
基于编解码器结构的中文文本摘要
2021-03-23 09:38李大舟
计算机工程与设计 2021年3期
李大舟,于 沛,高 巍,马 辉
(沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142)
0 引 言
自动文本摘要[1]按照摘要形式分为抽取式和生成式。其中生成式自动文本摘要方法更加贴近人类思维,更能准确反映文本意境,但同时算法的设计与实现更加困难。近年来,深度学习技术在自然语言处理领域得到广泛应用[2-4]。其中,基于编解码器结构的自动文本摘要生成方法灵感来源于机器翻译的神经网络模型[2]。来自Facebook的Rush等[5]提出了一种编解码器框架下的句子摘要模型,使用了一种基于局部注意力模型,在给定输入句子的情况下,生成摘要的每个词。Huang等[6]提出了一种结合注意力机制的长短时记忆(long short term memories,LSTM),对特定目标进行向量化处理,并结合注意力机制作为LSTM网络的输入,提升了模型的准确度。Rush等[7]在编码器上使用卷积神经网络,在解码器上使用了循环神经网络(recurrent neural network,RNN)。来自IBM的Nallaoati等[8]使用双向GRU作为编码器编码原文,解码器使用门控循环单元(gated recurrent unit,GRU),再结合注意力机制,并根据自动文本摘要任务的特点提出了模型上的改进。See等[9]构建了一个包含指针生成器网络,同时结合Cove-rage mechanism模型,改善了在生成式文本摘要中存在的信息生成不准确、对未登录词问题缺乏处理能力以及摘要重复率高等问题。Paulus等[10]利用自注意力机制解决了生成短语重复的问题,并结合强化学习进行训练,解决了曝光偏差的问题。基于以上针对NLP任务所取得的成果,本文提出了一种BiGRUAtten-LSTM网络模型来解决文本自动摘要生成问题。该模型主要包括:①构建基于双向门控循环单元的编码器。②引入注意力机制,使模型能够高度关注文本中的重要信息。③使用长短时记忆网络并结合先验知识和集束搜索完成解码器功能。实验结果表明,本文模型所生成的摘要在ROUGE[11](recall-oriented understudy for gisting evaluation)评价体系中取得了较好的效果。
1 构建基于编解码器结构的生成式摘要模型
本文提出了一种基于编解码器框架的自动文本摘要算法,用于新闻摘要的生成。编码模块和解码模块使用不同的神经网络模型。编码器使用双向GRU网络对整个输入序列进行编码;编码结果结合注意力机制获得上下文语义向量;解码器使用LSTM并结合先验知识和集束搜索完成摘要生成任务。总体框架如图1所示。详细内容在1.1节~1.3节。
1.1 双向GRU编码器
编码器根据输入序列读取每个输入元素,现有算法通常采用RNN对序列进行编码。但在编码过程中,使用tanh函数作为激活函数,迭代逐渐收敛,存在梯度爆炸和梯度消失等问题。因此,使用RNN模型进行长序列处理的效果不佳,导致在编码的最后阶段丢失大量的有效信息,难以将长序列记忆成为一个固定长度的向量。

