
基于因子分析的广东省短时强降水预报模型及其业务试验*
2021-03-17 07:17张华龙伍志方肖柳斯
气象学报 2021年1期
张华龙 伍志方,2 肖柳斯 涂 静
ZHANG Hualong1 WU Zhifang1,2 XIAO Liusi3 TU Jing1
1. 广东省气象台,广州,510080
2. 中国气象局广州热带海洋气象研究所/广东省区域数值天气预报重点实验室,广州,510640
3. 广州市气象台,广州,511430
1. Guangdong Meteorological Observatory,Guangzhou 510080,China
2. Institute of Tropical and Marine Meteorology/ Key Laboratory of Regional Numerical Weather Prediction,CMA,Guangzhou 510640,China
3. Guangzhou Meteorological Observatory,Guangzhou 511430,China
1 引 言
广东省地处亚热带季风气候区,短时强降水频率和最大小时雨强在中国均位于最高水平(陈炯等,2013)。短时强降水多由中小尺度系统造成,具有尺度小、突发性强、生命期短、致灾严重的特点,已有一些研究总结了广东短时强降水出现的不同天气流型配置(伍志方等,2016;陈元昭等,2016)以及华南前、后汛期引发强降水的天气系统配置(王坚红等,2014;梁巧倩等,2019)。边界层急流(Du,et al,2018)、华南复杂地形特别是海陆对比(Chen,et al,2018)在华南强降雨演变过程中起重要作用,这些要素之间的特殊相互作用是复杂的,导致了华南强降水的独特特征,致使预报存在相当大的困难(Luo,et al,2020)。如2017 年广州“5•7”特大暴雨过程,增城新塘镇记录雨强184.4 mm/h,各主流模式对该区域仅预报小雨或中雨级别降水(伍志方等,2018),造成业务预报的严重漏报。在目前数值模式对于华南降水预报评分仍较低的情况下(Zhang,et al,2016),利用天气过程的物理参数建立综合多方面要素的预报模型,是一个有益尝试。
短时强降水属于强对流天气现象之一,不同类别的强对流具有不一样的环境条件和物理量阈值特征,目前已有较多研究工作利用观测或再分析资料计算强对流发生的物理量,并使用统计后处理技术或机器学习方法构建预报模型,在雷电(Gijben,et al,2017;Bates,et al,2018)、强雷暴(Gallo,et al,2018)、强冰雹(Mohr,et al,2015)和龙卷(Simon,et al,2018)的预测上取得一定效果。这种基于构成要素预报强对流的方法称“配料法”(俞小鼎等,2020)。中国国家气象中心较早基于“配料法”思路开展强对流天气概率预报业务(张小玲等,2012),之后一些研究通过模式输出参数进行统计后处理,构建短时强降水预报模型。雷蕾等(2012)基于快速更新循环同化预报系统(BJ-RUC 模式)计算了一系列物理量,探索对强对流天气分类预报的可行性。曾明剑等(2015)应用相对偏差模糊矩阵评价技术,对中尺度模式输出的对流参数进行逐次筛选和权重分配,构建分类强对流天气预报概率模型并业务应用。朱月佳等(2019)借鉴“配料法”的思路建立基于集合预报的对流联合概率预报方法,对区域性集中短时强降水取得较好的应用效果。洪伟等(2018)利用ECMWF 全球模式细网格预报产品,通过物理量阈值判定和箱形图差异指数评估与短时强降水发生敏感度的方法建立短时强降水预报模型。
多数概率预报方法均直接以物理量作为模型预报因子。当物理量数增多时,某些无效物理量的引入会影响预测模型效果,因此需要构建合理的物理量筛选标准;另外,部分物理量之间的相关也会为模型带来冗余信息。为简化模型的输入变量,可对物理量进行二次处理,减少因子数量,提高因子的有效性。因子分析是一种构建少数几个因子描述多个指标联系的方法,能够从变量的方差/协方差结构入手,在尽可能多地保留原始变量信息的基础上,用少数新变量来解释原始变量。由于因子模型的特性,能够对包含复杂信息的对流性降水(Godart,et al,2010)和极端强降水(Felzer,et al,2020)的环境因子进行有效分析,并基于因子分析改进预报模型(熊开国等,2012;农孟松等,2011)。
