
构建基于科技文献知识的人工智能引擎
2021-03-22 02:52:54张智雄于改红
农业图书情报学刊 2021年1期
张智雄,刘 欢,于改红
(1.中国科学院文献情报中心,北京 100190;2.中国科学院大学经济与管理学院图书情报与档案管理系,北京 100190;3.中国科学院武汉文献情报中心,武汉 430071;4.科技大数据湖北省重点实验室,武汉 430071)
1 引言
人工智能技术近年来取得飞速突破,尤其是在自然语言理解领域很多任务上都得到了广泛应用[1,2]。人工智能的基础是机器学习,机器学习解决问题的模式是使用算法分析数据,让机器去学习知识,机器自动归纳总结成模型,最后再让机器使用模型做出推断或预测。作为人工智能的核心技术,深度学习近年来取得飞速突破,真正发挥其优越性,根本原因在于拥有了大量可计算的数据资源和拥有了支撑大规模计算的计算能力。科技文献是科技知识的重要载体,蕴含着丰富的知识内容和知识关系,因此科技文献库(数字图书馆)是天然最好的人工智能(AI)语料库,这些隐藏于科技文献中的知识是人工智能的基石。
如何利用科技文献中的知识对深度学习算法模型进行训练改进,以获取知识、发现知识,是情报研究的重要课题。本文以文献情报工作为出发点,立足科技文献是人类知识的最重要载体,围绕如何充分挖掘和利用文献情报知识价值和作用,创新性提出了文献情报领域从“科技文献库”到“科技知识引擎”转变的建设思路,论述了中国科学院文献情报中心在构建基于科技文献知识的人工智能(AI)引擎的建设实践,探讨了利用深度学习技术挖掘知识以服务情报研究的方法,以期为同行提供参考。
国内外很多研究团队开展了大量的基于科技文献数据实现知识挖掘与知识发现的研究,为人工智能时代贡献了力量。如AllenAI 提出的SciBERT[3]通过对来自Semantic Scholar 的生物医学及计算机科学领域的科技文献完成大规模的自监督训练构建了英文科技文献预训练模型。清华大学发布的Aminer[4]学术搜索和挖掘系统通过对科技文献中实体及关系的进行建模构建了复杂的学术关系网络。但当前就如何利用科技文献中的知识对深度学习算法模型进行训练及改进,以获取知识、发现知识的研究仍处在初级阶段。围绕构建基于科技文献知识的人工智能(AI)引擎,本文第二部分论述了科技文献是人类知识的最重要载体,对其开发利用构建科技知识引擎,在人工智能时代具有重要意义;第三部分重点介绍了作者构建基于科技文献知识的人工智能(AI)引擎建设思路;第四部分,详细论述了中国科学院文献情报中心在构建基于科技文献知识的人工智能(AI)引擎的建设实践;最后简要进行小结和未来工作展望介绍。
2 相关研究分析
隐藏于各种数据资源(语料)中的知识利用和开发是人工智能飞速突破的本质所在。而科技文献作为人类知识的最重要载体,对其进行充分的挖掘和利用可以实现从“科技文献库”到“科技知识引擎”的转变,对于人工智能时代的发展具有重要意义。
2.1 知识的开发和利用是人工智能飞速突破的本质所在
机器学习的出现和发展历史悠久,神经网络的概念早在1943 年就被提出[5],谷歌的GNMT 翻译系统所使用LSTM 算法模型早在1997 年就由HOCHREITER等提出[6],1997 年SCHOLKOPF 等使用SVM 方法在美国数字邮政服务数据库上进行了测试,其识别错误率低至3.2%,远远超越了同时期LECUN 等提出的卷积神经网络方法[7]。人工智能研究取得突破性进展的背后,都是围绕着计算机学习知识、开发利用知识的模式改变。这些都明确告诉我们,对隐藏于各种数据资源(语料)中的知识利用和开发是人工智能飞速突破的本质所在,同时也体现了计算机解决问题3个模式的改变。
(1)改变之一:从传统计算机程序到机器学习。传统的计算机程序是人输入知识让机器完成任务,而在机器学习技术中,它变成了让机器学习知识,再让机器去完成任务。这一过程可以分为两个阶段:第一模型训练阶段(Training),利用标注好的数据语料来训练模型,形成解决问题的知识。第二模型预测阶段(Predication),解决问题阶段,利用训练好的模型(解决问题的知识),来解决类似问题。
(2)改变之二:从小样本机器学习到大规模深度学习。拥有大样本训练语料和大规模计算能力,使得基于人工神经网络的深度学习的知识学习性能大幅提升。深度学习方法是一种特定类型的机器学习技术,具有强大的能力和灵活性[8],它将机器学习技术提升到新的高度。如前文中提到的机器学习、深度学习、神经网络等概念和算法都是很早之前就出现过,但直到近年来,深度学习方法开始真正发挥其优越性。人工智能研究中取得重大突破,有两个重要的原因:第一,拥有了大量可计算的数据资源。随着互联网的发展和大数据时代的到来,数据更容易被收集管理,也更容易被整理成适合机器学习应用的数据集。当数据量增加到一定程度后,传统的机器学习算法在性能提升上并不明显,而深度学习算法由于具有大规模的参数,可以表达复杂的特征,其性能会随着数据规模增大而提高。谷歌的GNMT 翻译系统所用的英文法文数据集WMT En-Fr 含有36 000 000个句子对[4],在大数据集下,深度学习的优势得以凸显,其翻译水平接近人类水平。第二,拥有了支撑大规模计算的计算能力。随着训练样本的增加和模型复杂度的提升,计算量急剧增加,传统的计算架构无法支撑深度学习的计算需求,需要有更高性能的硬件设施。与CPU 相比,GPU 由于其并行计算技术非常适合大规模的矩阵运算,在速度上能带来2~3个数量级甚至更多的提升[9]。谷歌专门为机器学习应用开发的TPU,速度能加快到最高100P Flops(每秒1 000 万亿次浮点计算),华为公布的人工智能平台Atlas 900,其总算力达到256P~1 024P Flops。硬件的快速发展带来了计算能力的不断提升,为深度学习的发展提供了保证。
