
空间文本数据流上连续查询评估技术综述
2021-04-11 12:48牛保宁
计算机与生活 2021年4期
杨 茸,牛保宁
太原理工大学信息与计算机学院,山西晋中 030600
空间文本数据流上连续查询(continuous queries over spatial-textual data streams,CQST),也称为位置感知的发布/订阅查询(location-aware publish/subscribe query),是在不断更新的空间文本对象数据流上,检索并实时更新满足空间和文本约束的对象,是广告定位、微博分析和地图服务等基于位置的应用程序的核心操作[1-21]。与一次查询(Ad-hoc query)相比,CQST是指在一段时间内(指查询有效期内),随着数据集的更新,系统连续地为CQST 计算并返回结果。评估CQST 的挑战性在于在CQST 上构建高效的过滤技术。通常系统中包含大量的CQST,数据流上的对象可能以很快的速度到来,对象的处理必须及时,任何延迟都有可能导致结果过时,使得用户体验变差,因此过滤技术的构建至关重要。
在本文,O 表示空间文本数据流。一个空间文本对象表示为o=(ρ,ψ,t)。其中o.ρ表示对象的地理位置,o.ψ是一组描述对象的文本集合,o.t表示与对象生命期有关的时间戳。近年来,空间文本数据流上连续查询主要包含连续布尔范围查询[1-11]及连续Top-k查询[12-21],定义如下:
空间文本数据流上连续布尔范围查询:连续布尔范围查询(continuous Boolean range query,CBRQ)表示为q=(r,ψ,t)。其中q.r是描述查询范围的一个空间区域,q.ψ是一组描述查询需求的文本(或数值)集合(或布尔表达式,本文只考虑“与”操作),称为关键字,q.t表示与查询生命期有关的时间戳。查询结果集为q(O)={o∈O|o.ρ∈q.r∧o.ψ⊇q.ψ},即返回落入查询范围内且包含全部查询关键字的对象。
空间文本数据流上连续Top-k查询:连续Top-k查询(continuous Top-knearest neighbor query,CTkN)表示为q=(ρ,ψ,k,α,t)。其中q.ρ表示查询的地理位置,q.k表示查询返回的对象个数,q.α表示平衡空间邻近度及文本相似度的查询偏好参数,其他参数意义同上。为CTkN 查询定义一个评分函数ST(o,q),返回ST(o,q)值最高的q.k个对象,即q(O)={o∈O|∄o′∈Oq(O),ST(o,q)≤ST(o′,q)}},其中|q(O)|=q.k。
CQST 的评估流程如图1 所示。用户向服务器端提交查询,服务器为查询计算并返回满足条件的结果。在查询有效期内,若对象更新,服务器为受影响的查询重新计算结果,直到查询失效。服务器端包含对象处理模块及查询处理模块。(1)对象处理模块负责处理到来的对象,包含查询过滤技术及对象处理算法。当新对象到来时,利用对象处理算法及查询过滤技术评估该对象可能会影响哪些查询的结果,更新相应查询的结果列表。(2)查询处理模块处理新提交的查询,包含对象索引及查询算法。新提交的查询依据查询算法在对象索引中检索满足空间文本约束的结果,更新结果列表。此外,将新提交的对象、查询插入相应索引。将到期的对象、查询从相应索引中删除,并更新查询结果列表。
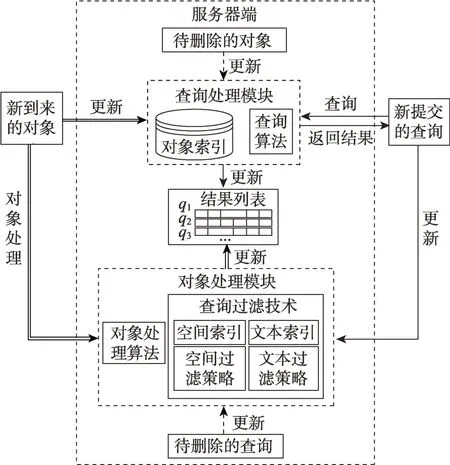
Fig.1 Framework of evaluating CQST图1 评估CQST 框架
