
一种基于重叠社区标签传播的学科划分方法
2021-03-22 02:52:58遆慧颖
农业图书情报学刊 2021年1期
遆慧颖,耿 骞,靳 健
(北京师范大学政府管理学院,北京 100875)
1 引言
随着网络技术迅猛发展,网络信息内容主要呈现出信息总量大、增速快和来源多样化等特征。同时,作为一种典型的非结构性化数据,海量的文本信息也不断涌现。普通用户以及广大学习者和研究人员可以通过Wikipedia、百度百科、必应百科为代表的网络全书类网站获取各学科概念定义以及使用发展等信息。但是各学科在理论与实用领域不断发展,并且不少研究都呈现了蓬勃的交叉融合、系统发展的趋势。这使得不具备专业知识的普通用户很难通过该类百科全书在短时间内获取目标概念所属学科的整体信息。因此,利用算法有效地、自动地实现学科领域划分将大大提高用户获取信息的效率。
同时,不同学科各具特点,且有的学科知识存在着一定的交叉融合。例如,艺术领域专业性较强。但在数学领域,除核心的概念定理之外,不少概念还广泛应用于各个学科。而情报学中有的概念是由计算机科学和数学等学科交叉产生。正如有学者研究指出[1],交叉学科在各个学科的知识、技术以及视野方面均有所交叉融合,而学科这一概念已经不能通过简单的“三独立说”实现,即独立的概念系统、独立的研究方法和独立的研究对象。传统的简单的规则已很难从包含海量知识的网络百科全书中获取当前的学科领域相关知识。而这一问题对不断发展的新兴学科更为严重。
目前,学科领域的文本划分多利用基于规则或统计的方式,在特定领域进行实现[2],缺乏系统性视角以及对语义之间的相互作用的整体性考虑。注意到学科概念与概念描述文本主题存在一定的相关度,而这种相关程度不能仅由文本相似度的绝对值大小来决定,还与概念间的联系程度、重要概念间关联程度等很多关联因素有关。这些因素都影响着一个概念是否可以被划入一个学科领域中。并且,实际中,一个词条可能属于多个领域。该现象与复杂网络中的重叠社团相对应。
因此,本研究尝试从复杂网络的视角探索领域词条划分问题。具体来说,本研究将通过分析词条间由相似度产生的语义相互作用,获取学科领域边界。首先,本研究将利用隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA)主题模型构建语义相似度网络。然后,针对语义相似度网络的特征,对复杂网络中的标签传播算法进行改进。最后,利用所提出的改进算法,实现学科边界的划分。
本研究提出的方法具有理论和实际意义。在理论领域方面,本研究提出了改进标签传播算法,为将复杂网络算法引入文本划分领域做出了探索。在实际应用方面,学科领域边界的划分可以提高用户查询效率,为建立相应学科本体构建基础语料库,帮助初学者更好地组织网络百科全书中的大量信息和了解学科领域包含的内容。
2 文献综述
2.1 多标签文本划分
按照每个文本单元具有的标签数,从分类结果角度,文本分类可以分为单标签划分和多标签划分。多标签文本划分算法在推荐系统、本体构建以及评论挖掘等方面都有广泛应用。
LILLEBERG 等提出了基于词向量和支持向量机的文本标签划分[3]。PAVLINEK 提出了利用LDA 主题模型和半监督学习方法展开多标签文本划分[4]。邓三鸿利用多个二元分类器以深度学习的方法实现了中文图书的多标签分类[5]。刘晋宏提出了利用图结构上的随机游走算法确定标签分布概率,从而实现多标签分类的算法[6]。刘心惠等综合神经网络、主题模型等提出了基于联合模型的多标签文本分类方法[7]。
