
基于维基百科的冬奥会概念下的低频词条双语迭代扩展
2021-03-17 07:48陶明阳于济凡单力秋张馨如
中文信息学报 2021年2期
王 星,陶明阳,侯 磊,于济凡,单力秋,张馨如,陈 吉
(1. 辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105;2. 清华大学 计算机科学与技术系,北京 100084;3. 清华大学 人工智能研究院知识智能研究中心,北京 100084;4. 清华大学 北京信息科学与技术国家研究中心,北京 100084)
0 引言
随着2022年北京张家口冬季奥林匹克运动会的临近,人们对冬奥会相关知识的需求越来越大,因此有必要构建一个与冬奥会相关的垂直领域知识图谱。目前,获取冬奥会术语词条的权威途径有冬奥会术语查询网和国际奥委会官方网站,但它们都有各自的局限性。冬奥会术语查询网可查询六种语言的术语信息,但缺少历届比赛运动员、获奖运动员、举办城市、比赛场地等信息,国际奥委会官方网站可查询历届冬奥会中各项目的获奖运动员的信息,但只有英文资料可供查询。因此,有必要对已有的冬奥会术语集进行补充,类似于集合扩展[1]的工作。
目前,集合扩展已经做了很多的工作,可以将它们分成两类。早期,集合扩展的方式都是基于web完成的[2-4]。这种方法虽然有较高的准确率,但是存在时间花费较长、查询花费较大等问题。Word2Vec模型出现后,集合扩展的方式逐渐转向了基于语料库[5]的扩展,这种方法也是目前常用的集合扩展方法[6-9],但这种方法在扩展冬奥会中文术语时效果较差,原因是冬奥会相关的词条整体词频较低、数量较少,训练时收集到的语义信息[10]会有部分缺失,扩展时出现语义漂移[11]的现象,导致扩展出的新词集合中有大量噪声数据。例如,将8名冬奥会运动员作为种子集进行扩展时,生成的扩展集中包括“刘艳”“张昊”“姚明”等词条,其中“刘艳”“张昊”是冬奥会运动员,而“姚明”则是篮球运动员,出现这种问题的主要原因是种子集的平均词频较低,训练时收集到的语义信息可能是运动会而不是冬季奥运会,所以扩展集中存在大量其他运动会的词条。
已有的集合扩展方法对英文术语的扩展效果比较理想,但对中文术语的扩展效果较差。在统计数据的过程中我们发现中英文的词条中有很多跨语言[12]的同义词,例如,“跳台滑雪”和“Ski jumping”。目前网络上有很完整的跨语言数据可以供我们使用,例如XLORE[13]的跨语言同义词数据集,XLORE融合了中文维基百科、英文维基百科、法语维基百科和百度百科,是对百科知识进行结构化和跨语言链接构建的多语言知识图谱。截至2019年4月末,XLORE包含了1 628万个实体,246万个概念,44万条关系。根据上述情况,本文基于XLORE的跨语言同义词数据集提出了中英文双语迭代扩展模型(bilingual iterative extension,BIE),利用词条数量较多的英文语料库及良好的扩展效果来解决中文词条数量较少的问题。
XLORE的主要数据来源是维基百科[14],所以本文利用维基百科的冬奥会相关的条目组成的数据集进行扩展。截至2019年4月末,维基百科中的数据包括了302种语言的词条,其中包括105万条以上的中文词条和583万条以上的英文词条。但由于参与者来自世界各地,在数据量大的同时容易出现信息缺失、上下位关系[15]不准确等问题。随着维基百科上的词条越来越多,分类错误或缺失等问题会越来越严重。本文提出的统计每个新词出现频率的方法(statistical new word frequency,SWF)的扩展对象主要是因上下位关系缺失导致无法找到的词条,并用于解决冬奥会词条平均词频较低的问题,例如在图1中,概念“奥林匹克花式滑冰场馆”和概念“2014年冬季奥林匹克运动会运动场”具有两个相同的实例“冰山冬季运动宫”,且概念“冬季奥运场馆”与概念“奥林匹克花式滑冰场馆”之间存在上下位关系,所以概念“冬季奥运场馆”与概念“2014年冬季奥林匹克运动会运动场”之间有可能存在上下位关系,由于分类错误导致此条关系缺失,因此概念“2014年冬季奥林匹克运动会运动场”及其实例“谢科竞技场”和实例“阿德列尔竞技场”很有可能是我们要扩展的词条。我们将这种数据全部找到并筛选作为最终的扩展集。