为解决一般物理量预测短时强降水出现的命中率和虚警率同步上升而导致TS 评分降低的问题,提高模型预测有效性,文中以显著性(物理量与多年平均态的差异)和敏感性(特征曲线面积)为标准,筛选在业务应用中具有较低虚警率和高预报技巧的物理量。广东省北依南岭,南邻南海,在华南前、后汛期,不同区域气候和降水特征差异大,导致短时强降水发生时各物理量与多年平均态偏差的差异显著,若采用所有数据样本直接进行因子建模,将导致因子预测能力减弱。为此文中按照前、后汛期以及不同区域的有效因子特征,建立分期、分区短时强降水概率预报模型。在实际业务应用中,将欧洲中期天气预报中心细网格数值模式(ECMWF-Fine)预报数据输入概率预报模型,形成短时强降水0—36 h 逐6 h 概率预报产品。除提供概率预报外,模型还可输出多个独立因子,分别反映短时强降水发生、发展的不同环境特征,可提供有利条件的定量指标,帮助识别不同类型的短时强降水,为主观预报短时强降水落区、强度提供参考。
2 数据处理与预报模型建立方法
2.1 数据处理
建模实况数据为广东省区域地面气象站(包含基本站和自动站)的小时雨量数据。自动气象站雨量资料经过质量控制处理:若某一站点记录到20 mm/h以上降水量,但以该站为中心,50 km 半径范围内的其余站点均无降水,则认为该短时强降水记录可疑;当1 a 内某一站点缺测数据比例超过5%,则视为故障站点。故障站点当年的数据与可疑数据均不作为短时强降水事件记录。基于站点观测记录,构建与ERA-Interim 具有相同空间分辨率(0.125°)的格点数据集并进行参数统计(曾明剑等,2015),方法如下:遍历所有格点,在再分析资料时次对应代表时段(前后3 h)内,若格点区域内有站点记录到≥20 mm/h 降水,则认为该格点出现了短时强降水。
文中使用欧洲中期天气预报中心的再分析同化数据集(ERA-Interim)计算相关物理量。ERAInterim 作为目前广泛使用的再分析资料,使用四维变分同化技术同化了大量卫星观测资料,结合多种误差校正技术实现了资料质量的提升,对于形势场具有较好的反映能力(Dee,et al,2011;慕丹等,2018),在中国地形复杂、观测资料稀缺的地区具有较好的适用性(Bao,et al,2013)。建模数据样本训练期为2009—2018 年的4—9 月,测试期为2019年4—9 月,模型效果验证和业务运行均使用ECMWF-Fine 预 报 场。 ECMWF-Fine 提 供1 天2 次起报(08 时与20 时,北京时,下同)、地面要素空间分辨率为0.125°、高空要素分辨率为0.25°的预报;为生成0.125°分辨率的模型输出产品,将高空预报要素进行双线性插值,形成与地面要素分辨率(0.125°)一致的格点场。将ECMWF-Fine 预报场计算的物理量参数输入概率预报模型,生成0—36 h 逐6 h 短时强降水客观概率预报产品。
2.2 建模方法
2.2.1 物理量计算与遴选
利用各层次ERA-Interim 资料风、温度、湿度、气压等要素,计算49 个反映大气动力、热力的物理量(见附录表1)。为减少气候背景差异对建模的影响,对物理量进行多年平均态扣除处理:对应某一天的某个时次,计算多年(2001—2018 年)当天及前后各2 d(共5 d)同一时次的物理量平均值。
为遴选具有更好指示意义的物理量作为建模参数,以显著性指标和敏感性指标为标准。显著性即短时强降水发生时物理量与多年平均态差异的显著性。用T 检验量作为评价指标,计算公式

