count,…,sn:sn.count]. 为实现算法的软件编程,此部分设计了以下几个函数: 1)函数snip():作用为获得所有长度为1的频繁模式,该结果用于得到长度为2的频繁模式.在F1中每一个候选子序列实际支持度都不小于给定的阈值σ,其中每个模式都以三元组(s,s.count,Y)形式表示,标记Y为默认值. 2)函数ConSP-snip():其作用为存储当下长度的所有模式片段的Pn作为输入,以挖掘长度大于等于2的邻接序列模式.经过3步剪枝操作,Pn会不断更新已检测片段. 3)函数CloConSP-snip():其作用为得到最后所需的闭合邻接序列三元组.根据3.1定义中闭合邻接序列的定义进行闭合性检测,可得包含闭合模式与非闭合模式的集合. 4)函数Count-Patterns():最作用为统计由FCloConSP所产生的训练集合,其中LCloConSPs存储阴阳性训练集集合的FCloConSP. 4.2.1 相似度计算 余弦相似度[16]用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小.余弦值越接近1,表明夹角越接近0度,则两个个体越相似.余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感.所选用的公开数据集中革兰氏阴性菌的蛋白质序列数量远大于阳性菌的蛋白质序列数量,在实际中亦是如此,本文在基础的余弦相似度公式上增加了参数k,目的是在计算过程中,通过参数k对模式的频数进行筛选,过滤不必要的模式,降低了数据的计算时间复杂度,如公式(1)所示.经过大量的实验计算得出,当k为每组训练集中所有模式项的频数的中位数时,删掉频数小于k的模式项后的精简训练集集合参加判别更准确.在训练集中,与待测序列的邻接序列模式取交集(若训练集中无此模式,则频数置为0),并以模式频数构建向量,利用公式(1)可计算待测序列向量与该组阴(阳)性训练集的余弦相似度. (1) 其中x,y为待比较的两个向量. 4.2.2 阴阳性判别主要步骤 Step 1.统计得到阴阳性训练集特征库中的模式项频数的中位数k,并过滤阴阳性特征库中模式项频数小于k的模式项,即对LCloConSP中si.count≤k(1≤i≤n)的模式删除,从而进行标准化. Step 2.将标准化后的阳性训练集集合与待测序列取交集,若训练集中无此模式,则频数置为0,并以训练集集合以及待测序列集合中模式频数(si.count)分别向量化,即T=[s1.count,s2.count,s3.count;…,sn.count],利用公式(1)求得待测序列与阳性训练集向量的余弦相似度,结果若在[0.8,1]则判定为阳性. Step 3.得到第1步判别结果后,对于相似性结果在[0,0.8)的序列,会出现假阴性性状.因此先将阴性特征训练集集合删除模式长度为2的模式,然后进行Step 2中标准化以及向量化得到阴性训练集向量,最后利用公式(1)求得待测序列与阴性训练集向量的余弦相似度,结果若在[0.8,1]则判定为阴性,否则为阳性.综合两步判别结果得到最终待测序列的阴阳性. 此部分的主要函数为: 函数Cosin-S():用于对向量化后的训练集以k值进行标准化,并得到测试集与阴阳性训练集的余弦相似度Cosine_sim.其中,TN、TP为阴阳性训练集的向量,Ttest测试集中单条序列的向量. GCBPS算法主要由两部分组成:1)为阴阳性训练集与测试集模式集合挖掘;2)为测试序列与阴阳性训练集的相似性计算. 以下为GCBPS算法伪代码,其中:原始的序列数据库为Seq-D,最小支持度为σ.F存储所有的邻接序列模式,Fn存储长度为n的序列模式.F1存储模式长度为1的频繁模式.模式集合F= {s,s.count,B}|f.count≥σ}为所挖掘频繁模式的训练集集合.集合LCloConSPs={(s,s.count,B)|f.count≥σ}存储序列数据库中全部序列挖掘的FCloConSP.LTest={(s,s.count,B)|f.count≥σ}存储一条待测序列的FConSP集合.阴性训练集向量为TN,阳性训练集向量为TP,测试集向量为TTest. 