
基于改进YOLOv3 的树上成熟芒果检测方法
2021-03-17 06:43:54李国进黄晓洁李修华
沈阳农业大学学报 2021年1期
李国进,黄晓洁,李修华
(广西大学 电气工程学院,南宁530004)
芒果是我国盛产的热带水果之一, 目前它的采摘工作主要依靠人工完成。 采摘工作耗费大量的人力和时间,导致其生产成本较高。利用机器视觉的方法识别和定位树上芒果,有利于实现芒果的机器采摘,从而降低芒果的生产成本,提高其生产效率。传统基于视觉的芒果检测主要依据果实的颜色、形状和纹理等特征,或是使用简单的BP 神经网络来完成检测任务[1-4]。 如HUSSIN 等[5]利用颜色特征除去与芒果颜色无关的背景,使用霍夫变换进行目标检测,检测精度只有60%。 PAYNE 等[6]利用密集像素分割方法,提取超级像素中SIFT 算子,设计基于颜色和椭圆形状的模型,检测夜间采集的树木冠层图像中的芒果,算法检测正确率达到84%。张烈平等[7]运用BP 神经网络技术,对损伤芒果进行不同等级的分类,识别芒果的准确率达85.5%。 在受到光照、枝叶遮挡和果实重叠的影响下,传统方法识别果实的准确度较低,耗时较长,无法满足现代农业中果实智能化收获的需求。
目前,对于水果的目标检测方法主要采取深度学习的方法,利用深度卷积神经网络自动学习到图像中目标的隐含特征,解决了上述传统方法的不足问题,也为实现树上芒果的检测提供了新的方向[8-10]。 薛月菊等[11]通过设计带密集连接的Tiny-yolo 网络结构,复用和融合了网络的多层特征及语义信息,对于未成熟芒果的检测取得了97.02%的准确率。 彭红星等[12]使用改进的SSD 深度学习水果检测模型对脐橙、苹果、皇帝柑和荔枝4 种水果在各种环境下进行检测,平均检测精度达到88.4%。岑冠军等[13]采用Faster R-CNN 深度学习模型构建了芒果图像识别算法,对芒果图像的计数识别准确率达到82.3%;熊俊涛等[14]结合残差网络和密集连接网络,构成Des-YOLOv3 网络结构,实现夜间复杂环境下对成熟柑橘的检测,平均精度为90.75%,检测速度为53FPS。为提高自然环境中树上芒果检测算法的适用性、准确性和高效性,以实现芒果果实的机器采摘,减少人工采摘作业耗费的成本,综合考虑算法的实时检测性和准确性,本研究提出改进的YOLOv3 算法对不同颜色和种类的芒果进行检测。 所提方法以YOLOv3 作为芒果果实检测的基础框架, 采用引入密集模块和eSE 模块的改进SE_ResNet50 网络作为新的特征提取网络,并与其他不同主干网络或基础框架的检测方法在芒果图像数据集上进行对比试验。