图1 BIE方法候选词选择原理图
本文的主要工作是:①提出一种双语迭代扩展的方法BIE,用于解决中文种子集种子数量少的问题; ②提出了统计每个新词扩展出的数量的方法SWF,用于解决中文种子集平均词频较低的问题; ③构建了一个较完整的冬奥会领域相关术语集。
1 模型
1.1 总体框架
为了对冬奥会术语集进行补充,本文根据目前维基百科中的中文数据量少的状况,提出了BIE方法。由于实例和概念的扩展方法相同,因此本文只介绍实例的扩展方法。BIE方法基于XLORE数据集进行跨语言同义词对齐,通过迭代扩展的方式解决中文种子集数量少的问题,具体做法是先将英文的实例按英文的词条扩展方法进行扩展和对齐,将找到的中文维基百科词条进行筛选后加入到中文待扩展的种子集Sc中,再将中文的种子集Sc按中文的词条扩展方法进行扩展和对齐,找到对应的英文维基百科词条筛选后,作为新的英文待扩展的种子集Se,将以上过程作为一次迭代过程并不断进行迭代,当不会产生新的候选词或产生的候选词的平均质量较低时,结束迭代,其中每次迭代过程如图2所示。

图2 BIE方法中一次迭代过程
BIE方法通过输入中英文实例和概念的种子集S,输出中英文实例和概念的扩展集,输出的扩展集中包括迭代扩展出的数据。英文词条扩展方法和中文词条扩展方法在本文1.2节和1.3节中详细介绍。
1.2 英文词条扩展方法
已有的集合扩展方法对冬奥会英文术语集的扩展效果较好,因此本文使用Word2Vec的方法对英文的词条进行扩展。本文方法与已有方法的区别主要在于已有的方法的种子集中的种子数量较少,会因上下位关系缺失等问题导致扩展的词条数量较少,而本文使用的种子集的种子数量较多,每个候选词可通过多个路径被找到,但该方法会扩展出较多的噪声数据,针对此问题,本文将种子集Se分成若干个待扩展集Hi,Se=[H1,H2,H3,…,Hn],计算每个待扩展集Hi得分,并根据得分选取不同的扩展策略。将所有待扩展集Hi进行扩展得到所有的候选词,并根据每个候选词出现的频率进行排序,将排名靠前的候选词加入到扩展集中。
本文使用两个词条对应的词向量计算两个词条的相似度。假设两个英文词条s1、s2分别对应的词向量为e1、e2,先计算两个词条的余弦相似度,当两个词条的余弦相似度的值小于零时,两个词的相关性为负相关,我们通过观察多组种子词与得分的关系并分析,认为得分小于0时相比得分趋近0时的效果要好,且当负相关的得分约等于正相关得分乘0.5时,两组词的关系比较接近。因此,当余弦相似度得分为负数时,将余弦相似度得分取绝对值后乘以0.5后作为两个词的相似度得分。两个英文词的相似度得分区间为(0,1),其计算方法如式(1)所示。

(1)
对于种子数量为n的待扩展集Hi,我们计算每两个种子的得分,取平均值作为该待扩展集Hi的得分,得到的待扩展集Hi的得分区间为(0,1),其计算方法如式(2)所示。
为了防止扩展过程中出现语义漂移,导致候选词集合中有大量的噪声数据,本文共设置三个参数,分别是depth_max、num_max、score_min,其中depth_max表示扩展时遍历的最大层数,并且为了防止在扩展的初始就出现语义漂移现象,每个待扩展集Hi在第一层扩展时限制扩展数量。具体地,将第一层扩展后的所有候选词按分数排序,将分数Se排名靠前的几个词加入到扩展集;num_max表示每个待扩展集Hi扩展出新词的最多数量,当扩展出的新词的数量超过num_max的值时,按照候选词的得分Se排序并保留得分较高的候选词;score_min表示生成的新词的最低分,当候选词分数低于score_min时,认为该候选词是噪声数据并舍弃该条候选词。假设种子cij扩展出的候选词e,其中cij是待扩展集Hi中的种子,待扩展集Hi中的其他种子为cik,则候选词e的得分的计算方式如式(3)所示。