算法GCBPS: 输入:由待测序列组成的序列数据库Seq-D,以及支持度 σ 输出:Seq-D中各序列的S.id与该序列革兰氏阴阳性判别结果 Begin: F←φ;//以F存储CloConSPs Fn←φ;//以Fn存储长度为n的ConSPs F1←snip//(Seq-D,σ)//获得1-sequences 1.for(n=2;Fn-1≠φ;n++)do 2.Pn←φ//以Pn存储当前切分长度片段 3.foreach sequence S ∈Seq-Dand l(S)≥ ndo 4.foreach con subsequence s ∈ S and l(s)= ndo 5. ConSP-snip(Seq-D,s,Fn-1,Pn,S.id,σ);//获得ConSPs 6.endfor 7.endfor 8.Fn-1←CloConSP-snip(Fn-1,Fn);//获得CloConSPs 9.F←∪n-1Fn-1; 10.endfor 11.LCloConSPs,LTest←Count-Patterns(F)//获得模式集合 12.TP←LCloConSPs//训练集集合向量化 13.TTest←LTest//测试序列模式集合向量化 14.Cosine_sim←Cosin-S(TP,Ttest)//相似度计算 15.ifCosine_sim ∈ [0.8,1]: 16. 待测序列为阳性 17.else:TN←删除LCloConSPs中长度为2的模式 18. Cosine_sim←Cosin-S(TN,Ttest) 19.ifCosine_sim∈[0.8,1]: 20. 待测序列为阴性 21.else:待测序列为阳性 End 为了验证GCBPS算法的准确性、可行性及优化性,设计和完成了以下两个实验. 论文选取蛋白质序列公开数据集PSORTb v3.0(1)https://www.psort.org/dataset/datasetv2.html.该数据集中包含1591条革兰氏阴性菌蛋白质序列和576条革兰氏阳性菌蛋白质序列.本文实验选取10折交叉验证,即1将数据集分成10组,轮流将其中9组做训练1组做验证,10次所得结果均值为算法精度的估计.本实验中,采用精准率P、召回率R、值F1-score作为实验的主要评价指标[17],计算方法如公式(2)-公式(4)所示.其中:TP:表示测试集中正确的把阴(阳)性菌预测为阴(阳)性的序列个数;FN:表示测试集中错误的把阴性菌预测为阳性的序列个数;FP:表示测试集中错误的把阳性菌预测为阴性的序列个数.F1值为综合度量准确率和召回率的指标. (2) (3) (4) 实验将数据集中的1591条革兰氏阴性菌蛋白质序列和576条革兰氏阳性菌蛋白质序列放入1个数据库中,再将数据集均匀分为10组,每组包含革兰氏阳性菌约57条,革兰氏阴性菌约159条,其中1组作为测试集,余下9组作为训练集,依次进行10组实验. 实验1.验证GCBPS算法的准确性与可行性 实验的步骤为: Step 1.取1组序列作为测试组,从中取1条未测序列作为待测序列,剩下9组数据序列,放入GCBPS的序列数据库Seq-D; Step 2.按GCBPS的方法判别出序列的阴阳性,即把数据带入事先编写好的算法程序运行得出结果; Step 3.记录算法得出的序列阴阳性结果与实际的阴阳性结果; Step 4.若测试组的序列未测试完,则重复Step 1-Step 3.若测试完,则计算该组评估指标(P、R、F1-score),并进入Step 5; Step 5.依次更换其余9组轮流作为测试组,重复Step 1-Step 4,得到10组的评估指标,并计算平均值,如表3所示. 用GCBPS算法对细菌进行革兰氏阴阳性判别结果的实验评价指标如表3所示.本实验在支持度σ=2 的条件下,分别从10组实验的精确率、召回率以及F1值来判断该算法的准确性及可行性. 表3 GCBPS算法10组实验评价指标Table 3 GCBPS algorithm 10 groups of experimental evaluation indicators F1是综合度量准确率和召回率的指标,由表3可看出第3组实验F1值最高为99.05%,10组的平均F1值为95.40%,所以GCBPS算法判别细菌的革兰氏阴阳性的结果较准确.因此可以得出:不进行生物实验,直接采用实现GCBPS算法的计算机软件进行细菌的革兰氏阴阳性判别方法是准确的和可行的. 实验2.验证GCBPS中选择FCloConSP的精简性与优化性 本组实验选取支持度σ=2,用FConSP替代GCBPS算法中对训练集进行特征提取的步骤,其余步骤相同,为以示区别,后称为GCBPS-X算法. 其实验步骤为: Step 1.按实验1的方法步骤并跳过5.1中的Step 3后运行; Step 2.记录GCBPS-X算法的评估结果; Step 3.统计GCBPS算法中产生的FCloConSP训练集特征库模式项的种类及个数. Step 4.统计GCBPS-X算法中产生的FConSP训练集特征库模式项的种类及个数. 由实验可得FConSP下的10组实验的评价指标由表4可见,图2-图4分别为GCBPS算法与GCBPS-X算法两种模式准确率、召回率、F1值对比. 