
融入新的特征选择机制的文本数据聚类算法
2021-03-23 09:38:42田夏利
计算机工程与设计 2021年3期
田夏利,熊 莹
(武汉华夏理工学院 信息工程学院,湖北 武汉 430223)
0 引 言
文本聚类是将文本信息划分为预定数量的文本群组的过程[1],广泛应用于文本挖掘领域[2]。矢量空间模型是用于文本挖掘的标准模型,它将文本特征表示为权重矢量。模型中,每个词条权重被描述为一维空间。因此,聚类效果主要受维度空间大小和无用特征量的影响[3]。文本文档中包含有用特征和无用特征,无用特征属于噪声和冗余特征。非监督特征选择的任务是寻找文档中新的有用特征最优子集,该技术可增强聚类效果,且不依赖于文档标签的先验知识。特征选择需要重点解决:①如何改善文本聚类效果;②如何准确获取最多有用特征[4,5]。文本挖掘都得益于特征选择,如文本聚类、基于聚类特征选择的文本划分、文本信息检索等。文本聚类即将数字文本集合划分为群组子集,是提供易于访问的非监督学习手段。而文本聚类的目标是寻找最优解将文本集合划分。
本文设计了基于粒子群算法的特征选择方法,可用于消除无用特征而选择有用特征的最优子集。在多个文本数据集的测试下,利用K均值文本聚类算法进行算法性能评测。结果显示,从快速聚类效果和特征维度降低效果上看,所提算法明显优于没有使用任何特征选择的K均值算法;而与另外两种利用特征选择的聚类方法相比,本文算法在各项性能指标上也是占优的。
1 相关研究
文献[6]针对传统K均值聚类在初始质心选取上的随机性,改进了初始质心的选择方法,为样本点引入了局部密度指标,并根据局部密度分布,选择密度峰值点作为初始质心,得到了更高的文本聚类准确度。文献[7]针对特征词的稀疏性,提出一种结合语义K均值文本聚类算法。算法以词语集表示短文本,缓解了短文本特征词的稀疏性问题;并通过挖掘文本集合的最大频繁词集得到聚类质心,克服了算法对初始质心的敏感度,得到较优的文本聚类效果。文献[8]提出一种基于增强蜂群优化搜索与K均值相结合的文本聚类算法。算法首先引入公平与克隆操作提高全局搜索能力,提高样本多样性并增强蜂群搜索能力。同时,克隆操作增强了各代之间的信息交流,提高了文本聚类质量。文献[9]提出基于后缀树文档模型的半监督自适应多密度文本聚类算法,该算法基于后缀树文档模型表征文档间的相似度,使用K最近邻思想传播扩展簇标签,并在传播扩展过程中不断更新扩展阈值,以适应多密度不平衡的文本数据集。