图1 BiGRUAtten-LSTM总体框架
当前的传统方法是使用GRU模型或者LSTM模型来解决长期依赖关系。这两种模型的显著共同点是:它们都包含了t时刻到t+1时刻的加法分量,并且GRU模型和LSTM模型都可以通过“门”结构保留许多特性。经过实验比较,GRU模型和LSTM模型的性能无明显差别。但在使用相同大小的数据集时,GRU模型比LSTM模型具有更好的收敛时间和迭代效率。
在自动文本摘要任务中,词汇(特指在文章分词后的一个词语,后文统称为词汇)的语义很可能与这个词的后文信息有很大的关联。在这种情况下,单向神经网络模型会忽略后文的信息,不能够更好地获取文本整体语义特征。针对这一情况,本文采用双向GRU模型来构建编码器,其结构如图2所示。
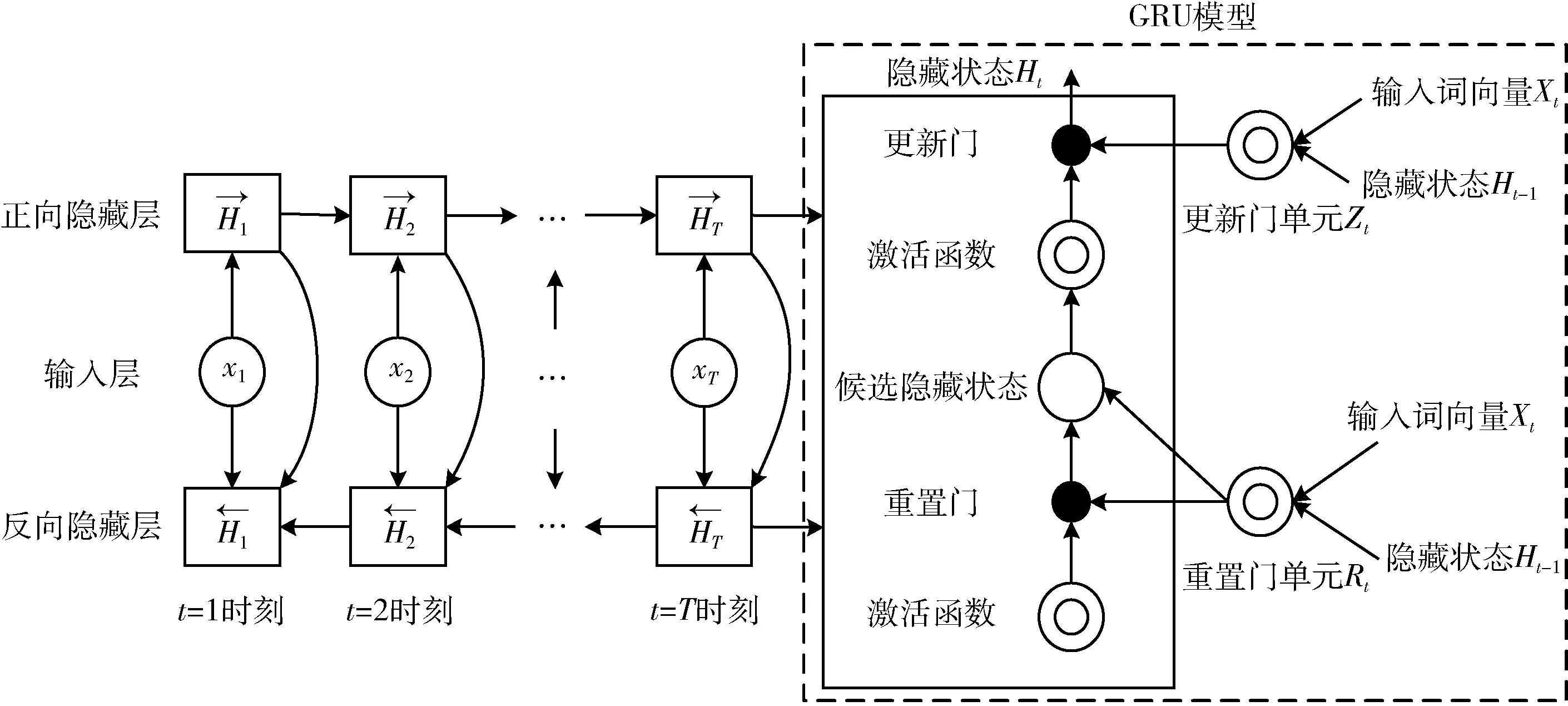
图2 双向GRU编码器
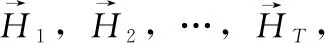
在门控循环单元中,重置门和更新门的输入均为t时刻的输入词向量xt与t-1时刻的隐藏状态Ht-1,并使用sigmoid函数将其激活值控制在区间[0,1]。设h为隐藏单元个数,给定时间t的小批量输入xt和上一时刻的隐藏状态Ht-1。 重置门Rt和更新门Zt的计算如式(1)、式(2)所示
Rt=σ(xtWx r+Ht-1Whr+br)
(1)
Zt=σ(xtWx z+Ht-1Whz+bz)
(2)
其中,σ为sigmoid激活函数,Wx r,Wx z和Whr,Whz是权重参数,br,bz是偏差参数。