值得注意的是,与本文密切相关的工作有:(1)连续移动的查询[22-25],即在查询有效期内,为移动的查询连续返回结果,如用户在移动过程中,查找附近的加油站或者出租车。为了减小客户端与服务器端的通信代价,通常采用安全区域模型,为移动的查询或对象建立安全区域。构建安全区域的代价是巨大的,因此这类工作专注于减小构建安全区域的代价。Qi 等人[26]综述了不同场景下的安全区域模型及其构建方式。(2)空间文本数据流上的一次查询,即在当前空间文本数据流上,为查询计算并返回结果,查询结束。GeoTrend[27]及Mercury[28]检索最近T时间段内与用户地理位置邻近、时间较新的微博,是在已有对象集上的一次检索,类似于经典的空间关键字查询。该类工作专注于数据流上到来对象索引的构建及更新,组织微博的地理位置及时间分值,忽略文本属性。(3)空间关键字查询[29-30],即在静态空间文本数据集上检索满足空间文本约束的对象。Chen等人[31]综述了多种空间文本查询模型下的空间文本索引性能。
1 评估CQST 的索引
索引是过滤大量不相关查询的基础,因此本章介绍评估CQST 的索引技术,并讨论它们的索引性能及优缺点。
表1 列出了现有评估CQST 的索引技术。
1.1 空间索引
从空间过滤角度看,评估CQST 为点刺探搜索(point stabbing search)问题,即返回该位置点命中的区域中的查询。空间索引是空间过滤的基础,定位到来对象落入的空间节点,验证该节点内的查询。验证的查询数量越少,过滤性能越好。评估CQST 采用的基本空间索引可分为以下两大类。
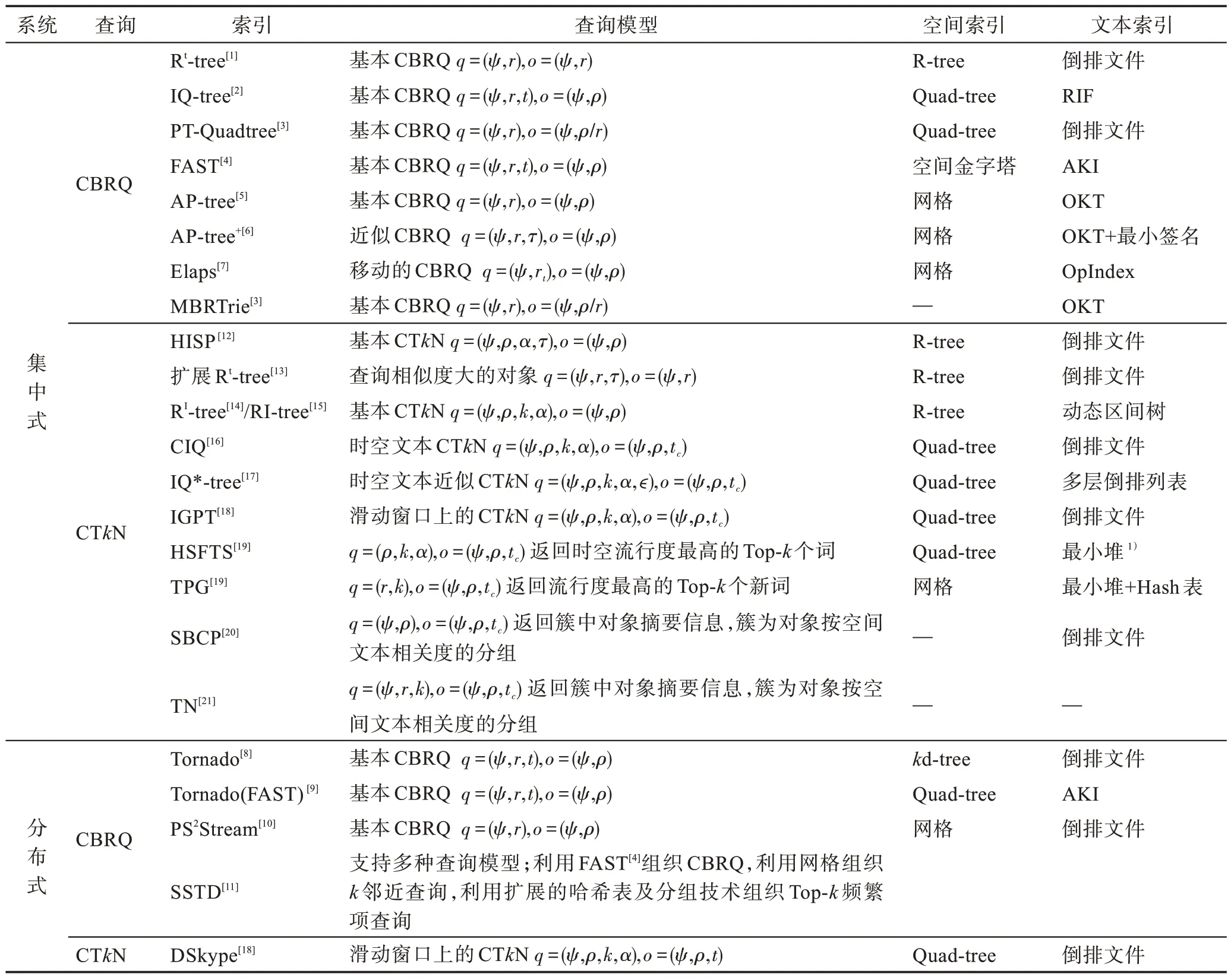
Table 1 Indexes of evaluating CQST表1 评估CQST 的索引技术
(1)数据驱动型(data-driven)索引。节点的边界由数据的空间分布决定。优点是不需要整个空间区域的先验知识,根节点空间信息由子节点得到。缺点是索引构建时间及更新时间较长。R-tree[1,12-15],索引自底向上构建,叶节点按照数据的空间范围或地理位置构建,非叶节点由叶节点迭代构建。R-tree是平衡树,节点中插入的查询数量不超过阈值。kd-tree[8-10],是二叉树,将整个空间区域不断从水平或垂直方向划分为两个子区域,划分后两个子区域的查询数量基本相同。
(2)空间驱动型(space-driven)索引。节点边界不依赖于数据的空间分布。优点是索引构建时间及更新时间短。缺点是需要明确整个空间区域的大小。Quad-tree/空间金字塔[2-4,9,16-18],从根节点开始,将整个空间区域迭代地划分为多层不同粒度的、均匀的、不重叠的节点。除叶节点外,每个节点包含四个子节点,数据既可插入叶节点,也可插入中间节点。网格/哈希桶[5-7,10,19],整个空间区域被划分为多个非重叠的矩形节点,并将查询插入到所有映射节点。粒度选择是关键。单粒度网格(哈希桶)范围较小,包含的数据集较少,过滤性能较强,但查询范围较大时,占用内存将成倍增加。
1.2 文本索引
从文本过滤角度看,评估CQST 为超集包含搜索(superset containment search)问题,即返回关键字包含在对象中的查询。文本索引是文本过滤的基础,用来检查数据流中的对象包含了哪些查询的关键字。验证的查询数量越少,过滤性能越好。评估CQST 采用的基本文本索引可分为以下两大类。
(1)数据无序性索引。索引中的数据无序,当进行数据验证时,需要验证索引中所有数据项。优点是索引构建简单,更新代价小。缺点是过滤性能弱。倒排文件(inverted file)[1,3,8,10,12-13,16,18,20]是最基本的文本索引,评估CQST 的大量过滤技术均采用倒排文件组织查询关键字。倒排文件包含一个文本集,每个文本对应一个列表(posting list)。为了增加倒排文件的过滤能力,一般每个CBRQ 查询只插入到一个列表,而每个CTkN 查询需要插入到其关键字对应的所有列表。Ranked-key 倒排文件(ranked-key inverted file,RIF)[2],查询按照包含关键字的频率被插入到低频关键字对应的列表(即最短的列表),以减少高频关键字对应的列表中的查询数量,适用于CBRQ 查询。多层倒排列表(multi-level inverted list)[17]是二叉树,每个叶节点指向一个倒排列表,该列表包含的查询数量不超过给定阈值。在非叶节点维护多个属性值,以提高倒排列表的过滤能力。