除考虑显著性以外,引入特征曲线面积(AROC,Area under Receiver Operating Characteristic Curve)(Richardson,2000)作为敏感性指标,该指标衡量物理量作为预报因子识别短时强降水发生的能力,值越大,预报技巧越高,对事件预报的敏感性越优。图1 为49 个物理量对应的受试者操作特征曲线(ROC,Receiver Operating Characteristic Curve)(Richardson,2000),其中红线为24 个T 检验量显著性较高的指标,可见,并非所有显著性高的因子均具有较优的敏感性,部分红线对应物理量的AROC 处于较低分位水平,表明两个指标的优势参数并不具有一致性。
对所有物理量的T 和AROC 两个指标进行标准化处理并相加,计算综合评价指标。综合评价指标较小的物理量,倾向于对应某一指标值较低,或两个指标优势均不明显(见附录表1)。文中挑选综合评价指标最大的18 个物理量作为建模参数,对遴选的18 个物理量利用因子分析方法,组合成6 个表征热力、动力、水汽等不同物理特性的因子,并赋予不同权重。
2.2.2 因子分析
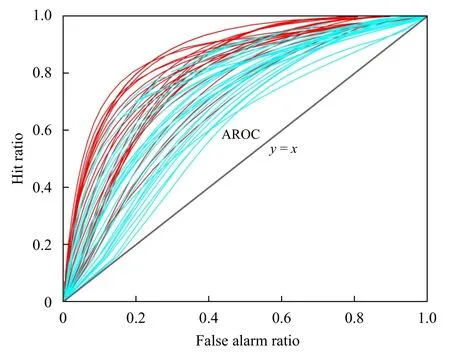
图1 49 个物理量受试者操作特征曲线 (AROC 为受试者操作特征曲线与y=x 函数线围成的面积;红、蓝色线分别代表在所有物理量的显著性检验中,显著度位于前50%分位、后50%分位的物理量)Fig. 1 ROC curves of 49 physical parameters (AROC represents the area surrounded by the ROC curve and the y=x line;Red lines and blue lines respectively represent physical parameters ranking the top 50% and the last 50% in the significance test of all physical parameters)
基于2.2.1 节选取的18 个物理量进行因子分析,因子分析的算法核心是将p 个物理量 x ( x=x1,x2, x3, ···, xp) 表 达 为m 个 因 子 f ( f = f1, f2, f3,···,fm)的线性组合形式,即

式中,A 为因子分析法的因子荷载矩阵,通过对原始变量( x)的相关系数矩阵变换处理得到。u( u=u1, u2, ···, up) 为原始变量( x)的平均值。为使每一个物理量在少数几个主因子上具有高载荷,采用方差最大正交旋转法对因子载荷矩阵(A)进行旋转变换。用因子载荷矩阵列元素的平方和除以维数,即可得到各因子贡献率,将各因子贡献率累加,即可得到因子累计贡献率。累计贡献率表明当前数目的因子累计方差占样本总方差的比例(在[0%,100% ]内变化,值越大,因子的解释能力越好)。虽然因子数增加,累计贡献率同步增加,但过多的因子不利于物理量的有效归纳和解释,理想模型是通过尽可能少的因子数获得最大的解释能力。图2 为因子数与贡献率/累计贡献率的关系。可见,当因子数较少(<5)时,因子贡献率增加幅度较大,因子数为6 时,总贡献已超过75.9%,但因子数继续增加,因子总解释能力提升幅度较小。因此,文中确定因子数为6,贡献率依次为19.1%、18.8%、12.2%、10.8%、9.8%、5.2%。
图3 为式(2)计算的载荷系数矩阵A。载荷系数反映了因子与物理量的相关性,同一因子对应的几个高载荷物理量所代表的共同物理意义反映了因子主要特征。如物理量组合因子1(简称组合因子1,其余因子同)系数较高的物理量分别为1000、925 和850 hPa 的假相当位温、总指数、修正K 指数与K 指数等,可知主要是反映大气的热力不稳定尤其是低层(850 hPa 以下)能量增长的因子。组合因子2 的高相关物理量为大气垂直液态水积分和大气可降水量,主要是反映大气水汽变化的因子;组合因子3 的高相关物理量为500 hPa 垂直速度、700 hPa 垂直速度与中低层垂直速度积分,主要反映大气中层垂直运动条件;组合因子4 的高相关物理量为修正K 指数、K 指数、700 hPa 相对湿度和总指数;组合因子5 的高相关物理量为850 hPa 垂直速度和涡度、700 hPa 垂直速度与中低层垂直速度积分;组合因子6 的高相关物理量为850 hPa 假相当位温和相对湿度、总指数、K 指数。
