
基于YOLOv4的空间红外弱目标检测
2021-04-09 13:44刘杨帆曹立华张云峰
液晶与显示 2021年4期
刘杨帆, 曹立华, 李 宁, 张云峰
(1.中国科学院 长春光学精密机械与物理研究所,吉林 长春 130033;2.中国科学院大学,北京 100049;3.激光与物质相互作用国家重点实验室,吉林 长春 130033)
1 引 言
空间红外弱目标检测技术是空间目标探测系统的重要组成部分,对于发现敌方导弹、飞机等各种机动目标具有极其重要的意义。通常情况下当信噪比小于3时,可以认为是弱目标。此时目标的信噪比低,它的纹理特征和结构形状特别模糊,难以进行有效检测[1-2]。特别是当目标在空中有云层或者云层较厚的情况下,由于云层的遮挡或者其他因素的干扰可能会丢失多帧目标的红外图像,这给空间红外弱目标检测带来了更大的困难。因此,研究空间红外弱目标检测对于提升我国国防能力和保障我国空域安全具有极其重要的意义[3]。
目前国外有关空间红外弱目标的研究机构主要有NASA、加利福尼亚大学、空军实验室等[4]。目前他们主要是通过两个方面来提升空间红外弱目标的检测效果,分别是红外探测技术和红外弱目标检测算法。在红外探测技术方面,主要是研究性能更高的探测器,例如使用新材料制作探测效果更好的焦平面器件,采用大面阵及单片多波段探测;其次是研究复合和双波段探测技术,例如采用雷达/红外复合检测系统。在红外弱目标检测算法方面,相较于传统算法,其越来越倾向于将深度学习应用于空间红外弱目标检测研究,类似于CNN系列算法和YOLO系列算法。相比于国外,我国的起步较晚,但国家在空间红外弱目标检测技术方面进行了大量的投入,目前也取得了一些不错的成果。
传统的红外目标检测与跟踪算法可以分为单帧检测法和多帧检测法。单帧检测法主要是通过对红外图像中的某一帧图像进行处理,从而实现对目标的检测和跟踪。通常为了提高检测的精度,往往会对得到的红外图像进行预处理。常用的预处理算法有时间域预处理[5]、变换域预处理[6]、空间域预处理[7]等。由于单帧检测往往伴随着较高的虚警,因此人们一般不单独采用单帧检测算法,往往是选择多帧图像来进行检测。多帧检测代表性算法有先跟踪后检测(DBT)[8]和先检测后跟踪(TBD)[9]算法。与传统的红外目标检测算法相比,卷积神经网络的红外目标检测算法计算难度小,适应力强。因此基于卷积神经网络的目标检测算法已越来越受到人们的重视。
目前,针对空间红外弱目标检测存在很多传统的检测算法,但是这些传统的红外弱目标检测算法存在检测率低、漏检率高以及实时性差等问题。针对以上问题,本文通过深入分析红外弱目标的几何特性,以YOLOv4[10]目标检测网络为基础,通过k-means聚类算法设计多种不同尺度的先验框以及利用多尺度融合来提高弱目标的检测精度,同时降低漏检率和虚警率。本文算法处理流程简单,提高了空间红外弱目标检测的准确率,降低了虚警率,而且检测速度达到38.99 ms/frame,具有很强的应用前景。
2 红外图像特性
对比可见光图像,红外图像成像纹理单一、成像分辨率低,使得特征网络很难提取目标的特征信息。其次,图像中的目标和周围的背景相比灰度值偏低,这导致图像中的几何轮廓较为模糊,很难提取目标的边缘信息。例如在背景相同的条件下,对同一架飞机通过红外设备和可见光设备分别进行观测,红外图像的轮廓和边缘信息较为模糊,可见光图像中的目标轮廓较为清晰,如图1所示。

图1 飞机的红外图像和可见光图像对比Fig.1 Comparison of infrared image and visible light image of aircraft
在实际应用中,不同红外图像目标的尺寸存在较大差异。针对这一差异,传统的解决方法有两种,一是构造图像金字塔,二是构造不同大小的滑动框,通过这些滑动框来实现对多尺度目标的检测,但是这两种方法都存在计算难度大、检测速度慢以及检测精度低的问题。因此本文采用目前在深度学习目标检测算法中性能特别优异的YOLOv4算法模型,在其基础上进行改进,从而实现检测精度高、实时性能优异的空间红外弱目标检测算法。图2展示了红外弱目标的多尺度特征。在图2(a)中目标的长宽所占像素为(10,12),核心像素仅占10个像素。图2(b)中,目标的长宽分别为(16,14),(17,15),核心像素为18个像素。

