
基于运动历史图的智能裁剪视频重定向
2021-03-25 04:06马婷婷严华
现代计算机 2021年4期
马婷婷,严华
(四川大学电子信息学院,成都610065)
0 引言
随着科学技术的不断发展,各种显示设备诸如手机、平板、电脑等层出不穷,且不同设备的屏幕尺寸和宽高比例也各式各样。但是一段视频的尺寸通常是固定的,将同一段视频显示在不同的设备时,为了保持视频内容的完整性和可读性,需要有效调整视频的宽高比例,这种技术称为视频重定向技术。
在改变视频数据宽高比和分辨率,以适应目标显示设备的前提下,保持尽可能多的重要内容和避免可见伪影是视频重定向的目的。视频重定向处理的难点在于如何快速生成同时保持时间连续性和空间图像形状的结果视频。传统的方法有裁剪、均匀缩放和边缘填充三种方法。这三种传统方法虽然能高效实现视频重定向,但都没有基于视频内容做出考量,影响了视频内容的可读性。针对这个问题,有学者提出了基于内容的视频重定向(video retargeting)方法,这种方法因能同时满足保持重要内容的形状和时间连续性的要求而广受好评。目前基于内容的视频重定向方法主要有以下4 类:基于智能裁剪的方法、基于细缝裁剪(seam carving)的方法、基于网格非均匀映射(wrapping)的方法和基于多算子的方法。
基于智能裁剪的方法,通过裁剪与目标尺寸宽高比一致的图像显著性区域,进而缩放裁剪区域达到视频大小调整的目的。Chou 等人[1]首先利用SSIM 检测算法和显著性检测方法进行显著性区域检测,然后基于显著性区域进行裁剪,若裁剪后图像不满足目标大小,则直接缩放至目标大小。这种方法虽然计算效率较高,但忽略了摄像机运动的情况,且对于包含剧烈运动场景的视频帧结果不太理想。基于智能裁剪方法的结果好坏很大程度上依赖于图像显著度图的正确性,一旦显著性区域出现偏差,极易产生视频帧之间的抖动。另外为了保持重要对象形状裁剪窗口需频繁移动,这样会导致视觉体验差。
基于Seam carving[2-7]的方法为重复插入或者删除视频帧中重要度值较低的细缝。Seam carving 方法容易错误裁去视频中的快速运动物体,造成内容不连续。基于wrapping[8-13]的方法首先在视频帧上划分多个网格,然后根据网格重要度和相关约束对网格进行映射。该方法主要缺点在于需要耗费较多的时间来保持时间连续性。基于多算子[15-19]的方法即应用两种或者两种以上的操作符进行视频重定向处理。基于Seam carving 的方法、基于wrapping 的方法和基于多算子的方法,一般而言时间复杂度要远高于基于智能裁剪的方法。为了能够高效处理视频重定向问题,本文将基于智能裁剪方法进行视频大小调整。
针对智能裁剪中对图像显著度图的依赖程度高、文献[1]方法不适用于剧烈运动场景的问题,本文提出了一种基于运动历史图的智能裁剪方法来调整视频大小。首先基于时间轴将视频帧通过估计帧间摄像机运动对齐获取全局运动模型;然后基于全局运动模型,利用融合了图像显著度图和运动显著度图的重要度图求得运动历史图;最后,基于运动历史图的重要区域进行裁剪。
与传统的图像显著性检测算法、运动显著性检测不同,本文采用近年的文献[20]的级联编-解码器的方法和文献[21]的视频分割方法获取更加精准的图像显著度图和运动显著度图。图像显著度图和运动显著度图的精确度的提高有助于提高重要度图的精确度,从而达到更好的视频重定向结果。与文献[10]求取运动历史图的方法不同的是,本文基于全局运动模型求取运动历史图,可保证视频序列中背景与前景的时间连续性一致。运动历史图的应用不仅可降低对图像显著度图的依赖程度,而且能更好地指导包含复杂摄像机运动和物体运动情况的视频序列的形变和保护重要对象的整体结构。
1 相关工作
智能裁剪方法典型的工作有:Cheng 等人[22]提出了一种基于内容重组的视频自适应新框架:首先通过视觉注意力特征的组合从视频场景中提取重要对象;其次,将删除重要对象后的视频帧进行缩放以满足目标尺寸大小;最后,将提取的对象重新整合到视频中。Yuan 等人[23]提出了一种内容感知的方法:在每个视频帧中裁剪一个用户感兴趣的区域作为重定向结果,同时应用动态规划优化裁剪区域的时间一致性。Liu 等人[24]提出了曲线拟合的方法:①获得基于感知的兴趣区域;②采用快速曲线拟合策略,在给定的视频镜头上寻找最优的裁剪序列,避免了帧间复杂的时间约束设计。
2 提出方法
图1 为本文方法的整体框架流程。首先,计算当前视频帧的图像显著性区域和运动显著性区域;其次,将图像显著区域和运动显著性区域融合,得到当前帧的重要性区域(重要度图);然后,采用特征点匹配建立视频帧的全局运动模型,结合重要度图获得其对应的运动历史图;最后,基于运动历史图的重要区域进行裁剪和缩放。重复上述步骤直至完成全部视频帧重定向。
下面对本文算法的实现进行具体描述。