文献[10]为了改进文本聚类性能,设计了基于遗传算法的特征选择机制。文献[11]同样提出了一种基于和声搜索算法的特征选择算法对文本聚类效果进行改善。以上两种算法在文本聚类时均采用了K均值聚类算法,以遗传算法和和声搜索机制得到的新的文本特征子集作为K均值聚类的输入,更好地收集了最优的信息性特征子集进行文本聚类,在聚类准确率和精确率上拥有更好的效果。
2 算法详细设计
基于粒子群优化的特征选择可以寻找最优的文本特征的最优子集进而改进文本聚类性能,其算法过程分为3个阶段:
(1)文本文档预处理阶段。该阶段包括词语切分(令牌化)、终止词移除、词干提取以及词条权重计算,如图1所示。
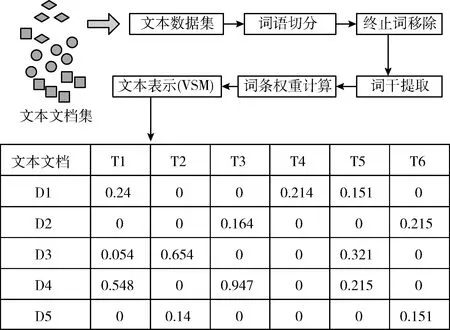
图1 文本预处理阶段
(2)第二阶段利用粒子群优化算法通过消除无用文本特征解决特征选择问题。图2是所提算法的第二阶段,粒子群算法用于寻找新的有用文本特征的子集,且算法运行在每个文档层次上,直到达到最大迭代数。在所有数据集中的文档上过滤后,粒子群算法将联合所有生成的文档子集以生成拥有有用特征的新的数据集。
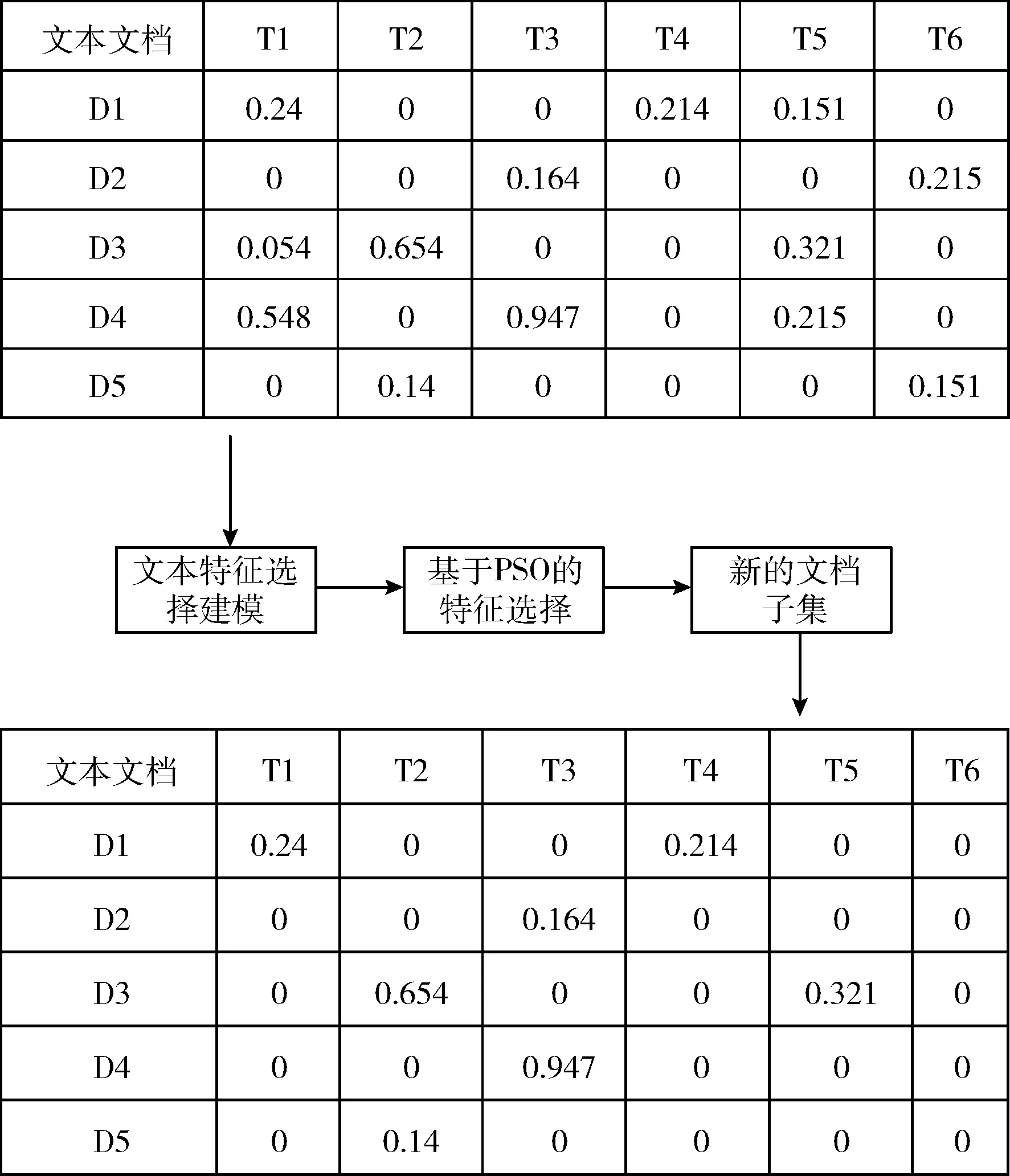
图2 特征选择阶段
(3)第三阶段利用K均值文本聚类方法将文档划分为不同聚类。图3是文档聚类的最后阶段。
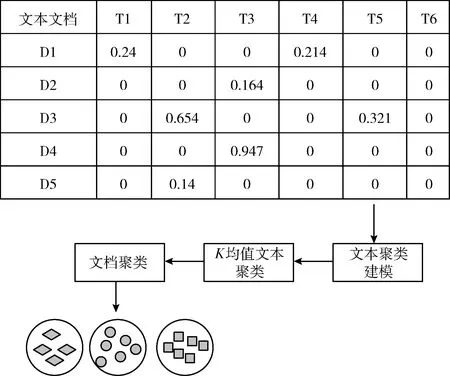
图3 文本聚类阶段
2.1 文本预处理
(1)词语切分
词语切分即是将文本文档流分割为词语或词条的过程,并移除空格部分。每个词语或符号从首字母至最后一个字母进行扫描,而每个词语则可视为一个令牌。
(2)终止词移除
常规词语,如an,that,be以及一些常用词语通常拥有较小权重,但却是高频率词语,文本聚类时可作为终止词语。该类词语需要从文档中移除,由于会影响文本聚类的效果。
(3)词干提取
词干提取即是通过移除每个词语的前缀和后缀将其转换到相同的词根上。例如:intersect,dissect,section均拥有相同的构词部分sect,可将其定义为特征。本文将利用Porter提词器进行词干提取任务,该工具是目前文本挖掘领域中最为常用的词干提取方法。
(4)词条权重计算
