
基于自注意力与指针网络的自动摘要模型
2021-03-23 09:38姜志祥
计算机工程与设计 2021年3期
姜志祥,叶 青,傅 晗,张 帆
(中国航天科工集团第二研究院 七〇六所,北京 100854)
0 引 言
文本自动摘要方法通常可分为抽取式摘要和生成式摘要两种。抽取式方法在理解源文本语义的基础上,利用词库中的单词,将源文本中重要的句子和段落组合成较短的文本,生成摘要。由于抽取式摘要主要考虑单词的词频等特性,并不包含语义信息,所以无法完整表达文本的语义信息。生成式摘要方法利用自然语言处理算法进行转述、同义替换、句子缩写等操作来获得文档的摘要。生成式摘要的质量更高,但难度较大、复杂性较高。
本文针对生成式摘要方法中基于序列到序列(sequence-to-sequence,seq2seq)模型存在准确率不高、词语重复、训练时间长等问题,提出了一个改进的模型。在原序列到序列结构的基础上加入指针生成网络以及自注意力机制,提升了模型摘要准确率,同时引入复制机制,以解决未登录词(out of vocabulary,OOV)问题,利用输入供给(input-feeding)方法来避免摘要中出现重复短语问题,使用自注意力(self-attention)来代替传统的循环神经网络(RNN),提升了模型训练的并行性,消除了卷积计算,减少了训练时间。
1 相关工作
抽取式摘要方法分为无监督抽取式方法和有监督抽取式方法。
抽取式摘要源于词频-逆文档词频(TF-IDF)算法,它根据文章中的词语的权重来获得摘要。Google的Mihalcea等在网页排序算法的基础上提出了基于图的TextRank算法,该算法通过构建节点连接图,将句子的相似度作为图中边的权重值,计算得到排名高的句子组成摘要,提升了抽取式方法的准确率。
随着机器学习技术的发展,抽取式摘要的研究逐渐从无监督方法向有监督方法发展。Cheng J等[1]利用卷积神经网络(CNN)与循环神经网络(RNN)来提取句子特征,改善了人工提取特征不稳定的缺陷。Nallapati等[2]使用分层神经网络提取句子的特征,获取单词以及句子和文档之间的分层关系,同时还加入了位置信息变量。
随着近几年深度神经网络的发展,不少生成式摘要模型的在测试集上的性能已经超越了最好的抽取式模型。由于生成式摘要具有更好的表征和生成文本能力,已经称为主流的自动摘要方法。
生成式模型的基本结构是由编码器和解码器组成的序列到序列模型。Nallapati等[3]将注意力机制与基于RNN的序列到序列模型相结合,其中注意力机制使得每个时刻的输出向量都有不同的权重值。Hu等[4]利用微博数据,得到大规模中文短文本摘要(large scale Chinese short text summarization,LCSTS)数据集,并提出了以RNN为基础的自动摘要系统。Chopra等[5]将卷积神经网络作为编码器,将长短期记忆神经网络作为解码器。吴仁守等[6]通过对文档进行字、句和全文档等多层次编码。
