
基于并行化K-means的综合能源服务客户识别
2021-04-08 08:18沈子垚袁晓玲
电力工程技术 2021年2期
沈子垚,袁晓玲
(河海大学能源与电气学院,江苏 南京 211100)
0 引言
随着综合能源服务的不断推广和互联网技术的高速发展,客户的档案信息与交易数据激增。传统的供电公司与综合能源服务企业积累了海量的营销数据。通过对营销数据的挖掘分析,能够获取客户的行为信息和状态数据,识别现有客户的特征与交易模式,预测综合能源服务需求,提高企业决策的前瞻性[1—3]。综合能源服务企业如想在激烈的竞争中保持优势,需要做好各类客户的识别与服务拓展工作。如企业能采取有效措施精准识别潜在客户,就能以较小的成本发展潜在客户,针对客户需求制定综合能源服务策略[4—8],提高投入产出比。文献[9]构建了数据仓库以整合数据资源并提取属性特征,通过信息匹配实现对潜在客户的识别。
传统的聚类算法在处理海量数据时,存在计算复杂度高和计算能力不足等问题。文献[10]优化了K-means聚类算法初始聚类中心的选取,并选用MapReduce并行编程方法,提高了传统聚类方法的计算效率。文献[11]将用户的用电行为数据按行保存于Hadoop分布式文件系统(Hadoop distributed file system,HDFS),将用电行为数据集划分为不同切片产生子数据集,利用MapReduce计算模块对各切片数据进行读取。Hadoop支持TB级别的数据和流式数据访问,但实时性较差,不适合大量小文件存储[12—13]。
在数据挖掘中,需处理大量数据,应构建简单有效的模型。数据挖掘是指通过对海量杂乱无章的数据进行挖掘,找到其中蕴含的规律和有价值的信息。数据挖掘的主要步骤包括:确定数据挖掘的需求,采集相关数据并预处理,采用合适的数据挖掘算法构建识别模型,对识别结果进行分析评估。
为进一步减少数据聚类迭代过程中的冗余计算,提高聚类算法的效率和准确性,文中针对综合能源服务潜在客户识别问题,研究基于Spark[14—17]的K-means聚类算法,优化了初始点的选取和聚类时影响因素的权值选取。文中通过并行计算提高了数据的处理速度,依据实验结果分析了算法的准确率和并行计算性能。
1 潜在客户识别数据库设计
潜在客户识别数据库的设计包括分析潜在客户的各项标签[18],利用数据仓库技术对数据资源进行整合。通过潜在客户数据库完成客户的精准识别工作,可构建完成综合能源服务潜在客户识别模型。
1.1 客户识别数据仓库
客户识别数据仓库的建立基于现有的营销业务系统及外部数据获取渠道[19],需要提取客户信息形成客户数据集。数据预处理操作包括缺失数据的补全,重复数据的删除,数据泛化等工作。基于预处理之后的数据集,可以建立综合能源服务潜在客户数据仓库。数据仓库的构建基于收入贡献、成本占用、成长性、信誉度、忠诚度等标签,潜在客户特征分析指标如表1所示。
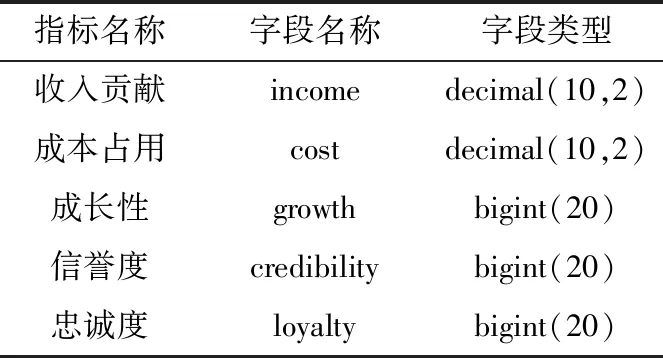