1 材料与方法
1.1 图像采集与扩增
在自然条件下采集不同树上的芒果图像,对图像中的芒果果实进行人工标注,建立目标检测的训练集和测试集;本研究采用的树上芒果图像数据集由在芒果成熟阶段拍摄的果园芒果照片构成,在不同时间段采集了不同距离、方向和角度的芒果图像。 初始经过筛选后的数据集的总共数目为360 张图片,包含了顺光、逆光、近距离、远距离、部分遮挡、颜色和种类各异等情况。 经过随机亮度、随机对比度、随机饱和度、水平镜像翻转和随机裁剪等图像增强方式,将数据集扩增至3200 张的图像,并随机划分其中的2500 张为训练集(含3487 个芒果目标),剩下的700 张为测试集(含1656 个芒果目标)。 图1 为部分芒果数据集图像。
1.2 图像标注
由于YOLOv3 模型的输入数据要求具有分类标签和定位信息,所以在将训练集和测试集的图像分别统一重新命名后,还需要对每一张图像中的目标进行人工标记感兴趣区域和类别标注。本次试验使用标注工具LabelImg 完成相应的标注工作,该工具会自动保存每幅图像的分辨率大小、用户所标记的包围目标对象的矩形边界框的左上角与右下角坐标以及目标所属的类别信息,从而将筛选出来的图像数据按照PASCAL VOC2012检测标准进行标注和存储。
1.3 YOLOv3 算法原理
2015~2018 年,REDMON 等[15-17]先后提出了YOLOv1、YOLOv2 和YOLOv3 算法,将目标检测任务看作为回归问题,只需单个网络就能直接从完整的图像中预测出目标的边界框和类别概率。YOLOv3 首次利用带有残差神经网路[18]的DarkNet53 网络作为特征提取器,解决了YOLOv1 和YOLOv2 在小目标检测上不准确的问题,提出了在检测中运用多尺度特征融合和多尺度预测的策略,拥有更快的检测速度和更高的准确度。 YOLOv3 网络结构如图2。

图1 树上芒果数据集示例Figure 1 The examples of mango dataset on trees
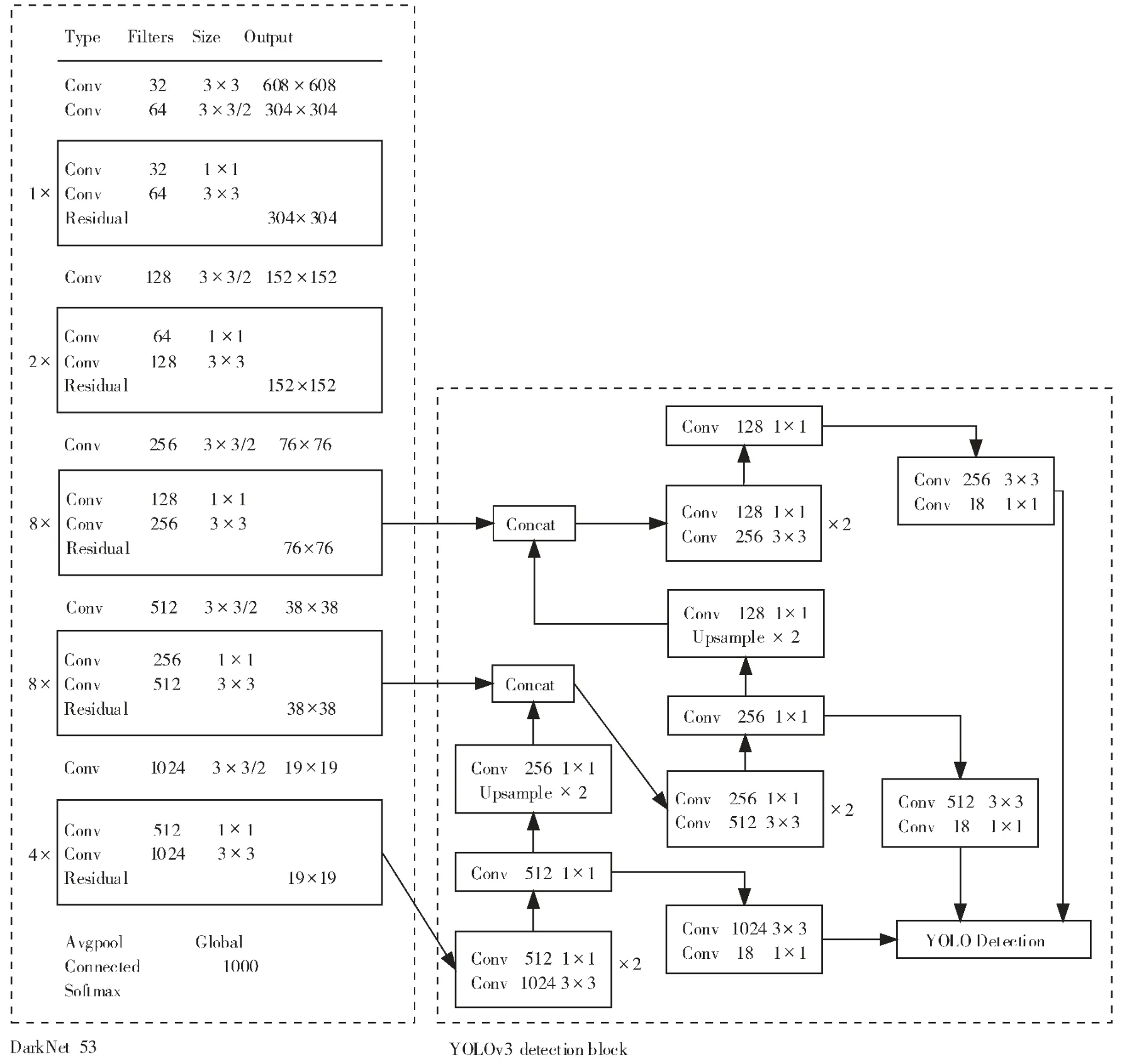
图2 YOLOv3 网络结构Figure 2 The YOLOv3 network structure