(3)改变之三:“预训练—微调”两阶段方法成为主流。近年来,基于预训练语言模型的深度学习方法,重写了自然语言处理的方式。特别是自Google AI团队2018 年发布Bidirectional Encoder Representations from Transformers(BERT)模型[10]以来,基于“预训练+微调”的两阶段模式,成为自然语言处理的主流。
在预训练(Pre-Training)阶段,通过对大规模无标注语料(如Wikipedia、BookCorpus 等)的无监督训练,有效学习文本的语言特征(如词法特征、句法特征、语法特征、上下文特征等),实现在深层双向神经网络中文本内容的深层向量表示,建立起相关领域的预训练语言表示模型;在微调(Fine-Tuning)阶段,在预训练语言模型的基础上,针对具体的下游任务(如文本分类、信息抽取、命名实体识别、自动问答、阅读理解等),以特定的经过标注的语料为输入,在模型上再加入一个输出层,在深度学习的基础上,实现具体的下游任务。
基于“预训练—微调”的两阶段模式颠覆了传统的自然语言处理方法。包括Google AI、Allen AI、Open AI、Facebook AI 等在内的多个人工智能研究机构凭借其数据资源及计算能力优势,都开展了预训练语言表示模型的研究,发布了ELMo[11]、GPT[12]、BERT[10]、GPT-2[13]、XLNet[14]、RoBERTa[15]等通用的英文预训练语言表示模型。这些模型相继刷新了通用语言理解评估基准GLUE[16]榜单,推动了自然语言处理的研究不断接近甚至超越人类。在中文语言模型的研究方面,国内多家机构也结合中文语言的相关特点,发布了中文的预训练语言模型。如百度发布的ERNIE1.0[17]和ERNIE2.0[18],哈尔滨工业大学与科大讯飞联合实验室发布的Chinese-BERT-wwm[19]以及清华大学发布的OpenClap[20]等。这些模型通过加入特定语料或者改造预训练任务的方式,生成了适用于中文的预训练语言模型,从而在各种中文自然语言处理任务上取得了新的突破。
2.2 科技文献是人类知识的重要载体
科技文献蕴含着丰富的科技知识,对其进行充分的挖掘利用可以实现从“科技文献库”到“科技知识引擎”的转变。人工智能(AI)需要语料来对模型进行训练,获取解决问题的知识,而科技文献中蕴含着丰富相关性知识和丰富语义知识,科技文献库就是很好的人工智能语料库。
而科技论文是科技知识的最重要载体,除了科技论文的研究主题和所属领域分类,还有很多更有价值的深层知识内容,如概念定义、研究背景、研究问题、研究基础、研究思路、论文中应用到的理论工具和方法、论文所进行的科学试验、得到的实验结果、形成的研究结论等丰富的知识内容。因此可将科技文献库蕴含的知识分为外部相关性知识和内部丰富的语义知识进行开发和利用。
(1)科技文献中的相关性知识。一篇科技论文具有很多外部的特征,比如作者、作者机构、期刊分类号、关键词等,这其中就隐藏着重要的知识关系,若我们利用文献内容与外部特征之间一一对应的结构化信息,将这些外部特征作为文献的标签,就可以形成较为成熟的人工智能训练学习语料。通过机器学习等技术手段建模,就可以实现面向新的文献数据的自动化应用。如谢玮等设计的基于TextRank 图算法思想的论文推荐系统,可实现自动为论文分配审稿人[21];王冬晖等提出的基于内容的科技论文推荐系统,可达到自动推荐期刊、会议的目的[22]。
(2)科技文献中的丰富语义知识。除了外部特征,一篇科技论文中还有很多更有价值的深层知识内容,如论文中出现的概念定义、用到的工具方法等,我们称之为丰富语义(Rich Semantics)知识。丰富语义相对于一般意义上的语义而言,它是由多类型语义元素有机组合在一起的复合体,具有结构化、模型化的特征。
许多国际知名学者和实验室正在尝试将丰富语义知识从文献中抽取和揭示出来,对科技文献的语篇元素建立了自动标注模型,我们开展了深入的调研研究[23],如SciAnnotDoc 模型[24]、CoreSC 模型[25]、AZ 模型[26]和Multi-Layer Scientific Discourse 模型[27]等。这些模型虽然由不同的任务驱动,但它们不仅在类别上具有相似的名字,在具体的标注范围也存在着交叉覆盖,基本上可以概括为研究目标、研究背景、研究方法、研究发现、研究结论以及包含科技文献中对关键术语的研究定义。
当前的预训练模型和应用,主要是基于网页新闻、维基百科等数据实现模型的预训练。由于科技文献具有特定的结构、格式、用语、用词等特征,这些预训练模型在支持科技文献的挖掘利用方面还存在不足,因此本文基于科技文献开展人工智能挖掘应用具有重要意义。
3 基于科技文献知识的人工智能AI引擎建设思路
为充分挖掘隐藏着丰富知识内容的科技文献资源,实现从“科技文献库”到“科技知识引擎”的转变,本文提出构建基于科技文献知识的人工智能(AI)引擎的基本思路,如图1 所示。从“预训练—微调”两阶段模式出发,首先以大规模的科技文献资源、科技信息文本等为基础,构建中国科技论文预训练模型(CsciBERT)。然后在预训练模型的基础之上,以“微调”的方式,结合科技文献数据中丰富的标记语料,构建基于科技文献知识的AI 引擎。

