
GAN 图像对抗样本生成方法
2021-04-11 12:49王曙燕孙家泽
计算机与生活 2021年4期
王曙燕,金 航,孙家泽
西安邮电大学计算机学院,西安 710121
深度学习模型的工作机理是依赖人类筛选和准备的训练样例,基于多层非线性变换来准确刻画和记忆数据,距离多领域通用的“强人工智能”还有较大差距[1]。因此大多数研究者更加关注模型的性能和训练效率,却忽略了模型的安全性和鲁棒性[2]。随着深度学习系统在自动驾驶[3]、图像识别[4]等领域应用越来越广泛,其安全性问题也受到广泛的关注。特别是医疗、航空航天等对精度要求较高的场景下,提升模型的稳定性和鲁棒性占据相当多的资源与时间。在这种背景下,对抗样本的相关研究越来越火热,对抗样本是一种能够欺骗模型做出错误判断的一类样本,能够触发深度学习模型的缺陷,从而指导模型进化。
“对抗样本”这一概念最早由Szegedy 等[5]提出,通过在数据集中加入微小扰动得到新的样本,使得深度学习模型以较高的置信度得到错误的分类,随后Szegedy 研究发现通过对抗训练,即将对抗样本加入原始数据集来训练模型可以提高模型的鲁棒性。在此之后,产生对抗样本的方法层出不穷,主要可以分为两大类:快速梯度符号标记法[6]和基于优化的方法[7]。Goodfellow 等[8]在2014 年解释了对抗样本的基本原理,证明了神经网络模型的高维线性是导致模型能够被对抗样本所欺骗的根本原因,而不是传统所认为的模型的高维非线性,同时还提出了一种基于梯度下降原理的对抗样本生成方法:快速梯度符号法(fast gradient sign method,FGSM)。通过在梯度上添加增量来使模型对样本做出误分类。Papernot等[9]提出一种针对于深度神经网络类型的对抗样本生成方法JSMA。该方法使用网络中的功能函数Jacobian 矩阵来生成前向导数,并利用前向导数来具体实现。JSMA 算法提出限制扰动的l0范数来产生对抗性攻击,也就是每次只修改目标图像的几个像素,并通过由前向导数计算生成的一个显著性图来执行监控,取使得所有显著值最大的输入特征来调整样本,与原来的值相减以后得到干扰值。前向导数使用网络模型的导数而非代价函数,且更多地依赖输入数据的特征而非网络参数,因此可以得到更好的输出结果。Carlini 和Wagner[10]在总结了LBFGS、FGSM 和JSMA 几个对抗样本生成的方法之后,提出了在范数L0、L2和L∞上均有较大改善的算法C&W attacks。此算法是前边三种算法的扩展,在白盒测试[11]和黑盒测试[11]的攻击方式下都适用,在不知道模型层参数的条件下,依然能够误导模型做出错误判断。
上述方法都是通过向原始样本集注入噪声来生成对抗样本,对抗样本的数量受限于原始样本集的规模,且对于同一个样本、同一个目标网络只能得到唯一与之相对应的噪声,以至于所得的对抗样本缺乏多样性。针对上述方法的问题,本文提出了一种基于GAN 的图像对抗样本生成方法,与现有图像对抗样本生成方法相比,本文在以下两方面提出创新:
