
机器视觉应用中的图像数据增广综述
2021-04-11 12:48林成创赵淦森杨志荣陈少洁黄润桦李壮伟易序晟杜嘉华李双印罗浩宇樊小毛陈冰川
计算机与生活 2021年4期
林成创,单 纯,赵淦森+,杨志荣,彭 璟,陈少洁,黄润桦,李壮伟,易序晟,杜嘉华,李双印,罗浩宇,樊小毛,陈冰川
1.华南师范大学计算机学院,广州 510631
2.广东技术师范大学电子与信息学院,广州 510665
3.挪威科技大学,挪威特隆赫姆17491
4.广州市云计算安全与测评技术重点实验室,广州 510631
5.华南师范大学唯链区块链技术与应用联合实验室,广州 510631
6.广东财经大学统计与数学学院,广州 510320
机器视觉中的图像处理是人工智能的一个重要的研究领域,包括图像分类、语义分割、对象分割和目标检测等应用[1-3]。现阶段,随着硬件设施的不断完善和深度学习[4]技术的提出以及不断发展,基于深度学习的图像分类方法也日新月异。自Alex 等学者将深度卷积网络AlexNet[5]应用在图像分类中并取得远比其他传统图像分类方法更低的错误率后,基于深度学习的图像处理解决方案成为主流。随后,新的深度学习网络结构,如NiN[6]、VGG[7]、ReNet[8]、GoogLeNet[9]、ResNet[10]、InceptionNet[11-12]、MobileNet[13-15]、DenseNet[16]、EfficientNet[17]、ResNeXt[18]和ResNeSt[19]等网络结构被不断地提出并在不同的图像应用场景大放异彩。
深度学习在计算机视觉领域取得的巨大成功,主要归功于三大因素[1,20-21]:(1)强大的深度学习模型的表达容量;(2)不断增大的可获得算力;(3)大规模可获得的标注数据集。为了促进深度学习在不同的图像处理领域的发展,数以万计的不同类型的图像数据被收集、标注和公开应用,其中最著名的是ImageNet[22]。按照图像应用场景和图像类型进行划分,现有数据集可以从图像的类型上分成2D 数据集、2.5D 数据集和3D 数据集[22-40],覆盖了图像分类、语义切割、对象分割和自动驾驶等各个应用,极大地促进了深度学习图像技术的发展。尽管如此,对于各种专业领域的深度学习图像应用,缺少合格的领域图像数据仍然是一个不争的事实,尤其是在医疗图像处理[41-42]、AI农业[43-44]等领域。
He等学者[45]指出自2012 年AlexNet[5]首次使用深度神经网络进行图像分类并获得比其他传统图像处理方法更好的效果以来到NASNet-A[46]的提出,Image-Net 的Top-1 分类准确率已经从62.5%提升到82.7%。同时作者也指出这些成就的取得,不仅仅归功于网络模型的设计和优化,包括图像增广在内的多种优化方案和训练技巧也同样非常重要。
图像增广是在有效训练数据受限的情况下解决深度学习模型训练问题的一种有效方法。大量的增广技术和方法被提出来丰富和增广训练数据集,提升神经网络的泛化能力。常见的图像增广方法主要基于图像变换,例如光度变化、翻转、旋转、抖动和模糊等[1,41,47-48]。随着深度学习中神经网络的层数不断扩大,表达能力的不断提升,为了能够更好防止模型过拟合,出现了以mixup[49]为代表的合成样本图像增广方法[50-57]和使用生成对抗网络(generative adversarial nets,GANs)[58]为代表的虚拟图像样本生成的图像增广方法[59-63]等。在不同应用数据集和应用场景下,图像增广的策略和方法也不尽相同。因此,为了在特定的图像数据集和应用场景中找到最佳的图像增广策略,出现了基于算法或模型进行增广策略搜索的智能图像增广相关研究。例如,Fawzi 等学者[64]提出了自适应图像增广,Cubuk 等学者[47]提出了基于循环神经网络的自动增广框架。除此以外,还有更多的研究[65-71]在探索智能或者自动化的图像增广技术。
当前,图像增广的研究层出不穷,各种新方法和新思路不断地被提出来用于增广训练图像数据集。在层出不穷的图像增广研究中把握住图像增广的范式,对现有图像增广研究进行分门别类,对于引导研究人员针对不同的视觉应用找到合适的图像增广方法以及启发新的图像增广研究是非常重要的。
本文从图像增广的对象、操作的空间、图像标签的处理方式和图像增广策略的调优方式四个维度出发,归纳出现有图像增广研究的主要内容,如图1所示。
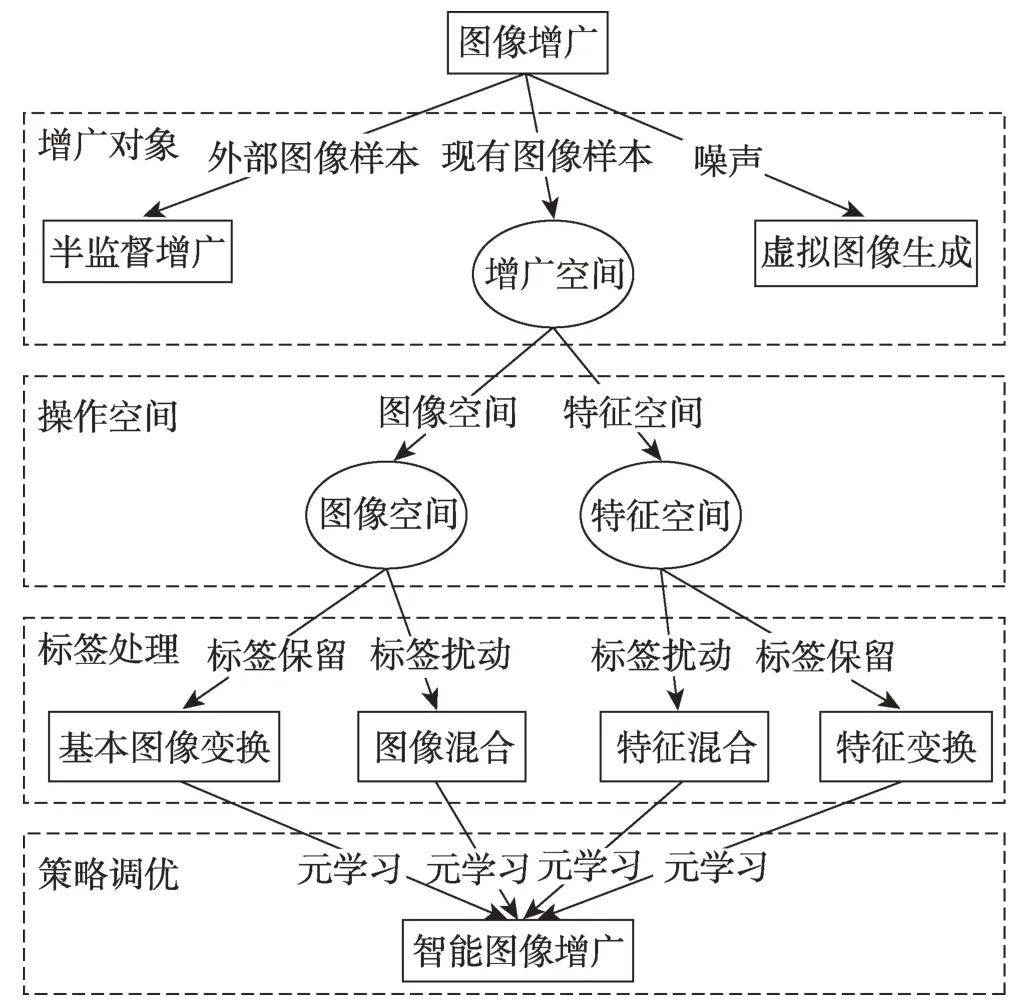
Fig.1 Main research contents of image augmentation under deep learning图1 深度学习下图像增广的主要研究内容
首先,本文根据图像增广的对象不同分成引入外部图像的半监督增广,从噪声生成虚拟图像样本的虚拟图像生成增广,以及面向图像训练数据集操作的图像增广。其次,本文从增广操作的空间上,区别直接在图像空间(raw image)进行增广以及在图像通过模型转换到隐空间(latent space)增广。根据图像增广过程中是否需要考虑图像标注信息以及增广后产生的新样本或者新样本特征的标签是否出现扰动,本文进一步将图像增广分成标签保留增广和标签扰动增广。最后,本文对使用算法或者模型确定图像增广的参数或者方法的研究归为智能图像增广,用于区别研究人员制定图像数据增广方法和具体策略的传统图像增广研究。
本文的主要研究内容和贡献可以总结为:
(1)系统性梳理图像增广领域的相关研究,提出图像增广的研究范式和分类体系,并对现有相关研究工作进行分类。
(2)依据本文提出的图像增广分类体系对每个类别中的代表性研究工作及其衍生研究进行客观的分析对比,并指出这些研究的创新点、适用场景和局限性。
(3)讨论并总结目前图像增广研究领域的发展现状、研究挑战及其未来的发展方向。
本文的内容将按照图2 所示的内容进行展开。
1 基本图像增广
本文首先对基本图像变换增广进行回顾。基本图像变换增广的主要特征是面向训练数据集的图像样本执行特定的图像变换操作(例如几何变换、光照变换等),产生新的图像样本的标签信息与原始图像样本的标签信息保持一致。可以通过以下形式化描述来定义基本图像变换增广的范式。

