
近地表结构特征属性平衡迭代规约和层次聚类分析
2021-03-23 03:18唐传章张锐锋王泽丹黄新亚王会来
石油物探 2021年2期
沈 华,宋 炜,唐传章,张锐锋,王泽丹,黄新亚,王会来,刘 慧
(1.中国石油天然气股份有限公司华北油田分公司勘探事业部,河北任丘062550;2.中国石油大学(北京)地球物理学院,北京102249;3.中国石油天然气股份有限公司华北油田分公司勘探开发研究院,河北任丘062550)
随着油田精细勘探的不断推进,深层岩性油气藏和复杂潜山油气藏成为油气勘探的重要地质目标,提高地震资料分辨率、改善目的层成像精度已深入到地震勘探的全过程。决定地震分辨率的关键是有效频带宽度,而制约有效频带宽度的两个主要因素是反射信号的能量和频宽,因此,如何在地震采集和处理过程中保持有效信号的能量和频宽,是研究的焦点问题之一。
地震波在地下介质中传播时,波的能量吸收因素主要来自介质粘弹性引起的吸收作用[1]。在松散的地层或裂隙发育的地层中,地震波的吸收响应比地震波速响应更为敏感[2-4]。华北油田冀中探区地表平缓,但表层结构松散且复杂多变、速度低,对地震波的吸收、衰减严重,导致地震资料分辨率低,尤其在表层结构复杂地区地震资料品质较差,难以满足复杂构造、深潜山和地层岩性勘探的需求[5-8]。岩石物理学研究结果表明,地下介质对地震波的吸收作用与介质固结程度、孔隙度和孔隙充填物关系密切[9-10]。因此,固结岩层的吸收规律不能简单地应用于表层未固结低、降速带。在常规地震资料处理中,地震波的吸收衰减补偿只针对浅、中、深层,而表层低、降速带介质对地震子波的吸收衰减基本未进行补偿。为了更好地消除复杂近地表因素对采集、处理带来的影响,需要对近地表结构有清晰的认识,并获取准确的近地表结构属性参数模型,如低、降速带厚度、速度、品质因子(Q)等。多年来,诸多学者在复杂近地表结构特征参数调查[2-4]、激发条件及观测方式[5-8]、复杂近地表的吸收衰减因子求取与有效补偿[11-21]、复杂近地表速度建模及静校正[22-24]等方面开展了大量的研究,并取得丰硕的研究成果。华北油田冀中探区表层结构的复杂性、介质不均匀性以及未固结低、降速带严重的吸收衰减,使得表层地震波的衰减补偿变得十分复杂。
本文针对华北油田实际生产面临的两个问题开展研究。一个是在高吸收衰减区地震资料分辨率和信噪比低,往往处理后,再要求施工方补炮,延误了数据采集的进度。另一个是基于环保的需要和对资料精度的要求,2018年底华北油田引进自适应非线性扫描激发采集技术,在冀中探区同口三维工区开展可控震源采集,由于自适应非线性扫描激发需要在每个激发点先按常规线性扫描激发,然后根据接收的单炮数据设计自适应激发参数,导致野外施工进度缓慢,成本增加,当时提出了施工前将近地表分类,再根据近地表类别分别进行常规线性扫描采集,确定不同类别地表条件下的自适应激发因子,具体施工时,按分类结果实施,但是由于时间仓促,未能提出较好的分类算法,主要采用平均衰减因子作为分类依据,由于分类太粗,在生产中并不能满足需求。