上述方法在精确率和召回率方法取得了较好的结果。但是这些算法大都将文本视为独立个体或者均以整体进行词频和概率展开分析,没有充分利用词条相似性的结构性信息。本研究的展开是建立在词条网络上的,通过探索词条间由相似度构建的语义相互作用,获取更大范围和具有实践意义的学科领域边界。
本研究以复杂网络的视角,立足词条的具体语义,对大量的词条及其它们之间的相互关系进行网络化的建模和结构分析。复杂网络作为系统科学研究的重要内容,已经广泛应用于电力系统[8]、社交网络[9]、城市交通[10]、经济预测[11]、网络划分[12]等重要领域。近年来,学者尝试将复杂网络相关概念和算法引入文本划分领域。赵辉等提出利用复杂网络理论中的节点加权度、加权聚集系数、节点介数等指标进行文本特征选择的分类算法[13]。尹丽英以最大公共子图文本语义相似度计算方法为基础来提取特征文本,从而构建训练文本集的语义复杂网络,并利用K 最近邻算法进行社团划分[14]。这些研究发现文本和实物同样具有网络结构,而其网络结构表现了文本之间的连接紧密的局部关系。
在这些研究中,尽管词条网络和文本网络逐渐进入研究视野,但是其语义分类尚未与复杂网络联系起来。而注意到学科领域内词条连接通常较明显地强于领域外的连接。因此,本研究将文本间的关联引申到学科领域,以实现学科词条划分。
2.2 词条语义相似度
在自然语言处理领域,研究人员围绕文本相似度的定义进行了多方面的研究。一方面,基于词频的文本相似度往往常利用“词频-逆文档频率”的方法将文本转化为词频加权向量,之后利用余弦相似度及类似方法计算相似度。在此基础上,许多经典研究希望可以挖掘词语本身的相互关系。为此,经典的研究利用字典来计算词语间的相似性。另一方面,从文本的生成结构的角度出发,研究人员构建了生成概率模型。其中,潜在语义(Latent Semantic Analysis,简称LSA)分析构建了“单词-文档”矩阵[15],概率潜在语义分析(Probabilistic Latent Semantic Analysis,简称PLSA)在LSA 的基础上构建了“话题-文档-单词”三级概率模型[16]。为了解决上述两种方法的参数随文本增加问题,BLEI 等引入了参数的先验分布模型,提出了LDA 主题模型,解决潜在导致的过拟合问题[17]。LDA 是一种经典的概率模型。在该模型中,文本被看作概率生成过程的结果。生成过程定义了观测随机变量和隐藏随机变量的联合概率分布。通过使用联合分布,计算在给定观测变量下隐藏变量的条件分布,并展开数据分析。在LDA 中,观测变量是文档中的词,而隐藏变量就是主题结构。LDA 主题模型将从文档中推测隐藏的主题结构的问题转化为计算在给定文档下隐藏变量的后验分布问题。
本研究将利用LDA 主题模型获取词条相似度,为后续的处理构建词条相似度网络。
2.3 社团划分算法
复杂网络中的社团划分算法从研究思路上可以分为基于图论的算法,如随机游走算法[18]等,基于层次聚类和连边性质的算法,如Newman 快速算法等[19],基于网络性质或网络动力学的算法[20]等。
以标签传播类算法为代表的系列算法计算速度较快,可以适用于大规模语料库。KOTHARI 等第一次提出标签传播的算法思想[21]。RAGHAVAN 等提出了接近于线性的快速标签传播社团划分算法[22]。在此基础上,GREGORY 首次将标签传播算法由非重叠社团划分拓展到重叠社团划分的领域,提出了Community Overlap PRopagation Algorithm(COPRA)算法,允许一个节点属于多个社团[23]。根据COPRA 算法,文献[22]中提出的快速标签传播社团划分算法可以看作将每个节点所属的最大社团数为1 的特殊情况。此外,还有学者对COPRA 算法做出改进。例如,饶仁杰等利用LeaderRank 算法减少了COPRA 算法随机性,加强了算法的鲁棒性[24],而杜长江等则利用“K-核分解算法”决定了标签传播的顺序[25]。
