
基于Openpose和Yolo的手持物体分析算法
2021-03-21 07:18贺文涛黄学宇
空军工程大学学报 2021年6期
贺文涛, 黄学宇, 李 瑶
(空军工程大学防空反导学院, 西安, 710051)
随着模式识别和图像处理技术的快速发展,人体分析作为该领域一个分支近来也受到了科研人员和工业应用的广泛关注,但当前的大多数分析算法仅将人体自身作为研究点,通过对人体的全身姿态或动作捕捉来进行相关应用,少有针对某一特定身体部位进行的分析研究,对人体与物体的关联研究也比较少。
现有的人体分析算法可按实现方式大致分为两类,自上而下(top-down)和自下而上(bottom-up)。自上而下的方式指的是在每次的检测中首先使用人物检测器识别图片中的人员,然后在此基础上进行分析,如Newell[1],WEI[2]等使用的姿态估计方法。这种方式的缺点是需要很高的前期人员识别准确率保证,一旦无法识别人物,姿态估计就会失效;另外,由于对每个人都要使用一个检测器,随着图片中人物数量的增加,其计算成本会随之成倍增加。相较之下,自下而上的方式则可以弥补这些缺点,其首先在全局进行关节热点图的提取,然后根据向量关系进行连通,从而为前期保证提供了高可靠性。但早期的自下而上方法,如Pishchulin[3],Insafutdinov[4]等提出的方法,由于最终的解析仍需要复杂的全局推断,因此并未提高效率。文献[5]用贪心算法将关键点连接起来,大大提升了效率,使得实时的人体分析成为现实。
当前的目标检测器通常由三部分组成:第一部分是在拥有海量的图片集如ImageNet上经过预训练的主干网络(backbone);第二部分是用于预测类别和物体方框位置的头(head),主要可分为二阶检测器(R-CNN[6-10]系列)和单阶检测器(YOLO[11-14],SSD[15]和RetinaNet[16]等);第三部分是Neck网络,指的是在backbone和head之间插入的连接层,用于连接不同阶段的特征图。
近年来,手持物体分析正受到越来越多的关注和应用,但大多应用通常有着严格的条件和区域限制。如文献[17]中驾驶员手持通话检测,首先摄像头需要正对驾驶员,然后进行人脸检测,估算耳部位置划出感兴趣区域,再根据区域内手部存在时间加上唇部张合状态来综合判断手持通话状态,步骤相当繁琐且需要很高的前期识别准确保证。
为补充专用于手持物体分析算法的缺失,以及更为准确稳定的识别结果,本文提出了一种可全局分析的手持物体行为分析算法。
1 OPENPOSE人体姿态估计方法
Openpose[5]是由卡耐基梅隆大学(CMU)感知实验室发布的一种实时多人姿态估计方法。该方法采用一种非参数的表达方式,即局部亲和矢量场(part affinity fields,PAF),来学习将各个身体部位与图片中的各个人体相关联。其体系结构通过对全局的内容进行编码,从而自下而上地用贪心算法进行解析,无论图片中有多少人,都能在保持高精度的同时保证实时性。其网络结构主要是通过一个连续的预测过程的两个分支来同时学习关键点的定位以及它们之间的关联。
Openpose的网络结构图如图1所示。

图1 多阶段的双支路网络结构图
图1中F是由经过微调的VGG-19卷积网络的前10层通过对输入图片的分析后生成的特征图集合,然后将F作为两个分支第一阶段(Stage 1)的输入,其中分支一(Branch 1)用于预测置信图St,分支二(Branch 2)用于预测PAFs-Lt。在每个阶段之后,两个分支的预测结果会被合并作为下一个阶段的输入,并重复上一阶段的操作。
通过上述重复操作,即可预测关键点位置及其置信图。最后,通过贪心算法将这些关键点连接起来即可获得人体的骨架图。如图2所示。

图2 Openpose检测结果
其中,两个相邻关键点dj1和dj2的关联性的评估是通过计算相应矢量场中向量间的线积分来实现的:
(1)
式中:P(u)表示dj1和dj2之间的点。
P(u)=(1-u)dj1+udj2
(2)
2 Yolov4目标检测算法
Yolov4是由Alexey Bochkovskiy[14]等人于2020年4月发布的目标检测算法。通过将时下最为先进的网络调优方法,如加权残差连接(WRC)、跨阶段部分连接(CSP)、跨小批量归一化(CmBN)、自对抗训练(SAT)、Mish激活函数、马赛克数据增强、DropBlock正则化、CIoU Loss等,在Yolov3的基础上进行对比改进实验,最终获得了检测速度与检测精度的最佳平衡的目标检测器——Yolov4。
图3为Yolov4与当前其他最先进方法在COCO数据集上的检测速度、精度对比图。