图1 整体框架流程
2.1 图像显著度图
本文应用文献[20]新颖的级联编码-解码器的方法求图像显著度图,实例见图2。与经典的图像显著性检测算法(如AC 算法、FT 算法等)相比,该方法能快速生成更加精准的图像显著度图。该方法以ResNet50 作为级联部分解码器框架的骨干网络来提取图像多层次特征信息,ResNet50 结构中的两个卷积模块分别作检测分支和注意分支。检测分支提取初步显著度图,注意分支对该显著度图进行优化,优化后的结果重新传回网络,再次进行编码-解码,从而得到最终的显著度图。
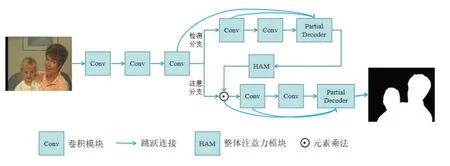
图2 图像显著度图实例
2.2 运动显著度图
运动显著图的应用不仅能整合运动信息,将更多的重要信息包含其中,而且可以弥补上述图像显著性检测偶尔带来的误差问题。与帧差法、光流法等相比,采用文献[21]的方法能更准确地计算出运动显著性区域。图3 是文献[21]方法的一个实例,其计算过程如下:①将输入视频帧分割为超像素,将图像上两个超像素间的最短路径定义为测地线距离;②利用帧内的静态边缘信息和帧间的运动信息生成时空边缘图。在帧内图和帧间图中,分别采用测地线距离来估计前景概率、更新每对相邻帧的时空显著度图;③定义能量函数并通过图形切割将其最小化以获得最终的分割结果。
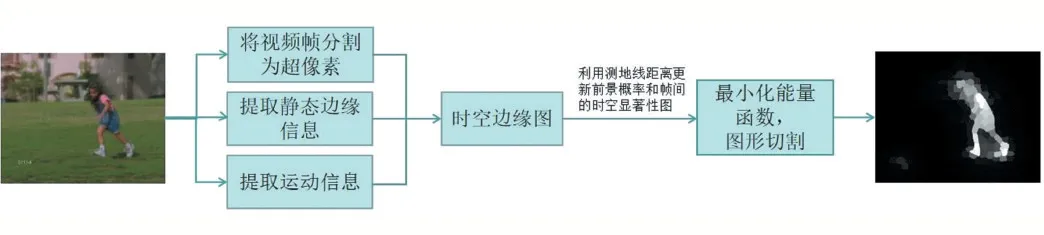
图3 运动显著度图实例
2.3 重要度图
重要度图越精确,根据重要性区域进行视频重定向的结果就越好。本文通过选取图像显著度图与运动显著度图中对应像素点的较大值来获取重要信息,从而构成重要度图。其计算公式如下:

2.4 运动历史图
运动历史图的计算步骤有如下3 步:①将全部视频帧基于时间轴对齐,建立全局运动模型;②在全局运动模型的基础上,以当前帧为起始位置的一个窗口内所有视频帧对应的重要度图进行滤波,从而求得当前帧的运动历史图。
(1)全局运动模型
采用文献[9]的方法,以输入视频序列的首帧为基准,通过估计帧间相机运动将所有视频帧基于一个公共的摄像机坐标系对齐,保证视频背景与前景的时间连续性一致,图4 是全局运动模型的一个实例。步骤如下:①利用SIFT 算法[25]获取相邻两帧间的匹配特征点;②使用RANSAC 算法[26]剔除SIFT 算法中匹配错误的结果并计算相邻帧之间的变换矩阵Ht→t-1。③利用变换矩阵进行图像融合,即可建立全局运动模型。
(2)运动历史图
运动历史图的应用不仅能降低对图像显著度图的依赖程度、较好地处理包含复杂运动场景的视频,而且由于其包含了当前窗口运动目标的所有运动信息,因而保证了视频帧重定向结果的时间连续性。其计算公式如下:
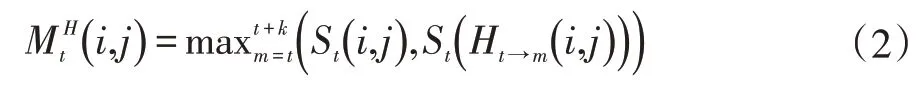
其中,St为第t 帧的重要性区域,k 是当前视频帧后面包含的视频帧数。通过调节k 值可以平衡背景与运动前景:k 值越大,运动历史图包含的运动信息越多,背景裁剪越少,但时间复杂度也随之增大;k 值越小,运动前景物体形状保持越好,但视频将有可能出现明显抖动。

图4 Stefan视频序列的全局运动模型
图5 和图6 是运动历史图的实例。图6 是从视频首帧开始,每隔5 帧取一次原始视频帧、文献[1]算法的结果帧和本文算法结果帧的实例。由图6 可看出,由于文献[1]算法只根据当前帧的显著性区域进行裁剪,当场景突变且显著物体数目由一个船员增加至一个船员和一艘白色舰艇时,该算法无法及时更新显著性区域,将丢失较多的重要信息。而本文算法使用运动历史图,可以得到后续k 帧的重要信息,所以在得到的结果视频帧中本文算法能保留更多的重要信息、更好地保护重要对象的整体结构。

