
基于门控循环单元神经网络的交通流预测模型
2021-03-30 11:59李宗花
淮阴师范学院学报(自然科学版) 2021年1期
沈 潇, 李宗花
(淮阴师范学院 计算机科学与技术学院, 江苏 淮安 223300)
0 引言
随着我国经济的快速发展,城市交通基础设施建设却远没有跟上迅速增长的交通需求,呈现常规公共交通萎缩、出租车和私人小汽车迅速增加、轨道交通管理技术水平有待提高等现象. 由此引发交通拥挤、环境污染、以及能源问题等. 随着大数据技术的发展,通过对交通数据的分析和统计进一步促进智能交通系统的发展成为可能. 智能交通系统中,实时交通流预测尤其重要. 对出行者来说,可以提前规划路线,避免拥堵道路;对于城市交通管理者来说,可调控交通流均匀分布,保持平稳的运行状态,减少某一主干道路的交通拥堵状况,提高城市交通的运输效益;还可以借助大数据和人工智能技术,自动调节干线交通的信号灯协调控制,减少车辆在交叉路口的停留时间和次数,从而减少环境的污染. 可见,实时交通流的预测可以为交通管理、控制和优化提供科学指导.
在大数据平台环境下,基于深度学习的交通流预测是当下智能交通领域研究的热点[1]. 学者们聚焦于交通流时间序列、交通流潜在趋势等方面进行交通流预测模型的研究. 对于交通流时间序列研究方面,陈小波等[2]考虑路网所有路段之间的时空相关性,提出了一种基于稀疏混合遗传算法,构建了最小二乘支持向量回归(LSSVR)模型,该预测模型可减少高维数据的冗余. 王祥雪等[3]构建了基于长短期记忆网络(LSTM)的城市快速路短时交通流预测模型,通过对交通流的实现时间序列进行重构和标准化处理,从而减小模型的样本依赖性. 然而,基于时间序列的模型会产生一些残差,导致预测精度有所降低. 对于提升交通预测精度研究方面,Lv Y等[4]使用层叠自编码器,取得了较高的精度. 沈夏炯等[5]在训练过程中,通过不断调整弱学习器的权重,纠正模型的残差,采用梯度提升回归树进行短时交通预测,具有更好的精度. 罗向龙等[6]则认为交通数据潜在的趋势对预测结果具有一定的影响,因此该团队基于深度信念网络模型(DBN),经过无监督的逐层特征训练和有监督的参数微调,抽象出交通流的本质规律,提高交通流预测的精度. Huang[7]等则将深度置信网络和多任务协同回归相结合来捕捉交通数据中的随机特征,进一步提升预测准确度. 针对复杂交通情况,黄廷辉等[8]则在梯度优化决策树模型的基础上,加入了时间、道路、天气等特征,设计了分布式城市交通实时预测模型,以应对城市复杂路况的预测,取得良好效果.
以上预测模型研究的重点主要是考虑交通流的预测精度问题,较少考虑交通流实时数据的处理速度问题,忽略了低延迟和实时处理效率的要求. 因此,本文旨在研究兼具高吞吐量和低延迟的实时交通流预测.首先,通过流式处理框架Flink和消息系统Kafka构建大数据平台,完成交通数据的采集,使之具备高效的大数据处理能力;然后,对采集的交通数据进行清洗处理和存储;最后基于门控循环单元神经网络构建交通流预测模型.
1 大数据处理技术
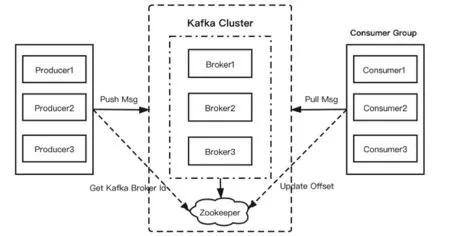
图1 Kafka结构图
1.1 Kafka简介
Kafka是一个分布式流的处理平台[9]. 具有快速、可扩展和可容错的分布式消息处理能力. 同时,Kafka还具有高吞吐、内置分区和支持数据副本的特性,适合在大规模消息处理场景使用. Kafka结构[1]如图1所示.
