
基于EDA和回译的导游投诉文本混合增强方法
2021-04-06 10:55余佳雨詹瑾瑜
计算机技术与发展 2021年3期
余佳雨,李 响,詹瑾瑜,江 维,曹 扬,杨 瑞
(1.电子科技大学 信息与软件工程学院,四川 成都 610054;2.中电科大数据研究院有限公司,贵州 贵阳 550022;3.提升政府治理能力大数据应用技术国家工程实验室,贵州 贵阳 550022)
0 引 言
近年来中国经济高速发展,旅游逐渐成为人们休闲娱乐的选择之一。随着游客人数越来越多、旅游可选地点愈发丰富,旅游过程中各种纠纷日趋复杂,负面新闻频发,如宰客、随意加价、强制消费等导游违规事件的相关新闻报道[1]。2017年12月黑龙江雪乡发生导游用威胁、辱骂手段强制游客参加自费项目事件,甚至打伤了两位游客;2018年5月10名中国游客在泰芭提雅旅游遭遇中国籍黑导游恐吓、逼迫购物,经历“大逃亡”的事件;2019年11月福建厦门鼓浪屿导游威胁游客视频在网络热传。这些负面的新闻不仅严重影响了景区形象,还暴露出旅游市场存在监管漏洞。
人工处理旅游投诉需要耗费大量人力,因此使用机器学习算法从导游投诉文本数据中挖掘出导游违规事件,辅助旅游监管人员工作,为旅游监管提供依据,成为一个必然趋势。然而,由于传统旅游业与大数据结合过程中存在着信息孤岛,导致导游投诉文本数据单一、难以获取等问题。为了改善原始导游投诉数据集存在的样本不平衡和语料不丰富的问题,如何对这些导游投诉文本进行文本增强以满足导游违规行为识别需要,是一个迫切需要解决的问题。
图像领域的数据增强技术已经比较成熟,通过对图像的翻转、旋转、镜像、高斯白噪声等技巧实现数据增强,以帮助训练更强大的模型,尤其是数据集较小的时候。然而在自然语言处理领域,文本数据增强技术仍处于探索阶段。Wang等人使用文本分类技术对推文分析,在词嵌入模型中使用K-近邻算法(KNN)寻找同义词对推文数据进行增强[2]。Sennrich等人使用自己训练的模型对不完整的语料进行翻译,将得到的结果和原语料混合得到增强的训练数据,在机器翻译任务上取得了更好的结果[3]。Fadaee等人先替换每个文档中的稀有词,再用LSTM语言模型翻译并校验去掉不合理的结果,得到增强文本数据在WMT15英德翻译任务上取得了一定的效果[4]。Xie等人引入unigram噪声(将目标词替换为根据unigram分布得出词)和空白噪声(将目标词替换为占位符),在IWSLT 2015的英德翻译任务上取得了不错的结果[5]。Hu等人提出了一个结合变分自动编码器(VAE)和整体属性识别符的神经生成模型,在斯坦福SST数据集和IMDB数据集的情感分析任务上比之前的方法生成的文本更准确[6]。Yu等人提出了QANet框架,使用了带有注意力机制的神经机器翻译模型将英文语料翻译为法文再翻译回英文以进行训练文本增强,在自动问答任务的SQuAD数据集上取得了更好的结果[7]。