图1 基于科技文献知识的人工智能AI 引擎建设思路Fig.1 Ideas for building the AI engine based on knowledge in scientific and technological literature
3.1 中国科技论文预训练基础语言模型(CsciBERT) 建设思路
本文对基于BERT 的预训练模型整体结构进行研究,总结预训练模型主要包含4个层次:输入层(Input)、嵌入层(Embedding)、网络层(Transformer Encoder)和目标层(Target)。针对每一个层次,开展了优化和改造研究,提出了中国科技论文预训练基础语言模型(CsciBERT)建设思路,如图2 所示。
输入层:主要对应预训练语料库的构建工作,充分发挥文献情报中心科技文献原始数据优势,丰富语料。BERT 原始中文模型BERT-base-Chinese 采用了中文维基百科语料,对于本文中文科技文献预训练模型,收集整理的预训练数据语料包括:①CSCD 中文科技文献摘要;②中文科技论文全文;③特定领域网络科技信息文本;④特定领域相关图书文本;⑤特定领域相关术语词表、知识库等。在此基础上构建研究全领域预训练语料库及生物医学、物理学、化学领域的预训练语料库。
嵌入层:主要用于原始语料的特征描述,在BERT 基础上,通过加入领域词表和POS 标签融合更多外部知识特征。
网络层:由复杂的Transformer 神经网络构成,实现自动学习。通过改进Mask 矩阵完善Transformer 中的注意力学习机制,提升学习效果。
目标层:通过设计语言模型训练目标完成模型训练,针对不同的语料特点,设计多种训练目标,完成多任务学习。
基于上述建设思路,可以利用不同的预训练语料,产出不同的模型输出,构建不同的预训练语言模型,如通用的科技论文预训练语言模型(CsciBERT)及生物医学、物理学、化学等特定领域的预训练语言模型CMedBERT、CMedBERT、CPhyBERT、CChemBERT。
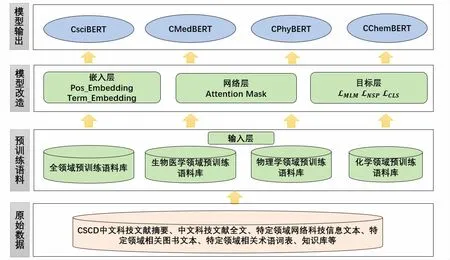
图2 中国科技论文预训练模型(CsciBERT)设计框架Fig.2 The design framework of Chinese sci-tech papers pre-training model(CsciBERT)
3.2 基于科技文献知识引擎建设思路
