
水利水电行业专用中文分词方法研究
2021-03-26 06:32唐颖复江新兰张伟兵王志璋
水利信息化 2021年1期
唐颖复,江新兰,张伟兵,王志璋,缪 纶
(中国水利水电科学研究院,北京 100038)
0 引言
近年来,水利信息管理系统在相关水利业务中得到广泛应用[1],产生和积累了大量的水利专业数据和文本资料。如何对日益增长的行业相关资料和数据资源进行高效的管理和利用已成为水利信息化必须解决的问题[2]。截至 2017 年底,全国省级以上水利部门存储的各类信息资源约为 1.9 PB[3]。目前对这些水利数据的整合规划测重于结构化数据,即信息化系统中的业务和水利工程运行管理中自动采集计算的专业的数据。然而,尚有大量以自然语言文本形式存在的水利水电行业相关资料有待被开发利用,如重要会议讲话、行业调研报告、前期勘测资料、规划设计报告、总结报告、项目档案等。这些非结构化形式的数据无法直接被计算机分析和处理,但其中隐藏着很多潜在的高价值的水利水电行业相关信息,可为管理部门的决策提供有效的信息支撑。
中文信息处理是处理中文自然语言文本资料的关键技术[4],已被广泛应用于各种行业,如医疗行业中的病例智能分析[5–6],媒体行业的新闻事件舆情抓取[7],公安部门的情报挖掘分析[8]等。然而,在水利水电行业,自然语言文本资料的信息抽取技术还不成熟,存在信息挖掘不充分、分析手段缺乏、资料利用率低等问题。
Jieba 分词是中文信息处理中重要的中文分词方法。本研究在改进 Jieba 分词方法的基础上提出一种针对水利水电文本资料的新分词方法,并将新方法应用于全国水利会议报告的主题词提取。1988 年,国家机构改革,水利和电力分家,水利发展开始一个新的历程;同年《水法》颁布,国家对水资源实行统一管理与分级、分部门管理相结合的制度,水利部作为国务院水行政主管部门,负责全国水资源的统一管理。1998 年国务院赋予水利部统一管理全国水资源的职能,水利部党组提出“从工程水利向资源水利转变,从传统水利向现代水利、可持续发展水利转变”[9]24–25。因此 1988—1997 年与 1998—2007 年这 2 个阶段的会议报告数据具有代表性,可作为本研究实验的样本数据,为此利用分词新方法对比分析 1988—1997 年与 1998—2007 年 2 个阶段全国水利工作内容变化趋势。
1 水利水电行业词典库的构建
1.1 水利水电行业文本数据的特点
中文文本无天然分隔符,因此,为正确了解一个中文语句的语义,中文信息处理要求将整句切分成更小的单元,这就需要利用中文分词技术[10]。中文分词通常是通过词典让计算机认识词汇,但若使用通用语料库对水利水电行业文本进行分词,则无法完全满足更多专业细化的现实需求。因此,构建一个水利水电行业专用的词库就成为研究水利水电行业专用中文分词的前提条件。通过对大量现有的水利水电行业文本资料的分析,发现水利文本数据具有以下特点:
1)地理名词出现频繁。水利工程和管理活动等涉及的业务范围覆盖国家、流域、省、地市、区县和村庄,因此在水利相关的文献报告中经常提及地理区域和河流湖泊的名称。而地理位置的描述在语义上具有唯一性,在缺少对地理名词认知的前提下,计算机会错误理解常用的地理空间描述。例如“天山北坡”会被错误切分成“天/山北坡”,而根据语义正确切分的结果应该是“天山/北坡”。
2)水利专业词汇丰富。随着水利学科的不断发展,形成水文学及水资源、水利水电工程、水力学及河流动力学、水工结构等子学科,每个学科都包含数千条有学科特色的专业术语。这些专业术语经常被错误切分,如“倒虹吸管研究”被切分成“倒/虹吸管/研究”,而正确切分应该为“倒虹吸管/研究”。
3)各类大中小型水利水电工程不断涌现。新中国成立以后,特别是 1978 年改革开放以来,我国水利水电工程建设得到蓬勃发展,据有限统计,截至2018 年我国已建有不同规模水库 98 822 座[11]。但计算机不容易正确理解水利工程名称,比如:“江南海塘”是一个中国水利工程名称,根据目前主流的分词器规则,它会被切分为“江南/海塘”或者“江/南海/塘”,这都是不正确的。
1.2 水利水电词典库的构建
1.2.1 专业词汇提取
基本词典库是中文分词系统搭建的基础,词典库包含的词汇越丰富,范围越广,分词系统切分正确率越高。但是目前还没有一套适用于水利水电行业的专业词典词库,因此,利用 Python 网络爬虫技术对《水利大辞典》[12]、《中国水利百科全书》[13]及《中国大百科全书 • 水利学》[14]中词条进行自动抓取。《水利大辞典》有 8 类 32 个分支,共计词目4 700 余条;《中国水利百科全书》有 21 分册,共包含词目 2 144 条;《中国大百科全书 • 水利学》包含词目 347 条。将 23 本著作的词条合并去重后共得到 6 485 条词目,再通过网络爬虫和人工整理的方式收集 3 175 个中国省市区县、74 个河流、83 个水文站的名称,结合以上所有词目,构建一个适用于水利水电行业的基本词典库。
1.2.2 词典构建
中文分词所用词典一般由词语及其权重组成。首先随机选取水利水电行业 100 篇项目报告作为确定词语权重的材料库,内容涵盖水利水电工程的多个子学科。通过对这些材料的提取、分析和统计,获得各专业词语的词频,并提出一种基于改进的词频(TF)权重确定方法。TF 概念自 1958 由 Luhn[15]提出以来广泛应用于信息检索与数据挖掘[16],它是指词语在文本中的出现频率。基于 TF 概念,根据不同对象将权重计算分为以下 2 种形式:
1)对象为原子词语。即不能再被拆分的词语,权重只由该词在材料中的词频决定。