本文在前人研究的基础上,利用冀中探区近万平方公里范围内的微测井解释成果,在构建和分析近地表结构特征属性参数的基础上,基于机器学习的平衡迭代规约和层次聚类分析(balanced Iterative reducing and clustering using hierarchies,BIRCH)方法[25-28],对华北油田冀中探区进行了多属性参数分类划分,将不同类别勘探区域的表层吸收衰减参数用于采集参数设计优化和地震资料处理,为深化华北油田冀中探区复杂地质目标的地震勘探提供有效的技术支撑。
1 近地表结构特征属性分析
华北油田冀中探区虽然地表平缓,但表层结构复杂多变,特别是人类活动对表层结构的改造,加剧了表层结构的纵横向变化。从高程数据可以看出,冀中探区地势总体平坦,南、北部较高,中间区域较低,海拔在-1.7~36.8m,平均海拔14.24m(图1)。探区表层结构变化复杂,低、降速带厚度从几米到四五十米,横向变化剧烈。地震勘探过程中,由于表层结构松散、速度比较低,因而对地震波的吸收、衰减非常严重,一些表层结构复杂的地区地震资料品质较差,甚至得不到有效的深层反射信息。受表层和深层条件双重影响,研究区内已有的一次和二次三维采集的地震资料信噪比低、频带窄,深层地震波吸收衰减严重,处理、解释结果达不到实际生产的要求。

图1 华北油田冀中探区地表高程分布情况
通过微测井数据分析将华北油田冀中探区近地表分为低速层、降速层,冀中探区低、降速层的厚度(h)不同,速度横向上也有显著差别(图2)。
球面扩散是导致反射信号能量降低的主要因素,吸收是使反射信号频带宽度变窄的主要因素,其中表层吸收尤为严重,是降低分辨率的主要因素之一。描述介质吸收性质的有关参数包括吸收系数α和品质因子Q。均匀吸收介质中传播的平面波振幅方程为:
A(r,t)=A0e-αrω(t)
(1)
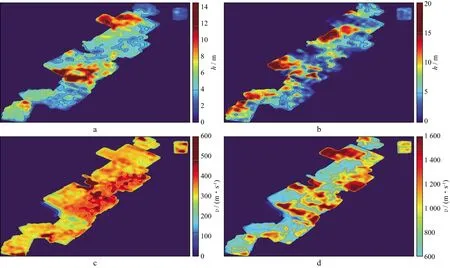
图2 低、降速层厚度及速度属性
在吸收介质中,振幅随传播距离的增大而呈指数减小。其中,r为地震波的传播距离,A0是初始振幅,A是地震波传播r后的振幅谱,ω(t)是波动函数,α为吸收系数。品质因子是用来度量介质对地震波能量吸收衰减的参量,地震勘探中常用能量损耗因子来表达:
(2)
其中,在谐波激励情况下,ΔE表示每震动一个周期的能量损耗量,E表示系统中处于最大应力和应变状态下的瞬时弹性势能,品质因子Q代表了储能与耗散能量之比,1/Q表示能量损耗因子,其值越大说明地层对地震波的吸收衰减作用越剧烈。由对数函数关系表可知,品质因子是一个正数,Q值越小,能量损耗越大。图3是冀中探区低、降速带品质因子属性图,可见探区内品质因子变化较大。地震波在近地表传播衰减过程可以表示为:
(3)
式中:Hi为第i层的厚度;Vi为第i层的速度;Qi为第i层的Q值;W0(f)为初始地震波的频谱;WN(f)为地震波在近地表传播N层后的频谱;f为频率。