通过“微调”的方式,针对知识服务工作的实际需求,将构建好的预训练语言模型应用于不同的下游任务中,如可以将文献服务工作中的审稿人推荐、期刊投稿推荐、文献自动分类等应用作为预训练模型的下游任务,形成相应的微调模型,进一步形成基于科技文献的知识引擎。
如图3 所示,科技文献数据中丰富的科学知识很容易转化为机器学习的标记语料。通过构建文献—作者、文献—期刊、文献—机构、文献—分类号、文献—关键词、摘要—语步、语句—定义等对应关系,可以形成深度学习的训练语料。以预训练语言模型为起点,在模型上加入一个分类层,用“微调”的方式形成相应的深度学习模型。采用微服务等架构,可以实现模型的快速调用。从而对于任意的科技文献,可以提供审稿人、分类号、期刊等实时推荐接口,从而建成面向实际应用的科技文献知识引擎。
4 基于科技文献知识的人工智能(AI)引擎建设实践
围绕上述设计思路和设计方案,团队开展了具体的项目实践。如图4 所示,分别在科技论文摘要语步识别、科技文献自动分类、科技论文命名实体识别、科技论文概念定义句识别、科技论文关键词识别、科技文本标签自动生成、科技论文投稿期刊自动推荐、科技期刊审稿人自动推荐等8 项任务应用中开展引擎建设实践。针对每一项任务分别构建了科技文献知识引擎微调模型,并对微调模型完成封装调用,初步建成基于科技文献知识资源的AI 引擎服务平台,提供网页客户端和API 服务接口两种对外服务模式。下边分别介绍引擎微调模型实践和AI 引擎服务平台实践。
4.1 科技文献知识引擎微调模型实践
4.1.1 科技论文摘要语步识别
在研究型论文摘要中,通常需要指出文章的研究目的、方法、结果和结论,笔者将这些语言单元称为科技论文摘要中的语步[28]。自动识别科技文献摘要中的语步信息,有助于读者快速掌握文章的主要内容,在科技文献的检索与发现系统中也具有重要应用价值。
我们提出Masked Sentence Model[29]来解决语步自动识别问题。通过改造BERT 输入层,将摘要中句子的内容特征与上下文特征有效结合,在语步识别实验中取得了较好的效果。使用PubMed 20K RCT[30]语料集,其中训练集包含20 000 篇摘要,验证集和测试集各包含2 500 篇摘要。按照Masked Sentence Model 的思想,将数据集构造如表1 所示。
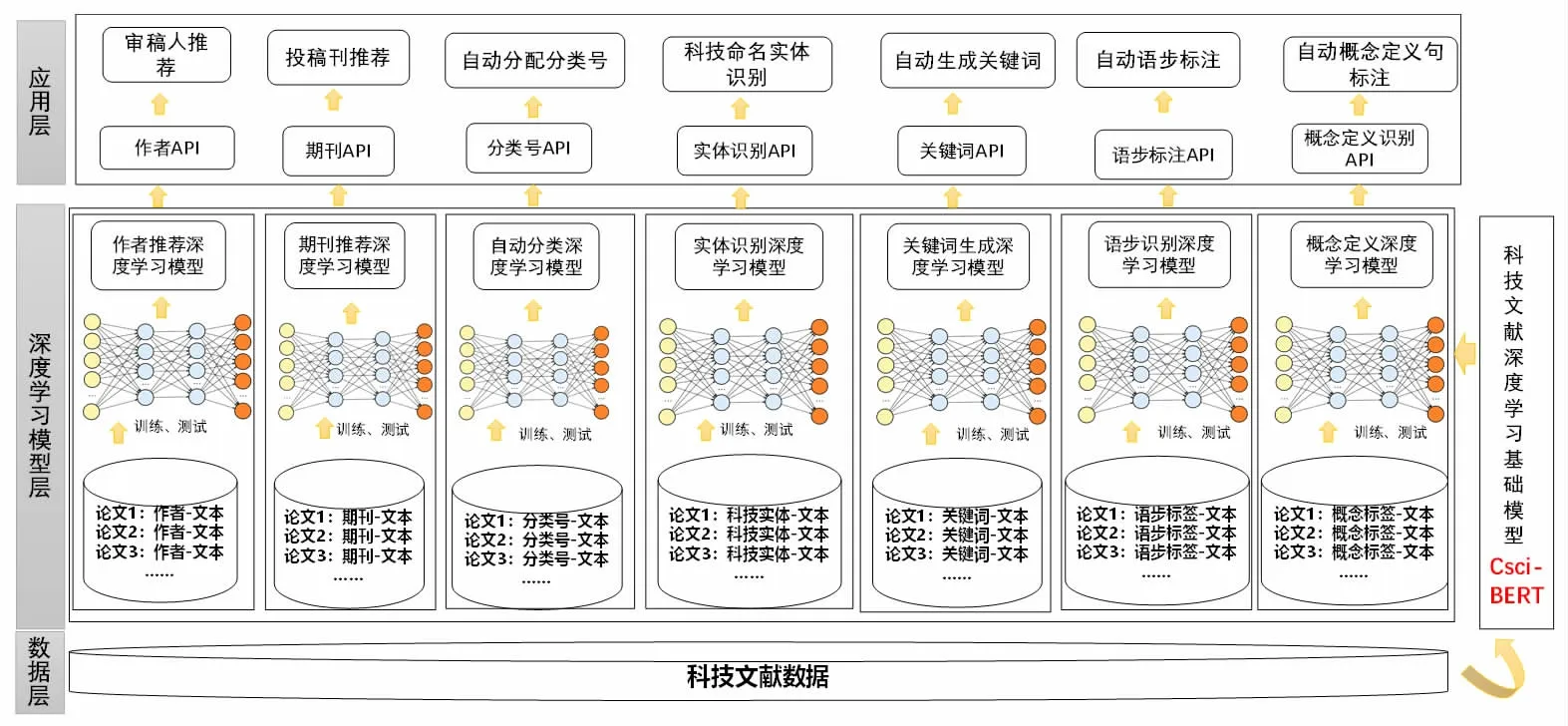
图3 基于科技文献知识的AI 引擎设计框架Fig.3 The design framework of the AI engine based on knowledge in scientific and technological literature