2.2.3 因子概率与组合因子优势
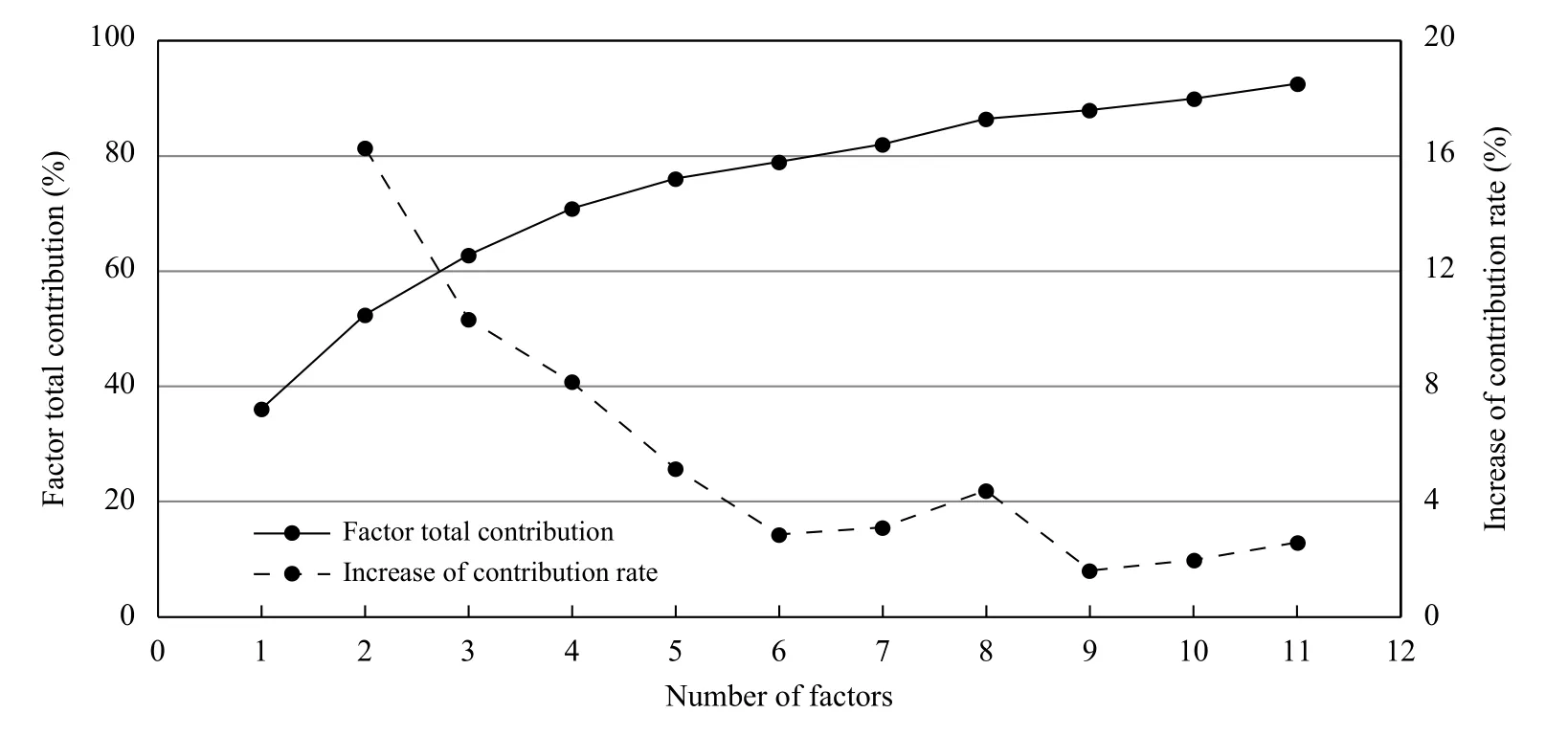
图2 因子总贡献和贡献率增加值随因子数变化Fig. 2 Total factor contribution and the variation of increase in the contribution rate with the number of factors

图3 6 个物理量组合因子对应遴选出的18 个物理量的因子相关系数Fig. 3 The load coefficients of 18 selected physical parameters corresponding to 6 factors
因子概率通过对因子得分处理得到,因子得分通过Thompson 方法(Devlieger,et al,2016)计算所得,即对2.2.2 节计算的因子载荷矩阵A 采用正交旋转变换,计算公式为

重组后的因子概率指示短时强降水的效果较单一物理量更好。以组合因子1 为例,该因子的AROC 显著大于6 个高权重物理量(图4a);对比该因子与各物理量在30%预测阈值时的虚警率与命中率(图4b),可以发现该因子的虚警率(35%)低于所有单个物理量,而命中率(88.2%)与6 个物理量相比接近(相差在1%范围内)。因此物理量组合后的因子模型在保证具有较高命中率的同时,显著降低了虚警率,体现了优化模型因子的效果。
2.2.4 概率预报模型
在业务中为应用概率预报模型生成产品,利用ECMWF-Fine 预报数据,通过2.2.3 节的处理步骤计算各因子概率;进一步对6 个因子概率进行加权组合,形成综合概率预报模型。各个因子概率的权重为因子贡献率占总贡献的比值(因子贡献率计算方法见2.2.2 节),因子贡献率占比越大,则该因子对环境物理量变化的总方差贡献越大,可在预报结果中有效体现大气环境参数的主要变化特征。当因子数为6 时,因子总贡献率为75.9%,单个因子的权重值是因子贡献率占6 个因子总贡献率的比值。因此综合概率计算公式为
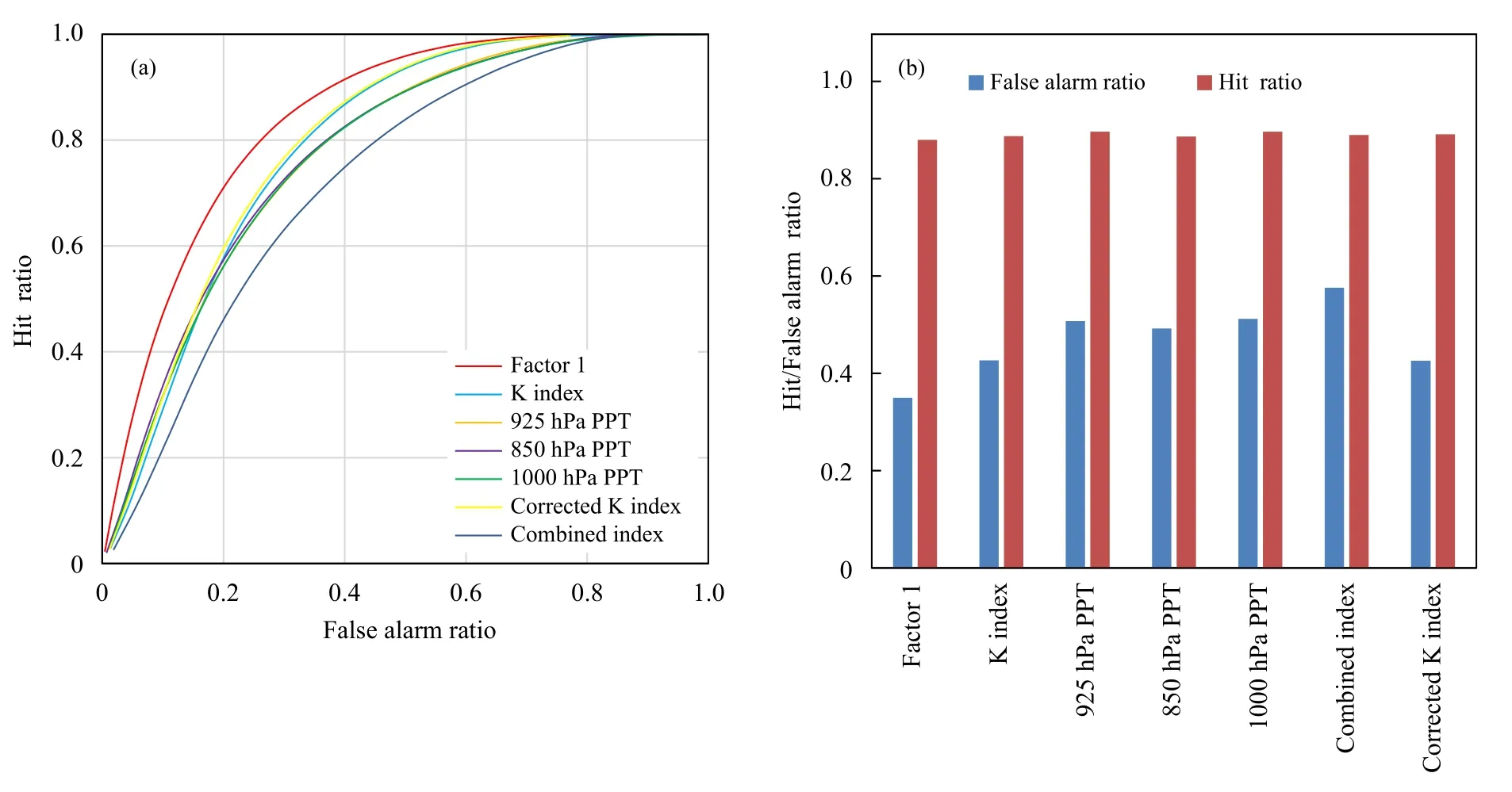
图4 组合因子1 与高相关物理量受试者操作特征曲线检验 (a)、虚警率与命中率 (b) (a 选取物理量为构成组合因子1 相关系数较高的物理量,b 为各因子与物理量对应30%分位预测阈值时的虚警率与命中率,PPT 为假相当位温缩写)Fig. 4 ROC tests (a),false alarm ratio and hit ratio (b) of Factor 1 and its highly correlated physical parameters(Physical parameters which are highly correlated with Factor 1 are selected. Fig. 4b presents the false alarm ratio and hit ratio of Factor 1 and each physical parameter corresponding to 30% fractional forecast threshold value. PPT is the abbreviation name ofpotential pseudo-equivalent temperature)
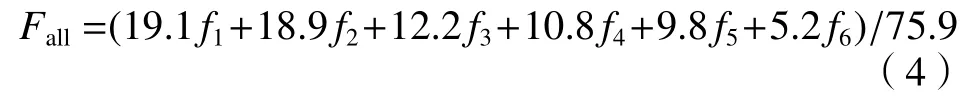
式中, Fall为 模型的 概 率 预报值, fi(i=1,2,···,6)为因子概率,各因子权重系数分别为单个因子贡献率占总贡献率之比。
3 短时强降水因子显著性的时、空分布特征
由于前、后汛期广东省短时强降水的气候背景与环流形势明显不同(梁巧倩等,2019),致使各物理量阈值分布也具有显著差别,因此首先对因子进行时、空统计,划分因子特征相似的时期与区域,进而建立独立模型,以提升模型有效性。为体现因子得分相对于多年平均态的偏离幅度,定义短时强降水对应的各因子偏离度(FB,Factor Bias)。式中, Fi(i=1,2,···,6)为经过标准化处理的短时强降水因子得分平均值, Fmean为因子得分的多年平均值。
