
改进U-net的红外影厅图像人数统计方法
2021-03-23 09:38侯慧欣吕学强游新冬
计算机工程与设计 2021年3期
侯慧欣,吕学强,游新冬,黄 跃
(1.北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101;2.首都医科大学 宣武医院,北京 100053)
0 引 言
人数统计是智能监控领域一个重要的研究分支,在电影院场景下,这一技术的应用可以帮助实时统计电影票房,有效防止“偷票房”、“幽灵场”等现象的发生。目前主流的人数统计方法主要分为基于检测的方法和基于回归的方法两大类[1]。基于检测的方法[2-4]通过检测人体整体或局部的特征直接检测到人体,进而统计人数。基于回归的方法[5,6]首先提取人群的整体特征,然后根据提取的特征建立其与人数之间的映射关系,利用回归算法获得图像中的人数。无论哪一种方法,其中一步很重要的工作就是前景提取。前景提取的好坏直接关系到后续人体检测、特征提取、回归等的效果。现有的前景提取方法大多数仅仅针对固定场景下的运动人群,无法克服人群分割中的所有问题,且可移植性差,只能处理某一固定场景的图像。针对这一问题,张君军提出将全卷积网络[7]应用于人群分割的设想,目前已有学者对此进行了研究,但针对影厅场景的研究还未深入。
针对影厅这一复杂背景,由于可利用的数据集很小,因此选用语义分割中适用于小数据集训练的U-net[8]网络作为基础网络架构,再针对其速度慢、边缘分割效果差等问题,采用Inception[9]网络中的卷积策略以及扩张卷积[10]进行改进,最后利用改进透视效应校正方法结合线性回归,实现观影人数统计。
1 相关工作
近年来,随着越来越多的深度学习方法被应用到计算机视觉任务中,一些学者开始尝试将卷积神经网络应用到前景提取和人群计数中。
Braham等[11]最先将卷积神经网络应用于前景提取,实验结果表明,使用神经网络能有效提高传统前景提取方法的精度且大大降低了背景减除过程的复杂性。此后,Wang等[12]提出一种多尺度级联卷积神经网络结构用于前景分割,使用不同比例对输入帧进行下采样。该网络结构相比其它网络结构取得了更高的精度,但其速度慢、计算冗余、精度低。针对以上问题,曾冬冬[13]首先尝试将全卷积网络应用到前景提取上,提出一种多尺度全卷积网络,该方法在精度上取得了较优的效果且能满足实时性要求。
深度学习方法在人群计数方面的研究也越来越深入。刘思琦等[14]利用扩张卷积网络进行人群特征提取,再通过对抗式损失函数将网络中提取的不同尺度的特征信息融合,得到密度估计结果。Boominathan等[15]使用深层和浅层结合的全卷积网络来预测给定人群图像的密度图,在UCF_CC_50数据集上进行测试,取得了较好的结果。J. Wang等[16]提出一种新的全卷积网络,通过对人群密度分布进行回归,实现对图像的人群计数。J. Fu等[17]设计了一种引入长短时记忆结构的CNN-RNN人群计数神经网络,能有效地预测高密度群体的人群密度。陈朋等[18]提出一种基于多层次特征融合网络的人群密度估计方法,利用多层次特征融合网络进行人群特征的提取、融合、生成人群密度图,最后对人群密度图进行积分计算求出对应人群的数量。