Wei等人针对文本分类任务提出了一种EDA(easy data augmentation)文本增强方法[8],该方法在较小的数据集上可以显著提高分类效果并减少过拟合。上述的多数方法都是在特定任务上进行的,如机器翻译、机器阅读理解,虽然在它们之间相互比较有一定困难,但仍然可以在是否需要训练语言模型和是否需要额外数据这两方面对它们进行对比。对于是否需要训练语言模型方面,上述大多数方法都是需要的;对于是否需要额外数据方面,文献[4]的翻译增强方法、文献[6]的VAE方法和文献[7]的回译方法都是需要的。相比于其他方法,EDA方法的优势在于不需要训练语言模型并且不需要额外数据。因此,该文提出的方法是基于EDA方法和不需要训练语言模型的回译方法,具有简单易用的优势。
针对导游违规行为识别中导游投诉文本数据样本不平衡和语料不丰富的问题,该文提出了一种基于EDA和回译的导游投诉文本混合增强方法,从EDA方法和回译方法两个方面得到增强后的导游投诉文本数据,混合生成新的数据集。并将该方法应用到了实际的导游违规行为识别系统中进行测试和验证。在实验中,基于EDA和回译的导游投诉文本混合增强方法与原始投诉文本数据、传统的EDA文本增强方法、传统的回译文本增强方法进行了分析与对比。实验结果表明,在实际的导游违规行为识别系统中,该方法相比于其他两种方法的文本增强效果更好,相比原始数据集其准确率提高了7.4%,可以有效地提升导游违规行为识别系统的准确率。
1 文本增强方法
1.1 EDA方法
传统文本增强方法都是基于原文本同义词替换实现的,而EDA方法在此基础上进行扩充,增加了另外三种方式,共由四种不同方式组成,包括:同义词替换、同义词插入、删除、交换词语位置。
具体操作如下:
(1)同义词替换:从一段导游投诉文本中随机选取一个非停用词,使用近义词预测工具找到选取词的同义词,然后在原句中把选取词替换为其同义词。操作对当前投诉文本重复n次。
(2)同义词插入:从一段导游投诉文本中随机选取一个非停用词,使用近义词预测工具找到选取词的可替换的备选词,将该备选词插入这段文本某随机位置。操作重复n次。
(3)删除:从一段导游投诉文本中随机选取一个词,然后删除它。操作重复n次。
(4)交换词语位置:从一段导游投诉文本中随机选取两个不同单词,然后交换它们的位置。操作重复n次。
以上四种操作都包含参数n,它表示对当前投诉文本的操作次数,具体公式为n=αl,操作次数n由当前导游投诉本文的单词改变比例α和当前导游投诉本文单词个数l决定。此外,对于每条导游投诉文本,文本数据增强生成的新的投诉文本条数为naug,naug为4的倍数,四个操作分别的执行次数均为naug/4。导游投诉文本的EDA增强示例如表1所示,原始的导游投诉文本为“导游黑心变更行程,诱导逛街购物”。

