
基于神经自回归分布估计的涉案新闻主题模型构建方法
2021-03-17 08:04毛存礼梁昊远余正涛郭军军黄于欣高盛祥
中文信息学报 2021年2期
毛存礼,梁昊远,余正涛,郭军军,黄于欣,高盛祥
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500)
0 引言
涉案新闻是指与司法案件相关的新闻,准确抽取涉案新闻主题信息对进一步开展涉案新闻检索、涉案新闻事件分析等研究具有重要价值。传统主题模型主要考虑词频统计特征,而忽略了文档中的词语出现的次序及上下文信息[1-2]。例如,“窃取”一词,可以是窃取个人财产,也可以是窃取国家机密,但是案件性质完全不同,前者涉及盗窃罪,而后者则是触及了非法获取国家秘密罪。神经主题模型由于能够获得文本的深层语义信息,既可以捕获文中词汇之间的局部依赖关系,又可以利用潜在主题捕获全局语义信息,有效弥补传统主题模型的缺陷,近年来在文本检索、文本分类、文本摘要等自然语言处理任务中表现出较好的效果[3-11]。
案件要素是案件关键信息的体现,涉案新闻与普通新闻的根本区别在于是否出现案件要素。对涉案新闻主题分析的核心是对案件要素相关词汇的主题进行预测,故可以将案件要素作为涉案领域知识来捕获文本中涉案相关词语的主题分布和文本的主题表征。然而,现有的神经主题模型忽略了领域知识对特定领域主题分析任务的作用。为此,本文针对涉案新闻主题分析任务,提出一种基于神经自回归分布估计的涉案新闻主题模型构建方法,是对Gupta 等人[3]提出的神经主题模型(document informed neural autoregressive topic models with distributional prior,iDocNADEe)的进一步扩展,把案件要素作为涉案领域知识,通过计算案件要素与涉案新闻文本中主题词的相关度构建注意力机制,对文本经过双向语言模型编码后的前后向隐状态进行加权,以此增强涉案新闻文本中主题词的涉案语义特征表示,最后利用神经自回归算法计算加权后双向隐状态的自回归条件概率实现涉案新闻文本主题抽取。在构建的涉案新闻数据集上进行了实验,结果表明,所提方法较iDocNADEe模型困惑度降低了0.66%、主题连贯性提高了6.26%;将构建的涉案新闻主题模型用于涉案新闻检索对比实验,准确率也明显高于基线模型。
本文第1节介绍主题模型的相关工作;第2节描述基于神经自回归分布估计的涉案新闻主题模型构建方法;第3节通过实验对比了所提方法在主题构建及文本检索方面的优势;第4节进行总结并提出未来的研究方向。
1 相关工作
随着狄利克雷多项式混合模型(dirichlet multinomial mixture,DMM)[1]、潜在狄利克雷分布(latent dirichlet allocation,LDA)[2]等概率主题模型的广泛应用,越来越多的研究聚焦于如何将主题模型应用于各类特定领域的自然语言处理任务。如张绍武等人[12]基于一种动态主题模型实现了新疆暴恐舆情分析;吴彦文等人[13]基于LDA模型与长短期记忆网络(long short-term memory,LSTM)模型实现了短文本情感分类;陈琪等人[14]基于支持向量机和LDA模型提出了一种评论分析方法。