图3 Yolov4检测效果对比[11]
由图3可知,检测速度差不多时Yolov4的检测精度更高;检测精度差不多时,Yolov4则更快。最终其结构如下:
backbone:CSPDarknet53[18]
neck:SPP[19],PAN[20]
head:Yolov3[13]
此外,网络结构针对单GPU训练做了优化,不需要额外的训练成本即可复现其优良性能,因此本文选择Yolov4作为物体检测器的基础框架,在其基础上搭建本文算法。
3 基于Openpose和Yolo的手持物体分析算法
本文的算法流程如图4,以右手为例进行说明。
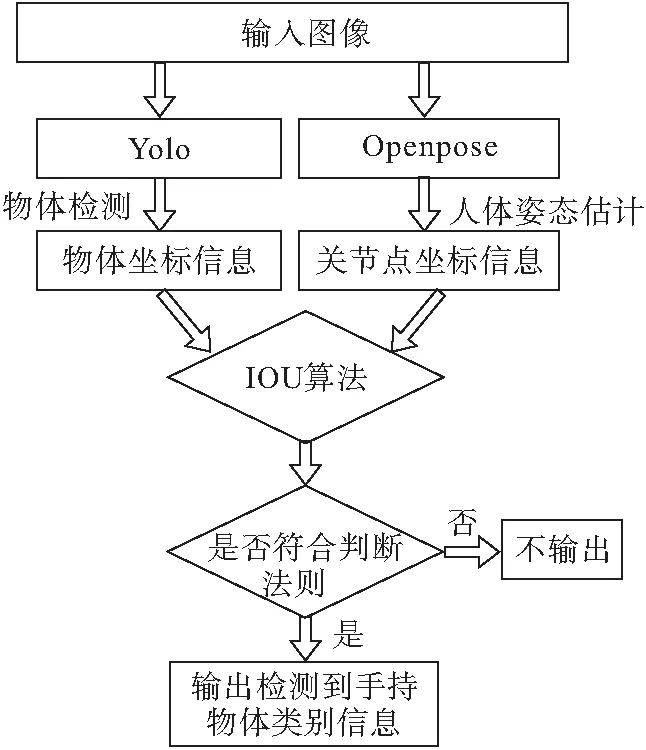
图4 算法流程图
输入图片首先经过Openpose处理后,提取出图片中的人员骨架关节点,其输出如下(Body_25模型),见图5。