YOLOv3 算法首先将原始输入图像缩放至608×608 像素的大小,经过DarkNet53 网络进行特征提取后,得到大小为19×19,38×38,76×76 的3 个尺度的特征图(网格);其次将3 种特征图分别输出到检测模块,利用2倍的上采样(Upsample)对相邻两尺度的特征图进行串联拼接(Concat),即多尺度特征融合;最后通过非极大值抑制方式融合3 种不同尺度特征图的检测结果。 每个网格预测3 个边界框和边界框的置信度, 以及所有类的类别概率。 置信度反映了边界框的准确性和边界框包含检测目标的概率大小。 置信度的定义为:

式中:Pr为预测边界框包含目标的可能性,若含有目标,则为1,否则为0;IoU 为真实标记框与预测框的交集和并集之比。
YOLOv3 网络在每个网格上预测每个边界框的4 个坐标,即tx、ty、tw和th。其中,tx和ty为预测边界框的中心坐标,tw和th为预测边界框的宽度和高度。 假设目标中心在网格中相对于图像左上角有偏移(cx,cy),并且锚框的高度和宽度分别为pw和ph,则经过修正后的边界框坐标为:

Sigmoid 函数的定义为:

1.4 YOLOv3 算法改进
在基于深度学习的目标检测算法中,主干网络用于完成目标特征提取任务,其在图像分类上的精度和速度会影响目标检测算法的性能。 通常分类精度越高的网络提取目标特征的能力越强。 HU 等[19]提出的SE_ResNet50 网络,在ImageNet 数据集上的分类效果优于DarkNet53 网络。 因此,本研究采用SE_ResNet50 替换DarkNet53 作为YOLOv3 算法的主干网络,并借鉴密集网络思想[20]和VoVNetV2[21]的思想,对其进行改进,进一步提高模型的检测性能。 SE_ResNet50 网络主要由残差模块和SE 模块构成的SE_ResNet 模块构成。 SE模块可以让模型关注更多通道中信息量最大的特征,同时抑制通道中不重要的特征,带来模型性能的提升。 SE_ResNet50 采用的SE_ResNet 模块如图3。 输入是H′(高度)×W′(宽度)×C′(特征图通道数)的特征图X,经过不同的卷积操作(Convs)得到大小为H(高度)×W(宽度)×C(特征图通道数)的特征图U;然后,利用全局平均池化(Global Pooling)操作对U 进行“挤压”,屏蔽其空间上分布的无用信息,提取特征通道的全局信息,输出1×1×C 大小的特征图;再经过两个带不同激活函数的全连接层(FC)实现“激励”;Scale 为特征重标定操作,将FC输出的权重与U 相乘,以增强重要特征;最后将特征图U*与原输入特征图X 进行残差连接后输出。
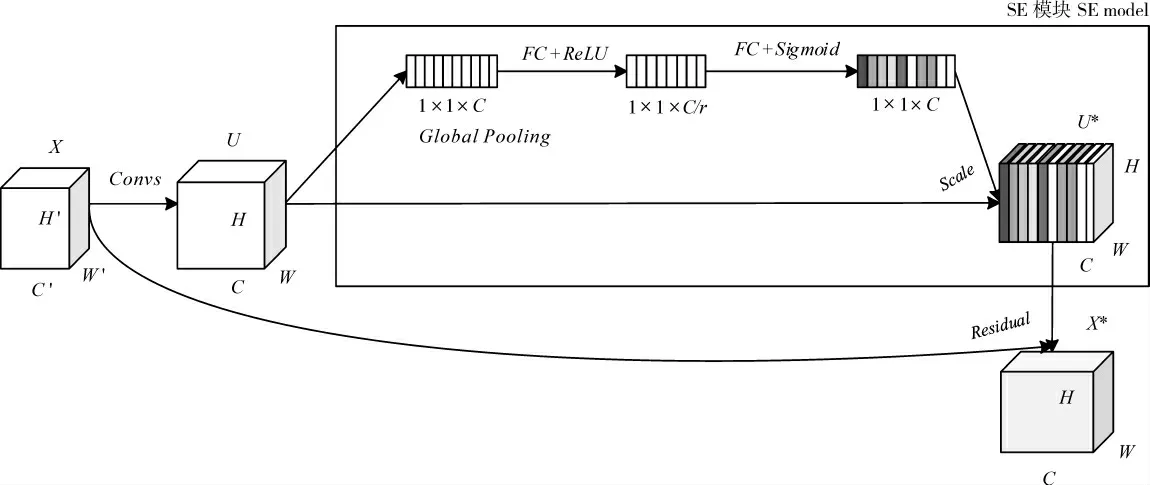