(2)数据有序性索引。索引中的数据有序,评估CQST 时只需验证部分数据项。优点是过滤性能强。缺点是索引构建复杂,更新代价大。有序关键字字典树(ordered keyword trie,OKT)[3,5-6]将一组查询按照其包含的关键字分为多个分支,到来对象只需要验证包含文本项的分支。自适应关键字索引(adaptive keyword index,AKI)[4,9]是一个混合索引,集成了RIF与OKT,利用关键字的频率提高索引的过滤能力。简而言之,检查待插入查询包含的关键字频率,若查询包含低频关键字,则将其插入RIF 中;若查询只包含高频关键字,则将其插入OKT 中。
除了上述文本索引外,部分CQST 查询请求中包含数值属性,故在空间节点中采用OpIndex[7]及区间树[14-15]等组织节点内查询的数值属性,即为每个属性值建立相应的倒排列表,列表包含了数值数据的区间。
2 评估CQST 的过滤策略
评估CQST 的查询优化技术采用一项或多项过滤策略及方法,以尽可能提升索引的空间和文本过滤性能,为到来对象过滤大量不相关的查询,提高对象与查询的匹配效率。
2.1 提升空间过滤性能的策略
将提升评估CQST 的空间过滤性能的策略分为以下四类。
(1)限制空间节点内插入的查询数量。为了提高空间过滤性能,空间节点中插入的查询数量是关键。Rt-tree 及其两个变体[1]、扩展Rt-tree 及其变体[13]、RI-tree[14]及RI-tree[15]利用R-tree 组织查询范围,HISP(hierarchical index with spatio-textual and region-aware prefix)[12]利用R-tree 组织查询地理位置。R-tree 节点内的查询数量不超过给定阈值。FAST(frequencyaware spatio-textual)[4]利用空间金字塔组织查询范围,HSFTS(hierarchical summarization and fast computation of the ranking score based subscription filtering to solve top-kspatial-temporal term subscription)[19]利用Quad-tree 组织查询的地理位置。它们在空间金字塔或Quad-tree 节点限制插入的查询数量,若查询数量大于阈值,则增加空间节点划分深度,将查询插入到下一级空间节点。
(2)最小化覆盖查询范围的空间节点区域,以减少评估查询时验证对象的数量。将查询范围映射到Quad-tree、空间金字塔的叶节点或小粒度的网格、哈希桶均可实现这一途径。Elaps(new location-aware pub/sub system)[7]考虑因查询位置更新导致的通信代价及数据流中对象的匹配代价,为移动的查询计算最佳安全区域。因查询在不断移动,查询安全区域需不断更新,为此该文献将查询的安全区域映射到网格,利用倒排文件组织映射到网格的查询,以适应查询移动(即查询在网格中的更新)。IGPT(index combining both individual and group pruning techniques)[18]利用Quad-tree 的叶子节点组织查询地理位置。该类策略空间节点内插入的查询数量没有约束,且查询范围较大的查询被插入到多个空间节点,其更新代价及存储代价增加。