表1 潜在客户特征分析指标表Table 1 Characteristic analysis index for potential customers
对于大量数据,如无法补全缺失数据的记录和属性,应删除该部分信息。对于缺失少量非关键数据的记录,可根据部分未缺失数据的均值、众数进行填充。综合能源服务潜在客户识别的数据来源众多,可能存在大量冗余的数据。因此,可通过优化数据库范式结构以删除重复数据,对粒度较小的标签进行泛化处理。数据的泛化是指用高层次的概念取代低层次的概念,能够进一步明确数据属性的取值差异,且减少数据的计算量。
1.2 客户价值评价
综合能源服务潜在客户的价值可以用当前价值与潜在价值进行综合评估,具体的客户价值评估体系如图1所示。
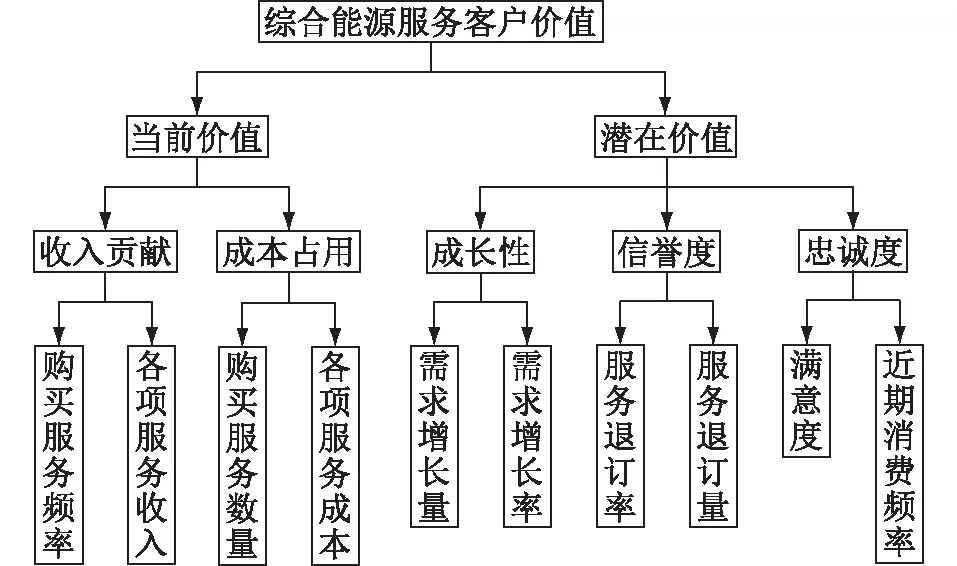
图1 客户价值评估指标体系Fig.1 Evaluation index system of customers
基于当前价值与潜在价值,可综合评估综合能源服务潜在客户。综合能源服务潜在客户的当前价值可以用收入贡献和成本占用两个指标衡量。收入贡献可以用购买服务频率和各项服务收入两个细分指标衡量。成本占用可以进一步细分为购买服务数量和各项服务成本。综合能源潜在客户的潜在价值可以用成长性、信誉度、忠诚度等指标衡量。客户的成长性包括需求增长量和需求增长率;信誉包括服务的退订率和服务的退订量;忠诚度包括满意度和近期消费频率。
1.3 指标映射数据库
由于评估潜在客户指标的量纲不同,需要将不同指标值进行无量纲化处理。文中通过构造综合能源服务潜在客户的指标映射数据库,定量计算客户之间的差异度。
若综合能源服务客户的当前价值为主导因素,则映射区间可以超出标准区间限制;而对于非主导因素的潜在价值,映射区间可以限制在一定范围内。
数据库映射关系f表示为:
f:(x1,x2,…,xn)→(y1,y2,…,yn)
(1)
式中:(x1,x2,…,xn)为评价客户价值的各个指标;(y1,y2,…,yn)为评价指标通过数据库映射,投影到映射区间的值。部分映射区间的取值如表2所示。
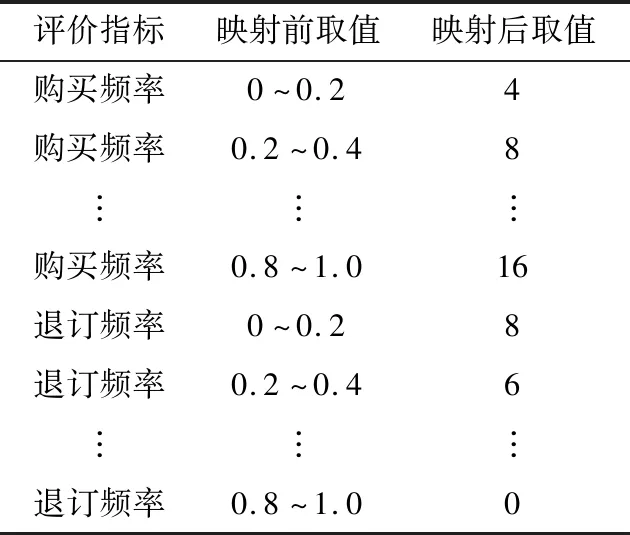
表2 部分映射数据库取值Table 2 Database value of partial mapping
在综合能源服务发展的过程中,如综合能源服务企业对潜在客户的评估标准改变,那么指标映射数据库的映射取值可能会发生变化。
2 K-means并行聚类识别潜在客户
聚类分析通过反复分区,将数据进行归类,使得同类的对象之间能够彼此联系。聚类算法能够在没有客户类别标识的前提下对客户进行分类,最大化不同类别客户的差异。聚类对象根据最大化同一簇中的相似性,最小化不同簇之间相似性原则进行划分[20]。
