
基于知识图谱的逻辑验证码方案*
2021-03-21 04:34盛超逸
通信技术 2021年2期
盛超逸,易 平
(上海交通大学,上海 200240)
0 引言
互联网发展之初是为了将不同的服务提供给大多数用户。服务提供商的目的是想让目标用户能够定位这些资源的位置并且合理访问它们[1]。而自动化脚本和恶意程序对这些资源的访问,使得资源被浪费,同时降低了系统性能,造成合法用户的请求难以得到响应[2]。完全自动化区分计算机和人的公共图灵测试(Completely Automated Public Turing Test to Tell Computers and Humans Apart,CAPTCHA)即验证码的出现,给互联网安全构建了一道保护屏障[3-4]。它通过引入一个对人类来说较为简单但对于机器却非常困难的测试,可以在提供服务之前将恶意程序和自动化脚本排除在外。一个好的验证码方案应该具有这样的特点:人类通过测试的成功率在90%以上,但是计算机程序只有小于1%的成功率[5]。
主流的验证码方案可分为基于文本的验证码方案、基于语音的验证码方案和基于图片的验证码方案[6]。文本验证码通常由大小写英文字母和阿拉伯数字组成,且会在组合的基础上对其进行复杂的形变、旋转或者添加噪声等方式来增加机器识别的难度。但是,很多针对文本验证码的攻击也被提出,威胁了现有文本验证码的安全性。早期简单文本验证码如谷歌、雅虎和微软等公司部署的验证码方案已经被攻破[7-8]。于是,研究者把视线投向图像验证码。他们认为,人类识别和描述图像的过程非常自然,但对机器而言却是一项很复杂的任务[9]。谷歌reCAPTCHA[10]就是这样一种典型的图像验证码,如图1所示。它通过给出一个关键词wine和一张示例图片,让用户从9个候选图片中选出所有与示例相似的图片。然而,随着深度学习的发展,神经网络在图像分类等领域的准确率已经接近甚至超越人类的水平[11-12]。通过神经网络对候选图片进行图像分类,再选出标签为wine的图片,可以轻易攻破reCAPTCHA方案。如图2所示,深度验证码(DeepCAPTCHA)是在reCAPTCHA的基础上,利用对抗样本(Adversarial Example)会使神经网络分类出错的特性,通过在主图片昆虫中添加对抗噪声,使得深度学习模型分类错误[13-14],从而无法在12个备选图片中选择正确的图片。然而,DeepCAPTCHA方案却没有考虑基于图像相似性搜索来获取图像标签的可能,通过对主图片进行图像相似度搜索来获得其标签,再比较它与备选图片的标签之间的语义相似程度,即可以攻破DeepCAPTCHA。

图1 谷歌reCAPTCHA验证码挑战

图2 DeepCAPTCHA挑战
容易被神经网络获取标签和直接比对标签的语义相似性方法破解,是传统图像验证码存在的固有安全问题。为了解决图像验证码的这一安全问题,本文提出了一种新的基于知识图谱的逻辑验证码算法。它通过增加逻辑推理的环节来对图像验证码进行防御。不同于传统的图像和文本的验证码算法的工作流程,如图3所示。它添加了利用人类的智能可以进行联想和推理的环节,而这些是机器和深度神经网络无法做到的。它侧重基于逻辑事实的推理并同时兼顾语义标签和文本信息的保护。本文提出的逻辑验证码基于常识知识图谱ConceptNet,通过选取其中的一条常识知识生成验证码。用户则需要根据验证码中给出的多个词组描述进行逻辑推理,并在添加了对抗噪声的候选图片中选择与推理结果最贴近的图片,如图4所示。