Vinyals等[7]提出了指针网络,指针网络是seq2seq模型的一种变体。该网络不执行序列转换,而是生成一系列指向输入序列元素的指针。指针网络用于文本摘要,主要解决单词稀疏和词汇不足的问题。Gu等[8]提出了复制机制,即当包含指针网络的模型生成摘要时,通常会生成两个概率,即现有词汇中的生成概率和在指针处复制的概率。必要时模型会直接在原文中复制单词作为摘要输出,此方法的提出能够缓解未登录词问题。Li等[9]提出了配备深度递归生成解码器的摘要框架,基于递归潜在随机模型学习目标摘要中隐含的潜在结构信息,根据生成的潜在变量和判别式确定性状态生成高质量摘要。
Abigail等[10]利用词频等特征,复制原文本的词来处理低频词,解决了未登录词问题。并加以改进,融合注意力机制形成混合式指针生成网络,缓解了细节偏差和低频词问题。谷歌的Ashis等提出了变换器(transformer)模型[11],利用自注意力机制实现快速并行,并且可以增加深度,提升了训练速度和准确度,在多项自然语言处理任务中表现良好。Zhang等[12]将根据自注意力机制训练的预训练模型转换器的双向编码表示(bidirectional encoder representation from transformers,BERT)应用到自动摘要任务中。
李晨斌等[13]提出了基于改进编码器-解码器(encoder-decoder)模型的方法,提升了摘要的连贯性与准确性。Guo等[14]提出将多头注意力Multi-Head与指针网络结合,抽象化了摘要文本的结构,增强了文本的语义表示。Wang等[15]提出概念指针网络,利用基于知识的上下文感知概念来扩展候选概念集,能够生成具有更高层次语义概念的摘要。Li等[16]提出双注意指针网络,自注意力机制从编码器收集关键信息,软注意力和指针网络生成更一致的核心内容,两者的组合会生成准确且一致的摘要。
由于RNN、LSTM和CNN等网络模型在序列到序列模型中取得了较好的效果,循环结构的模型和编码器-解码器结构得到了很好的发展。但是循环神经网络固有的顺序属性制约了训练的并行化,增加了训练时间;CNN网络在计算两个位置之间的关系时,训练次数会随着距离的增加而增加,不利于模型的训练。
本文提出了一个基于组合指针式网络和自注意力机制的模型,但由于自注意力机制对句子整体进行处理,并不包含序列的位置信息,因此在嵌入层引入了位置嵌入编码来表示序列中元素的相对关系,保证模型按照正确的序列顺序来进行处理。模型完全消除了重复和卷积,避免了递归,具有更高的并行性,提升了训练速度,降低了长时间训练导致的性能下降。与原来的混合指针式网络相比,提出的模型能够快速降低损失函数值,减少训练时间,并提升摘要的准确度。
2 序列到序列模型改进
2.1 模型框架
自注意力机制的基础是序列到序列模型,它属于编码器-解码器结构,本文使用的原始指针网络模型如图1所示。
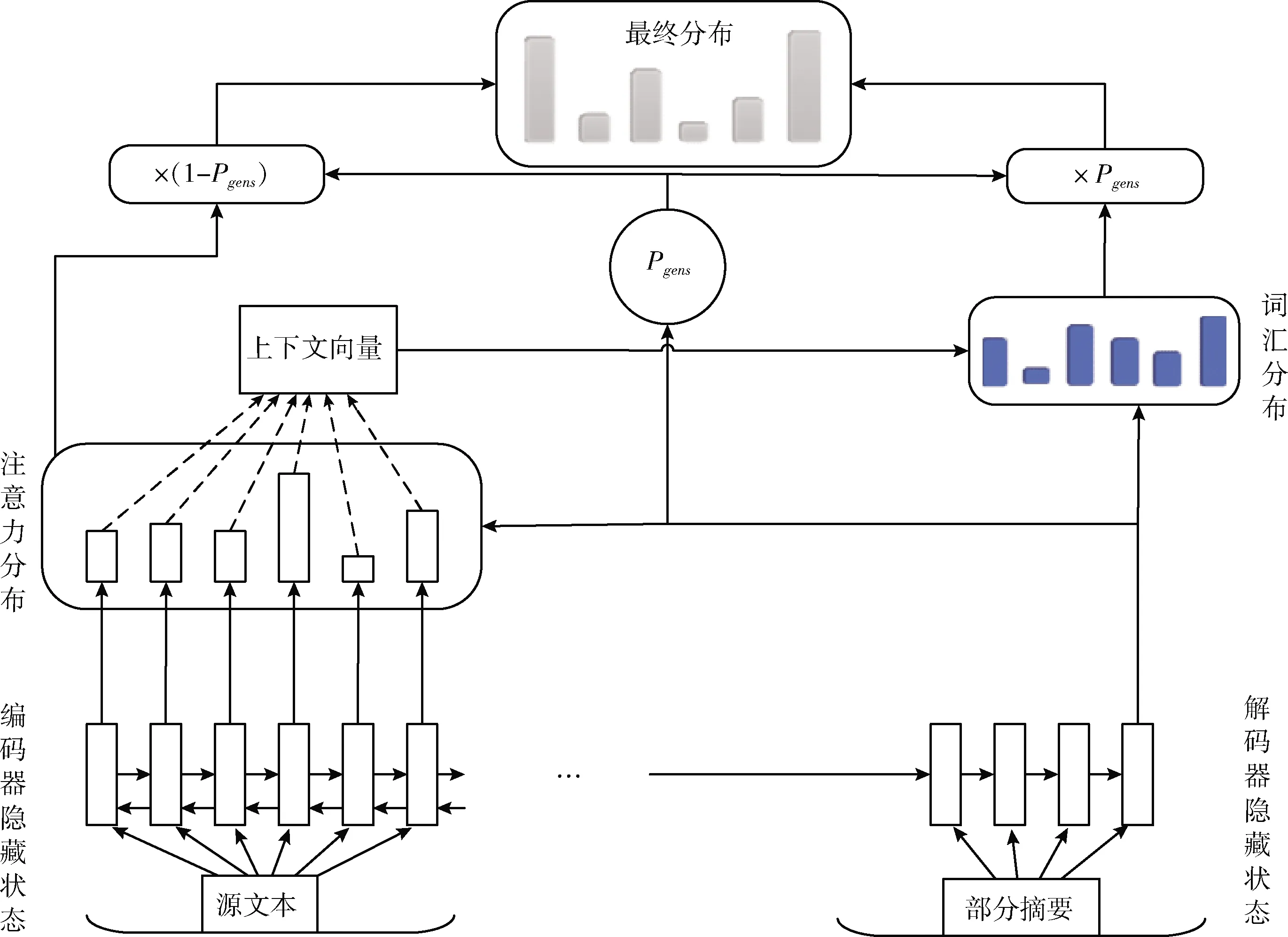
图1 指针网络模型
在原始指针网络模型中,源文本中的信息被输出到由单层双向长短时记忆网络(LSTM)组成的编码器中,从而产生一系列隐藏状态,通过隐藏状态计算得到文本的注意力分布,然后注意力分布用于生成编码器隐藏状态的加权总和上下文向量,上下文向量通过与两个线性变化层的解码器状态拼接在一起组成词汇分布,从上下文向量以及解码器状态计算得到生成概率Pgens,根据生成概率选择是从原文复制还是在词汇分布中生成得到最终分布。