综合能源服务企业可以修改客户价值的映射数据库,通过聚类效果探索出适合自身的映射关系。在与综合能源客户交易的过程中,用户的价值评价体系和企业的偏好可能会发生改变,综合能源服务企业可以根据偏好改变聚类过程中映射区间的取值。
文中采用Spark平台对大数据进行并行化处理。Spark是为大数据处理专门设计的快速通用的计算引擎,该框架多任务之间的数据基于内存进行通信,消除了冗余的Hadoop分布式文件系统读写,并针对Java虚拟机 (Java virtual machine,JVM)进行了优化。因此,Spark更加适用于实时处理等数据挖掘工作,在大规模的数据计算上优于传统的MapReduce编程模式[21]。基于Spark的潜在客户识别的并行聚类模型如图2所示。

图2 并行聚类模型Fig.2 Parallel clustering model
对于传统的K-means算法,首先利用流式聚类思想优化选取初始聚类中心点,再通过映射数据库衡量不同标签对聚类算法的影响,计算聚类中心。K-means并行聚类算法运行于Spark平台,并行聚类运算完成后更新聚类中心。
2.1 初始化聚类中心的优化
文中提出一种基于流式动态聚类思想的单遍权重K均值聚类方法(single-pass-weightedK-means,SWPK-means)。首先,在原数据集上通过随机抽样构造出s个大小为n的数据子集X。算法最初将每个数据子集X中的样本权重设置为1。然后,计算第一组权值为1的样本K-means的聚类中心y,得到最小的聚类误差平方和D(y):
(2)
式中:wi为样本第i个指标的权值;yi为该样本第i个指标的数据库映射值;yi,k为第k个聚类中心第i个指标的数据库映射值。
迭代剩余的X的数据子集,每一次迭代运用K-means聚类算法在一组更大的数据集上进行聚类划分,数据集由上一次迭代的聚类中心yt-1和本次的样本子集Xt-1组成。第t次迭代有t+n-1个实体进行聚类,重复迭代s次K-means算法,直至选择出共k个聚类中心。该方法基于上一次初始化的聚类中心加速收敛,代替了传统算法的阈值收敛方法,大大降低了聚类算法的迭代次数,在进行海量数据的聚类分析时更具有优势。
2.2 客户样本隶属的中心点
定义基于Spark平台的聚类过程中的距离为欧几里德距离,对于两点y′=[y′1y′2…y′n]和y″=[y″1y″2…y″n]之间的欧几里德距离计算公式为:
(3)

(4)
快速距离算法的优势明显,可以提前计算样本向量的2范数,极大地降低计算量。易知dquick(y′,y″)≤d(y′,y″),对于同一个样本,当聚类中心pi的快速距离大于聚类中心pj的欧几里德距离时,聚类中心pi的欧几里德距离必大于聚类中心pj的欧几里德距离。此时,该样本所在簇的聚类中心应为pj。倘若聚类中心pi的快速距离小于聚类中心pj的欧几里德距离,快速距离算法失效,需要重新计算样本与聚类中心pi的欧几里德距离。
2.3 聚类效果评估