2)对象为搭配词语。Manning 等[17]在 1999 年提出搭配的定义,本研究是中文分词的研究,因此搭配词语由 2 个或 2 个以上的原子词语组成。权重由该搭配词语的词频和紧密度共同决定,对于紧密度高的搭配,分词系统优先将其视为整体,停止继续切分。经过使用不同紧密度计算方式测试和人工判别准确率,发现紧密度通过加权因子计算时,切分准确率最高,其中:xi为 1 个原子词语,因此 (x1,x2,…,xn) 为词x1,x2,…,xn组合而成的词语,p(x1,x2,…,xn) 是该搭配词语的词频,p(xi) 是词语xi单独出现频率。因此,搭配词语的权重由词频与加权因子共同决定。
在确定词典每个词语的权重后,水利水电专业词典构建完毕。
2 水利水电专用中文分词方法改进
Jieba 是 Python 中一个重要的开源中文分词函数库,分词原理是利用本身的中文词库,将待分词的内容与其词库进行对比,对每一种切分的可能性生成一条路径,通过分析动态路径规划方法找到最大概率的切分词组。
基于 Jieba 分词的基础函数,在通用 Jieba 分词上进行以下 2 点改进:
1)加载构建的水利水电行业基本词典库,并将文本与专业词典库优先匹配,提升水利水电专业词汇的权重。
2)添加词语补充与更新模块,新方法得以通过学习认识新的搭配词语,避免较长的专业词语被错误拆分。
新方法分词流程如图 1 所示。

图 1 水利水电专用中文分词的算法流程图
算法所用相关概念解释如下:
1)正向最大匹配法。正向最大匹配法[18–19]是指从左到右将待分词文本中的几个连续字符与词表匹配,如果匹配上,则可以切分出 1 个词。但为了尽可能得到最大匹配,在第 1 次匹配后仍会继续扫描。以待分词文本{“海”“岸”“线”“长”“度”}为例:首先,从第 1 个汉字“海”开始,当扫描至第 2 个汉字时,发现“海岸”已经存在于词表中,记录下来,但这时不结束切分;继续扫描至汉字“线”,发现“海岸线”也在词表里;再继续扫描汉字“长”,“海岸线长”不在词表里,因此结束扫描;最后,将扫描结果 {“海岸”“海岸线”} 记录下来,用于构建后面的有向无环图。
2)停用词。停用词是指在自然语言处理中会自动过滤的某些字和词,如“的”“了”“你”“我”“他”等。
3)有向无环图。有向无环图指无回路的有向图。在 Jieba 分词中,有向无环图用来构建所有可能的词切分构造[20]。以原语句“洞庭湖区治理”为例,基于有向无环图的词切分构造步骤如下:
a.“洞”与后面的汉字可组成“洞庭湖”“洞庭湖区”,若用数字代表汉字在句中的位置,可用组合0∶[0,2,3] 标识以“洞”字开头的词语的切分位置。冒号前的数字为“洞”的位置 0。“洞”字可以切分成自己本身,因此括号里有数字 0;也可在位置 2切分,即“湖”的位置,得到“洞庭湖”;也可以在位置 3 切分,即“区”的位置,得到“洞庭湖区”。
b.“庭”与后面的汉字无法组成词语,所以只能在自己位置切分,它的位置为 1,组合为 1∶[1]。
c.“湖”字可与“区”字组成“湖区”,因此在“湖”和“区”的位置上都可切分,“湖”和“区”的位置分别为 2,3,可得到组合为 2∶[2,3]。
d.“区”与后面的汉字无法组成词语,只能在自己位置切分,它的位置为 3,所以组合为 3∶[3]。