上述方法普遍基于早期的概率主题模型,而这些概率主题模型存在泛化能力弱、主题可解释性差等缺陷。基于神经网络的方法来构建主题模型能有效解决这些问题。Cao等人[4]提出了基于前馈神经网络的主题模型(neural topic model,NTM),该模型将传统主题模型的主题—词分布以及主题—文档分布转换为两个权重矩阵,并使用了后向传播(back propagation,BP)算法训练参数。Kingma等人[5]在2014年提出变分自编码器(variational auto-encoder, VAE),能够训练一个直接将文档映射到后验分布的神经网络。因此,Miao等人[6]使用VAE构建了一种神经变分文档模型(neural variational document model, NVDM),并在此基础上加入主题—词分布,进而形成了基于VAE的主题模型。基于Larochelle等人[7]提出的神经自回归分布估计器(neural autoregressive distribution estimator, NADE),Lauly等人[8]提出了一种生成式主题模型——文档的神经自回归分布估计(document neural autoregressive distribution estimator, DocNADE),通过词的序列学习主题,即对某个词vi进行预测时,需要其前文作为输入。对比于概率主题模型,神经主题模型能够更好地利用词汇之间的语义相似度。随着循环神经网络的发展,文档的词序列作为输入能够更加充分利用词汇的上下文信息。Dieng等人[9]利用循环神经网络(recurrent neural network, RNN)捕获词之间的依赖,结合循环神经网络与主题模型提出了TopicRNN。Lau等人[10]利用卷积神经网络 (convolutional neural network,CNN)和LSTM提出了主题-语言模型联合训练模型(topically driven language model,TDLM),利用CNN提取文本特征,并使用LSTM刻画词汇之间的语义,将文本的主题信息与LSTM的隐藏层结合。这两种模型可认为是多任务学习模型,由主题推断和文本生成两个子任务组成,由此模型生成的文本语义更加自然,但这些方法更加侧重于对语言模型的优化。
Gupta等人[11]利用LSTM语言模型,经过训练后能够根据给定词序列来预测后续单词的特性,提出了基于词嵌入的语境化文档神经自回归分布估计器(contextualized document neural autoregressive distribution estimator with embeddings, ctx-DocNADEe),但并没有考虑到文档的双向语义。而Gupta等人[3]受双向语言模型[15]和递归神经网络[16-17]的启发,提出了一种纳入完整上下文语义信息的主题模型(document informed neural autoregressive distribution estimator with embeddings, iDocNADEe),该模型将上下文同时作为输入,并引入Glove词嵌入作为先验知识,将语言模型的预测方式应用到了主题模型。通过对以上工作的分析可以看出,无论是传统主题模型还是神经主题模型,都是基于通用领域,而在涉案领域暂无相关研究。因此,我们考虑如何将这些方法应用到涉案领域以获得更好的主题表示。