聚类效果评估采用集合内误差平方和(within set sum of squared error,WSSSE)WSSSE,WSSSE为所有数据点到距离该点最近的聚类中心的平方和:
(5)
式中:m为样本总个数;n为指标投影向量的维数;yi,j为i个样本的第j个指标投影到映射区间的值;yclose,j为第i个样本最近的聚类中心的第j个指标投影到映射区间的值。
易知随着聚类个数K的增大,WSSSE减少。当聚类个数K=m时,WSSSE=0。一般来说,最优的K取值是K-WSSSE曲线的拐点位置。在拐点处,K值的增加能最大程度地优化聚类效果。
3 案例分析
文中选取2017—2019年常州市供电局综合能源服务相关的部分负荷数据以组成客户识别数据仓库。此外,客户数据集加入实地客户集中调研及获取外部数据渠道提取的客户信息。将数据集的收入贡献、成本占用、成长性、信誉度、忠诚度等标签进行泛化处理,转化为客户的当前价值和潜在价值作为输入。对潜在客户案例及不同的数据挖掘算法进行对比分析,得出最优的挖掘算法。最终输出综合能源潜在客户及客户类型,针对性地对各类客户推广综合能源服务。
3.1 模型构建
客户的当前价值能帮助综合能源服务企业评估客户的购买力,且基于客户的潜在价值可衡量客户在后续交易中带来的利润。文中结合综合能源客户的历史数据,采用基于数据挖掘中的K-means聚类方法进行定量分析,利用矩阵分类法建立综合能源潜在客户的二维细分模型,如图3所示。

图3 基于当前价值与潜在价值的客户分类Fig.3 Customer classification based on current value and potential value
Ⅰ类用户的当前价值较高,且该类客户较为稳定,综合能源服务企业与该类用户合作可以获取较大的利润。Ⅱ类用户的当前价值同样较高,但综合能源服务企业无法满足客户的综合能源服务需求,导致后续交易过程中用户的潜在价值较低,需要投入一定资源激活,避免该类用户转向竞争对手。Ⅲ类用户的当前价值较低,但具有较大的发展潜力,同样属于综合能源服务企业的发展对象。Ⅳ类客户的当前价值和潜在价值都较低,该类客户购买力有限,对于综合能源服务需求较少,属于综合能源服务中的“劣质客户”,不属于综合能源服务的交易对象。
3.2 结果分析
3.2.1 聚类效果分析
文中通过综合评价指标F评估算法的性能:
(6)
式中:TP为正确识别潜在用户的数量;P为被分为潜在用户的类别中实际为潜在用户的比例;R为潜在用户被正确识别的比例,用于衡量覆盖面;FP为将非潜在用户识别为潜在用户的数量;FN为将潜在用户识别为非潜在用户的数量。
在不同的映射权值下,聚类结果不同。客户当前价值与潜在价值的映射权值为(0.67,1.33)时,聚类结果如图4所示。

图4 K-means聚类结果Fig.4 K-means clustering results
Ⅰ类客户449个,正确识别416个;Ⅱ类客户448个,正确识别448个;Ⅲ类客户262个,正确识别229个;Ⅳ类客户67个,正确识别67个。综合评价指标F为92.6%。