表1 EDA增强示例图
1.2 回译方法
回译是文本数据增强的常见方法,回译顾名思义就是将源语言翻译为中间语言,再把中间语言翻译回源语言,中间语言通常选取大语种语言(如英语)。回译的技术方案有两种,第一种是使用优质语料自行训练机器翻译模型,第二种是使用大公司提供的在线翻译工具或翻译API,如百度翻译、谷歌翻译、有道翻译等。
针对第一种技术方案,机器翻译(MT)是借助机器将一种自然语言文本(源语言)翻译成另一种自然语言文本(目标语言)[9],机器翻译方法通常可分成三大类:基于规则的机器翻译(RBMT)、统计机器翻译(SMT)和神经机器翻译(NMT),现在主流且较为成熟的方法是神经机器翻译[10]。虽然NMT方法在机器翻译上有着优异的表现,但是它仍存在着以下几个问题:
(1)很难寻找到一个合适的数据集;
(2)语料库对结果的影响很大,即使量级差不多,但不同领域的语料却能对翻译效果产生很大的差别;
(3)超参数设置对翻译效果的影响较大;
(4)训练所需的时间成本较大,同时训练规模较大时需要较大的硬件显存支持。
由于上述原因限制,该文采用了第二种方案。
第二种技术方案是使用大公司提供的翻译API进行回译,翻译方法已经被封装好了,只需要通过API先将中文翻译为英文,再将英文回译为中文即可。第二种方案比第一种方案更简单、快速、节省资源。该文使用这种方案来实现回译,对导游投诉文本进行数据增强。算法用JavaScript语言编写,在Node.js环境运行,参数为请求翻译的内容、翻译源语言、译文语言。第一轮翻译,将翻译源语言设置为中文、译文语言设置为英文;第二轮回译,将翻译源语言设置为英文、译文语言设置为中文。导游投诉文本的回译增强示例如图1所示。

图1 回译增强示例
2 基于EDA和回译的混合增强方法
EDA文本增强方法和回译文本增强方法都是常见的且效果不错的文本增强方法,但这两种方法互相独立。该文将两种方法结合起来,对导游投诉文本进行混合增强,即将两种方法得到的增强文本数据混合在一起作为新的训练数据,以获得更多的训练数据和文本特征,因此在后续的导游违规行为识别任务中可以取得更好的准确率。基于EDA和回译的混合增强方法将导游投诉文本分别送入EDA模块和回译模块,两个模块相互独立,可以并行执行,其组成如图2所示。

图2 基于EDA和回译的混合增强方法
针对混合增强方法的EDA模块,每次迭代将输入的一条导游投诉文本进行分词,根据参数naug,使四个操作函数(插入、删除、同义词修改、交换词语位置)分别执行naug/4次。例如当naug的值为8时,四个操作函数分别执行2次,1条原始文本便可以生成得到8条新文本。EDA模块的插入和同义词修改操作都使用了同义词预测工具,通过Synonyms中文近义词工具包来实现。EDA模块将四种操作得到的增强文本混合并打乱顺序作为输出结果,并结束一次迭代。遍历所有导游投诉文本,便可以得到增强后的导游违规投诉语料。同时,考虑到naug参数对最终增强效果的影响,参数选取过大可能导致过拟合,因此需要以4为倍数设置naug参数并对比不同naug取值的增强效果,从中选取最优取值。