词条权重根据每个文档中的词条频率分配至每个词条或特征。若词条频率较高,且相同特征出现在多个文档中,则该特征可用于区分文档内容。文档i中特征j的词条权重计算为
wi,j=tf(i,j)×idf(i,j)=tf(i,j)×logn/df(j)
(1)
式中:wi,j为文档i中词条j的权重,tf(i,j) 为文档i中词条j的出现,idf(i,j) 为倒数文档频率,n为数据集中的文档数量,df(j) 为包括特征j的文档数量。以下表达式表示利用矢量空间模型VSM表示的文档标准格式
(2)
2.2 基于粒子群优化的特征选择机制
(1)特征选择模型
特征选择问题可表示为寻找一个有用特征最优子集的最优化问题。给定文本特征集合F,表示为矢量Fi=(fi,1,fi,b,…,fi,j,…,fi,t),t为所有唯一文本特征数量,i为文档数量。令FS为新的有用特征子集,FSi=(si,1,si,2,…,si,j,…,si,m),通过特征选择算法生成,m为新的特征长度,si,j∈{0,1},j=1,2,…,m。 若si,j=1,表明文档i中的所选特征j为有用特征;否则,若si,j=0,则表明文档i中的所选特征j为无用特征。
(2)解的表示
基于粒子群的特征选择问题中,每个解(粒子)代表一个文档特征的子集,见表1。PSO的种群包括一个粒子集合(位置),表示一个二进制矢量,每个粒子包括一些位置,即文档特征。每个位置代表文档的一个特征。粒子中的第j个位置给出第j个特征的位置。
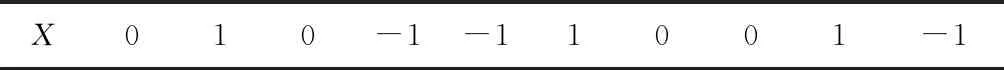
表1 特征选择的解表示
算法开始于随机解,然后不断改进种群直到得到全局最优解,最优解即是一个新的文档特征的子集。给定的数据集中的每个唯一特征考虑为一个搜索空间。如表1,若位置j等于1,则特征j选择为有用特征;若位置j等于0,特征j不选择为有用特征;若位置j为-1,则表明特征j不包括在初始文档中。
(3)适应度函数
适应度函数用于评估算法产生的候选解。每一代需要计算所有候选解的适应度。若解的质量得到改善,则该解可用于替换当前解,反之亦然。本文使用平均绝对差MAD作为基于标准权重策略TF-IDF特征选择的适应度函数。该策略用于评估特征解或粒子位置的目标函数。MAD是用于特征选择领域中的常用度量方式,可通过计算均值之差为每个文本特征分配一个相关分值(权重),然后计算均值与xi,j的中值之差为