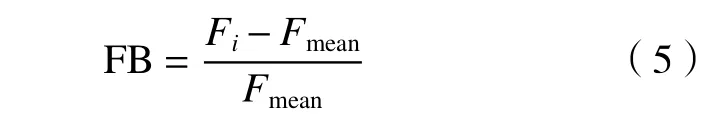
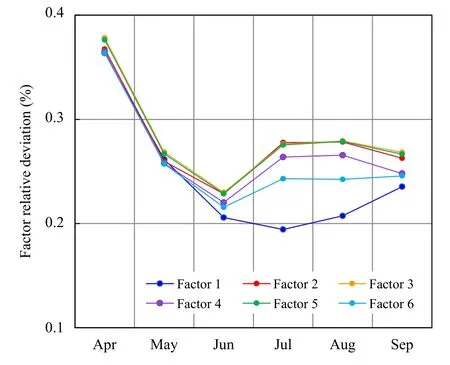
图5 不同月份广东省短时强降水因子偏离度Fig. 5 SHR deviation rates of individual factors in Guangdong in different months
图5 为广东省范围内所有格点的因子偏离度逐月变化,前汛期(4—6 月)所有因子偏离度随月份增长均呈下降态势,但不同因子的偏离度差异较小,显著小于后汛期(7—9 月);后汛期除组合因子1 随月份增长而增大外,其余因子均维持相对稳定。与动力和水汽条件相关的因子(组合因子2、3、5)偏离度比较一致,但与热力条件相关的因子(组合因子1、4、6)偏离度均低于动力和水汽因子,且因子间偏离度有明显差异,上述特征表明,随着季节逐渐从前汛期过渡到后汛期,上、下气层间的热力差异逐渐减小,组合因子1 的相对重要性也不断下降。值得注意的是,多数因子在6 月出现谷值,可能与该月短时强降水发生频率较高有关,过多的样本量导致因子偏离度较低。上述因子偏离度差异特征可作为前、后汛期独立建模的依据。
除季节差异外,不同地区的气候背景差异(孙喜艳等,2017)亦导致不同地域因子偏离度不同。为体现因子偏离的空间分布特征,计算广东省区域格点因子偏离度占所有格点总因子偏离度的比值,作为因子的相对偏离度,反映各因子对不同区域的相对重要性。由图6 可见,除组合因子4 外,其余因子在广东省北部和西南部均具有反向分布特征,组合因子1 相对偏离度较高的区域(粤北),不稳定能量条件对于短时强降水重要性高于相对偏离度较小的区域(粤西南)(图6a);与之类似,组合因子3 的南北差异(图6c)表明垂直运动条件对于粤西南的短时强降水发生具有更重要作用。组合因子2、5、6 也有类似的南北差异特征,且高、低值分布区域相似。因此,在分区建模中,考虑到上述因子相对偏离度的空间分布特征,以及广东沿海两个降水中心与内陆降水中心性质的不同(王坚红等,2017;Li,et al,2008),将广东省划分为3 个区域进行单独建模(图6a)。
基于上述的分时期与分区域方法,可形成6 个因子模型,在相同的因子数目下,不同模型选取的物理量、各因子贡献率、组成各因子的物理量的权重系数均有差别。进行时、空分区的独立建模后,其应用效果较未分区前模型有一定改善,尤其对于广东省西南部地区,短时强降水的命中率明显提升(图略)。
4 概率预报模型效果检验
4.1 TS 评分检验
为检验概率模型的业务应用效果,对测试期(2019 年4—9 月)模型输出结果进行检验。由于模型输出为概率值,为得到格点短时强降水预报产品,需要设定一个固定概率值作为预测概率阈值,阈值的选取方法为:对训练期间前、后汛期和不同区域设置不同的因子概率阈值,检验对应短时强降水TS 评分,以最优TS 评分对应概率值作为预报业务中的短时强降水的预测概率阈值。图7 为不同区域和时期预测概率阈值对应的TS 评分,可见,随着概率阈值增大,TS 评分均为先增大、后减小的趋势,当概率阈值大于40%时,命中率迅速下降。以分区、分期的最优TS 评分对应的概率阈值代入预测模型,并在测试期进行检验,具体概率阈值见表1。检验方案为:参考洪伟等(2018)区块TS 检验方法,对广东省区域划分为空间分辨率更高的0.5°×0.5°网格,同时采用更精细的时间尺度,预报时段为每天两次起报(08、20 时)12 h 预报时效内的逐6 h 产品,如08 时起报,则检验14 和20 时的短时强降水,对应短时强降水实况时段分别为11—17 时、17—23 时。在判定区块的对应时段内,若有2 个以上的测站记录到>20 mm/h 降水,则认为实况出现短时强降水。
