
基于会话的双层注意力机制新闻推荐方法
2021-03-24 11:14:38王海艳
南京邮电大学学报(自然科学版) 2021年1期
王海艳,胡 阳
(1.南京邮电大学 计算机学院,江苏 南京 210023 2.南京邮电大学江苏省无线传感网高技术研究重点实验室,江苏 南京 210023 3.南京邮电大学江苏省大数据安全与智能处理重点实验室,江苏 南京 210023)
在线新闻平台(如头条新闻和Google新闻)提供的新闻数量众多容易导致信息过载。为了减轻信息过载问题,针对用户的阅读兴趣向用户推荐感兴趣的新闻是很有必要的[1-4]。与其他项目(电影,音乐和书籍)不同,新闻通常具有高度的时间敏感性,过时的新闻经常被新发布的新闻所取代[3]。此外,用户的兴趣变化通常不如其他领域稳定,用户的某些兴趣可能持续很长时间,也可以由特定的上下文或者临时的需求触发。而传统的个性化推荐方法(如基于协同过滤的方法)由于忽略了用户浏览行为的顺序信息,难以捕捉用户不断变化的兴趣。
因此,有研究提出序列化新闻推荐方法,这些方法通常利用循环神经网络[2,5-6](Recurrent Neural Network,RNN)和注意力机制[4,7-8]对用户的历史交互行为进行建模,以捕获用户的顺序阅读模式,如文献[5]将用户浏览历史中的会话信息作为循环神经网络中的输入序列生成用户表示,文献[6]通过门控循环单元(Gate Recurrent Unit,GRU)捕获用户行为序列中的顺序信息,从而学习用户的长期兴趣,并将GRU网络的最后一个隐藏状态作为用户的短期兴趣,最终结合长短期兴趣进行推荐。文献[7]利用了注意力机制对用户近期交互的顺序行为进行建模从而学习当前的用户兴趣。然而,这类方法仍然面临一些问题:
(1)忽略会话内用户行为具有随机性和偶然性,难以捕捉会话内用户的主要阅读兴趣。
(2)将用户的行为视为单个序列,忽略各个会话之间用户兴趣的相关性。
为了解决上述问题,本文提出了基于会话的双层注意力机制新闻推荐模型(Session-based Neural Network with two-layer Attention Mechanism for News Recommendation,TLAM-NR)。 在 TLAM-NR 模 型中,用户阅读行为被划分成多个会话,并通过兴趣感知注意力层细粒度的学习用户在各个会话内的主要阅读兴趣。此外,在会话感知注意力层通过对当前会话和历史会话之间用户兴趣的相关程度进行建模,从而学习最终的用户表示,实现新闻推荐。本文的主要工作如下:
(1)本文提出了一种双层注意力机制新闻推荐模型(TLAM-NR),该模型结合了会话内和会话间的用户兴趣。
(2)在TLAM-NR模型中,首先使用卷积神经网络完成对新闻特征的提取;其次,在兴趣感知注意力层利用GRU网络和自注意力机制提取每个会话内的用户兴趣;最后,会话感知注意力层通过注意力机制来建模当前会话和历史会话之间用户兴趣的相关程度,并融合各个会话中的用户兴趣完成对候选项的预测从而实现新闻推荐。
(3)本文在公共的数据集上进行了实验,与现有的方法对比验证了所提模型的有效性,同时分析了影响TLAM-NR模型推荐性能的参数。
1 相关工作
1.1 传统新闻推荐方法
传统的方法包括基于协同过滤[9-11]的方法,基于内容的方法[12-13]以及混合方法[14]。 基于协同过滤的方法利用用户过去对项目的评分或者与给定用户相似的用户来预测用户的偏好。如文献[11]利用了用户的显式评分和隐式反馈来进行推荐。但是基于协同过滤的方法通常会遇到冷启动问题,因为新闻项经常被替换。基于内容的方法可以缓解冷启动问题,它通过对用户浏览新闻的内容进行分析从而向用户推荐类似的新闻。文献[13]是一个基于内容的深度神经网络模型,它通过余弦相似度计算文档之间的相关性从而对一组文档进行排名。混合方法通常结合不同的推荐方法进行推荐,文献[14]提出了一个两阶段的推荐框架,将基于协同过滤的方法和基于内容的方法相结合。然而,这些方法忽略了用户浏览历史中的序列信息,难以学习用户不断变化的兴趣。
1.2 序列化新闻推荐方法
会话的概念通常会在序列化推荐中提及,序列由会话组成。最近很多研究基于循环神经网络建模。文献[5]使用基于张量的卷积神经网络来提取会话内的新闻特征表示,并利用RNN捕获用户点击新闻的顺序信息。文献[6]提出通过GRU捕获用户行为序列中的顺序信息,从而学习用户的长期兴趣,并将GRU网络的最后一个隐藏状态作为用户的短期兴趣。随着注意力机制在各种机器学习任务(如图像/视频处理[15]和自然语言处理[16])中成功应用,近年来,注意力机制也经常被用于推荐任务中。