图5 BODY_25输出关节图
Body_25检测模型下与关节点的对应关系如表1所示,共有25个关节点,每个节点位置输出(x,y,score),分别为关节点横坐标、关节点纵坐标以及置信度。
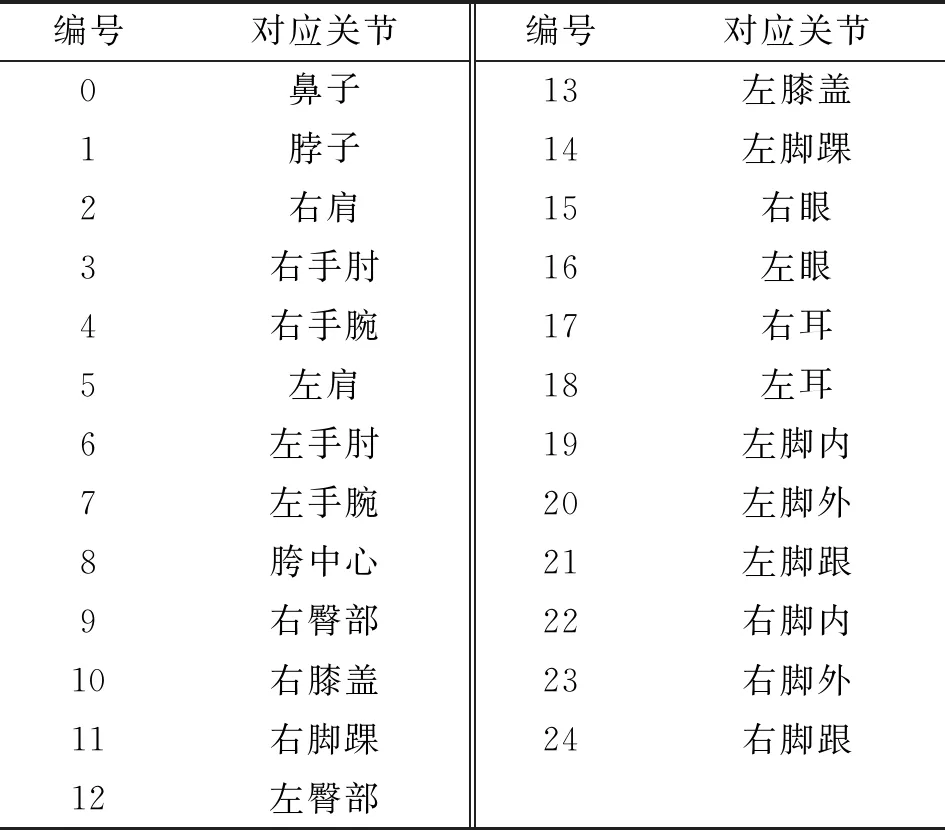
表1 输出编号对应关节
同时,输入图片经Yolo处理,检测出图片中感兴趣物体的类别与位置,画出方框。其输出包含(Xtop_left,Ytop_left,w,h),obj_id等,分别为方框左上角横-纵坐标,方框宽-高以及物体类别对应ID。
经过上述处理,融合两部分输出信息,使用IOU算法进行处理,最后进入手持物体行为分析算法的逻辑执行部分。实际手持场景中,不同尺寸大小的物体对手持位置与逻辑判定关系均有不同影响。按手持物体的尺寸大小分为小型物体和中、大型物体两类。
3.1 手持小型物体判定法则
小型物体的边长小于手的长度(15 cm),特点是尺寸较小,形状较规则,宽高比较小,手持时通常握在物体中心,如手机、小刀等,因此当手腕节点与感兴趣物体中心(Xcenter,Ycenter)的距离小于手的长度即可认为该物体被手持。
如图6所示,通过Openpose获得右手腕(x4,y4),右手肘(x3,y3)的位置信息,取右手腕到右手肘距离的一半作为手的长度Lhand(由于手指的关节数量众多,直接提取其关节位置信息会大大增加计算成本,增加算法复杂度),可得:

图6 手持物体逻辑判断图
(3)
使用Yolo获得感兴趣物体的类别和位置并画出方框,输出方框左上角点坐标(Xtop_left,Ytop_left),方框宽w,方框高h,可得物体中心点坐标为:
(4)
(5)
由式(3~5)可得手持小型物体的逻辑判断条件为:
(6)
当满足式(6)时,可认为当前人员手持物体。
3.2 手持中、大型物体判定法则
中、大型物体指边长分别大于手的1倍(15 cm)和3倍(45 cm)以上,特点是尺寸较大,形状不规则,宽高比变化多,手持中心位置浮动较大,如书本、晾衣杆等。此时小型物体的逻辑判断法则不再完全适用。如出现图7手持状态时,手腕位置与物体中心距离远大于Lhand,按照小物体逻辑判断法则(6),此时图7是未手持状态,因此出现漏检。因此,需要对小物体逻辑判断法则进行扩充。令手腕到物体中心的距离小于物体检测框最长边长的一半,即:
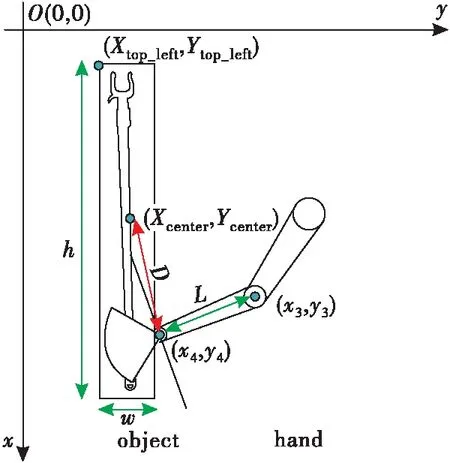
图7 手持中、大型物体情况1
(7)
根据式(7),虽然提高了图7情况手持物体的识别准确率,但对图8所示情况的误检(未手持却检出手持)会增多。为解决图8所示误检情况,需要对物体与手之间的关联性进行约束,因此参考图像检测中的交并比(IOU)算法进行补充。