(3)计算数据分布,将查询映射到相应的空间节点。针对第(2)种策略存在的问题,本策略通过计算系统中查询与对象的空间分布,为查询计算最佳映射节点,即将查询范围映射到多个大小不一的空间节点。IQ-tree[2]利用Quad-tree 组织查询范围,利用一个基于磁盘的代价模型将一组查询与一组Quad-tree节点关联,将查询插入到一个或多个Quad-tree 节点中,以平衡索引匹配及更新的I/O 代价。FAST[4]利用空间金字塔组织查询范围,查询按照关键字的频率划分到高层或较低层的空间金字塔节点。查询范围较小或只包含高频关键字的查询更倾向于插入到高层金字塔节点。AP-tree、AP+-tree[5]及AP-tree+[6]计算节点内查询及对象的空间分布,采用自适应的网格组织查询范围,即网格大小是由查询空间分布决定的。CIQ(conditional influence region based quadtree)[16]及IQ*-tree[17]使用条件影响区域(conditional influence ring,CIR)或者近似条件影响区域(approximate conditional influence ring,ACIR)表示查询。在CIQ 中,查询用一组CIR 表示,CIR 是与查询文本相关度及时间新近性有关的圆形区域。在IQ*-tree 中,查询用一组ACIR 表示,ACIR 是与查询文本相关度及时间新近性有关的环形区域。为此,将查询映射到一组覆盖整个空间区域的非重叠Quad-tree 节点,节点粒度由查询地理位置决定。
(4)在空间节点中引入空间邻近度过滤条件,避免对象验证不可能的查询,适用于计算分值的CTkN查询。给定任意查询,若确定文本相似度上界,可得到对象与查询匹配的空间邻近度下界。在空间节点引入节点内所有查询的最小空间邻近度下界,若对象和节点的空间邻近度小于该值,则对象与节点内所有查询均不匹配。HISP[12]在R-tree 节点,维护一个轻量级签名。LSB(R|w)表示节点中关键字前缀中包含w的查询的空间邻近度下界中的最小值。CIQ[16]及IQ*-tree[17]在每个Quad-tree 节点按照查询与节点的空间邻近度,将查询分为多个桶。IGPT[18]利用Quad-tree 的叶子节点组织查询地理位置,并在节点维护查询的最小空间邻近度下界。RI[14]在R-tree 节点集成查询最小及最大空间偏好参数,以及其他属性的聚合信息。当对象到来时,计算对象与R-tree 节点的相似度上界,以实现快速过滤。HSFTS[19]在Quad-tree 节点为每个查询集成一个存放结果的最小堆,并标记所有查询最小的第k个时空流行度。
2.2 提升文本过滤性能的策略
将提升评估CQST 文本过滤性能的策略分为以下四类。
(1)增加文本划分深度。Rt-tree及其变体[1],从Rtree 根节点开始,在R-tree 各层节点记录其后代节点内查询的一个或多个代表性关键字。MBRTrie(trie integrated with minimum bounding rectangle)[3]、APtree、AP+-tree[5]及AP-tree+[6]采用OKT 组织查询关键字,按关键字偏移度,查询被划分到自适应的文本区间内,即文本区间大小是由查询文本分布决定的。AP-tree+[6]在AP-tree 的查询节点及文本节点集成最小签名,以支持近似关键字匹配。为了改善数据处理性能,在GPU 平台上实现AP-tree+的并行化。利用一维数组将AP-tree+数据结构(即空间节点、文本节点及查询节点等)映射到GPU 中以形成G-AP-tree+。基于数据流中到来的一组对象的关键字和G-AP-tree+特征矩阵中的关键字(即查询的q-gram 关键字的最小签名)并行构造签名矩阵,计算签名矩阵中最小签名间的相似度,以加速对象与G-AP-tree+中查询的关键字的近似匹配。FAST[4]在空间金字塔节点,采用AKI 组织查询。若查询无法插入到任何低频关键字对应的RIF 中,将查询根据关键字的字典顺序插入OKT 中。若对应文本节点查询数量超过阈值,则增加OKT 划分深度。