为体现上述方法相对确定性模式要素预报的优势,将模型结果与业务常用的ECMWF-Fine 雨量预报产品进行对比。由于ECMWF-Fine 预报产品时间分辨率为3 h,并且检验评估表明ECMWFFine 对华南对流性降水经常低估(Huang,et al,2017),因此对确定性模式采取较宽松的标准:当检验时段对应格点内3 h 累计雨量预报最大值超过20 mm,则判定预报为短时强降水。另外,为考察模型对短时强降水的预报偏差,计算逐个格点的偏差(Bias)(江崟等,2019),当偏差大于1 时,表明模型虚警较多,值越大,虚警越严重;当偏差小于1 时,模型漏报较多。图8 为上述模型与ECMWF-Fine 模式的检验结果对比,可见,无论前汛期或后汛期,概率模型在全省大部分地区TS 评分均在0.25 以上,前汛期TS 评分高值(>0.30)区位于珠江三角洲及粤北地区(图8a),最大TS 评分超过0.42;后汛期TS 评分高值(>0.30)区则位于南部沿海区域(图8d),最大TS 评分超过0.41。而ECMWF-Fine 预报评分在前汛期较低,南部地区均在0.1 以下,后汛期有所增大,但最大不超过0.15(图8b、e)。前、后汛期概率模型全场平均较ECMWF-Fine 分别提升0.23 与0.21,尤其对前汛期的广东省南部沿海,以及后汛期广东省西南部,模型TS 评分提升显著。TS 评分提高的主要贡献来源于漏报率的降低,在获得高命中率的同时,虚警率虽有一定程度增大,但与命中率之间有较好的平衡。从图8c 可见,前汛期在TS 评分较高的珠江三角洲地区,偏差整体为0.75—1.5,而粤东以及粤西的沿海地区则是虚警相对较多的区域(偏差>1.5);后汛期,除了在粤东的沿海地区偏差接近1 以外,其余地区出现一定程度的虚警,以粤北地区虚警相对更多(图8f)。在天气尺度强迫较弱的情况下,应用概率模型有助于弥补数值模式漏报严重的缺陷,有效降低漏报率,并在短时强降水高频地区获得虚警率与命中率较好的平衡,但在部分地区会出现虚警增多的情况。
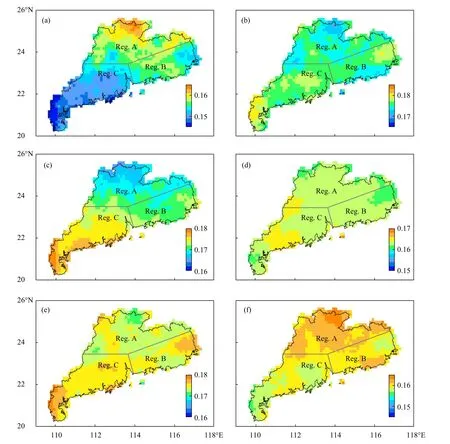
图6 汛期短时强降水的因子相对偏离度空间分布与区域划分(色阶为各因子相对偏离度,Reg. A—C 分别对应3 个独立建模区域,a—f. 组合因子1—6)Fig. 6 Spatial distributions of factor relative deviation rate of SHR in flood season (Color shadings represent relative deviation rate of each factor, Reg. A—C represent three independent areas for model training, a—f. respectively indicate Factor 1—6)
4.2 不同因子对短时强降水的指示性
实际业务应用中,基于模型输出的各因子概率对比可为预报难度更大的暖区强降水提供更多预警信息。目前主流的数值模式对于暖湿平流驱动的局地对流性降水预报技巧较低(Huang,et al,2017),因此当反映热力条件增长的因子概率较高时,业务人员仍要密切关注短时强降水发生的可能性。
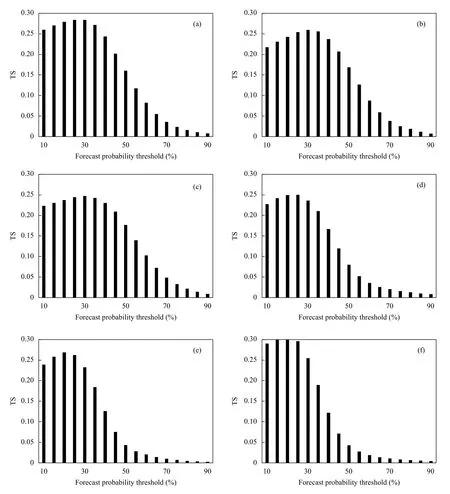
图7 训练期分期、分区模型不同预测概率阈值与对应TS 评分(a. 前汛期Reg. A, b. 前汛期Reg. B, c. 前汛期Reg. C, d. 后汛期Reg. A, e. 后汛期Reg. B, f. 后汛期Reg. C)Fig. 7 TS corresponding to different probability thresholds of the forecast model in different regions and periods during the training period (Results of Reg. A,Reg. B and Reg. C during pre-flood season are respectively shown in (a,b,c),and results of Reg. A,Reg. B and Reg. C during post-flood season are respectively shown in (d,e,f))