原始的指针生成网络模型虽然取得了一定的成果,但是仍存在一些问题。首先是无法聚焦核心内容,无法概括重要内容;其次是可能错误组合原文片段,导致出现错误结果;最后存在语句不够通顺和连贯的问题,降低了摘要效果[7]。
本文提出的改进模型结构如图2所示。编码器部分由6层编码器叠加在一起构成,解码器部分也是6层解码器叠加在一起。每个编码器在结构上是相同的,但不会共享它们之间的参数,每个编码器可以分解为自注意力层和前馈神经网络层。解码器中结构类似,但在中间加了一个编码-解码注意力层(多头自注意力层),用来关注输入句子的相关部分。模型最后利用解码器向量输出与注意力分布来计算概率分布Pgens,结合指针生成网络对词汇分布以及注意力分布进行加权计算,以确定是最终通过固定词汇表生成词还是通过指针复制单词。

图2 本文提出模型
本文提出的改进模型基于序列到序列模型,组合指针生成式网络模型和自注意力模型,增加了处理OOV单词的能力和准确性。模型保留了生成新单词的能力,运用自注意力模型加快了训练速度,能够快速并行计算,增加深度,较快降低损失函数值。
编码组件由6层编码器组成,编码器由自注意力层和全连接前馈神经网络层两个子层构成,子层之间的连接采用残差连接(residual connection)[18],然后进行层归一化(layer normalization)[19]。每个子层的输出都为LayerNorm(x+Sublayer(x)),其中Sublayer(x)是由子层本身实现的功能,为了使残差连接更加方便计算,所有子层以及嵌入层输出的维度大小dmodel都为512。
解码组件由6层相同的解码器组成,子层之间也是采用残差连接并进行归一化,与编码器不同的是,解码器加入第3个子层,该层用来对编码器输出结果进行多头注意力关注,同时自我注意力层,加入掩码(mask)机制[11],用来关注输入队列,确保对位置i的预测只能依赖i之前的已知输出。
输入句子通过词嵌入转为向量矩阵,进入编码器后经过自注意力层,计算得到自注意力向量,输出会传递到前馈神经网络中,每个位置对应的前馈神经网络都是一致的,然后经过多头注意力层向量拼接后,得到多头部注意力Z,编码器输出中包含有键向量和值向量的注意力向量集,这些向量会传输到解码器中编码器-解码器注意力层。编码阶段结束后进入解码阶段,每个解码的步骤都会输出一个输出序列的元素,直到出现终止符号。解码器最后会输出一个向量,经过线性变化层把向量投射到一个对数几率(logits)的向量中,向量中的每个单元格都会产生一个分数,经过softmax后会将这些变为一个概率,其中概率最高的单元格会被选中,然后对应单词会作为这一时刻的输出。利用解码器当前时刻以及前一时刻的输出以及注意力分布拼接得到指针生成网络的生成概率Pgens,该概率控制是复制源文本中内容生成摘要还是根据注意力生成摘要,若词汇表分布中不存在解码的词,则直接利用多头部注意力分布复制得到,若词汇表分布中存在分布,则使用词汇表分布。
2.2 模型原理
在改进的模型中,输入信息通过嵌入层转化为嵌入向量。因为模型是对句子中所有词同时处理的,不包含递归和卷积,所以在嵌入层并不包含句子中相对位置信息,必须加入有关序列的位置信息,因此我们在编码器和解码器的底部输入嵌入中为其加入位置编码。在这里选择使用不同频率的正弦和余弦函数
PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)