图3 SE_ResNet 模块Figure 3 The schema of the SE_ResNet model

SE 模块中的首个全连接层的主要作用是降维,在一定程度上会造成特征信息丢失,去掉该层,并将保留的全连接层中的Sigmoid 激活函数改成与其数值近似而计算量更小的Hsigmoid 激活函数,得到eSE 模块[21],图4。在模型中使用eSE 模块,能够有效增强提取到的特征信息,使模型性能得到改善。 其中HSigmoid 函数的定义为:密集网络以前馈的方式将每个密集模块中的所有层连接起来,使每一层的输入都包含了其之前所有层的特征图。 通过层间连接有效缓解梯度消失问题,加强特征的传递和复用,同时降低计算量。 假设一个密集模块含有L 层,其第l 层由前面l 个层的输出作为输入,第l 层的输出也会作为其余L-l 层的输入,则该密集模块共包含L×(L+1)/2 个连接。 密集模块中的第l 层输出为:

式中:[x0,x1,…,xl-1]为第l 层之前的输入特征图拼接;Hl(·)为非线性组合函数,由批量归一化(BatchNormalization,BN)操作、ReLU 函数、Conv1×1、BN 操作、ReLU 函数和Conv3×3 组成。
本研究采用的密集模块如图5。 共有4 层,大小为19(高度)×19(宽度)×1024(特征图通道数)的输入层x0,经过H1、H2、H3操作后,得到大小为19×19×1120 的特征图x3。x3层融合了前3 层x0、x1和x2的特征信息,达到多层特征复用的效果。

图5 密集模块Figure 5 The schema of the Dense Block
本研究算法采用密集模块替换SE_ResNet50 中的最后3 个残差模块,使网络深层充分利用各层之间的特征,实现芒果特征的多层复用和融合,并在密集模块之后增加eSE 模块和残差连接以进一步增强特征,提升模型性能。 改进后的YOLOv3 网络结构(ISD-YOLOv3)如图6。
ISD-YOLOv3 采用改进的SE_ResNet50 网络提取芒果图像的特征, 输出76×76×512 维、38×38×1024 维和19×19×1120 维的特征图; 接着通过连续使用1×1 和3×3 大小的二维卷积层、2 倍上采样操作和串联拼接等操作实现多尺度特征融合与预测;由3 个不同尺度特征图的反复训练确定模型的权重参数,最终在测试阶段输出带有分类和定位信息的树上芒果测试图像。
2 试验测试与结果分析
2.1 试验平台