由图1可见,Kafka由Producer、Consumer和Broker组成. 其中Producer是消息生产者,负责向Kafka Broker发送消息;Consumer是消息消费者,负责消费Kafka上的消息;Broker充当Kafka的服务端,多个Broker组成Kafka集群[10]. Kafka的消息通过主题(Topic)进行分类,主题可被分为多个分区(partition),一个分区就是一个append log文件. 消息以追加的方式写入分区,可以保证消息在单个分区内的顺序[9]. 因此,Kafka通过分区来实现数据冗余和伸缩性,从而提升数据处理的性能[10].
1.2 Flink简介
流处理框架是构建实时计算平台的关键,当前主流的流处理框架有Flink、Storm和Spark Streaming[11]. 其中Storm延迟低,但是吞吐量小;Spark Streaming 通过采用微批处理方法实现了高吞吐,但是牺牲了低延迟和实时处理能力;而Flink兼具低延迟和高吞吐,同时还具有分布式、高性能和随时可用的特点. Flink分布式的特点,可将大型的计算任务分成许多小的部分,每个机器执行一个部分;高性能的特点能够确保在机器发送故障时自动延续任务进行. 使用Flink可以降低成本和运维难度.
Flink的数据处理组件分为数据输入、数据处理和数据输出3部分,Flink对数据流的抽象称为Stream,程序运行时,数据会映射到数据流(streaming dataflow). 而数据流由流和转换运算符组成,每个数据流起始于一个或多个source,并终止于一个或多个sink,其数据流的处理过程[12]如图2所示.
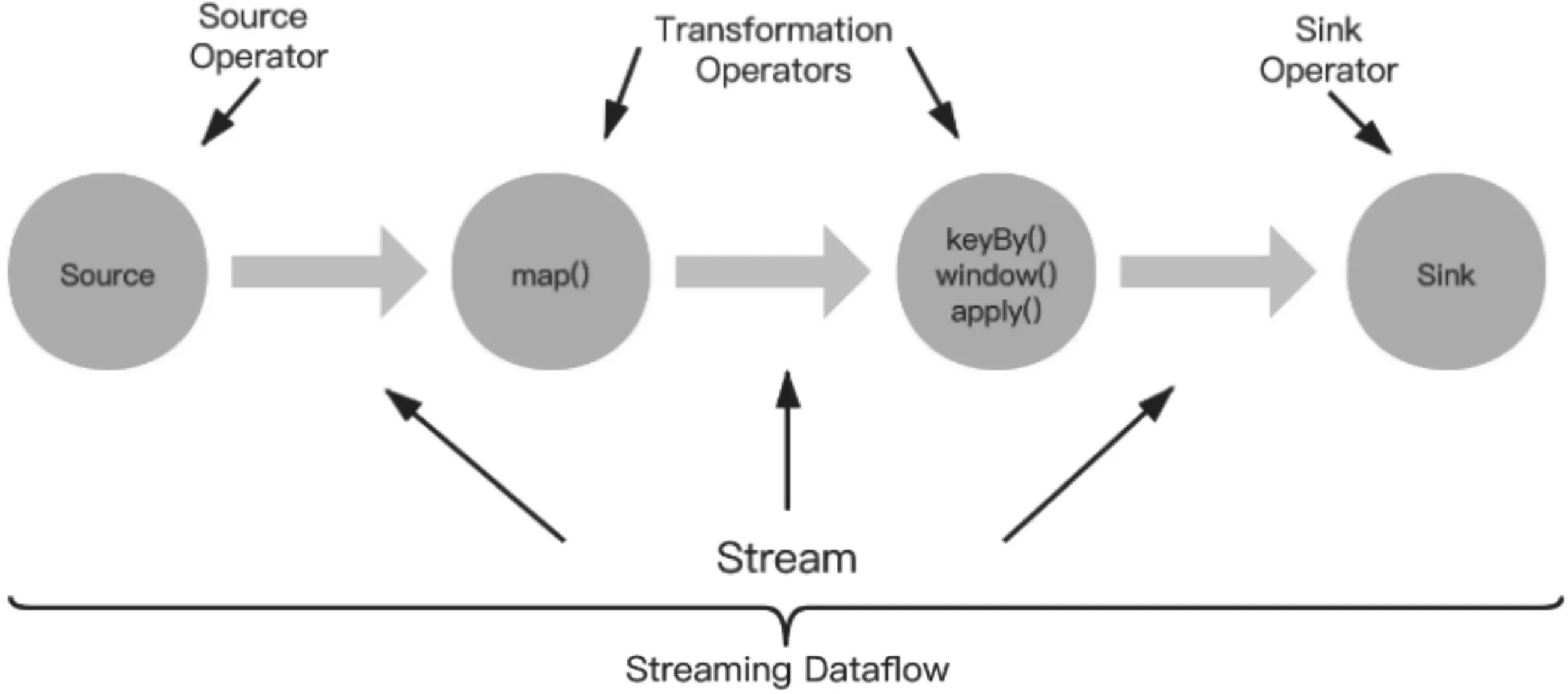
图2 Flink 数据流处理过程
2 系统架构设计
系统主要由实时数据采集模块、实时数据存储处理模块和数据应用模块3个模块构成,其构成的系统架构如图3所示.
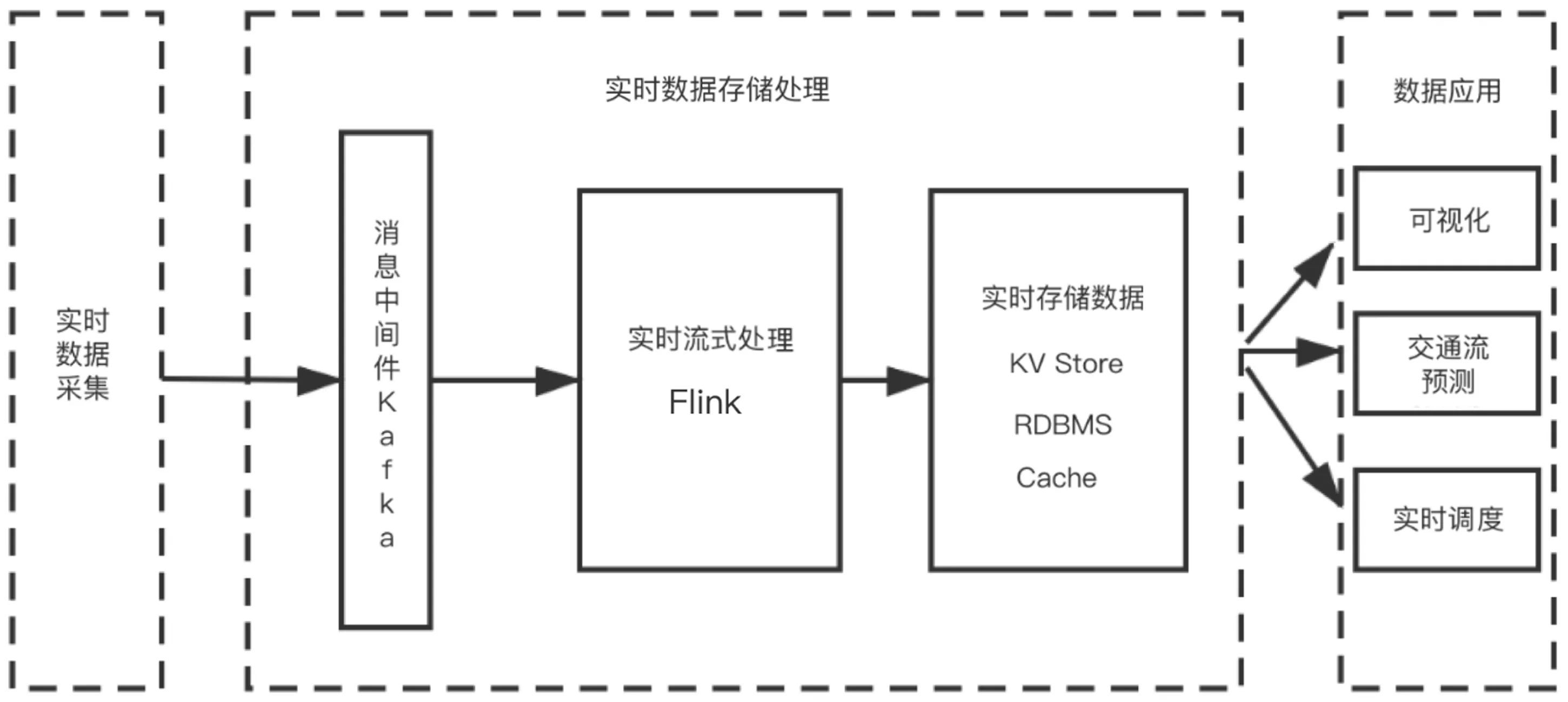
图3 系统架构
2.1 实时数据采集模块
由于交通设备监控数据产生的速度和频率通常与实时平台处理数据的速度不匹配,因此需要引入Kafka消息队列来作为缓冲,从而实现实时交通数据和处理的匹配. 道路线圈、地磁等检测器作为数据的生产者,根据数据采集方式的不同,发送到对应的Kafka Topic.
2.2 实时数据存储处理模块
模块的核心是实时流式数据的处理. 因此,可利用Flink流处理技术实现流式数据的处理,其处理的过程为:Flink从Kafka消息队列中按照时间窗口不断提取交通数据;Flink进行异常数据监测、数据格式转换和数据统计等数据处理操作;根据数据的种类,将处理完的数据分别存到关系数据库,K/V数据库等数据库中.
2.3 数据应用模块
将处理过的交通数据进行交通流预测和交通流可视化等应用操作, 通过本文设计的交通流预测模型训练交通流数据,完成规定时段的交通流数据预测.
3 交通流预测模型及实验仿真
3.1 模型介绍
门控循环单元(Gated Recurrent Unit)[13]作为循环神经网络(Recurrent Neural Network)中的一种,主要解决长期记忆和反向传播中的梯度等问题,其结构[13]如图4所示. GRU由更新门和重置门组成,其计算步骤[13]如下:
1) 设置重置门和更新门. 这2个门的输入均为当前时间与上一时间步隐藏状态,输出可利用sigmoid激活函数的全连接层进行计算,sigmoid函数可以将元素值变换到0到1之间. 如式(1)、式(2),其中W为权重参数.
zt=σ(Wz·[ht-1,xt])
(1)
rt=σ(Wr·[ht-1,xt])
(2)
2) 将当前时间步重置门的输出与上一时间步隐藏状态进行相乘. 如果重置门中元素值接近0,则丢弃上一时间步信息,如果元素值接近1,则保留上一时间步信息. 然后通过tanh激活函数的全连接层计算出候选隐藏状态,如式(3).