图3 传统图像验证码工作流程

图4 逻辑验证码工作流程
其中,添加根据人类所具有的常识知识设计的逻辑推理环节,能够使得在分类与回归两大问题上大有作为的人工神经网络黯然失色。通过研究用户的使用发现,逻辑验证码算法具有很高的可用性和安全性。实验表明,逻辑验证码的操作简单、耗时短且准确率高。对于4个提示词和6张候选图的组合,参与者可以在5 s以内完成验证码测试,并且通过率高达95%。对于暴力破解的方法,如果候选图中有两张符合答案的图片,没有决策依据的机器进行暴力破解只有1/15的成功概率。即使神经网络能够对候选图片进行正确分类并获取其标签,通过比较与给出的描述词组的语义相似度来进行攻击,也只能达到4.5%的通过率。
本文结构如下:第1节介绍文本和图像验证码的相关研究工作;第2节主要介绍逻辑验证码的方案;第3节进行了一些实验探究验证码设计的关键问题——图像数量、提示词选择以及分析其安全性;第4节总结和展望未来验证码安全的思路与方向。
1 相关研究
验证码最早诞生于20世纪中期,是由英国数学家阿兰·图灵制定的用于区分机器反应和人的反应。如今,人们在访问网站、登录邮箱等情况下都会先完成一个验证码测试,才能继续进行后续操作。为了区分正常访问的用户和恶意的计算机程序,验证码在今天已经衍生出多种多样的形式。最主要的3种形式是文本验证码、语音验证码和图片验证码,保护着人们信息的安全和网站资源的安全。然而,在人工智能飞速发展的今天,这些验证码也面临着各种各样的攻击,其安全性问题不容忽视。
基于文本的验证码容易设计与实现。它从字典中随机选取字母和数字进行扭曲组合,用户识别并提交这个组合。在这个词组的组合上,可以使用网格、添加噪声以及更改颜色等方式来对验证码文本进行失真操作。由于光学字符识别(Optical Character Recognition,OCR)和图像处理算法的进步[15-16],基于文本的验证码已经不能保证其验证的有效性。Kumar指出,衡量文本验证码的鲁棒性应该是从CAPTCHA图像分割字符的困难程度判断,而不是识别每个字符是什么,因为强大的深度学习网络如卷积神经网络(Convolutional Neural Networks,CNN)可直接识别旋转或扭曲的字符。在此基础上,Guixin Ye等人提出了基于生成式对抗网络(Generative Adversarial Network,GAN)来破解文本验证码[17],包括微软、维基百科、eBay和谷歌等50个网站中正在使用的11个验证码方案,且能够做到在使用桌面GPU的情况下以0.05 s的速度完成一个验证码测试。音频验证码的出现给视力障碍人士提供了一种新的选择,通过文本语音合成器形成一段包含字母数字组合的音频,通过听写给出正确的答案。随着AI技术在自然语言处理领域的发展,音频验证码也容易被攻破。
基于图像的验证码利用了人类对图像内容的认知水平。Elson等人提出了Asirra,要求用户从一组12张包含猫和狗的图片中选取猫的图片,数据集来源于Petfinder.com。目前最广泛使用的是谷歌提供的reCAPTCHA,包含多个版本,其中图像reCAPTCHA是让用户来识别具有相似内容的图片,每个问题包含1个提示关键词、1个样例图像和9个候选图。在深度学习未使用GPU进行加速前,机器识别图像的内容是一件很难完成的事情,需要很强的计算能力。随着GPU架构升级和并行处理性能的增强[18],深度学习进入了飞速发展应用的时代,神经网络层数不断加深,Resnet的出现使得训练一个具有几百层结构的网络模型成为可能。卷积神经网络通过输入层、隐藏层和输出层不断提取图像中的特征,引入激活函数使得网络具有非线性性质,利用反向传播算法对网络权重参数进行不断更新优化,使得最终的分类结果更为准确。