针对混合增强方法的回译模块,每次迭代将一条导游投诉文本翻译源语言设置为中文、译文语言设置为英文,翻译得到英文的投诉文本。再将英文投诉文本输入到回译流程中,将翻译源语言设置为英文、译文语言设置为中文,得到回译模块的输出结果。例如,输入“随意更改行程,压缩游览时间”这段原始导游投诉文本,经过汉译英回译模块,得到中间语句“Feel free to change itinerary and reduce tour time”,接着将中间语句输入进英译汉回译模块,最终输出得到回译文本“随意更改行程,缩短游览时间”。1条原始文本可以生成1条新的文本。遍历所有导游投诉文本,便可以得到增强后的导游违规投诉语料。
文中混合增强方法的EDA模块和回译模块可以并行操作,若EDA模块耗时为t1,回译模块耗时为t2,若t1>t2,则文中混合增强方法总耗时为t1,否则总耗时为t2;两个模块返回增强后的导游投诉语料后,混合得到最终的导游投诉增强文本。
3 混合文本增强方法在导游违规行为识别系统中的应用
实验的硬件环境为一台CPU为2.9 GHz双核Intel Core i5、内存为8 GB的macOS操作系统计算机,软件编程语言为Python和JavaScript。
导游违规行为识别是一个文本多分类任务,其中导游违规行为分为五类:
(1)强迫购物或消费;
(2)更改或终止行程;
(3)餐饮或住宿违规;
(4)导游无资质或无导游证;
(5)殴打辱骂。
将Word2Vec[11]作为文本表示,使用梯度提升决策树(LightGBM[12])分类算法对导游投诉文本进行识别和分类,识别出导游投诉本文最大可能性的导游违规行为。导游违规行为识别步骤包括:数据收集、数据增强、文本预处理、分类器训练、分类效果评估,如图3所示。
3.1 数据收集
导游违规行为识别的训练数据是有标签的导游投诉文本,来源于人民网旅游投诉平台,包含游客对酒店、航空、旅行社、导游等方面的投诉,实验对平台中关于导游的投诉文本数据进行了爬取,共获得757条投诉文本,再根据导游违规行为类别对投诉文本打标签。
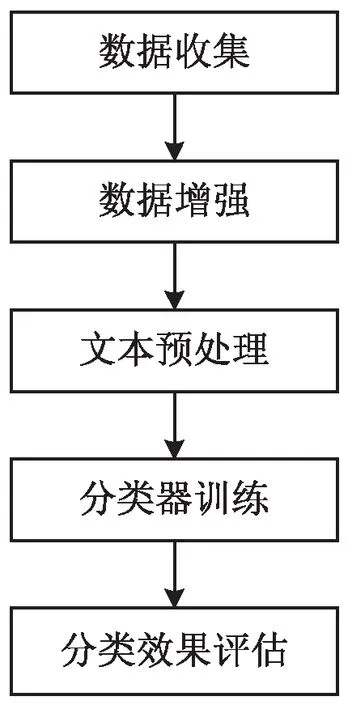
图3 导游违规行为识别的步骤
3.2 数据增强
为了验证基于EDA和回译的导游投诉文本混合增强方法对提升导游违规行为识别准确率的有效性,进行了四组实验,实验文本数据分别采用原投诉数据组、EDA文本增强组、回译文本增强组和文中的混合增强组。实验还测试了不同参数对EDA方法增强效果的影响,通过调整文本增强参数naug,得到最优的增强效果时的参数取值,并将该参数取值作为EDA方法的基准。