(3)
式中:⊗是向量之间元素相乘,Wxh和Whh是权重参数,bh是偏差参数。如果重置门控值为0,则会丢弃过去的隐藏状态信息,表示当前内存内容只有新的输入单词;如果重置门控值为1,则保留过去的隐藏状态。将按元素乘法的结果与当前时间步的输入连结,再通过tanh函数计算出候选隐藏状态,其所有元素的值域均为[-1,1]。
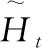
(4)
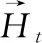
(5)
1.2 注意力机制
由于在编码过程中会丢失许多输入序列中的信息以及存在着难以对齐的问题,故本文引入注意力机制。注意力机制定义请参见文献[12]。在文本摘要任务中引入注意力机制,通过仅查看输入序列的一些特定部分而不是整个序列来预测摘要,能够有效地克服神经网络难以处理长序列的问题。
在文本摘要生成任务中注意力机制是在编码器和解码器之间增加的连接架构。注意力机制对从编码器中获得的语义向量C进行加权处理,以解决模型的文本语义理解不充分问题。引入注意力机制后,在生成输出序列时会得到对应时刻全文的注意力分布,根据生成词汇的不断变化将固定维数的语义向量C替换成语义向量Ct′。
本文将编码器的隐藏状态Ht和上一时刻解码器的隐藏状态St′-1通过加权求和融合成高维语义向量Ct′,详细计算过程如下
(6)
(7)
(8)

1.3 解码器

St′=LSTM(yt′-1,Ct′-1,St′-1)
(9)
(10)
其中,Wd是权重矩阵,bd是偏置向量。

图3 LSTM解码器
此外,本文为提高摘要准确性,引入了先验知识及集束搜索[13]方法。因为摘要中的大部分字词都在文章中出现过,对此,本文使用文章中的词集作为一个先验分布,加到解码过程的模型中,使得解码端摘要生成序列时更倾向选用文章中已有的字词。对于每篇文章,得到一个大小为T的0/1向量χ=(χ1,χ2,…χT),其中χi=1意味着该词在文章中出现过,否则χi=0,将该向量经过一个缩放平移层得到
(11)
式中:g,q为训练参数,然后将该向量与解码器得到的输出y取平均得到新的输出
(12)
集束搜索从左到右生成摘要词汇。每次生成一个词汇时,均对结果进行排序,并保留固定数量的候选。固定的数量被称为集束宽度。集束搜索通过这种剪枝操作,一定程度上降低了计算复杂度,提高了解码速度。本文模型设置集束宽度为3。
获得解码器的隐藏状态及新的输出后,通过自定义的输出层和softmax层来计算当前时间步输出yt′的概率分布,得到下一个词汇的词典位置,如式(13)所示
P(yt′|y1,y2,…,yt′-1,Ct′)=softmax(yt′-1,Ct′,St′)
(13)
2 实验与分析
2.1 数据集
本文采用自行设计的主题爬虫技术真实采集的中文数据集作为实验数据集,该数据全部为工业新闻的数据,主要包括贤集网(https://www.xianjichina.com)2016年-2019年的化学化工、机械工业、电子信息、生物食品、材料技术、医药医疗等板块新闻,共53 874条新闻-摘要对。
爬取的源数据需执行数据完整性检查、标签替换和数据对齐等处理。其中,结构化不完整的数据和新闻篇幅过长 (L文>1500) 或者篇幅过短 (L文<50) 的数据均视为无效数据。对于文本中可能出现的日期,如时间、日期、年、月、日等,本文使用标签替换。最终筛选后,有效数据为50 000条新闻-摘要对。摘要和新闻正文分别导入到同一个CSV文件中的两列,标题和文本内容应每行对应。
实验参照LCSTS数据集[14]的方法,将处理后的数据按照98%和2%的比例分为两部分,分别为训练集和测试集。测试集有1000条数据,用于评测摘要的效果。数据集文本的平均长度见表1。