图2 红外弱目标像素特征Fig.2 Pixel characteristics of infrared weak target
3 YOLOv4简介
YOLOv4是Alexey Bochkovskiy基于YOLOv3的改进目标检测算法,在YOLOv3的基础上结合了一些小创新。尽管没有目标检测革命性的改变,但是YOLOv4依然很好地结合了速度与精度。如图3所示,YOLOv4主体分为输入端(Input)、主干网络(BackBone)、特征金字塔(Neck)、预测层(Predication)。不同于YOLOv3所使用的主干网络Darknet53,YOLOv4在其基础上首先将Darknet53上的resblock_body结构进行修改,使其成为CSPDarknet结构,然后将主
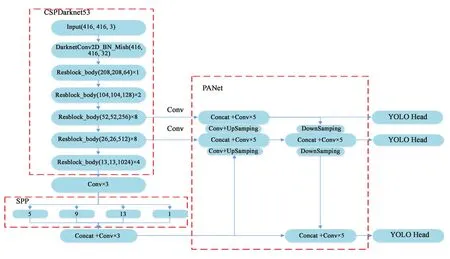
图3 YOLOv4模型结构Fig.3 Model structure diagram of YOLOv4
干网络里面的leaky_relu激活函数改为Mish激活函数,从而使Darknet53网络结构被修改为CSPDarknet53,YOLOv4的主干网络Backbone采用CSPDarknet53网络结构,具有以下优点,首先增强了CNN的学习能力,使得在轻量化的同时保持准确性,其次降低了计算瓶颈,最后降低了内存的成本。
YOLOv4为了增强数据,采用了MOsaic数据增强方法,通过该方法将4张训练图片先随机缩放,然后再随机进行拼接混合成一张新图片,这样不仅丰富了图像的数据集,而且在随机缩放的过程中增加了很多的小目标,从而使得模型的鲁棒性更好。另外,相比于YOLOv3的损失函数,YOLOv4不仅考虑了目标框的重叠面积,还考虑了中心点距离、长宽比,最终选择了CIOU_Loss的回归方式,使得预测框的回归速度和精度更高。
4 算法改进
4.1 先验框设置
在YOLOv4目标检测模型中,目标先验框的设置十分重要,它是通过k-means聚类算法对当前要训练的数据集进行统计而得出的。合适的先验框不仅可以降低模型最后的损失值,而且可以加快模型的收敛速度。在原始的YOLOv4网络中,用来提取原始图像更深语义特征是通过52×52、26×26、13×13这3个特征提取层实现的,这3个特征层将输入的原始图像分别切割成对应特征层网格的大小。如果真实框中的某个物体的中心坐落在网格框里,那么就用该网格框来对该物体进行预测,其中每个网格框包含3个由先验框的值构造出来的预测边界框。通过CIOU_Loss方法计算预测边界框和真实框之间的重叠面积、中心点距离以及长宽比。如果最后得出的值大于CIOU_Loss规定的值,那么就将其输出进行检测。另外,为了提高模型的检测效率,减少不必要的检测次数,本文采用了设置目标置信度的方法,当模型产生的预测边界框的置信度小于已经设定的目标置信度时,就直接将该框删去进行下一个检测,式(1)为CIOU_Loss[11]函数,其中ρ2是预测框和真实框中心距离的平方;c2是刚好包含预测框和真实框的最小框的对角线长度平方;υ是衡量长宽比一致性的参数;α是一个正的权衡参数。
(1)
(2)
(3)
本文训练所使用的红外图像数据集是实验室制作的数据集,而原始YOLOv4模型的先验框的大小是针对COCO数据集制作的。因此,为了降低本文模型的损失值同时提高它的检测精度,有必要对先验框的大小进行调整。因此在这里重新使用k-means聚类算法对本文的数据集进行统计,重新得到适合本文红外图像数据集的先验框。COCO数据集和本次红外图像数据集的先验框值如表1、表2所示。