(3)
(4)
MAD(Xi)为解i的适应度函数,xi,j为文档i中特征j的值,由词频逆文本频率指数TF-IDF计算得到,ai为文档i中所选文本特征的数量,t为所有文本特征的数量,x′i为矢量i的均值。
2.3 粒子群优化算法PSO
粒子群模拟了种群的社会行为,是通过对鸟群捕食行为的研究抽象出的迭代优化算法[12],算法首先随机初始化一个包含若干数量的种群粒子,每个粒子代表问题的一个可行解,算法的目标就是通过粒子在空间中的移动寻找目标问题的全局最优解。算法过程如算法1。
算法1: PSO
(1)input:generate the initial particles randomly//输入初始粒子
(2)output:optimal particle and its fitness value//输出最优粒子和适应度值
(3)algorithm
(4)initialize swarm and parameters of the particle swarm optimizationc1,c2andetc//种群及粒子相关参数初始化
(5)evaluate all particles using the fitness function by Eq.(3)//以适应度函数评估每个种群粒子
(6)while termination criteria do//迭代终止条件
(7) update the velocity//更新粒子速率
(8) update each position//更新粒子位置
(9) evaluate the fitness function//评估粒子适应度
(10) replaces the worst particle with best particle//以最优粒子替换最差粒子
(11) updateLBandGB//更新局部最优粒子和全局最优粒子
(12)end while
(13)return a new subset of informative featureD1//返回有用特征最优子集合
每个粒子所代表的候选解通过式(3)定义的适应度函数评估。PSO中,解包含一些单个实体(特征),算法在特征选择问题的搜索空间中运行,并对粒子所处的当前位置依据适应度函数进行评估。每个解通过根据当前和最优的适应度决定其移动的方向,直到达到代表问题最优解的粒子位置为止。PSO算法利用一个粒子群优化存储PSOM对解进行存储,表示如下
