
基于网络流量预测的高校个人健康状况上报系统设计与实现
2021-03-21 04:06熊鹰李凯郑競力吴驰毛文卉
中国教育信息化·高教职教 2021年9期
熊鹰 李凯 郑競力 吴驰 毛文卉


摘 要:新冠肺炎疫情的爆发对高校科研、教学工作的秩序造成严重影响,对全体师生的健康也产生严重威胁,面对疫情如何科学防控、精准施策对教育信息化工作提出了更高的要求。文章提出了一种支持高并发访问的个人健康状况上报系统:可根据需求快速升级迭代,实现全面采集师生每日健康状况信息,并对健康状况信息进行统计报表分析;针对海量填报数据进行分析查询,创造性地提出基于系统流量预测,对报表生成的执行计划与方案进行优化,从根本上解决系统大数据分析查询优化的问题。
关键词:信息化;疫情防控;高并发;查询优化
中图分类号:TP311 文献标志码:A 文章编号:1673-8454(2021)09-0072-04
一、引言
新冠疫情爆发以来,高校科研、教学工作的秩序受到严重影响,全体师生健康也遭受严重威胁。面对疫情如何科学防控、精准施策对教育信息化工作提出了更高的要求。疫情防控初期面对全校数万师生,传统渠道的摸排和疫情数据上报效率低下。如何在短时间内完成 “摸清家底”工作,对于疫情防控工作显得尤为关键,对个人健康状况上报提供信息化支撑迫在眉睫。
采用传统软件开发模式与技术手段很难在极其有限的时间内完成系统开发工作,并且短时间内解决因用户数量十分庞大导致的并发压力,以及填报后累积下来的海量数据分析与查询效率优化问题,这是传统教育信息系统开发工作中未曾遇到过的巨大挑战。
本文所设计的系统主要拟实现以下三个方面的目标:①敏捷开发。需要在极其有限的时间内完成健康状况填报系统与数据统计分析查询系统的快速开发、测试、部署、上线工作;同时要基于疫情防控需要根据各级部门新需求,完成系统的快速迭代升级。②高可用性。针对规模较大的高校,按照学校要求全体师生执行“每日一报”,系统需要在日均活跃用户突破10万人的情况下,支持系统实时动态扩展,支撑持续高并发访问。③数据查询效率。随着疫情防控常态化,针对一段时间填报而沉淀下来的数据,实现大数据分析与报表统计快速、查询高效。
二、相关工作
最近一段时间,微服务架构引发业界主流的巨大关注,已成为国内外各互联网企业架构治理的新趋势。不可否认,在软件开发过程中,微服务架构将一套完整、独立的单体,应用各项业务功能、应用模块从上至下拆分为若干个独立的微服务,[1]从而实现了软件开发过程中降低开发成本、提升系统运行速度、增强可维护性,[2]微服务架构的引入一定程度上满足了企业信息化中对快速迭代、持续交付的需求。[3]然而,微服务架构在一定程度上也带来了一些新问题,如跨进程通讯、服务注册发现、分布式Session管理等。[4]因此,对微服务架构在实际应用中的优化和改进也成为当前研究的一个主流热点。[5]
同时,对于任何信息系统,当用户量上升到一定规模以后,并发与高负载就成了必须应对的问题。针对高并发访问目前主要的解决方案是采用数据库集群技术和WEB缓存技术[6],当前应对高并发访问问题的主要研究方向集中在对数据库与存储的优化[7]、網站与系统架构的设计[8]、集群负载的方法与优化[9][10]。
信息系统中报表统计功能的用户体验一定程度上直接取决于数据查询效率的高低。随着大数据技术研究的不断发展,在数据量成倍增长的背景下,为了提高数据查询的效率,除了寄希望于硬件性能的不断增长,还需要把注意力转移到数据库技术的研究上来。[11]