3.3 文本预处理
导游违规行为识别系统使用了Word2Vec词嵌入方法作为文本表示方法,可以捕获词语的语义和句子中词语的顺序,这些都是离散表示方法(如词袋模型、N-Gram)不具备的。实验爬取了“旅游新闻网”的旅游新闻语料,并使用旅游新闻语料构建了面向旅游领域的词嵌入模型,以得到更为准确的导游违规行为投诉文本表示信息。
得到供Word2Vec模型训练的旅游新闻语料后,对训练语料使用分词工具jieba进行分词,再使用Gensim库提供的Word2Vec工具进行模型训练,步骤如下:
(1)将分词后的语料转为one-hot编码的向量作为输入;
(2)根据参数进行词语的遍历;
(3)训练模型得到隐藏层权重矩阵和词向量。
3.4 分类器训练
导游违规行为识别系统采用LightGBM分类算法。LightGBM通过基于梯度的单边采样(GOSS)排除很大比例的小梯度的样本来进行信息增益计算,相对于更大梯度的数据样本,小梯度样本通常在计算信息增益时的作用不大,GOSS的目标是不使用全部数据规模获得精准的信息增益估计。LightGBM使用独有特征打包(EFB)将多个独有特征进行打包以减少特征数量,找到最优的独有特征进行打包,这是一个NP难的问题,可以用贪心算法达到相当好的近似,既可以有效减少特征数量,又没有降低分裂点的决策精度。
3.5 分类效果评估
导游违规行为识别是一个多分类任务,评估分类效果有四个预测结果:TP(真正例)、FP(假正例)、TN(真负例)、FN(假负例),常见的评估指标有精确率(precision)、召回率(recall)、F1-score,其公式分别为:

(1)

(2)
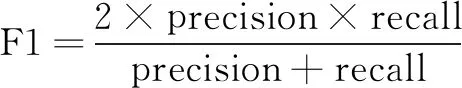
(3)
F1-score是调节精确率和召回率的综合指标[13],常用于评估二分类问题。在多分类任务中,将n分类的评估拆成n个二分类的评估,常用的评估指标有Macro F1[14](计算每个二分类的F1-score,n个F1-score的平均值即为Macro F1)和Micro F1[15](将n个二分类评价的TP、FP、FN对应相加,计算准确率和召回率,这样计算得到的F1-score即为Micro F1)。一般而言,Macro F1、Micro F1越高的分类效果越好,而Macro F1受样本数量少的类别影响大,考虑到数据集存在数据不平衡的问题,因此采用Micro F1作为本实验的评估指标。
3.6 实验结果分析
该实验首先进行文本增强参数naug对EDA方法的增强效果评价,以得到最优增强效果的naug取值,实验结果如表2所示。由实验结果可知,参数naug从4倍到8倍再到16倍时准确率依次提升,但到32倍时准确率却低于16倍时的准确率,原因可能是发生了过拟合。naug取值对文本增强的性能影响如图4所示,其中的性能提升率是使用数据增强方法相对于原始数据在导游违规行为识别的Micro F1值的提升百分比。因此,参数naug为16时,EDA方法的增强效果最优,后续实验将其作为文中混合文本增强方法的参数naug取值。