这些方法均为人数统计技术的发展做出了重要的贡献。但在本应用场景下,首先影院背景复杂度较高,易受光线、温度等因素的影响,传统前景提取方难以适用。其次,由于影厅面积较大,拍摄时透视效应严重,后排人体成像与前排差距较大。且实际可利用的图像数据量小。
因此,针对以上问题,本文主要贡献如下:
(1)提出了一种IDU-net的前景提取方法,有效解决了因影厅背景复杂导致的前景提取效果不好问题,提高了前景提取的准确性,为后续人数统计工作奠定了良好的技术基础。
(2)提出了一种改进透视效应校正方法,结合线性回归方法实现影厅人群计数。
(3)整理了3个影厅共300张图片数据,并在此数据集上进行大量实验,结果表明,提出的方法在前景提取及人数统计上均取得了最高的准确率。
2 基于IDU-net的红外影厅图像人数统计方法
本文提出的红外影厅图像人数统计算法流程主要包含以下步骤:
(1)图像预处理,主要包括对原始红外影厅图像进行预处理和制作标签图像;
(2)前景提取,利用IDU-net网络进行端到端训练,提取前景图像。常用前景提取方法包括ViBe算法、高斯混合模型等;
(3)透视效应校正,首先根据随机采样的数据进行拟合,明确纵坐标对成像大小的影响,再根据拟合结果进行校正,计算前景面积;
(4)建立前景面积与人数的回归关系,计算人数统计结果。
算法流程框架如图1所示。
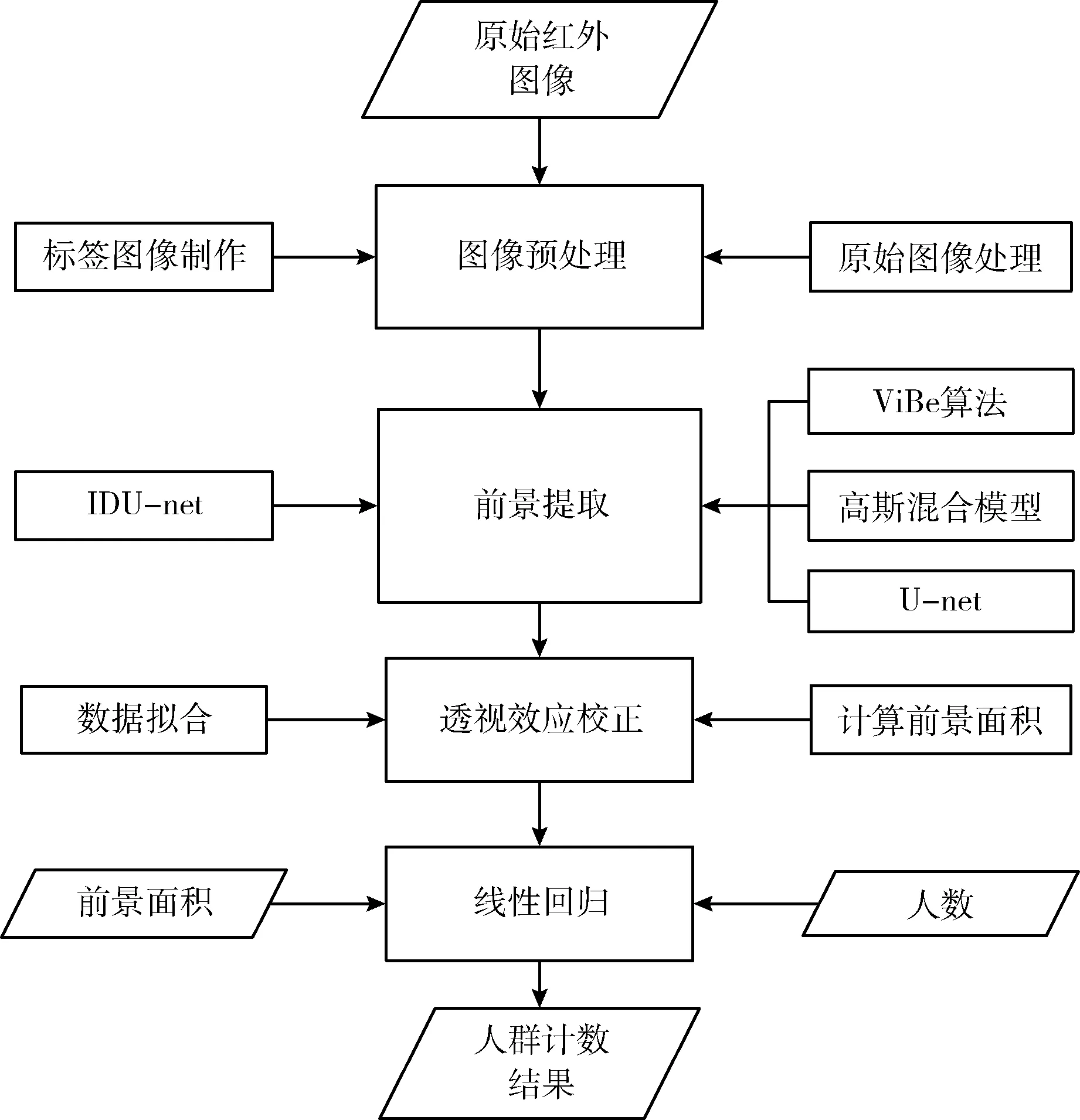
图1 算法流程框架
2.1 IDU-net:改进的U-net前景提取方法

图2 IDU-net网络架构
为实现观影人数统计,首先需要将人群与背景分割开,因此第一步重点工作是前景提取。本文采用U-net网络作为基本架构,如图2所示,U-net网络为一个U形结构,左侧为encoder部分,是重复卷积-卷积-最大池化的过程,用于获取图像的高层抽象信息;右侧为decoder部分,通过上采样操作还原分辨率信息,同时与上层提取的feature map进行concatenate操作。
但原U-net网络存在两个问题:①架构较大,训练时需耗费大量计算资源与时间;②原网络把输入图像下采样到非常小的特征图会使场景的空间结构不那么清晰,失去部分位置信息,不仅限制了分类的准确率,还影响前景提取的边缘分割效果。针对以上两个问题,本文对原网络进行改进。首先为了提高训练速度,本文采用Inception网络中的策略:将n×n的卷积核尺寸分解为1×n和n×1两个卷积。在进行卷积操作时,原网络采用3×3的卷积核,为了减少参数,提高训练速度,参考Inception网络中的卷积方式,采用1×3与3×1的卷积方式替代原有卷积,这种方法在成本上比单个3×3的卷积核降低33%。这种方法有效地减少了训练过程中的参数量,且减少了训练时长。其次,为了尽可能保留原图像的位置信息,提高分类准确率,本文将扩张卷积方法应用到U-net网络中。扩张卷积的好处就是既能保持原有网络的感受野,同时又不会损失图像空间的分辨率。这种方法使得网络在对图像进行下采样时能保留前景的边缘信息及位置信息,同时提高了将模型迁移到其它场景的性能。
U-net网络各层均采用ReLU非线性函数作为激活函数。由于本问题本质是一个二分类问题,因此采用对数损失函数定义模型误差,损失函数公式如式(1)所示
(1)