2 基于神经自回归分布估计的涉案新闻主题模型
2.1 涉案新闻案件要素库构建
案件要素是指案件的内在组成部分及各部分之间的相互关系和排列状况,如刑事案件由何事、何时、何地、何物、何情、何故、何人等7要素构成,对案件构成要素进行分析能够从根本上把握案件发生、发展的趋势和规律[18]。对于涉案新闻主题抽取任务,分析涉案文本与案件要素之间的关联关系有助于提高涉案主题分布的准确性。为构建案件要素库,我们从互联网中收集了有关重庆公交坠江案、丽江唐雪反杀案、昆明孙小果涉黑案等刑事案件的相关新闻,并基于韩鹏宇等人[19]的方法定义且抽取了涉案新闻中的案件要素,包括“案件名称、涉案人员、涉案地点、涉案触发词”,为涉案新闻主题建模提供了领域知识。以涉案新闻“还女司机清白!重庆万州公交坠江系乘客殴打公交车司机导致!”为例,其案件要素构成如表1所示。
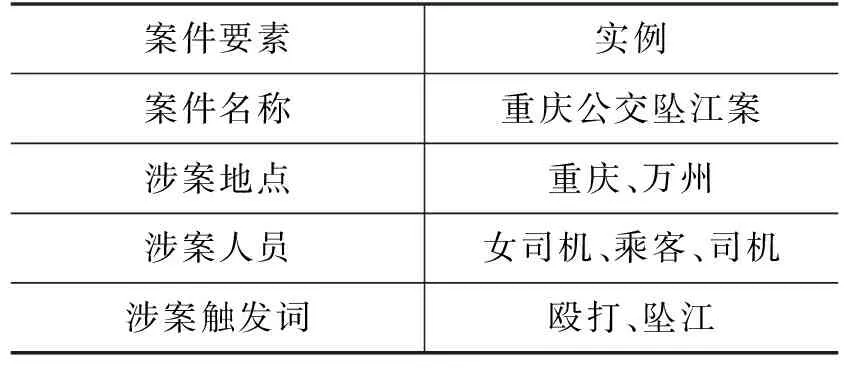
表1 案件要素实例
其中,涉案地点可能是案件中涉及到的地名,可能是省份、城市或更加具体的场所。涉案人员包括案件中涉及的人员,如嫌疑人、受害人、目击者等。涉案触发词指某些与司法领域相关或描述案件关键的词,如表1中的“殴打”及“坠江”。
2.2 融合案件要素的涉案新闻主题建模
2.2.1 基于神经自回归分布估计的主题模型
作为一种无监督的生成式主题模型,iDocNADEe的结构如图1(a)所示,该模型从文档中抽取其潜在特征,并据此重新生成文本,以生成文本的对数似然函数为最终的优化目标。

图1 iDocNADEe和本文模型架构,虚线框内代表本文所加入的案件要素注意力机制
首先,将一篇词数为D的文档表示为一个序列v=[v1,v2,…,vD],其中vi∈{1,…,V}表示文档中第i个词在词表中的位置,V表示语料库词表的大小。
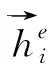


图2 前向隐状态的计算
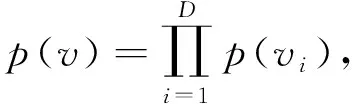
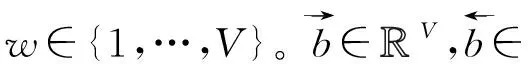
由此,任意文档的对数似然函数如式(5)所示。
(5)
2.2.2 融合案件要素特征构建的注意力机制

首先,本文模型的输入不仅包括了新闻的文本序列v,还有案件要素集合k=[k1,…,kn]。与文本隐状态计算类似,我们首先计算案件要素的前后向隐状态,如式(6)、式(7)所示。

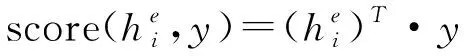
最终我们通过式(5)、式(14)、式(15)计算融入了案件信息的生成文档的对数似然函数。
2.3 模型训练
在模型的训练过程中,直接由式(14)、式(15)进行计算会导致计算成本过高,因此我们遵从Gupta等人[3]的实验设计,使用二叉树进行计算(见算法1)。在二叉树中,从根到叶子的每个路径都对应一个词汇[20-21]。树中每个节点向左(或右)的概率由一组二元逻辑回归模型建模,然后通过这些概率来计算给定词的概率。