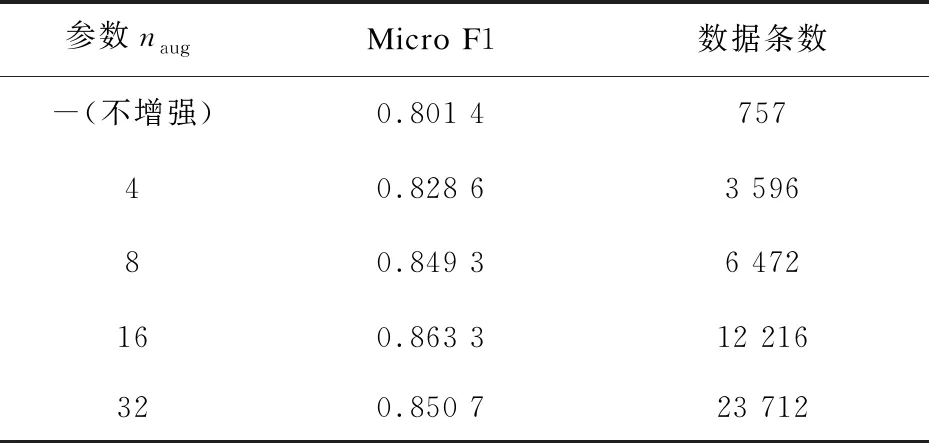
表2 naug对EDA增强效果的影响
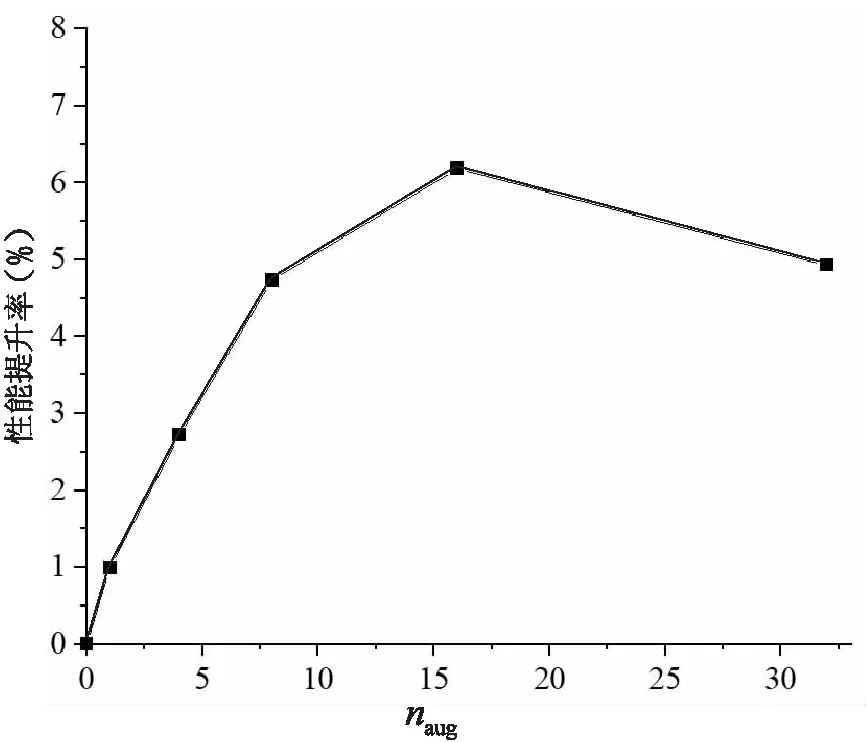
图4 naug对EDA文本增强性能提升率的影响
实验对四种文本增强方法在导游违规行为识别的Micro F1指标以及增强后的文本条数进行了比较,如表3和图5所示。EDA组、回译组、混合组比原始投诉数据组分别提升了6.2%、5.6%、7.4%,这说明使用文本增强方法对于提升导游违规行为识别的准确率都是有效的。对比EDA组和回译组,基于EDA的文本增强方法比基于回译的文本增强方法在导游违规行为识别准确率上提升了1.4%,说明EDA方法能够提供更多特征。对比三种文本增强方法,从实验结果可知,文中混合增强方法应用于导游违规行为识别中使准确率达到了87.54%,相对于原始数据集精度提升了7.4%,同时也优于其他两种文本增强方法。

表3 原始数据组和三种文本增强方法的实验结果
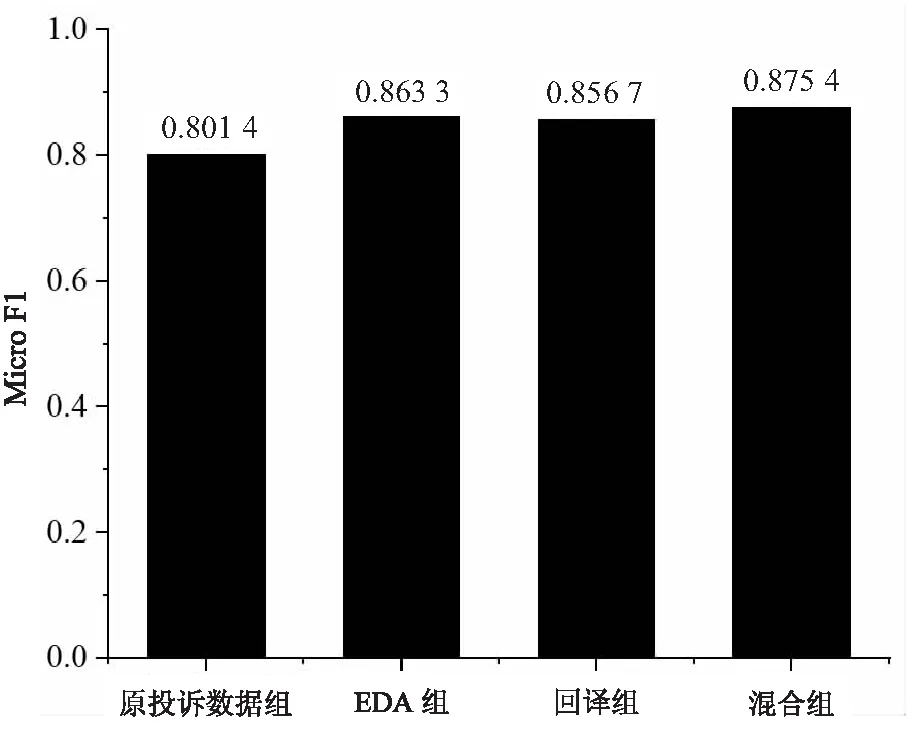
图5 原始数据组与三种文本增强方法的 Micro F1对比
4 结束语
使用机器学习、自然语言处理等技术对导游投诉文本进行违规行为识别,有助于旅游市场的智慧监管,节省了旅游监管的人力物力,还可以帮助消费者规避风险、提高旅游体验。但导游投诉文本语料单一、获取困难,针对这一问题,提出了一种基于EDA和回译的导游投诉文本混合增强方法,从EDA和回译两个角度对导游投诉文本进行数据增强,并将返回的增强语料进行混合得到最终的增强文本数据集,并且在实际的导游违规行为识别系统中进行了应用与验证。
实验结果表明,该方法比传统的EDA文本增强方法和回译文本增强方法具有更好的准确率提升性能,相比原始导游投诉数集,在导游行为识别准确率上提高了7.4%。基于EDA和回译的导游投诉文本混合方法适合于数据量较少的分类任务,具有较高的实用价值。
猜你喜欢
现代计算机(2021年33期)2022-01-21
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
奇妙博物馆(2021年2期)2021-03-18
健康体检与管理(2021年10期)2021-01-03
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
东坡赤壁诗词(2017年3期)2017-07-05
党的生活(黑龙江)(2016年10期)2016-10-17