根据具体不同的图像增广原理,可以从几何变换、光学变换、纹理变换和统计的角度对基本图像变换进行归类分析。
1.1 几何与纹理变换图像增广
几何图像变换和纹理变换是在图像的几何空间所进行的增广操作。主要的增广方法如表1 所列,包括图像翻转、噪声、模糊、缩放、随机裁剪、仿射变换等。
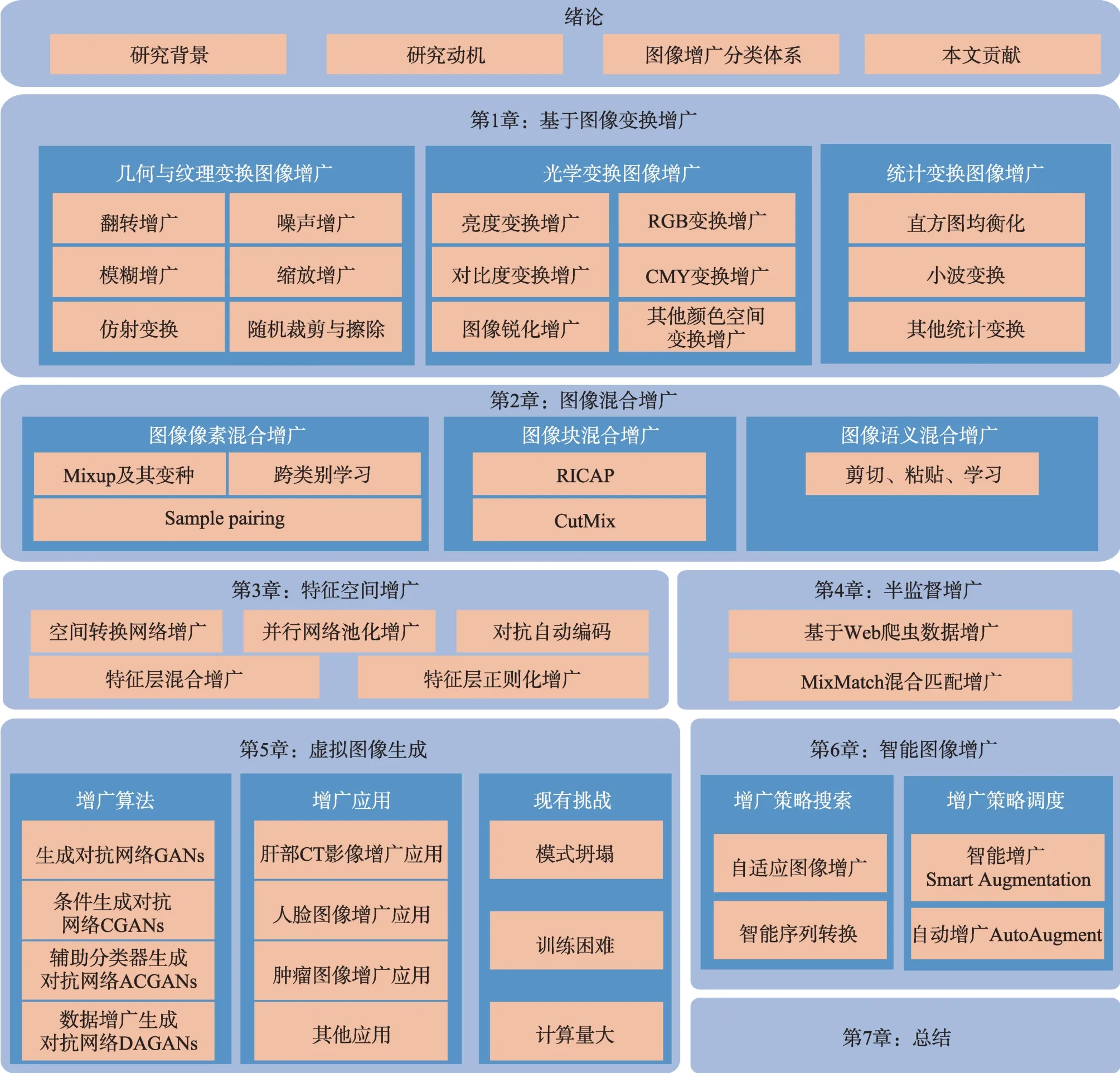
Fig.2 Organization of this paper图2 文章结构安排
1.1.1 翻转增广
图像的翻转是指沿着X轴或者Y轴进行旋转,使用I′表示翻转后的图像。当沿着y轴进行翻转时,I′表示左右翻转(也有文献称为水平镜像)后的图像样本。当X轴进行翻转时,I′表示上下翻转(垂直镜像)后的图像样本。翻转图像增广示例如图3 所示。其中,左边子图是原始图像,中间子图是在原始图像上通过水平翻转后的图像,右边子图是在原始图像上通过垂直翻转获得的图像。
1.1.2 噪声增广
图像的噪声增广是通过往原始图像中每个像素加入额外的随机信息,从而获得有别于原始图像的增广图像。为了方便起见,使用M表示噪声矩阵,其中M与原图像样本I具有相同的尺寸。当M中的每个元素由高斯分布N(μ,σ2)产生时,称为高斯图像噪声增广。
图4 为噪声增广的示例。左边子图为原始图I,中间子图为高斯分布产生的随机数所填充的噪声矩阵M,最右边子图为原始图像I与噪声矩阵M相加后生成的噪声增广图像I′。

Fig.3 Examples of flipping augmentation图3 图像翻转增广示例
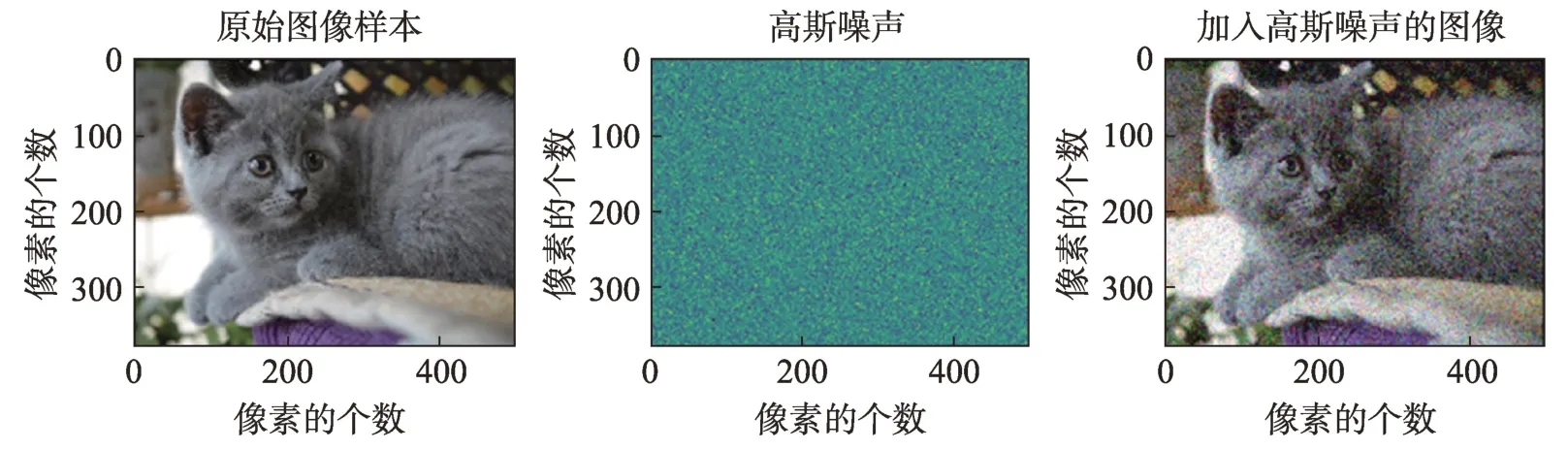
Fig.4 Examples of noise augmentation图4 噪声图像增广示例
1.1.3 模糊增广
图像模糊的原理是将图像中的每一个像素的取值重置为与周边像素相关的取值,例如周边像素的均值、中位值等。决定该像素取值与周边像素的范围称为模糊半径,常用γ表示。当γ=1 时,像素xi,j的取值相关范围包括{xi±1,j±1},当γ=2 时,像素xi,j的取值相关范围包括{xi±2,j±2}。γ越大,图像失真越严重,对应的视觉效果越模糊[75]。
给定图像模糊半径γ,计算区域内每个像素的取值方法不同决定了图像模糊方法的不同。例如,使用高斯分布计算区域内的每个像素的取值,称为高斯图像模糊,使用直方图均值方法计算区域的每个像素的图像模糊方法,称为直方图模糊[75]。如图5 所示,左侧是原始图像I,右侧是经过模糊半径为2(γ=2)的高斯模糊(σ=1.5)增广后形成的图像样本I′。

Fig.5 Examples of image blur augmentation图5 图像模糊增广示例
1.1.4 缩放增广
图像缩放包括图像的放大和图像的缩小。数据集的每张图像的长宽往往不一致,但是深度学习的输入往往需要一致的图像尺寸。例如224×224,因此图像缩放增广在深度学习中经常作为预处理操作。
给定图像样本I,其任意图像像素xi,j∈I,0 ≤i,j<N,N称为最大的像素坐标。则图像的缩放可以理解为任意的图像像素点xi,j沿着坐标轴X和Y轴上进行缩放,如式(2)所示。其中(i,j)为像素的原始坐标,(u,v)为经过缩放后的新坐标,kx和ky为X轴和Y轴方向的缩放比例。

如图6 所示,左侧子图是379×379 的原始图像样本,中间子图是缩小到224×224 的样本图像,最右边子图是放大到500×500 的样本图像。
1.1.5 仿射变换增广
仿射变换是图像样本I旋转θ角度后,并按照向量b进行平移的过程。当向量时,该仿射变换增广等价于旋转。仿射变换增广过程可以形式化为式(3),其中A(θ)为旋转矩阵,如等式(4)所示。
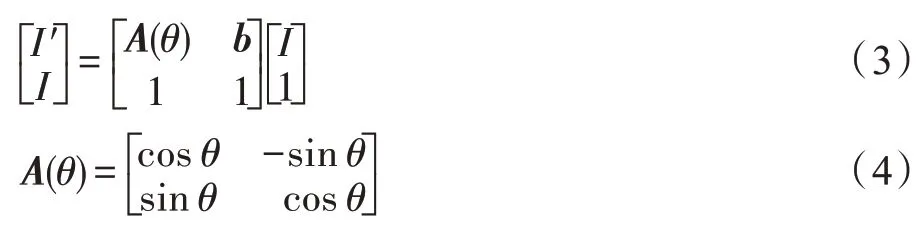
图7 是仿射变换图像增广示例。左边是原始图像样本,中间子图是经过θ=45°,时,仿射变换增广的图像样本。右边子图是经过θ=45°,时仿射变换增广的图像样本。
1.1.6 随机裁剪增广
随机裁剪是对图像I进行截取,获取图像I的子集Is,Is放大到图像I的尺寸得到随机裁剪后的图像I′。如图8 所示,左图是原始图像样本,右图是经过随机裁剪获得的图像样本。
1.1.7 图像擦除增广
图像擦除是对图像样本I的部分信息进行消除,使得消除后的图像样本I′仅仅包含I的部分信息。图像擦除增广的思想是模拟图像应用场景中的图像遮挡现象,通过人为地以一定概率对训练图像进行“损坏”,并将“损坏”的图像样本数据输入给神经网络图像分类模型,引导模型学习图像的残余信息,防止模型过拟合从而最终提升模型在测试样本的泛化性能。