算法1 使用二叉树计算涉案新闻文档的对数似然函数p(v)算法伪代码
算法1展示了我们的模型如何在案件要素的指导下计算每篇涉案新闻的对数似然函数。其中,第6~9行展示了我们如何结合案件要素和注意力机制对新闻隐状态进行加权。而第12~15行表示了如何使用二叉树来降低模型的计算成本,l(vi)表示从根到词vi的路径上的树节点的序列,而π(vi)表示这些节点中的每个节点的左(或右)选择的序列[例如l(vi)1将始终是树的根,如果词vi的叶子节点在其左子树中,则π(vi)1为0,否则为1]。因此,现在每个词的自回归条件的计算如式(16)~式(19)所示。

2.4 涉案新闻主题信息抽取
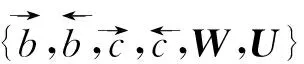
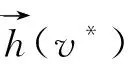
(20)
3 实验与结果分析
3.1 数据集
针对涉案新闻文本主题模型构建任务,由于目前还没有可用的公开数据集,本文使用的涉案新闻数据通过网络爬虫技术从新闻网站、微博以及微信公众号爬取了近年来部分热点案件的相关新闻,如重庆公交坠江案、丽江唐雪反杀案、孙小果涉黑案等。经过分析发现与案件相关的新闻正文的长度不均衡,而且文本中包含了大量的噪声,但新闻标题基本上都包含了跟案件相关的一些信息,如案件名称、涉案人员等重要信息。为此,本文仅选择了涉案文本的标题信息来构建涉案文本数据集,我们使用HanLP(1)https://github.com/hankcs/HanLP对其进行分词,并按照7∶3的比例划分训练集与测试集。数据集具体信息如表2所示。
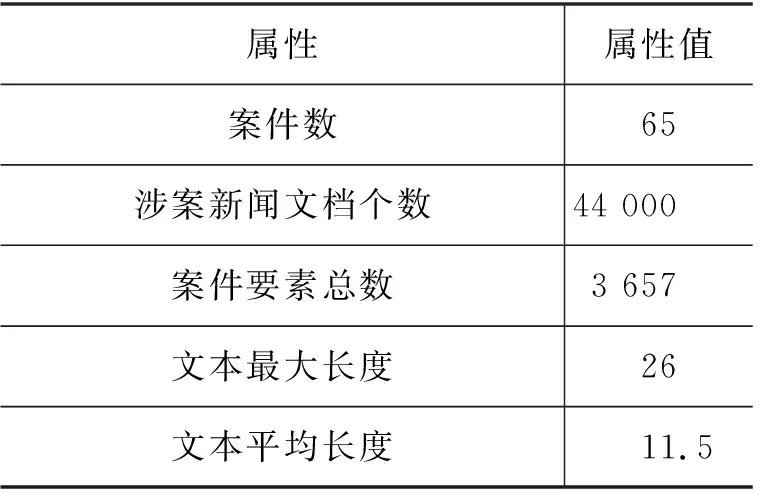
表2 本文数据集的属性
3.2 实验参数设置
实验涉及参数如表3所示。

表3 本文实验中各参数的设置
3.3 预训练词向量
在模型中,词向量作为对主题信息的补充,因此其维度需要与主题数一致,分别为50/200维,考虑到目前中文并没有基于大规模语料训练的开源50/200维词向量,我们利用开源库gensim中的Word2Vec工具包,联合了从中国裁判文书网爬取的裁判文书和本文中使用的语料(数据共计17GB)以及开源中文新闻语料 (news2016zh)(2)https://github.com/brightmart/nlp_chinese_corpus训练词向量,词向量的维度为50/200维。
3.4 评价指标
(1) 困惑度(perplexity)
困惑度(PPL)用于检验主题模型的泛化能力,困惑度越低,则代表模型具备的泛化能力越好。我们通过计算测试集中涉案新闻的困惑度来评估主题模型作为生成模型的文档生成能力。困惑度的计算如式(21)所示。
(21)
其中,N是新闻数量,|vt|则代表每篇新闻t∈{1,…,N}中的词汇数量。logp(vt)由式(5)得到。
(2) 主题连贯性(topic coherence)
我们使用了Röder等人[22]提出的自动度量指标CV来验证模型产生的主题的连贯性,并使用开源工具gensim(3)(radimrehurek.com/gensim/models/coherencemodel.html, coherence type=c_v)来完成这一项指标的计算。