除了适用于大规模网络外之外,标签传播算法中的“以周围节点定义自身”的运行逻辑与本研究预构建的语义相似度网络基本思想相符:在学科领域的语义相似度网络中,概念与概念之间具有互相定义和解释能力。另外,与实物网络相比,语义相似度网络的节点数目更多,连边密度更大,各个节点的权重相近。因此,在节点选择时,COPRA 算法及不少基于COPRA 的改进算法将面临多个权责差别较小的节点。该情况使得节点的选择具有较大随机性,这将影响算法整体性能。为降低节点选择的随机性,本研究将进一步对COPRA 算法做出改进,以适用于文本领域的概念划分。
3 研究思路
3.1 研究目的
本文的研究问题是在获取目标学科或者领域中的词条的基础上,提出智能算法,高效地实现学科领域地划分,从而帮助查询者提高信息获取效率。本文的研究目标是分析相互关联的概念所属的目标领域,从而划定目标学科的领域边界,以帮助确定与学科领域相关的概念。
为此,在指定领域内的给定词条情况下,本研究将以Wikipedia 为例对网络知识库中的概念展开分析,明确与指定词条相关的领域内容。
3.2 研究框架
本研究的整体思路分为词条的语义网络构建及基于改进COPRA 算法的词条社团划分两个部分。研究框架如图1 所示。原始数据来自于Wikipedia 的词条及其百科说明文本。在数据预处理步骤中,本研究主要对未知分类的词条文本和目标领域中人工筛选的已知文本做出小写化、删去标点符号及停用词、删去无关链接等预处理,以得到初始文本。
在构建词条网络步骤中,研究将以每一个词条及其百科说明文本作为研究个体,并使用LDA 主题模型训练初始文本中的词条,以得到每个词条的代表向量。在此基础上,以余弦相似度的大小衡量节点间的连边重要性,并去掉阈值以下的部分,得到初始网络。
在划分领域步骤中,本研究提出了改进标签传播算法。该算法将与给定领域的词条属于同一领域的词条作为目标领域的划分结果,实现文本网络的划分。
3.3 词条网络的建立
为了有效地描述概念和概念之间的关系,本部分将Wikipedia 的词条以及词条之间的相似度映射到了词条网络上。本研究将建立以词条作为网络节点,以词条相似度作为网络连边权重的词条文本网络。在该网络中,节点用来描述概念本身的独立性,连边表现概念与概念之间的相互作用。

图1 研究框架图Fig.1 Research framework
在计算词条相似度阶段,本部分分别尝试了Doc2vec 以及LDA 主题生成模型。经过多组试验分析,由于Wikipedia 的词条书写较为自由,而Doc2vec 对于语言表达用词的依赖性相对较强。这使得利用Doc2Vec 计算得出的词条相似度与学科概念本身相似度差异较大。所以,本部分选择使用LDA 主题生成模型对文本进行向量化。利用LDA 主题模型,本研究可以得到指定主题数条件下的文本分布向量。
根据LDA 主题模型的结果,以词条作为网络节点,以词条之间的余弦相似度作为连边的权重,即可得到所有词条的全连接网络。然后,删去相似度小于所设定的阈值的连边即可得到文本的语义网络。
3.4 COPRA 算法及其改进
3.4.1 COPRA 算法