将每个待扩展集Hi扩展结果进行整理,统计每个新词出现的频率。其中频率高的候选词代表与多个种子之间存在关系,是冬奥会相关术语的可能性较大。例如,实例“Snowboarding”可由实例“Bobsleigh”“Freestyle skiing”和“Doubles curling”等多个种子扩展出来。反之,频率低的候选词代表只与少量的种子词有关系,很可能是噪声数据。例如,候选集中的实例 “Kick scooter”出现次数只有1次,是由实例“Bobsleigh”作为种子时扩展出来的,因为它们均属于“车辆”,所以实例 “Kick scooter”是噪声数据。
1.3 中文词条扩展方法
与冬奥会英文术语集扩展相比,由于中文的数据用Word2Vec的方法进行扩展时效果较差,所以扩展方式存在一些差异。对中文术语集的扩展,本文将每个种子进行单独扩展,只将depth_max作为扩展的限制条件,使每个种子词在只限制扩展层数的条件下扩展出更多相关的候选词,最后通过统计每个候选词出现的频率,筛选掉频率较低的候选词。这种方法的缺点是对种子集的质量要求较高,因此需要手动完成对种子集的筛选工作。
1.4 BIE扩展方法
BIE扩展方法基于XLORE的数据集按图2的框架进行扩展,与XLORE数据集进行对齐时,会筛选掉一些具有相同意义的词,例如,在维基百科中搜索“Ksenia Makarova”“Xenia Makarova”“Ksenya Makarova”“Ksenia Olegovna Makarova”和“Ksenia Makarov”都对应着相同的实例“Ksenia Makarova”。针对此问题,本文用hash的方式进行存储,将XLORE数据集中的编号作为索引。同时,对齐维基百科跨语言同义词时,会找到少量的百度百科数据,可用来丰富冬奥会术语库。
2 实验
2.1 实验数据
在维基百科中分别以“概念: 冬季奥林匹克运动会”和“概念: winter olympic game”为根节点,向下遍历5层,获得中英文的概念集和实例集,得到的数据量如表1所示,并将得到的数据进行筛选。由于中文实例和英文实例的筛选方式基本相同,因此本文只介绍英文实例的筛选方式。
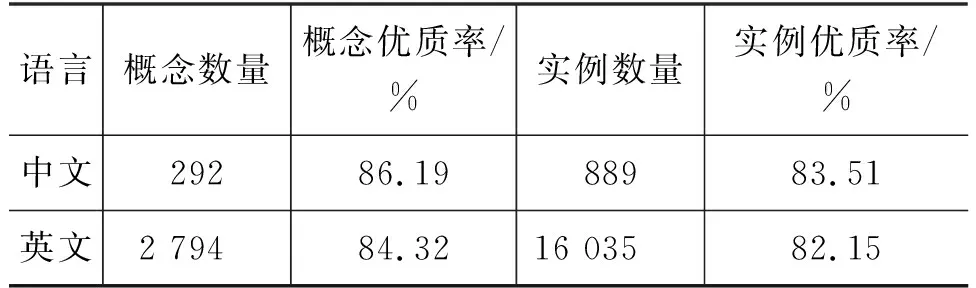
表1 维基百科中获取的冬奥会领域概念集和实例集数据数量
将扩展出的种子词进行筛选,选出质量较高的种子组成扩展集。经过测试,发现形如“List of Olympic venues in curling”“Poland at the 1964 Winter Olympics”等实例作为种子进行扩展时,扩展出的新词的总体质量较低,是较劣质的种子。当用“pavel angelov”“tommaso leoni”等运动员的名字或比赛项目名称作为种子进行扩展时,扩展出的新词的总体质量较高,是优质的种子。根据此测试结果,将得到的实例集进行筛选,并将剩余的数据作为种子集。按比例在种子集中选取一定数量的种子作为测试集,具体数量如表2所示,由于中文概念数量较少,所以选取全部种子集作为测试集。

表2 中英文实例和概念种子集及测试集数量