(2)限制倒排列表中包含的查询数量。IQ-tree[2]在Quad-tree 节点利用RIF 组织查询关键字,但倒排列表可能依然很长。FAST[4]在空间金字塔节点的RIF 中限制了倒排列表的长度,将多余的查询插入到OKT 或子节点中,若查询更新,会导致查询在RIF 和OKT 间不断调整。IQ*-tree[17]根据查询关键字的数量对查询进行分类,对每类查询构建单独的IQ*-tree,这是因为查询和对象的文本相似度与两者包含的关键字数量有关。在Quad-tree 节点集成多层倒排列表,限制倒排列表内查询的数量。
(3)为查询计算对象与其匹配需满足的文本前缀,查询只插入文本前缀对应的倒排列表中,减少查询关联的倒排列表数量。若到来对象不包含关键字前缀中的任一文本,则对象不可能是查询的结果,适用于CTkN 查询。HISP[12]为查询计算两类前缀:Spatial-oriented 前缀(SP 前缀)和Region-Aware 前缀(RA 前缀)。在R-tree 叶节点,查询插入到其前缀关键字对应的倒排列表中。SP 前缀的计算——对任意匹配的对象查询对,令空间邻近度为1,得到需满足的文本相似度下界θT。从查询最后一个权重最小的关键字开始向前求和,得到使权重和小于θT的最小关键字对应的序号p,则查询的SP 前缀为从第一个关键字到第p-1 个关键字构成的集合。若查询与对象匹配,则对象必须至少包含查询SP 前缀中的一个关键字,因为第p个关键字之后文本的总权重小于θT。类似地,RA 前缀的计算——对任意匹配的对象查询对,根据查询到叶节点边界的最小距离,计算需满足的文本相似度下界θ′T,根据该值,得到缩小的RA 前缀。SP 前缀对应的倒排列表用于过滤区域内部的对象,RA 前缀对应的倒排列表用于过滤区域外部的对象。扩展的Rt+-tree[13],利用空间邻近度上界计算对象与查询匹配需满足的关键字前缀,在R-tree 节点,记录后代子节点内查询的关键字前缀。
(4)在索引节点或倒排列表引入文本相似度下界,提前终止节点或倒排列表内查询的验证,实现节点、倒排列表或倒排列表组内查询过滤,适用于CTkN查询。按照过滤性能分为三类:①索引节点查询过滤。PT-Quadtree[3]在Quad-tree 节点集成后代节点内查询包含的共同文本项,或者多个最频繁的文本项。扩展的Rt-tree[13],除在R-tree 节点记录其后代节点内查询的关键字外,还记录节点中查询关键字的最小权重及最小的查询范围。当对象到来时,首先计算对象与节点的相似度,若相似度小于阈值,则该节点过滤。②倒排列表查询过滤。扩展的Rt++-tree[13]除在R-tree 节点依次记录其后代节点内查询的关键字外,关键字相应倒排列表中增加文本相似度下界,以加快对象处理。③倒排列表组内查询过滤。对倒排列表中的查询进行分组,每个组维护相应的文本相似度下界,若到来对象与当前组内查询的文本相似度小于该值,则提前终止该倒排列表的验证。CIQ[16]在Quad-tree 节点内各桶中建立基于块的倒排文件,倒排列表中的查询按ID 升序排列,每个块维护一个最低条件文本相似度,若到来的对象与块的文本相似度小于该值,则对象不可能是当前块内查询的结果,实现组过滤。否则,在每个桶中,基于DAAT(document at a time)技术并行遍历对象中所有关键字所在的倒排列表。