(3)
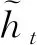
(4)
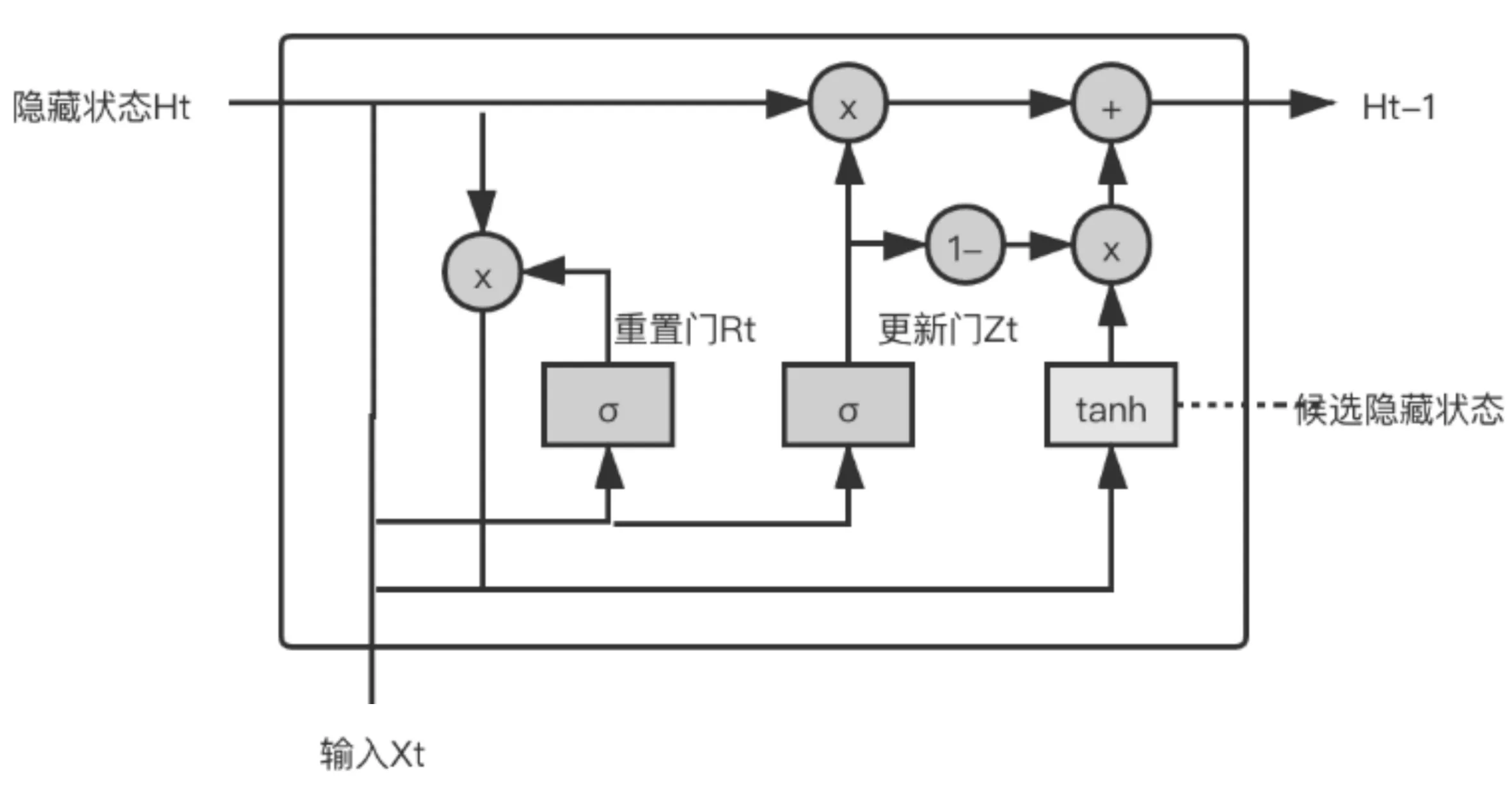
图4 GRU结构图
3.2 实验仿真
本文实验数据来自美国加利福尼亚交通管理局(PeMS)的SR13-N道路[14],起止时间从2018-01-01至2018-02-09,交通流数据为30 s的数据样本聚合成5 min一次的数据. 本文选择2018-01-01至2018-01-31期间的数据作为训练集,2018-02-01至2018-02-09期间的数据作为测试集. 实验中的GRU为两隐层网络,使用Keras构建. 本实验选择层叠自编码器SAEs模型[6]与GRU进行比较,评价指标为平均绝对误差(MAE)和均方根误差(RMSE),两种模型的MAE和RMSE计算结果如表1所示. 从测试集中选择同一天进行测试,GRU和SAEs的仿真实验结果分别如图5和图6所示.