选择2019 年2 次暖区降水个例(个例1 为2019 年5 月26 日,个 例2 为2019 年6 月13 日)进行对比分析。个例期间华南地区低层(700 hPa 以下)均受西南或偏南气流控制,无明显温度锋区。图9 分别为ECMWF-Fine 预报的6 h 累计降水、短时强降水实况及模型概率预报。两个个例短时强降水分别集中发生于珠江三角洲和粤西沿海(图9a、c 矩形),最大小时雨量均超过50 mm。ECMWFFine 显著低估了两个个例的雨量预报,尤其对个例2,在强降水发生区的6 h 雨量预报<5 mm。而概率模型对于两个个例的预报效果均较好,个例1 位于珠江三角洲及韶关、清远南部(图9a)的短时强降水落区与模型高概率区(>0.7)(图9b)一致,个例
2 预报的短时强降水概率在粤西南部(图9d)虽低于个例1,空间分布较不均匀,但仍出现>0.6 的高概率中心。整体而言,两个个例模型的高概率区对于短时强降水均有较好的指示作用。

表1 不同区域及时期模型固定预测概率阈值Table 1 The determined probabilistic thresholds of the forecast model in different regions and periods
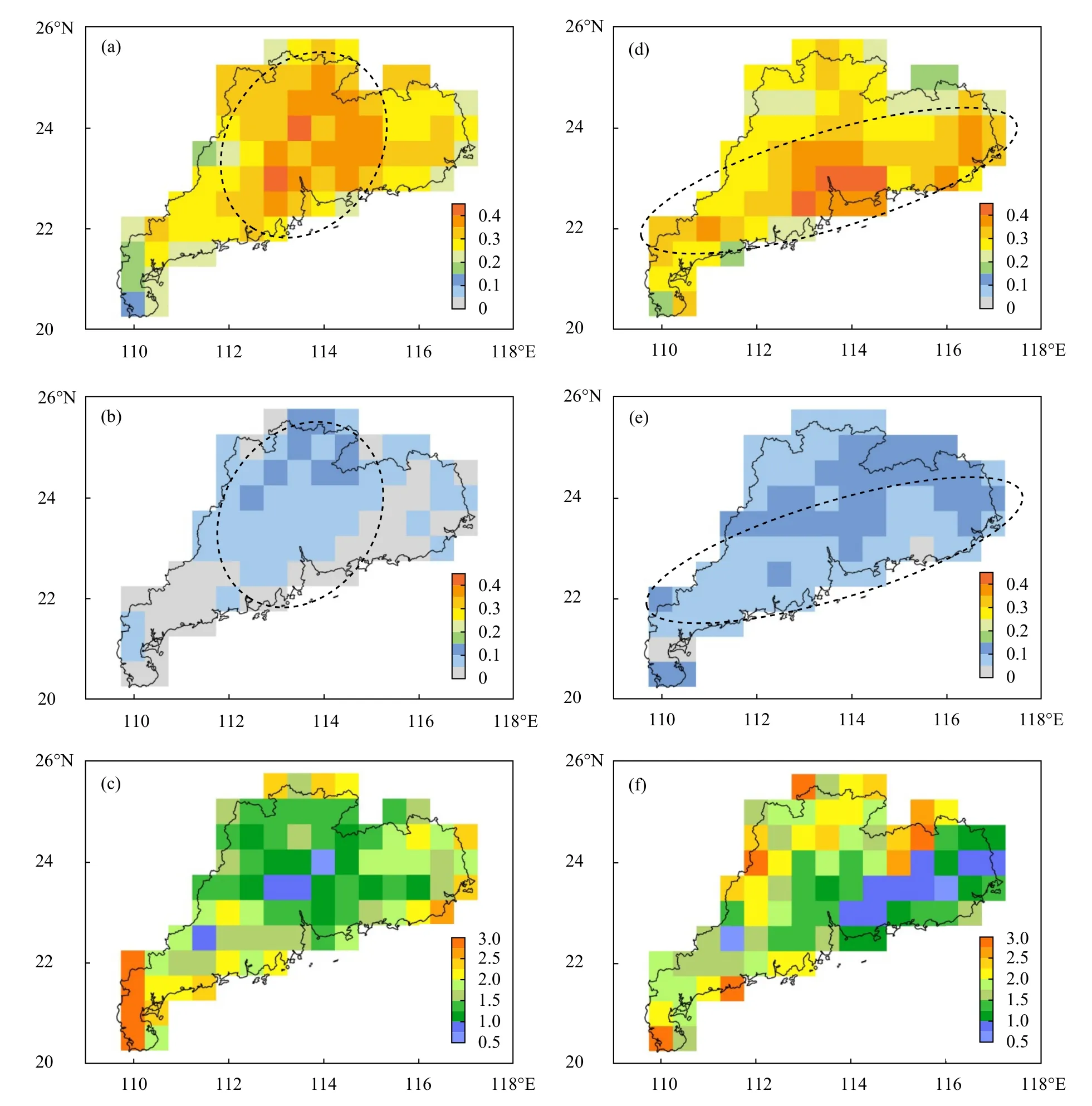
图8 前汛期 (a、b、c)、后汛期 (d、e、f) 短时强降水概率预报模型TS 评分 (a、d)、偏差 (c、f) 与ECMWF-Fine 模式降水预报TS 评分 (b、e)Fig. 8 TS scores of probabilistic model forecasts of SHR (a,d),TS scores of ECMWF-Fine model precipitation forecasts (b,e) and BIAS of SHR probabilistic model forecasts (c,f) during the pre-flood season (a,b,c) and the post-flood season (d,e,f)

图9 2019 年5 月25 日23 时—26 日05 时 (a、b)和6 月13 日11—18 时 (c、d) 数值模式6 h 降水量预报(单位:mm)、短时强降水实况及模型概率预报 (a、c 色阶为ECMWF 细网格模式6 h 累计降水量预报,散点为小时分级的短时强降水观测站点分布,b、d 色阶为短时强降水概率预报模型预报场)Fig. 9 NWP precipitation forecasts (unit:mm),observations at weather sites and probabilistic model forecasts of SHR from 23:00 BT 25 May 2019 to 05:00 BT 26 May 2019 (a,b) and from 11:00 to 18:00 BT 13 June 2019 (c,d)(6 h cumulative precipitation forecast of ECMWF-Fine and the distribution of SHR graded by hourly precipitation at weather stations are respectively shown in (a,c), color shadings in (b,d) represent the SHR forecast by the probabilistic model)