IQ*-tree[17]在Quad-tree 节点,根据查询到节点的最小及最大距离,生成两个ACIR,即在倒排列表中存储查询的文本相似度区间。IGPT[18]在Quad-tree 节点中建立倒排列表,查询根据偏好参数分组,且组内按相关性分值升序排列。若到来对象与倒排列表各组的文本相似度小于组中所有查询的最小文本相似度,过滤组。TPG(top-ktemporal popularity score index integrated with a subscription grouping mechanism)[19]将查询范围有共同交集的一组查询归为一组,并在其共同交集的区域,维护组流行度分值及组内拥有最大流行度分值,以实现组过滤。SBCP(segmentgen based block-wise inverted file with a cluster summary index to solve cluster publish/subscribe)[20]倒排列表内查询按照ID 插入,并分块,每个块维护查询统计信息及与其匹配的对象簇摘要信息,将与查询匹配的对象簇按相关度分组,并维护组内最大及最小相关度值,以实现组过滤。
2.3 调整空间文本索引结合机制提升过滤性能的策略
评估CQST 的查询技术紧密结合空间索引和文本索引,到来对象可同时使用两者过滤搜索空间。二者结合机制大多为空间优先,即将查询按照空间范围或地理位置进行组织,在空间节点内集成文本索引提高索引的过滤性能。为了进一步提高索引的过滤性能,研究人员计算当前节点内包含数据的空间分布和文本分布,比较空间划分与文本划分的过滤性能,通过相应的代价模型,择优选取过滤性能较强的索引组织方式。
FAST[4]虽然是空间优先的索引,但查询关联到金字塔的哪个节点,是由查询包含的关键字频率决定的。FAST 从金字塔顶层开始,尝试将查询插入到低频关键字对应的RIF 中,若该列表包含的查询数量小于阈值,则将查询插入。若查询无法插入到任何低频关键字对应的RIF 中,将查询按照关键字的字典顺序插入到OKT 中。若插入到OKT 的查询数量超过阈值,则选取查询范围较小的查询进行降维操作。AP-tree 及AP+-tree[5]利用查询集的空间和文本分布及一个划分代价模型,将一组查询自适应地划分到f个网格或f个文本有序区间,自顶向下递归构建。若查询位置较松散,则将当前节点中的查询按空间划分到f个自适应的网格中,每个查询按其查询范围属于多个网格;若文本区分度大,则按该节点当前关键字偏移度将查询划分到f个文本有序区间中,每个查询按关键字偏移度属于一个文本区间。AP+-tree 修整代价模型,在查询移动方向上增加额外的成本,以反映查询的移动,使AP-tree 适用于移动场景。LFILTER(location-based filtering algorithm)[3]采用一个代价模型确定采用MBRTrie[3]或者PT-Quadtree[3]过滤验证到来的对象。
此外,TN(triplet network for learning relevancy metric)[21]训练三元组卷积神经网络而非空间文本索引,计算新更新的对象簇是否与查询相关。
3 分布式集群上评估CQST 的过滤策略
上述工作都是基于中央服务器,即所有工作都在一台中央服务器上完成,为了进一步加快数据流中对象的匹配,研究人员扩展实时流处理系统Storm,研究分布式服务器集群上CQST 的评估,提出多个分布式空间文本数据流处理系统。如Tornado[8]、Tornado(FAST)[9]及PS2Stream[10]解决分布式集群上CBRQ 查询问题,DSkype(distributed real-time top-kspatial-keyword publish/subscribe)[18]解决分布式集群上CTkN 查询问题。