Fig.6 Example of scaling augmentation图6 缩放图像增广示例

Fig.7 Examples of affine transformation augmentation图7 仿射变换增广示例

Fig.8 Examples of random cropping image augmentation图8 随机裁剪图像增广示例
Zhong 等学者[76]提出随机图像擦除的方法实现对深度学习的训练图像集增广。该方法的主要实现方式是在一个小批次(mini-batch)中,每个图像样本I以p的概率决定是否需要擦除,在需要擦除的图像样本I中随机选择一个矩形区域R((r1,c1),(r2,c2)),其中(r1,c1)为左上角坐标,(r2,c2)为右下角坐标,并且保证所选的矩形区域R的面积占比总面积在设置的阈值范围内。约束条件如式(5)所示,其中Sl和Sh为矩形面积与图像样本I总面积的最小和最大占比,W和H分别是图像样本I的宽度和高度。使用随机分布函数,将矩形区域R内的像素替换成随机值∀pi,j∈R,pi,j←rand(0,255)。随机擦除图像增广的示例如图9 所示。
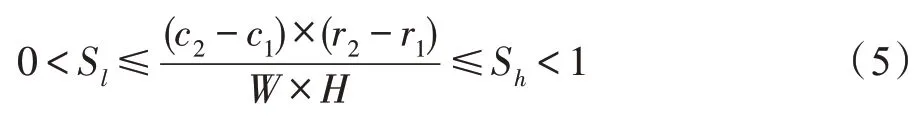
根据图像应用的场景不同随机擦除还有更多细分擦除的方法,如目标检测应用场景下的图像感知随机擦除(image-aware random erasing,IRE)、目标感知随机擦除(object-aware random erasing,ORE)和图像及目标感知的随机擦除(image and object-aware random erasing,I+ORE)[76]。

Fig.9 Examples of random erasing image augmentation图9 随机擦除图像增广示例
与随机擦除[76]思路相似的研究还有Cutout[72]。与随机擦除[76]不同的是,Cutout[72]认为擦除图像的面积比形状更重要,擦除的区域不要求是矩形或者其他规则化形状。同时,对于擦除部分填充,Cutout 提倡使用0 掩膜进行填充而不是使用随机噪声。其他类似的研究思路还有应用在中文字符识别应用的DropRegion[74]数据增广。
1.2 光学空间变换增广
光学空间变换增广是通过调整图像的光学空间进行的增广操作。主要的光学空间变换增广包括光照变化和颜色空间转换。其中,光学变换包括图像亮度变换、对比度和图像锐化,颜色空间变换主要包括RGB 颜色空间与CMY 颜色空间、XYZ 颜色空间、HSV 颜色空间、YIQ 颜色空间、YU 颜色空间和LAB颜色空间之间的转化[77]。常见的光学变换增广方法如表2 所示。
1.2.1 光照变换增广
光照变化增广包括亮度变化、对比度和图像锐化增广等。图像的亮度变化是直接对图像样本I的每个像素点进行线性变换操作[78]。使用λ表示图像亮度变换系数,则经过亮度变化增广的图像样本I′可以通过等式(6)表示,其中0 <λ<1 图像变暗,λ>1时图像样本变亮。

Table 2 Common optical transformation image augmentation methods表2 基于光学变换的常见图像增广方法

图像对比度增广是对图像样本I的细节进行增广,使得增广后的图像样本I′的细节更加突出的过程。图像对比度增广使用的变换算法有多种,因此图像对比度增广方法包括:线性对比度增广、平方对比度增广、幂对比度增广、指数对比度增广、对数对比度增广等。使用pi,j表示I中的第i行第j列像素,使用pi,j′表示I′中的第i行第j列像素。以线性增广为例,图像样本I的灰度范围为[m,M],若需要得到增广后的图像样本I′的灰度范围为[n,N],则I′可由式(7)获得。
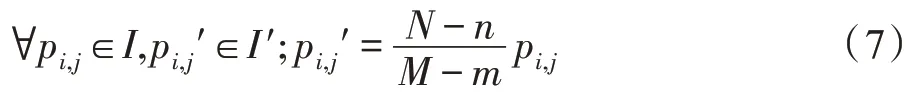
图像锐化增广的目的是增广图像样本I的边缘、轮廓以及图像细节,使得增广后的图像样本I′的边缘、轮廓线以及图像细节更加清晰。
图10 是图像光照变换增广示例。左上角是原始图像样本,右上角是经过亮度提升λ=1.5 后的图像样本,左下角是对比度提升后的图像样本,右下角是图像锐化后的样本。

Fig.10 Examples of illumination variation augmentation图10 光照变换增广示例
1.2.2 颜色空间变换增广
彩色图像中,常用的颜色空间主要有RGB颜色空间、CMY 颜色空间、XYZ 颜色空间、HSV 颜色空间、YIQ 颜色空间、YU 颜色空间和Lab 颜色空间等[77]。RGB 颜色空间是彩色图像样本中最常使用的颜色空间。在图像样本中使用三个通道表示,每个通道分别表示一种颜色。RGB 颜色模型的红绿蓝三种基色的波长分别是λR=700.0 nm,λG=700.0 nm 和λB=700.0 nm[77]。RGB 颜色空间的特点在视觉上非常均匀,任意一种颜色可以通过三种颜色混合而成。
CMY 颜色空间由青(C)、品红(M)和黄(Y)三种颜色构成颜色的三种基色。各种颜色可以由这三种基色加权混合而成。CMY 和RGB 两种颜色空间的转换如等式(8)所示。

XYZ 颜色空间把彩色光表示为C=WxX+WyY+WzZ,其中X、Y和Z分别表示颜色模型的基色量,Wx、Wy和Wz分别为X、Y和Z对应的权重系数。RGB颜色空间域XYZ 颜色空间转换关系如等式(9)所示。

在计算机视觉处理任务中,经常会遇到不同颜色空间描述的图像样本。因此,样本的颜色空间转换是非常常见的一种预处理和增广步骤。YUV 颜色空间是欧洲PAL 采用的颜色空间,YUV 颜色空间和RGB 颜色空间的转换关系如等式(10)。

其他颜色空间与RGB 的颜色空间的转换关系可查阅文献[77]。图11 为不同颜色空间增广的图像示例。第一排从左往右分别为原始RGB 图像样本、HSV 颜色空间样本和XYZ 颜色空间样本,第二排从左往右分别是YUV 颜色空间样本、Lab 颜色空间样本和CMY 颜色空间样本。
1.3 基于统计的图像增广
基于统计的图像增广方法通过引入统计学原理对图像进行建模,通过对统计变量进行变换,达到增广图像中关键信息的目标。基于统计的图像增广算法包括直方图均衡化增广、小波变换增广、偏微分方程增广和Retinex 图像增广等方法。其中,直方图均衡化增广和小波变换增广两种方法最为常见[79]。
1.3.1 直方图均衡化增广
直方图均衡化增广是对图像样本I的输入灰度映射为增广后图像样本I′的灰度级,使得I′的灰度级具有近似均匀分布的概率密度函数并最终使得I′比I具有更高的对比度和更宽的动态范围的过程[79]。
王浩等学者[79]将直方图均衡化描述为以下过程。原始图像I中的任意像素xi,j∈I代表图像样本I中坐标为(i,j)的像素,其中所有像素的灰度值h均在[0,L-1]之间(∀xi,j∈I,h(xi,j)∈[0,L-1])。图像I灰度标准概率函数可以描述为等式(11)。
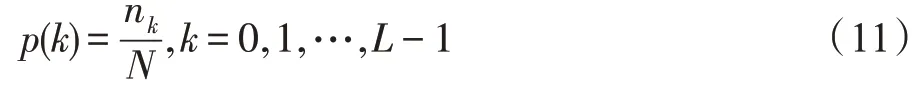

Fig.11 Examples of color variation augmentation图11 颜色空间变换增广示例
其中,N为图像样本I中的像素总数,nk表示灰度级为k的像素点的个数,则图像样本I的灰度级的累计分布函数可以表示为式(12)。
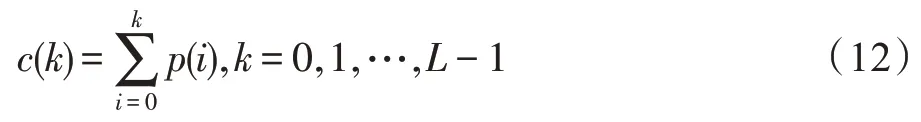
直方图均衡化生成的图像样本I′的灰度分布f(I)可以如式(13)所示。

1.3.2 小波变换增广
小波变换增广是基于数学统计变换的一种图像增广方法。小波变换将图像看作是一个离散的二维信号f(x,y)进行分解与重构。原始的图像样本I被分解用于描述图像中低频信息的低通子图和用于描述图像中的水平细节、垂直细节以及对角细节的高通子图像。其增广过程包括三个主要步骤。
小波变换增广的过程如下,首先加载原始图像样本将其分解成低通图像信息和高通图像信息。其次,对小波系数进行非线性增广,其增广的过程如式(14)所示[79]。最后将增广后的小波系数进行小波逆变换得到增广图像。
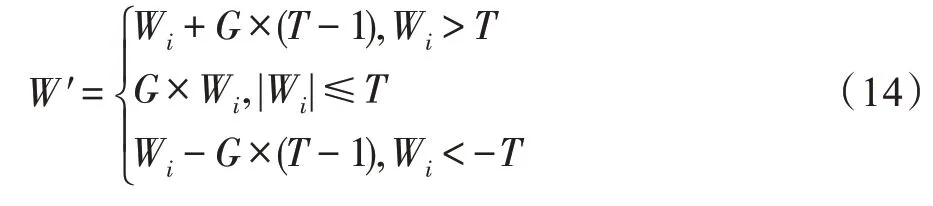
在式(14)中,G为小波变换的增广倍数,T为小波系数阈值,Wi为图像分解后的小波系数,W′为增广的后小波系数。小波图像增广以凸显图像中的细节信息,但是也有可能会放大图像中的噪声。
其他基于统计的图像增广还包括偏微分方程图像增广、Retinex 图像增广等方法。但由于这些方法在面向深度学习的数据增广中较少用到,感兴趣的读者请参考这些相关文献[79-85]。
1.4 基本图像增广总结
基本图像增广从传统图像增广中衍化而来,并且被广泛地应用到各种场景的图像识别应用中作为基础的数据预处理操作。因此,上述基本图像增广的方法被集成在面向深度学习应用的机器学习库中,例如ImgAug[86]和Albumentations[87]。
基本图像增广主要的特点可以总结为:
(1)图像语义信息不变,面向训练数据集中的图像样本,在原始图像空间上进行操作产生的增广后的样本语义信息与原始图像一致。
(2)多个不同基本图像增广方法经常根据应用场景需求串联使用。
(3)作为基本的图像预处理,广泛地应用在各种应用场合中作为数据预处理的一个步骤。
2 混合图像增广
图像混合增广方法通过使用训练集中的多个图像样本进行混合以合成新的图像样本。图像混合增广方法具备以下特点:(1)增广过程中需要两个或两个以上图像样本参与;(2)混合增广后生成的新的图像样本,其语义信息取决于多个参与增广样本的语义;(3)增广后生成的图像样本往往不具备人眼视觉理解特性。图像混合增广方法如表3 所示。
不失一般性,本文使用Mx(∙)表示图像混合增广算法,使用My(∙)表示图像语义混合算法。图像混合增广范式描述为Ik′=,表示由t个图像样本混合生成的图像样本Ik′。使用yk′=表示Ik′的语义标签。该语义标签通过上述参与增广操作的图像的标签混合计算生成。图像混合增广研究在于研究Mx(∙)和My(∙)内部算法。图像混合增广的典型研究包括像素混合图像增广、混合匹配增广、样本配对增广、剪切与粘贴增广以及上述方法的变种。