在筛选的过程中,我们还发现,有一些数据后面带有括号,括号里的内容是对该数据的解释。例如,实例“patrick caldwell (skier)”指的是滑雪运动员“patrick caldwell”,如果没有括号里的内容,则会产生歧义,在维基百科中搜索“patrick caldwell”,会搜索到来自南卡罗来纳州的美国代表“Patrick C. Caldwell”和美国越野滑雪运动员“Patrick Caldwell(skier)”这两个实例,前面的实例在本实验中是一条噪声数据。由于括号中的内容大多数是与冬奥会相关的词,所以我们保留了括号中的内容。
2.2 测试集实验分析及实验设置
实验中使用的数据集是维基百科的冬奥会相关词条组成的数据集,英文使用的词向量为300维,每组待扩展集Hi的种子数量为5,当待扩展集Hi的组内得分Sh在[0.3,1)区间内时,选择depth_max+num_max的策略进行扩展,参数depth_max的值为3、参数num_max的值为60;当待扩展集Hi组内得分Sh在(0,0.3)时,选择score_min+num_max的策略进行扩展,参数num_max的值为100、参数score_min的值为0.8,中英文迭代扩展的层数设置为3。
2.3 实验结果与分析
为了验证本文提出的模型在中文数据集上扩展的有效性,我们选取了Embedding based、SEISA、SetExpan三种扩展方法进行对比实验。评判标准是分别用每种方法扩展900个新词,比较每种方法扩展集中新词的质量。
•Embeddingbased[7]: 该模型基于Word2Vec的方法,训练基于中文维基百科的机器学习模型。通过维基百科的上下位关系选出候选词,并基于词向量计算新词得分,将所有候选词按得分进行排序,选择分数较高的候选词的集合作为扩展集。本文一共进行10次实验,每次实验选取10个优质种子作为种子集,将10次扩展的结果取平均值作为该实验的扩展结果。
•SEISA[3]: 本文模拟了SEISA的评分过程,并用SEISA的评分标准对扩展出的候选集合的所有词进行评分,按分数选出评分靠前的词条,并计算优质数据所占的比例。
•SetExpan[8]: 本文模拟了SetExpan的评分过程,并用SetExpan的评分标准对扩展出的候选集合的所有词进行评分,按分数选出评分靠前的词条,并计算优质数据所占的比例。
本文在维基百科的冬奥会相关的条目组成的数据集上进行了实验,实验结果如表3所示。

表3 维基百科的冬奥会相关条目组成的数据集上的对比实验结果
根据实验结果可以看出,扩展冬奥会领域术语集时,SEISA方法效果较差,说明种子集的平均词频较低时,对SEISA方法的影响较大。BIE+SWF的方法可以降低种子集平均词频较低造成的影响,且扩展效果相比其他方法提高12.12%以上。
2.4 模型参数分析
为了验证参数对实验的影响及BIE方法对扩展效果的提升程度。我们在英文测试集上进行待扩展集Hi种子数量n测试实验和扩展策略测试及参数测试实验,并在中英文数据集上分别对比了SWF方法和BIE+SWF方法。
2.4.1 待扩展集Hi的种子数量n测试
将1 000个测试集按每组1/5/10/20个种子进行分组。对4种分组方式分别进行扩展,统计每个候选词的次数并按次数由高到低进行排序,分别取5 000/7 500/10 000个候选词作为扩展集,将扩展集中优质种子数量占比作为模型的评分标准,分析待扩展集Hi的种子数量对扩展结果的影响。实验结果如图3所示。
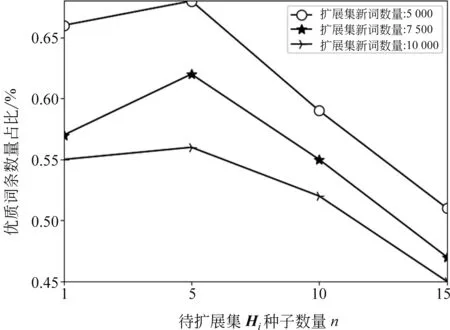
图3 待扩展集Hi的种子数量n对扩展结果影响
通过分析实验结果发现,优质词条数量占比按待扩展集Hi的种子数量n先增后减,可能原因是种子集Se中存在一定数量的噪声数据,当噪声数据所在的待扩展集Hi的种子数量较少时,噪声数据会对待扩展集Hi的语义理解造成较大影响,导致扩展出较多的噪声数据。例如,每个种子单独进行扩展时,如果这个种子数据是噪声数据,所扩展出的新词大部分是噪声数据。当待扩展集Hi的种子数量过多时,几个词会产生其他的语义信息。例如,待扩展集Hi中包括冬奥会运动员“申雪”“张丹”“庞清”“赵宏博”等,其中“申雪”“庞清”“赵宏博”是黑龙江省哈尔滨市人,容易扩展出与冬奥会无关的黑龙江人。综合考虑,对冬奥会领域术语进行扩展时,待扩展集Hi的种子数量为5时效果最优。