SSTD(streaming spatio-textual data)[11]解决分布式集群上多种查询模型。服务器集群计算资源可分为两类:一类为全局分发单元(global routing unit,GRU),负责全局调度,将到来的对象或查询分发到相应的数据处理单元;另一类为数据处理单元(data processing unit,DPU),负责数据处理。在分布式服务器集群上评估CQST,除了需要提高系统吞吐量,减小数据处理延迟外,GRU 数据分发、DPU 工作负载均衡及数据迁移等问题也需要考虑。本文只综述比较与查询优化技术息息相关的数据分发及数据处理两个模块。(1)数据分发。如何分发数据流中到来对象及查询到相应的DPU?通常划分整个空间区域,每个DPU 对应一块空间区域,查询及对象映射到一个或多个DPU 上,因此空间区域的划分需考虑DPU 中处理的对象及查询占用的内存。(2)数据处理。如何处理映射到DPU 的查询或对象?这一问题同在中央服务器上评估CQST。
Tornado[8]在Storm 中引入了自适应的时空文本索引层,根据对象和查询负载变化动态重新分配DPU 中的数据。(1)数据分发。在GRU 上,建立全局空间索引(kd-tree),对象和查询根据地理位置分发到相应DPU。(2)数据处理。在DPU 上,构建局部时空文本索引(多个kd-tree)组织对象,kd-tree 非叶节点集成倒排列表,以匹配查询。连续查询保存在连续查询缓冲区中,以处理到来对象。
如南宋.梁楷《李白行吟图》画唐朝大诗人李白,未画任何背景,也不讲究人体比例,只在表现人物精神上下功夫,寥寥几笔,便意溢神足,使李白洒脱飘逸的形象跃然纸上。
Tornado(FAST)[9]扩展Tornado。(1)数据分发。采用索引A-Grid(augmented-grid),该索引分为两层,底层为覆盖整个空间区域的细化的虚拟网格,上层为与各DPU 对应的非重叠矩形分区。这些分区覆盖在虚拟网格之上,每个网格单元只属于一个DPU 分区。到来对象及查询根据地理位置找到网格,继而找到相应的分区。A-Grid 为每个DPU 维护包含查询的文本摘要,以尽早过滤不相关的查询,减少网络通信开销。(2)数据处理。在每个DPU,查询通过索引FAST 组织,以快速处理数据流中到来的对象。
PS2Stream[10]与Tornado 最大的不同之处在于PS2Stream 考虑所有DPU 上的最佳工作负载分配问题。(1)数据分发。基于查询及对象的空间和文本分布,提出最佳工作负载分配算法,使得工作负载总量最小,且DPU 间的工作负载均衡。从kd-tree 根节点开始,计算查询与对象的文本相似度。若该值小于阈值,比较空间划分和文本划分产生的工作负载,并选择工作负载较小的策略。否则,选择使查询及对象文本相似度变小的方向执行空间划分。这样将整个空间区域划分为多个子空间得到的索引称为kdttree。为了减轻GRU 的负担,kdt-tree 的叶节点利用网格组织,每个节点中有两张hash 表描述文本项与DPU 的映射。当对象到来时,根据文本项找到需要验证的DPU。当新查询提交时,找到查询范围覆盖的节点,将查询插入到低频关键字对应的DPU 上。(2)数据处理。采用索引GI2(grid-inverted-index)组织查询,即在网格节点中集成倒排列表。