式中:n为像素总数,yi为第i个像素点真实类别(1或0),si为第i个样本点经过模型预测结果。
2.2 改进透视效应校正及回归模型
由于透视效应的作用,高度相同物体的成像大小与其和摄像机镜头的距离成反比。因此,只有透视校正后的前景区域面积才能更为准确地反映场景中的实际人数[19]。由于影厅图像四周存在许多背景区域,而在进行前景提取时这部分区域容易被误判为前景,如果直接对这部分区域进行透视效应校正,会影响后续人数统计效果。针对此问题,对透视效应校正方法进行改进,标记图像中的背景与前景区域,对两部分区域分别进行处理,使其更适用于影厅场景。
首先,为了明确纵坐标对成像尺寸是如何影响的以及其影响程度,随机选取50个点记录其纵坐标以及该点所在的座椅尺寸,画出其散点图,如图3所示,然后根据散点图显示的规律分别进行拟合,得到拟合系数α,β。

图3 座椅成像高度随纵坐标变化散点
改进后对位于坐标 (x,y) 的点,其高度计算公式如下
(2)
式中:h为校正后高度,H为图像高度。
传统的前景面积S计算公式如下
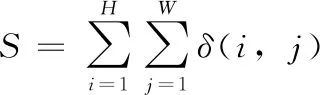
(3)
校正透视效应后,原有的前景面积计算公式需相应的进行修改。修改后前景面积计算公式如下
(4)
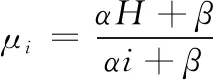
根据提取的前景面积,建立归一化前景与人数之间的回归模型。由于在影厅场景下,人群之间遮挡问题较小,前景面积与人群基本呈线性关系,因此使用线性回归模型。
3 实验结果及分析
为了验证本文人群统计方法的精度以及对不同场景的适应性,将基于U-net的前景提取方法与背景差分法、混合高斯模型、ViBe算法进行对比,分别比较4种方法的前景提取效果以及人数统计精度。
3.1 数据集及评价标准
本文使用的数据集为中国电影科学技术研究所提供的300张红外观影图像,包括3个座位分布不同的影厅图像各100张。
针对前景提取的效果评价,本文使用如下5个量化指标:分类准确率PCC(percentage correct classification)、召回率R(recall)、准确率PR(precision)、假负率FNR(false negative rate)、假正率FPR(false positive rate)。分类准确率表示正确检测到的前景的像素数和背景像素数占所有像素的比例,作为算法的整体性能指标。召回率表示提取的前景像素点与所有前景像素点的比例。准确率表示提取的前景像素点中真实前景像素点的比例。假正率分别表示检测到的错误前景比例,假负率表示误判为背景的前景像素占背景像素数的比例。分类准确率、召回率及前景准确率越高,表明算法提取效果越好。假正率、假负率越低,算法性能越佳
(5)
(6)
(7)
(8)
(9)
其中,TP为正确检测到的前景像素点个数,FP为背景中被误判为前景的像素点个数,TN为正确的背景像素点个数,FN为前景中被误判为背景的像素点个数。
对于3种方法的人数统计精度,使用平均准确率MAR(mean accuracy rate)、平均相对误差MRE(mean relative error)、平均绝对误差MAE(mean absolute error)等评价指标来评价估测误差。MAE、MRE、MAR定义如下
(10)