两个个例的主要驱动因子不同,个例1 与沿海风速辐合的动力作用关系密切,个例2 则是在弱动力强迫、强热力不稳定的环境下发生的,预报难度更大(Huang,et al,2017),对上游不稳定能量具有更显著的敏感性。图10 给出了两个个例组合因子1、组合因子3 的空间分布以及925 hPa 风场、中低层垂直速度分布。个例1 降水区的组合因子3 概率(图10c)高于组合因子1(图10a),而个例2 降水区组合因子1 概率则更高(图10b、d)。个例1 动力条件更好的原因为南海北部存在西南气流与东南气流的辐合区,因此在珠江口西侧具有大的垂直上升运动区(图10e 箭头),但个例2 动力条件相对较弱,南海北部受西南气流控制(图10f),风向与海岸线接近平行,因此粤西南部的垂直速度也较小。但对于热力条件,则是个例1 显著弱于个例2,两个个例降水区的925 hPa 假相当位温分别为354 K 与362 K(图10e、f 箭头),后者高假相当位温主要来源于季风气流导致强烈的增暖、增湿。在热力条件较好的背景下,个例2 出现了超50 mm/h 的短时强降水。而ECMWF-Fine 降水量预报以及组合因子3 概率对个例2 的降水预报值均显著偏低,仅组合因子1(图10b)给出了较高概率,提示了降水系统将在不稳定区域内发展的可能性。
在华南汛期季风爆发后,暖湿平流增强,热力不稳定性导致与个例2 类似的对流性降水增多,这一类强降水通常难以被业务模式的降水预报很好反映。而通过因子分析模型,预报员可进一步结合低空环流形势对不同地区的热力条件进行分析,有助于提升对暖区对流性降水事件预报的命中率。
5 结论和讨论
利用2009—2018 年汛期(4—9 月)广东省地面气象观测站数据建立短时强降水数据集,采用ERA-Interim 再分析资料计算数十个物理量与多年平均态的偏差值。在计算物理量参数及扣除多年平均态的基础上,提出了遴选物理量的指标AROC和分期、分区域建立因子分析模型方法,在业务应用中提升预报命中率的同时控制虚警率上升,为预报难度大的暖区短时强降水提供更多参考信息。
不同月份的因子偏离度具有明显差异:前汛期各因子偏离度随月份增长而不断下降,但各因子偏离度差异较小;后汛期与热力条件有关的因子偏离度差异较大,其相对重要性与前汛期相比也明显降低;各因子在不同区域的相对重要性也有差异,多数因子具有明显的南、北反向特征。根据因子偏离度的时、空分布,划分前、后汛期以及3 个空间区域,构建6 个因子模型。将各因子贡献率作为6 个因子概率的权重,采用加权组合方法构建分期、分区的短时强降水概率预报模型,其预测效果较未分区前有明显改善。
以训练期间最优TS 评分的概率阈值作为短时强降水预报阈值,在测试期对短时强降水概率预报模型进行TS 评分检验,前、后汛期广东省大部分区域TS 评 分 在0.25 以 上, 最 高 达0.42, 相 对 于ECMWF-Fine 全场平均在前、后汛期分别提升0.23与0.21,南部沿海TS 评分提升幅度最大。模型在获得高命中率的同时,虚警率与命中率取得较好的平衡,短时强降水高频地区偏差接近1,验证了模型业务应用的有效性。选择2019 年2 次ECMWFFine 模式漏报的暖区强降水个例,概率模型对于两个个例的强降水均做出高概率预报;对于动力强迫较弱,但不稳定条件好的对流性强降水,确定性模式容易漏报,而通过分析各个因子,可知表征不稳定的组合因子1 概率较高,为业务中预报难度较大的暖区强降水提供早期预警信号。
模型中输入因子与输出概率具有明确的映射关系,能清晰反映短时强降水发生、发展的环境条件。但模型的输入因子多,并且输入因子与短时强降水发生概率存在非线性关系,因此从模型优化角度而言,可引进机器学习算法,以应对具有复杂输入、输出因子关联特征的预报建模问题。将各建模因子作为输入量,针对华南区域进行机器学习训练以获得更优的预测效果,加强气象领域的人工智能技术专业性,将是未来的发展方向。
致 谢:感谢孙继松研究员和王秀明教授的指导。
猜你喜欢
现代职业教育(2022年35期)2022-10-13
成都信息工程大学学报(2022年3期)2022-07-21
云南地理环境研究(2022年2期)2022-05-10
成都信息工程大学学报(2021年5期)2021-12-30
科技与创新(2021年12期)2021-07-10
中华养生保健(2020年7期)2020-11-16
科技与创新(2020年8期)2020-05-08
现代农业科技(2017年19期)2017-11-14
理科考试研究·初中(2017年4期)2017-11-04
试题与研究·高考理综化学(2016年3期)2017-03-28