e.“治”字可与“理”字组成“治理”,因此在“治”和“理”的位置上都可切分,“治”和“理”的位置分别为 4,5,可得到组合为 4∶[4,5]。
f.“理”字后面没有汉字,因此只能在自己位置切分,它的位置为 5,组合为 5∶[5]。
因此,“洞庭湖治理”对应生成的有向无环图为{0∶[0,2,3],1∶[1],2∶[2,3],3∶[3],4∶[4,5],5∶[5]}。计算机根据有向无环图可得每一种切分的可能性,通过分析动态路径规划方法可找到最大概率路径得到对应的分词组合。
4)词库更新与补充。在完成分词后,遍历最后的分词结果,将相邻的 2 或 3 组词进行搭配。若搭配词语的词频大于 0.6 次/万字,则将该搭配词语补充进水利专用词典库 dict 中;若搭配词语的词频小于 0.6 次/万字,则不做改动。继续遍历,直到完成所有组合的搭配检测。
3 水利水电专用中文分词实验分析
3.1 实验数据
为验证本研究提出的基于改进 Jieba 分词的水利水电行业专用中文新分词方法,对水利水电行业文本资料中蕴藏的高价值信息的分析和挖掘效果,选取 1988—2007 年间共 121 万余字的全国水利会议报告[21–24]作为实验数据分析样本。会议报告是指在重要会议上由主要领导或相关代表人物发表的指导性讲话,是贯彻会议精神的重要依据,是一种以文本形式存在的宝贵的行业资料。
本次实验结果分析的依据是专业词语的词频,词频由专业词语出现的次数除以全文长度得到。对历次全国水利会议报告进行高频词提取,通过与实际情况对比分析,展示的实验分析结果很直观地反映和揭示了 1988—2007 年间我国水利工程事业重心的发展轨迹和趋势。
3.2 实验过程
实验过程包含以下 4 个部分:
1)分词。使用新方法提取全国水利会议报告中的专业词语。
2)计算词频。利用 Python 对提取词语进行分年度词频统计。
3)词云图绘制。根据材料中关键词词频的高低,通过不同字体大小和颜色,视觉化展现关键词的显著性。词云图的绘制可以过滤掉大量低频的文本信息,使得浏览者只要一眼扫过就可抓住文本内容的关键词,领略文本内容的主旨意思。
4)结果分析。为体现我国水利事业发展中心随着时间推移的改变,根据现有资料将实验数据分为1988—1997 年与 1998—2007 年 2 个阶段,在分词和计算词频的基础上对历次全国水利会议报告进行高频词提取,并且分析对比改进前后 2 种方法的分词效果。
3.3 实验结果分析
实验结果分析如下:
1)新方法提取的高频词反映我国水利工作重心。原 Jieba 方法和新方法提取的词频最高的 10 个词语如表 1 所示,可以看出:原 Jieba 方法效果不突出,除了第 1 个词是“水利”,其他排名靠前的词皆为通用词语,如“工作”“发展”“建设”“管理”,而这些通用词语无法体现我国水利工作中心;新方法中,由于建立了水利水电专业词典,因此计算高频词语可以针对水利水电专业词语,高频词结果中“水利”“水利工程”“水资源”“防汛”“防洪”“水库”“农田水利基本建设”等词语频率一直保持着高位,这与我国一直以来的“除害与兴利相结合”的方针相符。