图4 基于科技文献知识的人工智能AI 引擎建设实践内容Fig.4 Content of AI engine construction based on knowledge in scientific and technological literature

表1 Masked Sentence Model 语料示例[29]Table 1 Examples of Masked Sentence Model in our corpus[29]
其中,对于摘要中每一个句子,将其本身作为内容特征,将完整摘要中除目标句之外的所有句子作为该句子的上下文。在上下文特征的表示中,将目标句用统一的替换字符串“AAA”代替,然后将处理后的摘要内容作为该句子的上下文特征输入到模型。
表2 为Masked Sentence Model 的实验结果。其中Step1 表示仅输入句子内容特征(与BERT Fine-Tuning分类的输入一致),Step2 表示仅输入句子上下文特征,Step3 表示合并两种特征的输入方式,即Masked Sentence Model。实验结果表明,Masked Sentence Model模型在PubMed 20K 数据集上取得了91.5 的F1 值,相比BERT fine-tune 方法,提升5.04,接近该数据集上的最好效果模型HSLN-RNN[31]。

表2 Masked Sentence Model 实验结果Table 2 Experimental results of Masked Sentence Model
4.1.2 科技文献自动分类
基于中图分类法构建了中文科技文献的多层级分类模型[32],如图5 所示。通过两层的分类模型实现医学领域112个类别划分:先构建第一层大类分类模型(First Level),用于预测16个医学二级类目(R1-R9)大类分类结果。然后对每个一级大类构建第二层分类模型(Second Level),进一步细分,预测医学三级类目(R11-R99)。
针对每一个分类模型,利用科技文献摘要及分类号构建映射关系,构建用于模型微调的数据集。数据示例如表3 所示。
在人工构建的测试集上对两层分类模型完成测试,同时对比了单层分类(训练一个模型,直接预测112个医学三级类目)的实验结果,结果如表4 所示。实验结果表明,BERT 两层分类模型相比单层分类方法,效果提升4.39%。
4.1.3 科技命名实体识别
通用领域的命名实体识别中实体类别一般包括人名、地名、机构名等,在科技文献中存在更丰富的实体类型值得挖掘利用,例如工具模型、方法理论等。针对物理学领域,构建科技实体识别体系。利用物理学本体ScienceWISE 构建了物理学领域实体的范畴体系,包括一级范畴4个,二级范畴47个。一级范畴包括:计量、仪器和数据分析、现象和现象规律、模型、方法理论和数学,二级范畴包括量子力学、核物理学、理论宇宙学等。利用该范畴体系,借助预训练模型微调,实现了物理学领域细粒度的科技命名实体识别。

表3 中图法医学层级分类数据示例Table 3 Medical record examples based on the Chinese Library Classification
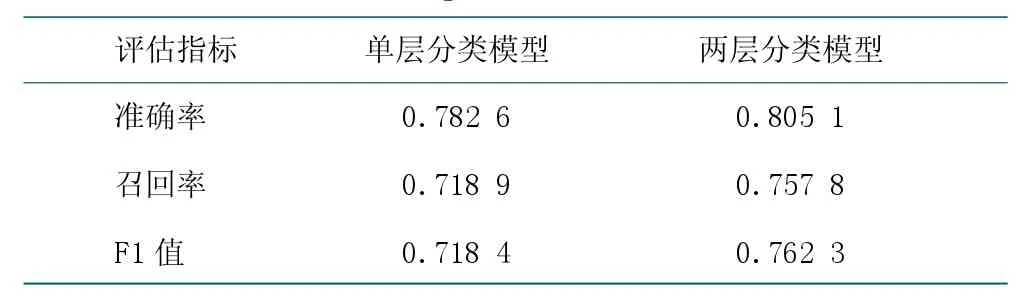
表4 医学领域层级分类实验结果Table 4 Classification experiment results of medical records
研究将物理学领域科技文献摘要及其ScienceWISE范畴构建为BIO 格式标注语料(对语料中的每个单词进行标记,B 表示某实体开头的单词,I 表示实体内部的单词,O 表示实体外部的单词),作为模型微调的数据集。其中训练集90 000 条,测试集2 000 条。数据示例如表5 所示。
研究对一级范畴和二级范畴的模型识别结果分别统计,实验结果如表6 所示显示,模型在一级和二级范畴的识别F1 值均达到90%以上。
4.1.4 科技论文关键词识别

图5 基于中图分类法的多层分类模型Fig.5 Multi-layer classification model based on the Chinese Library Classification