Table 3 Methods of mix sample augmentation表3 图像混合增广方法
2.1 像素混合增广及其变种
Tokozume 等学者[94]提出将两段不同类别的声音片段简单地线性混合BC Learning(between-class learning),用于深度学习模型进行语音的识别。BC Learning 的方法使得模型对语音识别的泛化能力大大提高,并在语音识别的准确率上超越人类。鉴于BC Learning 在语音识别任务的成功应用,原作者Tokozume 等学者将BC Learning 的思想引入到图像分类应用的图像增广中[53]。
BC Learning 图像增广的思想是将任意两个不同类别的图像样本Ii和Ij(Ii≠Ij)进行随机比例λ比例混合,产生新的图像样本和新的图像样本的混合标签。然后将所有的混合样本代替纯类别样本作为训练数据集,用于基于深度学习的图像分类模型训练。混合过程如等式组(15)所示。

BC Learning,从视觉上看由两张图像样本混合而成一个新样本是没有任何意义的,但是从卷积神经网络的角度看,图像的像素值可以通过傅里叶变换变成二维的波形图。两张图片的混合可以等价于是两个波形的混合,因此卷积神经网络可以从图像转成的频率数据中把图像识别当成语音识别任务。受到这种思想的启发,由于图像转成的频率波形图的均值并不等于0,作者提出了BC Learning 的升级版本BC+[51],将图像Ii看作是均值μi和波形成分σi的相加Ii=μi+σi。BC+[53]的混合方法如式(16)所示。
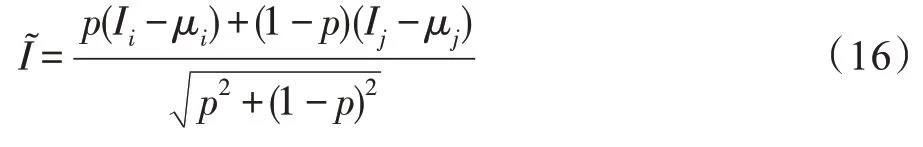
其中,p如等式(17)所示,(μi,σi)和(μj,σj)分别为图像样本Ii和Ij的均值和标准差。

BC Learning[94]和BC+[53]将图像像素线性混合的增广方式引入到图像分类中并在CIFAR-10/100[23]数据集上验证。BC Learning[94]可以将现有深度学习模型在CIFAR-10 上的SOTA(state-of-the-art)的错误率从6.07%降到5.17%,BC+[53]可以将现有深度学习在CIFAR-100的SOTA 的错误率从26.68%降到23.68%。
BC Learning 在CIFAR 数据集增广示例如图12所示。Ii为语义为狗的照片,Ij为语义为猫的照片,按照λ=0.5 的比例混合。

Fig.12 Example of BC Learning augmentation图12 BC Learning 图像增广示例
mixup[49]与BC Learning[94]的思路如出一辙,且均在同时期提出。不同的是,mixup 的核心思想是基于经验风险和临近风险最小化的原则。mixup 通过将传统图像标签的单热向量编码加权得到多热向量编码。同时在不增加模型复杂度的情况下,让神经网络学习到复杂度更低的函数来降低泛化误差。mixup的做法是将任意两个图像样本Ii和Ij及其对应的语义标签yi和yj通过权重参数λ进行加权相加,产生新的图像I=λIi+(1-λ)Ij和对应的的标签(1-λ)yj。
由于mixup 图像合成是通过两个图像样本进行逐像素线性相加,因此具有非常高效的特点。同时,由于合成图像的标签不再是独热形式,起到了标签平滑的效果,有效地提升了模型鲁棒性。mixup 在ImageNet-2012[22]和CIFAR 数据集上进行验证,均进一步降低了SOTA 中的Top-1 和Top-5 的错误率。
Guo 等学者[88]认为,尽管目前有大量的研究[57,66,95]对mixup 的整体有效性进行研究和解释。然而,截止到文献[88]发表时为止,mixup 等像素混合图像增广的有效性都没有完全被证明,只能依靠经验在给定的数据集上反复实验调整超参数λ。为此,Guo 等学者提出了自适应版本的AdaMixup[88]。在AdaMixup研究中,作者将2 个样本混合扩展到k(2 ≤k≤kmax)个样本混合,并将该方法视为一种神经网络外的正则化技术进行自适应学习mixup 的混合策略。
Sample Pairing[50]是IBM日本研究中心研究员Inoue等学者提出的混合图像增广框架。Sample Pairing 的核心思想是在包含N张图像的数据集D中,任意选定一张图像数据Ii,经过基本的图像增广后分别将其与数据集D中剩余的N-1 张图像(同样经过基本的图像增广)进行混合。最终产生N-1 张新图像样本,这些样本的语义标签仍然为yi。使用Sample Pairing图像增广框架,可以在样本数量为N的数据集D上产生样本数量为N2的新数据集。Sample Pairing 的增广流程如图13 所示。
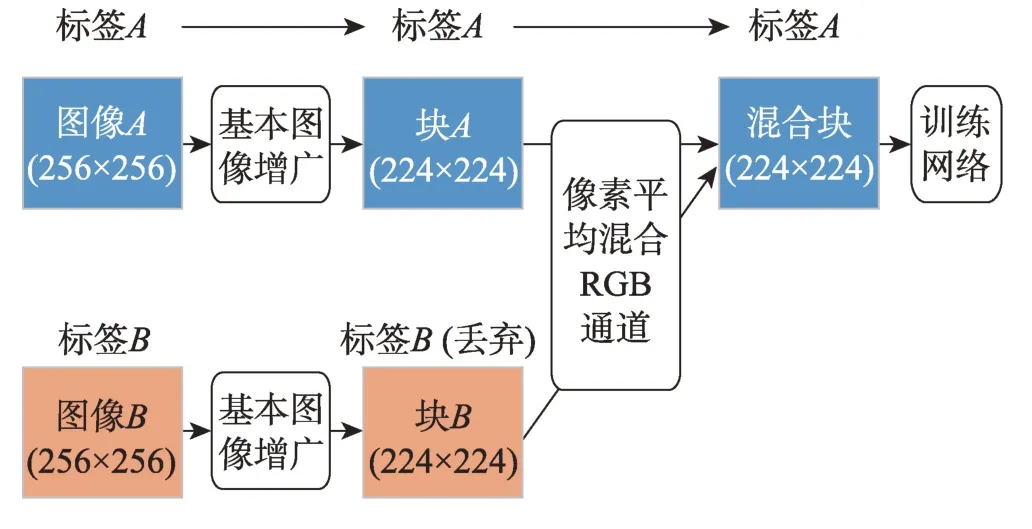
Fig.13 Procedure of SamplePairing augmentation图13 SamplePairing 增广流程图
SamplePairing图像增广框架,在CIFAR-10、CIFAR-100、SVHN 和ILSVRC 公开数据集上进行验证,能够显著地降低分类错误率。其中,在ILSVRC2012 数据集中,使用SamplePairing 数据增广框架分类错误率从33.50%降低到29.00%,在CIFAR-10 数据集上,分类错误率从8.22%降低到6.93%。
mixup 作为一种图像混合增广方法能够降低模型在训练过程中的过拟合,但是至于为什么会起作用以及有没有比以λ作为比例进行线性混合更有效的方法,仍然吸引着大家的关注[93]。为了能够进一步提升混合样本图像增广的性能,Summers 等学者[93]提出噪声混合、垂直连接混合、水平连接混合、混合连接、随机2×2 混合、垂直跨类别混合和随机矩形混合等在内的多种非线性混合的方法。作者在数据集CIFAR-10/100 上进行测试,实验结果表明垂直跨类别混合增广最为有效,在两个数据集的错误率分别为3.80%和19.70%。但是,作为图像混合的关键性问题,如何从理论上回答为什么这样混合是有效的,目前仍然是一个开放性问题。其他mixup的衍生研究还包括mixup 训练过程解析[57]、特征层混合[96]、Manifold Mixup[54,97]和FMix[89]等。
2.2 块混合
块混合是将图像样本分成若干个图像块(patch),然后使用不同的块进行组合的图像增广技术。随机图像剪切合成增广方法(random image cropping and patching,RICAP)[90]是Takahashi 等学者在ACML(Asian Conference on Machine Learning)提出的新颖图像增广方法。RICAP 的思想非常简单,随机从训练数据集中选出4 个图像样本Ii、Ij、Ik和Il,然后从4 个样本中各随机裁剪一部分,凑在一起合成一份新的样本I′。如图14 所示,合成的样本I′的语义标签y′由4张图像样本按照像素贡献总数占比进行合成。作者在CIFAR10/100 数据集上验证RICAP。实验表明,RICAP 在CIFAR-10 的错误率从Baseline 的3.89%降低到2.94%,达到当时新的SOTA;在CIFAR-100 的错误率,从Baseline的18.85%降低到17.44%。