表1 两种模型MAE和RMSE的实验结果
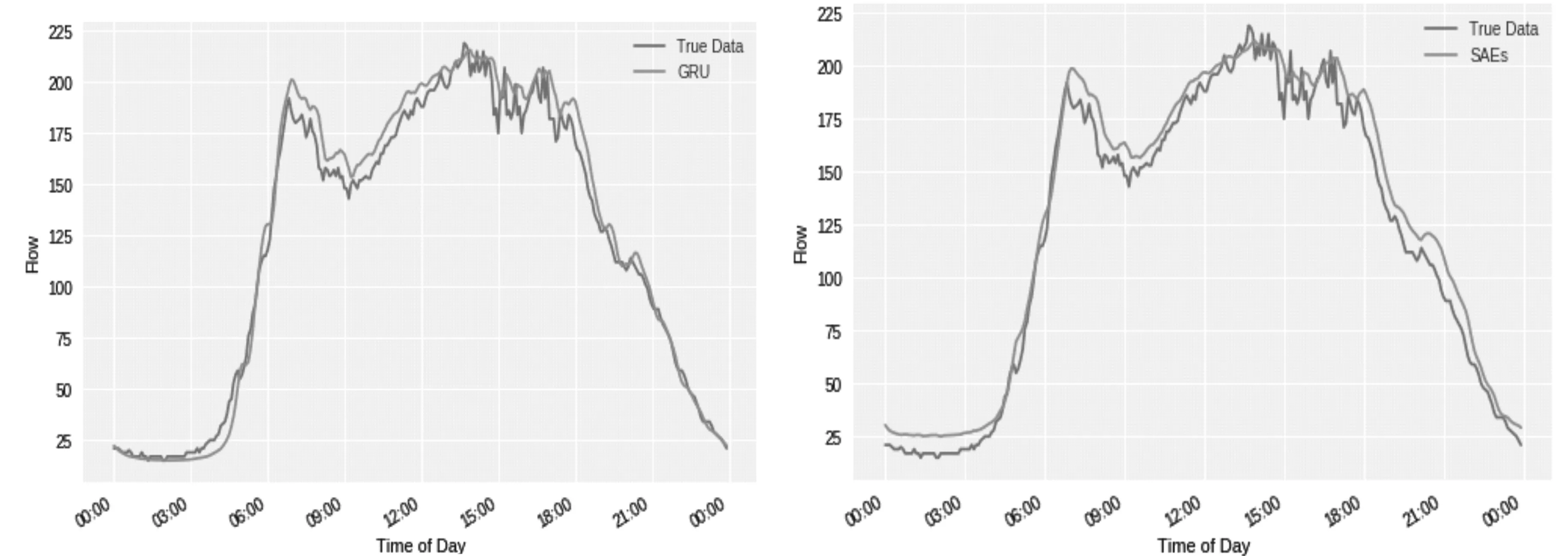
图5 GRU预测结果 图6 SAEs预测结果
从图5和图6中可以看出,SAEs和GRU都能正确地显示交通流变化的大体趋势,GRU预测的结果更加接近真实数据流. 表1中列出了这两种模型的MAE与RMSE计算值,可以看出基于GRU模型的MAE和RMSE都要低于SAEs模型. 说明本文采用的GRU模型由于能够捕捉时间序列数据之间的关联性,使得平均绝对误差和均方根误差较SAEs模型有所降低,可以明显提高交通流预测的精度,是一种有效的交通流预测方法.
4 结束语
提出了基于门控循环单元神经网络的交通流预测方法.利用流式处理技术Flink和消息系统Kafka对交通流数据进行处理,使之具备高效的大数据处理能力,从而提高交通流数据处理的高吞吐量和降低交通流数据的延迟. 利用门控循环单元神经网络设计交通流预测模型,捕捉交通流数据中时间序列数据之间的关联性,对未来交通流进行预测. 实验结果表明,本文提出的基于门控循环单元神经网络的交通流预测方法可以有效降低平均绝对误差和均方根误差,并有效提高预测的精度. 而更为详细、准确的时间序列数据分析是本文未来研究的重点.
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
中国交通信息化(2022年5期)2022-07-23
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
数据与计算发展前沿(2021年5期)2021-11-30
建材发展导向(2021年12期)2021-07-22
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
计算机技术与发展(2018年1期)2018-01-23
中国交通信息化(2017年7期)2017-06-06