(11)
(12)
其中,N为图片总张数,G(i) 是第i张图像经过算法预测的结果人数,T(i) 是第i张图像经手工标出的人数,作为参考值。
3.2 实验结果
本文将所提方法与混合高斯模型、ViBe算法、原 U-net 模型进行对比,分别比较其前景提取效果、人数统计结果。
3.2.1 定量分析
(1)前景提取效果对比
本文将所提方法与传统前景提取方法:混合高斯模型、ViBe算法、原U-net模型进行比较,分别从召回率(R)、准确率(PR)、假负率(FPR)、假正率(FNR)以及分类准确率(PCC)5个指标进行对比。结果见表1。
从召回率上看,ViBe算法、原U-net模型、IDU-net模型均表现良好,这表明这3个方法均能将前景区域提取出来。但结合准确率来看,ViBe算法虽然能正确提取前景区域,但同样会将大量背景区域误判为前景区域,因此该方法无法正确的将前景与背景区域分割开。而混合高斯模型虽然准确率较高,但召回率却很低,这表示混合高斯模型能较好的将前景与背景区分开,但是该方法提取的前景不完整,因此该方法表现也较差。相比之下原U-net模型、IDU-net模型的召回率、准确率均较高,表明这两种方法表现优于混合高斯模型与ViBe算法。其中,IDU-net模型在这两个指标上均高于原U-net模型,这表明改进后的模型前景提取效果更佳。
从假负率与假正率这两个指标来看,混合高斯模型假负率最低但假正率最高,这也表明其将大量背景像素点误判为前景像素点。而ViBe算法正相反,假负率最高而假正率最低,这表明该方法易将许多前景像素点误判为背景像素点。原U-net模型、IDU-net模型方法的假正率、假负率虽然均不是最低,但是其两个指标均保持在较低的范围。这表明这两种方法虽然都会出现将前景误判为背景或者将背景误判为前景的情况,但都处于误差可接受范围内。其中原U-net模型比IDU-net模型的假负率高,假正率低。这表明原U-net模型更易将背景区域误识别为前景,因此提取的前景区域会多于正确的前景区域。相比而言,IDU-net模型假正率与假负率几乎保持平衡,虽然不是最低,但是针对前景区域面积提取这一情况效果最佳。
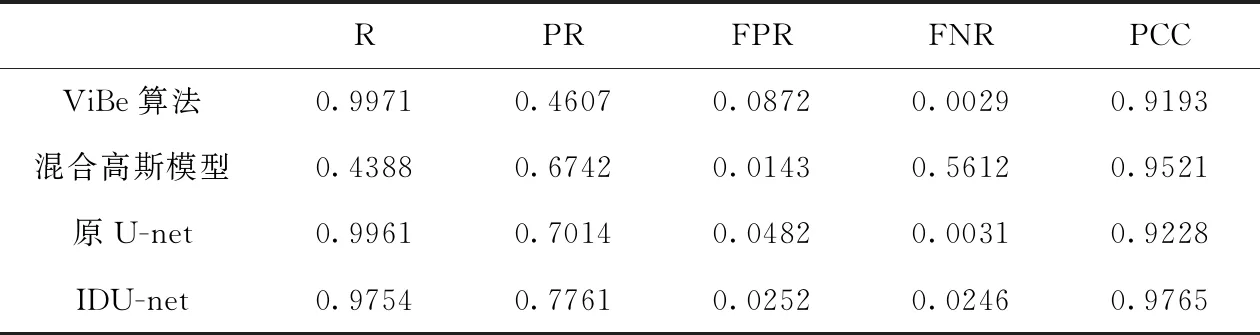
表1 前景提取效果对比
从分类准确率这一综合指标来看,IDU-net模型分类准确率达97.65%,高于其它3种方法。这直接表明,IDU-net模型在影厅这一场景下前景提取效果最佳。
(2)人群计数效果对比
本文从平均准确率、平均相对误差、平均绝对误差3个指标来分析4种方法的人群计数效果。分别将改进前后的透视效应校正方法应用在4种前景提取算法上的结果进行对比。结果见表2。

表2 人数统计结果对比
从结果可以看出,IDU-net前景提取算法能有效提高人数统计准确率。相比原U-net模型、混合高斯模型、ViBe算法,IDU-net模型的准确率较高且误差较小。同样,从实验结果来看,改进透视效应校正方法相比原透视效应校正方法,在4种前景提取方法上的人数统计准确率均获得了有效提高,误差也有所下降。但由于原U-net模型与IDU-net模型能有效切割出前景区域,因此改进透视效应校正方法在这两个前景提取方法上改进效果较小。在前景提取效果不佳的混合高斯模型与ViBe算法上效果提升较大。综合来看,IDU-net前景提取方法与改进透视效应校正方法相结合能获得最佳人数统计结果,其准确率达到89.79%。