图8 手持中、大型物体情况2
交并比(intersection over union)是用于目标检测任务中计算图像重叠比例的算法,主要用于生成候选框的置信度排序。在本文的算法中,利用交并比来判断手与感兴趣物体的关联性大小。
如图9所示,A为Yolo检测物体后生成的矩形框,B为以右手腕关节点(x4,y4)为中心,以手长的两倍2Lhand为边长绘制的矩形,蓝色部分C为A与B的交叉部分。

图9 交并比法则
设A左上与右下坐标为(X11,Y11),(X12,Y12),设B左上与右下坐标为(X21,Y21),(X22,Y22),则有:
X11=Xtop_left
(8)
Y11=Ytop_left
(9)
X12=Xtop_left+w
(10)
Y12=Ytop_left+h
(11)
X21=X4-Lhand
(12)
Y21=Y4-Lhand
(13)
X22=X4+Lhand
(14)
Y22=Y4+Lhand
(15)
可得:
xA=Max(X11,X21)
(16)
yA=Max(Y11,Y21)
(17)
xB=Max(X12,X22)
(18)
yB=Max(Y12,Y22)
(19)
式中:xA,yA,xB,yB分别为交叉部分左上角与右下角点,故有矩形A、矩形B、交叉部分Intersection的各部分面积分别为:
SA=(X12-X11)(Y12-Y11)
(20)
SB=(X22-X21)(Y22-Y21)
(21)
Sinter=Max(xB-xA,0)Max(yB-yA,0)
(22)
则交并比为:
(23)
由式(6)~(7)和式(23)得到算法的最终逻辑判断法则为:
(24)
其中Limit为自定义的IOU阈值。
通过手持状态判定结果结合物体类别识别结果即可输出手持物体类别结果。
4 实验及结果分析
首先对Yolo进行训练。按照小型、中型和大型3种不同的尺寸大小,包括小刀、手机、水杯、书本、扫帚、晾衣撑共6种类别,包含了危险品和日常家庭使用的各种物品,分辨率为1 280×720,采集了共计1 489张图片制成数据集。具体组成如表2,图片数据输入网络前统一缩放成512×512的尺寸大小,将训练集与测试集按照4∶1的比列分配。

表2 数据采集类别及数量
为了提高网络的鲁棒性,对训练数据使用了随机旋转,随机缩放,改变色相、对比度、曝光度和马赛克数据增强等方法。其中马赛克数据增强是一种新的数据增强方法,将4张图片数据按随机比例拼成一张,这样就能将4张图片的内容混合,使得在目标检测时能超出原有的内容范围。图10为马赛克数据增强效果图。通过这一方法与未使用该方法相比,最终物体检出率提高了大约0.3%。

图10 马赛克数据增强
本文的实验环境配置为:硬件:CPU为Inter Core i5-10600KF@4.10 GHz,GPU为NVIDIA GeForce RTX3070(8G),16 GB内存,软件:Windows 10操作系统,安装CUDA 11.1,CUDNN 8.0.5,使用Visual Studio 2019作为编辑器,OPENCV 4.2.0用于结果显示。
为适应手持物体的特点,加快算法运行速度以及方便后期将算法移植到轻型计算设备,对网络作出适应性调整。将Yolov4-tiny的基于Resnet的预训练模型yolov4-tiny.conv.29替换成了基于EfficientNet-B0的enetb0-coco.conv.132,称为Effinet-Yolo;同时在训练时将输入网络尺寸设置为416×416,在检测时放大至512×512,以提高小目标物体检出率。分别使用原生的Yolov4,Yolov4-tiny,以及调整过的Effinet-Yolo进行训练,预设迭代次数为12 000次,初始学习率分别设置为0.001 3,0.002 6,0.002 6,学习策略为step。当average loss降到0.05至3.0以内,或者经过多次迭代后average loss不再下降时,停止训练。
在本文实验中迭代至6 000次时损失函数即不再下降,停止训练。分别用3种模型对验证数据集进行测试,其结果如表3所示。