文献[17]首次利用注意力机制来获取当前会话内的用户兴趣。文献[7]通过设计了一种基于注意力机制的RNN来捕获用户点击新闻的顺序信息。自注意力机制最早由 Google提出并用于机器翻译[18]。自注意力是注意力机制的一种特例,它只需要一个序列即可计算其表示形式。与传统的注意力机制不同,自注意力机制侧重于句子中多个单词之间的交互学习[19],它可以捕捉单词之间的长距离依赖关系。文献[8]提出了一种考虑时间因素的自注意力机制从用户最近的浏览序列中学习短期兴趣,并将其与用户的长期兴趣结合进行新闻推荐。文献[20]提出了一种顺序知识感知推荐模型,它使用自注意力机制来发现用户交互序列中的顺序模式。
2 TLAM-NR模型
本文提出了基于会话的双层注意力机制新闻推荐模型TLAM-NR,如图1所示。该模型由两个重要部分组成:(1)结合GRU网络和自注意力机制的兴趣感知注意力层。(2)基于注意力机制的会话感知注意力层。
2.1 问题描述
用户集为U={u1,u2,…,u|U|},新闻集X={x1,x2,…,x|X|},每个用户u对应其会话交互集表示为,其中历史会话为,当前会话为。用户u对应每个会话中的交互序列表示为。给定一个用户u的所有会话,推荐模型旨在预测用户u在当前会话下是否对其未见过的新闻有潜在的兴趣。表1定义了本文使用的主要符号。

表1 相关符号定义
2.2 新闻特征提取
受卷积神经网络成功应用在计算机视觉领域的启发[21],研究人员提出了许多基于卷积神经网络的语义嵌入模型[22-23]并在 NLP领域得到了广泛使用。在本文中,使用卷积神经网络作为新闻特征提取器,将新闻的标题作为输入,学习每条新闻的特征表示。
令W1:n是长度为n的新闻标题的原始输入,W1:n= [w1w2…wn]∈Rd×n为输入标题的词嵌入矩阵,其中wi∈Rd×l为第i个单词在标题中的嵌入,d为单词嵌入的维数。然后将卷积核应用于单词嵌入矩阵中进行卷积运算,其中l(l≤n)为卷积核的窗口大小。具体来说,新闻的一个特征表示向量ci由子矩阵Wi:i+l-1产生。
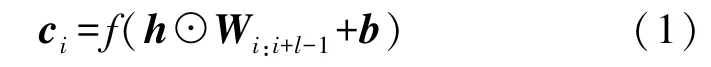
其中,f为非线性函数,⊙为卷积操作,b为偏置向量。将卷积应用于词嵌入矩阵中的每个可能位置后得到特征图。