2.4.2 扩展策略测试及参数测试
在扩展策略测试实验中,我们对3个参数进行分析,发现参数depth_max和score_min可以较好地提高新词的质量,并且当种子集得分Sh较高时,score_min的效果较好,当种子集得分Sh较低时,depth_max的效果较好。当待扩展集Hi得分Sh在[0.3,1)区间内时,score_min+num_max策略最优,当待扩展集Hi得分Sh在(0,0.3)时,depth_max+num_max策略最优。我们分别对两种扩展策略的参数进行调整并扩展,实验的结果如图4、图5所示。

图4 depth_max+num_max策略参数测试结果

图5 score_min+num_max策略参数测试结果
通过实验结果可以看出,当参数depth_max为3、num_max为100时,depth_max+num_max的扩展策略效果达到最优。当参数score_min为0.8、num_max为60时,score_min+num_max的扩展策略达到最优。
2.4.3 BIE方法效果测试
对中英文的实例集分别使用SWF方法和BIE+SWF方法进行扩展。实验结果如表4所示。

表4 SWF方法和BIE+SWF方法实验结果
通过分析实验结果,我们发现BIE方法对中文实例的扩展效果提升明显,对英文实例的扩展效果提升不多,证明BIE方法可以解决中文种子集种子数量少的问题。
2.5 其他数据集实验结果
为了测试我们的方法在除冬奥会外的其他领域也有效,我们在其他低频词领域进行了对比实验,实验选择的领域是世界锦标赛、兵器和亚运会,并使用BIE+SWF方法进行扩展,实验的结果如表5所示。

表5 BIE+SWF方法在其他低频词领域上的实验结果
BIE+SWF方法在世界锦标赛领域、兵器领域和亚运会领域也有较好的表现。其中兵器领域扩展出的新词数量最多且新词的平均质量最高。我们认为主要原因是兵器领域的词条大多数都没有歧义,上下位关系相对较少,所包含的语义信息比较简单。而其他三个领域的词条,有着比较复杂的上下位关系,且包含的语义信息比较复杂。例如,乒乓球运动员“马龙”获得过奥运会、世界锦标赛、亚运会等比赛项目的冠军,将实例“马龙”作为亚运会领域下的词条进行扩展时,较容易扩展出其他运动会的相关词条。
3 相关研究
集合扩展是把一个比较小的种子集合作为输入,找出更多同类型的数据来扩充这个集合的规模。早期解决此项工作任务的有Google Set[16],SEAL[2],SEISA[3]和Lyretail[4]等,它们都是使用搜索引擎或者其他互联网上的信息来对已有的概念或者实体集进行扩展的。其中Google Set是最早使用集合扩展功能的产品,主要用于丰富谷歌搜索的结果。SEAL由CMU在2007年的ICDM上提出,使用一个两步的策略对已有的种子词进行扩展。将输入的种子词输入到搜索引擎中,通过解析网页,得到候选词,然后再将候选词放入一个图中进行排序,得到候选结果。SEAL的优点是跨语言且准确度高。2011年,微软推出了SEISA扩展系统,并提出了生成概念的置信度的方法,所使用的信息是web list和 query log,分别代表相关性和上下文的语义性的关系。在2016年,Chen等人提出Lyretail,利用了web的信息对已有词条字典进行扩充,与之前的方法相比,它引入了一个弱监督[17]的抽取器来提取网页中的词条。在此类方法中,所用的方法都是将种子提交给搜索引擎,用通过挖掘网页的方式进行扩展,虽然这种方法扩展出的新词质量较高,但代价比较高,不适用于大规模扩展。