深度学习的发展给图像验证码的安全性提出了全新要求,而对抗样本的出现则为Margarita Osadchy等人设计出深度验证码(DeepCAPTCHA)提供了契机。他们通过引入不可变对抗噪声对图像进行加工使之成为对抗样本,使得图像能够抵抗诸如去噪等移除图片中对抗噪声的尝试,使得图像验证码对深度学习模型有一定的抵抗能力且有较高的安全性。但是,尽管对抗样本具有一定的迁移性,经过对抗训练的神经网络仍可以识别对抗样本,且随着网络模型结构的改变和在不同数据集上进行训练,生成好的对抗样本也可能失去欺骗效果,会导致深度验证码在未来不断更新时的代价变高。同时,它要求生成验证码的图片集无限大(bottomless)且尽量未公开,用完即丢弃,会提高验证码的生成成本。
本文提出的验证码并不需要图片集无限大,也无需使用后丢弃。用户获取提示词所给的部分信息,凭借自己的生活经验和常识等进行合理推断,并在候选图像中选择与自己所想内容符合的图片作为最终的答案即可。
2 验证码方案设计
本文的目标是设计一种基于知识图谱的逻辑验证码方案。验证码设计的整体过程包括随机选取实体、选择与实体相关的常识描述、生成验证码文本、从图库中选择候选图片、生成对抗样本和生成一组逻辑验证码挑战等。方案设计流程如图5所示。
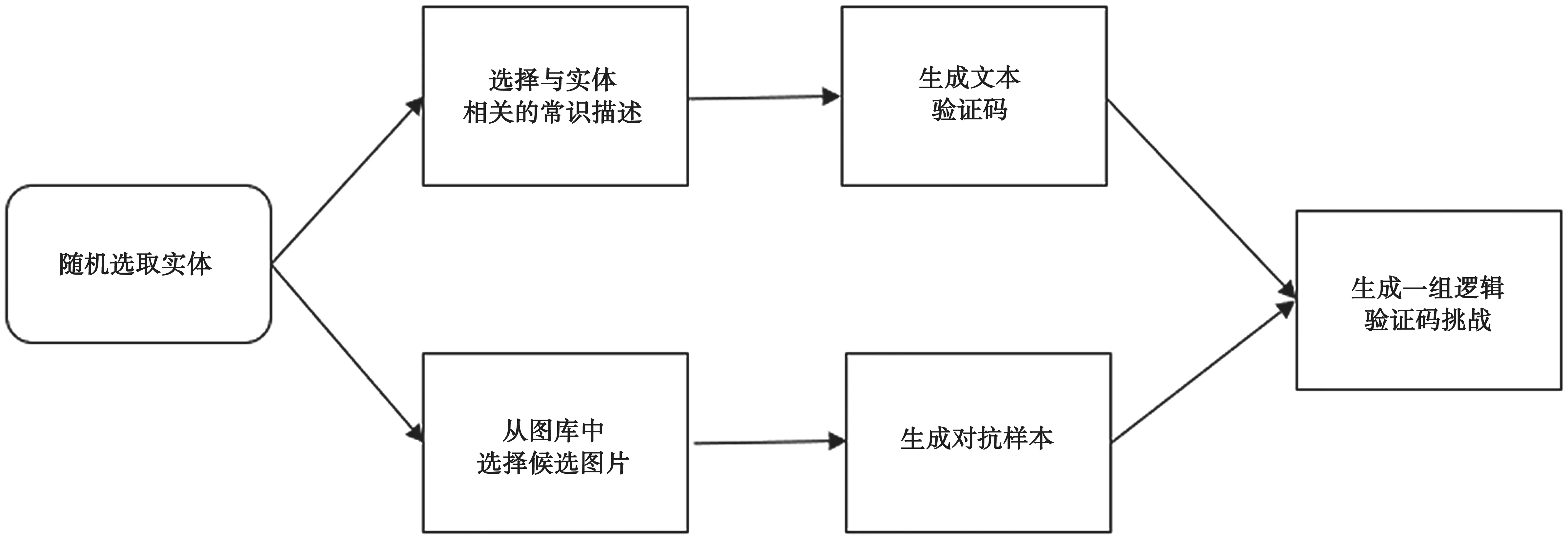
图5 逻辑验证码设计流程
总体算法设计从随机选取实体开始,预先建立好包含8个大类的实体名称库。它包含诸多类别如动物、植物、食品、自然、交通工具、衣物服饰、电子产品和生活物品等,每个大类中包含多个细分实体。生成一组验证码挑战时,会从实体名称库随机挑选一个实体A作为本次验证码的答案所属类别,以及一定数量的不相关的实体集合B作为干扰项。然后,通过查询常识知识库ConceptNet中有关实体A的常识性描述,选择一定数量的描述即提示词组,利用golang CAPTCHA的API接口生成文本形式的验证码。同时,需要在构建的图片库中随机选择一张实体A的图片和数张不相关实体集合B的图片构成所有的候选图片。为了欺骗神经网络分类器使之无法获得图片的正确标签,还需要对这些图片添加对抗噪声以生成对抗样本。将生成好的文本验证码和添加了对抗噪声的图片组合,即可形成一次完整的逻辑验证码挑战。
2.1 实 现
验证码系统基于Vue框架进行搭建。以一个由4个提示词组和6张候选图组成的验证码挑战为例,如图4所示,首先选择鸟这个实体作为本次验证码挑战的答案,查询ConceptNet获取4个关于鸟bird的常识性描述——羽毛(feathers)、可以扇动翅膀(spread the wings)、唱歌(can sing)和在树枝上栖息(land on a branch),利用API接口生成了图6最右侧一列展示的文本验证码。在实体名称库中,随机选择5个与鸟不相关的实体——猫、闹钟、汽车、金鱼和苹果,同时在图库中选择实体所对应的图片,利用Resnet网络对这些图片添加对抗噪声,随机摆放好这些图片所在的位置,使得正确答案不会出现在固定的位置,这样就完成了一次验证码挑战的生成。
用户所要做的是要通过右侧给出的几个词组的描述,推断出所描述的实体是什么,从而在左侧候选的图像中选择符合逻辑的图片作为答案,并点击提交即可完成测试。根据提示词羽毛和唱歌,人可以很容易推断出左下角内容为鸟的图片为正确答案。这里的提示词组选择用英文显示,也可以根据不同地区做相应的语言调整。此外,系统添加了超时机制,一旦超过预定的判断时间,会刷新验证码内容,以提升逻辑验证码的安全性。