本试验是在配置为CPU Intel Core i3-8100、英伟达Tesla V100 显卡、主频3.6GHz 和内存8G 的PC 端上完成。 使用的操作系统为Windows10 专业版,训练和测试框架均为Python3.7.3 环境下的PaddlePaddle1.7.1 机器学习开发框架。
2.2 模型参数选择
本试验对象为3200 张自然环境下的树上芒果图像,其中2500 张为训练集,700 张为测试集。 在模型训练过程,设定网络中的目标类别数为1,权重衰减系数为0.0005,批量大小为8,迭代次数为14000 次;每次训练输入图像的分辨率从设定的多尺度集{320, 352, …, 608}中随机选择一个尺度进行训练,并通过随机裁剪、随机调整饱和度、曝光量以及色调等方式增强训练样本,提高网络对不同分辨率输入图像的泛化能力和准确性;初始学习率为0.001,当网络训练迭代7000 次和9000 次时,学习率依次降低为0.0001 和0.00001,防止网络出现过拟合。 在测试阶段,使用的批量大小为8,IoU 阈值为0.7,类别分数阈值为0.05,输入图像的分辨率大小固定为608×608 像素。
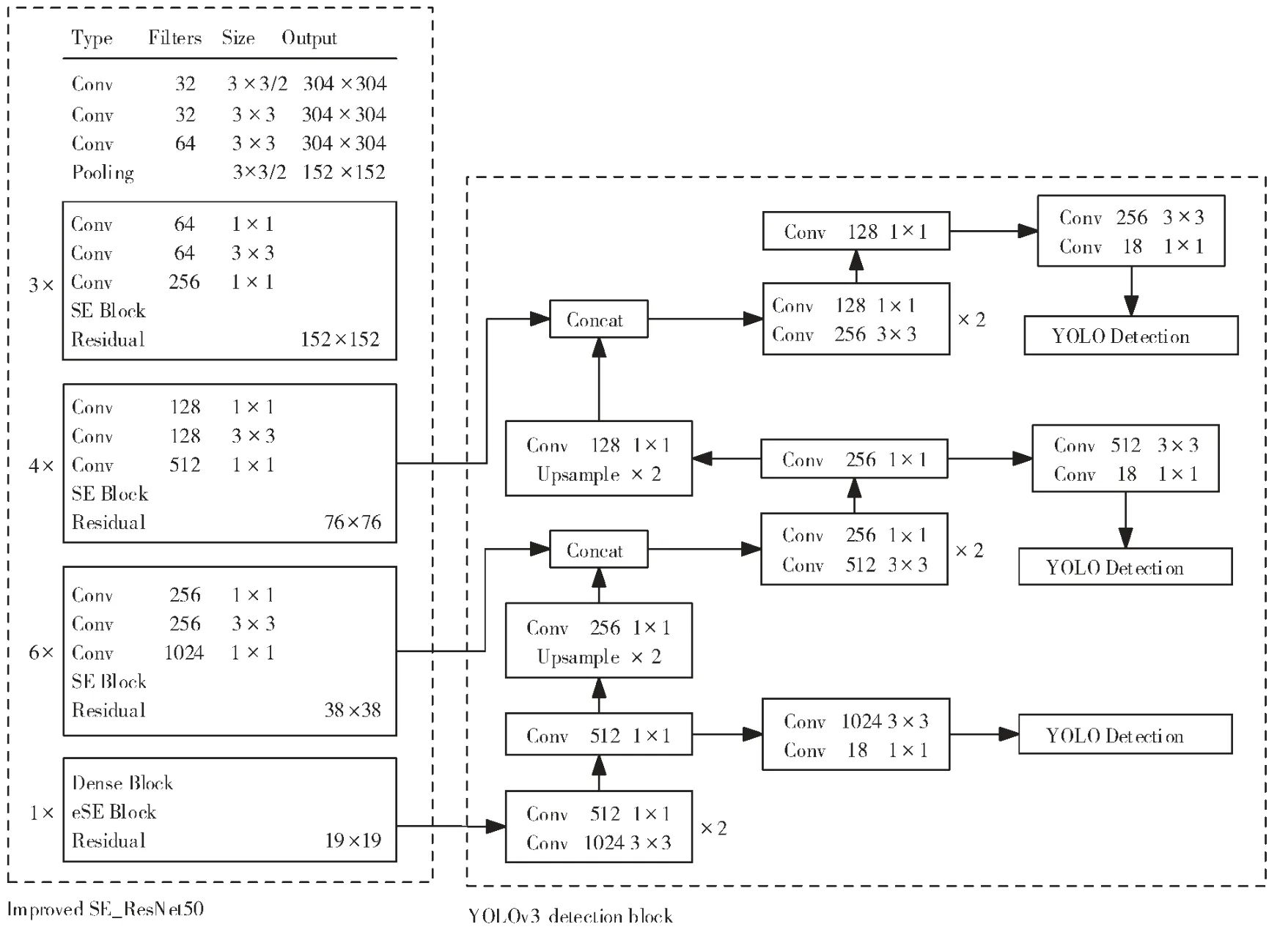
图6 ISD-YOLOv3 网络结构Figure 6 The ISD-YOLOv3 network structure
2.3 试验测试结果及分析
为更准确地表现本研究所提出模型的性能,试验使用目标检测中常用的平均精度(AP)和每秒检测的图片数量(FPS)作为模型的评价指标。 AP 是衡量网络结构对目标物体敏感度的标准之一,AP 数值越高就说明卷积神经网络的检测精确度越高。其计算方式与准确率(Precision, P)和召回率(Recall, R)有关。假设预测框与真实标记框的交并比大于IoU 阈值,则将该预测框归为正样本,否则为负样本。 准确率P(%)和召回率R(%)计算公式为:
式中:TP 为正样本正确检测数量;FP 为正样本错误检测数量;FN 为未检测出的真实标记框数量。
本研究AP 的计算方式采用COCO 数据集评价方式中的101 点插值法,即分别选取[0,0.01,…,1]101 个不同的召回率数值,计算每个数值对应的最大准确率,将其求和后取平均得到AP:

式中:r 为召回率;r′为101 个不同的数值。