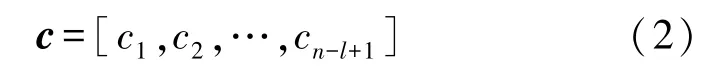
然后在特征图上使用最大池化操作来提取标题中最重要的特征。
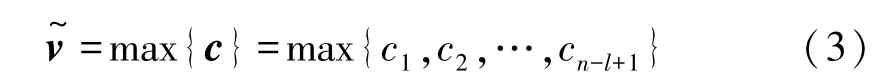
最后将这些特征进行拼接形成新闻特征表示向量v。
2.3 兴趣感知注意力层
兴趣感知注意力层根据用户在会话内点击的新闻记录的顺序信息并结合自注意力机制来学习用户在该会话内的主要阅读兴趣。由于用户点击新闻的顺序信息可以很好地反映一段时间内用户兴趣的变化和多样性,因此,使用GRU网络对用户顺序行为进行建模。给定一个会话中用户点击的新闻序列Sj={xj,1,xj,2,…,xj,t},则它们的嵌入表示为{vj,1,vj,2,…,vj,t}。将新闻特征嵌入表示向量作为 GRU的输入,在每个时间步长它都会生成一个隐藏状态hj,k,它由先前的隐藏状态hj,k-1和候选状态线性组成,其中1≤k≤t。使用每个隐藏状态作为用户的兴趣表示

更新门为zj,k
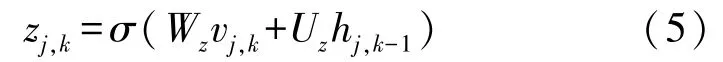
其中,Wz,Uz∈Rd×d为更新参数,σ(·)为 sigmoid 函数。 候选隐藏状态的计算公式为
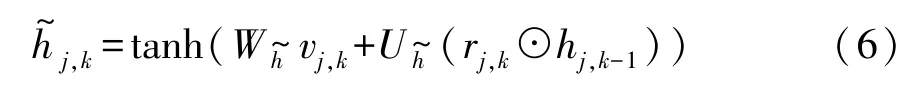
重置门的隐藏状态rj,k为

其中,Wr,Ur∈Rd×d为重置参数。
在获得了用户每个时间步长的隐藏状态后,使用自注意力机制去捕捉序列中用户点击项之间的长距离依赖关系。自注意力是注意力机制的一种特例,它以序列本身作为查询,键和值向量,通过单个序列与其自身匹配来捕获序列内部用户对于不同新闻项的注意力。将GRU输出的隐藏特征Hj={hj,1,hj,2,…,hj,t}通过非线性变换投影到相同的特征空间
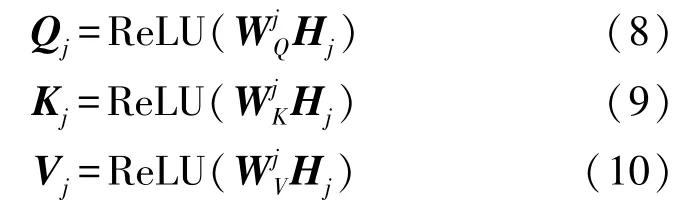
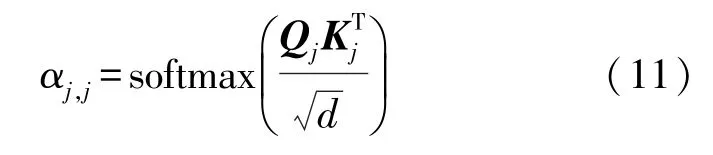
其中,αj,j∈Rd×t。比例因子是为了避免点积过大并加快收敛。因此用户在第j个会话中的主要兴趣特征pj可以表示为:
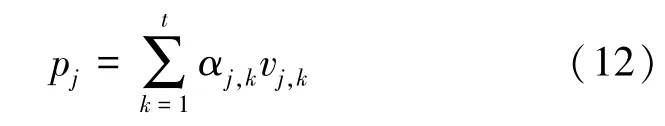