表1 COCO 数据集的先验框值Tab.1 Value of anchor in COCO data sets

表2 红外图像数据集的先验框值Tab.2 Value of anchor in infrared image data sets
4.2 多尺度融合算法
YOLOv4目标检测模型框架中使用了多尺度预测[12],也就是利用13×13、26×26、52×52这3个特征层同时对输入进来的红外图像或者是视频中的目标进行检测,在检测之前都会对其特征层上的网格利用之前计算好的先验框的值进行预测边界框的绘制。这种方法虽然可以提高目标的检测精度,但是对于空间红外弱目标这种只有较少像素且规则形状特征提取较为困难的物体仍然存在漏检或者难检的问题。因此针对这一问题,本文深入分析红外弱目标图像数据集的特性,最后在YOLOv4原模型的基础上增加了一个特征尺度,以提升对小目标的检测精度。具体方法为先将52×52的PAnet层进行卷积并进行上采样,从而使它的大小成为104×104,然后将上采样后的特征层和CSPDarknet53的104×104层输出层进行张量拼接,最后再将其进行5次卷积输出到YOLO Head模块进行输出。通过张量拼接,特征层的维度会扩充,这样就能提取出更多的特征信息。同时,本文对新增加的特征尺度也采用了Mish激活函数。由于特征尺度增加了,因此先验框值也要进行调整。改变后的检测模型和先验框值如图4和表3所示。

图4 改进后的YOLOv4模型结构Fig.4 Model structure diagram of improved YOLOv4

表3 红外图像数据集的先验框值Tab.3 Value of anchor in infrared image data sets
5 实验与结果分析
5.1 实验的基础条件设置
算法的实现平台为:Ubuntu16.04TLS操作系统和Windows10 64位操作系统,I7-8700M型号CPU、openCV3.4、python3.6,使用GeForce RTX 1080 Ti型号GPU进行加速运算,在TensorFlow卷积神经网络框架下对改进的YOLOv4空间红外弱目标检测模型进行训练和测试。
5.2 实验设计
针对本文所研究的问题,利用真实红外数据制作了红外图像数据集,该数据集包含了多场景下的各种目标的红外图像,该数据集共含有图片40 402张,共包含6个类别:导弹、其他飞机、客机、战斗机、鸟、直升机。在进行实验的过程中,将其中的70%作为训练数据,20%作为验证数据,剩下的10%作为测试数据。在实验中本文还对数据集进行了随机角度的旋转,扩增数据集容量,提升了模型的泛化能力。数据集样图如图5所示。

图5 数据集样图Fig.5 Sample data set
实验主要过程如下:(1)数据采集,通过红外测量样机对检测目标进行探测,然后将视频片段每隔40帧进行截取,将截取后的图片随机打乱并标注,然后按照7∶2∶1的比例,制作成红外图像训练数据集、验证数据集以及测试数据集;(2)利用训练数据集训练空间红外弱目标检测模型;(3)用验证数据集对训练好的空间红外弱目标检测模型进行超参数调整;(4)用超参数调整完的模型对测试集进行识别;(5)最后对检测结果进行评价。
实验a:分别利用COCO数据集先验框值以及通过k-means聚类算法重新得到的红外图像数据集的先验框值在红外图像数据集上对YOLOv3模型、YOLOv4模型进行训练。在训练完成之后,分别利用红外图像测试集进行测试,最后通过比较测试结果来分析重新调整先验框对于提升目标的检测性能。
实验b:在先验框值都经过k-manes聚类算法得出后,分别利用COCO数据集和红外图像数据集来对YOLOv3、YOLOv4、MY-YOLOv4进行训练,在训练完成之后,分别利用制作好的测试数据集进行测试,最后通过分析测试结果来比较分析改进后MY-YOLOv4的性能。
实验c:用改进的MY-YOLOv4模型的检测算法,利用从长波红外相机上采集到的真实数据进行检测,最终来判断该模型对各个目标的检测效果。
5.3 实验结果分析
为了更加合理有效地对最后的检测结果进行判别,根据检测速度和检测精度要求,本文将检测速率(模型检验目标所需的时间)作为检测速度的评价指标。将检测精度(P)和召回率(R)作为检测精度的评价指标[13]。检测精度和召回率的定义如下:
(4)
(5)
式中,ZTP为检测正确的目标,ZFN为漏检的检测目标,ZFP为检测错误的目标。通过从检测精度、检测速度、召回率等3个指标来评估在红外图像数据集下使用不同先验框值对于YOLOv3和YOLOv4模型检测实验,考察用k-means聚类算法对于提升系统检测性能的大小,最终得到的模型对比结果如表4所示。