由表3可知,GCBPS判别实验F1值均值为95.40%;由表4可知,GCBPS-X判别实验F1值均值为94.26%.因此,GCBPS算法比GCBPS-X算法综合准确率高.由图2可知有6组实验的准确率是GCBPS高于GCBPS-X;由图3可知有8组实验的召回率是GCBPS高于GCBPS-X;由图4可知有6组实验的F1值是GCBPS高于GCBPS-X,由此可见GCBPS比GCBPS-X的判别准确率更高. 表4 GCBPS-X算法10组实验评价指标Table 4 GCBPS-X algorithm 10 groups ofexperimental evaluation indicators 接下来进行两种算法中模式项的精简性对比.图5为革兰氏阴性菌GCBPS与GCBPS-X两种算法中模式项数目的对比图,其中横坐标为模式项的长度,纵坐标为模式项的数目.在阴性菌序列数据库中,FConSP共有130978个模式项,FCloConSP有11064个模式项,由此可见,FCloConSP的数目远远小于FConSP.由图5可以看出两条曲线在同一支持度下(σ = 2)呈下降趋势,FCloConSP的模式项主要集中在长度为3和4之间,分别占比46.74%与39.34%,而在FConSP中,长度为3与长度为4的模式仅占4.09%与4.88%.随着模式长度增长的同时,FCloConSP中模式长度较长的模式为0.相比而言,GCBPS中的FCloConSP更为精简. 图6为革兰氏阳性菌GCBPS与GCBPS-X两种算法中模式项数目的对比图,其中横坐标为模式项的长度,纵坐标为模式项的数目.在阳性菌576条序列数据库中,FConSP数目为203494条,而FCloConSP仅为3323条,由此可见,FCloConSP的数目远远小于FConSP.在FCloConSP中,长度为3和4的模式数目分别为1869与360,分别占比为56.24%与10.83%,而在FConSP中,模式长度为3和4的数目为2376与1841,分别占比为1.17%和0.90%.由此可见,在同一支持度下,FCloConSP的模式长度小于普通FConSP;FCloConSP集合大小远远小于FConSP集合. 实验结果表明,GCBPS算法选择FCloConSP进行序列特征分析,所处理的模式项数目更少,软件运行时间更短,准确性更高,其具有精简性和优化性的特点. 图2 算法准确率比较Fig.2 Comparison of algorithm precision 图3 算法召回率比较Fig.3 Comparison of algorithm recall 图4 算法F1值比较Fig.4 Comparison of algorithm F1 value 图5 革兰氏阴性菌特征集两种模式项数目对比Fig.5 Comparison of the number of two model items in the Gram-negative bacterial feature sct 图6 革兰氏阳性菌特征集两种模式项数目对比Fig.6 Comparison of the number of two model items in the Gram-positive bacterial feature set 本文首次提出的用计算机软件实现的GCBPS算法是细菌革兰氏阴阳性判别领域的创新方法.算法通过对已知阴阳性序列的挖掘和分析,提取出阴性和阳性序列的特征向量,再将待测未知阴阳性序列进行相似性判别,可得出阴阳性结果.该方法中的阴阳性特征向量可以通过不断增加数据库中已知阴阳性序列的数量来进行动态更新,从而可持续提高判别准确性.为了缩短判别时间,也可事先运行软件的训练集训练部分,判别时直接运行待测序列与前述的训练结果比对判别的部分即可. 在未来的工作中,将进一步优化序列特征提取时所选用的模式,尽可能减少丢失的特征,提高判别准确性和缩短计算时间.以后还将尝试把GCBPS算法用于亚细胞的定位.3.2 问题陈述


4 GCBPS算法
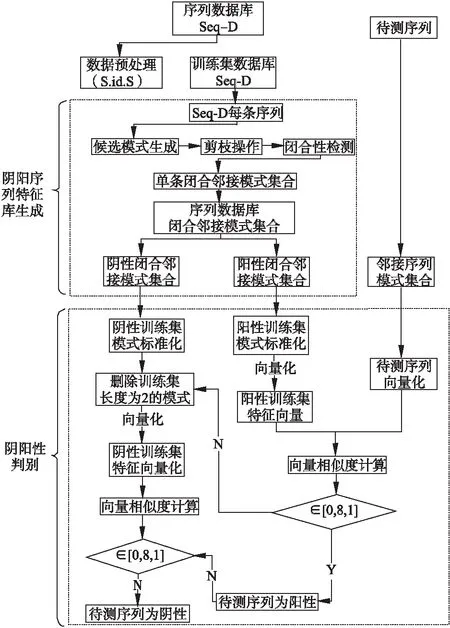
4.1 阴阳序列特征库生成
4.2 阴阳相似性判别
4.3 算法过程
5 实 验
5.1 实验设置
5.2 实验及结果分析
6 总 结
猜你喜欢
安徽农业科学(2022年9期)2022-05-17
中国典型病例大全(2022年12期)2022-05-13
祝您健康·文摘版(2021年8期)2021-08-10
环球时报(2018-06-14)2018-06-14
科学种养(2017年9期)2017-09-12
旅游(2016年12期)2017-05-09
数学学习与研究(2016年21期)2017-05-08
现代养生·上半月(2016年7期)2016-05-14