(1)在样本生成方面,采用双生成器的构造策略,生成器G1 用于模拟原始样本集的分布,增强最终生成的对抗样本的差异性,提高样本多样性;生成器G2 用于产生噪声,保证对抗样本的攻击成功率。
(2)在黑盒攻击模式下,对目标黑盒模型引入模型蒸馏技术得到其本地复制,再利用传统的白盒攻击方式进行攻击,这种方式较少地依赖对抗样本的转移性,在保证样本多样性的同时进一步提升黑盒攻击模式下的攻击成功率。
1 生成对抗神经网络
1.1 生成对抗神经网络相关研究
生成对抗网络(generative adversarial network,GAN)是由Goodfellow 等人在2014 年提出的一种无监督学习算法框架[12],其算法思想受启发于二人零和博弈理论。GAN 的网络结构由生成器和判别器两部分组成,模型结构如图1 所示。
其中,生成器G的输入为高维随机噪声z,输出为虚假样本数据G(z),生成器G的作用是模拟真实样本的数据分布;判别器D的输入为真实样本集和虚假样本数据,输出通常是输入数据为真的概率,理想状态下,判别器D输出的概率值为0.5,即整个系统达到纳什均衡状态,此时生成器G生成的数据使判别器D难分真假,模型达到最优。GAN 的目标函数定义为:

Fig.1 GAN architecture diagram图1 GAN 架构图
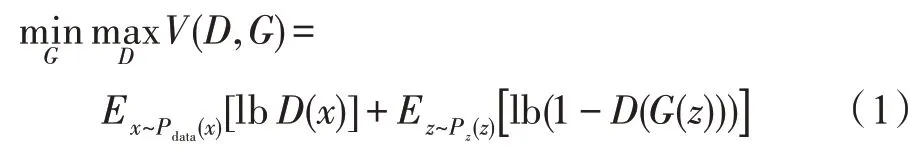
其中,Pdata表示真实数据的分布,Pz表示原始噪音的分布,E指期望值。一般是通过先固定G来最大化V(D,G)得到D,然后固定D并最小化V(D,G)得到G,如此迭代直到整个模型达到预定目标。GAN 以其独特的对抗性思维和优秀的表现,成为近几年深度学习的热点课题,被广泛应用于机器学习、语音识别、数据扩增和计算机视觉等场景,并产生了一系列衍生模型。CGAN(conditional GAN)[13]在原始GAN 基础上增加了约束条件,控制了生成器G过于自由的问题,使得网络能够朝着预期方向生成样本。LAPGAN[14]基于CGAN 进行改进,用来生成高品质图片。该方法创新地将图像处理领域中高斯金字塔[15]和拉普拉斯金字塔[16]的概念引入GAN,利用高斯金字塔进行下采样,拉普拉斯金字塔进行上采样来重建图像,改善了GAN 的学习能力和生成图片的质量。DCGAN(deep convolutional GAN)[17]将卷积神经网络和GAN 结合在一起,使得生成图像的质量和多样性得到了提升,对GAN 的发展有着极大的推动作用。InfoGAN[18]是Chen 等提出的一种衍生GAN 模型,其最大的特点是增加了互信息(mutual information,MI)的判断部分,通过最大化GAN 噪声变量子集和观测值之间的互信息,以实现对学习过程的可解释性。他们将输入的噪声数据分成两部分,一部分记为z代表随机噪声,另一部分是可解释的有隐含意义的信号c。其中c代表的是图像的光照、倾斜度或者具体的类别等语意特征信息。在以MNIST 数据集训练的模型中,信号c可以分为label code来代表数字种类信息(0~9),以及feature code来表示倾斜度、笔画粗细等。