式中:pos表示在句子中的位置,i是维度,dmodel为512。
注意力计算方式如图3所示,首先根据嵌入向量和加权矩阵计算得到3个向量,分别是查询向量Q、键向量K和值向量V。这3个向量的生成方式是词嵌入与3个权重矩阵 (WQ,WK,WV) 相乘

图3 两种注意力计算
接下来计算缩放点积注意力[11],计算公式如下所示,计算完成后,通过softmax传递结果,得到注意力向量就可以传递给前馈神经网络。除以dk是为了防止经过softmax后的结果变得更加集中,使得梯度更稳定
计算出自注意力头部矩阵后,需要将8个矩阵拼接起来,然后与矩阵WO相乘,得到多头部自注意力向量,WO是经过联合训练的矩阵

多注意力网络相当于多个不同自注意力的集成,将数据X分为8个头,分别输入到8个自注意力层中,乘以各个加权矩阵,得到8个加权后的特征矩阵Z,将8个矩阵Z按列拼成一个大的特征矩阵,乘以权重矩阵WO得到输出Z。
编码器和解码器每一层还包括一个全连接的前馈神经网络,由两个线性变化组成,在它们中间包含一个ReLu激活函数,使用Relu函数能提升计算速度以及收敛速度。内层维度为dff=2048,输入输出维度dmodel为512
FFN(x)=max(0,xW1+b1)W2+b2
在解码器中,注意力模块(transformer block)比编码器中多了个编码器-解码器注意力(encoder-decoder attention)。在编码器-解码器注意力中,Q来自于解码器的上一个输出,K和V则来自于与编码器的输出。掩码自注意力(mask-self-attention)是计算当前摘要的内容和摘要的前文之间的关系,而编码器-解码器注意力是计算当前摘要内容和编码的特征向量之间的关系。最后再经过一个全连接层,输出解码器的结果。加入掩码机制原因是,因为在预测摘要内容时,为防止信息泄露,当前时刻应该无法获取到未来时刻的信息。输入供给(input-feeding)[10]方法通过对上一时刻的注意力进行跟踪,将此时刻词嵌入向量与将前一时刻的注意力向量进行拼接,得到新的注意力向量,作为输入到解码器中。该方法能够考虑前一时刻的注意力信息,从而帮助模型注意力更准确地决策,提高了摘要准确率。
设解码器输出为di,注意力分布为ai,t-1时刻的注意力向量为ai-1,词嵌入向量为embXi,l2为输出端最大长度,词汇注意力分布为Pv ocab。 将t-1时刻注意力与t时刻嵌入向量进行拼接得到新向量embYi
embYi=concat[embXi,ai-1]
那么在t时刻解码器的输出即为
Si为解码器输出经过全连接层后的输出
Si=FFN(di)
根据t时刻和t-1时刻解码器已经得到的摘要字符的向量,以及最新的注意力分布,利用输入供给可以计算出生成概率Pgens
Pgens=sigmod[Si-1,Si,ai]Pv ocab=softmax([Si,ai])
最终单词的概率分布为
Pgens可以看作是一个开关,控制是从输入队列复制词还是生成新词,如果是OOV单词,Pv ocab=0,只能通过复制得到,并保留右侧部分;如果没有出现在输入文本中时,单词只能通过模型生成,并保留左侧部分。复制网络的引用能够在很大程度上减轻OOV问题[8],防止摘要对原文的描述出现细节偏差问题。