表5 科技文献命名实体识别数据样例Table 5 Samples of named entity recognition data in scientific and technological literature
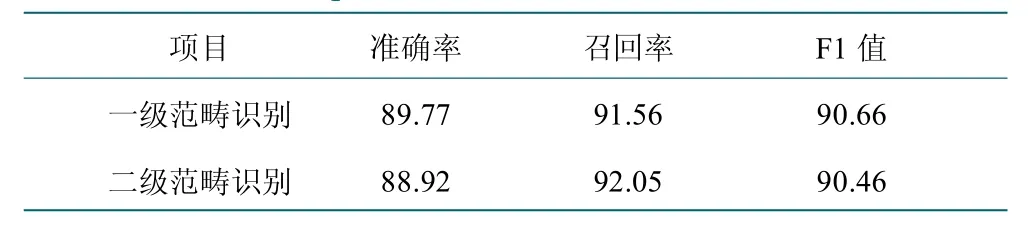
表6 命名实体实验结果Table 6 Experimental results of named entities
关键词抽取任务指从文本中抽取重要的主题短语,是信息检索、文本摘要、文本分类、意见挖掘和文档索引的基础。在科技文献中,从摘要原文中自动抽取几个关键短语,作为该文献的关键词。将其定义为字级别序列标注问题,利用BERT 模型微调构建科技论文关键词识别模型[33]。
我们将科技文献摘要与关键词数据进行整理,以BIO 方式构建模型微调数据集。选择100 000 条记录作为训练数据集,6 000 条记录作为评估集,3 094 条记录作为测试集,数据示例如表7 所示。
对比传统无监督的TF-IDF[34]方法以及基于深度学习序列标注的BiLSTM-CRF[35]方法。基于字级别序列标注的微调模型取得最佳效果,结果如表8 所示。

表7 关键词识别模型数据集示例Table 7 Sample dataset of the keyword recognition model
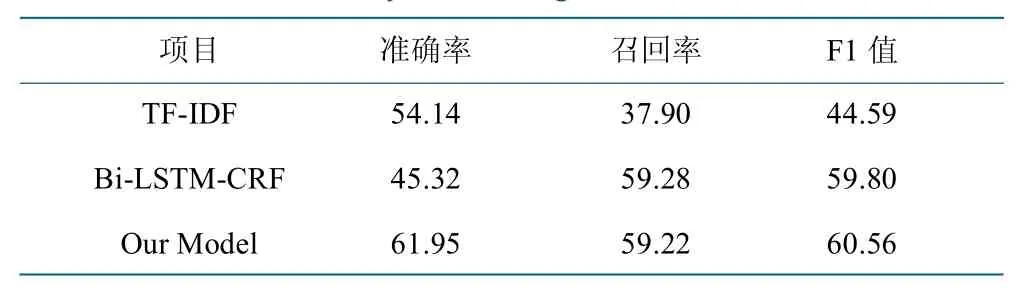
表8 关键词识别模型微调实验结果Table 8 Experimental results of the fine-tuned model of keyword recognition
4.1.5 科技论文概念定义句识别
概念定义句识别任务为自动识别科技文献中表达概念定义的句子。将其作为一个二分类问题,利用预训练模型微调的方式构建概念定义句自动识别模型。
首先基于科技网站、维基百科等收集整理了8 000个概念数据和非概念句子,作为训练集,以BERT Fine-Tuning 方法构建二分类模型,数据示例如表9 所示。

表9 概念定义句识别数据示例Table 9 Sample sentences that contain a concept or a definition
在结果测试时,同时使用了统一WCL 定义句识别数据集[36]对我们的方法进行测试,结果如图表10 所示。结果表示,我们的方法在定义句识别任务中达到0.926 的F1 值,远远超越了WCL 原始测评方法的效果。
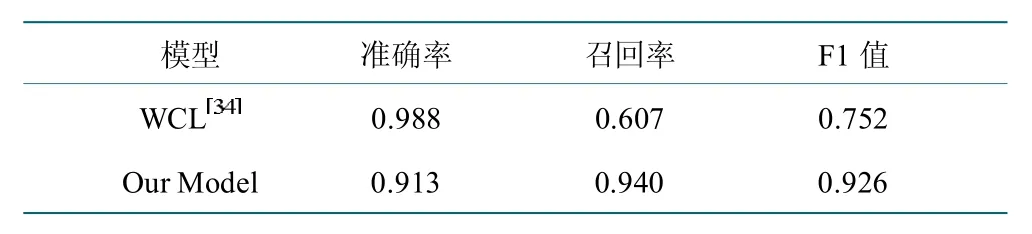
表10 WCL 数据集测评结果Table 10 Test results of the WCL dataset
4.1.6 科技文本标签自动生成
科技文本标签自动生成旨在为科技文本内容生成标签,以反映文本的主要内容。在科技文献中,利用摘要内容,自动生成一个新的短语概括文献内容,作为其文本标签。使用基于BERT 的生成式模型UniLM[37],以序列到序列(Seq-to-Seq)模式,进行文本生成模型的微调实验。
研究将科技文献的标题作为其摘要的文献标题,构建文献标题生成的数据集,如表11 所示。提取全领域中文科技论文的摘要及标题,共计50 万条来完成微调模型的训练。
在结果测试时,随机抽取了部分科技文献摘要完成测试。通过对比原论文题目(图6)和模型生成的标题(图7),发现模型自动生成的标题能够完成对论文原始摘要内容的概括,与原文标题也比较相似。
4.1.7 科技论文投稿期刊自动推荐
科技期刊审稿人自动推荐旨在根据科技论文摘要内容,自动推荐若干与该论文相关的领域专家作为候选审稿人。这项任务可快速帮助期刊编辑部发现和找到合适的审稿专家,加快审稿速度,提升审稿质量。
同样以文本分类模式,基于78 万篇科技文献和4万多位作者构建审稿人自动推荐数据集,将标题和摘要作为输入文本,作者作为分类标签,语料示例如表12 所示。