从以上的研究基础中可以看出,GAN 在计算机视觉领域具有相当的优势,在图像超分辨率、图像数据库扩充和图像对抗样本方面具有重要的应用价值。在生成对抗样本的应用中,刘二虎等[19]提出一种衍生对抗样本生成方法,该方法利用FGSM 法构造的对抗样本作为输入,训练一个GAN 模型,使得生成器G能够模拟对抗样本的分布,扩充了对抗样本的规模,但攻击成功率较低,只有30%左右。Xiao 等提出一种AdvGAN 网络架构来生成对抗样本[20],在该方法中一旦架构中的生成器G训练完毕,对于任意输入图像都能高效生成所对应的扰动,提高了攻击成功率,但该方法中针对一个样本的输入,只能生成相对应的一个扰动,限制了对抗样本的数量,虽然攻击成功率高但是样本数量少、样本多样性低。
1.2 样本多样性提升方法
GAN 在图像数据扩充方面的优秀表现,启发出通过生成器模拟原始样本集的分布,扩展样本规模和样本之间的差异性的方法。以InfoGAN 为框架构造生成器G1,用以生成指定类别的图像。将随机隐含信号c进行初始化,信号c是一个长度为40 的列表,用以控制最终所生成图像的倾斜角度、笔画粗细等图像风格,图像风格的随机性导致最终样本的表现差异巨大,以此来提升最终对抗样本在主客观层面的差异性和多样性。再将目标类别y转化成one_hot 类型编码并与之拼接,目标类别y控制最终生成图像的类别,两者共同组成生成器的输入信号z。利用互信息对c进行约束,z与G(z,c)具有高度的相关性,优化的目标函数如下式:
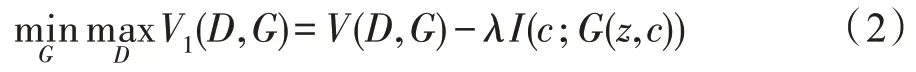
实际上,互信息项λI(c;G(z,c))很难直接被最大化,因为需要先获取后验概率项P(c|x)。为了解决这个问题,引入一个辅助定义Q(c|x) 的下确界来逼近P(c|x),于是目标函数被重新定义为如下形式,λ为超参数:
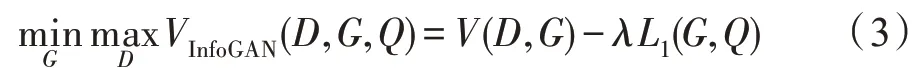
在此基础上构造基于转置卷积的样本生成器G1,最终输出目标图像。
1.3 扰动生成器构造方法
图2 描述了利用GAN 生成样本噪音的流程。构造扰动生成器G2,其输入为某一样本,有目标攻击下还需输入目标类别,输出为该样本所对应的扰动,可对目标模型进行半白盒和黑盒攻击。主要包含三部分:对抗噪声生成器G2、判别器D和目标网络f。G2 接受一个图像实例x并生成所对应的扰动G2(x),对抗样本由G2(x)+x构成。判别器D的作用是引导G2 的训练过程,最小化其损失值LGAN保证所生成的对抗样本的真实性,同时在扰动系数的限制下尽可能减小噪声。LGAN的定义如下:

Fig.2 AdvGAN architecture diagram图2 AdvGAN 架构图
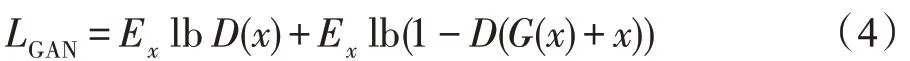
目标网络f用以检验对抗样本在攻击过程中的效果,最小化其损失值Ladv可以使对抗样本在攻击过程中的结果更接近于本文的期望。Ladv的定义如下:

其中,lf表示目标模型f的损失函数,在有目标攻击中,t为攻击目标,最小化Ladv可以使对抗样本在攻击过程中的结果更接近本文的期望;在无目标攻击中,t为样本的真实类别,最大化Ladv可以使对抗样本在攻击过程中的结果无限远离真实结果。
综合以上对于LGAN和Ladv的操作,通过反向传播修改G2 的模型参数,使得G2 能够以尽可能小的噪声代价生成尽可能符合预期的扰动。
2 模型蒸馏
模型蒸馏是模型压缩和加速的技术之一,将教师网络的知识迁移到学生网络上,使得学生网络能够以较小的规模和计算成本得到与教师网络相当的性能表现。Caruana 等首次提出知识迁移(knowledge transfer,KT)[21],借助模型的输出软标签训练一个压缩后的小型网络,该小型网络能够得到与原网络相近的输出结果,但这种方法只能对浅层网络进行压缩。Ba 等提出知识蒸馏(knowledge distillation,KD)的概念[22],将一个层数宽且深的模型压缩为一个小型网络模型,该模型能够模拟原始模型的输出,且具有较好的性能。Hinton等介绍了模型蒸馏的流程[23],将包含多个神经网络的集成模型压缩为一个层数相同的学生网络,Hinton 等以手写数字和语音识别作为实验对象,证实了蒸馏模型的确能够达到如教师网络的泛化能力。Romero 等提出了FitNet方法[24],同时使用教师网络的标签输出和中间隐藏层的参数值来训练学生网络,学生网络具有与教师网络相同的层数,但约减了层的宽度,得到一个深且窄的轻型模型,该方法得到的学生网络性能足以媲美教师网络且参数量和计算开支远远小于教师网络,但是FitNet方法由于假设性过强,在有些情况下甚至会对网络的收敛性和性能起到反作用。
2.1 神经网络模型的攻击方式
2017 年Kaggle 组织的NIPS 大赛将对抗样本分为目标针对性和非目标针对性[25]。目标针对性又称有目标攻击,指的是对抗样本可以使目标模型给出所期望的分类结果;非目标针对性又称无目标攻击,指的是对抗样本只需使模型给出错误的分类结果即可,不需指定某个特殊分类目标。同时,对抗样本的攻击方式也可分为黑盒攻击和白盒攻击[11]。黑盒攻击将目标模型看作一个不知道内部结构和层次属性的黑盒子,只能通过给出的I/O 接口进行查询的攻击方式;白盒攻击则是指在已知目标模型的内部结构和参数,可以通过对样本进行针对性的调整的攻击方式。在实际应用中,模型的内部结构和参数往往难以获得,因此黑盒攻击的场景较为常见,对黑盒攻击的研究也更具有价值。
2.2 基于模型蒸馏的黑盒攻击方式
传统黑盒攻击方式通过观察神经网络的决策结果,利用查询的方式来生成对抗样本。本文提出将模型蒸馏技术应用于深度神经网络的黑盒攻击,使用模型蒸馏技术获取目标模型的本地复制,然后使用与白盒攻击相同的攻击方式对蒸馏模型进行攻击。首先根据实验场景构建目标黑盒模型b的蒸馏模型f,对于模型b和模型f来说,要使得模型蒸馏过程中的目标函数最小化,目标函数表示为:
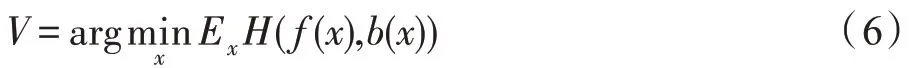