在时刻t,目标单词在此时刻被解码,那t时刻的损失函数就是该单词对应的概率分布的对数值的负数,在损失函数前面添加一个以e为底的对数
在训练过程中对语料进行自动摘要训练时,并不是只需要对每一时刻计算损失函数值,还需要计算整体损失函数值的反向传播,以更新模型。设当前解码总时长为T,则对应输入序列的总体损失函数值为
3 实验结果与分析
3.1 实验结果
实验使用的训练数据集为LCSTS,其特性见表1。LCSTS分为训练集、测试集、验证集3部分,训练集包含2 400 591组数据(包含短文本和摘要),验证集10 666组数据,是人为标记的,包含有不同的分数,从1到5。得分越高表示摘要与原文越相关,摘要更简洁,包含信息较多;得分较低的摘要中,许多单词比较抽象,有的单词没有在原文中出现。测试集包含1106组数据,不具有很高的抽象性,比较适合作为生成任务的测试集。不同的分数代表任务的困难程度。
图4是从测试集中随机选取的不同分数测试用例,用来观测模型在不同困难程度的摘要效果。
实验时,设置字典大小为10 396,通过预处理将每篇正文和原摘要放在同一行中,利用jieba对数据集进行分词处理,对照词典,生成句子的有向无环图(DAG),找到最短路径后,直接对原句进行截取,如果某个字在字典中出现的概率为零,则使用UNK标记代替。对OOV词,使用隐马尔可夫模型进行新词发现,得到分词后,再使用gensim进行字向量训练,训练得到的结果再作为编码器端的输入。

表1 LCSTS数据集数据统计

图4 不同分数的测试案例
模型的训练环境Tensorflow,使用基于RTX 2080s的机器进行训练测试。
训练参数设置如下:编码器和解码器部分由6层相同的编码器组成,它们之间并不共享参数,编码器解码器的内部隐藏层都包括512个节点单元,前馈神经网络层节点单元数量是2048。一次训练所使用的样本数batch_size=32。学习率(learning rate)初始设置为0.0005,利用学习率动态衰减公式,初期学习率增加,步长较长,梯度下降较快;训练预热步数到达设定值后,逐步减小学习率,有利于快速收敛,容易得到接近最优的解,Warmup_steps为4000。学习率的变化为

最大输入长度为150,超过后进行截断,输出序列最大长度为25。训练轮数为32。搜索解码时采用集束搜索,按顺序生成摘要内容,每生成一个词汇时,需要对结果进行排序,保留与集束宽度相同数量的词汇,通过剪枝操作来提升解码速度。解码时设置宽度为beam_size=4。
3.2 实验结果分析
由Lin等提出的Rouge(recall-oriented understudy for gisting evaluation)标准被广泛应用于文本自动摘要的评价中。Rouge的基本思想为将系统生成的自动摘要与人工生成的摘要对比,通过统计两者之间重叠的n元词的数目,来评价生成摘要质量。评价时,一般采用Rouge-1、Rouge-2和Rouge-L作为标准,即计算一元词和两元词以及最长公共子序列的重叠程度。
本文提出的模型在训练集上得到Rouge评价结果见表2,表2还给出了其它模型的Rouge结果。

表2 模型Rouge结果