通过调用训练过程保存的模型参数文件,即生成的权重文件,可对芒果数据集中的图片进行相应的测试,测试后可自动识别并定位测试图片中的芒果,显示相应的定位信息和类别信息。 试验对于单个树上芒果的部分测试结果如图7。图中红色的矩形边界框对目标芒果做出了定位,边界框的左上角标明了该目标的类别为芒果和被识别为芒果的概率。由图7 可知,模型能够很准确地定位和识别单个不同条件下的芒果;图7c 虽然有小部分的遮挡,也不影响目标检测的准确性。 对于含有多个果实且有重叠的芒果图像检测结果示例如图8,除了个别被严重遮挡的果实外,对于含有小部分重叠的芒果,模型依旧能够正确识别并准确定位,说明本研究算法对于芒果的检测具有良好的检测性能。

图7 单个树上芒果测试结果实例Figure 7 The result of single mango test

图8 多个树上芒果测试结果实例Figure 8 The result of multiple mangoes test
为进一步验证本研究算法的检测效果,在同等的试验平台和模型参数下,使用相同的树上芒果数据集,分别在YOLOv3_DarkNet53、YOLOv3_SE_ResNet50、Faster R-CNN[22]以及本研究算法ISD-YOLOv3 共4 种不同算法模型上进行算法的训练与测试。部分测试结果如图9。试验在测试集上获得的平均精度AP、检测速度以及网络模型大小的统计结果见表1。
由图9 可知,由于图像1 中的芒果被叶片遮挡面积较大,只有YOLOv3_SE_ResNet50 和本研究算法ISDYOLOv3 能够正确检测出,YOLOv3_DarkNet53 和Faster R-CNN 算法出现了漏检;图9 中的图像2 含有3 个芒果果实,其中一个果实面积很小,其他3 种算法未能检测出,本研究算法能正确识别并定位的芒果数量最多,说明本研究提出的ISD-YOLOv3 目标检测算法召回率更高,检测目标更准确。
由表1 可知,由于SE_ResNet50 网络引进了可以增强通道特征的SE 模块,采用其作为YOLOv3 算法的主干网络,与原来使用的DarkNet53 算法相比,在保持较高检测速度的同时,平均精度AP 提高6%;本研究的算法ISD-YOLOv3 通过将SE_ResNet50 的部分卷积层改为密集模块结合eSE 模块及残差连接,增强网络的特征复用,使AP 提高至94.91%,检测速度达到85FPS,在精度和和速度上都明显高于其他3 种算法。 结果表明,ISD-YOLOv3 网络规模更小,提高了目标识别精度和速度,可很好地用于水果采摘机器人的定位检测。

图9 不同算法模型检测结果示例Figure 9 Detection results of different algorithms
3 讨论与结论