图6 逻辑验证码挑战
逻辑验证码的设计有令人耳目一新的特点。这是第一次通过设计逻辑推理的过程来区分人与机器,并且结合了图像与文本验证码的特性,同时提示词内容可以根据不同国家地区的语言进行调整。常识具有一般性,是能为大部分人群所熟知和接受的知识。因此,通过获取与实体相关的常识,并以一种类似你说我猜的游戏方式进行呈现,受到了参与测试用户的一致好评。他们认为,逻辑验证码非常有趣,且能够快速准确地完成验证码测试。
2.2 常识的来源与选择
利用神经网络解决一些图像分类和数据回归的问题,并且提升模型的准确性和鲁棒性,一直是人工智能研究的热点。然而,利用已有知识和信息进行逻辑推理的能力是人类所特有的,对于目前的人工智能技术来说是一件较为困难的事情。现有的图像验证码防御设计多针对神经网络的分类能力,意图欺骗它使之分类错误。逻辑验证码利用常识进行逻辑推理过程的设计。所谓常识,即对不同区域、不同年龄层次、不同职业的人群来说都要具有普适性。因此,选择合适的常识在逻辑验证码设计的过程中尤为重要,而蕴含相关知识的知识图谱(Knowledge Graph)是一种较好的来源。
传统的知识图谱的构建以三元组的方式存储。三元组由实体、实体关系和实体构成。常见的以相关领域知识和语言学为基础的知识图谱有Wikidata、YAGO以及NELL等[19]。知识图谱常以可视化的具有指向性的图(Graph)的形式展现,实体与实体之间以相互的关系作为链接的媒介。以具有上下位关系的知识图谱为例,一个实体会不断连接延伸它的上位词直至没有上位词为止,会使图的结构非常庞大复杂,且实体只与其直系的上位词之间的关联度较好。如果从中随机抽取不同实体,在图的结构中难以伸展至同一个交点,导致出现歧义性的可能较大;提示词组选择好后,攻击者一旦知晓所使用的知识图谱,则可以轻易从单一的依赖关系中找到答案。领域类知识图谱GoodsKG则是基于京东商城的1 300种商品的上下级概念进行构建的,包含了10万品牌和65万种品牌的销售关系。然而,由于领域知识的限制,它并不适合用来作为具有一般性的常识。对于男性来说,他们可能不会熟悉化妆品和女性服饰的品牌,而对于女性来说一些品牌则是常识。即便是女性,对于多种多样的化妆品和服饰品牌,她们的知识储备也仅在知名品牌中。这种情况在其他商品中也非常常见,因此将会限制验证码生成的有效数目。
常识知识图谱ConceptNet是一个大规模的包含数百万个节点和关系的知识图谱,如图7所示。其中,实体的介绍主要包含是什么、被用于做什么、组成和具有的特征等,且三元组之间边的权重也可以通过数值化的形式展现。本文利用ConceptNet作为知识载体,通过选择合适的常识实体和与之有着一定关联权重的描述生成逻辑验证码,同时限制描述词组的数量和文本验证码生成的方式,以防止基于图网络结构对所选常识实体的回溯定位。