大量的研究表明,通过增加索引和提高SQL语句查询质量在一定程度上确实能够极大提升数据库查询的效率。郭峻峰等[12]提出,通过一种综合索引模型相比以往索引方式在一定程度上提高了查询效率;谭磊等[13]提出,通过提高SQL语句的质量来解决查询效率的问题。然而,在对数据量为n的数据进行查询时无论采取哪种优化算法,其时间复杂度最低只能达到O(logn),数据查询的时间仍然会随着数据量的不断增长而增长。这意味着系统的响应在系统上线初期可能由于充分的优化而非常迅捷,但是随着时间推移,积累下来数倍于以往的数据以后,系统的查询效率会明显降低。因此,根据系统实际情况设计数据查询的方案才是解决统计报表效率问题的关键。
三、系统关键技术研究
1.系统架构
由于项目性质的特殊性,为了能够在极其有限的时间内迅速完成系统的快速迭代工作,系统建设过程中很容易联想到利用微服务架构在敏捷开发和持续交付上的优势。传统的微服务架构方案在系统设计的时候必须要充分考虑服务之间的逻辑层次,以便在后期服务治理中处于有利地位。本文借鉴微服务的思想划分各项服务层次逻辑,并充分利用已上线的应用中台作为支撑,完成系统的平台搭建工作。
如图1所示,为了提高系统的可用性,我们根据最底层对个人健康填报用户身份的不同(教职工、本科生、研究生)进行了服务上的划分。这样设计的优点在于:一方面对不同身份的用户进行了并发访问层面的分流;另一方面不同服务之间存在极低耦合度——即使其中一部分服务持续不可用也不会导致其他服务的宕机。
为了满足不同客户端访问形式,本系统建设时没有单独开发系统的入口,而是完全依托于成熟的前台应用——以企业微信(微信企业号)作为移动端用户的入口,以网站群建设专题防控网站作为浏览器端用户的入口。前期对企业微信与网站群进行了大量投入与建设,且已经在用户中产生较高的黏度,这为系统上线时的推广与使用提供了极大便利。
为了实现填报表单的快速迭代,系统建设采用现有的成熟可靠的流程引擎作为应用中台,通过可视化配置的方法,快速迭代渲染表单页面,减轻了前端代码开发的工作量。同时与统一身份认证系统与基础数据库进行对接,迅速完成了系统架构搭建。
个人健康状况填报系统核心功能就是全面采集全校师生个人健康状况数据,各级管理员能够通过查询统计报表全面、及时、准确地掌握本单位基本情况。由于“每日一报”政策的执行,海量的用户对业务系统带来高并发冲击的同时,在一定程度上对数据库形成了巨大的写压力。同时,针对不同层级管理员提供多维度、个性化的报表统计功能,需要进行大量逻辑复杂的查询操作,也容易导致数据库读压力过大。为了解决数据库读写方面的瓶颈问题,如图1所示,本文将数据库配置为一主多从模式,个人健康信息填报等所有数据增删改有关的业务模块直接访问系统的主数据库,而其他与数据查询、读取相关的业务则访问业务数据库从库A;系统额外冗余业务数据库从库B负责数据备份,以及与其他业务系统进行数据共享与交换。通过数据库的主从配置与程序上读写分离的设计,既增强了系统稳定性,也提升了系统的整体性能。
2.基于系统流量预测的统计报表预生成算法