该指标使用参考语料库上的滑动窗口来确定每个主题词的上下文特征。该指标越高,即代表主题的连贯性越好,主题模型效果越好。遵从Gupta等人[3]的实验设计,上下文滑动窗口的大小被设置为110。
3.5 基线模型
本文选择了在ICLR、AAAI等会议发表的几个具有代表性的神经主题模型作为基准模型。
(1)DocNADE[8]: 由Lauly等人提出的一种神经主题模型,作为NADE和RSM的扩展模型,该模型使用神经自回归估计对文本进行主题建模。
(2)TDLM[10]: 由Lau等人在ACL2017提出,该模型是一种基于卷积神经网络、注意力机制以及LSTM网络的双神经网络模型,是一种多任务学习模型,由主题推断与文本生成两个子任务组成。
(3)ctx-DocNADEe[11]: 由Gupta等人在ICLR2019提出,该模型在DocNADE的基础上引入了LSTM语言模型和Glove词向量,其文本的隐藏状态由三者共同计算得到。
(4)iDocNADEe[1]: 同样是DocNADE的扩展版,由Gupta等人在AAAI2019提出,详情见2.2节。
3.6 实验结果与分析
第一组实验是本文提出模型与4个基准模型在涉案新闻数据集上,主题数H设置为50时的困惑度(PPL)对比,实验结果如表4所示。
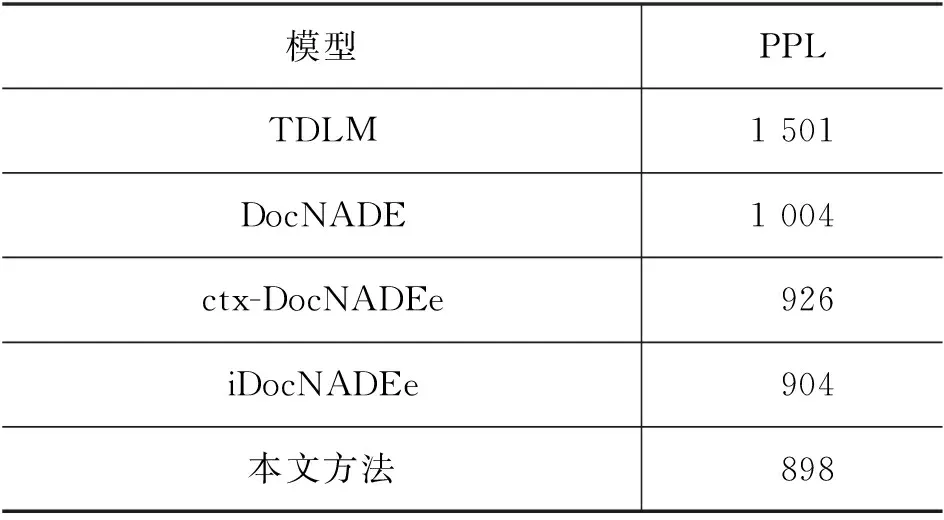
表4 本文方法和基准模型困惑度对比
根据表4可以看出, TDLM模型的困惑度最高,即该模型的泛化能力最差,我们认为这主要因为该模型是一种双任务模型,并且主要目标在于优化语言模型,因此其主题模型的效果并不明显。而本文提出方法的困惑度最低,较基线模型降低了0.66%,说明了案件要素通过注意力机制融入主题模型中的确可以提升生成文本的质量,并且可以提升模型的泛化能力。虽然提升的效果有限,但主题模型的生成能力仅代表了主题模型的一项能力,我们更加注重主题的质量,即主题连贯性和基于主题的文档检索效果。
主题连贯性能够评估模型所发现的主题的意义。本文第二组实验对比了本文提出方法与4个基准模型在涉案新闻数据集上,主题数H设置为50时的主题连贯性,实验结果如表5所示。其中T10和T20分别代表每个主题取前10个以及前20个主题词计算出的主题连贯性。

表5 本文方法和基准模型主题连贯性对比
根据表5的实验结果可以看出,TDLM模型所得到的主题连贯性分数最低,即该模型得到的主题词的语义连贯性较差,因为其主要目的是通过主题模型来优化语言模型,而DocNADE只考虑了文本的前向序列,并没有考虑反向序列,因此其效果较拓展类模型较差。而其他两种方法都考虑了文章的上下文信息,所以效果有明显提高。而本文方法取得的主题连贯性最高,10个主题词时,效果较基线模型提升了6.26%,20个主题词时,效果提升了8.78%,这也表明基于案件要素的注意力机制能够帮助模型找到连贯性更好的主题。
为了进行词汇向量表示的测试,本文使用构建的涉案新闻数据集对所提出的模型进行了训练,并使用W:,vi作为每个词汇的向量表示(200维)。我们选取了三个词汇以及与其相似度最高的5个词汇进行展示,此处的相似度由余弦相似度计算得到。实验结果如表6所示,其中sy,sw分别代表使用本文提出方法计算得到的词的向量表示与使用Word2Vec训练得到的词的向量表示所计算出余弦相似度。