表3 模型训练结果对比
由表3可知Yolov4拥有最高的准确率和召回率,但由于其网络层数最深导致其网络权重也最大,运行速度最慢;Yolov4-tiny由于削减了主干网络,运行速度最快,但准确率最低,而准确率较低的主要原因是小型物体的检出率不足。Effinet-Yolo在替换了backbone后,使得网络权重相对于Yolov4-tiny减少了4.8 MB,从而降低了算法的复杂度;另外通过在训练时减小网络输入尺寸、在检测时增大网络尺寸的方式,使得小型物体的检出率有所提高,相较于Yolov4-tiny准确率提高了3.5%左右。因此,在满足检测性能的前提下,最终选用权重最小最易部署的Effinet-Yolo网络模型作为本文算法的物体检测器。
然后对Openpose的关节点输出进行筛选,仅保留手腕和手肘的关节信息。使用C++ API进行Openpose和Yolo的坐标信息融合,并用IOU算法进行处理,最后进行识别结果验证。将Yolo封装成动态链接库使用,并在VS上进行本文算法的代码运行。分别使用表中所示模型搭配以及传统的方法,均采集手持不同种类的物体,交替左右手,采用单手或双手,改变身体位姿等视频数据集进行验证结果对比实验。
不同模型搭配本文算法结果如表4。由第一组结果可知,Yolov4与body_25的组合,虽然准确率最高,但是运行速率只有6 fps,无法满足实时性要求;由第二组与第三组结果对照可知,body_25模型运行速度更快,这是因为相较于coco模型虽然提取更多的关节点,但是其参数量少,并且由于使用了CUDA技术进行加速,因此其运行速度更快。另外,由于本文算法需要依赖于物体检测器Yolo和关节提取器Openpose的准确率,且二者同时运行,而Openpose运行相对较慢,因此限制了算法的运行速率。另外,相较于表中第4组传统方法即文献[20]模型,本文算法的准确率有所提高,且本文所提算法不需要划定感兴趣区域,可直接对全局进行分析,表现出更好的泛用性。由表4综合考量,Effinet-Yolo和body_25组合为最优搭配。

表4 检测结果对比
算法运行效果如图11,最终在图片上输出人体骨架及节点,物体检测框以及左上角的手持状态以及左右手的手持物体类别,由图11(a)可知算法对前文所提手持小、中、大型物体均有较好识别效果,且能区分左右手,非手持状态也能准确识别;图11(b)在双手持物、背面以及部分遮挡重叠时也能保持较高准确率,验证了算法的鲁棒性。

图11 算法运行效果图
本文算法潜在应用场景如下:在工地中,可识别工人是否佩戴安全手套;在家庭的安全监察中,可对儿童拿起刀具等危险品的行为进行识别警告;可用于手持危险品行为检测,如在地铁站或者火车站等闸口用监控视频进行危险行为检测以补充安全检测遗漏;在战场中可通过是否手持武器来区分敌我。
综上,Effinet-Yolo和Body_25组合的模型组合结合算法的判定法则,可使正确识别手持状态同时识别出手持物体类别的准确率达到91.2%,运行速度可达13 fps,并且总参数量最少,仅有118.1 MB。因此将其作为本文的实时手持物体行为分析算法的最终框架。相较于传统手持物体识别的思路,以姿态估计和目标检测为基础进行手持物体识别具有更高的准确度和泛用性,手持定位更为准确,同时本文算法不需要严格的前期人员识别保证,不需要划定感兴趣区域即可进行全局分析。
5 结语
本文针对当前人体分析算法很少以某一特定部位作为研究点的问题,提出了专用于手部的全局实时手持物体识别算法。通过使用Openpose和Yolo对图片做预处理,然后使用C++ API进行二者的坐标信息融合。根据手持物体的尺寸大小分为小型,中型和大型两类情况进行分类,参考交并比(IOU)算法进行处理并作为手持物体状态的辅助判断,最终分别设计出了判断法则,实现了手持物体行为分析算法,并以提高运行速率和方便部署为目的做了适应性调整。在采集的手持物体视频流数据集上,最终识别手持状态的同时准确识别手持物体类别的准确率可达到91.2%,通过插帧等方式基本可达到实时运行的要求。相较于传统思路方法,本文所提以姿态估计和目标检测为基础的算法定位更为精准,识别准确率更高,算法在民用以及军用等多种场景均具有良好的潜在应用价值。
下一步的工作是使用多线程调度机制等方法,进一步提高算法的运行效率,同时将算法分析的范围扩展到脚部、头部等其他身体部位,形成一套完整的人-物交互分析系统,最终将其应用到无人机监查、智能监控等工程应用中。
猜你喜欢
测控技术(2022年4期)2022-04-27
雷达科学与技术(2021年5期)2021-11-29
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
科技风(2018年15期)2018-05-14
少儿科学周刊·儿童版(2015年2期)2015-07-07
科普童话·百科探秘(2015年4期)2015-05-14
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