表1 数据集平均长度统计
2.2 分词工具
本文分别使用jieba的精确模式、THULAC的不标注词性模式和pkuseg[15]的医药领域模型对上述数据集进行分词处理,分词样例见表2。表2为测试中文分词样例,包括原始短文本和各分词工具的分词结果。

表2 中文分词样例
从表2中可以看出:例1的pkuseg的分词精度更高,明确地将‘溶于’,‘脂肪烃’等词提取出来。例2的‘脂肪酸皂类’,‘有机锡化合物’等词提取精准,结果对比表明了在工业新闻领域数据集上pkuseg的分词效果更好、准确度更高
(14)
(15)
(16)
本文对3种分词工具进行了精度(precision)、召回率(recall)、F值(F-score)评价指标的对比实验,分词工具的评价指标计算公式如式(14)~式(16)所示。结果表明pkuseg更适合用于实验数据集的分词工作。不同分词工具之间的评价指标对比见表3。
实验选用pkuseg作为本文数据集的分词工具。此外,根据工业新闻的历史数据中的人名、公司名、化学式及相应的专有名词,人工构建了232个词的专有词典,进一步提升了pkuseg的分词准确率,并且从一定程度上解决了文本摘要生成过程中的未登录词问题。

表3 不同分词工具之间的评价指标对比
2.3 自动文本摘要的评价方法
本文实验结果将采用ROUGE评价体系进行评测。ROUGE评价体系定义请参见文献[11]。本文的对比实验分析中,主要使用ROUGE-1、ROUGE-2和ROUGE-L这3个值来评价本文的生成式摘要质量和模型性能。ROUGE-1、ROUGE-2和ROUGE-L评价指标的计算公式如式(17)~式(21)所示
(17)
(18)
(19)
(20)
(21)
其中,LCS(X,Y) 是X和Y的最长公共子序列的长度,m和n分别表示参考摘要和生成摘要的长度,Rlcs,Plcs分别表示召回率和准确率,在DUC任务中β被设置为一个很大的数,所以ROUGE-L几乎只考虑召回率。举例说明见表4。
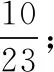

表4 评价指标计算样例(β设为10)
2.4 参数设置
本文中出现的符号说明见表5,其它符号均在文中详细标注。

表5 本文中出现的符号说明
本文使用控制变量法对学习率(learning rate,lr)和dropout进行对比实验,寻找其最优初始值。
首先为了找到最优的学习率初始值,本文在每次迭代结束后都初始化网络并同时增加学习率,统计每次迭代计算出的损失值。学习率取值范围为1e-05至1。每次迭代设置的学习率参数如图4(a)所示。损失值随学习率增加的变化曲线如图4(b)所示。
如图4(b)所示,损失值在学习率为1e-05-0.1内随学习率的增加而震荡减小;在学习率为0.1时,损失值达到最小值;学习率超过0.1后,损失值均高于最小值。因此,在本次实验中最优学习率初始值为0.1。
其次,为减少过拟合现象,本文使用dropout参数,dropout定义请参见文献[16]。dropout取值范围为0%至100%。损失值随dropout的变化曲线如图5所示。