其中,f(x)和b(x)分别代表同一张图像在蒸馏模型和黑盒模型的输出结果,H代表交叉熵损失,最小化此函数使得模型f的输出结果逐渐逼近模型b,两个模型的某些关键权值向量能够逐渐吻合。相较于传统利用对抗样本转移性的黑盒攻击方式,蒸馏模型能够显著提高黑盒攻击方式下的攻击成功率。
3 实验及结果分析
首先介绍双生成器GAN 的构造框架,然后在此基础上开展实验。
3.1 GAN 对抗样本构造框架
GAN 生成对抗样本的框架如图3 所示,整个过程可以分为以下几步:
(1)使用原始样本集训练一个样本生成器G1,G1 为生成图像的InfoGAN 架构,用于模拟原始样本分布。
(2)构造n个扰动生成器AdvGAN0至AdvGANn,n为数据集的类别个数。每一个扰动生成器的输入为G1 输出的图像数据,分别用于有目标攻击情况下生成对应目标的扰动。例如AdvGAN0用于生成目标指向为label[0]的扰动。
(3)使用G1 生成1 000 张类别label[0]的图片,记为Φ0;生成1 000 张类别label[1]的图片记为Φ1;…以此类推,生成一组ΦN图片集合,其中N∈[0,n]。
(4)将Φ0~Φn作为输入,分别输入到AdvGAN0,得到Φ0~Φn所对应的、有目标攻击指向label[0]的扰动,排除Φ0攻击自身label[0]类的数据,最终得到Φ1→0,Φ2→0,…,Φn→0共(n-1)组扰动;以此类推可得到所有ΦN的扰动ΦN→M,其中N≠M,N∈[0,n],M∈[0,n]。
(5)将Φn与Φn→m对应相加并将图片规范化处理之后,即可得到原始样本类别为label[n],攻击目标为label[m]的有目标攻击对抗样本ψN→M,其中N≠M,N∈[0,n],M∈[0,n]。

Fig.3 Adversarial examples structure图3 对抗样本构造框架
3.2 黑盒模型的模型蒸馏
模型蒸馏进行黑盒攻击,主要是使学生网络拟合教师网络关键层的权值向量,较少依赖对抗样本的转移性,表1 展示了利用模型蒸馏技术进行黑盒攻击与传统方式的差异。首先训练深度神经网络MD、卷积神经网络MC和一个对照的黑盒网络MB,其模型的准确率在MNIST 数据集下分别是98.51%、98.93%和98.69%,对于MD和MC采用模型蒸馏法进行黑盒攻击,对于MB采用传统基于查询的方式进行黑盒攻击,采用本文对抗样本构造方法各自生成对抗样本,分别记为AdvD、AdvC和AdvB,然后分别使用所生成的三个对抗样本集来攻击三个模型。可以看出,利用蒸馏模型进行黑盒攻击,模型准确率大幅下降为1.19%和0.66%,而传统基于查询的方式进行黑盒攻击,模型仍可保持13.51%的准确率,这说明蒸馏模型能够提高黑盒攻击下的攻击成功率。同时,AdvD能够在MD上保持较高的成功率,但对MC几乎没有造成影响,同样AdvC也有类似表现,说明模型蒸馏技术进行黑盒攻击并不依赖对抗样本的转移性,这与传统黑盒攻击方式具有本质区别。
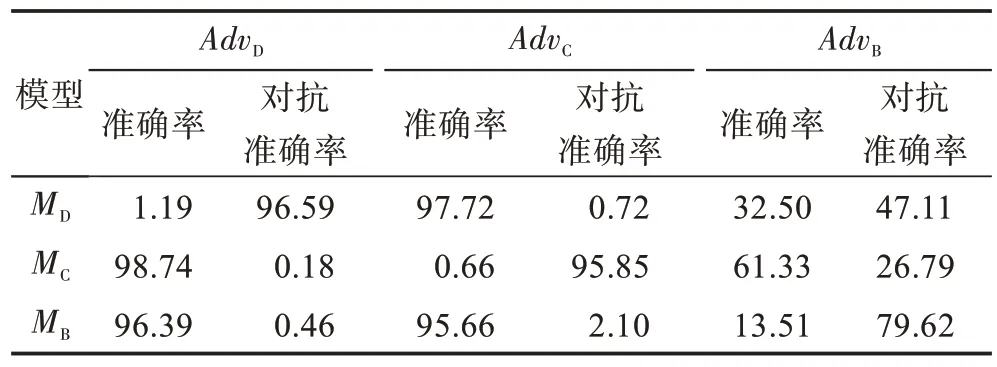
Table 1 Comparison of model distillation black box attack表1 模型蒸馏黑盒攻击对比%