为确保人民群众的生命安全,最大程度地减轻灾害损失,每年的水利工作都将防汛防洪抗旱及水利工程建设放在首位。农田水利基本建设是农业发展的关键因素,我国粮食安全的重要保障。我国以占全球 6% 的径流量、9% 的耕地,保障了占全球 21% 人口的温饱和经济社会发展,农田水利设施发挥了至关重要的作用[9]3。
图 2 是统计了所有词频之后制作的词云图,从图中可看出:新方法针对水利水电专业词语绘制的词云图重点突出,水利专业词语的词频高低可以根据字体大小清楚识别,而且弥补了原 Jieba 方法不能识别组合专业词语的缺陷。
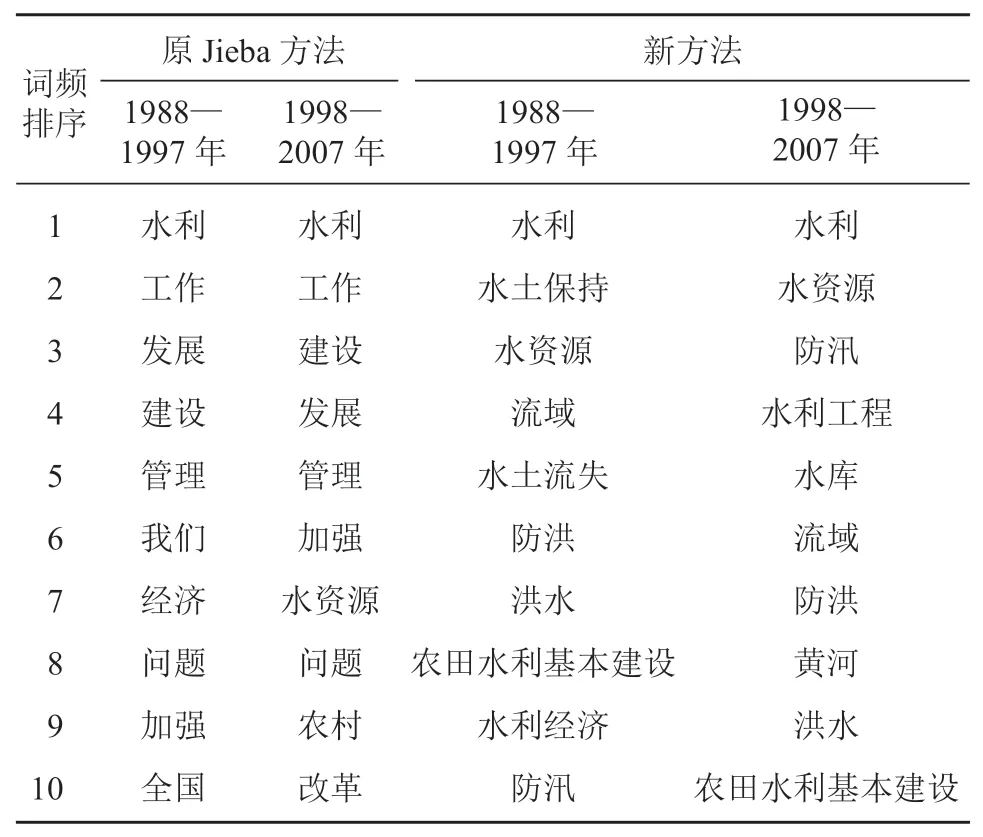
表 1 使用 2 种分词方法在不同阶段提取的高频词

图 2 1988—2007 年全国水利会议报告的词云图
2)新方法捕捉分词正确率更高。原 Jieba 方法虽然可以通过学习认识新词语,但学习新的搭配词语的能力有限;新方法基于水利水电专业词典,在遇到水利水电专业中新搭配词语时,可以通过加权因子调整该搭配词语的权重,因此切分表现较好。表 2 列出了 2 种分词方法分词的 9 个例子,可以看出:原 Jieba 方法具有代表性的切分错误情况,而新方法解决了切分错误及颗粒过小的问题。
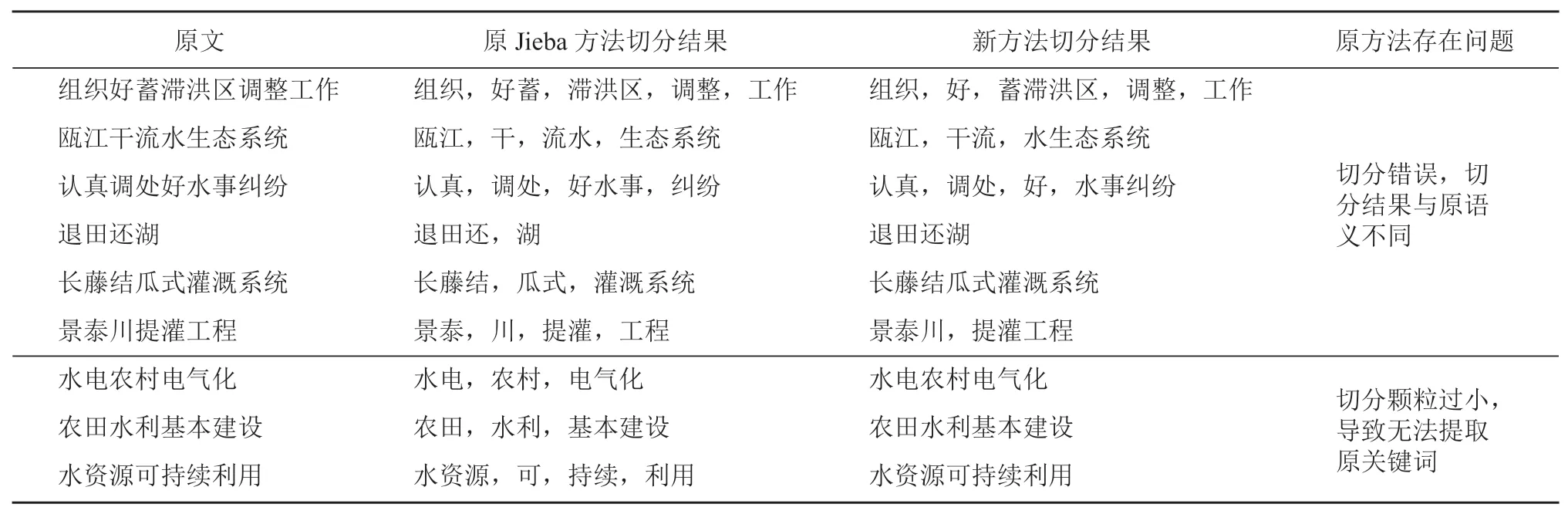
表 2 2 种分词方法分词结果
3)不同时期出现的新词汇是我国水利发展改革和治水思路改变的体现。在年度词频的基础上,对每年出现的新词进行了统计,2 种方法得到的 2000 年后出现的新词出现年份和词频变化如图 3 所示。可以看到新方法比原 Jieba 方法更能体现我国水利发展改革和治水思路改变:原 Jieba 方法的结果中只有“污水处理”与水利紧密相关,其它词语多是通用词语;新方法结果全部是水利专业词语,如“水资源配置”“南水北调工程”“农村饮水安全”“节水型社会”“水权制度”“水利信息化”“污水处理”,这也说明改革开放以后,中央明确了新时期水利工作方针。随着治水思路发生深刻变化和水利投入大幅度增加,我国进入可持续发展水利的新阶段。
使用新方法得到的出现频率较高的新词分析如下:
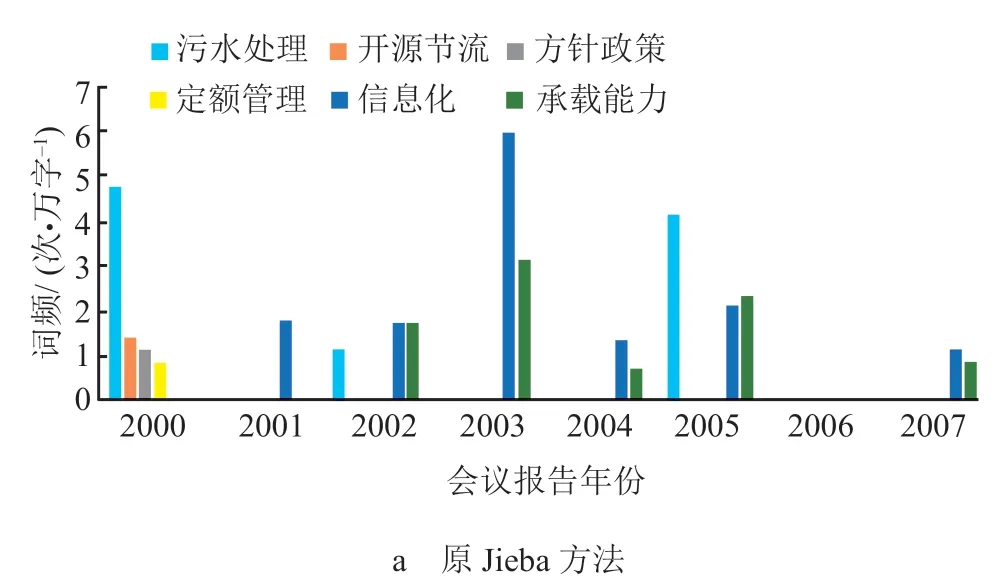

图 3 新词的首次出现年份与词频变化
a. 水资源配置、南水北调工程。1998 年国务院赋予水利部统一管理全国水资源的职能,水资源管理工作以水资源配置、节约和保护为重点,逐步从供水管理向需水管理转变。因此,水资源配置这一新词汇在随后的水利工作报告中得以出现。同样,2002 年国务院批复南水北调工程总体规划后,当年12 月 27 日,南水北调工程建设正式开工,因此,2002 年水利工作报告中的“南水北调工程”成为当年出现频率最高的词汇。随后,随着以南水北调为代表的我国水资源调度建设工程的实施,我国逐步建立了水资源“四横三纵、南北调配、东西互济”的配置格局,提高了我国水资源调度能力,成功化解了多个重要地区和城市的供水危机。