表4 实验a:红外图像数据集下不同先验框值检测结果
在验证完k-means聚类算法对于提升系统检测性能后,为了考察改进后的YOLOv4空间红外弱目标检测模型的性能,又进行了实验b,在不同数据集下对YOLOv3、YOLOv4以及改进后的YOLOv4 空间红外弱目标检测模型进行对比实验。最终得到模型实验对比结果如表5所示。
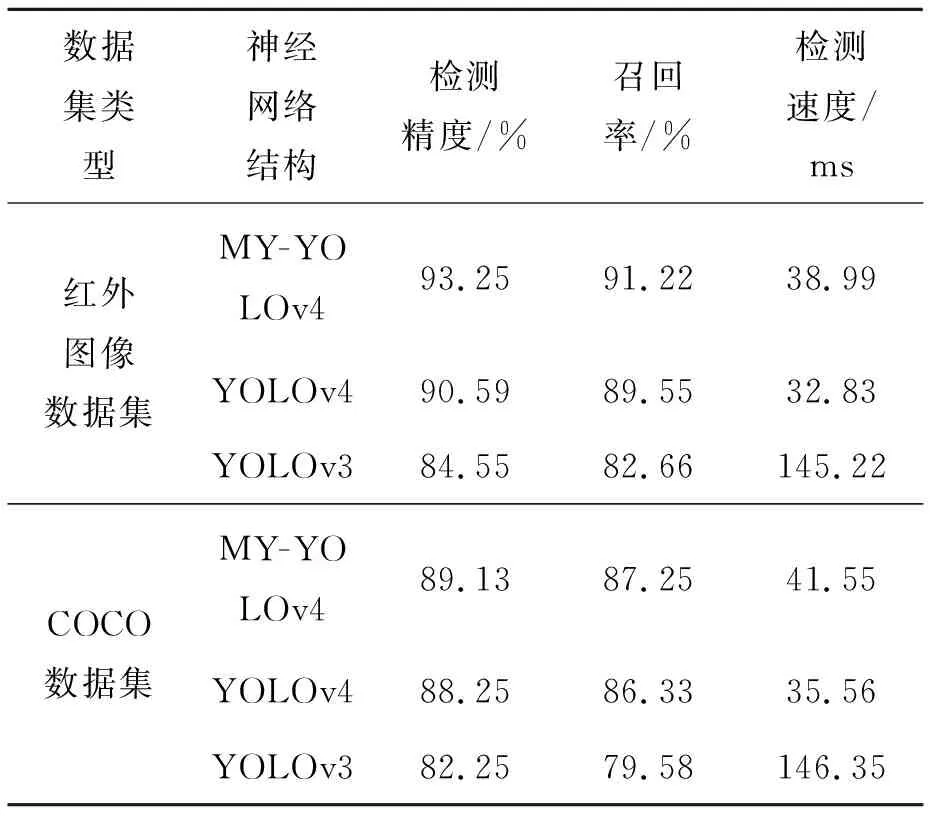
表5 实验b:模型对比结果Tab.5 Experiment b: Model comparison results
为了能够更加有效地验证本文改进的MY-YOLOv4模型的检测效果,又进行了实验c。利用从长波红外相机上采集到的真实数据进行检测,最后得到各目标的检测结果(表6),检测效果图如图6所示。
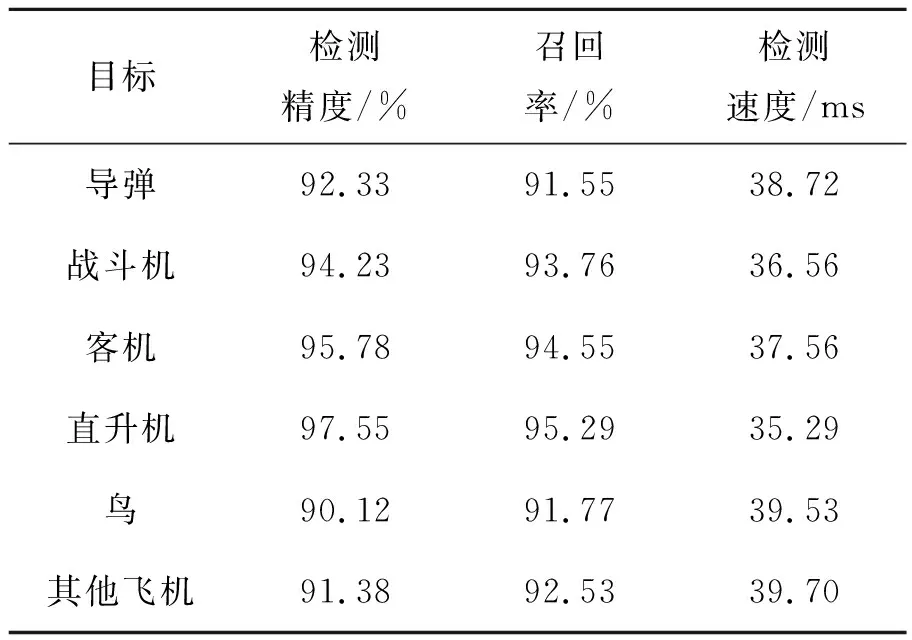
表6 实验c:模型MY-YOLOv4检测结果
由表4可以看出,在数据集相同的情况下,使用k-means聚类算法计算先验框值的YOLOv3和YOLOv4模型在检测速度变化很小的条件下,其检测精度分别提高了1.43%、1.7%,其召回率分别提高了0.55%、0.61%。因此,通过k-means聚类算法重新调整先验框可以有效提高弱目标的检测精度和召回率。