无论是通过提升硬件性能,使用更强性能的数据库,还是通过各种索引对系统程序中的关键SQL语句性能进行优化,在一定程度上都能够起到提升查询效率的作用。但是,这些方法的数据查询时间依然会随着数据的不断累积而逐渐增长。对于个人健康填报系统,当填报数据经过一段时间累积、数据量增长到一定的数量级以后,其统计报表查询时间也会出现大幅增长,从而增加了系统的响应时间,影响用户体验。随着疫情防控的常态化,对个人健康状况的采集、统计查询工作已经转变为一个长期执行的流程,对于个人健康填报系统来说,常规的数据查询优化方法不能从根本上彻底解决报表数据查询效率的问题。本文提出一种全新的基于业务流量预测模型的统计报表预生成算法。即数据统计报表不在用户使用报表统计功能的时候才生成,而是根据本文所设计的算法提前执行并计算好统计报表的结果,当用户查询报表时只需要直接读取已经计算好的报表数据结果即可。同时,为了保证用户报表查询的结果实时性更高,根据采集的业务系统每天不同时间段的历史访问量进行分析,预测系统在第二天不同时间段的访问流量变化,然后依据第二天的预测访问量来制定当天统计报表任务,并执行计划。
基于系统流量预测的统计报表预生成算法的核心思路是确定统计报表SQL查询的执行起始时间,然后循环执行统计报表任务并将统计出的结果写入缓存数据库。为了确定报表任务每天执行的起始时间,首先采集系统过去一段时间的访问量,根据历史访问量预测第二天的业务访问量,根据预测访问量进行计算,必然存在某一个初始时刻t0,使系统对各个时间段尽可能多的人在查询报表统计结果的实时性上达到最高。
如图2所示,对前N天系统的访问量进行采集、分析。定义:第i天任意时刻t系统的访问量为Yit(1≤i≤N)。则利用移动均值预测第N+1天的对应时刻t访问量即可表示为:
为了最大限度保证统计报表查询的时效性,使尽可能多的用户获取最新的统计报表结果,因tk-tk-1=ts,只需要求得tr,当初始时刻t0=tr(0≤tr≤ts)时,使访问量方差?着为最小值。系统只需从tr时刻起,每间隔ts循环执行统计报表查询,并将查询结果存放至系统缓存数据库中。当用户需要查询统计报表结果时,直接从缓存数据库中读取即可。
四、算法性能评估
本文采集了系统从2020年1月30日上线到2020年4月8日武汉“解封”共计7996923条系统访问日志数据。通过分析发现,每日填报的并发量从侧面印证了疫情形势的变化趋势,如图3所示。从2020年1月30日至2月8日,由于疫情防控初期,为了更加全面采集全校师生的健康信息,填报人数在一定时间内出现了小幅增长;其后由于疫情防控工作逐步显现成效,人们心态逐步趋于缓和,填报系统的访问量呈现缓慢下降趋势,但因为学校执行全体师生“每日一报”制度,所以系统每日实际填报量始终维持在相对稳定范围内,因此每日填报记录数量始终呈现线性增长,如图4所示。
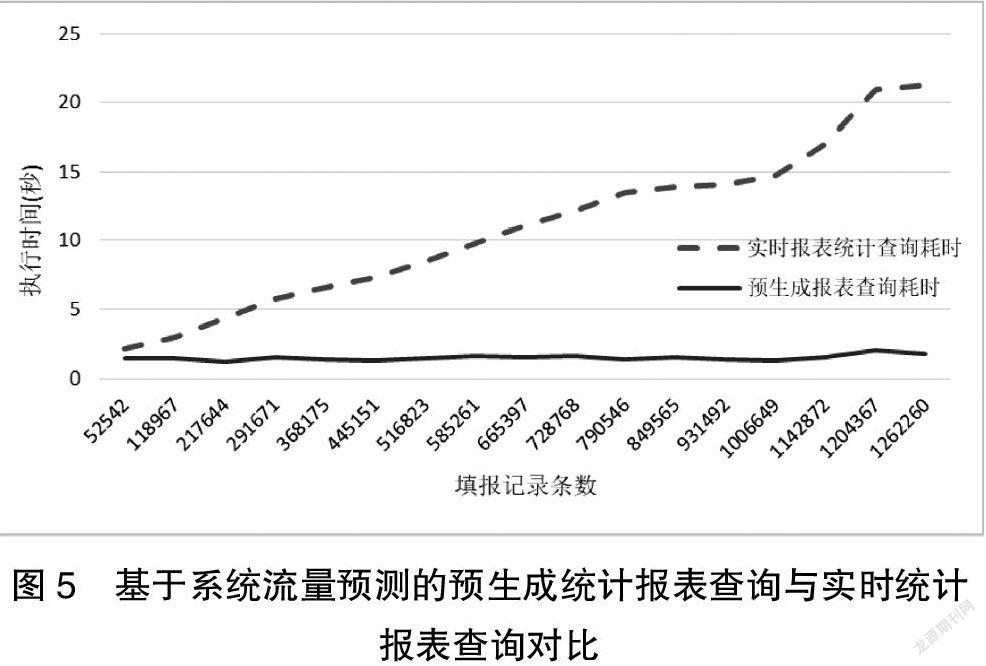
随机选取不同时间段进行对照实验比较,实时报表统计查询与基于流量预测的预生成报表统计查询的执行耗时情况,结果如图5所示。实时报表统计查询耗时会随着数据库中数据量的持续增长而不断增长;而采用本文提出的算法按照预测流量提前生成统计报表结果,查询统计数据耗时能够始终维持在相对恒定的范围内。这是由于系统根据本算法预测的流量,提前规划出统计报表SQL的最优执行计划,查询出来的统计结果相对固定,当用户真正需要查询统计结果的时候可以在极短时间内完成响应,大幅提升了系统执行效率与用户体验。
综上所述,在系统数据库读写分离的基础上,采用基于业务流量预测的统计报表预生成算法实现的报表统计查询程序,能够在显著降低统计报表响应时间的情况下,从最大程度上保证了统计报表数据查询的实时性。这种方法跳出了传统方法(通过增强硬件性能、使用更强性能的数据库或者采用新增各种索引等方法)的局限,对SQL语句性能进行优化等方法没有从根本上消除海量数据查询过程中数据量持续增长对查询效率的影响,本文所提出的算法从根本上提升了系统执行效率的同时,最大程度上保证了报表查询结果的实时性。