重叠社团标签传播算法(Community Overlap PRopagation Algorithm,COPRA 算 法)是2002 年KOTHARI 提出的[21]。该算法将经典标签传播算法由非重叠社团划分拓展到重叠社团划分的社团划分算法。算法具体说明如下:
与经典的标签传播算法一样,COPRA 的核心思想是一个节点由其周围相连的节点定义。假设第i个节点的标签是b。每个节点都由节点标号x 和标签b 表示,即{xi:b}。在COPRA 算法中,每个节点可以由多个标签表示,而各个标签在对该节点的表示中的不同贡献用不同的权重表示{xi0:bi0,xi1:b11,…}。并且,权重需要做归一化计算。例如,一个节点a 可以由1/2 的e,1/3 的c 和1/6 的d 表示,那么a 在算法中表示为{a:1/2,e:1/3,d:1/6}。另外,COPRA 算法设定了每个节点可以属于的最多社团数v。在传播结果中,删去隶属度小于1/v 的标签,以控制节点的所属社团小于等于v。
在算法的初始阶段,每个节点的标签是自己本身。标签传播开始后,每一步每个节点的标签由与之相连的节点的标签决定。相同标签则累加其权重。之后,通过删去标准化后权重小于1/v 的标签,控制每个节点所属的社团数。迭代到节点标签不变或社团总数不变时,算法停止。此时,网络中含有同一标签的节点属于同一个社团。图2 描述了利用COPRA 算法实现4个节点且社团数为2 的标签更新流程。
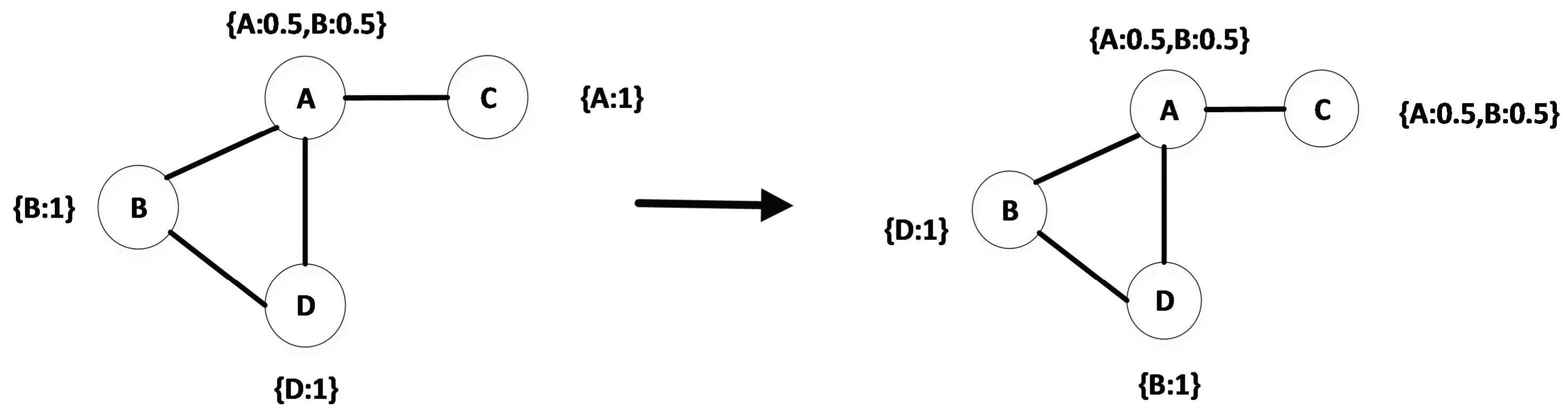
图2 标签传播算法说明(最多社团数v=2)Fig.2 A diagram of label propagation algorithm(Maximum number of communities v=2)
3.4.2 COPRA 算法的改进
通过对经典标签传播算法的分析和实验,本研究发现在语义相似网络中,因为概念词条两两之间计算了相似度,而相似度本身的取值在[0,1]之间,所以网络的连边密集并且各个连边的权重都差距较小。这种特殊性使经典的标签传播算法在根据周围节点确定节点标签时存在很严重的“过度筛选,随机选择”的问题:因为众多邻居节点的标签在定义节点自身时很难具有大于1/v 的权重,且权重常常相似。这使得常常会出现过度筛选掉了所有邻居标签,从而使得可能在邻居节点中任取一个社区标签的作为该节点的标签。这种情况会导致节点所属社团脱离实际,节点只属于某一个社团且算法过早收敛,无法达到学科领域划分的预期效果。例如,在图3 中,A、B、C 的标签均因为小于1/2,可能导致标签选择的随机性很高。
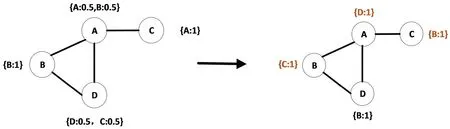
图3 原标签传播算法的过度收敛问题(最多社团数v=2)Fig.3 Overconvergence of the original label propagation algorithm(Maximum number of communities v=2)
为了提高算法的准确度,本研究对于算法进行了改进。对于节点的所有标签隶属度小于1/v,但是其含有多个隶属度相同的标签时,本研究提出了“one more chance”的思路:给予在所有标签中权重最大的标签更多一次的机会,让它们多一次不被过度筛选的机会。具体的说,在标签筛选阶段,如果存在某些节点权重大于其他标签,但该节点权重小于1/v,那么删去其他节点。对于这些节点的标签进行重新的整合和归一化,再次根据1/v 的原则进行筛选。该改动减少了算法的随机性,加强了算法的稳定性,以充分挖掘网络信息。COPRA 算法和改进COPRA 算法的对比如表1 所示。