图7 ConceptNet有关dog的常识描述
2.3 基于对抗样本的图像生成
Christian Szegedy等人发现,在图像数据集中故意添加细微的干扰所形成的输入样本,将会导致模型以一个较高的置信度给出一个错误的分类输出,这样的图像样本被称作是对抗样本。GoodFellow的文献[20]指出,深度神经网络在高维空间中的线性特性已经足以产生这种攻击行为,并提出了一种更高效生成对抗样本的方法叫做快递梯度符号算法(Fast Gradient Sign Method,FGSM)。图8利用FGSM方法对熊猫图片产生对抗噪声,使得神经网络以99.3%的置信度认为这是一只长臂猿。这种方法基于目前神经网络,为了提高训练效率,所使用的激活函数在局部都过于线性。通过添加与训练好的参数向量方向一致的微小扰动,就可以对神经网络最终激活层的计算产生巨大干扰,从而愚弄神经网络训练出来的模型。

图8 在GoogleNet上用FGSM生成对抗样本
在已知模型参数条件下,通过求出模型对图片输入的导数,用符号函数得到具体的梯度方向并乘以步长,可以利用式(1)产生对抗噪声:
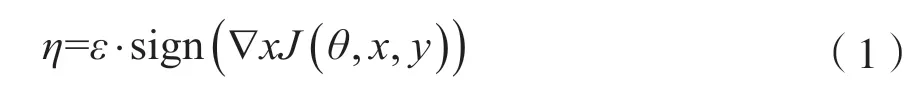
式中,sign()是符号函数,J是训练模型的损失函数,θ是模型的权重,x代表输入图像,y代表图像对应的真实标签,ε是噪声系数,η是叠加在x上的噪声。
本文用于生成验证码的图片是经过精心挑选和设计的,所有原始图片都来自于www.pexels.com,需要保证实体主体部分清晰明了,以减少对人的歧义性。按照实体在Wordnet中的种属关系,选择了8大类常见实体,并为每类实体建立对应图集,同时会不断替换其中的图片,以保证每次生成的验证码所使用的图片不相同,进而防止通过搜集相关图片数据进行分类训练,同时对每张图片使用迭代FGSM方法生成对抗样本,从而使得神经网络分类器难以获取其真实的语义标签。对于候选图片中除去答案图片的剩下其他图片的选择,利用Wordnet的路径相似度进行分析,从而使得在图片集里随机选择时有较好的类间区分度,减少同类或者有着相近描述的实体,降低人的出错概率。
2.4 文本验证码
根据一条常识,在ConceptNet中确定好用于描述该常识的文本内容,对其进行文本验证码的生成,以防止攻击者直接获取对应的文本信息。利用golang CAPTCHA,可以无需依赖第三方图形库生成验证码,同时可以对文本的字体、多种颜色组合、验证码显示大小、文字模式、文字数量和干扰强度进行自定义设置。图9展示了各种自定义设置下对提示词产生的文本验证码,原文为can sing、eat meat和round。

图9 提示词文本验证码
3 实验设计与结果分析
3.1 实验环境
本文的验证码通过在100类常见实体中进行一次常识知识的生成,利用ConceptNet所提供的信息进行提示文本选择,同时利用自动化工具获取pexels.com上的图片来不断扩充每类实体的代表图片。对于图片的对抗样本的生成,采用目前最主流的深度学习框架——Pytorch进行神经网络Resnet50的搭建。采用两块Nvidia 1080显卡进行分类和产生对抗样本,使用图像分类领域著名的数据集ILSVRC-2012的验证集,共50 000张图像,包含1 000类对象每类各50张。采用预训练好的Resnet50对ILSVRC-2012的图片进行分类,可以达到88.1%的准确率。
对于验证码中的候选图片,设置不同的噪声系数ε来衡量噪声对用户识别速度和准确度的影响。在L∞范数条件下共设置4组不同噪声系数,即ε为0.01、0.05、0.1和0.2。图10列举了原图和在不同噪声系数下生成的对抗样本。可以发现,当噪声系数大于0.05时,人眼已经可以看到明显的噪点,但是并不影响人的判断结果。
在具有6张候选图和4行提示词的验证码设置下,噪声系数对人的识别速度和正确率影响如表1所示。可以发现,噪声系数变大会在一定程度上影响人的正确率,也会增加完成一次验证码测试的时间,但都处于可接受范围。因此,权衡生成对抗样本的代价和识别结果,选择噪声系数为0.05较为合适。

图10 原图和生成的对抗样本

表1 噪声系数与正确率与平均用时
3.2 图像与提示词组数量的选择
在设计逻辑验证码的过程中,一个较为关键的问题是如何设置候选图片的数量和提示词的数量。人们希望候选图像更丰富,同时能够使人在进行验证码测试时有更高的正确通过率,且所需的反应思考时间更少。为了确定最合适的数量组合,逻辑验证码的测试通过线上和线下进行。主要测试群体为上海交大的学生,覆盖不同专业和大一至研三不同年级的同学。统一设置图片大小为320×180,表2表示在噪声系数0.05的条件下,不同的图片数量和提示词数量的组合下人的正确率和平均用时。