Fig.14 Illustration of RICAP data augmentation图14 RICAP 图像增广示意图
RICAP 的具体操作方法如下:
(1)使用随机函数从数据集X中进行无放回抽样选出4 个基图像样本,分别命名为Ii、Ij、Ik和Il。
(2)随机生成合成位置坐标(xw,yh),其中xw∈(0,W),yh∈(0,H),W和H分别表示图像的宽度和高度。则位置坐标(xw,yh)将需要合成的图像划分成4份,左上角的面积为Si=w×h,右上角面积为Sj=(W-w)×h,左下角的面积为Sk=w×(H-h),右下角的面积为Sl=(W-w)×(H-h)。
(3)依次从第1 个图像样本Ii中随机剪切出左上角面积的图像部分,从第2 个图像样本Ij剪切出右上角的面积,从第3 个图像样本Ik剪切出左下角的面积,从第4 个图像样本Il剪切出右下角的面积。并根据面积计算合成图像I′的标签y′,如式(18)所示。
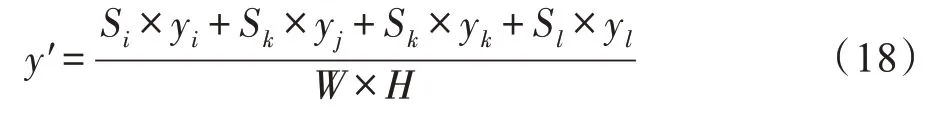
受到Cutout[72]图像遮挡和mixup[49]图像混合思想的启发,Yun 等学者提出了一种剪切混合的图像增广思路CutMix[91]。CutMix 增广策略的思路是从一张图像样本中随机移除一个块(patch)。同时,从另外一个类别的样本中切出相同大小的块替换掉移除的块,合成一个新的样本。该样本的标签按照两个类别样本所占的像素比例确定多热向量编码。
CutMix 具体的思路如下,给定图像样本I∋RW×H×C,W、H和C表示图像样本的宽度、高度和通道数。CutMix 的目标是给定两个图像样本(IA,yA)和(IB,yB)合成一个新的样本(I′,y′)。其中合成过程如方程组(19)所示。
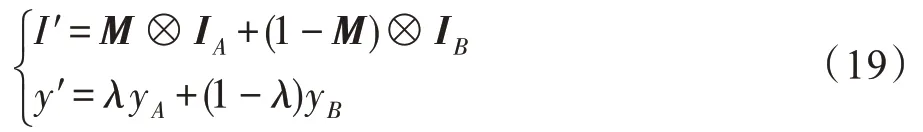
其中,M∈{0,1}W×H表示二进制掩膜矩阵。⊗表示像素级乘法操作。λ服从Beta(α,α)分布,其中α=1 进行采样。为了生成掩膜矩阵,首先需要生成候选框B,B=(rx,ry,rw,rh)表示两个图像样本中的取景区域。其中rx和ry表示区域左上角的坐标,rw和rh表示宽度和高度,如方程组(20)所示。对于M中坐标在B区域内的赋值为0,其他值赋值为1。
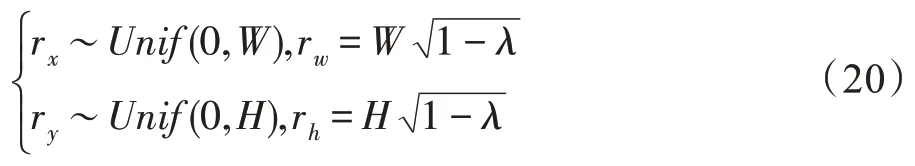
CutMix 在ImageNet 上使用ResNeXt-101[18]模型Top-1 和Top-5 的准确率分别提升2.4 个百分点和1.05 个百分点,在CIFAR-100 数据集上分别提升2.64个百分点和1.4 个百分点。
2.3 语义混合
剪切、粘贴与学习图像增广[92]是卡内基·梅隆大学研究员Dwibedi 等学者提出的在目标检测应用场景下的有效图像增广方法。其方法是为了在有限的数据集合成足够多的标签数据进行图像示例切割模型的训练。该方法的增广思路是从样本中切出实例像素区域作为实例元素库,随机选择不同的背景图像,随机从实例元素库中选取实例元素并将其随机覆盖到背景图像中。由于图像样本通过算法进行控制合成而来,因此在合成的过程中可以直接生成切割标注。剪切、粘贴与学习图像增广有效地解决了实例切割中需要大量标注图像的问题。实例示意图如图15 所示。
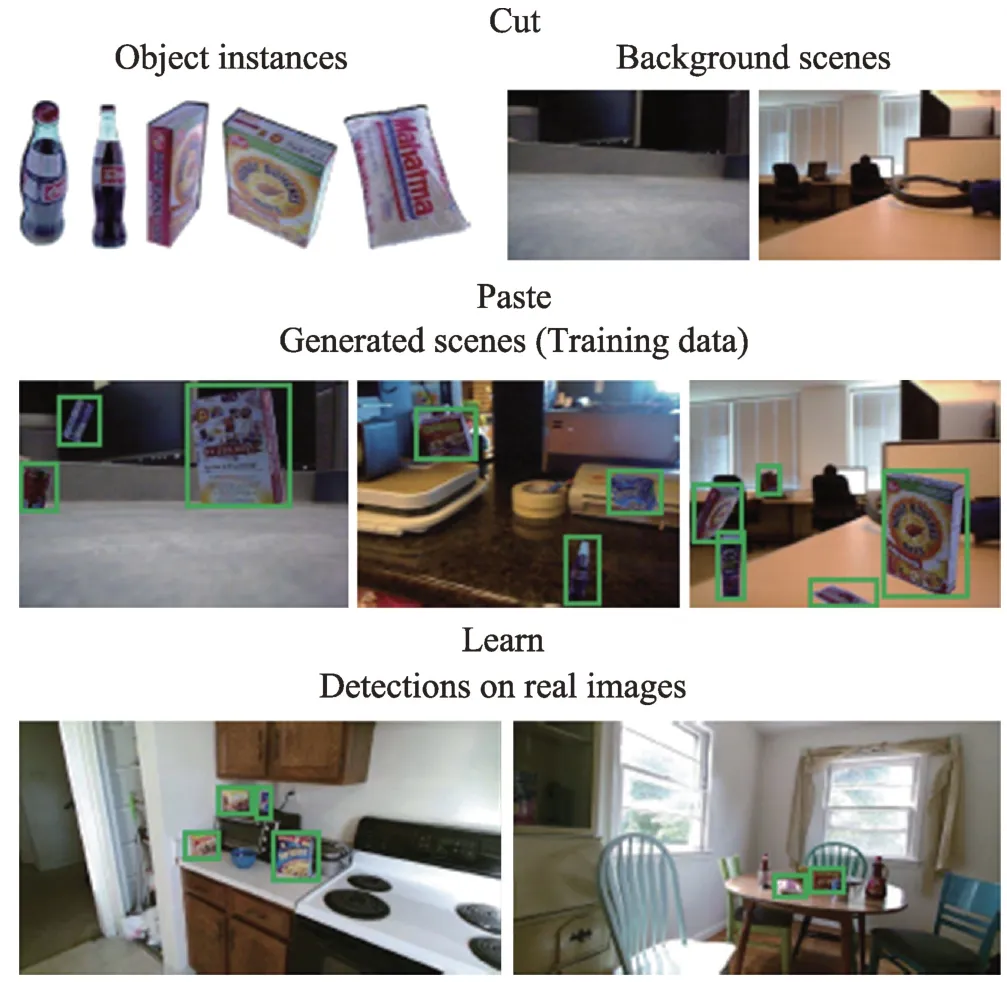
Fig.15 Example of cut,paste and learn augmentation图15 剪切、粘贴与学习图像增广示意图
2.4 图像混合增广总结
图像混合增广的最大创新之处就是改变图像样本标签的独热标注信息。训练样本数据集的标签信息更加平滑,在一定程度上能够提升网络的泛化容量。尽管目前有很多不同类型的图像混合的方式,但是图像混合研究目前还主要处于实验科学阶段,缺乏完备的科学理论对其进行解释。
3 特征空间增广
特征空间增广是面向训练样本的特征进行增广,达到提升模型泛化性能的目标。特征空间增广区别于传统图像空间增广,增广操作在样本经过若干个神经网络层所产生的隐向量上进行。使用Zi=F(Ii)表示图像样本Ii经过特征编码函数F(∙)获得其隐空间的特征Zi的过程。与图像空间增广类似,特征空间增广可以依据特征增广后的特征标签是否出现扰动进一步分类成特征变换和特征增广。
特征变换增广可以表示为等式组(21),其中Zj′表示执行增广操作T(Zi)输出的增广隐特征。

特征混合增广范式可以形式化表示为等式组(22)。其中,Mz(∙)表示特征的混合算法函数,My(∙)表示对应的标签混合算法函数。
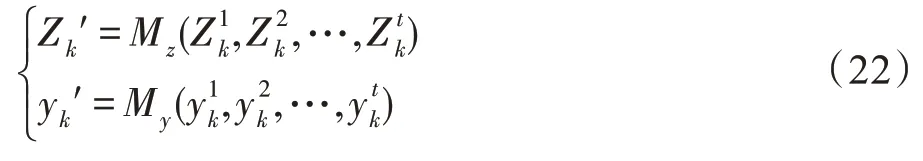
特征空间增广研究汇总如表4 所示。Devries和Taylor 两位学者在2017 年ICLR(The International Conference on Learning Representations)中提出了在数据集特征空间实现数据增广的方案[102]。该方案由三个步骤构成:首先,使用一个序列自动编码器从无标签的数据X中学习该样本不同序列的表达,并形成该样本的特征向量集合C。然后,将样本通过编码器生成样本的特征,再对特征进行增广。例如增加噪声、插值等。最后,经过增广后的特征将可以用于训练静态的特征分类器或者用于训练序列分类器。该方法用于阿拉伯数字识别中进行评估,可在基线测试中将错误率从1.53%降至1.28%。该方法的创新之处是将在样本空间中的增广方法迁移到特征空间中,能够在少量训练样本中学习到更强的表达逻辑,从而降低模型的误差。
Liu 等学者认为诸如翻转、变形、噪声、裁剪等图像空间的数据增广方法产生的合理数据非常有限,因此Liu 等学者提出了在特征空间进行线性插值的对抗自动编码(adversarial autoencoder,AAE)[100]图像增广方法。AAE 是自动变分编码器(variational autoencoder,VAE)和生成对抗网络GANs 的结合体。AAE 将自动变分编码器中的KL 散度损失替换成生成对抗网络的判别器损失。
AAE 与标准的VAE 一样,从图像样本I经过编码器转换成隐空间中的特征变量Z,在隐空间中对Z进行线性插值后再通过解码器生成增广样本I′。不同的是引入对抗网络从Z中进行采样P(Z)作为其中的一个输入,同时将隐空间中插值后的Z作为另外一个输入,计算两路输入之间的对抗损失。AAE 在CIFAR 数据集中进行评估后获得了最优的结果。
特征空间增广将在图像层(raw image layer)的增广操作泛化到特征隐藏层(latent layer),使得图像增广的范畴更加广泛和图像增广研究的思路更加开阔。同时,研究[96]表明在特征空间增广相对于在图像空间增广效果更加显著。未来,更多在图像空间增广的研究成果可以在特征空间上进行应用、检验和改善。
4 半监督增广
半监督图像增广的思路是将训练数据集外的其他未标注数据通过半监督技术使其加入到训练数据集中,以此达到扩充训练数据集的效果。使用U=表示具有K个样本的无标签数据集,使用Φ(∙)表示通过使用已有训练数据集X进行预训练的模型。使用yk′=Φ(uk)表示无标签样本uk的伪标签,并将(uk,yk′)加入到训练数据集X中,以此达到扩充训练数据集的目标。