最终通过兴趣感知注意力层能够得到各个会话下的用户兴趣集P={p1,p2,…,pm}。
2.4 会话感知注意力层
由于会话内的行为有限,缺乏用户的长期行为交互,不足以进行准确的预测。考虑到用户不同时期的会话体现了用户的阅读兴趣,并且会话之间并非彼此绝对独立,因此使用注意力机制来建模当前会话和历史会话之间用户兴趣的关联程度。
将兴趣感知注意层提取的各个会话下用户主要兴趣集P={p1,p2,…,pm}作为会话感知注意力层的输入。因此各个会话用户兴趣的注意力权重为
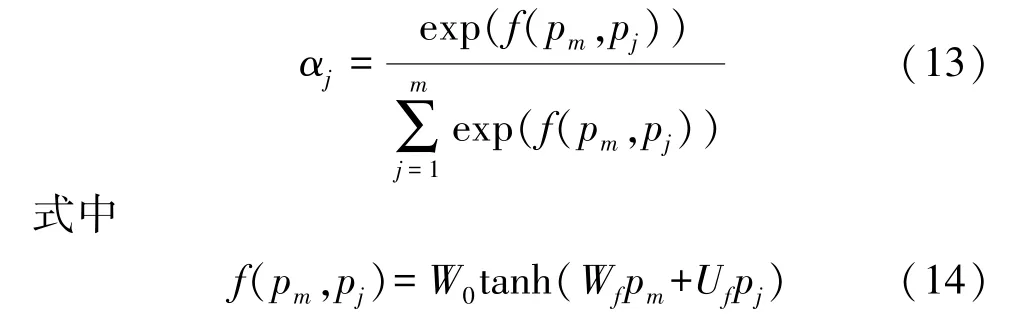
其中,W0∈Rd,Wf∈Rd×d,Uf∈Rd×d。 将各个会话下的用户兴趣融合生成最终的用户兴趣表示
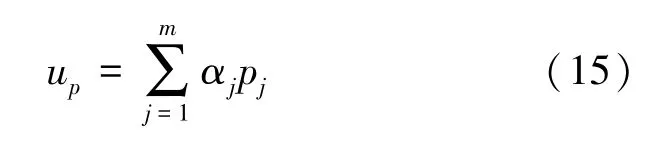
2.5 推荐
设vc为候选新闻嵌入表示,在获取用户u的嵌入表示up后,通过点积计算候选项的得分

最后通过函数softmax来获取模型的预测值
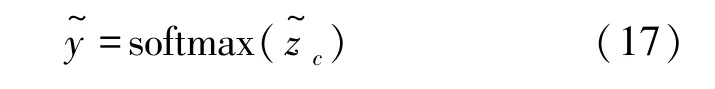
其中,表示用户u点击候选新闻项的概率。
为了训练提出的模型,从现有观察到的点击阅读历史中选择正样本,从未观察到的阅读中选择负样本。 训练样本表示为X=(su,x,y),其中x是预测是否点击的候选新闻项。输入正样本时,y值为1,负样本y值为0。使用交叉熵损失作为损失函数,则有

3 实验结果与分析
为了验证TLAM-NR模型的有效性和准确性,本节首先介绍整个实验的实验准备,然后展示实验结果并对其进行分析。
3.1 实验准备
主要对数据集、实验环境与具体设置、基准方法与评价指标这3个方面进行叙述。
(1) 数据集
为了验证提出模型的有效性,选取了真实世界的数据集Adressa[24]进行实验。使用两种版本的数据集Adressa-1week和Adressa-1month,分别对应一周和一个月的新闻点击日志。选择具有订阅服务的非匿名用户,移除了少于3个交互的会话,并且保留了4个以上会话以提供足够的历史会话信息。对于每个用户,80%的会话划分在训练集中,剩下的用于构建测试集。将每个用户的会话集分成一系列的序列和标签。 例如,对于会话集,生成历史会话和当前会话以及标签。 统计数据如表2所示。