(5)
粒子位置更新如式(6),粒子移动速率更新如式(7)
xij=xij+vij
(6)
vij=w×vij+c1×rand1×(LBI-xij)+c2×rand2×(GBI-xij)
(7)
惯性权重处于[0,1]间,LBI为迭代I时当前的局部最优解,GBI为迭代I时当前的全局最优解,rand1和rand2为[0,1]间的随机数,c1和c2为两个常量学习因子。惯性权重计算方式如下
(8)
式中:wmax和wmin为最大和最小惯性权重。
由于算法需要处理二进制优化问题,本文通过每个维度上的离散值方式更新解的位置。式(9)表示用于决定位置i的概率的单峰函数,式(10)用于更新粒子的新位置
(9)
(10)
表2~表4给出了一种特征选择示例。表2是文档D中初始特征的词条频率,其中选择为无用特征的地方以黑体显示。应用特征选择机制后,无用特征将在表3中被移除。最后,若该特征不出现在任一文档中(即特征9未出现在任一文档中),维度大小将降低,进而得到特征移除后的表4结果。因此,一个新的有用特征子集D1将可以用于改进文本聚类的性能。

表2 文档初始特征的词条频率

表3 文档被移除无用特征
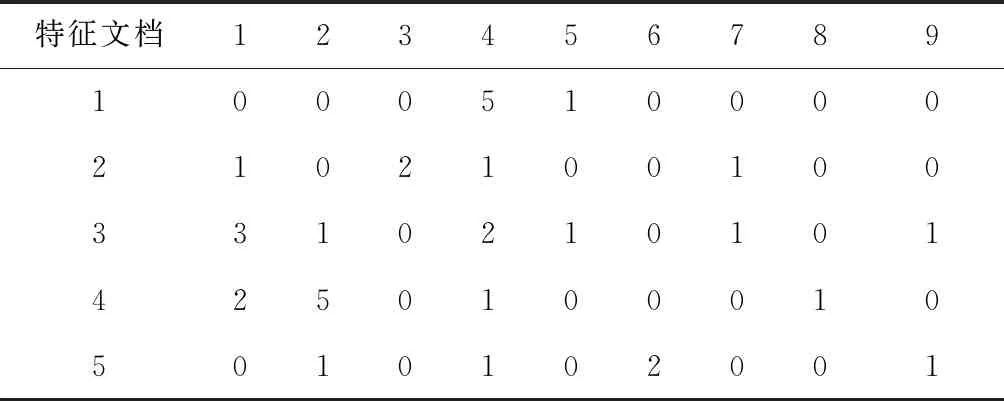
表4 新的有用特征子集
2.4 文本聚类
(1)文本聚类模型
文本聚类可定义为:给定文本文档集合D,D=(d1,d2,…,dj,…,dn),n为文档数量,d1标记文档序号1。聚类目标是将文本划分为若干子集,满足文档i与聚类质心j间的余弦相似度达到最大化,余弦相似度即为聚类的目标函数,是文本聚类中常用的评估标准,可以有效评估聚类方法的有效性。
(2)聚类质心计算
为将文本文档集合划分为聚类子集,每个聚类具有一个聚类质心,在每次迭代中通过式(11)更新。每个文档基于与聚类质心的相似性分配至相似的聚类中。令Ck为聚类k的质心,表示为矢量Ck=(ck1,ck2,…,ckj,…,ckt),ckj为聚类j的质心,t为聚类质心的长度。以下公式用于计算聚类质心
(11)
式中:di为属于聚类质心i中的文档i,akj为属于聚类j中的所有文本文档数量,ri为聚类i中文本文档的数量。
(3)相似性度量