映射权值表示综合能源服务企业对该类价值的重视程度。以客户潜在价值为主导时,客户的潜在价值映射区间大于当前价值的映射区间,Ⅰ类用户与Ⅲ类用户的潜在价值都较高,主要差异为客户当前价值。当前价值的映射区间较小时区分度不明显,此时聚类模型无法很好地区分Ⅰ类用户与Ⅲ类用户。
客户当前价值与潜在价值的映射权值为(1,1)时,基于权值的K-means算法聚类结果如图5所示。

图5 基于权值的K-means聚类结果Fig.5 Weighted K-means clustering results
Ⅰ类客户431个,正确识别423个;Ⅱ类客户448个,正确识别448个;Ⅲ类客户280个,正确识别272个;Ⅳ类客户67个,正确识别67个。综合评价指标F为98.6%。
设映射权值为(1,1),SPWK-means算法聚类结果如图6所示。

图6 SPW K-means聚类结果Fig.6 SPW K-means clustering results
Ⅰ类客户431个,正确识别426个;Ⅱ类客户448个,正确识别448个;Ⅲ类客户280个,正确识别275个;Ⅳ类客户67个,正确识别67个。综合评价指标F为98.7%。
客户的当前价值与潜在价值的映射区间相同时,客户的当前价值与潜在价值重要程度相近,聚类结果更符合矩阵分类法建立的二维细分模型。优化特征向量的权值将改善基于权值的K-means算法与SPWK-means算法的聚类性能。在权值相同且测试数据较少的情况下,初始中心点的选取对最终的聚类结果影响不大,这表明基于权值的K-means算法具有良好的稳定性。
为验证进一步不同算法的聚类效果,对原有的数据集进行扩容,不同扩容倍率下聚类算法的误差平方和如图7所示。
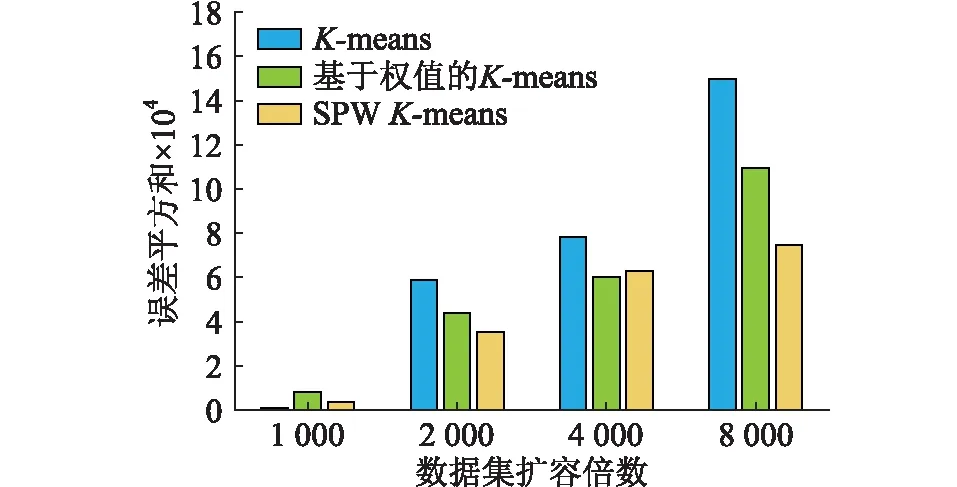
图7 不同扩容倍数下的误差平方和Fig.7 MSE with different expansion times
由图7可知,随着数据集扩容倍数的增长,SPWK-means的聚类误差增加趋势小于K-means算法和基于权值的K-means算法。在数据集扩大的情况下,初始聚类中心点选取的优劣程度将决定最终的聚类性能。
3.2.2 性能分析
为了检验算法的执行效率,对20 000个测试数据进行算法的时间复杂度分析,并行聚类部分执行时间,如图8所示。

图8 不同并行度下的算法执行时间Fig.8 Algorithm execution time with different parallelism
随着算法并行度的增加,聚类模型执行的时间优化幅度减少。这是因为增加算法的并行度能充分利用空闲线程,提高运行效率。同时,并行度为4时的算法运行时间小于并行度为8的时间,这是由于随着并行度的提高,运行节点之间的数据传输会消耗资源。
采用加速比Speedup和扩展比E测试并行K-means算法的并行化性能,加速比Speedup和扩展比E的公式为:
(7)
(8)
式中:Ts为单节点进行运算消耗的时间;Tp为p个节点进行运算所消耗的时间。
通过聚类算法的串行执行时间与并行执行时间的比率来判断并行效果,不同聚类算法的加速比如图9所示。

图9 不同并行度下聚类算法的加速比Fig.9 Speedup of clustering algorithm with different parallelism
在不同并行度下,文中提出的SPWK-means算法加速比优于其他聚类算法。添加节点后,处理速度变快,但加速比未能符合线性增长。
文中通过对数据集的规模进行扩展,比较SPWK-means算法在不同节点数量下的扩展比,如表3所示。
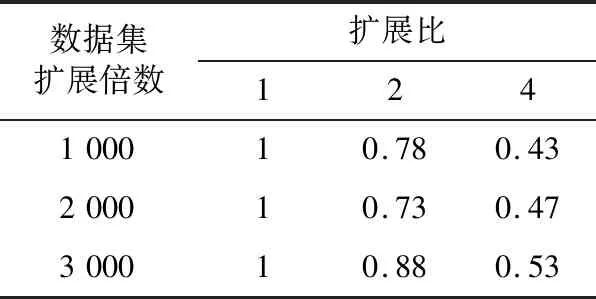
表3 SPW K-means聚类算法的扩展比Table 3 The expansion ratio of SPW K-means clustering algorithm
Spark框架更加适合大量数据的处理,当数据量足够大时,集群并行化能够有效提高聚类算法的速度,数据集越大,并行效果越明显。这是因为数据量增加,节点更容易发挥它的计算能力,节点利用率提高。而随着节点的增加,扩展比未能线性增加。这是因为在集群上运行时,平台启动,任务调动与数据通信等因素会影响聚类算法的运行。
4 结语
文中针对综合能源服务潜在客户的精准识别问题,整合了近期的客户信息,建立客户识别数据库;基于流式动态聚类的思想优化初始聚类中心的选取,分析了客户的不同标签并用标签的映射权值来衡量对价值的影响;基于分布式内存计算框架Spark进行并行化聚类,达到了综合能源服务潜在客户精准识别的目的。
文中将改进后的K-means聚类算法在集群上并行运行,比较聚类的准确率。通过比较不同并行度下的算法执行时间、加速比、并行度,验证并行化计算的高效性。结果表明基于Spark平台的改进K-means算法不仅能够有效利用闲置CPU内核的运算能力缩短训练建模时间,且能根据各类标签对客户价值的优化调节映射权值提高分类的精度。针对海量数据集,调节聚类算法的并行度可以减少算法执行时间,这说明该算法具有良好的扩展性。但基于Spark框架的K-means聚类算法本身具有局限性,未来如何在不同场景下对聚类算法进行并行化设计有待进一步实践。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
小学科学(2020年5期)2020-05-25
铁道通信信号(2019年6期)2019-10-08
————不可再生能源
家教世界(2019年4期)2019-02-26
自动化学报(2017年7期)2017-04-18
知识经济·中国直销(2017年3期)2017-04-16
雷达学报(2017年6期)2017-03-26
现代电子技术(2016年15期)2016-12-01
互联网天地(2016年1期)2016-05-04