b. 农村饮水安全。进入 21 世纪以后,我国逐步进入“以工哺农”“以城带乡”的经济发展新阶段,为解决广大农村人口的饮水问题,我国开展了防病改水、扶贫攻坚、饮水安全工程建设等工作。据统计,截至 2004 年底,我国农村饮水不安全人口依然有 3.2 亿,占农村人口总数的 34%[25]。因此,随着国家持续增加投入提高饮水安全与水源地建设,“农村饮水安全”成为这一时期出现频率较高的词汇,反映了中央对改善广大群众生活用水状况工作的重视。
c. 节水型社会、水权制度。2000 年,国民经济和社会发展第 10 个“五年计划”明确提出建设节水型社会。2001 年,水利部批复张掖市为第 1 个全国节水型社会建设试点。2004 年,中央人口资源环境工作座谈会要求,把节水作为一项必须长期坚持的战略方针,把节水工作贯穿于国民经济发展和群众生产生活的全过程。因此,自 2002 年开始,“节水型社会”成为出现较高的词汇。同样,“水权制度”概念的提出体现了我国从国家、流域和区域等多层面规划水资源利用,建立健全定额管理、取水许可、有偿使用等一系列用水管理制度。
d. 水利信息化。2003 年,水利部印发的《全国水利信息化规划(“金水工程”规划)》,成为第 1 部全国水利信息化规划。如何充分发挥信息化技术的驱动引领作用,大力推进高新技术与水利深度融合,是需要统筹规划、协同推进的工作重点。水利信息化将把水利创新和建设推向新高度,为新时代水利工程补短板,水利行业强监管提供有力的技术保障[26]。
4 结语
随着水利水电行业信息爆炸式地增长,如何及时、准确、全面地获取所需要的信息是水利信息化研究中的难点。本研究提出的适用于水利水电行业的中文分词新方法,在分词过程中,可基于搭配词语的词频对水利水电专用词典进行补充与更新。将新方法应用于 1988—2007 年的全国水利工作会议报告的比较分析,得到的主要结论如下:新方法可有效解决原 Jieba 分词方法存在的切分颗粒过小及错误等问题;新方法可实现提取高频词、捕捉新词汇、统计词频变化等功能。
中文分词技术是中文信息处理的基础技术,是搜索引擎与全文检索等技术实现的前提。下一步将结合其它算法,建立水利水电行业专用的信息搜索引擎和分类等系统。
猜你喜欢
内江科技(2021年8期)2021-09-13
校园英语·月末(2021年13期)2021-03-15
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
英语文摘(2019年5期)2019-07-13
中国修辞(2017年0期)2017-01-31
读者·校园版(2015年7期)2015-05-14
中关村(2014年5期)2014-05-15