余弦相似度是文本聚类中用于计算两个矢量(即文档与聚类质心)间的相似度的标准度量方式。若d1为文档1,d2为聚类质心,则余弦相似度计算为
(12)

(4)K均值聚类算法
K均值聚类算法可用于将文本文档集合D=(d1,d2,…,dn) 划分为K个聚类,通过式(12)分配每个文档至最为相似的聚类质心,即相似性最大的聚类中。算法利用X作为数据矩阵n×K,n为所有文档的数量,K为聚类数量。每个文本文档显示为权重矢量di=(wi1,wi2,…,wij,…,wit),t为文档D中所有文本特征的数量。算法过程如算法2所示。
算法2:K均值文本聚类
(1)Input:a set of text documentDandKis the number of all clusters//输入文本文档集合和聚类数量
(2)Output:allocateDtoK//将文本文档分配至聚类中
(3)termination criteria//算法迭代终止条件
(4)randomly choosingKdocuments as clusters centroidC=(c1,c2,…,cK)//随机选择K个文档作为初始聚类质心
(5)initialize matrixXas zeros//初始化分配矩阵
(6)for alldinDdo
(7)j=argmaxk∈{1 to K},based onCos(di,ck)//寻找余弦相似度最大的目标聚类质心
(8) assigndito the clusterj,A[i][j]=1//分配文档至聚类并更新分配矩阵元素
(9)end for
(10)update the clusters centroid using Eq.(11)//更新聚类质心
(11)end
3 性能评测
本节利用Matlab实现基于粒子群优化的文本特征选择算法,寻找拥有更多有用文本特征的新的最优子集,然后利用K均值算法对文本进行聚类,观察在给定测试文本数据集合中融入了粒子群优化机制的文本特征选择后聚类结果的性能变化。
3.1 测试文本数据集
表5给出了6种标准的文本数据集合,用于测试基于粒子群优化的特征选择算法的性能,该测试数据集是计算智能实验机制LABIC提供的文本聚类标准数据集,数据集包括文档数量、文档特征数量和聚类数量。对比算法选择基于遗传算法的特征选择机制下的文本聚类算法GAFSTC[10]和基于和声搜索算法的特征选择机制下的文本聚类算法HSFSTC[11],以及未使用任何特征选择机制的K均值文本聚类算法。