随着Word2Vec模型的出现,集合扩展的工作逐渐从只靠web信息,转向了基于文本的任务。基于语料库的集合扩展一般有两种方法。第一种方法找到所有的候选词后再进行排序[6-7],这种方法的优点是准确率高,缺点是不能充分理解语义,导致扩展结果出现非法闯入现象。第二种方法是迭代式扩展,从种子实体开始提取质量模式,基于预定义的模式评分机制。这种方法的缺点也比较明显,只在每次迭代中种子词和迭代产生的词精度很高时才有效,否则可能会出现严重的语义漂移。针对这两种方法存在的问题,2017年Shen等人在KDD上提出SetExpan[8],扩展效果超过了大部分已有的方法,有针对性地解决了实体入侵和非法闯入的问题,在小规模扩展时效果很好,但在大规模扩展时会出现语义漂移的现象。2018年,Jonathan Mamou等人基于SetExpan提出了SetExpander[9],SetExpander为术语集扩展实现了一个迭代的端到端工作流,使用户能够选择输入语料库,训练多个嵌入模型,并且该算法结合多个上下文项嵌入,捕捉语义相似性的不同方面,使系统在不同领域具有更强的鲁棒性。
平行语料库[18]对于训练统计机器翻译系统特别重要。一个典型的平行语料库的提取过程主要分为识别具有双语内容的网站、爬取网站、文档对齐、句对齐和句子对过滤这5个步骤[19]。基于平行语料库的研究有很多,例如,在2005年Regina Barzilay等人基于平行语料库,运用无监督的学习方法,提出了一种基于语料库的同一原文多个英译本的释义识别方法[20]。在2018年,Zdenka Urešová等人基于平行语料库构建了捷克英语类词典并作为一个开源数据集发布[21]。本文提出的集合扩展的方法是基于跨语言的平行语料库进行研究的。
维基百科是最广泛的百科全书,基于维基百科的语料库进行的研究有很多,其主要集中在实体消歧、语义相关性、跨语言分类等方面[22-24]。其中比较有代表性的是DBpedia[25]。近年来,基于维基百科开展了复杂词汇识别[26]和知识多样性[27]等工作。在本文的实验中,我们使用维基百科中冬奥会领域相关的词条组成的数据集进行实验。
4 结论与未来工作
4.1 结论
集合扩展在知识图谱的构建中有着重要的应用。本文针对冬奥会领域的中文词条扩展过程中存在的问题,提出了SWF方法和BIE方法。SWF方法通过统计每个候选词出现的次数选择质量较高的词条,用于解决冬奥会领域的中文词条平均词频较低的问题。BIE方法通过借助数据量较大的英文语料库和XLORE的跨语言同义词数据集进行扩展,用于解决冬奥会领域的中文词条数量较少的问题。我们使用BIE+SWF方法对其他领域的低频词进行扩展,得到的扩展集质量较高,证明本文的方法具有较好的适用性。
4.2 未来工作
目前,我们通过中英文迭代扩展的方式解决了中文实例种子集数量少的问题,并用每个种子单独扩展统计每个新词数量的方式解决了中文实例词频低的问题,但需要手动筛选种子集,且在种子集数量较少时扩展效果不理想。后续我们将进行筛选种子集的实验,同时将尝试多种语言的联合扩展,用更多种语言迭代扩展的方式来弥补种子集数量少、低频词带来的问题。
猜你喜欢
英语文摘(2021年8期)2021-11-02
音乐天地(音乐创作版)(2019年12期)2019-02-09
知识经济·中国直销(2016年5期)2016-11-07
知识经济·中国直销(2016年4期)2016-11-07
知识经济·中国直销(2016年10期)2016-02-27
读者·原创版(2015年11期)2015-03-01
信息安全研究(2015年3期)2015-02-28
语文知识(2014年12期)2014-02-28
意林(2014年2期)2014-02-11