基于公式(3),根据地表速度、Q值和厚度可以模拟地震信号不同频率成分经过地表传播后的相对衰减量。频率越大,衰减量越大。图4给出了不同主频的子波能量相对衰减量。由图4可见,不同频率成分有不同的衰减量,特别是高频成分,在穿透低、降速带时,衰减更严重。基于公式(3),对比分析了主频为30Hz的雷克子波经过地表传播后峰值频率和频宽的变化(图5)。由图5a和图5b可见,衰减越严重的地区,峰值频率和频宽减小得越多。为了进一步评价子波穿过近地表后能量的变化,通过对比分析衰减前、后子波峰值振幅比属性(图5c)和子波总能量比属性(图5d)来研究地表横向衰减特征的变化。由图5c 和图5d可以看出,在高衰减区域,无论是子波峰值振幅比还是子波总能量比其变化都很明显,因此低、降速带不仅对地震资料的分辨率有影响,对信噪比也同样有影响。
为了研究近地表本身属性的影响,需要将与地震信号有关的物理参数消除。定义:
(4)
式中:QNA为N层近地表介质的平均衰减效应因子,其与近地表地层条件有关,与频率和地震信号的特征无关。利用华北油田冀中探区的微测井资料计算得到的QNA见图6a;以QNA为基准,以子波衰减前、后最大振幅比和能量比为参考,将冀中探区表层条件分为3类(图6b)和9类(图6c)。3类表层条件的具体划分阈值细节如下。

图3 冀中探区低、降速带品质因子(Q)

图4 不同主频的子波能量相对衰减量

图5 30Hz雷克子波穿透低降速带后属性变化情况
1) 第1类:QNA<0.01,该表层表现为轻度衰减。
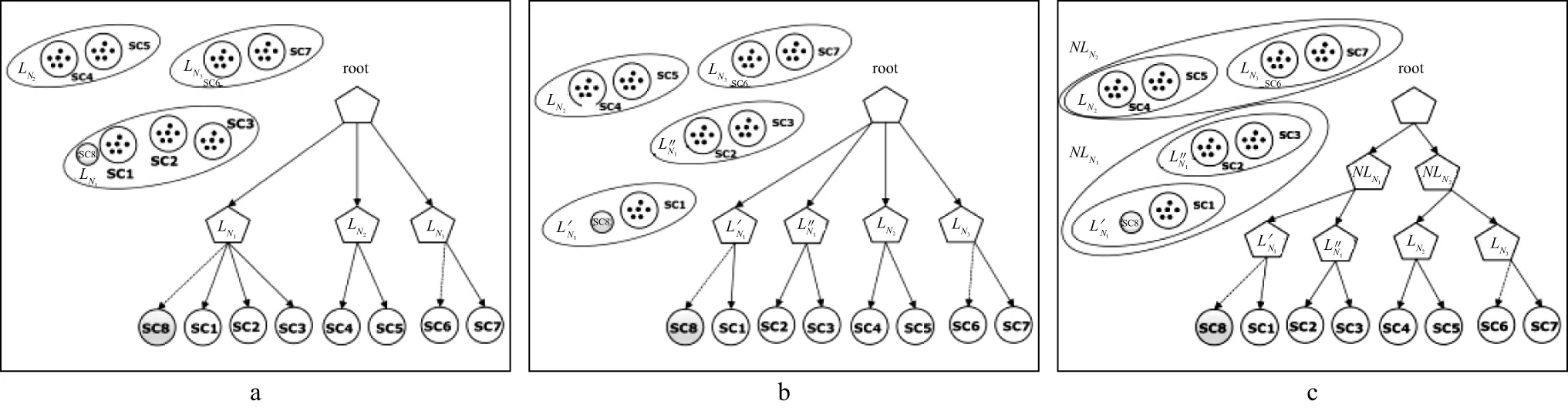
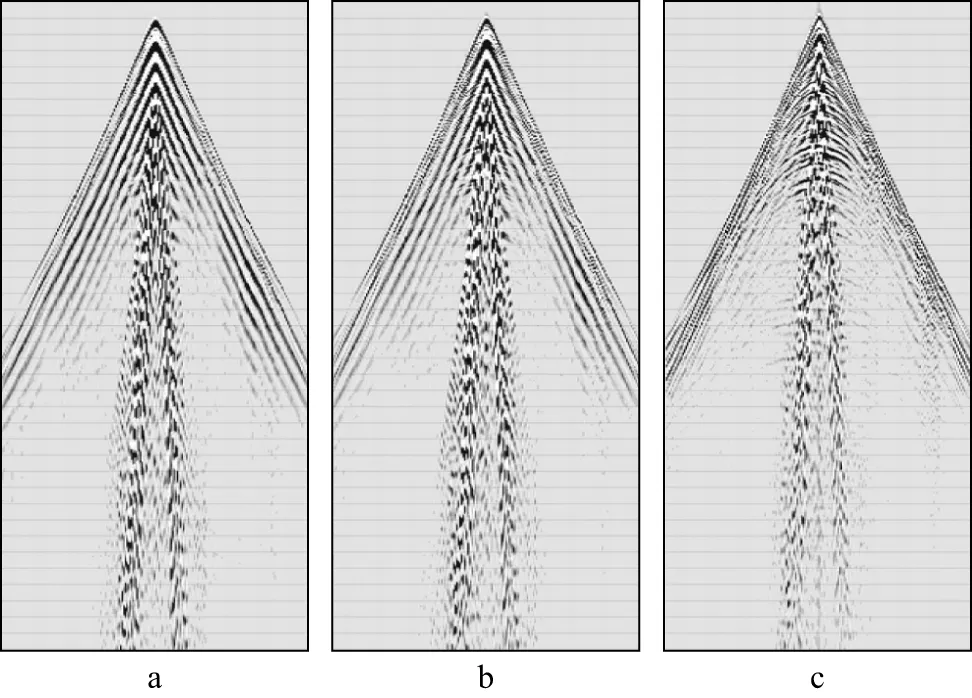
2) 第2类:0.01 3) 第3类:QNA>0.023,该表层表现为严重衰减。 9类表层条件的具体划分阈值细节这里不赘述。 基于上述分类结果,分别就不同地表类型对地震信号的分辨率、振幅衰减、频谱特征和信噪比的影响开展讨论。图7a给出了目的层时间厚度Δt=16ms,对于不同地表类型,以主频30Hz雷克子波穿透近地表,再由目的层顶、底反射回地面,观测到的反射波对地层的分辨能力。图7a中蓝色线是第1类近地表条件,属于低衰减区,薄层可以分辨;红色线是第2类近地表条件,属于中等衰减区,薄层不可分辨;绿色线是第3类近地表条件,属于高衰减区,薄层不可分辨。图7b给出了目的层时间厚度Δt=25ms,对于不同地表类型,以主频30Hz雷克子波穿透近地表,再由目的层顶、底反射回地面,观测到的反射波对地层的分辨能力。图7b中蓝色线是第1类近地表条件,属于低衰减区,薄层可以分辨;红色线是第2类近地表条件,属于中等衰减区,薄层可分辨;绿色线是第3类近地表条件,属于高衰减区,薄层不可分辨。由图7可见,在地震资料的采集处理过程中需要考虑地表的影响。图8展示的是主频30Hz雷克子波穿过不同类型的地表后子波波形和频谱变化规律。由图8 可见,第3类区域子波振幅衰减严重(图8a中绿色子波);第1、2、3类区域子波频谱主频向低频方向移动,频带变窄(图8b)。 图6 利用华北油田冀中探区的微测井资料计算得到的平均衰减效应因子(a)以及基于衰减因子门槛值的3类(b)和9类(c)分类结果 图7 不同地表类型对不同目的层厚度的分辨率影响(雷克子波主频30Hz) 图8 主频30Hz雷克子波穿过不同类型的地表后子波波形(a)及频谱(b)变化规律 地震信号的信噪比和地表条件密切相关。在相同噪声水平下,由于地表条件不同,有效信号的衰减量不同,因此反射地震数据信噪比也不同。