Table 4 Methods of feature augmentation表4 特征空间增广研究汇总
Han 等[103]学者提出了基于Web 的数据增广的方法用于提升图像分类的效果。增广的思路总结如下:(1)将相同类别的训练样本放入同一个有序列表中,排在越前的样本代表该类的可信度越大。然后从每个类别的列表中随机选择图像样本作为种子上传到Google 进行以图搜图。(2)下载所有的搜索结果,计算所下载图像样本与列表中图像样本的相似度。满足相似度阈值的图像样本将加入到候选集中,其样本标签与种子标签一致。(3)每个图像列表中选择Top-K个最高相似度的下载图像样本,加入到训练数据集中。该方法的有效性易受到诸如网络和图像提供方等外在因素的影响。该方法适合在缺乏额外图像样本的情景下作为一种可选的训练集增广方法。
Berthelot 等学者[51]提出MixMatch 的半监督数据增广方法。首先,MixMatch 使用半监督的技术预测K个经过随机数据增广后的无标签样本的标签。然后,将K个标签经过算法最终确定给出该无标签样本的预测标签。最后使用mixup 技术随机从半监督增广获得数据集和已有标签数据集中选择图像样本进行混合形成最终增广后的训练数据集。
MixMatch 的半监督过程如图16 所示。对于任意给定的一张没有标签的图像数据I,分别使用K种不同的数据增广方法对其进行增广K次,产生K个增广后图像样本{I0′,I1′,…,IK-1′}。然后将K个样本输入分类器获取K个输出{y0′,y1′,…,yK-1′},并对K个输出进行求平均后锐化得到y′。使用y′作为无标签样本I的标签。
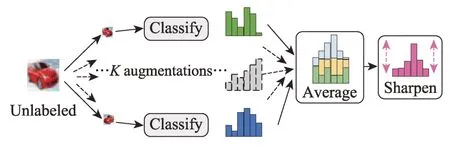
Fig.16 Overview workflow of MixMatch augmentation图16 MixMatch 增广的核心思想流程图
作者在CIFAR-10 数据集上,使用MixMatch 对没有标签的数据进行半监督学习,使得模型的分类错误率降低4 倍。然而,由于CIFAR 数据集的分辨率太低以及MixMatch 方法仅在CIFAR 数据集上进行评估,因此该方法在高分辨率的数据集上的效果有待评估。
获取大量的标签数据集是一个昂贵且费时的过程,然而获取无标签的原始数据集是一个相对容易的事情。而半监督数据增广方法能够将无标签的数据集利用起来提升模型的性能。因此,半监督数据增广是图像增广的一个重要研究方向。
5 虚拟图像增广
虚拟图像生成增广是通过生成模型(主要以生成对抗网络为主)直接生成图像样本,并将生成的样本加入到训练集中,从而达到数据集增广的目标。使用I′=G(Z,y)表示以噪声信号Z为种子,通过模型G(∙)生成标签为y的虚拟样本。虚拟图像生成增广通常使用生成对抗网络及其衍生网络作为图像样本的生成模型。
Goodfellow 等学者[58]提出生成对抗网络的模式,让网络模型之间通过对抗学习的方式不断地提升生成网络的生成质量和判别网络的判别能力,随即掀起了一股对抗学习的热潮。后续GANs 模型的改善主要是为了解决对抗学习过程中存在的模式坍塌和训练困难的问题。
5.1 GANs的虚拟图像增广方法
研究[62,104]表明GANs 是一种有效的无监督的图像数据增广方法。基于GANs 的图像增广是使用GANs 及其衍生模型作为工具在已有数据集上产生更丰富的图像样本,以此达到丰富训练数据样本提升应用模型在测试集性能的目标。
5.1.1 朴素生成对抗网络
将Goodfellow 等学者[58]提出的生成对抗模型称为朴素生成对抗网络。该模型首次将两个相互对抗的图像样本生成网络和真假鉴别网络融合在同一个模型,使用异步训练的方式相互提高两个模型的性能。使用图17(a)来描述朴素生成对抗网络的模型。
5.1.2 条件生成对抗网络
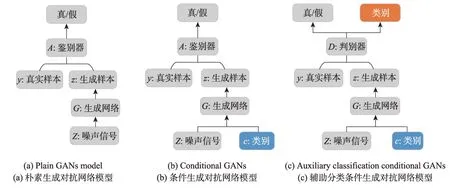
Fig.17 Model illustrations of different GANs图17 不同生成对抗网络模型图
由于朴素生成对抗网络[58]缺少外部类别信息作为指导,训练过程非常困难,为了给生成器和判别器添加额外信息加快收敛速度,条件生成对抗网络技术(conditional generative adversarial networks,CGANs)[105]在生成器的输入端将待生成样本的类别信息作为监督信号传入到生成模型中作为约束,如图17(b)所示。可以根据输入的条件信息生成符合条件的图像样本,尤其适合在图像增广方面应用[106]。
5.1.3 辅助分类条件对抗网络
为了能够提供更多的辅助信息进行半监督训练,Odena 等学者提出在条件生成对抗网络的判别器中加入一个额外分类任务,便于在训练过程中利用原始任务以及分类任务的优化对模型进行调优,这个方法称为分类辅助生成对抗网络(auxiliary classifier generative adversarial networks,ACGAN)[107]。
在ACGAN 中,除了随机噪声图像Z外,每个生成的样本具有对应的标签。生成器G同时接受噪声图像Z和待生成的样本的标签C,产生虚拟图像Xfake=G(C,Z)。判别器接收真实图像样本Xreal和虚拟图像样本Xfake的数据分布,判断出样本是否为真,如果为真则预测出该样本的类别。ACGAN 的模式可以简化描述为图17(c),额外的分类任务的加入可以生成更加清晰的图像并且加入辅助分类器有效缓解了模型崩塌问题。实验结果表明ACGAN 在CIFAR-10 数据集上分类准确性达到同期研究的最好效果。
由于ACGAN 图像增广的研究框架的适用性,ACGAN被应用到多个领域的视觉处理任务相关研究中。例如:Mariani 等学者为了解决图像分类中数据集标签不平衡的问题提出了数据平衡生成对抗网络(balancing generative adversarial networks,BAGAN)[108]。作者以ACGAN 为基础,将ACGAN 中的“真假”输出和“类别”输出合成为一个输出,解决了在训练过程中遇到少数类时两个损失函数相互冲突的问题。实验结果表明BAGAN 在MNIST、CIFAR-10、Flowers和GTSRB 四个数据集中,分类准确性表现比ACGAN更优秀。
Huang 等学者[109]基于ACGAN 模型提出了Actor-Critic GAN 解决图像分类应用在中类内数据不平衡的问题。使用ACGAN 模型对类内不平衡的样本进行有差别的增广,扩大类内图像的差异性。实验结果表明相比原始图像,作者的方案能提高大约2 个百分点的准确率。
Singh 等学者提出基于ACGAN 模型的恶意软件图像增广框架(malware image synthesis using GANs,MIGAN)[110]。作者使用MIGAN 解决了在恶意软件分析过程中带标签的恶意软件图像数据缺乏的问题。
5.1.4 其他生成对抗网络变种
Antoniou 等学者提出了基于GANs 的数据增广对抗网络(data augmentation generative adversarial networks,DAGAN)[63],并在多个数据集中应用DAGAN进行数据增广验证。
DAGANs 的架构如图18 所示。左边是图像生成网络,右边是判别器网络。生成网络分成两部分:一部分是线性投射网络,接收由高斯分布产生的随机噪声图像zi,并通过线性投射到新的zi;另外一部分是接收一个真实的图像样本xi,并对该样本进行初始特征编码生成ri。解码器接收xi和zi生成虚拟图像xg。判别器网络接收真实图像样本的数据分布(xi,xj)和生成器生成的虚拟图像分布(xi,xg),输出标量识别虚拟图像是否为假。DAGANs 与CGANs 最大的不同是监督信号直接是训练数据集的图像样本本身而非样本的标签。
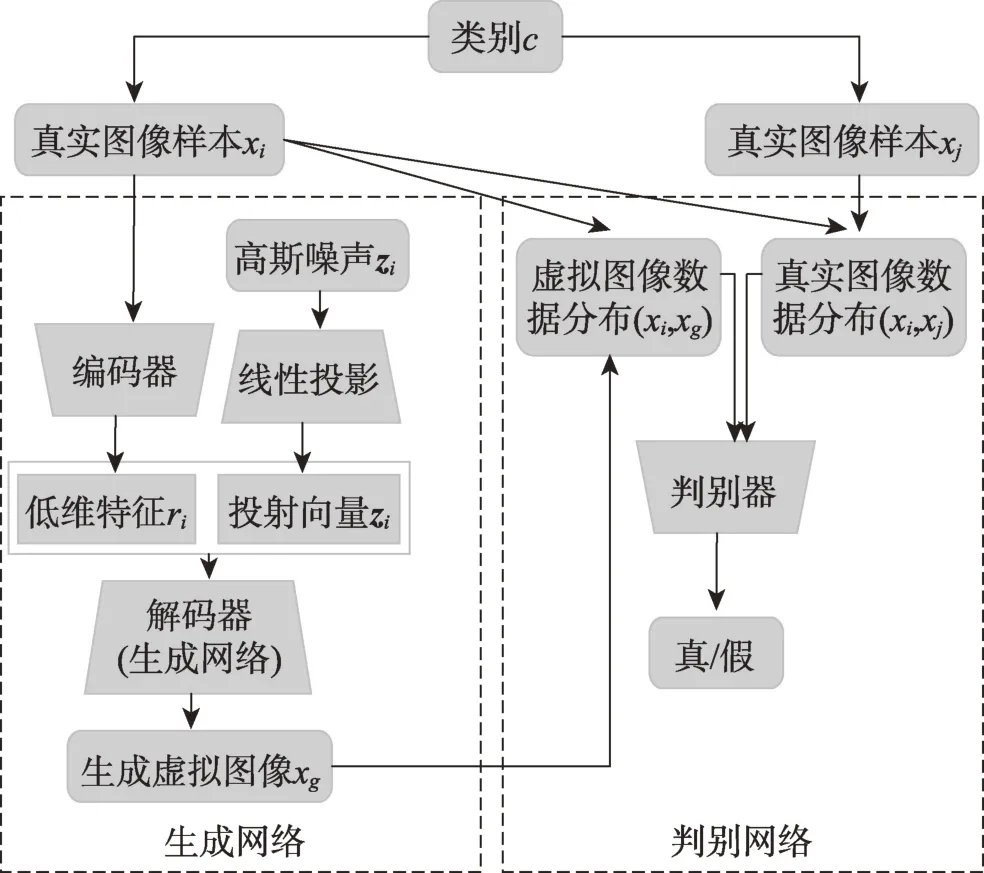
Fig.18 Architecture illustration of data augmentation GANs图18 数据增广对抗网络示意图
实验结果表明,在字体分类应用场景中,Omniglot[111]数据集中准确率从69%提升到82%,准确率提升幅度为13个百分点,在EMNIST[112]数据集准确率从73.9%提升到76%,累计提升幅度为2.1个百分点。在字体匹配场景中,Omniglot 数据集中准确率从96.9%提升了0.5个百分点到97.4%,在EMNIST数据集准确率从59.5%提升到了61.3%,累计提升1.8 个百分点。
Tran 等学者[67]提出了一种基于生成对抗网络的贝叶斯的图像数据增广方法,称其为BDAA(Bayesian data augmentation approach),如图19 所示。在现有图像数据集D的基础上,训练一个图像生成网络G,使用生成网络G生成虚拟图像样本集D′,通过训练集合成的方式将虚拟图像样本集D′合成到现有图像数据集D,D=D⋃D′。再使用新的D重新训练G,直到D的数据集达到预设的条件后,使用D训练图像分类网络C。BDAA 的亮点是提出了数据增广的框架,对于样本生成模块可以灵活替换成不同的生成网络模型。为了能够更好地理解虚拟图像生成增广的方法及其研究,本文通过表5 回顾生成对抗网络(GANs)及其衍生变种。表6 总结了其他相关的生成对抗网络模型,受限于篇幅,本文不再展开分析。
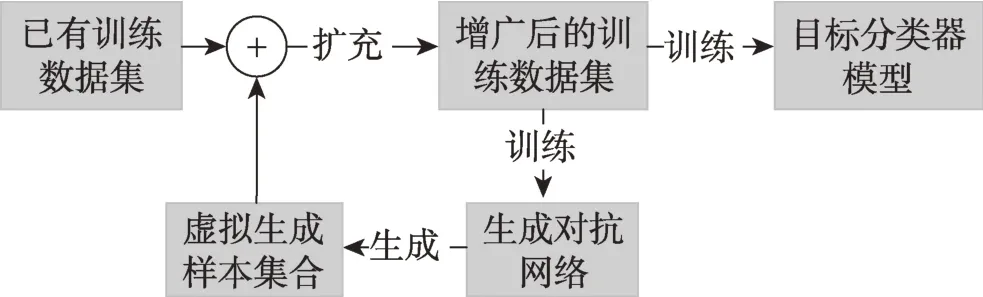
Fig.19 Architecture illustration of Bayesian data augmentation approach图19 BDAA 数据增广方法示意图
5.2 基于GANs图像增广应用
Frid-Adar等学者[131]使用DCGANs(deep convolutional generative adversarial networks)[115]模型对肝部CT 扫描图像进行增广,解决了肝部肿块等异常图像数据标注困难的问题。作者使用DCGANs 在少量标准的样本数据集中合成大量的带标注图像,能够有效地扩大肝部异常检测的训练数据集。实验表明,训练数据集中加入DCGANs 合成的图像样本,应用模型在测试数据集中灵敏度和特异度分别提升7.1个百分点和4 个百分点。
Table 5 Review of GANs model表5 GANs模型的回顾