DSkype[18]扩展IGPT 到分布式集群上以解决CTkN 问题。(1)数据分发。DSkype 为GRU 设计四种高效的、轻量级分发机制(hashing-based,locationbased,keyword-based 及prefix-based),将数据流中对象及查询分发给DPU。hashing-based 机制根据查询ID 将查询均匀地分发到各DPU,location-based 机制利用kd-tree 将地理位置邻近的查询分发到同一个DPU,且kd-tree 划分方向为最小化两个子节点代价差的方向。两类机制中,查询只会分发到一个DPU,但对象到来时需分发到所有DPU,通信成本较高。在keyword-based 及prefix-based 机制中,每个DPU 关联一个文本集合,查询根据关键字关联到多个DPU。为了降低查询关联的DPU 数,只将查询插入到前缀关键字对应的DPU 中。数据流中对象只分发到相关的DPU。(2)数据处理。利用IGPT 组织查询,以快速处理到来的对象。
SSTD[11]支持多种查询模型。(1)数据分发。在GRU上基于数据流中对象构建QT-tree(quad-text tree),旨在使DPU 保持负载平衡且总工作负载降至最低。对一组对象,QT-tree 从Quad-tree 根节点开始,计算当前节点执行空间划分及文本划分产生的负载量,选取负载量小的节点划分方式。若执行空间划分,节点被划分为4 个均等的空间节点,对象按照地理位置被插入到相应的子节点;若执行文本划分,节点被划分为4 个文本节点,对象按照代价模型被插入到使负载增量最小的子节点。当对象到来时,其按照QT-tree构建方式,插入到相应叶节点,即相应的DPU;当查询到来时,若其包含范围属性,遍历QT-tree,找到与查询范围在空间上有重叠的所有叶节点,将查询分发给相应的DPU;否则,将查询分发到所有DPU。(2)数据处理。每个DPU 对应QT-tree 的多个叶节点。在DPU 上,为每个叶节点各类连续查询构建单独的索引以处理数据流中的对象。利用FAST[4]组织范围查询,利用网格组织k邻近查询,利用扩展的哈希表集成分组技术组织CTkN 查询。
4 总结与未来发展方向
本章总结全文工作,并讨论评估CQST 的未来研究方向。
4.1 总结
4.2 未来发展方向
本文综述揭示了评估CQST 的两大趋势。
(1)追求更高效的评估CQST 的技术。①利用硬件技术提高CQST 的评估效率。通过GPU、分布式集群等硬件技术进一步加快数据流中对象的处理。AP-tree+将AP-tree 与GPU 技术结合,Tornado、PS2Stream、DSkype 及SSTD 实现了分布式系统上CQST 的评估。②牺牲精度提高数据流上对象处理效率。IQ*-tree 解决近似CTkN,判断到来的对象与查询匹配的条件是动态的,牺牲小的精度,极大提高数据流上对象处理效率。
(2)解决空间文本数据流上连续查询的更多场景。除了基本的查询需求外,CQST 的查询模型也在不断增多。①评估连续移动的CQST。AP+-tree 及Elaps 考虑了移动场景下CQST 的评估技术。②其他类型的CQST 查询模型。扩展的Rt-tree 及变体检索指定查询范围内相似度大于给定阈值的所有对象。AP-tree+解决指定查询范围内文本的近似匹配,IQ*-tree 查询近似的CTkN 对象,即到来的对象与查询相似度只要高于当前维护分值的1-ϵ倍,则对象就有可能被匹配给查询。HSFTS 及TPG 在数据流上检索与查询地理位置邻近的、时空流行度最高的Top-k个趋势关键字。SBCP 及TN 在数据流上检索与查询相关的对象簇摘要信息。
猜你喜欢
航空学报(2022年7期)2022-09-05
华人时刊(2022年1期)2022-04-26
华人时刊(2021年23期)2021-03-08
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
动漫界·幼教365(大班)(2019年10期)2019-10-28
作文新天地(初中版)(2019年6期)2019-08-15
网络空间安全(2019年10期)2019-03-20
环球时报(2009-11-25)2009-11-25