如图9所示,含噪声主频30Hz雷克子波穿过第1类轻度或无衰减区域后信噪比最高(信噪比为3.20),第2类次之(信噪比为0.90),第3类由于信号衰减严重,信噪比较低(信噪比为0.06),有效信号几乎淹没在噪声中。尽管上述分类方式具有一定的指导意义,但是这种分类方式要根据具体的地质情况确定分类门槛,而且门槛的设定对分类结果影响较大,将复杂地表结构简单地分成3类,在生产实践中难以起到指导作用,因此需要新的分类划分方法。 图9 不同地表条件对反射地震数据信噪比的影响 BIRCH算法是由ZHANG等[28]提出的对大规模数据集进行聚类分析的一种非常有效的基于距离的层次聚类算法。该算法首先采用自底向上的层次聚类算法,然后再通过迭代重定位来改进聚类结果。BIRCH算法利用聚类特征树(clustering feature tree,CF Tree)来实现快速聚类。特征树的节点由多个聚类特征(clustering feature,CF)组成。CF是一个由(N,LS,SS)来表示的三元组,其中,N代表CF中拥有的样本点的数量;LS代表CF中样本点各特征维度的和;SS代表CF中样本点各特征维度的平方和。例如,在CF Tree某个节点的某个CF中,有5个样本(1,3),(3,5),(2,4),(4,6),(5,7),则其三元组参数N=5,LS=(1+3+2+4+5,3+5+4+6+7)=(15,25),SS=(12+32+22+42+52+32+52+42+62+72)=190。CF满足线性运算,如CF1+CF2=(N1+N2,LS1+LS2,SS1+SS2)。在CF Tree上,对于每个父节点中的CF节点,它的(N,LS,SS)三元组的值等于这个CF节点所指向的所有子节点的三元组之和。CF Tree的重要参数有:①每个内部节点的最大CF数B;②每个叶子节点的最大CF数L;③叶子节点每个CF的最大样本半径阈值T,即在CF中所有样本点一定要在半径小于T的超球体内。 在聚类开始时,CF Tree是空的,首先从训练集读入第1个样本点,将它放入新的CF三元组A,该三元组的参数N=1,将新的CF作为根节点,此时的CF Tree如图10a所示。继续读入第2个样本点,如果该样本点和第1个样本点A在半径为T的超球体范围内,则属于同一个CF,将该点也加入CFA,此时A的三元组参数N=2,CF Tree如图10b所示。继续读入第3个样本点,如果不能融入前面的节点形成的半径为T的超球体内,则需要新的CF三元组B来容纳这个新值。此时根节点就由两个CF三元组A和B组成,CF Tree如图10c所示。读入第4个样本点时,如果它和B在半径小于T的超球体内,则更新后的CF Tree如图10d所示。 当叶子节点的最大CF数L=3时,随着样本点的不断读入,CF Tree的节点需要分裂,假设分裂前的CF Tree如图11a所示,叶子节点LN1有3个CF,LN2和LN3各有两个CF。当新的样本点读入时,可发现它离LN1节点最近,因此需要判断它是否在sc1,sc2,sc3这3个CF对应的超球体之内,如果不在,则要建立一个新的CF,即sc8来容纳它。