3.3 样本生成器G1
在MNIST 数据集和CIFAR10 数据集下开展实验。实现训练四个神经网络模型,作为实验的攻击对象,这四个模型的层次架构和在MNIST 上的识别准确度如表2。
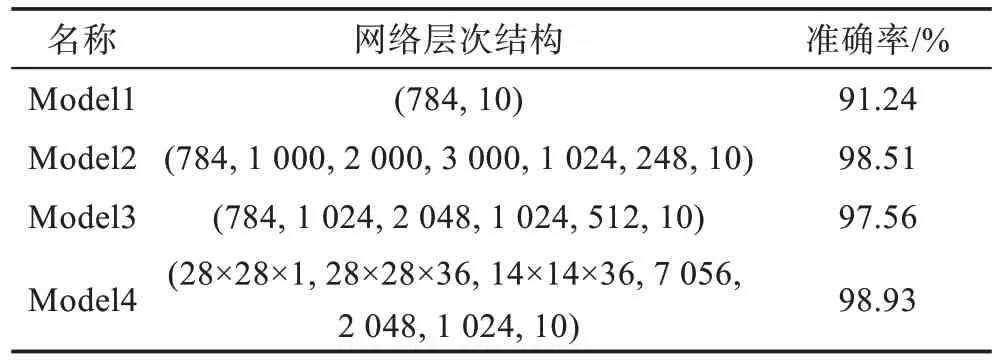
Table 2 Preset target network structure and accuracy表2 预设目标网络的架构及准确率
样本生成器G1 在训练阶段的输入为数据集和对应的类别,在应用阶段只需输入类别即可生成相对应的图像。生成系统训练过程采用Adam 优化器,Softmax 函数作为激活函数,训练400 次,生成器和判别器的损失函数如图4 所示,模型在训练200 次左右已经相对稳定。

Fig.4 GAN model loss function value图4 GAN 模型损失函数值

Fig.5 Simulated sample examples图5 模拟样本图示

Fig.6 Simulation sample recognition success rate图6 模拟样本识别成功率
模型训练完毕后,生成如图5 所示的样本,同时为了检测G1的生成样本在模型中的表现,将生成样本通过预设的4个模型,得到的识别准确率如图6所示。从图中可以看出,G1 能够模拟原始样本的分布,且相较于原始样本集生成的数据更加规范,排除原始样本集异常数据影响,使得模型的识别准确率反而更高。
3.4 扰动生成器G2
G2 的输入为模拟样本,输出为其所对应的扰动。G2 训练过程使用Adam 优化器,还需调整扰动系数λt。扰动系数控制噪声的大小,如式(7)所示:
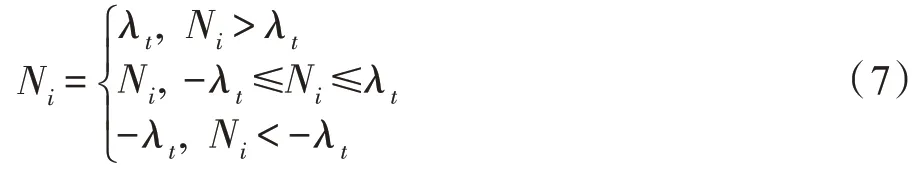
其中,N代表G2 生成的数组形式的扰动数据,像素值转换为双精度型,范围在(-1,1)之间。扰动系数限制了噪声的动态范围,对模型的影响如图7 所示。可以看出随着扰动系数的增大,模型的准确率(acc)下降,对抗准确率(adv_acc)上升,但是过大的扰动系数会导致图像失真,经过实验,选取扰动系数为0.2 时,在保证图像质量的同时拥有较高的攻击成功率。将得到的扰动数据与输入图像合并,并将图像的灰度范围规范化为(0,255)之间,得到最终对抗样本。对抗样本在模型上的表现如表3 所示,其中Model1~Model4 是上文提到的MNIST 数据集下的模型,Model5 是CIFAR10 数据集下的卷积神经网络模型,其模型准确度为78.06%。由表可知,最终生成的对抗样本能够以平均98.07%的致错率触发模型的缺陷,同时平均对抗准确率保持在96.75%。
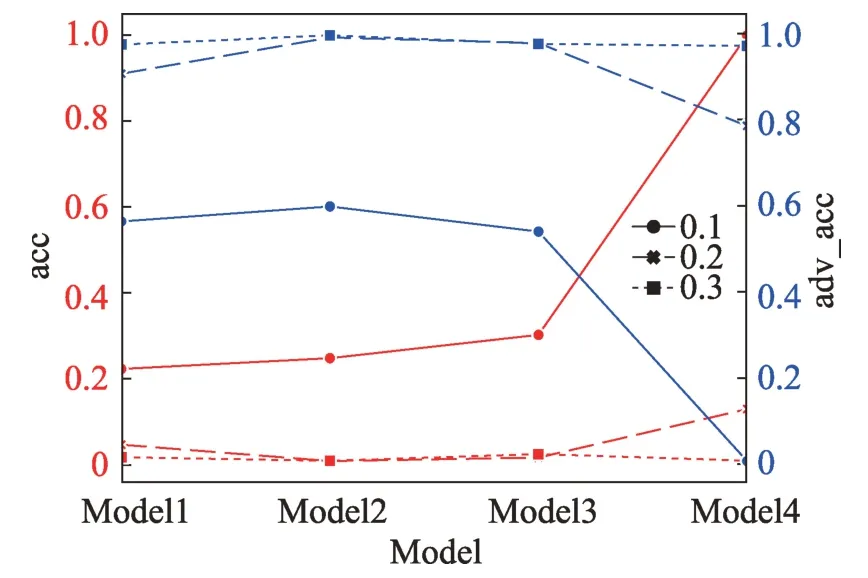
Fig.7 Influence of disturbance coefficient on model accuracy图7 扰动系数对模型准确度的影响
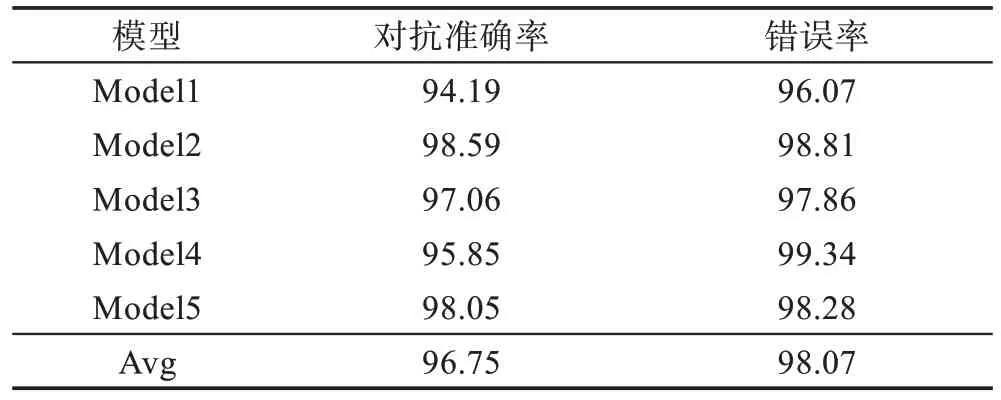