表11 科技文本标签自动生成数据集示例Table 11 Sample dataset of automatically generated text labels

表12 审稿人自动推荐语料示例Table 12 Examples of automatic recommendation of reviewers based on a paper's abstract

图6 科技论文原始题录信息示例Fig.6 An example of journal article metadata
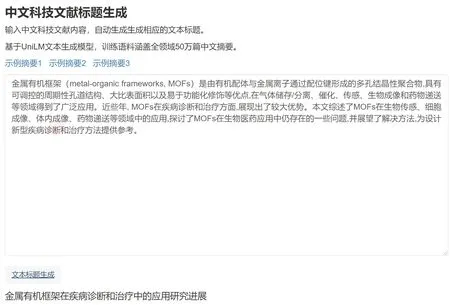
图7 科技文本标题生成实际效果展示Fig.7 Actual effect of the generation of a text title
针对微调模型,笔者随机抽取部分科技文献摘要完成测试,结果示例如图8 所示。我们发现,对于大多数文献,模型都能推荐出相关性较高的审稿人。
4.1.8 科技期刊审稿人自动推荐
科技论文投稿期刊自动推荐旨在根据科技论文摘要内容,自动推荐若干与该论文相关的期刊作为候选投稿期刊,可帮助科研人员快速找到合适的期刊。

图8 审稿人自动推荐实际效果展示Fig.8 Actual effect of automatic recommendation of reviewers
以文本分类模式,基于科技文献摘要及期刊信息构建投稿期刊自动推荐数据集,标题和摘要作为输入文本,期刊作为分类标签。语料示例如表13 所示。其中包含全领域的文献摘要2 729 244 篇,候选投稿期刊类型共计1 585 种。
针对微调模型,随机抽取部分科技文献摘要完成测试,结果示例如图9 所示。我们发现对于大多数文献,模型都能够推荐出相关性较高的期刊。
4.2 科技文献AI 引擎服务平台实践
为推动科技文献知识引擎在文献情报工作中的实际应用,初步建成科技文献AI 引擎服务平台。如图10所示,平台架构主要包含3个层次,模型封装层:以BERT-AS-SERVICE 工具将微调模型封装,形成底层模型微服务;Web 响应中间件层:基于Python 语言的FLask+Tornado+Nginx 架构形成Web 响应架构,实现反向代理、动静分离、负载均衡;引擎服务层:AI 引擎对外提供两种形式服务,包括网页端在线标注和API 接口服务。
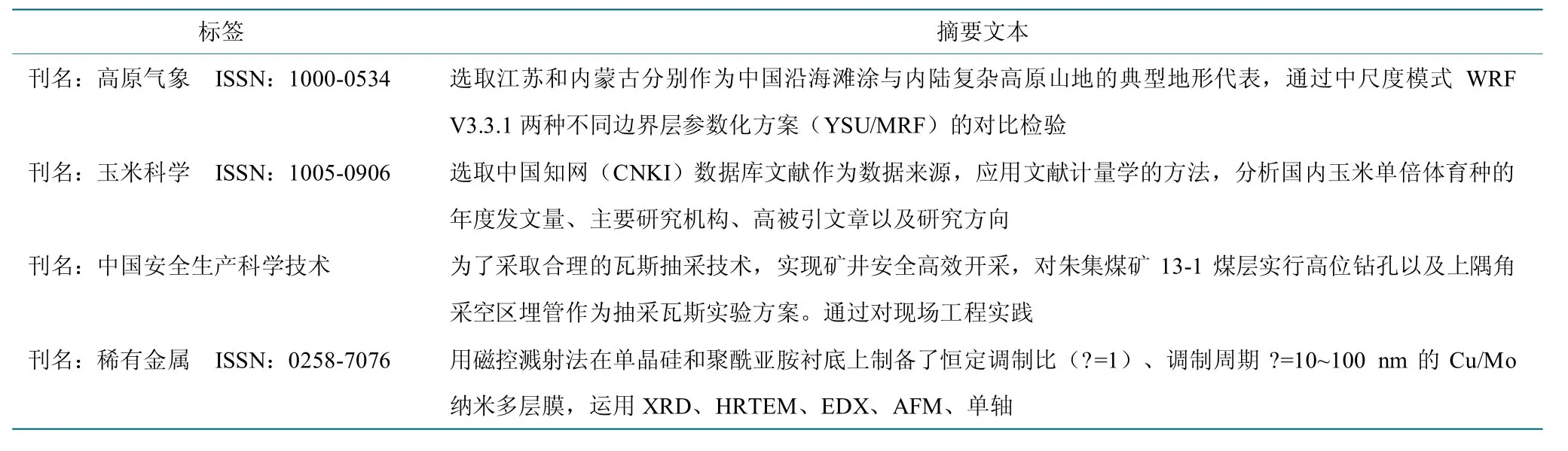
表13 投稿期刊自动推荐语料示例Table 13 Examples of journal recommendation based on a paper's abstract