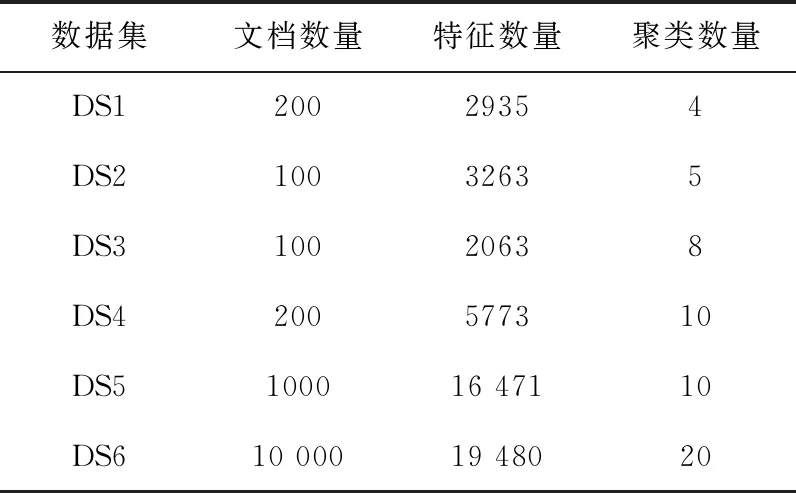
表5 测试文档数据集
3.2 评估标准
除相似性度量标准外,另外引入4种评估标准,包括:准确率Accuracy(Ac)、精确率Precision(P)、召回率Recall(R) 和F-measure(F),这些均是评估聚类准确度的标准评估方式。
F-measure可用于度量分类模型的优劣,表示的是聚类匹配百分比,取决于两个要素:精确率P和召回率R。两个要素的计算方法为
P(i,j)=ni,j/nj
(13)
R(i,j)=ni,j/ni
(14)
其中,ni,j为聚类j中分类i的成员数量,nj为聚类j的成员数量,ni为分类i的成员数量
(15)
式中:P(i,j) 为聚类j中分类i的成员精确率,R(i,j) 为聚类j中分类i的成员召回率。所有聚类的F-measure计算为
(16)
准确率AC是用于计算文档分配至聚类正确比例的常用度量指标,计算方法如下
(17)
式中:P(i,j) 为聚类j中分类i的精确率值,n为每个聚类中的文档数量,K为聚类数量。
3.3 结果对比
利用K均值算法检测特征选择对文本聚类的影响,特征选择可以通过生成的新的包括有用特征的子集改进文本聚类效果,并以此作为K均值算法的输入。表6是利用基于粒子群的特征选择机制后的K均值文本聚类结果。根据结果,本文算法在所有给定的数据集中均生成了有效的文本聚类结果(由评估指标决定)。在AC方面,本文算法在6个数据集中4个获得了最优的结果,即DS3-DS6。在PE方面,本文算法在所有6个数据集文档中均得到了最优的结果。在F-measure方面,该指标是最为常用的文本聚类领域中的重要指标,本文算法在所有6个数据集中均效果更佳。
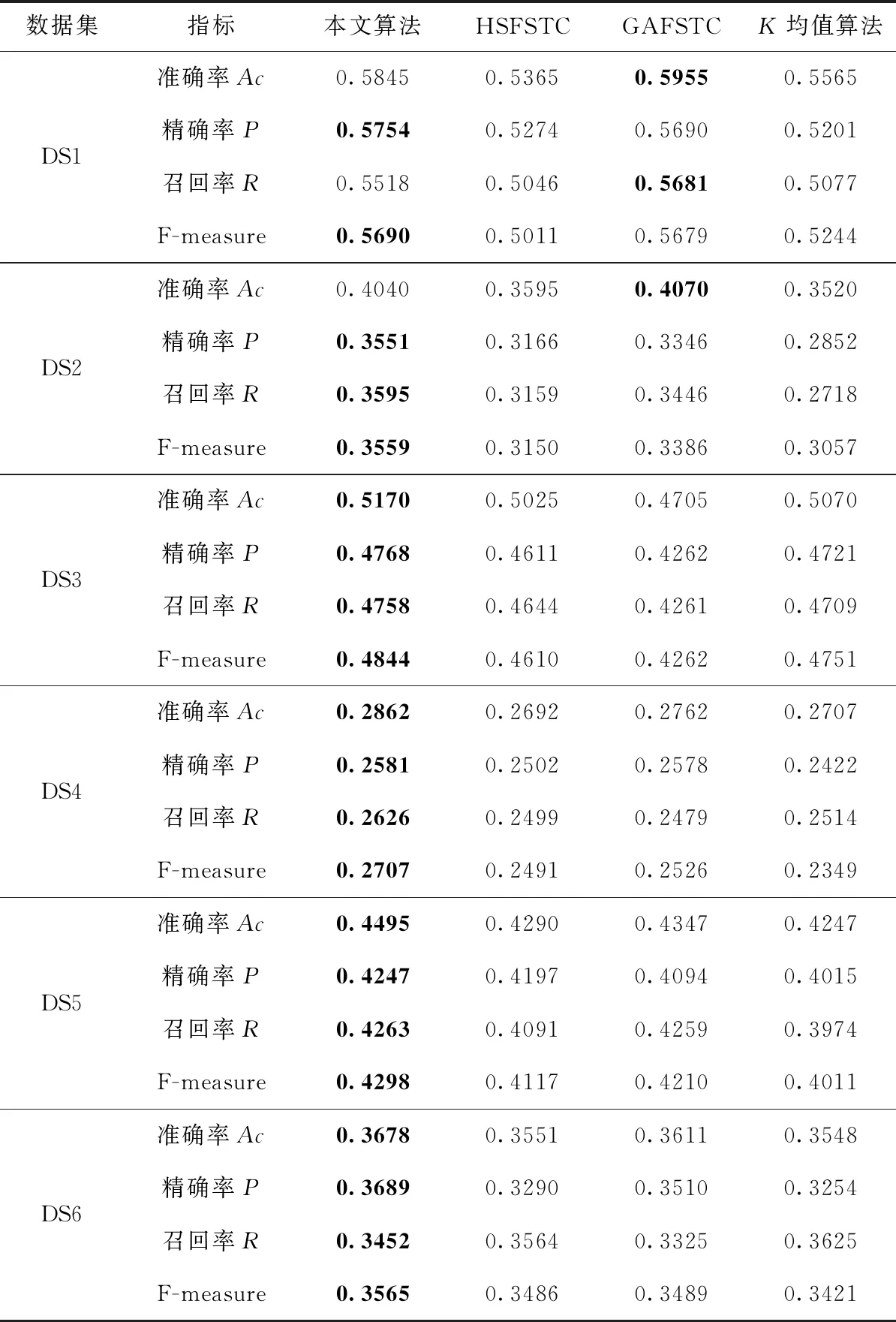
表6 各算法的性能指标情况
图4是不同特征选择机制下得到的特征下降率情况。综合不同类型的数据集文档看,本文算法基本可以实现最大的特征下降率,这表明算法在文本聚类前的特征选择上可以更大量地降低无用特征的出现比例,降低文本数据的维度空间,建立有用特征为新的子集,并以此为标准进行文本聚类,生成更好的聚类结果。
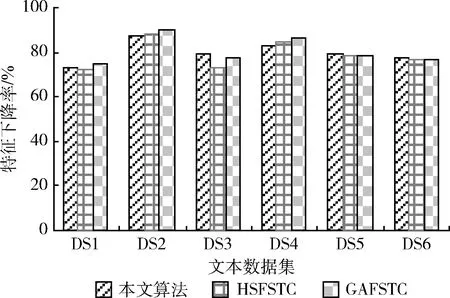