图4 学习率参数实验

图5 损失值与dropout的变化曲线
如图5所示,损失值在dropout取值为0%-40%内时随dropout值的增加而减少;dropout超过40%后,损失值随dropout值的增加而增加;在dropout为40%时,损失值达到最小值,即在本次实验中最优dropout初始值为40%。
2.5 实验结果分析
本文采用上述数据集进行实验,在基于编解码器的文本摘要模型训练过程中使用多分类交叉熵损失,lr设置为0.1,batch_size为128,dropout设置为0.4。迭代19轮的结果如图6所示。分别代表训练损失值(train loss)变化情况和测试损失值(test loss)变化情况。
为防止过拟合的发生,实验使用提前停止(early stopping),如果test loss增加,则停止训练。通过实验结果分析,随着时段数Epoch的增加,损失值逐渐减少,在训练进行到第20轮时,test loss值为2.0404,而第19轮的test loss值为2.0372,测试损失增加,故训练停止,模型共迭代19轮,train loss值下降至1.8052,test loss值下降为2.0372。
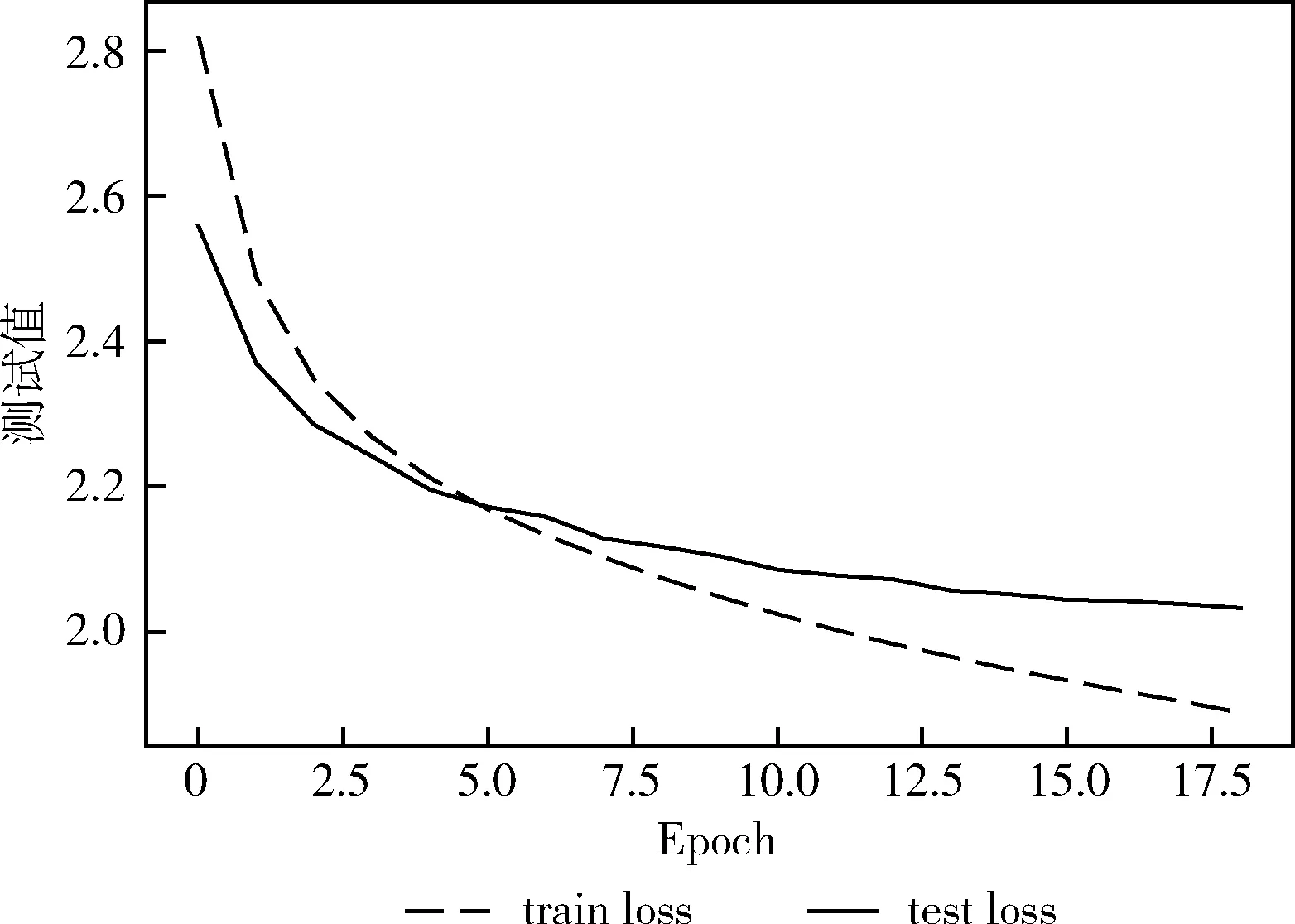
图6 BiGAtten-LSTM模型训练损失值与 测试损失值变化曲线
本文又进行了系列对比实验,实验结果详情见表6。其中:
RNN[14]:代表Hu等提出的模型,使用循环神经网络作为编码器,并且将编码器得到的最后一个隐藏状态传输到解码器。
MC-LSTM+atten[8]:代表编码器为卷积神经网络,解码器为LSTM,并加入attention的模型。
BiGRU-GRU+atten[9]:代表编码器使用双向GRU网络,解码器使用单向GRU网络,并加入attention的模型。
BiGRUAtten-LSTM(本文):代表本文提出的基于编解码器结构的自动文本摘要模型。
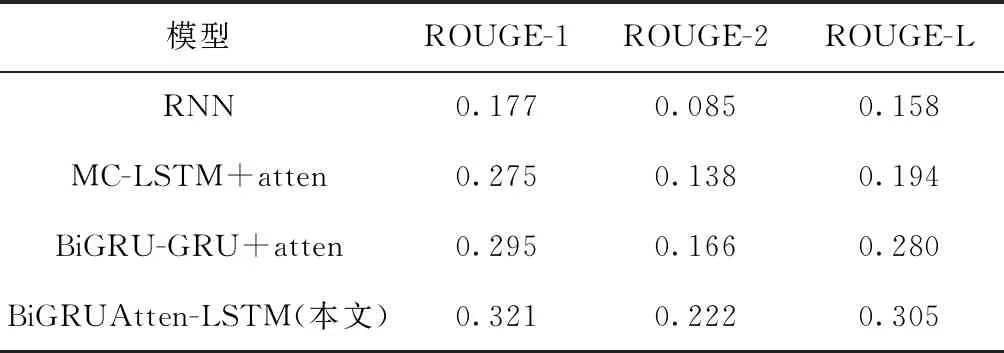