图9 科技论文投稿期刊自动推荐实际效果展示Fig.9 An example of automatic journal recommendation
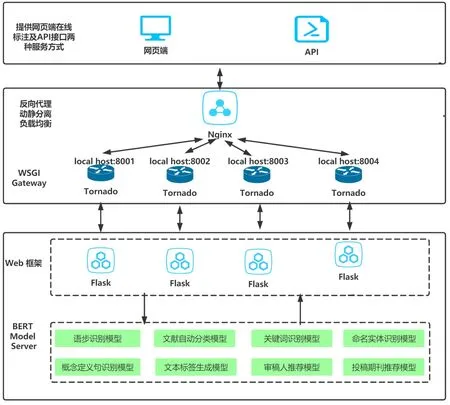
图10 科技文献AI 引擎平台架构图Fig.10 AI engine platform based on scientific and technological literature
4.2.1 底层微调模型优化调用实践
针对实际应用,对知识引擎模型加载和调用过程进行优化。
一方面,使用Freeze_Graph 工具完成微调模型的固化压缩,将原有的1.22GB 的.ckpt 模型文件压缩到为417MB 的.pb 文件,大大缩减了模型的空间占用。
另一方面,参考Web 服务快速调用的模式,利用BERT-AS-SERVICE 工具,在应用端和BERT 模型服务端之间构建起中间件微服务端,实现模型的预加载,并通过实时服务端口提高调用效率。
通过上述两种优化方式,对单篇摘要的标注平均时间从原来的10 秒缩减为1 秒,明显提升了系统响应效率。
4.2.2 网页端在线标注服务实践
提供上述所有应用的在线标注服务(http://sciengine.whlib.ac.cn/)。通过在网页端输入任意科技文本,系统将自动调用相应的微调模型,完成模型预测,返回实时的标注结果,如图11 为其中一种应用,语步识别在线标注服务示意图。
4.2.3 API 接口服务实践
同时提供基于GET 和POST 两种方式的API 接口服务。
GET方式支持单篇文档,如图12所示,url 为http://sciengine.whlib.ac.cn/Move_GET,传入英文摘要文本,以json 格式返回该摘要的语步标注结果。
POST 方式支持多篇文档,如图13 所示,url 为http://sciengine.whlib.ac.cn/Move_POST,将多个摘要文档以list 类型上传,以json 格式将多篇摘要标注结果放在列表中返回,其中每篇摘要标注结果格式与上述GET 方式一致。
5 总结与展望

图11 语步识别在线标注服务示意图Fig.11 A diagram of move recognition in an abstract

图12 GET 方式访问示例Fig.12 An example of GET access

图13 POST 方式访问示例Fig.13 An example of POST access
本文以文献情报工作为出发点,探究人工智能取得飞速突破的本质所在,立足科技文献是人类知识的重要载体,围绕如何充分挖掘和利用文献情报知识价值和作用,创新性提出了文献情报领域从“科技文献库”到“科技知识引擎”转变的建设思路,论述了中国科学院文献情报中心在构建基于科技文献知识的人工智能(AI)引擎的建设实践,初步取得了一定效果和成果,但仍存在很多问题和挑战,在接下来的工作中将进一步完善和改进。首先,鉴于语料收集整理工作不充分,下一步会进一步收集、整理预训练语料库,尤其是特定领域科技文献全文、书籍、知识库、术语词表等。其次,应用推广工作待完善。进一步完善基于科技文献知识资源的AI 引擎平台建设,完善相关功能,提升平台运行效率,完善对外服务API 接口建设,尽快正式发布基于科技文献知识的人工智能(AI)引擎。最后,实际应用效果待提升。基于科技文献情报工作的实际应用场景,进一步实验、测试模型的应用效果,根据实际情况调整相关研究的改进方向,形成实际可用、有效的工具化的模型。
猜你喜欢
电线电缆(2018年2期)2018-05-19 02:03:44
家庭影院技术(2017年10期)2017-11-23 03:35:51
商周刊(2017年22期)2017-11-09 05:08:31
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
河南电力(2015年5期)2015-06-08 06:01:46
皖西学院学报(2015年5期)2015-02-28 17:52:46
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
教育科学论坛(2014年8期)2014-03-01 04:01:54