图4 特征下降率
图5通过计算在不同数据集文档中算法进行特征选择的适应度函数值评估算法的收敛性能。算法收敛值即为通过若干次迭代得到的最优适应度值。明显地,本文基于粒子群优化的特征选择机制具有最好的收敛性能,特征选择迭代完成后,其得到的特征选择结果也具有最高的适应度值,说明粒子群优化的特征选择结果是有效可行的。
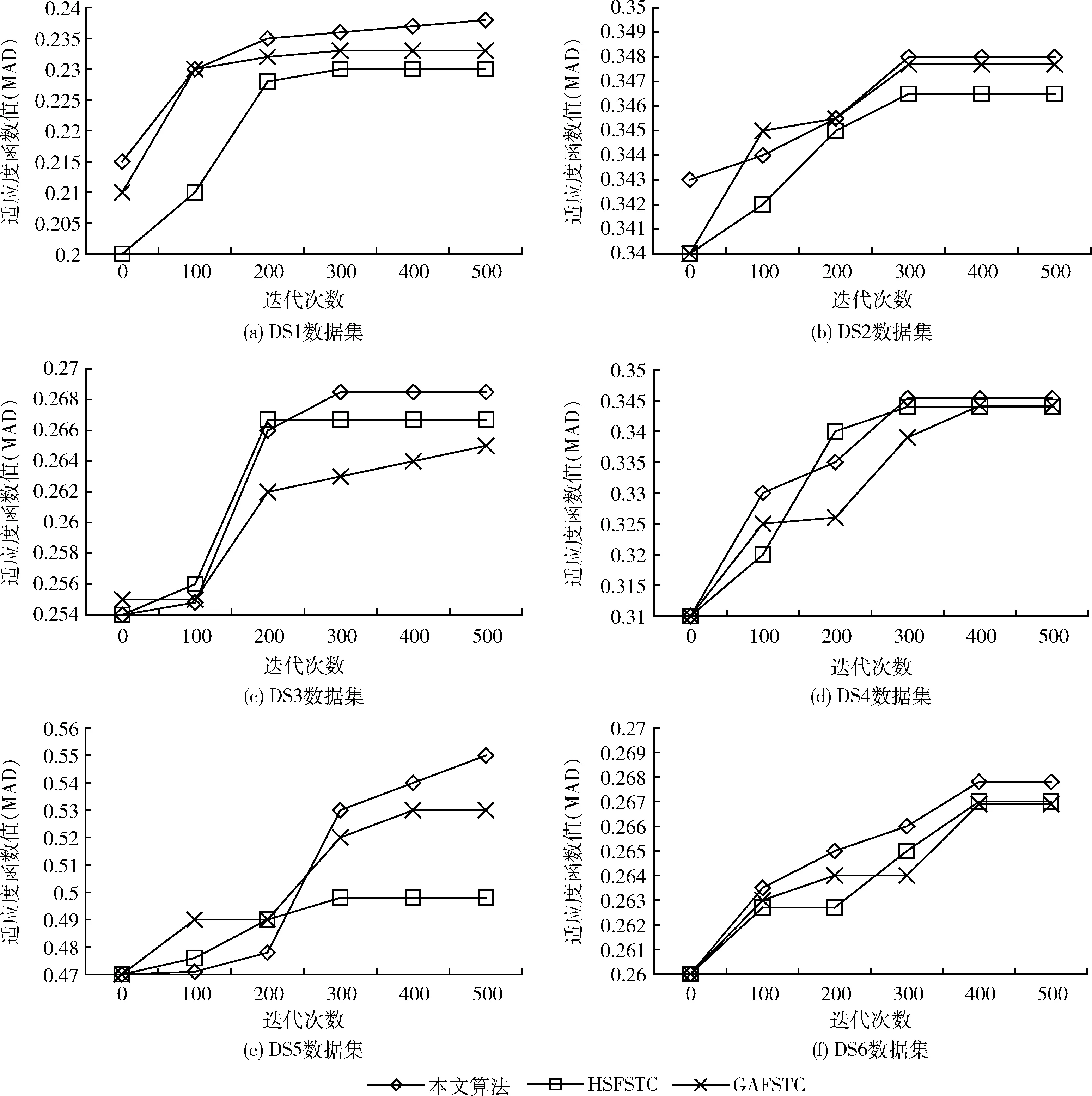
图5 6种测试文本数据集的特征选择收敛性
图6是不同算法进行特征选择的计算时间。计算时间越小,说明算法在得到最优特征子集的求解时间越少,也进一步表明算法的收敛速度越快。从结果可以看到,本文算法在大部分测试数据集文档中均得到了最小的计算时间,说明基于粒子群优化的特征选择机制比较基于遗传算法的特征选择和基于和声搜索算法的特征选择机制均是更好的。
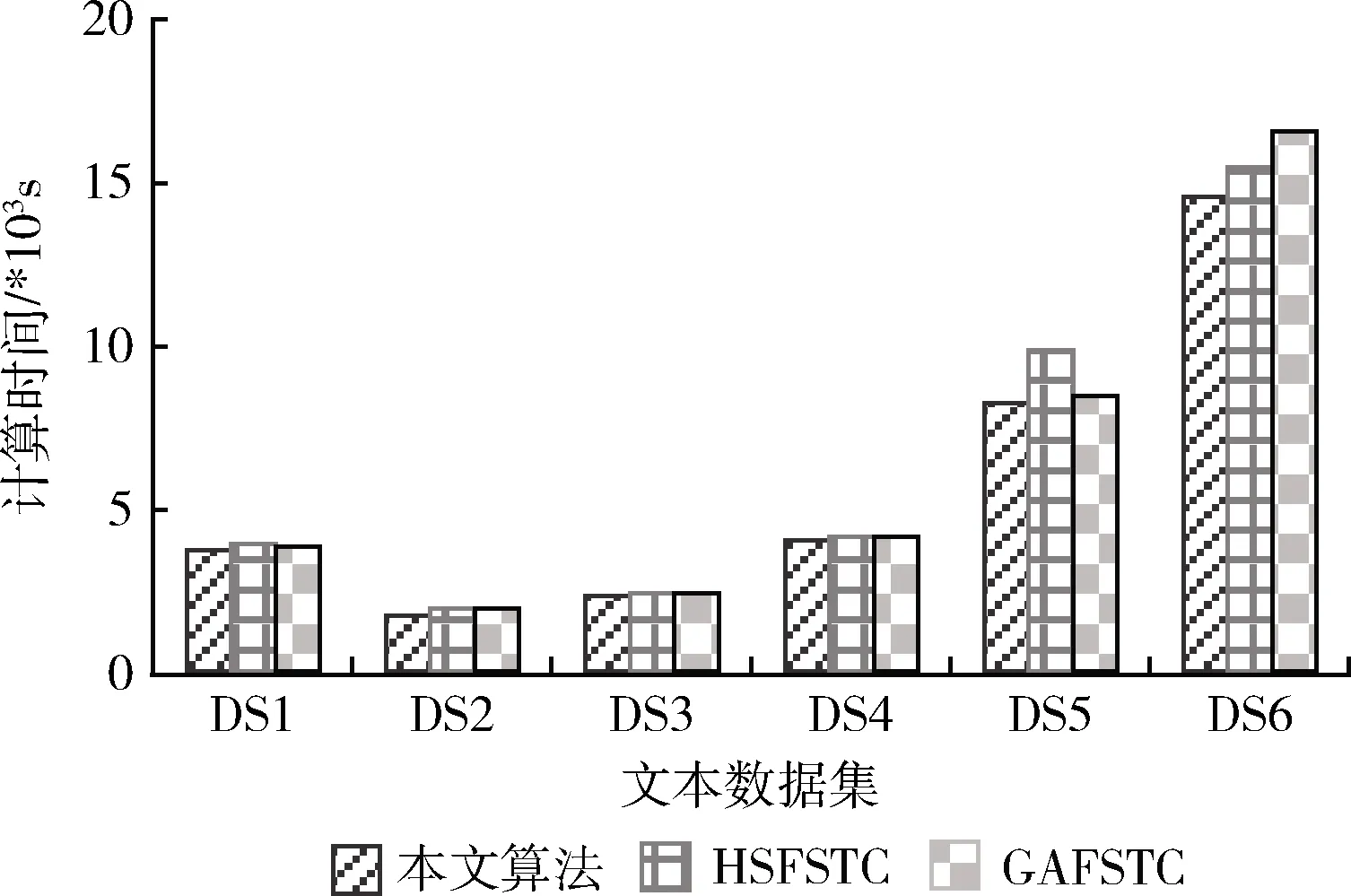
图6 特征选择计算时间
4 结束语
提出了一种基于粒子群优化的文本特征选择算法,算法利用词频逆文本频率指数为目标函数评估每个文档层次上的文本特征,并从初始的文档数据集中求解新的有用特征最优子集。然后以该最优有用特征子集作为K均值文本聚类算法的输入进行文本聚类,得到最优的文本聚类结果。结果表明,利用了基于粒子群优化的特征选择机制后的文本聚类算法,在多项评估指标上均比对比算法表现得更加优秀,可以更好地实现相似度更高的文本聚类,且在特征选择规模上也降低了初始文档特征规模。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
汽车实用技术(2022年14期)2022-07-30 06:24:26
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
北京航空航天大学学报(2021年4期)2021-11-24 01:13:12
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
都市丽人(2015年4期)2015-03-20 13:33:22
航天器工程(2014年5期)2014-03-11 16:35:53
振动工程学报(2014年4期)2014-03-01 01:15:41