在改进算法中,节点更新示例如图4 所示。按照规则更新后,若某一标签权重大于阈值,则选择保留该标签,以减少由于过度筛选引入的潜在的误差。
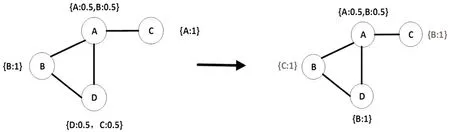
图4 改进算法说明(最多社团数v=2)Fig.4 The improved algorithm(Maximum number of communities v=2)
4 实 验
4.1 数据及预处理
本实验以计算机、文学、数学、体育、情报学和音乐等6个领域为例,对所提出的算法做出验证分析。这些领域是较为常见的且具有一定关注度,而对这些领域词条的自动归档将帮助初学者快速了解本学科的关注点。具体来说,首先,对于一个领域,本研究首先人工选择五个核心词条作为种子。然后,在种子词条的维基百科页面中,本研究提取了“See Also”部分中展示出的相关词条,将这些词条作为与核心词条相连接的词条。在此基础上,本研究根据这种方法逐层扩展,以得到更多词条。接着,对于一个领域,本研究从获取的这些词条中人工选取50个词条,以构建基础数据集。例如,在计算机领域,本研究选取了“Computer science”“Database”“Algorithms”“Distributed computing”“Machine Learning”等6个词条作为核心词条,并以此扩展为50个领域概念词条。为此,本研究获取了来自6个不同的领域的共计300个Wikipedia 的英文词条文本作为实验的基础数据。为了提高处理效率,减少冗余数据的影响,实验对这些词条做出如图1 所示的数据预处理步骤中去除标点、停用词等操作。

表1 改进标签传播算法与原算法的对比Table 1 Comparison of the improved label propagation algorithm and the original one
4.2 评价标准
由于学科之间存在交叉,而Wikipedia 中没有说明。所以,除300个词条的已知分类,实验对于词条的交叉分类进行了人工标注,并将这些人工分类得到结果作为基础评价网络。具体评价指标如下。
(1)调整后的模块度。为了衡量重叠社团的紧密程度,本研究采用如公式(1)所示的拓展的集聚系数。
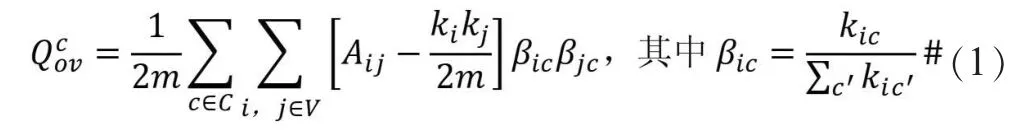
其中,ki,kj指的是节点i,j的度,m是边的总数,Aij是邻接矩阵,βic是i 对于社团c 的隶属度,kic指的是节点在社团c 内的连接总权重。
(2)精确率。假设C1是实际社团,C2是估计社团。精确率描述估计的划分结果中属于实际社团的比例。计算如公式(2)所示。
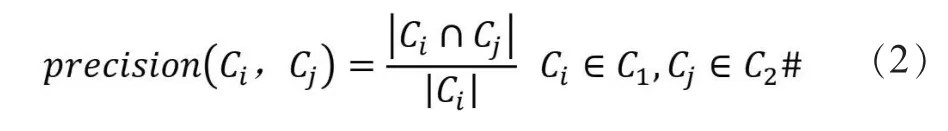
(3)召回率。假设C1是实际社团,C2是估计社团。召回率描述估计的划分结果中属于实际社团节点数占实际社团节点数的比例。计算如公式(3)所示。
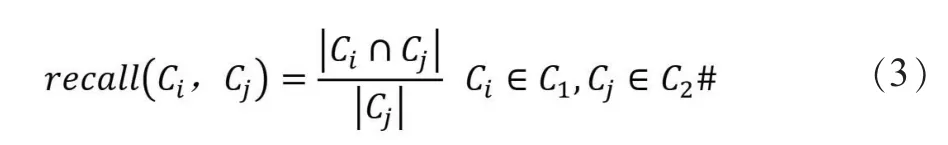
(4)F1-score。查全率和查准率不能综合说明算法的有效性。实验将采用在节点层次的F1-score 对结果进行评估。F1-score 是介于0~1 之间的用于衡量节点水平准确度的一种指标。假设C1是实际社团,C2是估计社团。F1(C1,C2)衡量重叠集合C1,C2的查全率和精确率的调和平均值。计算方法如公式(4)所示。
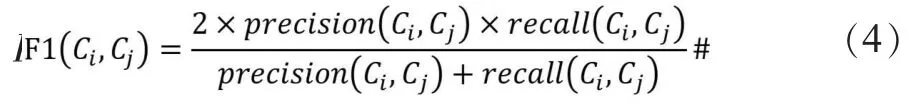
4.3 构建文本网络