3.2.2 定性分析
本文将所提IDU-net前景提取方法与高斯混合模型、ViBe算法、原U-net模型进行对比。在此主要选取:①密集人群+清晰背景;②密集人群+模糊背景;③稀疏人群+清晰背景;④稀疏人群+模糊背景,共4组图片进行定性分析。结果见表3。
通过对比发现:
(1)IDU-net的3个模型均对影厅这一场景具有极高的鲁棒性,无论是人群密集或稀疏,无论图片清晰或模糊,均几乎完美分割开了人群与背景,避免了复杂背景的干扰。
(2)GMM算法在密集人群场景下分割效果较好,但在稀疏人群场景下,前景提取效果较差,无法完全提取出前景区域。GMM算法对背景的光线变化鲁棒性良好。但总体而言,GMM算法无法完全避免复杂背景的干扰,提取的前景区域中包含许多背景信息。
(3)ViBe算法在这4种方法中表现最差,虽然该方法几乎能提取出所有前景区域,但受到复杂背景的干扰,将背景误判为前景的情况十分严重,提取的前景面积中包含大量背景信息。在稀疏人群场景下表现尤其差。
(4)原U-net模型相比传统方法表现较好,对这4种场景均适应良好,且能避免复杂背景的干扰,提取出正确的前景区域。但相比IDU-net模型,其缺点在于提取的前景区域边缘模糊,没有明显的人形轮廓。通过图4的细节对比图可发现:当人群较为集中时,原U-net模型提取的前景区域中边界较为模糊,人与人之间易发生粘连,存在大片模糊区域。相比之下,IDU-net模型前景提取结果具有较为清晰的边界,相较而言具有更为清楚的人形轮廓。
在3个影厅测试图片下,本文所提方法的效果都明显优于GMM算法、ViBe算法。而且本文所提方法无论是在人群稀疏还是密集场景,均能够得到较好的前景提取效果,增强了算法对不同场景、不同光线的鲁棒性,扩大了算法的应用范围。

表3 前景提取效果对比

图4 前景提取结果细节对比
4 结束语
针对传统前景提取方法在影厅这一场景下无法避免复杂背景干扰问题,提出IDU-net模型进行影厅图像前景提取,然后对提取的前景区域进行改进透视效应校正,统计校正后的前景面积后进行线性回归,得到最终人数统计结果。通过与混合高斯模型、ViBe算法、原U-net模型等前景提取方法进行对比,验证了本文方法在影厅这一场景下前景提取的有效性。但是本文方法还存在一些问题,目前在影厅场景下人群统计技术仍旧依赖于不同影厅的座位分布情况,无法直接移植到其它影厅,后期可以在人群统计方法的通用性、可移植性上进行更多研究,可以利用前景图像的其它特征对前景面积进行自动校正。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
建材发展导向(2021年6期)2021-06-09
今日农业(2020年17期)2020-12-15
中国外汇(2019年11期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
综艺报(2018年5期)2018-03-19
恋爱婚姻家庭·养生版(2017年7期)2017-07-05
恋爱婚姻家庭(2017年21期)2017-07-05
意林(2017年6期)2017-04-05