表2 噪声系数0.05,不同组合下的正确率与平均用时
可以得出,当提示词数量不变时,图片数量越大,平均完成测试的时间越长,但对正确率的影响不大。究其原因,在于不同图片之间的相似度小,区分度好。当提示词增多时,正确率会逐渐提高,因为词组描述的内容的重叠区域变小,易于用户选择更合适的图片。用户的平均用时在图片数一定的前提下没有增加太多,一方面是由于第一行信息没有给人带来直接的推断,因此识别多行内容会增加一定的时间,另一方面是由于用户不一定会按照顺序从第一行读起,中间的某行吸引到用户的注意且具有足够的信息量供用户推断,那么无需看其他提示词即可进行选择。
3.3 安全性
根据现有的实验可以发现,图片和提示词的数量、内容的选择等,都会影响验证码的可用性和安全性。因此,下面将从暴力尝试、基于获取语义标签进行相似度匹配和可能存在的其他攻击3个方面进行分析。
对于没有决策机制的随机猜测,是最简单的攻击方法。实验结果表明,对于6张候选图的验证码,其随机猜测成功的概率与实际通过率一致均为1/6,这是在答案图片数仅有一个的条件下得到的。如若答案设置为2个,即满足常识性描述的图片数为2个时,则可以将随机猜测的成功率降低至1/15。当候选图片数为12张时,则可以大大降低成功率,但也会以牺牲人的识别准确性和时间为代价,其正确率为70.3%,平均用时7.5 s。
由于在候选图片中添加了对抗噪声,使得神经网络难以正确获取每张图片的语义标签,且逻辑验证码的设计也保证了其低重复性,降低了攻击者通过收集数据进行训练和回溯的可能。即便可以用其他方法获取到标签的方式,如经过对抗训练和图像相似度搜索获取图片语义标签和提示词的文本信息,再利用Wordnet比较语义标签与文本信息之间的相似度和关联性的攻击方式。在6×4且只有一个正确答案的验证码设置下,它的破解率为17%,略高于随机猜测。而对于有两个答案的情况下,它的破解率仅为4.5%。这是因为Wordnet中的相似度是比较两个实体在路径上的距离,而文本信息中描述的内容往往不直接与实体同类,所以即便能够正确分类对抗样本和文本验证码,逻辑验证码也是较为安全的,且超时机制的加入增加了另一道保障。
对于未来可能存在的基于知识图谱的攻击,在攻击者不知道验证码系统所使用的知识图谱的情况下,它不能通过建立拓扑结构进行查询。即使攻击者知道了所使用的知识图谱,文本验证码对文本的变形也会使得获取节点变得困难,同时可以对文本进行同义转化和句子补全等,使得攻击者无法直接在知识图谱中查询到这些文本内容信息。当然,较为安全的方式仍是建立属于自己的知识图谱,虽然会是一个工程量较大的事情,但是非常必要。
4 结语
本文提出了一种新的基于知识图谱的逻辑验证码方案,要求用户根据变形后的提示文本进行推理,并在添加了对抗噪声的候选图中选择最符合的答案。实验结果表明,逻辑验证码在可用性和趣味性上都有着不错的表现,用户可以在较短的时间内准确完成测试。本文也对逻辑验证码的安全性进行了分析,确保了验证码设计的安全。以前的工作主要聚焦于识别任务区分人与机器,通过字符变化和产生对抗样本虽然是较为有效的方式,但是安全性在人工智能技术的发展下受到了挑战。逻辑验证码的出现能够提升验证码安全,并为防御提供新的角度和思路。
猜你喜欢
军事文摘(2022年24期)2022-12-30
法律方法(2022年2期)2022-10-20
北京航空航天大学学报(2022年8期)2022-08-31
中学生百科·大语文(2021年11期)2021-12-05
纺织科学研究(2021年7期)2021-08-14
少先队活动(2020年12期)2021-01-14
文苑(2020年11期)2020-11-19
好孩子画报(2020年4期)2020-05-14
孩子(2019年9期)2019-11-07
37°女人(2017年11期)2017-11-14