首先,实验对文本进行LDA 主题模型训练,获取每个词条的向量化表达。其次,通过词条文本之间的余弦度计算,实验得到了初始的全连接文本网络。本实验假设余弦相似度在0.05 以下的词条主题语义相似度可忽略。因此,在实验数据集构建的网络中,删去对应连边,最终得到基础实验初始网络:含有300个词条节点,9 900 条连边的加权网络。初始网络中文本的主题相似度分布图5 所示。
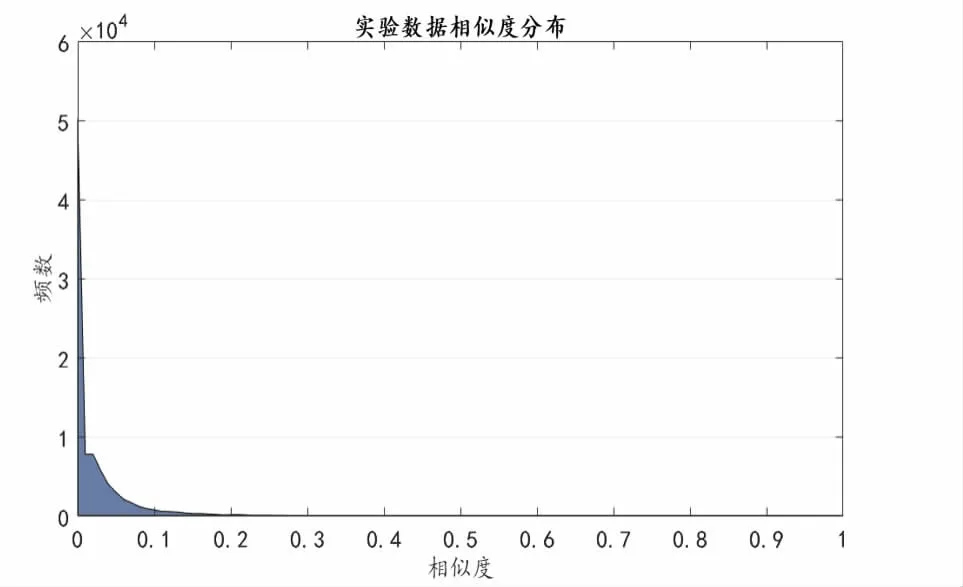
图5 实验数据分布说明Fig.5 Distribution of experimental data
为了验证取样的代表性,本实验对Wikipedia 所有词条进行随机抽样,得到3个抽样数据集。3个抽样数据集的词条量及主题相似度统计特征如表2 所示。从表2 可以看出,实验数据集与两组基于抽样数据集构造的网络的节点相似度分布差异不大。因此,本研究假设在实验数据集得到的测试结果可以很好反映出不同算法的性能。

表2 实验数据词条量及主题相似度统计特征Table 2 Entry numbers of experimental data and statistics of topic similarity features
4.4 社团划分结果
在实际应用中,初始阶段,实验需要给定一个主题,提供属于该主题的一个或一定数量的种子词条。在社团划分结果中,所有的词条都被划入了不同的社团。本研究选取与初始阶段提供的种子词条属于一个社团的词条的并集作为划分结果。该词条的集合被认为属于给定主题的学科领域。实验选用了每个学科领域名称的词条作为种子词条。例如5 号计算机社团选用Computer Science,则与该词条在划分结果中处于同一社团的词条均被划入该主题,即使得这些词条被划入计算机领域。
在模型参数设置时,本次实验选定最大社团数v为9。根据构建的词条网络,实验利用改进COPRA 算法,并选取集聚系数Q 值最大时的词条划分结果。集聚系数的最大保证其结果是当前算法下社团内部的连接是最紧密的。划分结果如图6 所示。其中,图6 中横坐标为标签,纵坐标为含有该标签的节点。横坐标相同的点被划分为同一社团。在实验中,横坐标标签0~49、50~99、100~149、150~199、200~249、250~299分别是已知核心分类为音乐、体育、数学、情报学、文学、计算机的词条。例如,图6 中红色和蓝色的色块交接处为与体育相关的核心词条。
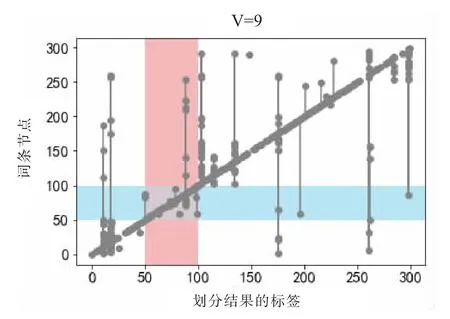
图6 文本划分结果Fig.6 Results of text classification
4.5 结果评价及说明
4.5.1 基础结果说明
表3 和表4 分别列出了改进的COPRA 算法和COPRA 算法在情报学领域及数学领域所获取有关词条划分的部分结果。从结果可以看出,相比COPRA 算法,改进COPRA 算法可以获得更好的结果。

表3 改进COPRA 算法及COPRA 算法在情报学领域获取的部分词条对比Table 3 Comparison of some entries obtained by the improved COPRA algorithm and the original one in theInformation Science field
图7、图8 和图9 呈现了改进COPRA 算法和COPRA 算法在6个不同领域上有关词条社团划分的精确度、召回率和F1 值比较分析。如图7 至图9 所示,对于音乐、体育、计算机领域的词条的社团划分,相比于COPRA 算法,改进后的算法在精确度、召回率和F1 值都得到明显改善,对文学领域词条的划分结果没有明显改善,但对情报学和数学领域的划分结果略有下降。