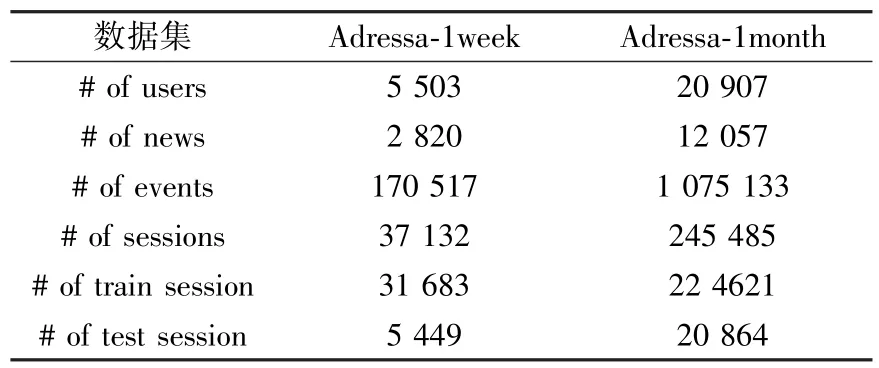
表2 Adressa数据集
(2)实验环境和具体设置
实验环境是 CPU 为 Intel(R)Xeon(R) silver 4210@2.20 GHz,内存 64 GB,系统为 Ubuntu16.04LTS。为了实现TLAM-NR,主要使用python及其深度学习框架TensorFlow与科学运算库Numpy实现。使用Adam方法来优化损失函数,设置卷积核窗口大小为{2,3,4},GRU 隐藏单元设置为 100,隐藏层设置为1,学习率设置为0.001,批处理大小设置为256。
(3)基准方法与评估指标
在Adressa两个版本的数据集上与4个基准方法进行了对比:
DeepJoNN[5]使用基于张量的卷积神经网络提取基于会话的新闻特征表示,并使用RNN来捕获点击和相关特征流中的顺序模式。
LSTUR[6]利用门控循环单元(GRU)捕获用户行为序列中的顺序信息,从而学习用户的长期兴趣,并将GRU网络的最后一个隐藏状态作为用户的短期兴趣,最后结合长短期兴趣形成统一的用户表示。
DAN[7]设计了一种基于注意力机制的RNN来捕获用户近期点击新闻的顺序信息,实现新闻推荐。
TANN[8]使用自注意力机制来发现用户交互序列中的顺序模式,以学习更准确的用户短期兴趣,并将通过潜在因子模型获得的长期兴趣和短期兴趣拼接进行预测。
为了评估推荐效果,采用了3种广泛采用的指标:
①MRR@K。平均倒数排名,即被正确推荐项目的倒数排名的平均值,当排名位置超过K时,倒数排名设置为0。MRR评估指标考虑了推荐排名的顺序,其中MRR值大的表示正确推荐的项目位于排名列表的顶部,表达形式为
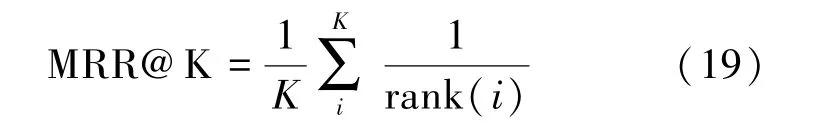
②nDCG@K。归一化折损累计增益,其表达形式为
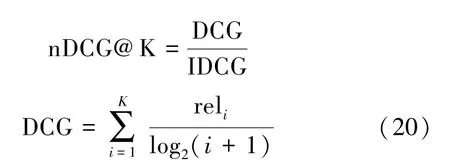
在计算折扣累积收益(DCG)的式(20)中,reli表示第i个推荐的相关程度。当reli=1时表明该项目实际被选中,否则 reli=0。IDCG是归一化的DCG,即根据理想排序,获得的最大DCG值。
③AUC。ROC曲线下面积,表示从样本中取正样本的预测值大于负样本的概率,定义为