如果设定叶子节点的最大CF数L=3,即LN1的CF个数已经达到最大值,不能再创建新的CF,就需要将LN1叶子节点分裂为二,并从LN1所有CF元组中,找到两个最远的CF作为这两个新叶子节点的种子CF,然后将LN1节点里所有CF(sc1,sc2,sc3),以及新样本点的新元组sc8划分到两个新的叶子节点上。LN1节点分裂后的CF Tree如图11b所示,如果设定内部节点的最大CF数B=3,则此时叶子节点一分为二会导致根节点的最大CF数超出范围,因此根节点也要分裂,分裂的方法和叶子节点分裂一样,分裂后的CF Tree如图11c 所示。当所有的训练集样本建立了CF Tree,一个基本的BIRCH算法就完成了,对应的输出就是若干个CF节点,每个节点里的样本点就是一个聚类的簇。因此BIRCH算法的主要过程就是建立CF Tree的过程。 BIRCH算法的主要优点有:①节约内存,所有的样本都保存在磁盘上,CF Tree只保存了CF节点所对应的指针,聚类特征树概括了聚类的有用信息,并且占用空间较元数据集合小得多,可以存放在内存中,从而可以提高算法在大型数据集合上的聚类速度及可伸缩性;②只需要扫描训练集一次就可以建立CF Tree,且CF Tree的增、删、改都很快速,因此聚类速度快;③可以识别噪声点,还可以对数据集进行初步分类的预处理。BIRCH算法的主要缺点有:①由于CF Tree对每个节点的CF个数有限制,导致聚类结果可能和真实的类别分布不同;②对高维特征数据聚类效果不好,比如样本数据维度超过20,此时可以选择Mini Batch K-Means。 图12a为随机生成的样本数据,共1000个样本,每个样本2个特征,共4个簇;图12b是不指定聚类类别数得到的聚类结果,共分为8个类簇;图12c是指定类别数为4时得到的聚类结果。由图12b和图12c 可见,如果对数据的类别属性有所了解,指定类别数可获得更好的聚类结果。图13显示的是由两组1500个点构成的随机样本,一组是两个圈形数据,另一组是两个月牙形数据,分别采用K-means和BIRCH算法进行聚类得到的结果。对比聚类结果可以看出,传统K-means聚类方法主要依据样本点的距离关系进行聚类,因此聚类结果和真实数据分布不一致,如图13a和图13c将圈形和两个月牙形的样本簇按距离远近进行聚类,得出了错误的聚类结果。而本文所述的BIRCH算法则是一种基于距离的层次聚类算法,根据其树形结构的特征层次聚类思想,得到如图13b和图13d的正确聚类结果。而本文所涉及的问题,即近地表类别的变化类似于图13所示的样本点分布,需要基于多属性的层次关系,寻找到正确的聚类结果,因此最终选用了BIRCH算法。当然,在机器学习领域,还有很多聚类算法,比如DBSCAN、凝聚层次聚类、谱聚类等都可以取得和BIRCH方法类似的效果,因为本文的重点不是分析算法的差异,因此不作详细对比分析。 图10 聚类特征树生成示意 图11 CF Tree节点分裂示意 图12 随机样本不同参数BIRCH聚类结果 图13 两组随机样本分别采用K-means和BIRCH聚类方法得到的结果 本文以华北油田冀中探区近10000km2范围内的微测井处理解释成果资料为基础,用于多属性聚类分析的向量由以下属性构成:近地表高程,低、降速带速度、厚度、Q值,不同主频率(10Hz,20Hz,30Hz,40Hz)的雷克子波能量相对衰减量,主频30Hz雷克子波峰值振幅比属性、总能量比、峰值频率属性、频带宽度属性,平均衰减因子属性。 