第1个模型是传统的序列到序列模型,由Hu等[4]在LCSTS的基础上提出,没有引入注意力机制,编码器使用循环神经网络对文本进行建模,可以得知最后一个词的状态包含句子所有信息,将此状态传递到解码器中。
第2个模型在第一个模型的基础上引入了上下文,将RNN编码器的内部隐藏状态组合起来以概括地表示单词的上下文[4],其余同第一个模型。
第3个模型结构将复制机制[8]与序列到序列模型结合,复制机制可以很好地将解码器中常规的单词生成方式与新的复制机制集成在一起,该机制可以选择输入序列中的子序列,并将它们放置在输出序列中的适当位置。
第4个模型将提出了一种新的摘要框架,该模型是配备深度递归生成解码器的序列到序列模型[9],基于递归学习目标摘要中隐含的结构信息以提高摘要质量。
第5个模型为指针生成式网络[10],采用了基于注意力机制的序列到序列模型[8],引入了指针网络的复制机制指导生成过程,同时引入覆盖率向量。
第6个模型提出了一种基于双注意指针网络(DAPT)的编解码器模型[16],自注意力机制从编码器收集关键信息,软注意力和指针网络生成更一致的核心内容。
第7个模型是本文提出的模型,采用基于自注意力的transformer机制,组合了指针生成网络,引入了复制机制和输入供给(input-feeding)方法。
从表2可以看出,本文提出的模型Rouge评价结果,相比其它模型有较大的提升,Rouge-1、Rouge-2、Rouge-L均高于其它模型。
本文提出的模型没有采用传统的循环神经网络和生成式对抗网络,而是使用了自注意力机制,可以并行训练;经过较少步骤后,损失函数值能够达到稳定状态,减少了训练所需时间,同时也提升了摘要的准确性。图5为指针式生成网络[10]的损失函数值变化曲线,可以看到,经过较多训练步骤后,损失函数值才下降到较低的范围,所需训练时间较长。图6本文提出模型的损失函数值曲线,可见其下降速度很快,到达稳定值后曲线十分平稳。

图5 指针式生成网络损失值变化曲线
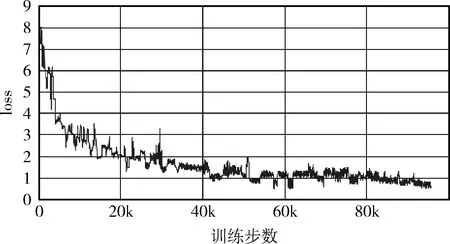
图6 本文模型的损失值变化曲线
4 结束语
本文在序列到序列模型的框架下,提出了一种将指针生成式网络与自注意力机制相结合的模型,通过复制机制防止了UNK标记的出现,解决了OOV问题。与循环神经网络或生成式对抗网络相比,自注意力模型能够并行训练,消除了卷积,加速了训练过程,损失函数值能够较快下降并达到稳定。同时,采用输入供给方法也能追踪过去时刻的注意力信息,提升注意力机制作出决定的准确率。所提出的模型的Rouge评分相对原模型有一定的提升。但有时会概括一些不太重要的信息,并且没有使用覆盖率机制,摘要会出现重复词语,下一步研究工作将考虑添加覆盖率机制来提升在长文本摘要上的性能,减少重复短语的出现,以及将模型部署到实际应用中,实现从理论到实际应用的转变。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
成都信息工程大学学报(2018年3期)2018-08-29
制造技术与机床(2017年7期)2018-01-19
广东第二课堂·小学(2017年9期)2017-09-28
电子器件(2015年5期)2015-12-29
电测与仪表(2015年5期)2015-04-09
电测与仪表(2014年13期)2014-04-04