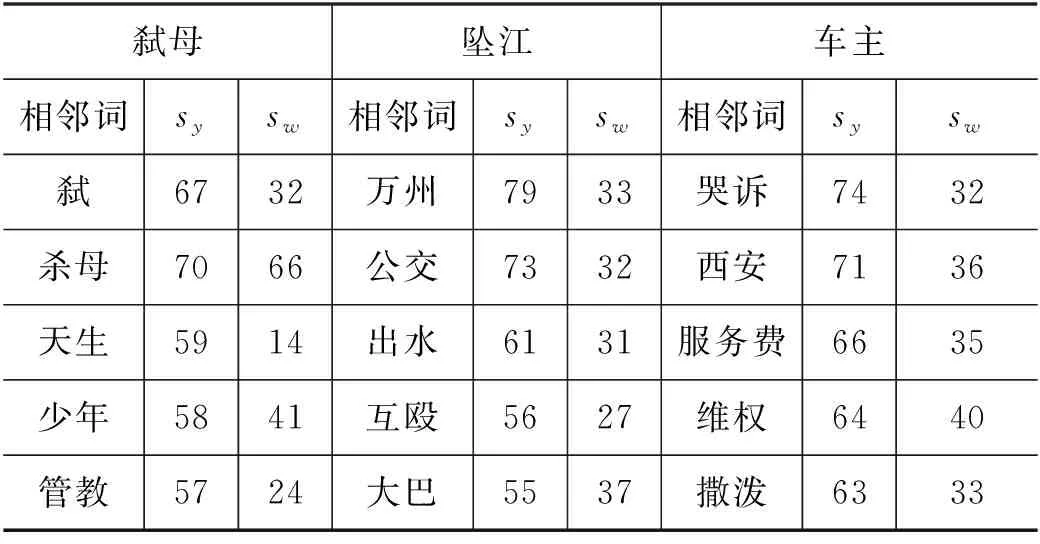
表6 词汇向量表示对比(%)
根据表6的实验结果可以看出,通过训练,我们提出的方法抽取到的主题词跟案件要素具有更大的语义相关性。
主题模型的一个重要用途就是得到文档的主题信息。我们通过执行一个涉案新闻检索任务以评估本文所提出方法以及对比方法所得到的新闻主题信息的质量。我们使用式(20)来抽取每篇新闻的主题信息,并将训练集中的新闻用作检索,而测试集中的新闻用作查询。
本文设置了多组不同的检索分数(fraction of retrieved documents)以进行对比。我们将用作查询的新闻的主题信息与所有检索集中的新闻的主题信息做相似度计算,返回相似度最高的前Np条新闻。Np的计算如式(22)所示。
Np=Nr*检索分数
(22)
其中,Nr是检索集的新闻数量。最终我们通过查询新闻的标签和返回的Np条新闻的标签计算检索精确率。新闻检索系统的精确率表示在检索到的文档中,相关文档所占比例。已知混淆矩阵如表7所示,则精确率计算如式(23)所示。

表7 新闻检索系统中的混淆矩阵
(23)
结果如图3所示,纵轴代表各模型取得的精确率,横轴代表检索分数。可以看到,检索分数与精确率成反比,因为检索分数越高,代表返回的新闻数量越多,而检索到无关新闻的数量也就越多,直接导致精确率的降低。当检索分数为1%时,检索系统所返回新闻的数量恰好与检索集中一个类别新闻的平均数量相近,当检索分数继续升高时,返回的新闻几乎都是无关新闻,因此精确率大幅度降低。但无论检索分数的高低,利用我们提出模型所抽取的主题信息获得的检索精确率始终是最高的。这是因为我们将案件要素融入模型,因此模型所抽取的主题信息包含了案件信息,质量也就越高。这也证明了本文使用案件要素信息对模型进行注意力加权指导是有效的。
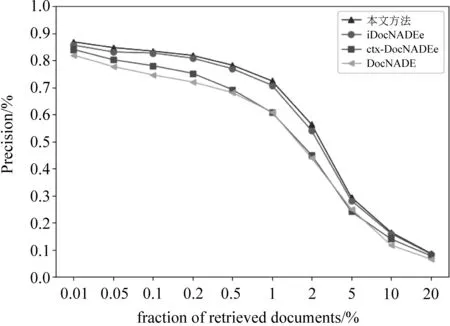
图3 各模型的文档检索精确率对比
4 结束语
由于现有的主题模型忽略了上下文信息及外部知识对词语主题分布的帮助,本文对iDocNADEe模型做了进一步扩展,提出了一种基于神经自回归分布估计的涉案新闻主题模型构建方法。该方法通过融入案件要素作为外部知识,能较好地解决神经主题模型在涉案新闻领域效果不佳的问题,并能获得更低的困惑度以及更好的主题连贯性,在涉案新闻检索实验中也获得了更佳的性能。我们将在下一步工作中,研究如何利用除案件要素外的涉案领域知识,如裁判文书和法律条文等对涉案新闻主题模型的帮助。
猜你喜欢
客联(2022年3期)2022-05-31
中国药学药品知识仓库(2022年7期)2022-05-10
中国新闻周刊(2021年26期)2021-07-27
疯狂英语·新悦读(2021年1期)2021-01-27
信息安全研究(2016年4期)2016-12-01
专利代理(2016年1期)2016-05-17
山西大同大学学报(社会科学版)(2014年2期)2014-02-06
外语学刊(2011年6期)2011-01-22
质量与标准化(2010年5期)2010-05-03