Table 3 Accuracy against sample attacks表3 对抗样本攻击准确率%
由于G2 的训练过程要不断对蒸馏模型进行白盒访问,且蒸馏模型的关键层权值向量与原始模型高度吻合,因此G2 所生成的扰动极大地迎合原始模型的“口味”,诱导模型做出期望的判别结果,因此会出现对抗准确率比模型原始准确率高的现象。
3.5 样本多样性分析
相较于传统基于AdvGAN 模型生成对抗样本,本实验通过样本生成器G1 动态地生成样本来供扰动生成器G2 训练和生成对应扰动,能够有效提高最终生成的对抗样本的多样性。实验使用原始方式和本文方法分别生成1 000 份数据,每一份都是相同输入条件下所产生的两个对抗样本。图8(a)所示为样本间SSIM(structure similarity)指数,SSIM[26]是一种衡量数字图像主观感受的一种方法,在设计上考虑了人眼的视觉特性,分别从结构、亮度和对比度三个角度度量图片的相似性。SSIM 值范围在[0,1],与图像间相似度成正比,本文方法所生成的样本SSIM 指数分布明显较原始方式更靠下,而原始方式数据则聚集在1.0 附近,平均SSIM 值降低了50.7%,在视觉层面提升了多样性。图8(b)展示了基于互信息的图像相似性指标,互信息(mutual information,MI)是信息论中的重要概念,描述了两个系统之间相互包含信息的多少即二者之间相关性,在图像匹配中,两幅图像的互信息是通过熵以及联合熵来反映它们之间信息的相互包含程度,对于图像F、R来说,它们之间互信息值表示为:

当两幅图像相似度越高,其联合熵越小,互信息就越大,因此互信息与图像相似性成正比,图示平均MI 值降低了10.96%,样本像素之间相互包含程度降低,多样性更高。图8(c)展示了样本的Cosin 相似度,该方法将图像表示为一个向量,计算两个向量之间的余弦值来表征图片间相似度,直观结果较SSIM法有所提升,与图像相似度成反比,图示实验结果表明本文方法Cosin值分布较为靠下,平均Cosin值降低了28.7%。图8(d)展示了样本间MSE(mean squared error)指数,MSE 均方误差值越小,代表两张图像越相似,MSE 表示为:

Fig.8 Violin plot of adversarial sample difference values图8 对抗样本差异值小提琴图
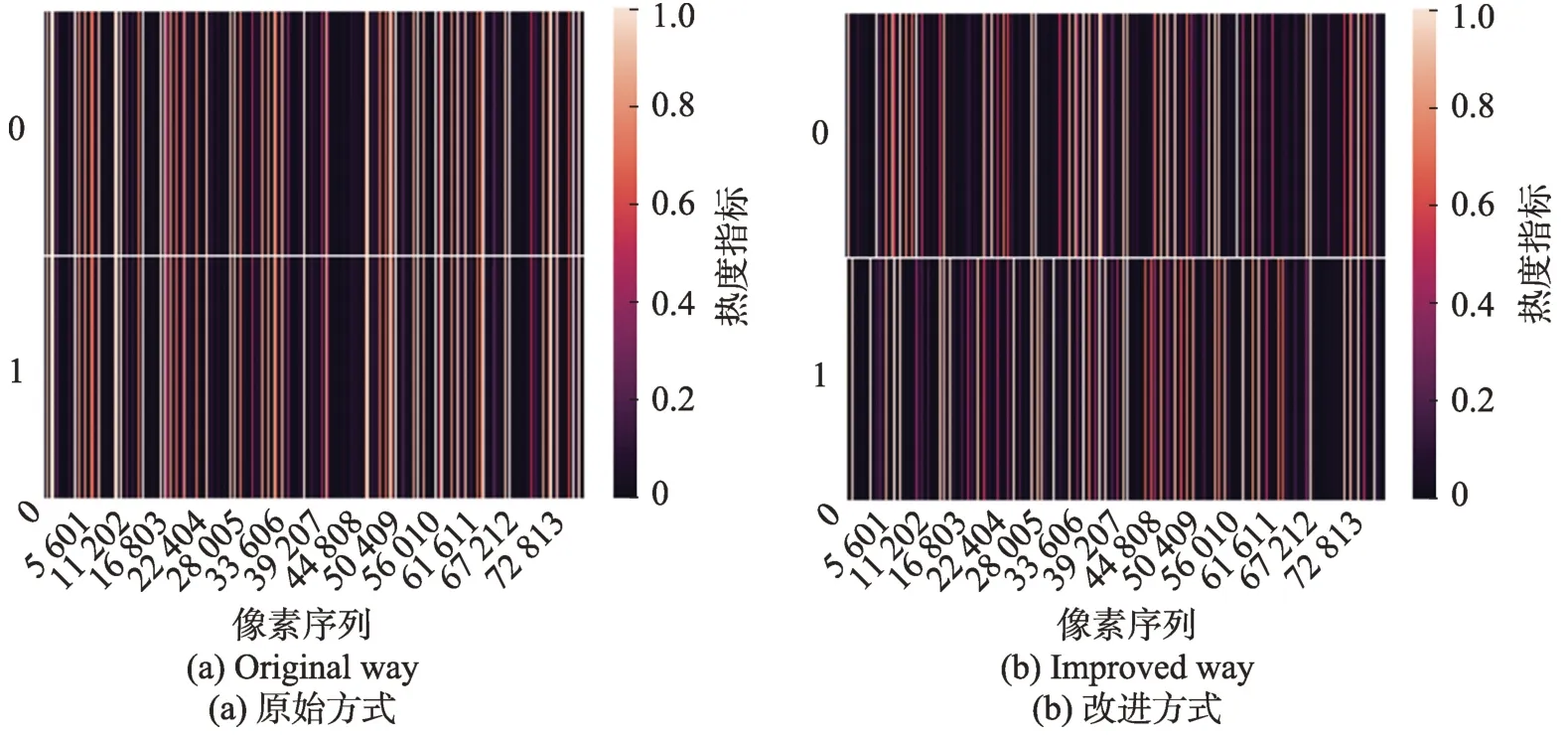
Fig.9 Comparison of adversarial examples heatmap图9 对抗样本热力图对比
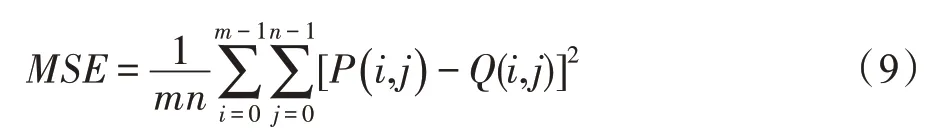
其中,m和n分别表示图像的宽和高,P和Q表示两张图片对应的像素值,MSE 值的取值范围为[0,1],与图像间相似度成反比。图示原始方法样本的MSE 值聚集于0,本文方法样本MSE 值分布均衡,平均MSE值提升了7.6%,像素间差异大,样本整体多样性提高。