BIRCH多维向量层次聚类假设特征数据为正态分布(即满足零均值且单位方差呈高斯分布),需要对输入多属性向量数据进行标准化,使其满足正态分布。算法实现中,以Scikit-Learn的开源数学库为基础,选择其中的Preprocessing.StandardScalar函数实现输入数据标准化[25]。按上述方法,完成了研究区近10000km2的无监督BIRCH聚类分析研究。 图14给出了基于BIRCH多维向量层次聚类方法得到的近地表结构分类结果。图14中将冀中探区分为9类,与图6b的分类结果相比,将近地表结构的差异划分得更加细致,图14中划分的1、2、3类相当于图6b中的第3类,对应吸收衰减比较严重的区域;4、5、6类相当于图6b中的第2类,对应吸收衰减中等区域;而7、8、9类相当于图6b中的第1类,对应吸收衰减相对较弱的区域。对比图14和图6c可见,尽管图6c也通过门槛值将平均衰减因子属性划分成了9类,但是分类细节还是不如多属性参数BIRCH聚类分析方法。由此可见,两种分类方法有一定相关性,但是BIRCH聚类分析方法无需人为设定任何门槛值,更易于实现,且分类更精细。例如图14中左下角红色区域和右上角橙色区域,按图6采用的分类方法都归为第3类,实际上从图2的低、降速带厚度、速度和图3中的Q值分布来看,这两个区域还是有明显差异的。 沿图14中测线AA′和BB′进行吸收衰减试验来验证近地表结构对子波能量、分辨率和信噪比的影响。图14中的a1,b1分别表示主频为30Hz的雷克子波穿透测线AA′和BB′所在位置的低、降速带层,经吸收衰减后波形特征的变化,可以明显看到,不同类别地层对子波波形的改变。图14中的a2,b2分别表示主频为30Hz的雷克子波穿透测线AA′和BB′所在位置的低、降速带层,然后透过一个厚度为Δt=20ms的地层反射回来后的子波,可见低衰减区域分辨率明显高于高衰减区域。图14中的a3,b3分别表示主频为30Hz叠加随机噪声的雷克子波在相同信噪比情况下穿透测线AA′和BB′所在位置的低、降速带层,经吸收衰减后的子波。可以明显看到,低、降速带对地震资料信噪比的影响。 图14 基于BIRCH多维向量层次聚类方法得到的近地表结构分类结果 在实际应用中,通常要考虑不同类别的近地表结构下激发条件对地震资料品质的影响。冀中探区的三维地震资料采集以井炮为主,图15给出了图14中C点所在位置采用BIRCH聚类方法得到的1类区域不同激发深度的单炮记录,由图15可见,激发深度对单炮质量的影响明显。图16给出了图14中D点所在位置采用BIRCH聚类方法得到的1类区域不同药量激发的单炮记录。由图16可见,同样在高速顶以下15m激发,采用的炸药量不同,单炮记录品质明显不同。小药量激发的单炮记录高频低能,大药量激发的单炮记录低频高能,随着药量的增加,单炮记录质量提高。由图16h可见,继续增大药量,单炮记录的质量提高有限,但生产成本却明显提高,因此在采用BIRCH聚类方法得到的1类区域,激发药量达到8~9kg即可满足生产要求。 