HUSSIN 等[5-6]采用基于手工特征的传统方法识别芒果, 人工选取果实的颜色和椭圆形状作为特征,由于环境的多样性变化容易使这些特征发生明显改变,造成识别的精度较低,因而适用性不高。 本研究采用基于深度学习的目标检测算法,通过卷积神经网络自动学习目标隐含的特征,对树上芒果进行检测。 其中的Faster R-CNN[22]算法利用区域建议网络(RPN)生成检测框,YOLOv3[17]算法使用检测模块生成检测框,与YOLOv3 的检测模块相比,RPN 包含更少的卷积层,但能生成更多的检测框。 因此,Faster R-CNN 在网络结构上比YOLOv3 小,检测的平均精度较高,而检测速度仅有6 FPS,无法满足高效的机器采摘作业需要的最低实时速度30 FPS。由于YOLOv3 生成的检测框数远少于Faster R-CNN,导致其检测精度较低,但其能达到78 FPS的实时检测速度。 本研究综合考虑了算法的精度和速度,选择YOLOv3 作为芒果检测方法的主要框架,采用在分类任务上精度更高的SE_ResNet50 网络替换DarkNet53 网络,能够提取芒果图像中更多的果实通道特征,在保持较高的实时检测速度的同时,提高了检测精度;采用密集模块和eSE 模块改进SE_ResNet50 网络,可以减少模型参数,加强深层卷积层中特征信息复用与融合,进一步提高芒果检测的实时速度和精度。

表1 不同检测算法性能对比Table 1 Comparison of different detection algorithms
本研究结果表明,提出的ISD-YOLOv3 方法对于自然环境下的树上芒果果实检测具备更加良好的实时性、准确性和鲁棒性,为现代农业的果实智能化收获提供了新的方法。 此外,如何提高识别重叠度较大且目标很小的果实的准确度和减少人工标注样本将是今后研究的主要方向。
猜你喜欢
动漫界·幼教365(中班)(2020年3期)2020-04-20 11:03:27
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
电子制作(2018年11期)2018-08-04 03:25:38
动漫界·幼教365(小班)(2018年10期)2018-05-14 11:52:11
动漫界·幼教365(大班)(2018年10期)2018-05-14 11:50:49
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
河南科技(2014年23期)2014-02-27 14:19:15