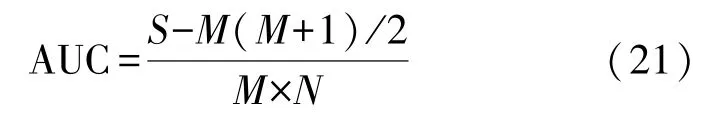
其中,M,N分别代表正样本和负样本的个数,S为所有样本的排名。
3.2 实验结果与分析
(1)推荐模型结果比较
将TLAM-NR模型与基准方法进行比较,表3和表4分别显示了在 Adressa-1week和 Adressa-1month两个版本数据集上各个方法的结果。
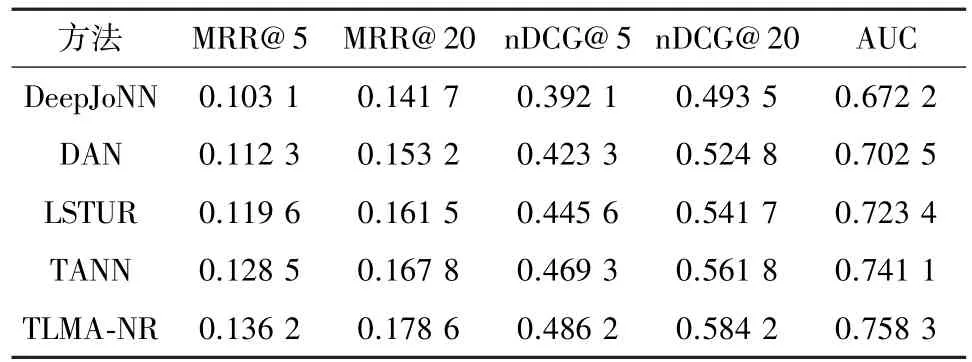
表3 在Adressa-1week数据集上不同方法的性能比较
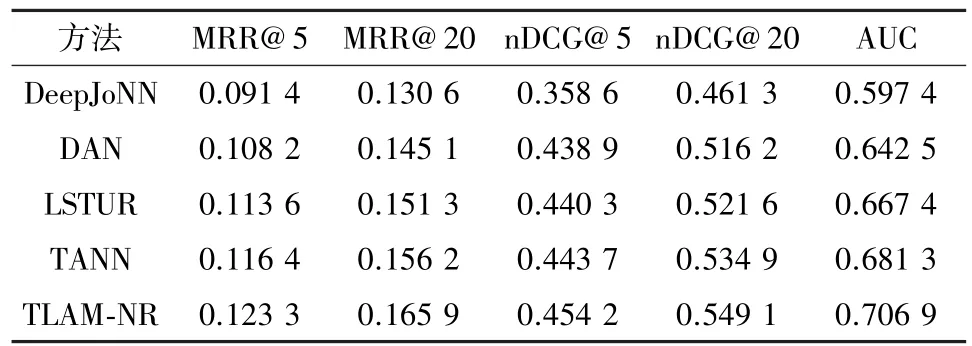
表4 在Adressa-1month数据集上不同方法的性能比较
从表3和4可以看出,TLAM-NR的指标在所有基准方法中总体性能表现最佳,尤其是MRR@5和nDCG@20分别提高了6.43%和3.98%,这验证了TLAM-NR模型的有效性。这是因为TLAM-NR模型不仅利用门控循环单元捕捉用户的顺序信息,而且结合了自注意力机制更好地学习会话内用户的主要兴趣。此外,相较于其他基准方法,所提的模型不仅考虑了会话内的用户交互行为,而且还考虑了会话之间用户兴趣关联性,从而进一步提升推荐的性能。
(2)模型变体分析
对模型的 3种变体进行了比较:(1)变体TLAM-NR-H不考虑使用自注意力机制学习各个会话内用户的主要兴趣。(2)变体TLAM-NR-S不考虑使用注意力机制学习用户兴趣在当前会话与历史会话之间的相关性。(3)变体TLAM-NR则同时考虑了各个会话内用户的主要兴趣以及用户兴趣在会话之间的关系。图2和图3分别显示在两个版本数据集上的实验结果。
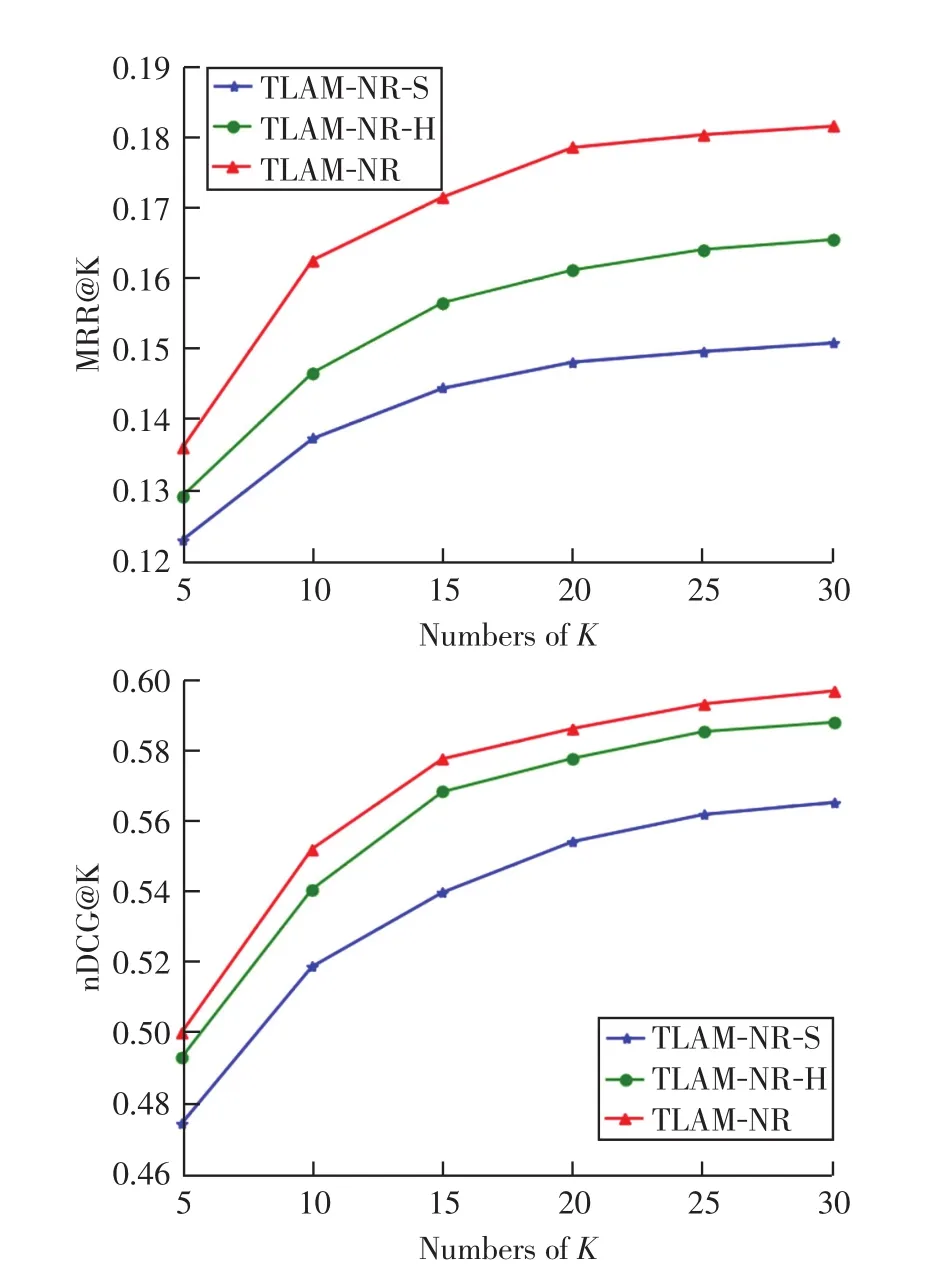
图2 Adressa-1week

图3 Adressa-1month
从图2和图3可以看出,当不使用自注意力机制学习会话内的用户兴趣时模型性能会下降明显,这验证了兴趣感知注意力层设计的有效性,这是因为自注意力机制能够学习会话内各个点击新闻项所占的不同权重,可以有效捕捉单个会话下用户的主要兴趣。此外,当移除会话感知注意力层时,实验结果稍差,这说明对不同会话之间的用户兴趣相关性进行建模从而学习最终的用户表示是合理的。
(3)模型参数分析