图15 基于BIRCH多维向量层次聚类方法得到的1类区域不同激发深度的单炮记录(激发药量为8kg) 图16 基于BIRCH多维向量层次聚类方法得到的1类区域相同激发深度(15m)下不同药量的单炮记录 另外,在观测系统设计时,可采用如图14所示的分类结果进行分区设计,如BIRCH聚类分析的1类区域,属于强吸收衰减区域,可采用加密炮增加覆盖次数提高信噪比。 本文方法采用多种属性参数构成的向量作为输入进行空间聚类分析,可有效克服基于平均衰减因子的单属性划分近地表特征的缺点,提高分类划分的精度。当然,输入参数的多少也值得关注。图17a是采用12个属性参数(去掉低、降速层的速度和厚度属性)进行BIRCH聚类分析得到的近地表结构平面分布图。从图17a可见,分类结果大体趋势上和图14一致,但是缺少细节信息。图17b是采用8个属性参数(去掉了低、降速层的Q值属性)进行BIRCH聚类分析得到的近地表结构平面分布图。从图17b可见,分类结果大体趋势和图14一致,但更加平滑。可见,如果用来聚类的属性相关度不是太大,保留多属性聚类分析,可以更加精细地描述表层特征的变化。 图17 基于BIRCH多维向量层次聚类方法得到的近地表结构平面分布 近地表参数的变化,对地震资料的信噪比、分辨率有直接影响,因此无论是资料采集还是处理,确定目标区近地表结构类别,并合理利用,是提高采集资料品质和处理质量的关键环节。本文引入无监督机器学习的BIRCH多属性向量层次聚类方法划分近地表结构类型,可以有效克服基于平均衰减因子属性分类划分的缺点,提高近地表结构分类划分精度和可靠性,理论模型和实际资料分析结果证明了本文方法的有效性,并得出以下结论: 1) 平均衰减因子属性可以作为近地表结构划分的参考性属性,但是由于门槛值很难把握,因此在实际应用中并不是好的分类依据; 2) 基于无监督机器学习的BIRCH多属性向量层次聚类分析方法,可以很好地利用近地表多属性参数向量实现近地表结构的分类划分,为观测系统设计和地震资料激发、接收和处理提供帮助; 3) 通过对华北油田冀中探区近地表结构的分类划分及其对地震资料信噪比和分辨率的影响因素分析,认为基于近地表多属性参数聚类分析结果优化地震资料采集和处理参数是可行的,为地震资料采集和处理参数优化提供了新依据。



2 平衡迭代规约和层次聚类方法原理
2.1 BIRCH算法核心思想
2.2 聚类特征树的生成



3 应用效果分析



4 结论
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
火炸药学报(2021年5期)2021-12-06
上海人大月刊(2020年12期)2020-12-30
北京航空航天大学学报(2019年9期)2019-10-26
铁道通信信号(2019年6期)2019-10-08
中国新闻周刊(2019年9期)2019-04-29
雷达学报(2017年3期)2018-01-19
科技视界(2017年5期)2017-06-30
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