热力图(heatmap)能够反映数据表中多个特征的两两相似度,在图像领域,热力图能够被用来反映图像间差异。首先使用传统方式和本文方法分别生成100 组对抗样本,每组对抗样本包含两份相同输入条件下产生的两个样本,然后将图像伸展成一维数组并组合,分别构造成一个二维的图像向量。图9(a)展示了传统AdvGAN 构造的对抗样本的热力图,上下分别表示对于同一个输入所生成的两个对抗样本,不同对抗样本热力图重合度高,图像间差异不明显。图9(b)展示了本文方法生成的对抗样本的热力图,可以看出即使在相同的输入条件下,本文方法构造的对抗样本依然具有较高的多样性。
图像指纹也被称为图像Hash,可用于检测图像间相似程度[27]。图像Hash 是检测一张图片的内容,然后计算出该图像所对应的唯一值的过程,不同于传统Hash 算法之处在于:图像的微小差异并不会生成差异巨大的Hash 值,相反相似图像的Hash 值也相似。本文通过均值散列(average Hashing)、感知散列(perception Hashing)、梯度散列(gradient Hashing)和离散小波散列(wavelet Hashing)四种方式来计算图像指纹,在得到图像之后再计算其汉明距离(Hamming distance)判断其相似度。实验采用传统AdvGAN 和本文方法在相同输入条件下生成1 000 组样本,结果如表4 所示,感知哈希法其汉明距离提升3 653.32,平均散列法汉明距离提升871.90,差值散列法海明距离提升2 042.61,离散小波散列法汉明距离提升1 331.35,四种方式平均海明距离提升1 974.80。实验结果表明本文方法相较于原始方案,能够显著提升图像的多样性。

Table 4 Image fingerprint Hamming distance表4 图像指纹汉明距离
4 结束语
神经网络模型的安全性和鲁棒性已经受到越来越多的关注,利用对抗样本触发模型缺陷是一种有效的模型检测方法。本文提出一种具有双生成器的GAN 图像对抗样本生成方法,提升了对抗样本的多样性,使其在攻击过程中能够更好地触发模型的缺陷;在黑盒攻击情境中,提出基于模型蒸馏技术的黑盒攻击方法,有效提升了黑盒攻击的攻击成功率。在未来的工作中,如何将两个生成器模型约减成一个整体是一个研究难点,同时对于GAN 生成的对抗样本,如何对模型进行对抗训练提升模型鲁棒性是下一步继续研究的方向。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
上海师范大学学报·自然科学版(2022年3期)2022-07-11
汽车实用技术(2022年5期)2022-04-02
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年7期)2021-08-13
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
软件(2017年6期)2017-09-23
数学学习与研究(2017年3期)2017-03-09