Table 6 Summary of GANs-based augmentation methods and corresponding improvements表6 基于GANs的图像增广方法及其效果汇总
Shin 等学者使用GANs 进行阿尔兹海默症图像和多模态脑肿瘤图像的增广和去隐私[132]。作者使用不存在任何关系的公开脑部标签图像数据集和私有的病人肿瘤标签图像数据集,其中公有的脑部标签数据集的数据远远大于私有的肿瘤标签图像数据集。使用GANs 生成脑部的标注后和已经切割出来的肿瘤图像进行合并生成脑部肿瘤图像及其标签,并以此作为训练数据集。
Lai 等学者[133]提出了一种条件脸部合成框架,该框架将变分自动编码器与条件生成对抗网络相结合,以合成具有特定身份的脸部图像。作者通过大量的定量和定性实验表明,使用作者的方法生成的面部图像更具有多样性和真实性,可用于数据增广和训练高级人脸识别模型。
Han 等学者[134]以PG-GANs(progressive growing of generative adversarial networks)[118]为基础提出了脑部CT 影像的肿瘤检测图像增广框架,该框架针对脑部的囊肿、转移肿瘤和血管瘤进行针对性增广。作者使用YOLOv3[135]目标检测框架进行训练和验证。实验结果表明,在多种训练技巧结合的情况下,mAP指标提高了3 个百分点,灵敏度指标提高了10 个百分点。
基于GANs 的数据增广相关的研究还包括Zhu等学者[60]提出使用CycleGANs 技术做表情图像数据的增广。Frid-Adar 等学者[61]使用DCGANs 实现肝脏数据的增广。其他基于GANs 图像增广的相关研究读者可以更近一步阅读原文献[65-66,103,136-139]。
5.3 基于GANs图像增广小结
基于GANs 生成接近真实的虚拟图像样本的方式进行训练集图像增广,为图像增广提供了新的思路。更重要的是,虚拟图像从噪声图像中生成,比真实的图像更具有随机性和多样性。在训练数据不足的场景下能够有效地提升图像分类等应用的效果。有效地解决了样本不足、提取特征困难、生成图像质量差等机器视觉应用中经常遇到的问题。表6 汇总了当前基于GANs 图像增广的具有代表性的研究及其效果。尽管如此,基于GANs 的图像增广方法仍然需要面对以下挑战:
(1)模式坍塌。由于GANs 的训练过程缺乏监督信息的指导,拟合过程的随机性很大。同时由于生成对抗网络的学习能力有限,导致其只模拟出真实数据的一部分或者完全无法模拟真实的样本数据,产生模式上的缺陷,即模式坍塌(mode collapse)。模式坍塌生成的样本冗余度大,质量低和样本的差异性小,难以达到训练数据增广的目标。虽然WGANs(Wasserstein GANs)[123]及其后续优化研究WGANGP(WGAN with gradient penalty)[124]能够在一定程度上抑制模式坍塌,但并没有从根本上解决这个问题。
(2)训练困难。GANs 的训练过程存在梯度突变和梯度消失的问题,训练过程极其不稳定,虽然目前已有部分研究能够缓解该问题,但仍需要结合大量的训练技巧才能获得理想的训练结果[58,115,140-141]。
(3)庞大的计算量。由于GAN 的训练过程极其复杂且需要庞大的计算量,限制了其在大尺寸图像数据集上广泛应用。以目前的硬件计算速度而言,仅仅在小分辨率的图像增广上适用,例如28×28 或者64×64,但是超过256×256 或更高分辨率的图像,计算代价较高[103]。
(4)实用性有待验证。尽管已有研究表明使用基于GANs 的图像增广方法能够有效地提升模型的性能,然而作为图像增广而言,GANs 及其衍生模型相对复杂,甚至模型的复杂度已经超过了应用模型的复杂度。因此,复杂的模型和训练过程限制了基于GANs 的图像增广方法不能和基本图像变换增广方法一样作为预处理应用。
6 智能图像增广
由于图像增广需要大量的专家知识作为业务指导,在一个场景适用的图像增广方法和策略到另外一个场景却不一定适用[62,142]。因此促进了大量的智能化、自动化图像增广策略的相关研究[47,62,64-66,69,71,143-144]。智能图像增广研究是在此背景中产生。在给定具体的图像应用任务和训练数据集中,智能图像增广算法或者模型通过训练学习的方式获取最优的图像增广策略。使得在其他条件不变的前提下,机器视觉相关的任务得到最大的性能提升。将智能图像增广分成策略搜索和策略调度两个大类的方法,其中策略搜索方法解决给定增广方法的策略参数的搜索,策略调度解决给定的应用场景,确定图像的增广方法。
6.1 增广策略搜索
Fawzi等学者[64]提出了自适应图像增广方法。该方法使用仿射变换作为基本的数据增广操作算子。已经训练好分类器中,自适应算法使得基于仿射变换后的增广图像在已有的网络中获得最大分类误差。增广后的图像在现有网络表现最差意味着增广后的图像样本I′与原始样本I在现有网络C中的差异度最大。使用增广后的图像样本重新训练分类器网络,而获得分类准确性的提升。作者在MNIST-500[145]和Small-NORB[146]两个数据集上分别测试了该方法。在MNIST-500 数据集上,没有增广算法的前提下错误率为1.84%,使用随机仿射变换增广算法错误率为1.58%,使用作者提出的自适应增广的方法错误率为1.03%。在Small-NORB 数据集上,不做数据增广错误率为6.80%,随机仿射变换增广的错误率为6.49%,使用作者提出的增广方法,错误率为4.02%。实验结果表明,自适应图像增广算法在两个数据集上都表现得比随机仿射变换增广方法好。
Ratner 等学者[66]提出智能转换序列元学习增广的方法。将每一种传统的数据增广技术(旋转、镜像、缩放、对比度调整等)作为一个操作单元T,将多个操作组合在一起变成增广序列(transformation functions,TFs)。使用生成模型G从无标签的数据集D0中通过增广序列产生生成数据集D′并合并到已有标签的训练数据集D中,作为目标数据集对目标网络进行训练。增广过程如图20 所示。
序列学习增广[66]在自适应增广方法[64]的基础上,将搜索空间限定在有限范围之内,使得策略的搜索更加高效。
6.2 增广策略调度
Lemley 等学者[65]针对如何在训练数据集不足以训练目标网络的情况下,提出智能增广(smart augmentation)技术。智能增广的目标是给定一个类别的训练样本,在训练过程中找到最佳的增广策略。智能增广过程如图21 所示。该方法合并两个或者多个相同类别的图像样本,合并后生成的样本用于目标网络的训练。目标网络的损失函数用于反馈到增广网络中进行增广策略的调整。该方法基于Feret[147]数据集的人脸图像性别分类任务测试,其准确率从83.52%提升到88.45%。
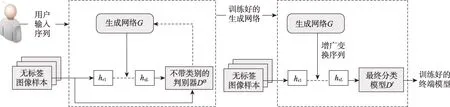
Fig.20 High-level diagram of domain-specific transformations augmentation图20 指定领域智能转换序列增广的顶层范式
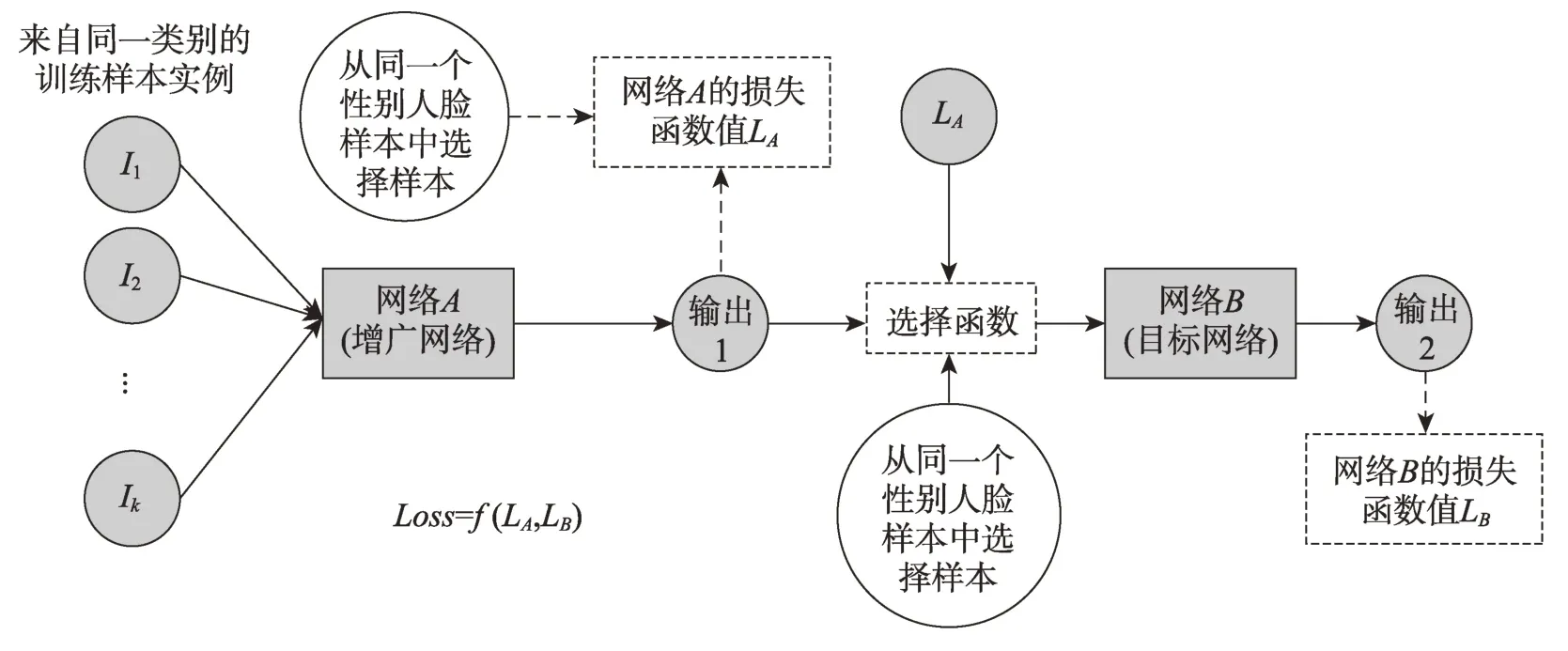
Fig.21 Illustration of smart augmentation图21 智能增广数据流图