改进后的算法使得情报学和数学领域词条的社团划分的精确率和F1 值偏低。其原因在于该算法的领域划分结果比常用的领域定义相对较广。例如,在数据集中,数学、计算机和情报学领域存在较大程度交叉。即部分计算机领域词条被划入情报学和数学领域,如Computer Science、Virtual Education、SQL、Data ControlLanguage 等被划入情报学领域,而Atmospheric_Wave被划入数学领域。而对于文学领域的词条,改进后的算法的划分结果的F1 值没有明显的提高。这种情况表示,在所选数据集中,给予对应领域的词条增加“one more chance”的筛选过程并没有对划分结果有明显的影响。即在词条划分中,某些领域标签已被赋予较大权重,则不需要在较小的权重的领域标签内进行二次选择。此外,从6个领域的划分结果中可以发现,除文学和体育领域外,其他领域的划分结果均达到了较高的水平。这可能与文学、体育领域概念相对较为分散,相似度相对较低有关。

表4 改进COPRA 算法及COPRA 算法在数学领域获取的部分词条对比Table 4 Comparison of some entries obtained by improved COPRA algorithm and original one in Mathematics

图7 改进算法精确率的对比Fig.7 Comparison of precision of the improved algorithm
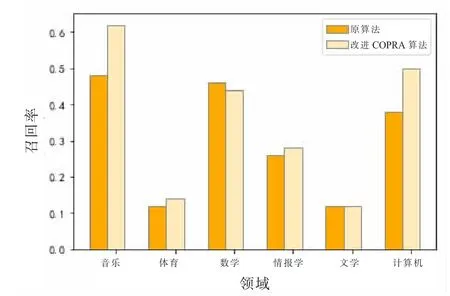
图8 改进算法召回率度对比Fig.8 Comparison of recall of the improved algorithm
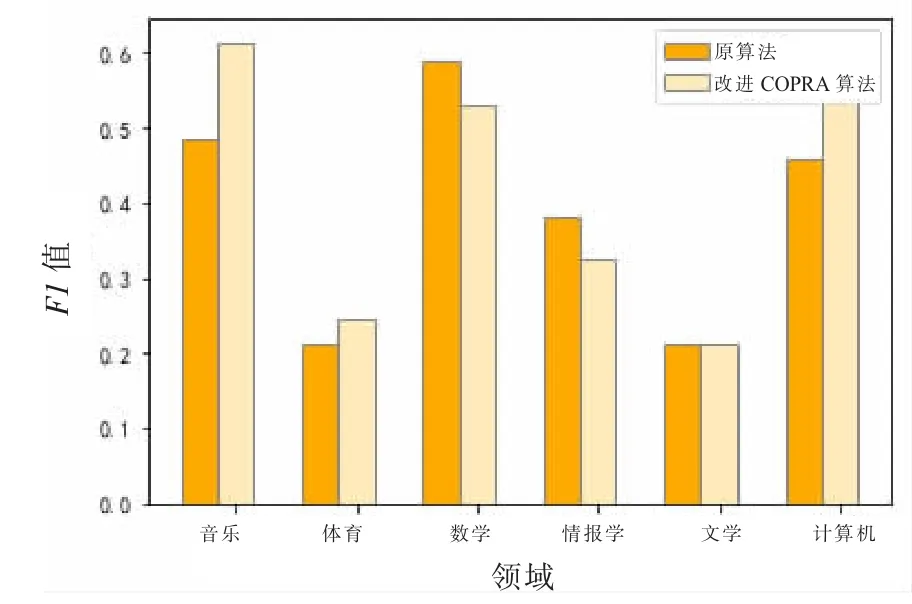
图9 改进算法F1 的对比Fig.9 Comparison of F1 of the improved algorithm
改进后的算法对于领域划分结果的集聚系数有明显提高,如图10 所示。从划分结果来看,改进算法解决了原算法过快收敛的问题,可以得到合理的划分结果,而不是大量的单节点社团,提升了分类器的性能。除了划分结果与学科的特异性有关之外,整体划分结果表现出学科领域的形态是基础学科范围扩张以及交叉学科内部聚合。例如,从划分结果中可以看出,尽管部分情报学的词条同时属于计算机科学和数学,但是依然存在大量概念是独立属于情报学的。此现象说明,在原有学科概念拓展和交叉的基础上,某些交叉学科具有一定的独立性。而在其发展过程中,此类交叉学科也会演化出自身的概念,并不仅仅是简单的对来自不同领域学科概念的融合。
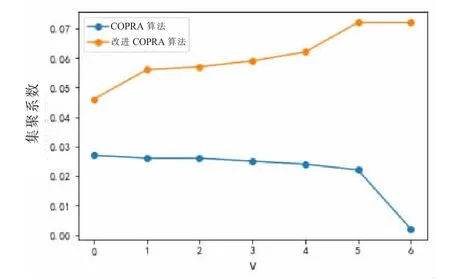
图10 改进算法集聚系数的对比Fig.10 Comparison of clustering coefficient of the Improved algorithm
4.5.2 参数敏感性分析
本章节在下面实验探讨最大社团v 和初始种子词条数等参数对结果的影响。
(1)最大所属社团v。改进的算法要预设每个节点所属的最大社团数v。利用6个领域的词条数据,实验分析了不同最大社团数对划分结果的影响。图11 表示了6个领域中不同的v 值对精确度和F1 值的影响。从图11 可以看出,随着最大社团数v 的增加,精确率和F1 没有明显的正相关关系。即是该参数的调整对结果没有显著影响。