图5 第1张是k=3时的运动历史图,其余是重要度

图6
2.5 裁剪方案
在保证了视频重定向结果的时间连续性的基础上,本文基于运动历史图的重要性区域大小进行裁剪。若重要区域大小尺寸小于目标尺寸,则以重要区域为中心进行裁剪;否则,裁剪重要区域,将裁剪后的视频帧缩放至目标尺寸。同时保证每一帧的裁剪方案一致,并对相邻帧的裁剪做平滑处理。
3 实验结果
为了验证本文多算子视频重定向算法的普遍适用性,本文实验选取了13 个不同类型的YUV420 格式视频,使用MATLAB 软件,在CPU 为3.20GHz、内存8G的计算机上进行测试。视频类型包含了摄像机静止、摄像机运动、慢速物体运动、中快速物体运动、1 个对象运动和多个对象运动。本次实验采用2 种视频重定向方法(文献[1]算法和本文算法)对13 个视频序列进行了各种视频长宽比变化的测试。在上述进行测试结果中随机选取了宽度缩小至原宽度50%的3 个视频序列中的任意连续4 个视频帧作比较,结果如图6~8 所示。
下面将从主观性能比较和重要信息量比较对重定向后的视频质量进行讨论分析。
3.1 主观性能比较与分析
图7(b)~图9(b)是各视频序列采用文献[1]算法得到的结果视频帧。由图7(b)红色框中的小车可看出裁剪窗口在频繁移动,降低了人们的视觉体验感。这是因为裁剪窗口为了展示尽可能多的重要性信息需要频繁移动。对于中快速物体运动的视频,由于场景突变和显著性检测的误差会导致视频产生抖动。由图8(b)和图9(b)的黄色虚线可以看出,图8(b)第二行和第三行之间、图9(b)第一行和第二行之间存在抖动现象。
图7(c)~图9(c)是各视频序列采用本文算法得到的结果视频帧。由图7(c)红色框中的小车可看出,由于运动历史图的作用,图7(c)相较于图7(b)来说,背景无移动现象,增强了视觉上的舒适度;图8(c)相较于图8(b)以及图9(c)相较于图9(b)来说,各视频帧之间不存在抖动现象。由此可见,本文方法在保持重定向视频时间连贯性、减少视频抖动方面效果较好,同时能较好地保持重要物体整体结构。
3.2 重要信息量比较
以原始视频帧中的重要对象信息量为基准,本小节对基于内容感知的文献[1]算法和本文算法进行重要信息量的比较。重要信息量的比较有助于了解算法在保持重要对象整体结构方面的性能。表1 是3 个视频序列(图7~图9)平均每帧重要信息量的比较结果。

图7 Sign_irene 视频帧的宽度缩小至原来的50%

图8 Stefan 视频帧的宽度缩小至原来的50%

图9 Coastguard 视频帧的宽度缩小至原来的50%
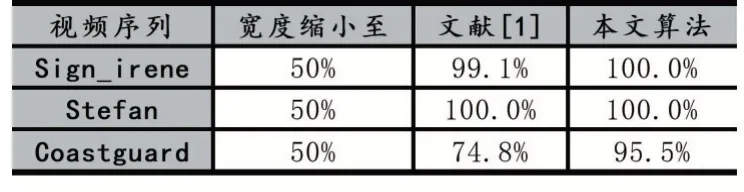
表1 视频序列平均每帧重要信息量比较
从表1 可以看到:本文算法的平均每帧重要信息量高于文献[1]算法的方法。这是因为文献[1]算法仅获取了当前视频帧的重要信息,而本文算法采用了运动历史图,可以获取更多的重要信息。由此可见,本文算法在保持重要对象的整体结构方面具有一定优势。
4 结语
本文提出了一种基于运动历史图的智能裁剪方案以进行视频大小调整。该方法首先融合了图像显著度图和运动显著度图,以生成重要度图;然后基于时间轴将视频帧通过估计帧间摄像机运动对齐获得由重要度图生成的运动历史图;最后基于运动历史图的重要性区域顺序指导单帧图像裁剪不重要的边界。实验结果表明,本文方法在实现视频时间连续性的同时能有效地保持重要对象的形状,获得较好的视觉效果。另外,运动历史图的运用降低了对图像显著度图的依赖程度,同时能更好地处理包含复杂摄像机运动和物体运动场景的视频。如何与其他算子结合进一步提升视频重定向性能将成为日后努力的方向。
猜你喜欢
速读·下旬(2021年11期)2021-10-12
大东方(2019年12期)2019-10-20
大东方(2019年1期)2019-09-10
中国知识产权(2018年12期)2018-12-29
初中生世界·九年级(2018年12期)2018-12-22
河南科技(2018年9期)2018-09-10
科学与财富(2017年22期)2017-09-10
中国知识产权(2017年5期)2017-05-25
商情(2017年1期)2017-03-22
读者(2015年9期)2015-05-04