基于学习的增广策略的优点是设计好增广网络及目标网络后,在不需要人为干预的情况下通过不断的训练能够找到最优增广策略使得目标网络的错误率最低。但智能增广存在以下弊端:首先是增广网络和目标网络同时训练,GPU 计算代价庞大;其次训练及复现困难。迭代1 000 多次仍未收敛,获得的数据增广策略未必是全局最优。
Cubuk 等学者[47]提出了基于自动机器学习的图像数据增广方法AutoAugment。如图22 所示,Auto-Augment的工作流程如下:首先预设图像增广策略集合,通过搜索算法从增广策略S中产生一个子策略Si,Si∈S。使用递归神经网络作为控制器,使用经过Si策略增广的训练集进行训练,把获得的模型在测试集的模型性能作为R的反馈,进行搜索策略的更新。AutoAugment 在应用过程中的主要问题是庞大的计算量,即便是在CIFAR 数据集上进行增广都需要超过5 000个GPU 小时。AutoAugment在对每一个增广策略的搜索过程中,直接对增广策略的连续参数空间进行学习搜索,因此庞大的连续搜索空间也是其巨大的计算量的原因之一。
Lim 等学者意识到尽管AutoAugment[47]方法能够显著地提高许多图像识别任务的性能,然而数千GPU小时的计算量大大地限制了该方法的可用性[148]。因此,Lim 等学者使用图像样本的密度分布进行增广策略的匹配从而提出了快速自动增广方法(Fast Auto-Augment)。首先,Fast AutoAugment[148]将任意一个给定的训练数据集等比例划分成K份,其中每一份训练数据集都包含一个用于训练的数据集和一个用于评估的验证集。然后,使用k个并行训练视觉模型的参数θ。当完成视觉模型的参数θ已经训练完成后,Fast AutoAugment[148]算法在k个评估的验证集DA上评估不同的图像增广策略,并获得k组top-N个策略,加入到最终的增广策略列表中,用于最终重新训练视觉模型参数θ。Fast AutoAugment[148]能够大幅度降低AutoAugment[47]算法的GPU 时间。
Lin 等学者在AutoAugment 的基础上,提出在线超参数优化技术(online hyper-parameter learning for auto-augmentation,OHL-Auto-Aug)[69],该方法将每种增广策略划分成不同的增广幅度,强、中、弱,从而将策略的连续搜索空间变成离散搜索空间。该方法极大地降低了搜索空间,从而加速了智能增广策略的训练效率。而Ho 等学者[70]则从搜索算法的角度对AutoAugment 的搜索过程进行改进,提出了基于种群的搜索方法(population based augmentation,PBA),该方法通过生成灵活的增广策略调度方法改变Auto-Augment 的固定搜索策略的方法。在同等测试准确率的前提下,AutoAugment 在CIFAR 数据集上需要5 000 个GPU 训练小时,PBA 仅需要5 个GPU 小时。
6.3 智能图像增广小结
使用智能图像增广的研究还包括Wang 等学者[62]使用神经网络学习多种数据增广的方法,并找到最适合当前分类器的最优增广策略。更多智能图像增广研究请读者查阅参考文献[68,70,149-154]。使用智能图像增广方法根据特定的图像应用任务,自动搜索出最佳的图像增广策略是目前图像研究一个趋势。其最大优势是可以降低对专家经验依赖,最大的问题是计算代价较大。表7 汇总了不同智能图像增广算法所需要的运算代价。
7 结束语
图像增广技术能够有效地缓解由于训练标签数据不足带来的过拟合问题,因此图像增广技术的研究近年来受到越来越多的关注和学者的持续投入。本文以图像增广的对象、操作空间、图像标签处理方式以及增广的策略的制定方式为依据,提出了图像增广研究的分类框架。依据该分类框架,本文提炼出每类图像增广的研究范式,并系统性地梳理了每类研究范式下的最新图像增广研究工作。
(1)从图像的增广对象上,本文将增广对象分成三大类:分别是训练数据集外的其他无标签图像样本,训练数据集已有标签样本以及从噪声空间进行随机采样虚拟图像样本。其中针对训练数据集外的其他无标签图像样本,主要通过半监督学习技术确定无标签图像的伪标签,并将伪标签作为无标签样本的标签加入到已有训练数据集,达到扩充训练数据集目标。针对噪声空间中的虚拟图像样本,通过以生成对抗网络及其衍生网络为主的技术直接生成图像样本,达到扩充训练数据集的目标。面向已有的训练集图像样本的增广研究则相对复杂需要进一步进行区分。
(2)在图像增广的操作空间上,本文对现有的增广研究分成两类:分别是原始图像空间上进行操作和在经过若干层卷积网络后产生的特征空间上进行增广操作。
(3)在图像标签的处理上,本文将现有图像增广的研究分成标签保留和标签扰动两大类。标签保留是指经过图像增广后图像样本其标签与增广前保持一致,反之将增广标签产生变化的增广称为标签扰动。
(4)面对特定应用场景,本文依据增广策略的生成方式分成三类:默认是由专家或者学者依据经验和探索人工制定增广的策略和参数;其次由专家或者学者制定增广策略,通过算法搜索出最优的增广参数组合;最后一类是直接交给系统进行元学习,通过深度学习网络生成恰当的增广策略和参数。
通过系统性梳理当前图像增广的研究,当前的研究现状可以总结为:
(1)自2017 年以mixup 为代表的标签扰动研究提出,掀起了图像混合增广的研究热潮。尽管图像混合增广研究能够提高模型的在测试集的误差,但是仍然存在着作用机制不明确的问题。
(2)随着生成对抗网络提出和不断完善,基于生成对抗网络及其变种的图像增广研究百花齐放。然而,由于增广过程中需要进行大量的模型训练和优化,增广过程操作复杂程度甚至超过了目标模型本身,因此,实际的应用价值还存在争议。
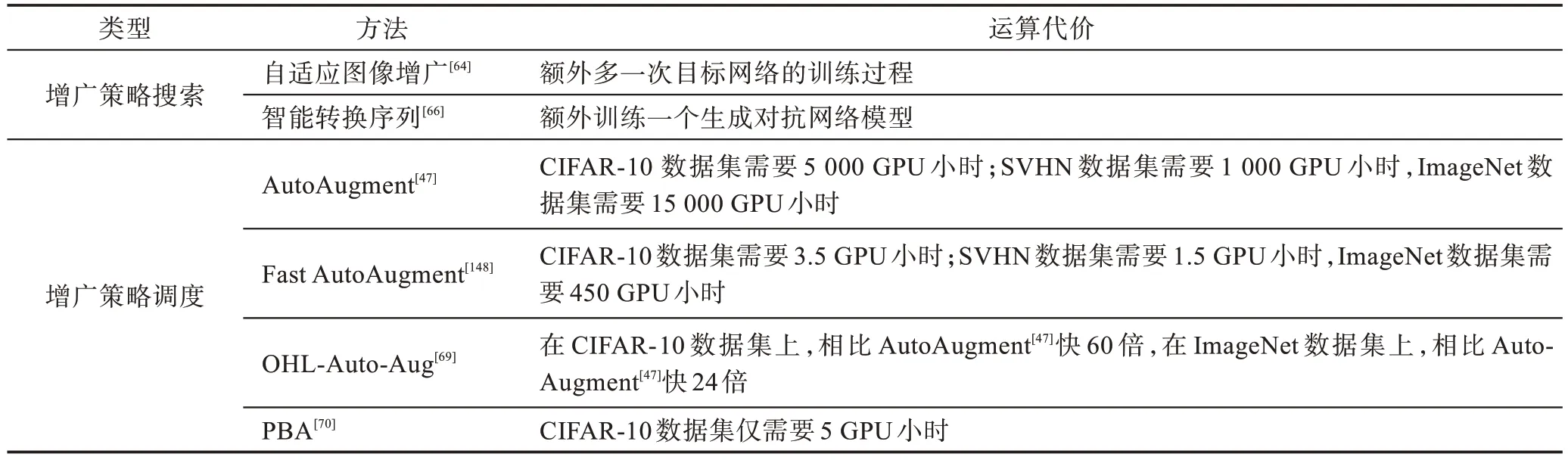
Table 7 Cost comparisons of different smart augmentation methods表7 不同智能图像增广算法成本比较
(3)随着自动机器学习和智能图像增广发展,现有图像增广研究已经开始采用元学习的方式探索最优图像增广参数或者图像增广策略。通过引入学习的机制代替专家制定增广策略逐渐成为图像增广研究的一个重要分支。
通过对现有图像增广研究的系统性分析和分类,图像增广研究在未来将呈现以下趋势:
(1)图像增广的研究范式出现交叉融合。不同的增广对象之间出现融合,例如在无标签图像样本中引入噪声生成虚拟图像样本。虚拟图像生成增广中引入学习机制等。
(2)半监督图像增广有望成为重要分支。随着自监督学习和半监督学习技术的推进,无标签图像样本的数据价值将会得到进一步的释放。
(3)特征空间图像增广有望成为主流。当前已有大量的研究探索在图像空间进行增广,并取得了大量的进展。当前研究人员在图像空间进行数据增广已经取得了不错的成果,未来在图像空间增广的研究思路有望在特征空间上进行应用和改良。
致谢本文在撰写过程中获得了华南理工大学金连文教授、中国科技大学俞能海教授和拉卡拉集团王欣明博士的指导,在此表示衷心的感谢。
猜你喜欢
现代装饰(2022年5期)2022-10-13
学苑创造·A版(2019年8期)2019-08-15
领导决策信息(2018年16期)2018-09-27
海峡姐妹(2018年3期)2018-05-09
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
西南学林(2011年0期)2011-11-12