(2)初始种子词条。本组实验将以情报学领域概念为例,分析初始种子词条数对结果的影响。图12 表示了不同初始种子词条数对领域划分的精确率、召回率、F1 的影响。
从图12 可以看出,初始词条的数量对领域词条的划分结果产生显著的影响。精确率和F1 值随种子词条数量的增加呈明显的上升趋势,但是召回率没有明显的正向变化。本实验将学科的核心的、具有代表性的、内容详尽的词条文本作为种子词条、增加词条数都可以提高算法的有效性。但增加词条数量的同时,新加入的词条本身可能属于不同的学科社团,降低了算法的召回率。
5 总结与展望

图11 不同最大所属社团数v 对各领域划分结果精确率和F1 的影响Fig.11 The influence of distinct maximum number of communities v on precision and F1 of divided results in different areas
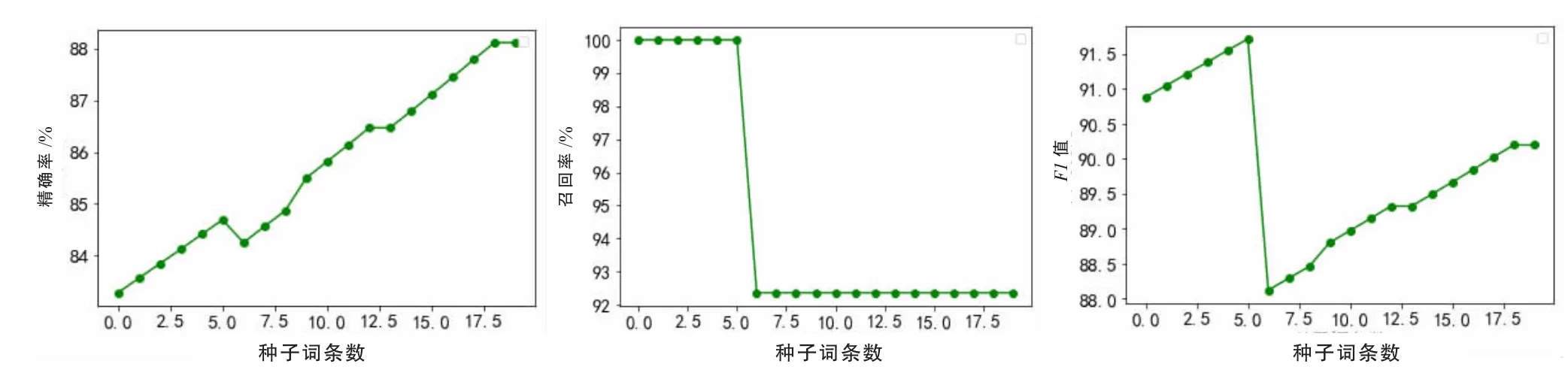
图12 初始种子词条数对结果精确率、召回率、F1 的影响Fig.12 The influence of original seed entries on the precision,recall and F1 of the results
本研究从复杂网络中社团划分的视角挖掘了词条相似度的相互作用。本研究通过构建主题文本网络和改进重叠社区标签传播算法,实现了学科领域的边界划分。其重点在于以网络的形式表现概念的内容和概念之间的相互作用,以网络的视角观察概念之间的结构,并最终以网络的方法划分海量概念的学科结构。本研究将复杂网络中相关算法的整体性、系统性引入文本语义分析中。这为文本的语义的分析引入新的方法。另外,本研究挖掘了词条网络的社团结构以及复杂性,以高效快速地在海量信息中获取与领域相关的概念,为构建相关学科知识库、自动化构建语料库等工作提供了有效的方法和思路。
在未来的工作中,相关研究可以将已有的基于各种特征的文本分析方法加入网络分析的框架中。这会为文本分析领域注入新的视角,以提升学科领域的划分性能。例如,本研究的工作重点在于利用网络分析方法对相同层级的学科词条做出划分。然而,各个学科领域是具有多个层级的。在标签传播等网络分析方法的基础上,如何结合文本分析方法并融入文本特征,实现词条的多层级自动分类、分析词条间潜在的拓扑关系等将帮助对知识文本的高效归档。同时,本研究对于算法的改进说明语义相似网络是具有其特异性的,不能直接搬用复杂网络的方法展开分析。如何有效地、合理地改进相关方法,使其适应于语义网络也是研究人员需要进一步分析探讨的。
猜你喜欢
阅读(中年级)(2022年9期)2022-10-08 01:56:16
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
军事文摘(2017年16期)2018-01-19 05:10:15
中学生(2016年13期)2016-12-01 07:03:51
知识经济·中国直销(2016年5期)2016-11-07 09:35:07
知识经济·中国直销(2016年4期)2016-11-07 09:34:04
公民与法治(2016年10期)2016-05-17 04:12:58
知识经济·中国直销(2016年10期)2016-02-27 16:16:54
计算机工程(2015年8期)2015-07-03 12:20:27