表6 不同模型之间的ROUGE评价指标对比
4种模型训练过程中的ROUGE-1指标、ROUGE-2指标和ROUGE-L指标的变化情况如图7(a)~图7(c)所示。
图7 不同模型之间的ROUGE评价指标对比
由图7和表6可以看出,在中文工业新闻数据集上,本文模型与传统的生成式文本摘要模型相比,ROUGE-1指标提高了0.026-0.144、ROUGE-2指标提高了0.056-0.137和ROUGE-L指标提高了0.025-0.147,说明本文设计的BiGRUAtten-LSTM模型获得的上下文语义更加丰富,语言理解的更充分。同时本文模型在解码器端使用先验知识和集束搜索方法在一定程度上提高了摘要的准确性。
3 结束语
文本自动摘要生成是NLP领域的重要分支,在新闻、报告和论文的概要信息的快速阅览上具有重要指导意义。本文通过对生成式文本自动摘要的学习与研究,针对传统模型长期依赖和语言理解不充分等问题,提出了基于编解码器结构的文本摘要生成模型(BiGRUAtten-LSTM)。编码器使用双向GRU网络进行编码,注意力机制结合编码器输出的语义向量获得上下文语义向量,较大程度上丰富了编码输出的中间信息内容,帮助解码器获取足够的信息,提高了解码的准确度。同时结合先验知识和集束搜索方法,有效减少文本摘要生成过程中的未登录词问题,进一步提高了摘要质量。在真实的工业新闻领域的数据上,通过ROUGE评价体系,实验对比分析了现有文本摘要生成方法,本文的文本摘要生成效果有了很大的提升。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
校园英语·月末(2021年13期)2021-03-15
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
成都信息工程大学学报(2018年3期)2018-08-29
制造技术与机床(2017年7期)2018-01-19
电子器件(2015年5期)2015-12-29