图6 检测效果展示图Fig.6 Display diagram of detection effect
另外通过表5可以看出,针对空间红外弱目标检测任务改进后的MY-YOLOv4模型相较于YOLOv4原模型在红外图像数据集以及COCO数据集上虽然在速度上损失了约6 ms,但是在检测精度上分别提升了2.66%、0.88%,在召唤率上面提升了1.67%、0.92%,同时相较于YOLOv3模型,改进后的MY-YOLOv4模型在检测速度、检测精度以及召回率方面都有很大的提升。最后通过表6可以看出,本文算法对于所要检测的各个目标(检测精度、召回率)都具有良好效果,而且都达到了实时性的要求,更适用于空间红外弱目标的检测。
6 结 论
本文针对空间红外弱目标这一检测任务,提出了基于YOLOv4的空间红外弱目标检测算法。该算法在YOLOv4模型的基础上通过提出k-means聚类算法来重新调整先验框,另外加入多尺度特征融合来进一步提高弱目标的检测精度。为了验证算法的有效性,本文充分利用COCO测试集和实验中制作的红外图像测试集,将其和YOLOv4模型和YOLOv3模型进行对比,最终得出以下结论:
(1)改进的YOLOv4算法在目标之间无云层遮挡的情况下,可实现对空间红外弱目标的准确识别。
(2)通过k-means聚类算法重新计算先验框值对于红外图像数据集的检测精度和召回率有近1.5%、0.5%的提升。
(3)在相同的情况下,改进YOLOv4模型算法对于弱目标的识别效果优于YOLOv3和YOLOv4算法。在目标之间有云层遮挡的情况下,改进的YOLOv4算法和原模型算法不能完全准确地识别出图像中的所有目标。因此针对红外图像较差以及目标被遮挡的空间红外弱目标检测还需要作进一步的研究。首先是要研究如何通过样本增广的方法对目标的数据集和测试集进行数据的扩充,提升该网络的泛化能力;另一方面是如何将目标的辐射特性这一特征加入到本文的模型判别过程中,从而实现对模型准确度和精确度的进一步提升。
(4)针对COCO数据集,改进后的MY-YOLOv4相较于YOLOv4在速度损失约6 ms的情况下,其精度提升了0.88%,召回率提升了0.92%,因此改进后的MY-YOLOv4对于COCO数据集也具有一定的提升效果。
(5)在检测速度方面,由于本文使用的硬件条件为GeForce RTX 1080 Ti,可以达到25 frame/s,已经具备了实时性的要求,目前已在工程中应用。
猜你喜欢
环球时报(2022-05-23)2022-05-23
金桥(2021年4期)2021-05-21
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2019年7期)2019-04-25
电子制作(2018年11期)2018-08-04
自动化学报(2017年5期)2017-05-14
光学精密工程(2016年3期)2016-11-07
测绘科学与工程(2016年5期)2016-04-17
探测与控制学报(2015年4期)2015-12-15
东南法学(2015年2期)2015-06-05