主要分析新闻特征嵌入维度和会话数量对于推荐模型性能的影响。
特征维度的影响。分别设置新闻特征嵌入向量的维度d为{50,100,150,200}。 观察特征维度对指标MRR@20和nDCG@20值的影响如图4所示。
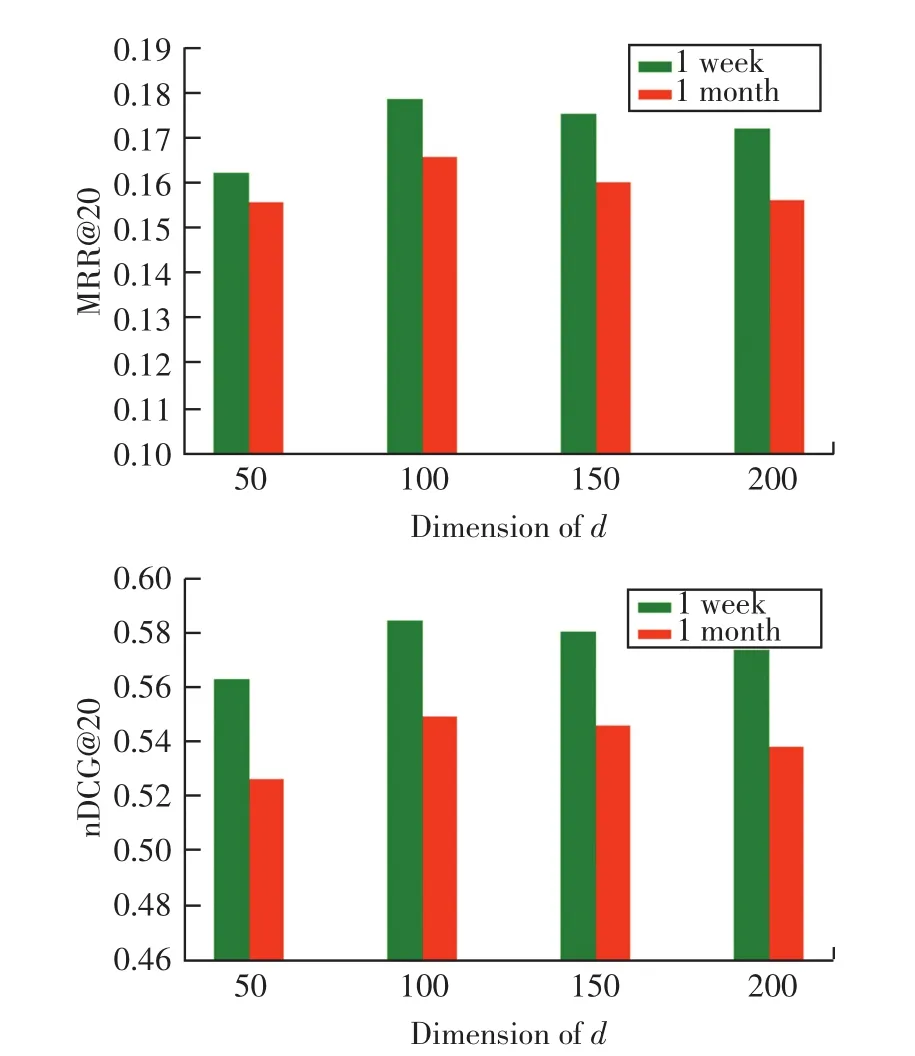
图4 特征维度d对于推荐性能的影响
从图4可以看出模型性能随着d的增加先增加,后降低。当d的维度等于100时推荐性能最佳,这表明该维度最能表达新闻的语义信息。综合以上情况分析,过低的维数不足以捕获有效的信息,而过高的维数会导致模型的过拟合,这些情况都会导致推荐性能的下降。
会话数量的影响。图5给出了随着会话数量增加,评估指标值的变化趋势。
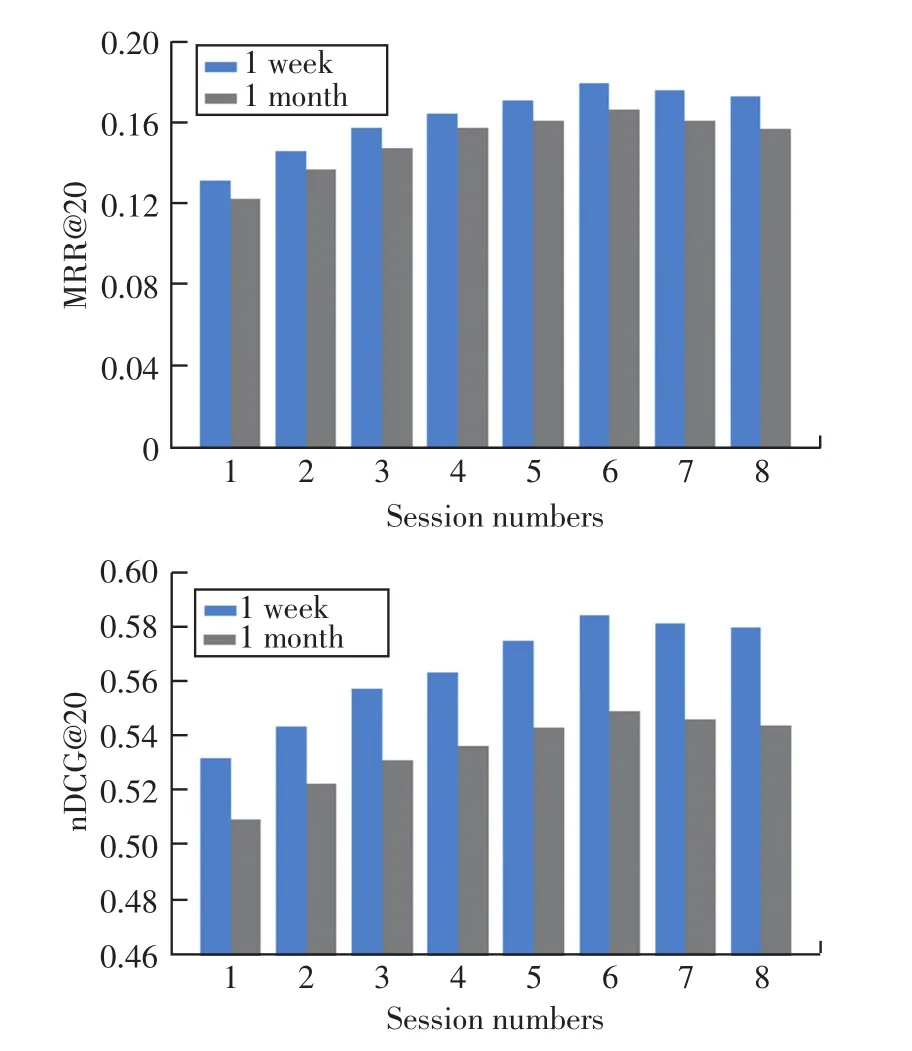
图5 会话数量对于推荐性能的影响
从图5可以看到,随着会话数量的增加,模型性能逐渐提高,这说明引入历史会话信息可以丰富用户的兴趣表示,提高推荐的准确性。但是当会话数量大于6时,模型性能有所下降,可能的原因是用户兴趣随着时间而发生偏移,这意味着结合过多的会话信息会给融合后的用户表示带来一定程度的噪声。
4 结束语
本文提出了一种基于会话的双层注意力机制新闻推荐模型(TLAM-NR)。该模型综合分析了会话内和会话间的用户兴趣,它不仅利用兴趣感知注意力层捕捉会话内用户的主要兴趣,而且还使用会话感知注意力层建模当前会话与历史会话之间用户兴趣的相关度,有效地捕捉不断变化的用户兴趣并实现新闻推荐,进而提高新闻推荐的准确度。
在后续工作中,将利用更多的新闻属性信息(如主题、类别以及实体关系等)来挖掘深层次的新闻语义特征,进一步提高新闻推荐的性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
疯狂英语(双语世界)(2017年4期)2017-04-28 09:10:37
海外华文教育(2016年3期)2017-01-20 08:22:18
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电视技术(2014年19期)2014-03-11 15:38:20
山西大同大学学报(社会科学版)(2014年5期)2014-01-23 01:30:51