五、总结与展望
通过本文提出的设计方案,“华中科技大学师生健康状况填报系统”从2020年1月23日着手设计到2020年1月30日完成正式上线,上线首日共计43232位师生完成了健康状况填报,整个系统从需求调研、方案设计、系统开发、测试上线仅仅用了不到一周的时间,且能够支持根据疫情防控形势与各级部门防控政策的变化完成快速迭代。为坚决防止疫情进一步扩散,并有效收集、全面掌握教职工及学生地理位置、健康状况等重要信息提供重要支撑。系统运行至今采集到共计614万条有效记录,通过本文提出的算法实现的统计报表功能,对于即使每日持续不断增长的海量数据,无需扩容计算资源,也能实现各项统计报表查询秒级响应。
随着疫情防控工作的常态化,后续工作将在保持系统稳定运行的基础上开展以下研究:一是对系统流量预测的算法进行改进,能够更加精准地预测出不同时刻用户访问量变化趋势;二是对优化统计报表预生成算法,进一步提升报表查询结果的实时性;三是将用户填报的健康状况数据与用户在其他业务系统中的数据相融合开展大数据研究,为学校疫情防控的科学决策工作提供支撑。
参考文献:
[1]龙新征,彭一明,李若淼.基于微服务框架的信息服务平台[J].东南大学学报(自然科学版),2017,47(A01):48-52.
[2]李贞昊.微服务架构的发展与影响分析[J].信息系统工程,2017(1):154-155.
[3]洪华军,吴建波,冷文浩.一种基于微服务架构的业务系统设计与实现[J].计算机与数字工程,2018,46(1):149-154.
[4]张晶,王琰洁,黄小锋.一种微服务框架的实现[J]. 计算机系统应用,2017, 26(4):82-86.
[5]谭一鸣.基于微服务架构的平台化服务框架的设计与实现[D].北京:北京交通大学,2017.
[6]梅华威,張铭泉,李天.高并发高负载网站系统架构研究[J].计算机与网络, 2009(14):54-57.
[7]范新民.高并发环境下MySQL软硬件配置优化[J].福建师范大学学报(自然科学版),2013, 29(6):49-54.
[8]包立辉,黄彦飞.高并发网站的架构研究及解决方案[J].计算机科学,2012, 39(z2):184-187.
[9]张尧.基于Nginx高并发Web服务器的改进与实现[D].长春:吉林大学,2016.
[10]戴华.基于Nginx和Memcached的高并发WEB服务器设计[D].上海:复旦大学,2013.
[11]王珊,王会举,覃雄派等.架构大数据:挑战、现状与展望[J].计算机学报,2011, 34(10):1741-1752.
[12]郭峻峰,倪志伟,高雅卓等.一种提高数据仓库查询效率的有效方法[J].计算机集成制造系统,2009,15(12):2451-2457.
[13]谭磊,顾国强,王占宏.基于优化器的提高海量数据查询效率方法研究[J].计算机应用与软件,2012(1):207-210.
(编辑:王天鹏)
1888501705276
猜你喜欢
前线(2020年3期)2020-03-13
医学信息(2019年20期)2019-12-02
现代农业科技(2019年10期)2019-07-03
中国医药科学(2019年2期)2019-06-10
活力(2019年21期)2019-04-01
中国卫生产业(2018年30期)2018-05-14
中国卫生(2014年1期)2014-11-12
江苏年鉴(2014年0期)2014-03-11
